
Всем привет. 26 февраля в OTUS стартовали занятия в новой группе по курсу «MS SQL Server разработчик». В связи с этим я хочу поделиться с вами своей публикацией про оконные функции. Кстати, в ближайшую неделю еще можно записаться в группу ;-).

Оконные функции прочно вошли в нашу практику, но мало кто знает как работают фреймы RANGE и ROWS.
Возможно поэтому они несколько реже встречаются. Цель этой статьи привести примеры использования, чтобы у вас точно не осталось вопросов “Кто есть кто?” и “Как это применять?”. Вопрос “Зачем?” в статье останется не освещенным.
Давайте разберемся что такое фрейм, и как схожего эффекта достичь с помощью ORDER By в предложении OVER().
Для демонстрации будем использовать простую таблицу, чтобы можно было просчитать примеры без использования компилятора. Вообще, очень рекомендую — посмотрите и продумайте, что будет в результате выполнения, а потом проверьте себя — так вы обнаружите белые пятна в восприятии работы оконных функций, которые могут быть совсем не очевидными, когда читаешь уже готовые результаты.
Таблица
Давайте начнем с простого момента — разницы функции SUM с указанием сортировки и без нее

Давайте посмотрим на первые незаметно лежащие грабли, как вы считаете сколько разработчиков в процессе чтения кода подумают, что cum и cum_uniq совпадают? Думаете немного? Возможно, но потому то тут это очевидно, а так ли очевидно это при чтении кода в приложении, да еще при не столь очевидной неуникальности поля сортировки.
Теперь откроем нашу замечательную форточку.
Форточка, а точнее фрейм бывает 2х видов ROWS и RANGE, познакомимся сначала с ROWS.
Варианты ограничения фрейма:
Но давайте посмотрим фрейм в действии.
Открываем “форточку” на текущую строку и все предыдущие, для функции SUM как видите это совпадает с сортировкой ASC
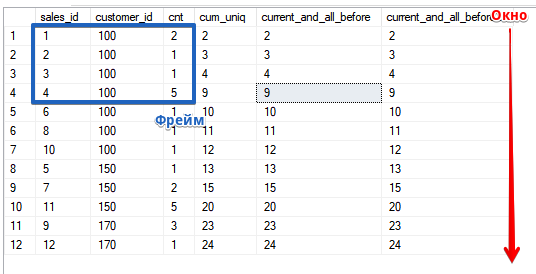
При этом хочу напомнить, что порядок сортировке в окне (в предложении OVER()) не связан с порядком сортировки в самом запрос, в примере он совпадает для того, чтобы упростить подсчет, если вы решите проверить расчет и свое понимание того, как работает функция
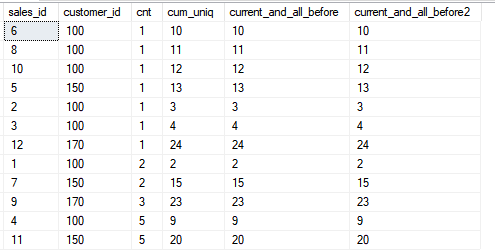
Теперь давайте посмотрим на функционал фрейма, когда мы включаем все последующие строки.

Как видите тут тоже можно получить тот же результат для аггрегатной функции, если использовать обратную сортировку — но при этом ROWS немного стабильнее, так как если ваши поля сортировки не уникальны, можно получить сюрприз в виде одинаковых значений.
И наконец вариант, который уже не сымитируешь сортировками, когда мы указываем конкретное количество строк, которые должны войти во фрейм
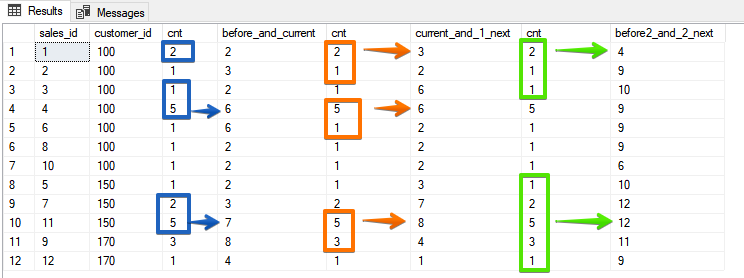
В этом вариант вы уже конкретно указываете какие строки входят в диапазон, и он, на мой взгляд, наиболее очевиден по результатам.
Разница заключается в том, что ROWS оперирует строкой, а RANGE диапазоном. Правда это очевидно из названия, но мало что объясняет на практике?
Давайте посмотрим на картинке (источник внизу статьи)
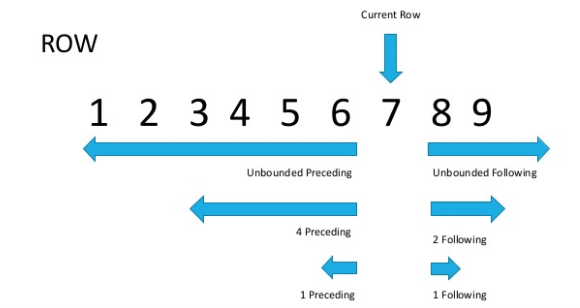
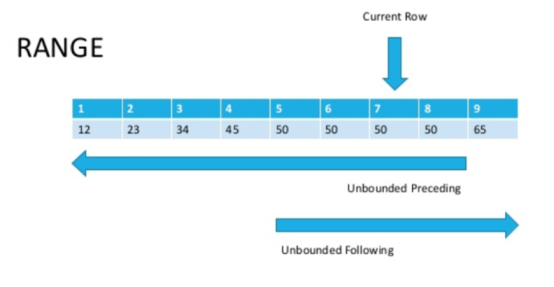
Теперь, если мы внимательно посмотрим, то станет очевидно, что диапазоном называются строки с одинаковым значением параметра сортировки.
Как уже было сказано выше ROWS ограничивается именно строкой, в то время как RANGE захватывает весь диапазон совпадающих значений, которые у вас указаны в ORDER BY оконной функции.
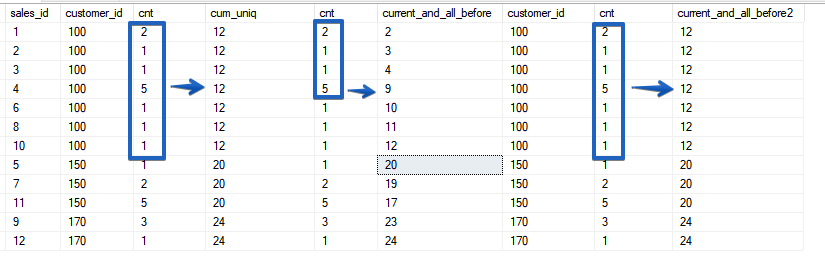
ROWS — всегда оперирует конкретной строкой, даже если сортировка не уникальна, а вот RANGE как раз объединяет в диапазоны периоды, с совпадающими значениями полей сортировки. В этом смысле функциональность очень похожа на поведение функции SUM() с сортировкой по неуникальному полю. Давайте посмотрим еще один пример.

Тут уже 2 поля и range определяется диапазоном с совпадающими значениями по обоим полям
И вариант когда мы включаем в расчет все последующие строки от текущей, который в случае с функцией SUM совпадает со значением, которое можно получить, воспользовавшись обратной сортировкой:
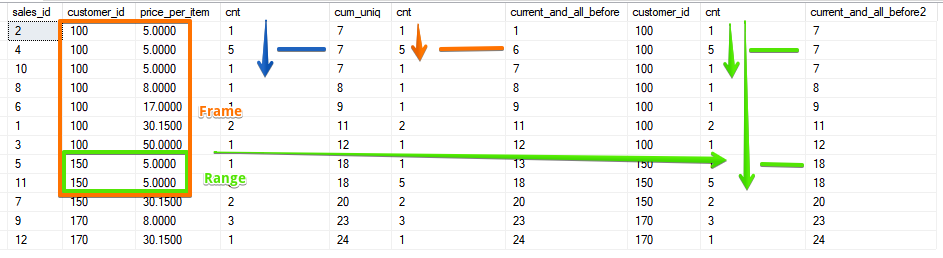
Как видно RANGE опять же захватывает весь диапазон совпадающих пар.
Несмотря на то, что функциональность ROWS и RANGE далеко не новая каждый раз возникают вопросы про то, как же ей пользоваться. Надеюсь эта статья добавила понимания чем различаются ROWS и RANGE и вы теперь не будете сомневаться в каком случае нужен тот или другой фрейм.
Источник иллюстрации про разницу RANGE и ROWS
Window functions with SQL Server 2016, Mark Tabladillo
Успеть на курс
Оконные функции прочно вошли в нашу практику, но мало кто знает как работают фреймы RANGE и ROWS.
Возможно поэтому они несколько реже встречаются. Цель этой статьи привести примеры использования, чтобы у вас точно не осталось вопросов “Кто есть кто?” и “Как это применять?”. Вопрос “Зачем?” в статье останется не освещенным.
Давайте разберемся что такое фрейм, и как схожего эффекта достичь с помощью ORDER By в предложении OVER().
Для демонстрации будем использовать простую таблицу, чтобы можно было просчитать примеры без использования компилятора. Вообще, очень рекомендую — посмотрите и продумайте, что будет в результате выполнения, а потом проверьте себя — так вы обнаружите белые пятна в восприятии работы оконных функций, которые могут быть совсем не очевидными, когда читаешь уже готовые результаты.
Таблица
Create table sales
(sales_id INT PRIMARY KEY, sales_dt DATETIME2 DEFAULT GETUTCDATE(), customer_id INT, item_id INT, cnt INT, price_per_item DECIMAL(19,4));
INSERT INTO sales
(sales_id, sales_dt, customer_id, item_id, cnt, price_per_item)
VALUES
(1, '2020-01-10T10:00:00', 100, 200, 2, 30.15),
(2, '2020-01-11T11:00:00', 100, 311, 1, 5.00),
(3, '2020-01-12T14:00:00', 100, 400, 1, 50.00),
(4, '2020-01-12T20:00:00', 100, 311, 5, 5.00),
(5, '2020-01-13T10:00:00', 150, 311, 1, 5.00),
(6, '2020-01-13T11:00:00', 100, 315, 1, 17.00),
(7, '2020-01-14T10:00:00', 150, 200, 2, 30.15),
(8, '2020-01-14T15:00:00', 100, 380, 1, 8.00),
(9, '2020-01-14T18:00:00', 170, 380, 3, 8.00),
(10, '2020-01-15T09:30:00', 100, 311, 1, 5.00),
(11, '2020-01-15T12:45:00', 150, 311, 5, 5.00),
(12, '2020-01-15T21:30:00', 170, 200, 1, 30.15);
Давайте начнем с простого момента — разницы функции SUM с указанием сортировки и без нее
SELECT sales_id, customer_id, count,
SUM(count) OVER () as total,
SUM(count) OVER (ORDER BY customer_id) AS cum,
SUM(count) OVER (ORDER BY customer_id, sales_id) AS cum_uniq
FROM sales
ORDER BY customer_id, sales_id;Давайте посмотрим на первые незаметно лежащие грабли, как вы считаете сколько разработчиков в процессе чтения кода подумают, что cum и cum_uniq совпадают? Думаете немного? Возможно, но потому то тут это очевидно, а так ли очевидно это при чтении кода в приложении, да еще при не столь очевидной неуникальности поля сортировки.
Теперь откроем нашу замечательную форточку.
Форточка, а точнее фрейм бывает 2х видов ROWS и RANGE, познакомимся сначала с ROWS.
Варианты ограничения фрейма:
- Все, что до текущей строки/диапазона и само значение текущей строки
BETWEEN UNBOUNDED PRECEDING
BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
- Текущая строка/диапазон и все, что после нее
BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING - С конкретным указазнием сколько строк до и после включать (не поддерживается для RANGE)
BETWEEN N Preceding AND N Following
BETWEEN CURRENT ROW AND N Following
BETWEEN N Preceding AND CURRENT ROW
Но давайте посмотрим фрейм в действии.
Открываем “форточку” на текущую строку и все предыдущие, для функции SUM как видите это совпадает с сортировкой ASC
SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY customer_id, sales_id;При этом хочу напомнить, что порядок сортировке в окне (в предложении OVER()) не связан с порядком сортировки в самом запрос, в примере он совпадает для того, чтобы упростить подсчет, если вы решите проверить расчет и свое понимание того, как работает функция
SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY cnt;Теперь давайте посмотрим на функционал фрейма, когда мы включаем все последующие строки.
SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_frame,
SUM(cnt) OVER (ORDER BY customer_id DESC, sales_id DESC) AS current_and_all_order_desc
FROM sales
ORDER BY customer_id, sales_id;
Как видите тут тоже можно получить тот же результат для аггрегатной функции, если использовать обратную сортировку — но при этом ROWS немного стабильнее, так как если ваши поля сортировки не уникальны, можно получить сюрприз в виде одинаковых значений.
И наконец вариант, который уже не сымитируешь сортировками, когда мы указываем конкретное количество строк, которые должны войти во фрейм
SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS before_and_current,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS current_and_1_next,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) AS before2_and_2_next
FROM sales
ORDER BY customer_id, sales_id;В этом вариант вы уже конкретно указываете какие строки входят в диапазон, и он, на мой взгляд, наиболее очевиден по результатам.
Разница ROWS и RANGE
Разница заключается в том, что ROWS оперирует строкой, а RANGE диапазоном. Правда это очевидно из названия, но мало что объясняет на практике?
Давайте посмотрим на картинке (источник внизу статьи)
Теперь, если мы внимательно посмотрим, то станет очевидно, что диапазоном называются строки с одинаковым значением параметра сортировки.
Как уже было сказано выше ROWS ограничивается именно строкой, в то время как RANGE захватывает весь диапазон совпадающих значений, которые у вас указаны в ORDER BY оконной функции.
SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, sales_id;ROWS — всегда оперирует конкретной строкой, даже если сортировка не уникальна, а вот RANGE как раз объединяет в диапазоны периоды, с совпадающими значениями полей сортировки. В этом смысле функциональность очень похожа на поведение функции SUM() с сортировкой по неуникальному полю. Давайте посмотрим еще один пример.
SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item;Тут уже 2 поля и range определяется диапазоном с совпадающими значениями по обоим полям
И вариант когда мы включаем в расчет все последующие строки от текущей, который в случае с функцией SUM совпадает со значением, которое можно получить, воспользовавшись обратной сортировкой:
SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id DESC, price_per_item DESC) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item, sales_id desc;Как видно RANGE опять же захватывает весь диапазон совпадающих пар.
Несмотря на то, что функциональность ROWS и RANGE далеко не новая каждый раз возникают вопросы про то, как же ей пользоваться. Надеюсь эта статья добавила понимания чем различаются ROWS и RANGE и вы теперь не будете сомневаться в каком случае нужен тот или другой фрейм.
Источник иллюстрации про разницу RANGE и ROWS
Window functions with SQL Server 2016, Mark Tabladillo
Успеть на курс
gleb_l
Вот этот материал от ОТУСа годный! Пойдет в качестве закладки, cпасибо.