
Итак, что же делать? Традиционный способ CREATE INDEX WITH (ONLINE = ON) вам не подходит, потому что, например, вызывает падение системы и сердечный приступ вашего ДБА, все топы пристально следят за response time вашей системы и в случае увеличения оного приходят к вам и вашему ДБА на разговор по поводу завышенных цифр вашей компенсации за труд.
Скрипты и описанные приёмы были использованы на системе с нагрузкой 400К requests per minute, версии SQL Server 2012 и 2016 (Enterprise).
Есть два очень разных подхода создания индекса, которые используются в зависимости от размера таблицы.
Кейс № 1. Маленькая, но очень популярная таблица
Таблица 50 тыс. записей (небольшая), но очень популярная (несколько тысяч обращений в минуту). Вам нужен новый индекс и минимальное время простоя и блокировок на таблице.
В приложении весь доступ к БД только через процедуры.
При ошибке приложение сделает повторную попытку обратится к таблице.

В чём проблема применить этот индекс просто, спросите вы? С предложением WITH ONLINE = ON (да, нам повезло, и этот был Enterprise).
Дело в том, что при таком активном доступе получить блокировку (даже ту минимальную, которая нужна с опцией with Online = ON) занимает какое-то время. В процессе ожидания новые запросы ставятся в очередь, очередь копится, ЦПУ растет, ДБА потеет и нервно косится в сторону разработчиков, при этом на графиках мониторинга приложения плавно, но неотвратимо начинает повышаться ваш response time. Ваш Vice President of Engeneering нежно интересуется, а не случится ли из-за этого роста времени ответа какого-нибудь простоя системы, что в конце года доступность приложения будет оценена не 5 девяток (99,999), а ниже? А то у компании контракты, обязательства и большие штрафы в случае снижения доступности, и, конечно, не будем забывать о репутационных потерях.
Что мы сделали, чтобы избежать этой прискорбной ситуации?
Индекс системе всё-таки нужен.
Забрали права у всех, кроме текущей сессии на эту таблицу.
Применили индекс.
Да, у решения есть минус: все, кто обратился в эти секунды к таблице получит Access Denied. Если ваше приложение нормально обработает такую ситуацию и повторит запрос к базе, то стоит присмотреться к этому варианту. В случае нашего проекта этот способ отлично срабатывал. Опять же можно убрать спокойно ONLINE = ON, так как мы знаем, что во время создания индекса доступ к таблице будет только у этой сессии.
Код для применения индекса:
REVOKE EXECUTE ON [dbo].[spUserLogin] TO [User1]
REVOKE EXECUTE ON [dbo].[spUserLogin] TO [User2]
REVOKE EXECUTE ON [dbo].[spUserCreate] TO [User1]
REVOKE EXECUTE ON [dbo].[spUserCreate] TO [User2]
CREATE NONCLUSTERED INDEX IX_Users_Email_Status
ON [dbo].[Users] ([Email],[Status]);
GRANT EXECUTE ON [dbo].[spUserCreate] TO [User1]
GRANT EXECUTE ON [dbo].[spUserCreate] TO [User2]
GRANT EXECUTE ON [dbo].[spUserLogin] TO [User1]
GRANT EXECUTE ON [dbo].[spUserLogin] TO [User2]
График изменения времени ответа и процента ошибок во время тестирования под нагрузкой.
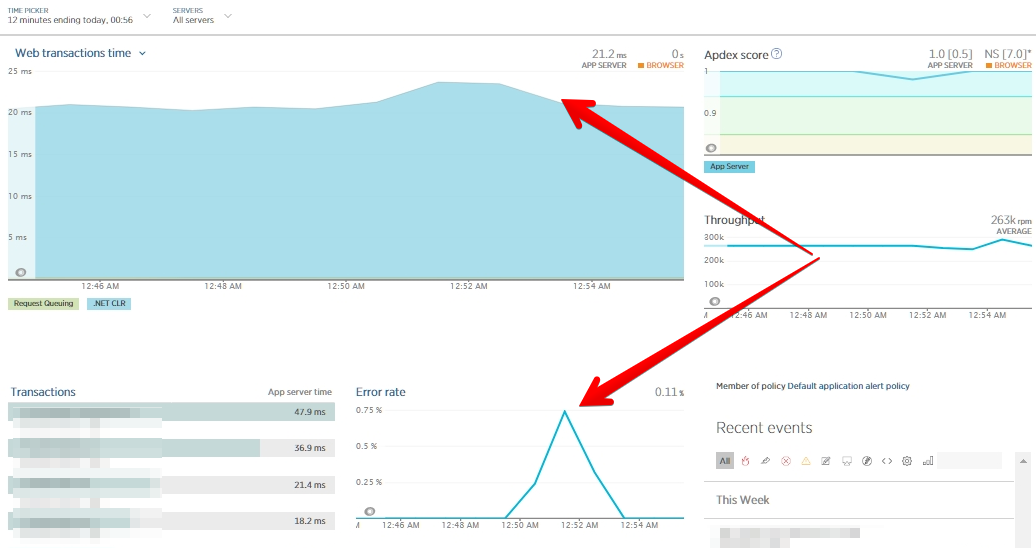
Способ можно применять, если у вас, как в описанном случае, небольшая таблица, и вы знаете, что без нагрузки индекс создастся за секунды (или за приемлемое для вас время). При этом, как вы видите из графика выше, response time приложения расти не будет, хотя видно, что error rate в секунды без доступа к таблице был выше.
Кейс № 2. Большая таблица
Если у вас большая таблица и вам нужно изменить индексы на ней, то часто самый безболезненный способ для прода — это создать рядом таблицу с правильным индексом и постепенно перенести данные в новую таблицу.
При этом есть 2 пути:
- Если у вас есть специальная процедура для изменения таблицы, вы просто меняете код процедуры, чтобы новые данные вставлялись только в новую таблицу, удаление шло из обеих, update тоже применялся к обеим, а выборка делалась из двух таблиц с UNION ALL.
- Если у вас много разных частей кода, где вы можете менять данные в таблице, то есть два популярных приема: вью с триггерами или переписывание всех частей кода на вставку данных в новую таблицу, delete из обеих и update обеих таблиц. Вью с триггерами — вариант, когда вы создаёте вью с двумя таблицами и делаете ренейм, вашу текущую таблицу переименовываете в TableOld, а вью в Table. Тогда у вас автоматом все обращения к таблице попадают на вью, тут с ренеймом может быть тоже проблема, так как нужен SchemaLock, но ренейм проходит очень быстро.
Чуть подробнее вариант про переписывание обращений на новую таблицу:
- У вас таблица Orders, создаёте новую таблицу OrdersNew с той же схемой, но уже с нужным индексом. При этом, если вы используете Indentity, то нужно установить, чтобы первое значение identity в новой таблице было равно максимальное значение в старой таблице + шаг изменения либо зазор, который вы можете себе позволить отступить от максимального значения в Orders.
- Создаём представление OrdersView, внутри которого выборка из Orders UNION ALL OrdersNew
- Изменяете все процедуры\вызовы на выборку данных из представления, вставку в OrdersNew, удаление и изменение обеих таблиц.
- Мигрируете данные из старой таблицы в новую, например, так:
DECLARE @rowcount INT, @batchsize INT = 4999; SET IDENTITY_INSERT dbo.OrdersNew ON; SET @rowcount = @batchsize; WHILE @rowcount = @batchsize BEGIN BEGIN TRY DELETE TOP (@batchsize) FROM dbo.Orders OUTPUT deleted.Id ,deleted.Column1 ,deleted.Column2 ,deleted.Column3 INTO dbo.OrdersNew (Id ,Column1 ,Column2 ,Column3); SET @rowcount = @@ROWCOUNT; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber, ERROR_MESSAGE() AS ErrorMessage; THROW; END CATCH; END; SET IDENTITY_INSERT dbo.OrdersNew OFF;
- Возвращаете все процедуры на версию до миграции — с одной таблицей. Это можно делать через alter или через удаление и создание процедур (тогда не забудьте про права), и можно переименовать новую таблицу в Orders, удалив пустую таблицу и представление.
На шаге 2 можно было, если позволяет загрузка, сделать переименование основной таблицы Orders -> OrdersOld, а OrdersView -> Orders и само представление на OrdersOld UNION ALL OrdersNew, тогда не нужно менять все места, где есть выборка из таблицы.
При переносе блоками из одной таблицы в другую данные будут фрагментированы.
Если изменяемая таблица активно используется для чтения, но данные в ней редко меняются, вы можете опять же воспользоваться триггерами — записать копию всех изменений в 3-ю таблицу — перенести данные из таблицы через bcp out и bcp in (или bulk insert) в новую таблицу, создать на ней индексы после переноса данных и затем применить изменения из таблицы с логом изменений — и переключить одну таблицу на другу — текущую, переименовав в TableOld, а новую из TableNew в Table.
Вероятность ошибок в этой ситуации несколько выше, поэтому протестируйте применение изменений и разные кейсы переключений в этом случае.
Описанные варианты не являются единственными. Они были использованы мной на высоконагруженной базе SQL Server и не вызвали проблем при применении, чем порадовали нашу команду ДБА. Такие подпрыгивания обычно не нужны для баз с более спокойным режимом нагрузки, когда можно спокойно применить изменения в часы наименьшей активности. Пользователи проекта, в котором использовались описанные подходы, находятся в США и Европе и активно используют приложение в рабочие дни и в выходные, а таблицы, на которых применялись изменения, используются постоянно в работе. Более «спокойные» объекты обычно изменялись автоматическими скриптами, сгенерированными через Redgate Toolkit после ревью скриптов разработчиком и одним из ДБА.
Всем добра! Поделитесь в комментариях, использовали ли вы что-то из этих способов или опишите свой способ! Также мы приглашаем вас на открытый урок и день открытых дверей нашего нового курса «MS SQL Server разработчик»
Комментарии (24)

alexhott
18.01.2019 19:5050 тысяч записей и 400 тыс обращений в минуту на чтение
я привык оперировать обращениями в секунду
6,6тыс обращений в секунду для среднего сервера с хорошей скоростью дисков до 500мю/с не проблема -можно на ходу добавить индекс за пару секунд
на мой взгляд не смертельно

dikkini
18.01.2019 22:42+1Почему все запросы к БД через процедуры? Есть глубинный смысл?

Vladnev
19.01.2019 11:47+2Это ведь сказ про кровавый энтерпрайз, где запросы могут жить и не меняться годами.
Получаем несколько преимуществ: это быстрее чем какой-нибудь ORM. Каждый запрос проверен на оптимальность ДБА. Не нужно потом искать кто где в приложении «накодил».
Может ещё что-то упустил.
K010mb0
19.01.2019 12:07+3Это дополнительный уровень абстракции (DAL: Data Abstraction Layer) который позволяет:
— прозрачно для приложения менять структуру данных. Можно разбить таблицу на несколько, поменять хранимку и не вносить изминения в приложения которые ей пользуются — как и описано в статье.
— безопастность (проверять на уровне базы если конкретному приложению разрешено читать\писать поле\столбец. Также всякие SQL Injection разбиваются об параметры хранимых процедур)
— производительность (запрос парсится только один раз)
— разработчики могут ничего не знать про структуру хранения данных и фокусироваться на коде приложения, а отдел работы с базой — заниматься только базой
…
плюсов много на самом делеdikkini
20.01.2019 04:01+1KristinaMyLife, Vladnev, отвечаю всем :)
Тут все таки ещё важно ответить на ещё один вопрос: бизнес логика внутри этих процедур или в приложении?
Если бизнес логика в приложении(не в БД), то минусы вот такие:
- каждый релиз — стоп системы, либо пляски с невероятными решениями по обновлению процедур и прочих компонентов, уровень изощрённости решений, примерно как в статье, только в статье описывается кейс, который может приключится раз в пол года, а релизы обычно каждую неделю/два дня;
- новый функционал: рекомпиляция всех связанных процедур, с теми что рекомпилируются;
- как только у вас появляется сложный запрос — появляется динамика (своеобразный eval из мира JavaScript);
- сложность (невозможность?) шардирования;
- ALTER TABLE? Изменение ее только приложения, но и рекомпиляция процедур;
- ещё одна сущность, которую необходимо тестировать, если внутри процедуры что-то меняется, дополняется;
Это то, что сходу пришло в голову.
Пожалуй, из плюсов есть только безопасность.

KristinaMyLife Автор
20.01.2019 11:41В проекте бизнес логика и в БД тоже, это мне кажется довольно холиварный вопрос, на который у меня нет ответа, потому что так сложилось, что все проекты, в которых я работала имели много бизнес логики в бД, а хотелось бы помимо теории, попробовать руками.
Теперь по пунктам:
- про управление релизами всегда есть код для релиза в БД и приложения, конечно ни о каком полном стопе не может быть и речи, процедуры всегда делаются с обратной совместимостью и сначала накатывает код для БД, потом обновляется приложение. Код для релиза базы готовится с помощью специального ПО, которое помогает сформировать скрипты для деплоя и отката изменений в случае чего, всегда делается версия для отката изменений и пишется иснтрукция для ДБА, если откат много ступенчатый и сложный, но обычно нужно просто последовательно применить файлы с sql кодом на базу.
- это sql server и ненужно вызывать рекопиляцию, как кажется надо делать в Oracle, server сам рекомпилирует процедуры, ситуаций, когда этого не случалось или рекомпиляция почему то ломалась не было.
- про eval — простите нужно больше деталей, не очень понимаю о чем речь, писала на javascript довольно давно, но возможно это решается походом в кэш (он есть)
- сложность шардирования — да, это сложно и тут БД шардированы и это был целый проект по шардингу, я его не застала и пришла в команду уже после
- тоже про alter table — в теории да, по факту даже когда таблица меняется и она используется во многих процедурах это не вызывает проблему на сервере (спасибо разработчикам СУБД)
- да тесты — это головная боль, в проекте нет отдельных тестов для БД, есть тесты для приложения, если в БД есть отдельный функционал, обычно там же добавляют тесты для его проверки через приложение.
Совсем не обязательно этот подход является оптимальным, ситуация as is, и подходы к ее решению скованы пока тем, что не переписываем все заново, хотя возможно к этому и придут.
KristinaMyLife Автор
19.01.2019 12:09Vladnev и K010mb0 уже хорошо ответили на вопрос, это и правда кровавый enterprise про большую нагрузку и с оптимизированными запросами с хранимыми процедурами работает хорошо (кэш планов процедур и прочие плюшки).
Кроме того хотя и были agile команды, все равно ест люди, которые хорошо видят, что может вызвать проблемы на базе, а другие что в коде приложения, получается что можно разделять ревью, что и делали, даже проект на БД и приложение разные и это позволяет быстрее проходить ревью.
Naves
19.01.2019 11:21Не совсем понятен первый случай.
Не хотим увеличивать время отклика, поэтому начинаем пляски с бубном. 0,75% запросов получают быстрый отклик в виде ошибки, которая передаётся приложению. Приложение или начинает заново стучаться в базу, или выплевывает конечному клиенту некую заглушку вида «приходите позже, у нас обед». И тогда в любом случае увеличится показатель response time для конечного клиента.Vladnev
19.01.2019 11:51Как вариант запросы идут в асинхронном или многопоточном коде, и есть полезная нагрузка которую приложение может делать пока паралельно пытается достучаться к базе.
хотя если это так — то стоило это указать)
KristinaMyLife Автор
19.01.2019 12:15Приложение фоновое и оно просто постучится к БД еще раз с тем же запросом, и уже попадет на рабочую БД. Получается мы перестаем обслуживать запросы к одной таблице, но зато остальные запросы не подвергаются влиянию, во время применения индекса.
По сути мы немного избавляем сервер от необходимости выстраивать очередь доступа к этой таблице на время применения индекса, что экономит его ресурсы и он спокойно обрабатывает другие запросы и делает наш индекс.Vladnev
19.01.2019 12:39Действительно, ведь БД нужно поддерживать все эти соединения и работать с очередью.
А у вас есть порядки цифр сколько нужно ожидающих запросов чтобы БД начала деградировать, в конкретно вашем случае?KristinaMyLife Автор
20.01.2019 11:27Нет к сожалению, хотя данные интересные и по идее их можно было бы собрать на нагрузочном тестировании.
kolu4iy
19.01.2019 19:17Я бы, пожалуй, при таких ограничениях смотрел уже в сторону от ms sql, ибо нарушение sla и репутационные потери в итоге выйдут дороже лицензий… Понятно — рефакторинг, все такое, но это уже как-то в описанных условиях выглядит ненадёжно.
KristinaMyLife Автор
20.01.2019 11:44В этом есть своя соль, к сожалению всегда проблема в балансе между ресурсами команды на рефакторинг и добавлении новых фич, чтобы успеть за рынком, пока баланс сильно смещен в сторону новых фич, и рефакторинг происходит в момент, когда «уже дальше так нельзя». Некоторый функционал переведен на решения не через MS SQL.
kolu4iy
20.01.2019 13:39+1Да, мы кажется об одном и том же говорим. Дело в том, что те самые новые фичи скоро может стать просто невозмодно вывести в продакшн без нарушения sla. С денежной точки зрения вы сейчас близки к максимуму эффективности, но с технической — у вас просто нет права на ошибку. С учётом того, что команда состоит из людей (причем даже не космонавтов, а обычных людей), так делать просто нельзя.
Ну, это все имхо, разумеется.
kl09
21.01.2019 01:56Высоканагружееная система? Наверняка есть реплики. Не проще ли это сделать переключением мастера
KristinaMyLife Автор
21.01.2019 08:38Да есть реплики, мастер и read-only в Availability Group. Изменения я могу применить только на master реплику, то есть сделать изменения схемы для read реплики и потом failover на нее не получится.
Для read с read-only реплики эта таблица не использовалась, так как к сожалению в SQL Server 2012 были нюансы с выборками с read-only реплик по производительности.kolu4iy
21.01.2019 09:32так как к сожалению в SQL Server 2012 были нюансы с выборками с read-only реплик по производительности
Мы пока не нарывались, если честно. А вот на фрагментацию индексов и «съезжающие» статистики — было дело. Кстати, а что вы делаете с фрагментацией индексов? У вас есть технологическое окно?
vagon333
Для SQL Server рассмотрите вариант Memory-Optimized Table с сохранением данных (SCHEMA_AND_DATA).
К сведению: у Microsoft есть группа чуваков, которые специализируются, как консультанты, на переносе нагрузки клиентов на Memory-Optimized Table. Успешное решение.
epee
вот не стал бы я так вот влоб советовать высоконагруженую таблицу, на которую хотят повесить новый индекс, переносить в Memory-Optimized таблицу
у Memory-Optimized таблиц помимо плюсов хватает ограничений (их конечно с каждой новой версией становится меньше, но тем не менее). кроме того они работают в редакции Enterprise.
вот тут есть над чем призадуматься
docs.microsoft.com/en-us/sql/relational-databases/in-memory-oltp/unsupported-sql-server-features-for-in-memory-oltp?view=sql-server-2017
docs.microsoft.com/en-us/sql/relational-databases/in-memory-oltp/transact-sql-constructs-not-supported-by-in-memory-oltp?view=sql-server-2017
Но конечно, если удастся таблицу перенести в Memory-Optimized выигрыш в производительности должен быть существенным
vagon333
Обсуждение ограничений — офтоп к текущему посту.
Обратите внимание: обращение к таблице через хранимки снижает шансы нарваться на ограничения.
Хранимки для работы с таблицей нужно сконвертить под Natively Compiled SPs.
К разговору о скорости: в реальных задачах получали 2-3 раза повышение скорости по сравнению с disk based tables.
KristinaMyLife Автор
У нас были SQL Server консультанты, но почему то ни мы ни консультанты не смотрели в ту сторону, хотя возможно стоит сделать проект и посмотреть насколько сложно будет перенести, и насколько будет выигрыш — так как нагрузочные тесты можно запусктаь на специальной среде, то это вполне можно проверить, осталось взвесить за и против, эта таблица вполне хороший кандидат.