

Я давно знал о сайте Have I Been Pwned (HIBP). Правда, до недавнего времени никогда там не был. Мне всегда хватало двух паролей. Один из них неоднократно использовался для мусорной почты и пары аккаунтов на странных сайтах. Но пришлось от него отказаться, потому что почту взломали. И, честно говоря, я благодарен хакеру, потому что это событие заставило меня пересмотреть свои пароли — то, как я их использую и храню.
Конечно, я поменял пароли на всех аккаунтах, где стоял скомпрометированный пароль. Затем мне стало интересно, попал ли утёкший пароль в базу HIBP. Я не хотел вводить пароль на сайте, поэтому скачал базу данных (
pwned-passwords-sha1-ordered-by-count-v5). База весьма впечатляет. Это текстовый файл на 22,8 ГБ с набором хэшей SHA-1, по одному в каждой строке со счётчиком, сколько раз пароль с данным хэшем встречался в утечках. Я вычислил SHA-1 своего взломанного пароля и попытался найти его.Cодержание
- [G]rep
- Trie-структура
- Двоичный поиск
- Не быть эгоистичным ублюдком
- B3
- Бенчмарки
- okon — библиотека и CLI
- Ссылки и обсуждение
- Спасибо за чтение
[G]rep
У нас текстовый файл с хэшем в каждой строке. Вероятно, для поиска лучше всего использовать grep.
grep -m 1 '^XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' pwned-passwords-sha1-ordered-by-count-v5.txtМой пароль оказался вверху списка с частотой более 1500 раз, так что он реально отстойный. Соответственно, результаты поиска вернулись практически мгновенно.
Но не у всех слабые пароли. Я хотел проверить, сколько времени займет поиск наихудшего варианта — последнего хэша в файле:
time grep -m 1 '^4541A1E4605EEBF3F4C166329C18502DF75D348A' pwned-passwords-sha1-ordered-by-count-v5.txtРезультат:
33,35s user 23,39s system 41% cpu 2:15,35 totalЭто печально. Ведь поскольку мою почту взломали, я хотел проверить наличие в базе всех своих старых и новых паролей. Но двухминутный grep просто не позволяет комфортно это сделать. Конечно, я мог бы написать скрипт, запустить его и пойти прогуляться, но это не выход. Я хотел найти лучшее решение и чему-то научиться.
Trie-структура
Первой идеей было использовать структуру данных trie. Структура кажется идеальной для хранения хэшей SHA-1. Алфавит маленький, поэтому узлы тоже будут маленькими, как и результирующий файл. Может, он даже поместится в оперативной памяти? Поиск ключа должен происходить очень быстро.
Так что я реализовал эту структуру. Затем взял первые 1000000 хэшей исходной базы, чтобы построить результирующий файл и проверить, всё ли находится в созданном файле.
Да, я смог всё найти в файле, так что структура работала хорошо. Проблема оказалась в другом.
Результирующий файл вышел размером 2283686592B (2,2 ГБ). Это не очень хорошо. Давайте посчитаем и посмотрим, что происходит. Узел — это простая структура из шестнадцати 32-битных значений. Значения являются «указателями» на следующие узлы при заданном символе хэша SHA-1. Так, один узел занимает 16 * 4 байта = 64 байта. Вроде бы немного? Но если подумать, один узел представляет собой один символ в хэше. Таким образом, в худшем случае хэш SHA-1 займёт 40 * 64 байта = 2560 байт. Это намного хуже, например, текстового представления хэша, которое занимает всего 40 байт.
Преимущество структуры trie — в повторном использовании узлов. Если у вас два слова
aaa и abb, то узел для первых символов используется повторно, поскольку символы одинаковые — a.Вернёмся к нашей проблеме. Посчитаем, сколько узлов хранится в результирующем файле:
file_size / node_size = 2283686592 / 64 = 35682603Теперь посмотрим, сколько узлов будет создано в худшем случае из миллиона хэшей:
1000000 * 40 = 40000000Таким образом, структура trie повторно использует только
40000000 - 35682603 = 4317397 узлов, что составляет 10,8% от наихудшего сценария.С такими показателями результирующий файл для всей базы HIBP занял бы 1421513361920 байт (1,02 ТБ). У меня даже жёсткого диска не хватит, чтобы проверить скорость поиска ключей.
В тот день я узнал, что trie-структура не подходит для относительно случайных данных.
Поищем другое решение.
Двоичный поиск
У хэшей SHA-1 две приятные черты: они сопоставимы между собой и все они одного размера.
Благодаря этому мы можем обработать исходную базу данных HIBP и создать файл из отсортированных значений SHA-1.
Но, как отсортировать файл 22 ГБ?
Вопрос. Зачем сортировать исходный файл? HIBP отдаёт файл со строками, уже отсортированными по хэшам.
Ответ. Я об этом просто не подумал. В тот момент я не знал о сортированном файле.
Сортировка
Сортировка всех хэшей в оперативной памяти — не вариант, у меня не так много оперативной памяти. Решение было таким:
- Разделить большой файл на меньшие, которые поместятся в RAM.
- Загружать данные из небольших файлов, сортировать в оперативной памяти и записывать обратно в файлы.
- Объединить все маленькие, отсортированные файлы в один большой.
С большим отсортированным файлом можно искать наш хэш с помощью двоичного поиска. Доступ к жёсткому диску имеет значение. Давайте посчитаем, сколько обращений требуется при двоичном поиске:
log2(555278657) = 29.0486367039, то есть 30 обращений. Не так уж и плохо.На первом этапе можно произвести оптимизацию. Преобразовать текстовые хэши в двоичные данные. Это сократит размер результирующих данных вдвое: с 22 до 11 ГБ. Отлично.
Зачем сливаться обратно?
В этот момент я понял, что можно поступить умнее. Что, если не объединять маленькие файлы в один большой, а проводить двоичный поиск в отсортированных маленьких файлах в оперативной памяти? Проблема в том, как найти нужный файл, в котором искать ключ. Решение очень простое. Новый подход:
- Создать 256 файлов с названиями "00"… "FF".
- При чтении хэшей из большого файла записывать хэши, которые начинаются с "00..", в файл с названием "00", хэши, которые начинаются с "01.." — в файл "01" и так далее.
- Загружать данные из небольших файлов, сортировать в оперативной памяти и записывать обратно в файлы.
Всё очень просто. Кроме того, появляется ещё один вариант оптимизации. Если хэш хранится в файле "00", то мы знаем, что он начинается с "00". Если хэш хранится в файле "F2", то он начинается с "F2". Таким образом, при записи хэшей в небольшие файлы мы можем опустить первый байт каждого хэша! Это 5% от всех данных. В общем объёме экономится 555 МБ.
Параллелизм
Разделение на файлы меньшего размера даёт ещё одну возможность для оптимизации. Файлы независимы друг от друга, поэтому мы можем сортировать их параллельно. Мы же помним, что все ваши процессоры любят потеть одновременно ;)
Не быть эгоистичным ублюдком
Когда я реализовал вышеописанное решение, то понял, что наверняка у других людей возникала подобная проблема. Вероятно, многие другие тоже скачивают базу HIBP и проводят поиск по ней. Поэтому я решил поделиться своей работой.
Перед этим я ещё раз пересмотрел свой подход и нашёл пару проблем, которые хотел бы исправить, прежде чем выкладывать код и инструменты на Github.
Во-первых, как конечный пользователь я не хотел бы использовать инструмент, который создаёт много странных файлов со странными именами, в которых непонятно что хранится и т. д.
Хорошо, это можно решить, объединив файлы "00".."FF" в один большой файл.
К сожалению, наличие одного большого файла для сортировки порождает новую проблему. Что делать, если я хочу вставить хэш в этот файл? Всего один хэш. Это всего лишь 20 байт. О, хэш начинается с "000000000..". Ну, ладно. Давайте освободим для него место, переместив 11 ГБ других хэшей…
Вы поняли, в чём проблема. Вставка данных в середину файла — не самая быстрая операция.
Ещё один недостаток этого подхода в том, что нужно снова хранить первые байты — это 555 МБ данных.
И последнее, но не менее важное: двоичный поиск по данным, хранящимся на жёстком диске, намного медленнее, чем обращения к оперативной памяти. Я имею в виду, что это 30 операций чтения с диска против 0 операций чтения с диска.
B3
Ещё раз. Что у нас есть и чего мы хотим достичь.
У нас 11 ГБ двоичных значений. Все значения сопоставимы и имеют одинаковый размер. Мы хотим найти, присутствует ли конкретный ключ в сохранённых данных, а также хотим изменять базу. И чтобы всё работало быстро.
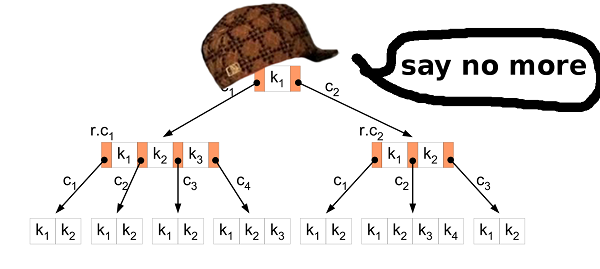
B-дерево? Точно.
B-дерево позволяет минимизировать доступ к диску при поиске, модификации и т. д. У него гораздо больше возможностей, но нам нужны эти две.
Сортировка вставками
Первый шаг — преобразование данных из исходного файла HIBP в B-дерево. Это означает, что нужно извлечь все хэши по очереди и вставить в структуру. Для этого подходит обычный алгоритм вставки. Но в нашем случае можно сделать и лучше.
Вставка большого количества исходных данных в B-дерево — хорошо известный сценарий. Мудрые люди изобрели для этого подход получше, чем обычную вставку. Прежде всего, нужно отсортировать данные. Это можно сделать как описано выше (разделить файл на более мелкие и отсортировать их в оперативной памяти). Затем вставить данные в дерево.
В обычном алгоритме, если вы находите концевой узел (leaf node), куда нужно вставить значение, и он заполнен, то вы создаёте новый узел (справа) и равномерно распределяете значения по двум узлам, левому и правому (плюс одно значение переходит к родительскому узлу, но здесь это не важно). Если вкратце, то значения в левом узле всегда меньше, чем значения в правом. Дело в том, что когда вы вставляете отсортированные данные, вы знаете, что в дерево больше не будут вставляться меньшие значения, поэтому больше никакие значения не пойдут в левый узел. Левый узел всё время остаётся полупустым. Более того, если вы вставите достаточно значений, вы можете обнаружить, что правый узел заполнен, поэтому нужно переместить половину значений в новый правый узел. Разделяющийся узел остаётся полупустым, как и в предыдущем случае. И так далее…
В результате после всех вставок вы получите дерево, в котором почти все узлы полупусты. Это не слишком эффективное использование пространства. Мы можем сделать лучше.
Разделять или нет?
В случае вставки отсортированных данных можно произвести небольшую модификацию алгоритма вставки. Если узел, в который нужно вставить значение, заполнен, не разбивайте его. Просто создайте новый, пустой узел и вставьте значение в родительский узел. Затем, когда вставляете следующие значения (которые больше, чем предыдущие), вы вставляете их в свежий, пустой узел.
Чтобы сохранить свойства B-дерева, после всех вставок необходимо перебрать самые правые узлы в каждом слое дерева (кроме корневого) и равномерно разделить значения этого крайнего узла и его левого соседа. Так вы получите минимально возможное дерево.
Свойства дерева HIBP
При проектировании B-дерева нужно выбрать его порядок. Он показывает, сколько значений можно хранить в одном узле, а также сколько дочерних элементов может иметь узел. Манипулируя этим параметром, мы можем манипулировать высотой дерева, двоичным размером узла и т. д.
В HIBP у нас
555278657 хэшей. Допустим, мы хотим дерево высотой три (так что нам нужно не более трёх операций чтения для проверки присутствия хэша). Нам нужно найти такое значение M, чтобы logM(555278657) < 3. Я выбрал 1024. Это не самое маленькое возможное значение, но оно оставляет возможность вставить больше хэшей и сохранить высоту дерева.Выходной файл
У исходного файла HIBP размер 22,8 ГБ. У выходного файла с B-деревом — 12,4 ГБ. Его создание на моей машине занимает около 11 минут (Intel Core i7-6700, 3,4 ГГц, 16 ГБ RAM), жёсткий диск (не SSD).
Бенчмарки
Вариант с B-деревом показывает довольно неплохой результат:
| | time [?s] | % | |-----------------:|------------:|------------:| | okon | 49 | 100 | | grep '^hash' | 135'350'000 | 276'224'489 | | grep | 135'480'000 | 276'489'795 | | C++ line by line | 135'720'201 | 276'980'002 |
okon — библиотека и CLI
Как я уже говорил, хотелось поделиться своей работой с миром. Я реализовал библиотеку и интерфейс командной строки для обработки базы HIBP и быстрого поиска хэшей. Поиск настолько быстр, что его можно, например, интегрировать в менеджер паролей и давать обратную связь пользователю при каждом нажатии клавиши. Существует множество возможных вариантов использования.
У библиотеки интерфейс C, поэтому её можно использовать практически везде. CLI это CLI. Можете просто собрать и запустить (:
Код лежит в моём репозитории.
Дисклеймер: okon пока не предоставляет интерфейс для вставки значений в созданное B-дерево. Он может только обработать файл HIBP, создать B-дерево и искать в нем. Эти функции вполне работают, поэтому я решил поделиться кодом и продолжить работу над вставкой и другими возможными функциями.
Ссылки и обсуждение
Спасибо за чтение
(:




pensnarik
А я все ждал, когда же вы изобретёте btree индекс ;). В таком случае, почему сразу просто не залить таблицу в любую базу данных, которая умеет btree индексы и искать в ней? Если взять докер образ какого-нибудь постгреса весь проект уместится в 5 строчек на баше.
fougasse
Как мне кажется, запускать докер с базой — оверкилл.
Кстати, а сколько будет вставляться весь набор данных никто не замерял?
Аналогично с поиском.
Было бы интересно увидеть порядок цифр.
yleo
Вставка такого объема одной транзакцией может не пройти без подстройки конфигурации, а несколькими транзакциями будет накладно для диска.
Но вот если взять libmdbx, то точно будет проще и быстрее.
Вполне возможно что в 10-100 раз быстрее постгреса и без докера.
funny_falcon
SQLite3 очень шустро импортирует csv файл в пустую базу (в классическом режиме. С WAL тормозит). Тем более, если посортировать предварительно.
erthink
На всякий — SQLite уже пересаживали на LMDB получая существенное ускорение (2-10 раз). В свою очередь libmdbx быстрее LMDB на 10-20% (тем и живём, так сказать).
mspain
Накой грузить 11ГБ одной транзакцией? Накой тут вообще транзакции? В почти любую субд лучше сначала загрузить данные, потом создать индекс.
11ГБ в ту же монго это несколько МИНУТ работы, потом от силы час на создание индекса.
Искать будет в районе милисекунды.
Лучше расскажите сколько автор креатива реального времени убил на этот мусорный проект.
funny_falcon
SQLite3
Сортированный файл, обьявленный как csv через встроенный импорт csv влетит пулей.
pensnarik
А вообще, мне кажется, для этой задачи хорошо подойдёт bloom filter.