
В последнее время я получаю достаточно много вопросов по поводу организации стораджа в OpenNebula. В виду своей специфики она имеет аж три разных типа хранилища: images, system и files. Давайте разберёмся зачем нужен каждый из них и как их использовать чтобы планировать размещение данных наиболее эфективно.
Этот пост — частичная расшифровка моего доклада про OpenNebula на HighLoad++ 2019 с упором на дисковую составляющую.
Итак по стораджам:
В OpenNebula есть три типа стораджей: images, system и files.
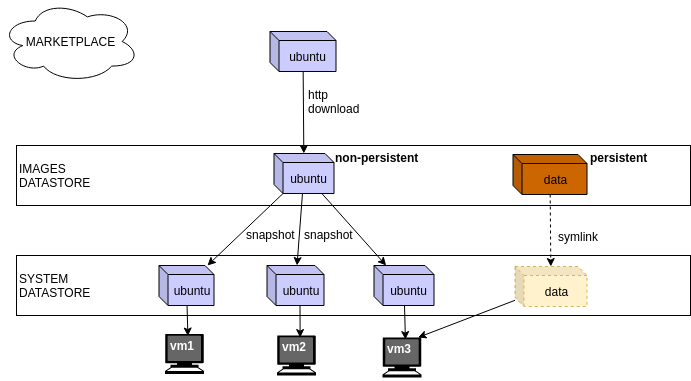
images datastore — это начальное хранилище где и должны храниться ваши данные, а также образы из которых создаются виртуалки.
Образы бывают двух типов:persistentиnon-persistent— разница лишь в том как они копируются в system datastore:
- non-persistent образы как бы копируются из images в system datastore, в драйвере linstor_un есть два режима копирования:
copyиsnapshotв первом случае произойдёт полная копия образа, во втором он создаст снапшот и развернёт копию образа из него. - persistent образы как бы перемещаются из images в system datastore
(я говорю "как бы" потому что формально для линстора этого перемещения не происходит, persistent-образы просто подключаются напрямую из images-datastore к создаваемой виртуалке)
- non-persistent образы как бы копируются из images в system datastore, в драйвере linstor_un есть два режима копирования:
соответсвенно system-datastore — это хранилище где виртуалки исполняются.
То есть образы хранятся в system-datastore только в тот момет когда виртуалка существует. Как только виртуалка умирает, persistent образы возвращаются обратно в images хранилище, а non-persistent образы удаляются вместе с виртуалкой.
Соответсвенно юзкейс такой:
По возможности храним все данные в виде persistent-образов в images-датасторе, подключаем их к виртуалкам, в system-датасторе должны остаться только системные диски виртуалок, но не данные с которыми они работают, именно при таком подходе можно тонко планировать размещение ресурсов. (для каждой виртуалки system-datastore может быть только один, а подключить дисков из разных images-datastores можно столько сколько захочешь).
Соответсвенно во всём кластере у вас может быть один system-datastore с какой-нибудь базовой характеристикой (к примеру тип: SSD, количество реплик: 2), это не особо важно т.к. при правильном подходе системные диски виртуалок не занимают много места.
А все ваши данные в виде persistent-образов лежат уже в нужных images-datastores, к примеру:
- база данных — на быстрых SSD с количеством реплик: 3
- файлопомойка — на медленных HDD с количеством реплик: 2
и т.д, то есть под каждый тип размещения нужно создать отдельный images-datastore
Что же такое files-datastore?
- files datastore — это специальное хранилище в котором могут находиться инит-скрипты, ядра и прочие файлы которые будут скопированы в runtime-директорию и использованы непосредственно при формировании самой виртуалки.
Например вы можете положить туда определённый инит-скрипт и указав его в контекстуализации для вашей виртулки, тогда при включении она всегда будет его исполнять.
Как правило files-datastore особо не требовательно к ресурсам дисковой подсистемы, поэтому самый удобный драйвер для него это ssh, когда файлы напрямую копируются с вашего frontend на compute-ноду где и запускается новая виртуалка.
Так вот, как же работает linstor_un драйвер?
По умолчанию мы имеем два хранилища:
images:
NAME="linstor-images" TYPE="IMAGE_DS" STORAGE_POOL="data" AUTO_PLACE="2" BRIDGE_LIST="node1 node2 node3" DISK_TYPE="BLOCK" DS_MAD="linstor_un" TM_MAD="linstor_un"
system:
NAME="linstor-system" TYPE="SYSTEM_DS" STORAGE_POOL="data" AUTO_PLACE="2" CLONE_MODE="snapshot" CHECKPOINT_AUTO_PLACE="1" BRIDGE_LIST="node1 node2 node3" TM_MAD="linstor_un"
Когда мы загружаем из маркетплейса образ системы и сохраняем его в linstor-images, по умолчанию он создаётся как non-persistent, т.е. мы можем использовать его для инстантиирования нескольких виртуалок:

Таким образом мы будем иметь две реплики созданных на случайных нодах в images-датасторе (параметр AUTO_PLACE="2" для linstor-images)
И так как наше system-datastore имеет параметр CLONE_MODE=snapshot, то на тех же самых нодах будет созданно по снапшоту на каждую созданную виртуалку из этого образа. Количество созданных реплик также всегда будет равно количеству реплик исходного образа.
Но стоит заметить, что если у нас планируется много виртуалок и мало образов, то лучше использовать CLONE_MODE=copy, который при инстантиировании создаст отдельный образ в system-datastore такого-же размера как и в images-datastore и побайтово скопирует в него данные.
В этом случае количество реплик будет зависеть от параметра AUTO_PLACE для system-datastore.
Так-же можно воспользоваться функцией instantiate as persistent в OpenNebula, тогда сначала в images-datastore создастся полная копия начального образа затем он как persistent-образ будет подключён непосредственно к виртуалке.
К вопросу что такое diskless-реплика:
Когда OpenNebula собирается запустить виртуалку на одной из нод, где ещё нет созданной реплики, то непосредственно перед запуском виртуалки линстор создаёт на этой ноде специальный diskless-ресурс. Этот ресурс, по сути блочное устройство, оно нужно для того, чтобы виртуалка могла получить доступ к данным, даже не смотря на то, что текущая нода не имеет никаких данных, выглядит это слелующим образом:

Как только виртуалка будет смигрированна на другой хост, то линстор удалит эту diskless-реплику т.к. здесь она больше будет не нужна.
На этом пожалуй всё что я хотел сказать про дисковую подсистему в OpenNebula.
Если данная тема показалась вам интересной, рекомендую посмотреть полное видео моего доклада:
Спасибо за внимание!