
Излишнее стремление к точности стало оказывать действие, сводящее на нет теорию управления и теорию систем, так как оно приводит к тому, что исследования в этой области сосредоточиваются на тех и только тех проблемах, которые поддаются точному решению. Многие классы важных проблем, в которых данные, цели и ограничения являются слишком сложными или плохо определенными для того, чтобы допустить точный математический анализ, оставались и остаются в стороне лишь по той причине, что они не поддаются математической трактовке. Л. Заде
Определение и характеристики
В мире очень многое не делится только на белое и чёрное, на правду и истину, … Человек использует множество нечётких понятий для оценки и сравнения физических величин, состояний объектов и систем на приближенном, качественном уровне. Так, любой из нас способен оценить величину температуры за окном, не прибегая к помощи термометра, а руководствуясь лишь собственными ощущениями и шкалой приближенных оценок (“достаточно пасмурно, чтобы взять зонт”).
Но качественная оценка не обладает свойством аддитивности, присущим привычным нам числам; т. е. мы не можем определить результат операций для приближенных оценок (“небольшая сумма денег” + “небольшая сумма денег”), в отличие от, к примеру, натуральных чисел (2 + 2). Не можем определить потому, что качественная оценка сильно зависит от лица, принимающего решение, контекста и смысла, вкладываемого в конкретном случае.
Однако, в мире имеется достаточно величин, которые мы не в состоянии по тем или иным причинам точно оценить: степень порядка в комнате, "престижность" автомобиля, красота человека, “схожесть" вещей, … Но работать с ними как с привычными числами хочется хотя бы для задач автоматизации.
Формализация таких оценок может основываться на теории нечётких множеств. Понятие нечёткого множества появилось в 1964 году благодаря американскому учёному азербайджанского происхождения Лютфи Заде.
Начнём рассмотрение его теории с базовых понятий.
Нечётким множеством (размытым множеством) в универсальном множестве (универсуме) U называется совокупность пар вида
, где
, а
— функция принадлежности нечёткого множества
,
. Нечёткое множество можно записать также в виде
.
Для любого элемента U функция принадлежности определяет степень принадлежности (степень принятия) данного элемента u к множеству(-ом)
. Так как функция принадлежности практически исчерпывает понятие нечёткого множества, очень часто эти два понятия отождествляют. Поэтому можно встретить как кто-либо определяет нечёткое множество лишь задав функцию принадлежности.
Одной из трактовок является вероятностная трактовка (не принимаемая Л. Заде), по которой значение функции для данного элемента – вероятность его нахождения в этом множестве. Другой – степень чёткости элемента из множества U на множестве
. Вообще говоря, трактовка исходит из задачи, которая решается методами нечёткой математики.
Привычные нам чёткие множества, в которых функция принадлежности имеет вид , являются таким образом частным случаем нечётких множеств.
Как принято, можно задать несколькими способами:
- графика или диаграммы (в непрерывном и дискретном случаях соответственно);
- формулы;
- таблицы;
- суммы или интеграла;
- ...
Например
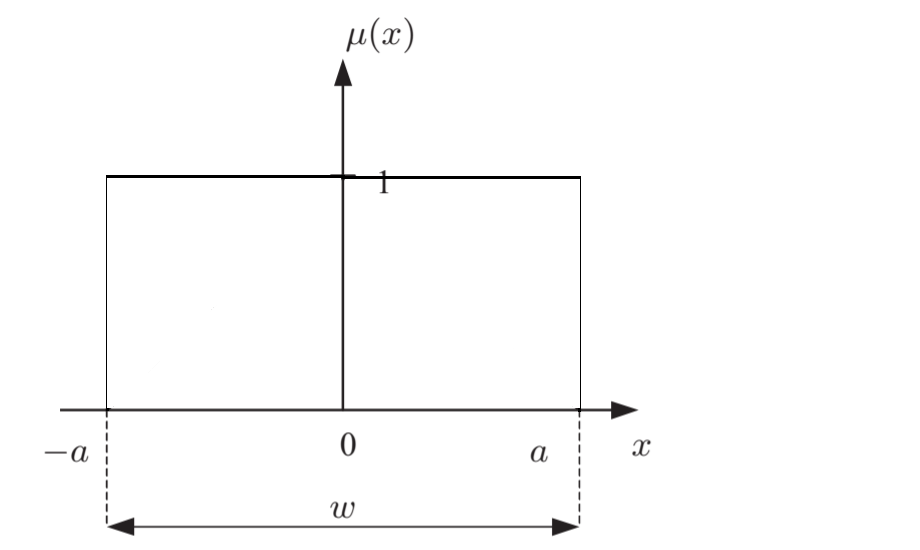
Непрерывная характеристическая функция принадлежности элементов множества действительных чисел к чёткому множеству -a?x?a.
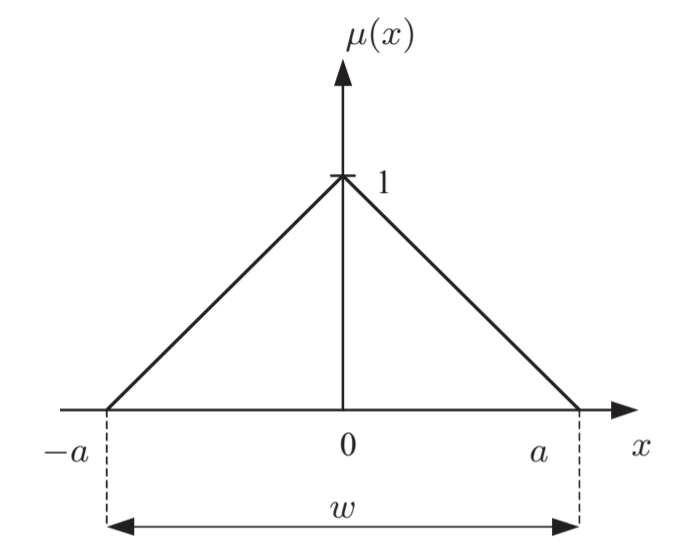
Непрерывная функция принадлежности элементов множества действительных чисел к нечёткому множеству чисел “примерно ноль”.
.
Рассмотрим основные понятия и характеристики нечётких множеств.
Чёткое значение множества – значение, степень принятия которого равна 1. На показанном примере чётким значением является только число 0.
Элементы, для которых значение равно 0.5, называются точками перехода нечёткого множества. Точками перехода в примере являются -a/2 и a/2.
Высотой нечёткого множества является величина .
Нечёткое множество нормально, если его высота равна 1, иначе оно субнормально. Каждое нечёткое множество возможно нормализовать – поделить значение функции принадлежности для каждого элемента на высоту множества.
Очевидно, что, если для каждого элемента универсального множества его функция принадлежности к А равна 0, то такое множество называется пустым.
Нечёткое множество унимодально, если функция принадлежности равняется 1 лишь для одного элемента.
На картинке 2 ограничивает область
– носитель множества
. Обычно в литературе носитель нечёткого множества обозначается как
или
.
Функция принадлежности относится к классу с конечным носителем, если существует такой элемент x, для которого ; с бесконечным – когда существует
.
Операции над нечёткими множествами
Все сравнения и операции, проводимые над нечёткими множествами, определяются через действия над их функциями принадлежности. Также необходимо несколько оговорок:
- Так как нечёткие множества являются обобщением известных нам классических, то в частных случаях операции должны сводиться к привычным нам;
- Сравнение и выполнение операций над множествами возможно только тогда, когда они определены в одном универсуме;
- Несмотря на то, что одно и то же множество может быть определено разными функциями, формально мы обязаны говорить о различных нечётких множествах.
Для всех операций и сравнений мы будем иметь в виду: — нечёткие множества на U, все
. Итак, начнём.
Равны два множества тогда и только тогда, когда
.
Множество включено в другое тогда и только тогда, когда
для любого x.
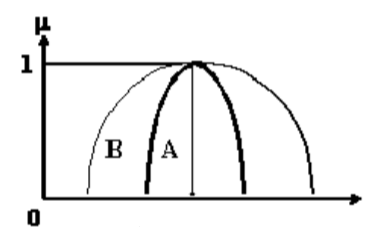
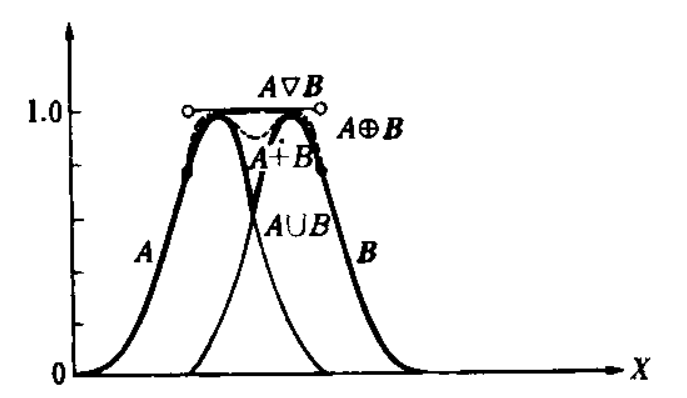
Объединение множеств такое, что
. Объединение соответствует союзу ИЛИ и обозначается короче, как
. (t–конорма или s–норма)
Пересечение множеств такое, что
. Пересечение соответствует союзу И и обозначается короче, как
. (t-норма)
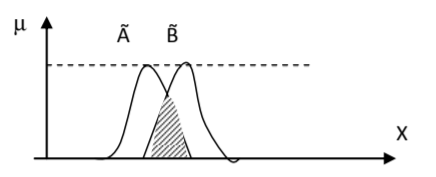
Следующие соотношения доказываются графически:
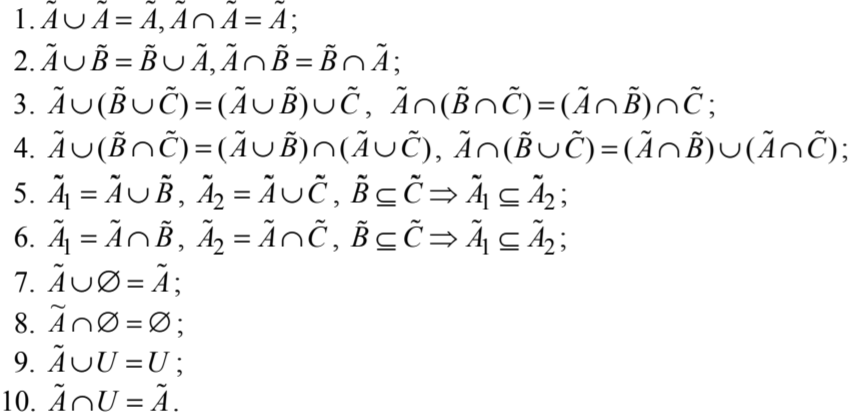
Существует несколько способов определения базовых операций пересечения и объединения. К примеру, для операции пересечения иногда используют алгебраическое произведение функций принадлежности, их среднее геометрическое и несколько иных. Выбор того или иного подхода зависит от конкретной задачи, когда использование операций min и max приводит к неадекватности модели реальной ситуации.
Разность множеств такая, что
.
Разность называется дополнением нечёткого множества и обозначается
. Из определения разности множеств следует, что
.
Введённые операции совпадают с аналогичными для чётких множеств. Далее читатель может сам попробовать доказать соотношения, сходные с законами де Моргана, и найти те, которые в общем случае не выполняются (например, ). Рассмотрим специфичные для нечётких множеств:
?-разбиение нечёткого множества. Множеством ?-уровня нечёткого множества называется чёткое множество , для элементов которого
.
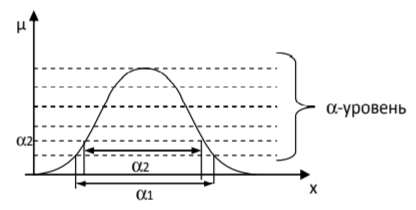
Теорема о декомпозиции. Всякое нечеткое множество разложимо по его множествам уровня в виде , M — область значений функции принадлежности.
Возведение в степень такое, что
. Наиболее употребительны частные случаи:
- Концентрирование при ? = 2 ( CON(A) ). Снижает диапазон определения информации, представляемой нечётким множеством. Можно сказать, что концентрирование является аналогом словосочетания “более чем” для множества;
- Растяжение при ? = 0.5 ( DIL(A) ). Наоборот, расширяет диапазон. Заменяет выражение “почти что”.
Замена концентрирования и растяжения оценочными выражениями имеет больше смысла при использовании лингвистических переменных.
Алгебраическое произведение .
Граничное произведение .
Драстическое произведение .
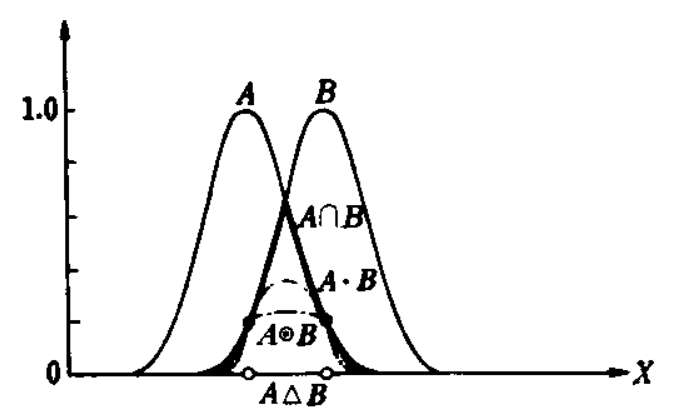
Алгебраическая сумма .
Граничная сумма .
Драстическая сумма .
Лямбда-сумма – среднее A и B с весами ? и (1 — ?) (или выпуклое линейное объединение первого порядка A и B). .
Между произведением, суммой и ?-суммой справедливо соотношение:

Каким образом можно построить функцию принятия?
Функция принадлежности должна быть задана вне самой теории нечёткой математики и, следовательно, её адекватность не может быть проверена средствами непосредственно самой теории. Это мешает применению нечёткой теории множеств для решения прикладных задач. Исходя из природы субъективных оценок, построение функции может выполняться лишь по экспертным оценкам (эксперта называют также лицом, принимающим решение ЛПР). Выделяют 2 группы методов построения – прямые и косвенные.
Прямые определяются тем, что ЛПР непосредственно задаёт правила определения значения функции принадлежности. Они, как правило, используются для описания понятий, которые характеризуются измеряемыми параметрами и в которых шанс ошибок и искажений незначителен. Группа включает в себя такие методы как: частотный, метод парных соотношений.
В косвенных методах экспертная информация является только исходной для дальнейшей обработки, значения функции выбираются таким образом, чтобы удовлетворить заранее сформулированным условиям. Например, на основе стандартного набора графиков.
Вообще говоря, функция принятия может иметь какой угодно вид, учитывая, конечно, некоторые ограничения, такие как:
- 0 <= ?(x) <= 1;
- Функция должна быть нормальной (если не оговорено обратное);
- В функции и множестве определяемых функций должна присутствовать естественная разграничиваемость понятий, представленных соседними множествами;
- Не должно возникать промежутков на универсальном (или же ограниченном для рассмотрения) множестве, для которых не поставлено в соответствие какое-либо множество;
- Для соседних множеств максимум одного должен совпадать с минимумом другого, а точка пересечения их графиков – соответствовать точкам перехода;
- и некоторые другие, зависящие от задачи.
хотя существуют и исключительные ситуации, в которых определять функцию приходится исходя из контекста. Построение таких функций – отдельная и достаточно сложная тема.
А на сегодня всё.




MinimumLaw
Привет Fuzzy Logic, давненько о тебе не было слышно…
По сути вопрос прост: каким видется практическое применение данных выкладок, и как такой вариант может работать с современными дискретными или аналоговыми решениями.
Когда-то подобные блоки вставляли в контроллеры и вполне уважаемые производители убеждали всех в том, что за этим будующее. Будующее наступило. А господству дискретных систем пока никто и ничего противопоставить не может. Как же так? И что с этим можно (и нужно ли) делаать?
d0rj Автор
Первое, что приходит на ум, это прикладная лингвистика и распознавание образов. Судя по количеству работ по теме, эти два направления довольно мейнстримные. Также довольно часто упоминают "задачи управления", по типу автоматизации заводов, управления поездом и тд.
По поводу господства дискретных контроллеров ничего сказать не могу. Самому кажется, что применение НМ оправдано пока лишь на программном уровне.
MinimumLaw
Я пока не очень понимаю вот какой момент — есть аналоговый сигнал. Пусть и пропущенный через АЦП. С ним все понятно. Есть дапазон от нуля (минус максимум) до максимум (плюс максимум). Дальше в ним можно что-то делать. Умножать, складывать — обрабатывать одним словом. Есть дискретный сингал. Ну в смысле или есть, или нет. И на наличие-отсутствие или изменение состояния можно реагировать.
Что должно быть на входе с нечеткой логикой? Какими средствами будет выполняться (и требуется ли) нормализация сигналов по входам? Как быть с блоками нечеткой логики. Ведь наверняка одной-двух жестко заданных операций окажется мало и будет ли с этого выхлоп, больший чем с DSP обработки (а то и прогонке через нейросети)?
Идея сама по себе довольно интересная, но прикладная реализация неочевидна. Тем более, что попытки уже были. И, думаеся мне, закончились ровно на тех вопросах которые я озвучил. Впрочем, вариант «жестких блоков», заточенных под распознавание образов или текстов — это может быть крайне интересно. Но мат аппарат… Не факт, что это получится лучше (дешевле?) какой-нить специально обученной нейросети.
Пока приятен тот факт, что сама идея нечеткой логики не погибает. А раз так, то есть шансы на ее реинкарнацию. В контроллерах ли, или ПК/серверах уже не столь и важно. Спасибо за ответ.
Vilyx
Из моего опыта, нечёткая логика годится только для управления поведением, не встречал ничего о распознавании.
На входе могут быть данные любых величин, они на этапе фаззификации нормализуются.
Гораздо интереснее в нечёткой логике то, что можно делать ИИ для игр, даём каждому персонажу на вход набор каких-то игровых данных, а потом пишем логику
ЕСЛИ врагов_вокруг ЕСТЬ мало ТО дерёмся
ИНАЧЕ убегаем
а другому юниту пишем логику
ЕСЛИ врагов_вокруг ЕСТЬ мало ИЛИ друзей_рядом ЕСТЬ много ТО дерёмся
ИНАЧЕ убегаем.
Неплохая такая альтернатива графу поведений.
Больше в своей практике не нашёл применений этому инструменту.
Griboks
Таково положение нечёткой логики, т. е. она что-то знает (вероятность не используется), но это не точно (аналитических формул не составить). Поэтому она пригодна только тому, кто готов считать вручную и всецело доверяет экспертам. Иными словами, от экспертов для экспертов, которым это не нужно, ибо они сами эксперты. А поскольку люди ленивы, а эксперты некомпетентны, применяется либо полностью вероятности, которые автоматизированы (привет от нейросетей), либо нормальные формулы (привет от алгоритмов). Вот и не находится место для нечётких вычислений.
Akon32
Это такие же экспертные оценки, только вместо эксперта нейросеть.
Griboks
Только я могу взять любую (аналогичную) нейросеть и получить точно такой же результат. А в нечётких вычислениях разные эксперты дают разные результаты, невоспроизводимые и непредсказуемые.
Кроме того, нейросети работают с уже имеющимися фактами. А вот эксперты предсказывают вероятность на основе своего опыта.
d0rj Автор
Под экспертом (или лицом, принимающим решения) здесь понимается скорее что-то по типу вектора правильных ответов, на подобие обучения нейросети с учителем.
Akon32
Всё не так.
Нейросети, обученные на немного разных данных, или с разными векторами инициализации, или имеющие разную структуру, могут давать различающиеся результаты.
Эксперты могут давать одинаковые ответы, особенно если они компетентны и вопрос имеет однозначный ответ.
Нейросети имеют некоторую способность к обобщению, их "опыт" — это весовые коэффициенты, вычисленные во время обучения.
В данном случае разницы между нейронной сетью и экспертом вообще нет. Здесь можно подставить любой "чёрный ящик".
Griboks
Вы не поняли. Если мы возьмём две одинаковы нейросети и обучим их по одинаковым алгоритмам, то получим одинаковые результаты. Если во время обучения с учителем мы случайно где-то ошибёмся (нашумим), то различие в результатах будет статистически незначимым. Поэтому мы можем прочитать статью и повторить её у себя дома на компьютере.
Если мы возьмём двух одинаковых экспертов с одинаковыми послужными списками, возрастом и т. д., то их экспертные оценки будут ощутимо различаться в контексте нечётких вычислений и давать разные результаты.
А могут и не давать. А как это проверить? А никак, если только не нанять других экспертов.
А опыт экспертов — это непонятно что, вычисленное непонятно когда, непонятно из каких исходных данных. Да, вы можете доказать, что именно ваши эксперты имеют именно определённый опыт и «правильные» оценки, только это уже будет статистический подход, а не нечёткий. Почему? Потому что можно будет заменить экспертов на формулу из статистики.
В каком случае?
Нет, разница есть, минимум в вычислительной природе. Если бы разницы не было, то не было бы и нечётких вычислений, просто появился бы новый класс нейронных сетей. Ой, подождите, уже появился, и это совершенно другое понятие.
Akon32
Для чистоты эксперимента возьмите двух одинаковых экспертов, при этом одинаково обученных. Это эквивалент одинаковым нейросетям. Внезапно, процент одинаковых ответов будет высоким. Независимо от правильности.
Конечно, это естественно, что одинаково обученные нейросети выдают одинаковые результаты, а различно обученные эксперты — различные результаты. Результат-то от обучения и от опыта зависит.
Мы задаём вопрос и получаем ответ. Каким образом он получен — не важно, важен только ответ. Это, фактически, "чёрный ящик", в обоих случаях. По поводу того, чего мы не знаем, мы консультируемся с "экспертом".
Или вы намекаете, что отличие в том, что двух одинаковых людей не найти? Но ведь по конкретному вопросу разные люди могут иметь одинаковое мнение.
Griboks
Вы всё-таки не поняли меня. Хорошо, обозначим эксперта как f(x), а нейросеть как g(x).
Вот, что я утверждаю:
(1) |f1(x) - f2(x)| > e(2) |g1(x) - g2(x)| < e
(3) |f(x) - g(x)| >> e
, где x — исходные данные, e — неточность.
Да, вы можете представить экспертов как чёрный ящик h(x). Но тогда
h(x) = rand().Кроме того, точность такого чёрного ящика слишком плохая.
Кроме того, как регулировать чёрный ящик?
Кроме того, этому чёрному ящику нужно ещё и заплатить за работу.
Иными словами, нечёткая логика — плохой чёрный ящик, а нейросети и аналитические формулы — хороший, поэтому их и используют.
d0rj Автор
Мне кажется, что проблема в вашей пресупозиции относительно обучающей выборки для нейросетей и системы на основе нечёткой теории (для простоты будем считать, что они раздельны и не пересекаются). Почему вы думаете, что данные для обучения нейронной сети всегда объективны (что бы это ни значило), а данные для нечёткой системы — всегда случайные? Ведь и там и там используются разнородные данные из разных источников; к примеру, странно будет учить нейросеть распознавать машины на примерах одного лишь Логана, как и странно будет строить функции принадлежности (хотя иного выхода порой нету) на основе данных одного эксперта.
Griboks
Окей, не нравится моя математика, приведу аналогию.
К вам на работе подходит начальник и сообщает, что лишает вас новогодней премии. Он объясняет это тем, что фирма наняла эксперта (в вашей области), который сказал, что вы очень плохо работаете.
У вас сразу возникнут вопросы. Что за эксперт? Откуда он такой? На основе каких данных он так решил? На основе каких умозаключений он так решил? Почему начальник ему (рандомному челу) доверяет больше, чем вам (многолетнему сотруднику)? Да и, собственно, шо за редиска с горы ваши деньги забирает.
Другой начальник объясняет это тем, что вы не выполняете KPI. Что за KPI — прописано в контракте. Почему не выполняю — заданы нормы. Откуда нормы — статистические данные за прошлый квартал коллег в этой области в фирме. Тут уже и не поспоришь, в суд не подашь и т. д.
Возвращаясь к нейросетям:
Данные для обучения — это статистические данные, это формулы. И ошибки появляются только из-за неправильной методики сбора этих данных. Очевидно, что даже пьяный Петрович не сможет каждый день в течение года специально или случайно подменять показания, например, счётчика. Мы исключаем человеческий фактор, остаётся сухая математика.
Эксперты — это люди. Здесь человеческий фактор очень решает. Кроме того, центральная предельная теорема тут не работает, поэтому количество переходит только в накопление ошибки.
Так почему же компании вместо 10 000 экспертов используют 10 000 фотографий? Это ведь так очевидно, просто наймите недостающих экспертов, да?
Vilyx
Мне кажется, что неверно понимаете суть «эксперта» в нечёткой логике. Когда у вас есть 10000 размеченных фотографий, то в понимании нечёткой логики у вас эксперты их разметили.
Для чего нужна нечёткая логика, для случаев когда слишком сложно обучить нейросеть, но построить правила для получения вывода достаточно легко, и входные данные понятны или даже очевидны.
Например, возьмём StarCraft2, можете посмотреть как там работает AlphaStar. Чем дальше обучается, тем хуже играет, потому, что основная часть игр происходит между агентами, а игр против человека слишком мало.
С другой стороны нечёткая логика, можно построить ИИ управляющий армиями. Обозначить правила поведения в формате:
ЕСЛИ противников=много ТО убегать
а вот что значит «много» нам скажут «эксперты», это может быть один профессиональный игрок или много любителей, в итоге окажется не так важна точность их показаний.
Поведение нейронной сети непредсказуемо, может быть так что в обучающую выборку не попал частный случай и с ним будут ошибки, а в нечёткой логике можно построить систему принятия решений, которая учтёт все возможные исходные условия.
d0rj Автор
Не хотел вас никак задеть.
Очевидно, что я и вы говорим о разных понятиях, называя их одним словом. Ну или вы пытаетесь привести аргумент через аналогию, что не корректно, особенно в данном случае. И вот почему. Из вашего комментария понятно, что, употребляя слово «эксперт», вы имеете ввиду человека, который конвенционально разбирается в данном вопросе лучше остальных. Я же, как и, смею предположить, Заде, понимаю под этим словом вообще любой источник, которому мы доверяем, из которого черпаем «правильные ответы» для построения новых и корректировки существующих функций принадлежности. Да, в основном этими «экспертами» являются люди, ведь применяется теория чаще всего в связи с размытыми понятиями, которые по своей природе не отрывны от человека. Их не представляется возможным описать одним набором значений, как с изображением машины.
Приведу пример, для объяснения разницы. Чтобы «научить» программу распознавать автомобили, мы показываем ей
разнообразных машин. Достаём или создаём этот массив данных,
обучаем — вуаля. Валидность ответов не вызывает сомнения, Рено Логан и в Африке Логан; хотя в выборке тысячи моделей машин со своими особенностями строения, не говоря уже о внешнем виде. Грубо говоря, мы имеем возможность запечатлеть конкретный пример понятия (отражение эйдоса в реальном мире, если угодно) одним вектором значений (множеством в случае выборки). Обучить модель можно и другими методами: можно при выводе картинки на экран отвечать, машина это или нет))) и тд.
У нас не получится ни каким образом, кроме как интуитивными ответами конкретного человека, запечатлеть на носителе проявление понятия «бюджетный» по отношению к автомобилю, даже учитывая контекст.
Возвращаясь к разнице в понимании слова «эксперт».
В случае обучения нейронки, экспертом, в моём понимании, будет либо источник, у которого позаимствовали выборку, либо вы, как тот, кто эту выборку создаёт. Хоть их и можно назвать «статистическими», проблема в том, что ответы эксперта в случае построения ФП для НМ в таком случае так же можно назвать статистическими. Качественной разницы в двух выборках, на мой взгляд, нету (буду рад, если покажете её).
Последнее, что хотелось опровергнуть, — нематематичность теории нечёткости. Человеческий фактор может влиять и на выборку для нейронной сети, раз на то пошло. Как вы сами и сказали, неправильная методика, переобучение и тд. «Сухая математика» работает по обе стороны — что в построении нейронки, где по чётко заданному алгоритму на каждом шаге корректируются веса на ней всей (она суть «большая сложная функция»), что в построении ФП для НМ, в котором происходит примерно то же, но сама функция зачастую проще.
Позволю себе заметить, что было бы странно ожидать выполнения теоремы, относящейся к теорверу, от теории, никак не претендующей на отношение к нему.
Извиняюсь за многословный ответ.
Griboks
Допустим, вы правы, и я недостаточно хорошо разбираюсь в нечёткой логике и её экспертах. Но в чём же тогда, по вашему мнению, причина её абсолютной непригодности в реальном мире? Если, конечно, я неправильно определяю только причину, а не проблему целиком.
d0rj Автор
Если честно, то я не думаю, что она «абсолютно не пригодна». Судя по количеству статей и трудов, её уже давно и довольно успешно применяют в различных областях, как и машинное обучение, которое начали пробовать прикладывать к реальным задачам в 70-80хх годах. Очень часто пишут про применение нечёткой теории в лингвистике, что неудивительно, ведь одно из нововведённых понятий — лингвистическая переменная; и в автоматизации разного рода производств.
Akon32
Ваши утверждения неверны в общем случае. Примеры, опровергающие их, я привёл выше.
Akon32
Нейронная сеть, выдающая вектор вероятностей, элементы которого соответствуют распознаваемым классам, как раз использует матаппарат нечёткой логики, а именно понятие функции принадлежности к нечёткому множеству. Без этого нейросеть выдавала бы битовый вектор (значения функции принадлежности к чётким множествам), а не вектор вещественных величин в диапазоне [0;1].
Ну и человек мыслит именно в нечёткой логике, вольно оперируя вероятностями. "Обычная" логика — редкое исключение.