
Картинки и видео — это «чёрные ящики», внутри которых лежит много интересного и непонятного. Но можно заглянуть внутрь некоторых форматов, всё там поменять и посмотреть, что из этого получится.
Полина Гуртовая из компании «Злые марсиане» выступила на нашей конференции«Я  Фронтенд»
Фронтенд» в феврале. При помощи эксперимента Полина разобралась, как превращать простые картинки в «эффективные изображения» с метриками. Инструменты, которые могут делать это за нас, Полина рассмотрела ближе к концу доклада. Получился большой экскурс во внутренности и принципы работы разных форматов: от PNG и JPEG до AV1 и экзотики.
— Всем привет. Меня зовут Полина, я фронт в компании «Злые марсиане».
Может быть, вы знаете марсиан по нашему многочисленному open source. Я вам про него немножечко расскажу попозже. И наверное, надо сказать, что мы еще продукты разрабатываем, а не только пилим open source.

Материалы к докладу будет доступны вам по чудесной ссылочке в репозитории на GitHub.
Давайте немножечко поговорим про оптимизации. Когда мы ими занимаемся, проблема в том, что они получаются хорошо, если мы понимаем, что мы делаем. Если не понимаем — получается плохо. Когда дело доходит до оптимизации изображений, к сожалению, тут все совсем-совсем не круто. Мы можем вообще не оптимизировать изображения, и тогда будут двухметровые монстры на проде, это все грустно и печально.
Если же мы все-таки оптимизируем, то что мы делаем? Мы думаем: вот у нас есть картинка, это какой-то таинственный черный ящик, и программа-оптимизатор с этой картинкой что-то делает, какое-то черное шаманство. Качество оптимизации, которое у нас получается, немножко сомнительное.

Давайте посмотрим на пример. У меня есть котик в формате PNG. Я думаю, надо его оптимизировать. Что я делаю? Я создаю WebP-вариант и заботливо складываю оба изображения в тег <picture>. Как вы думаете, я молодец здесь или нет? Почему так мало рук? Я правда молодец!
Я сделала все правильно, но WebP-вариант получился на два килобайта больше, чем оригинал. Это немножко не то, чего я хотела.?
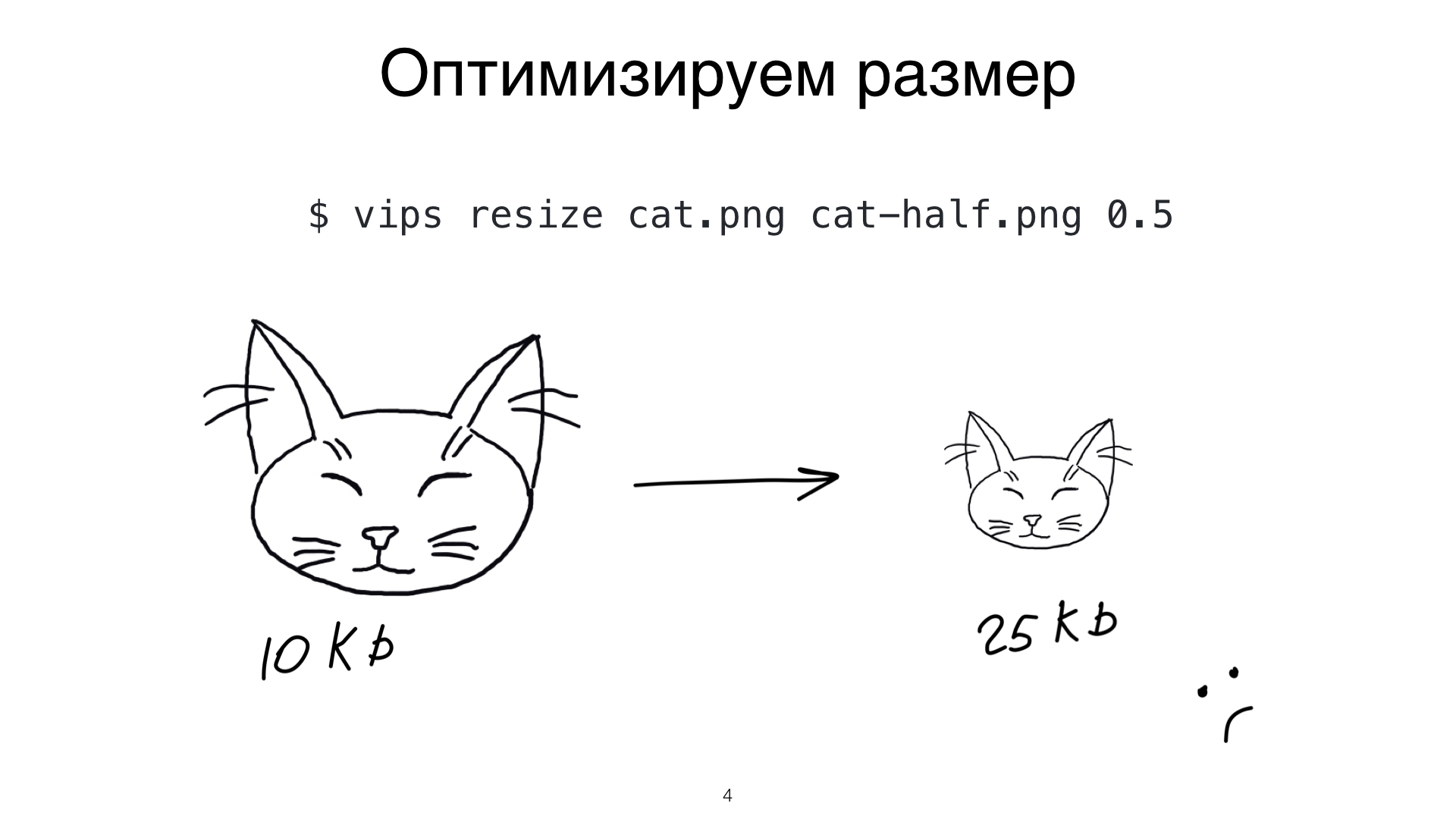
Еще одна оптимизация, попытка №2. У меня есть маленький контейнер на страничке и большой-большой котик. Я хочу большого котика в маленький контейнер вложить. Что я делаю? Я делаю ресайз, потому что глупо гонять байты по сети, если у меня размер моего контейнера маленький. Я, конечно, учитываю device pixel ratio своего устройства. Как вы думаете, здесь я молодец или нет? Я молодец! А смотрите, что у меня получилось.
Я использую библиотеку libvips. Она очень классная и популярная, и из моего огромного, но довольного легкого котика получился маленький и очень тяжелый. В 2,5 раза увеличился (в байтах) котик при ресайзе (в пикселях) в меньшую сторону. Круто, да?
В общем, чтобы с нами такого не происходило, чтобы мы понимали, как нам правильно оптимизировать свои картинки под свою задачу, и, вообще, чтобы мы хоть понимали, что происходит, давайте-ка заглянем в коробку и поймем, что же там внутри.
Заглядывать начнем с такого интересного формата, как PNG. Примерно на каждом сайте где-то спрятана маленькая пээнгэшечка. Это раз. Поэтому их надо понимать. Второе: PNG — формат сжатия без потерь. Это значит, мы гарантируем идеальное совпадение с оригиналом по пикселям, но при этом мы, увы, ограничены природой, мы не можем сжать меньше, чем насколько-то.

Пээнгэшка складывается в контейнер, как и любой картиночный формат. Одна из первых вещей, которые нам надо сообщить программе, если она это все будет читать, — что же там внутри лежит. Если вы предполагаете, что ваши декодеры определяют картинки по расширению, — это не так.
Пээнгэшка сообщает, что она PNG, первыми восемью байтами в своем контейнере. Там написано «PNG». Дальше — опять же, это характерно для любого контейнера — у вас есть некоторый layout чанков. То есть инфа упакована в чанки, они как-то устроены. Как — определяет контейнер. В PNG это выглядит так: у вас есть четыре байта, которые отвечают за длину, и четыре байта, которые отвечают за тип чанка. Какие типы — мы поговорим чуть попозже. ?
Если у чанка ненулевая длина, у него есть payload. Кроме этого, есть такая штука, как контрольная сумма. Вы проверяете, не побилось ли там чего. Дальше идут следующие чанки.

Разобрать не только PNG-файл, но и практически любой довольно легко. Берем FileReader, это браузерный API. Читаем файл с помощью FileReader. Как только мы прочитали, мы режем этот файлик на чанки. Я не буду приводить здесь код функции split to chunks, но вы можете догадаться, что там затейливое сочетание if и for. ?

Окей, нарезали, смотрим, что получается. У нас есть несколько типов чанков, и они очень-очень характерны практически для любого формата. Первый называется IHDR. Есть некоторое количество чанков, которые называются IDAT. Эти названия могут показаться вам немножко странными, но мы сейчас разберемся, что это такое. Когда все заканчивается, мы видим чанк end.

Давайте повнимательнее посмотрим внутрь чанков. IHDR — мета-чанк, и такой мета-чанк есть практически у любой картинки. Он называется по-другому, он устроен по-другому, но он, скорее всего, есть. Без него ваш декомпрессор — штука, которая показывает вам пээнгэшки или не пээнгэшки, — не сможет вам ничего показать. Что лежит в этом чанке? Опять же, содержимое характерно для большинства форматов. Это высота и ширина. Высота и ширина зашита в ваш файл, она вам приходит. Дальше тут типичные пээнгэшные флаги: bitDepth, colorType и interlacing. ?
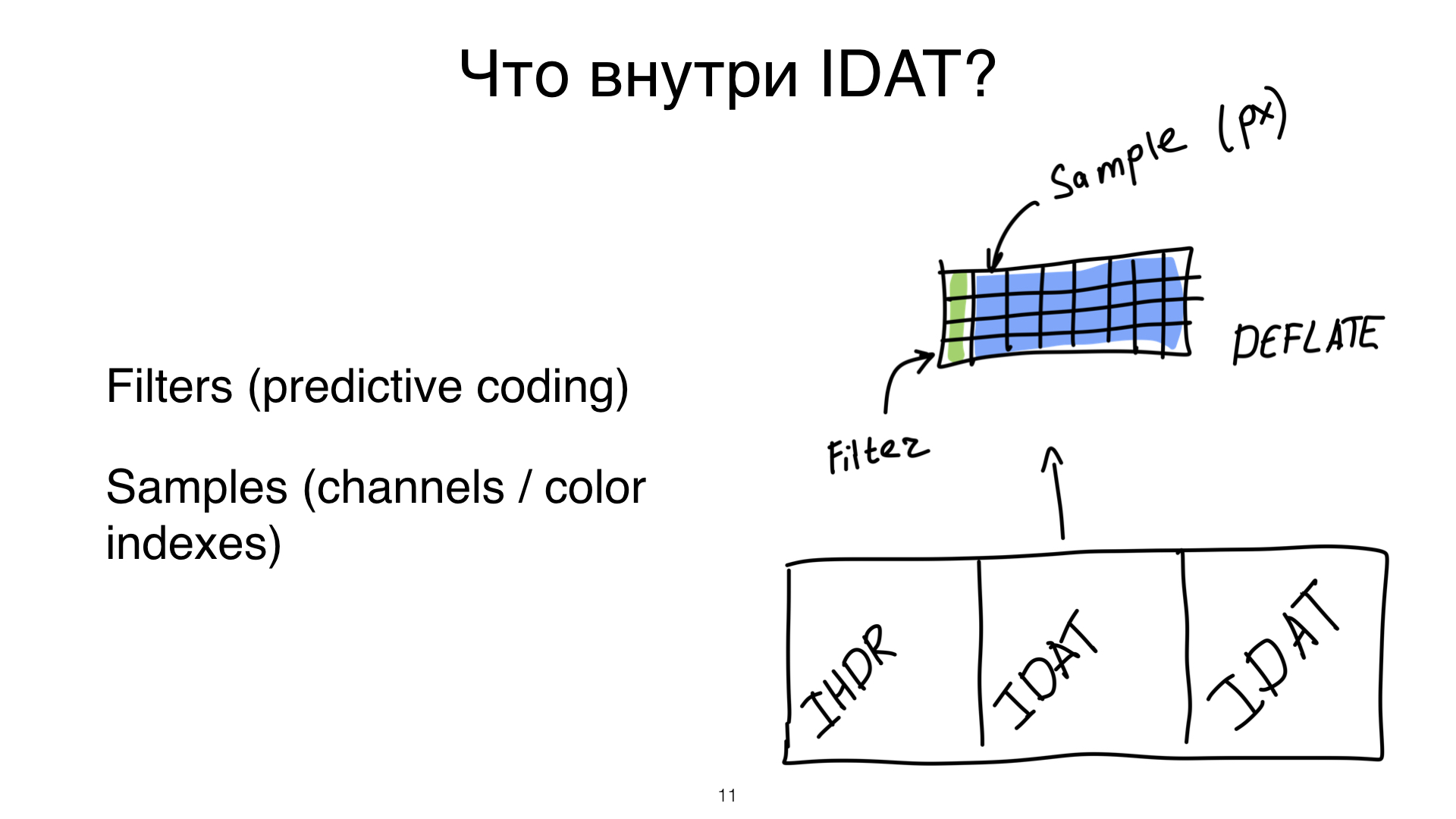
Перед тем, как мы поговорим, что значат эти флаги и почему они так сильно-сильно нам важны, давайте посмотрим, как мы храним в пээнгэшках пиксели. В пээнгэшках пиксели хранятся внутри чанка, который называется IDAT. При хорошем раскладе пиксели — некоторое количество чисел, которые запакованы в чанк, и этот чанк сжат алгоритмом сжатия Deflate. Кто пользовался алгоритмом сжатия Deflate? Окей, а когда вы последний раз что-нибудь зипали? Вы знаете, что Deflate это и есть gzip? Так что я думаю — пользовались многие.
Но в пээнгэшках появляется еще одна интересная штуковина, которая используется в огромном количестве форматов, но наверное, что во всех. Эта штуковина называется predictive coding. Дело в том, что наши изображения — это не рандомные пиксели. То, что нарисовано на нашей картиночке, как-то связано друг с другом. Есть какие-то темные области, светлые области и так далее.
Мы пытаемся заэксплойтить этот факт, и вместо того, чтобы в этих синих ячейках хранить значение пикселей, мы пытаемся эти пиксели предсказать на основе предыдущих. В PNG эти предсказания очень простые, и они пакуются в самый-самый первый байтик перед строчкой с пикселями. Предсказание может быть таким, например, давайте ничего не предсказывать и просто положим все, как есть. Или, например, мы можем сказать так: а давайте мы будем хранить только разницу между текущим пикселем и предыдущим.
Если у вас один и тот же цвет в вашей строке у вас будут все нули, все прекрасно сжалось, это очень круто.

Но теперь давайте поговорим что, собственно, значит пиксель. Пиксель представляется в пээнгэшке как некоторое количество чиселок. Манипулируя тем, какое количество чиселок есть, вы можете очень и очень сильно сжимать ваше PNG — раза в три.
Какие тут есть варианты? Первое — True Color и alpha. У нас есть три канала, три цвета, три числа за цвет. Плюс канал, который отвечает за прозрачность.
Размер этой чиселки в битах — это bitDepth, тот самый флаг, который мы видели в чанке IHDR. Чем меньше ваш bitDepth, — тем меньше файл, но тем меньше цветов вы сможете им представлять. Типичная чиселка — 8. Это сколько? По-моему, будет 16 млн с чем-то.
Окей, первая оптимизация, которую вы можете сделать, — выкинуть alpha-каналы в своей пээнгэшке. Это будет уже другой colorType.
Вы можете еще круче оптимизировать и вместо четырех чисел использовать всего одно. Но проблема в том, что тогда ваша пээнгэшка должна быть черно-белой.
Если вы все-таки хотите только одно число, а цвета оставить, то так тоже можно сделать. Что здесь происходит? Вы берете все цвета внутри вашей пээнгэшки и вырезаете их в отдельный чанк. Называете его палитрой. Дальше внутри сэмпла, который отвечает за пиксель внутри чанка IDAT, вы храните просто индекс этой палитры. Если у вас какой-нибудь скриншот без затейливого бэкграунда или какой-нибудь чертежик, вот эта штука заходит просто идеально. Она сжимает пээнгэшки прямо ух!
Еще одна важная вещь, про которую нужно сказать, — это Interlacing. Что такое Interlacing? Это когда вы грузите свою пээнгэшку постепенно. У вас не одна пээнгэшка, а несколько изображений. Каждое это изображение называется скан.
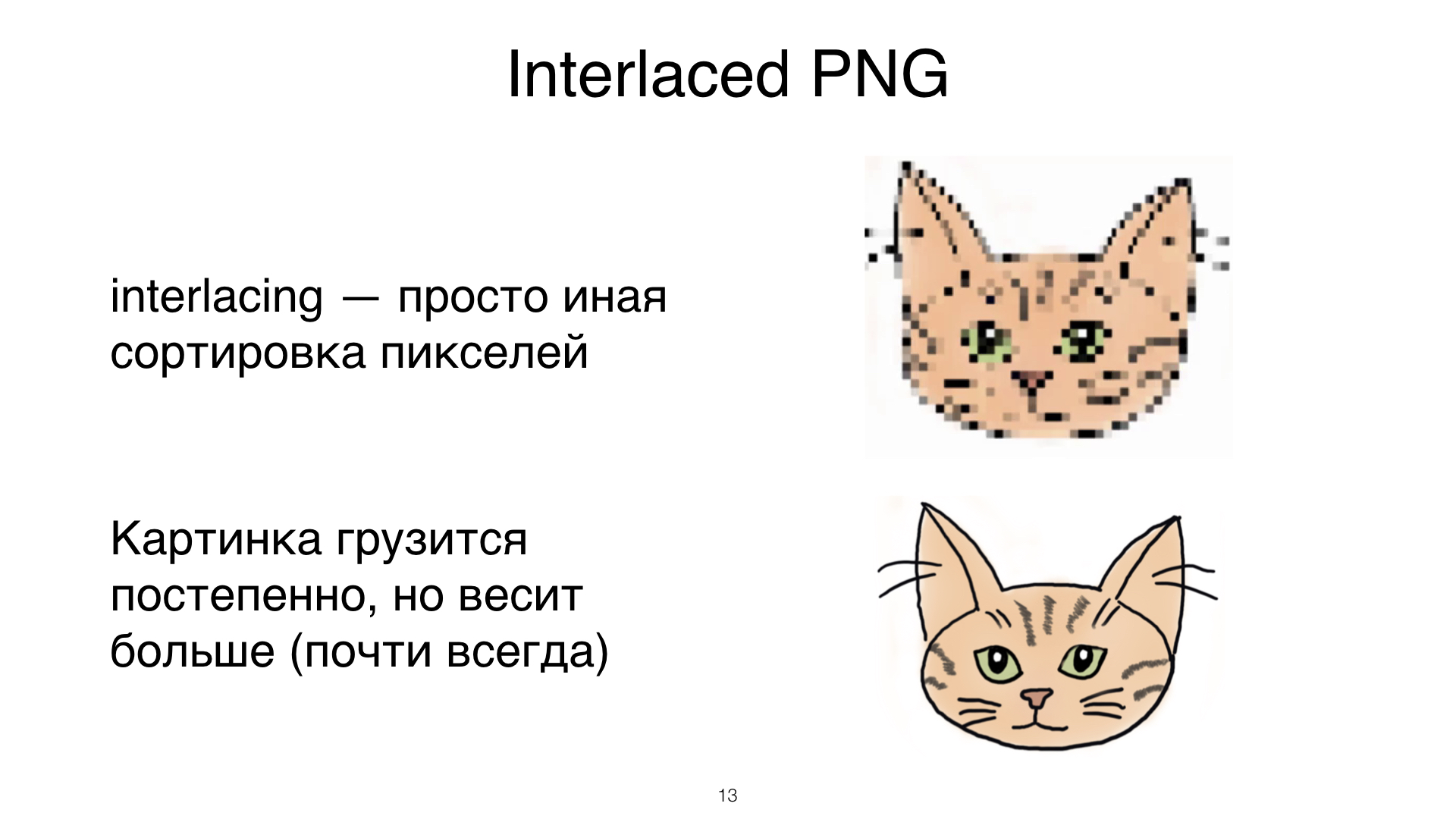
При этом внутри пээнгэшки вы сортируете пиксели таким образом, что часть пикселей выдрана из картинок, из специальных мест идет одно изображение. Следующая часть — другое и так далее. Казалось бы, крутая техника, как прогрессивный JPEG.
Но выглядит это вот так. Я не уверена, хотите ли вы, чтобы ваши пользователи это видели, хотя, может быть, для вашей задачи это может быть полезно.
Вторая и очень серьезная проблема Interlaced PNG заключается в том, что как только вы интерлейсите свою пээнгэшку, размер вашей пээнгэшки становится больше. Причем не слабецки так больше, где-то на пару килобайт ваша шести-килобайтная пээнгэшка вырастет, если вы выключите Interlaced. Поэтому подумайте внимательно, хотите вы этого или нет.

Мы поговорили всего-навсего о PNG, но уже из этой штуки можно сделать важные и полезные выводы. Первый вывод: размер вашего файла, вы не поверите, зависит от того, что там нарисовано. Черный квадрат сжимается лучше, чем котик, не буду тут никакой рекомендации давать. Второе, более важное: размер вашего файла очень сильно зависит от энкодера и от его параметров, которые вы передаете.
Если вы хотите посмотреть, как работают ужасные энкодеры, воспользуйтесь браузерными. Как это делается? Берете PNG-файл, рисуете его на canvas, потом нажимаете save as и сравниваете то, что было, с тем, что получилось. В общем, Chrome вам увеличит размер файла в 2,5 раза, Firefox — в 1,6.
От формата, кстати, это тоже всегда зависит, то есть не только PNG надо пользоваться. Давайте разбираться, почему все зависит от формата и какие у нас еще есть интересные варианты.

Для этого мы поговорим о технологии древних, о JPEG. Нельзя, конечно, преуменьшить важность JPEG. Они встречаются везде. Они такие классные, хорошие, и тем более, котики в JPEG — довольно частая история. Но JPEG — довольно сложная штука, и сложна она за счет того, что JPEG — это сжатие с потерями. Причем JPEG — это всегда сжатие с потерями. JPEG 100% quality все равно сжимает с потерями.
Как мы получаем сжатие с потерями? Очень просто. Мы берем какой-то источник, выкидываем из него данные, а потом сжимаем без потерь. То есть плюс один шаг.
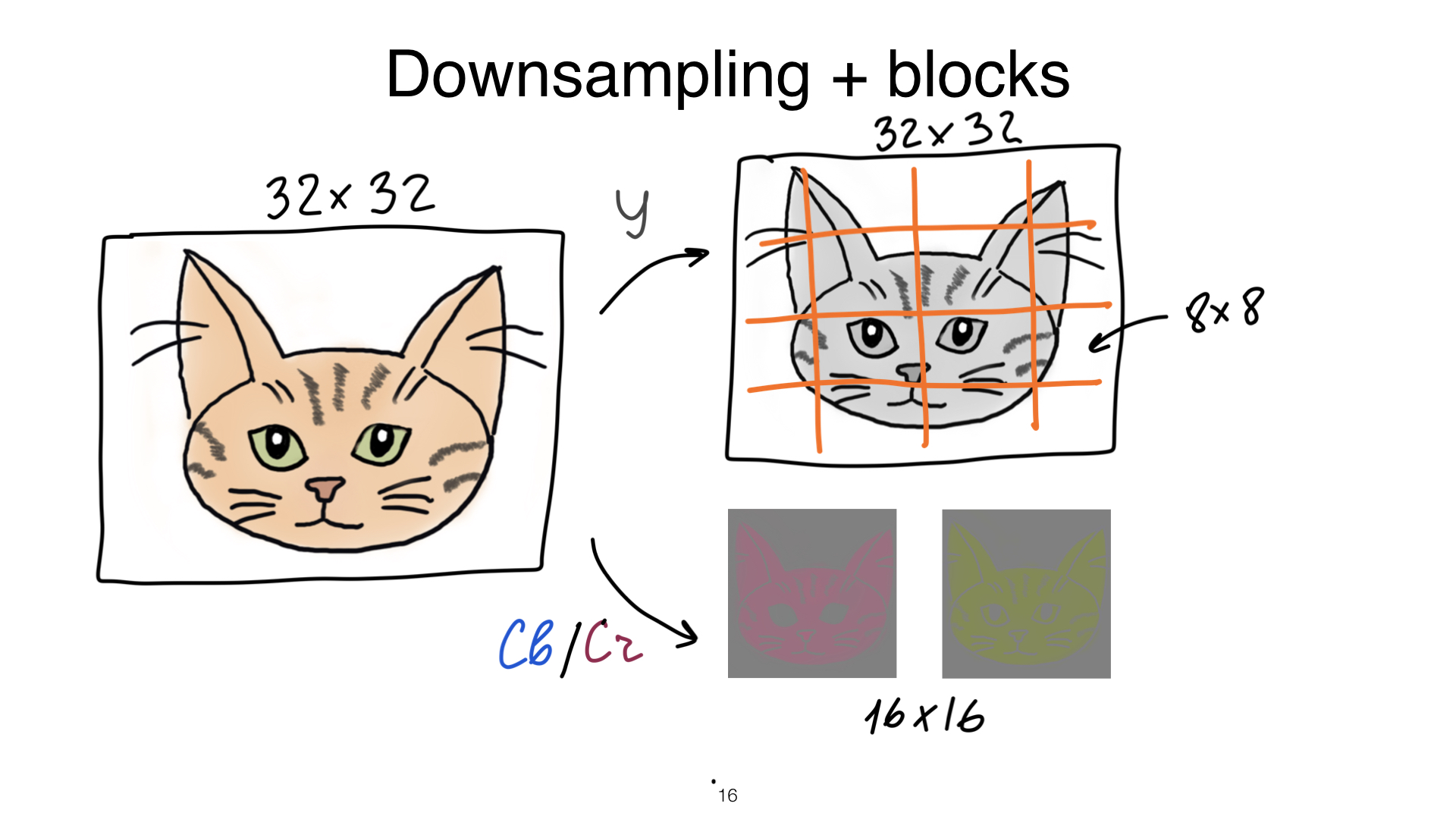
Давайте разберемся, как мы вносим потери в наши JPEG. Итак, у вас есть котик размером 32 на 32. Чтобы нам сделать первый шаг с потерями, нужно поменять у него каналы. Обычно мы рассуждаем о картинках в терминах RGB. Но мы воспринимаем цвета немножечко затейливо. Наш мозг — это вообще большая проблема, хотя он нам очень сильно помогает сжимать JPEG.
Мы очень хорошо воспринимаем черно-белое изображение. Даже если вы присмотритесь, вы обратите внимание, что детальки на черно-белом изображении вы различаете лучше. Мы просто выносим это черно-белое изображение в отдельный канал. Он называется Y. На самом деле, Y-штрих. Мы с ним ничего не делаем, просто оставляем его как есть.
Есть еще два канала, которые отвечают за цвет. Это CB и CR. С этими каналами мы уже можем немножечко развлекаться. Здесь с этими каналами мы производим такую прикольную процедуру, которая называется Downsampling. Мы берем и уменьшаем разрешение этого канала. Для JPEG типично уменьшать в два раза. То есть, по сути, у вас получилось три картинки — одна оригинальная и две в два раза меньше. Ура!
Что мы делаем дальше? Мы не сжимаем JPEG, не как целый файлик. Мы разбиваем его на блоки и дальше сжимать мы начинаем уже блоки. Блоки в JPEG размером 8 на 8, и смотрите, что с ними происходит. Давайте смотреть только на канал Y. CB и CR — все то же самое.

Итак, блок — это не картинка, а чиселки. Нам нужно внести потери в JPEG. Этот блок 8 на 8, 64 пикселя, какой выкинуть? Тот, что слева, тот, что справа, тот, что посередине? Непонятно. Но есть классная математика, которая позволяет нам порешать эту проблему.
Эта математика называется — сейчас, пожалуйста, не нервничайте, если кто вспомнит страшное институтское прошлое — дискретное косинусное преобразование. Так вот, при помощи этого дискретного косинусного преобразования вы можете эти чиселки в вашем блоке преобразовать так, чтобы среди них были важные и неважные.
Важно: в верхней левой части блока после преобразования остаются важные чиселки. В нижней правой остаются не важные чиселки.
Дальше вам нужно внести в ваши JPEG потери. Это тоже очень просто сделать. Этот трюк называется квантизацией. Простите, если вам сейчас хочется спать, но это важно, поверьте мне. Так вот, эта самая квантизация работает довольно простым образом. Вы берете ваш блок и специально придуманную табличку. Эта табличка определяется вашей программой-энкодером. Те чиселки, которые получились в вашем блоке, вы на эту табличку делите почленно и целочисленно. Что у вас получится в результате?
Так как в нижней правой части таблички цифры большие, там будут одни нули.
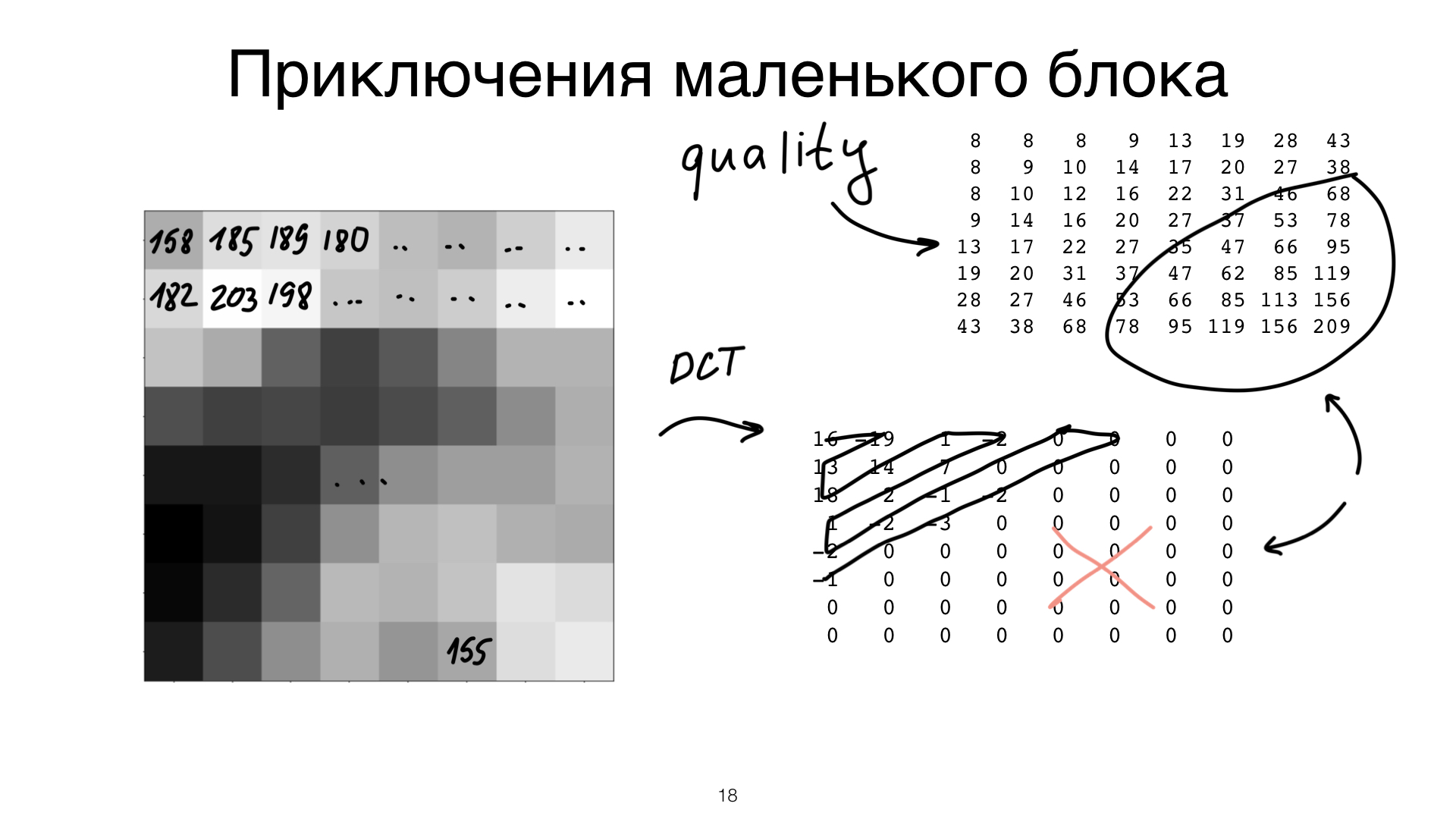
И при этом ваш JPEG, ваш блок отлично сожмется. У вас останется небольшое количество чисел, которое вы вот таким затейливым зигзагом обойдете, нули все уйдут, и, ура, наш блок готов к сжатию. Дальше нам осталось только сжать его алгоритмом сжатия без потерь. В JPEG используется Huffman Coding, чем бы это ни было.
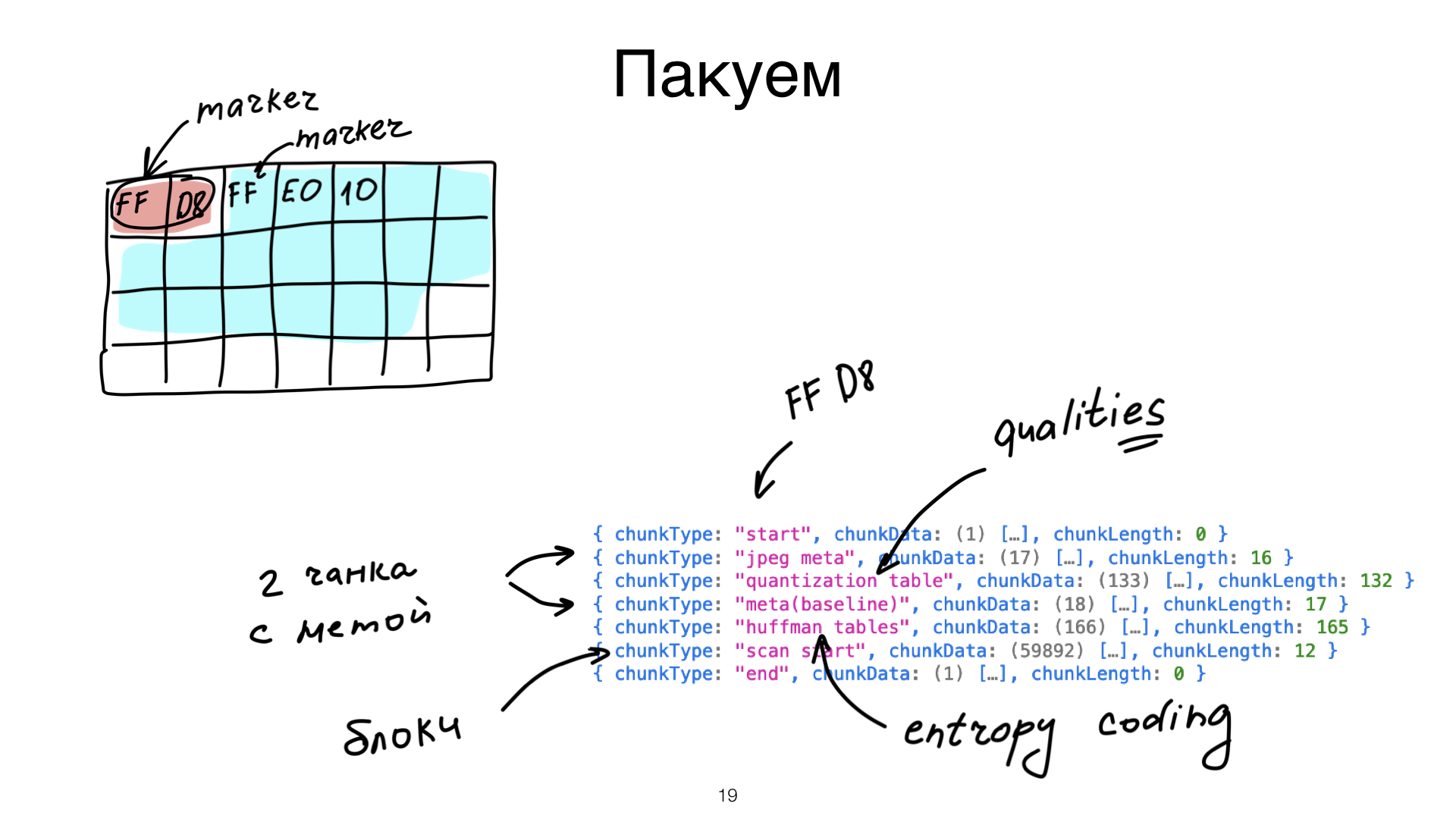
Как это пакуется в контейнер? Контейнеры JPEG выглядят немножечко стремно, я их боюсь. Потому что вы видите первые два байта и там написано, что, скорее всего, это JPEG. Но пока непонятно.
Дальше вам надо поискать два мета-чанка. Почему два? Потому что JPEG — это очень большой сет разных стандартов. То, что мы называем JPEG, по стандарту называется JIFF. Это специальное расширение стандарта JPEG. Дальше я продолжать не буду — в общем, там два мета-чанка, просто поверьте мне. В этих мета-чанках лежит информация о ширине и высоте вашего файлика и о версии JPEG. Представляете, у JPEG еще версии есть! И, кроме того, прогрессивный ли это JPEG? Это важный флаг. Он говорит о том, как ваши блоки будут распределены дальше.
Если JPEG не прогрессивный, то что вам нужно, чтобы раскодировать ваши блоки? Качество JPEG, вот эта самая табличка. Табличка, на которую вы делите ваши блоки, и есть качество. Но у JPEG качеств два. Первое качество отвечает за канал Y, второе — за каналы CB и CR, это то, что определяет цвет. Так как качество мы положили в файлик и все сжали алгоритмом сжатия без потерь, нам нужен еще специальный словарик Huffman Tables, чтобы это все поразжимать.
Дальше идут ваши блоки, и дальше ваш JPEG закончился.

Окей, прогрессивная история. Все абсолютно точно так же. В самом начале у вас идет мета-чанк. Дальше идет ваше качество в виде 64 чиселок, плюс 64 чиселок. А дальше просто те же самые блоки, но просто немножечко по-другому с распределенными чиселками. Сначала часть блоков, потом еще одна часть, еще одна часть и так далее. По мере получения этих блоков браузер отрисовывает вам приближение вашего JPEG, потому что, по сути, вот эти числа — это некоторое приближение вашего файла.

Про JPEG мы закончили, можно выдохнуть, все хорошо. Давайте поговорим по такую интересную вещь, как JPEG 2000. Кто-нибудь из вас в продакшене использует JPEG 2000? Окей, а кто про это что-то когда-нибудь слышал? А кто из вас в Lighthouse прочитал — «используйте современные форматы»?
В общем, JPEG 2000 — классный интересный формат, который, во-первых, эффективней JPEG. Во-вторых, вы не поверите, он в некоторых случаях эффективнее еще и WebP, о котором поговорим попозже.
Он умеет быть прозрачным, умеет сжиматься без потерь. Просто идеальный формат. Но, к сожалению, да, работает он только в Safari.
Еще стоит сказать, что JPEG 2000 устроен очень затейливым образом и работает на классной математике, которая называется wavelet transform. Если вам вдруг интересно, погуглите, а мы пойдем дальше.
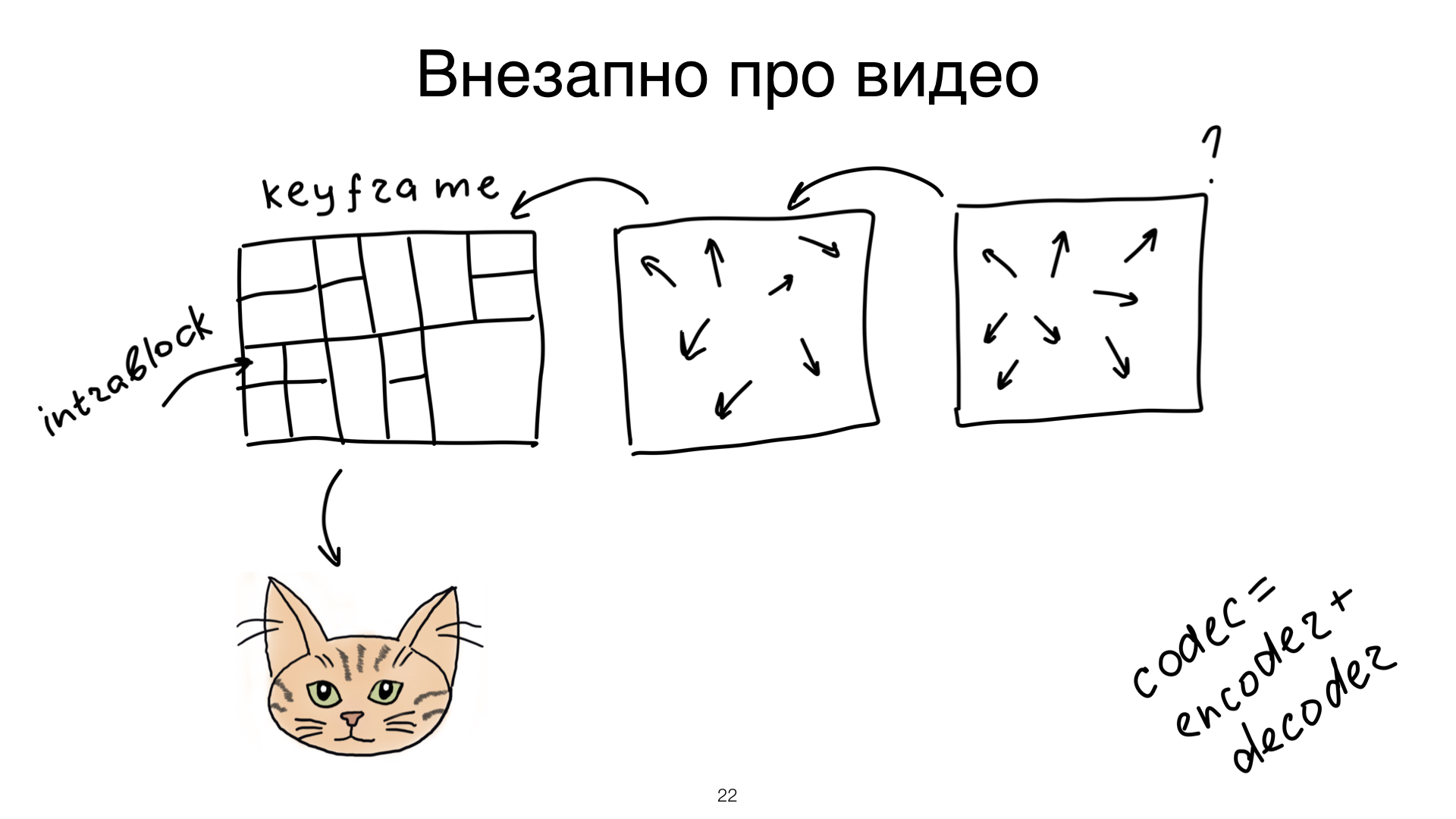
Дальше нам неожиданно надо поговорить про видео. Весь этот доклад — он про оптимизации изображений и про изображения. Но видео здесь очень важно, вы сейчас увидите, почему. Когда мы думаем о видео, первое слово, которое приходит нам в голову, — «кодек». Видео надо как-то энкодить, и чтобы видео показать, нам надо его задекодить. Если мы декодим видеопоток, что мы получаем?
В первую очередь, у нас набор фреймов. Но не надо думать об этих фреймах как о картиночках в гифке. Все не так. То, какие фреймы бывают, очень сильно зависит от кодека. Но в общем случае можно считать, что у вас есть keyframe. Из keyframe можно вытащить котика — в смысле, любую картинку, которая на этом keyframe есть. И есть зависимые фреймы. Вот из зависимого фрейма котика вытащить нельзя, потому что в зависимом фрейме хранится не только информация не об изображении, если она там вообще есть, а о том, как блоки предыдущего или предпредыдущего фрейма подвинулись на этом. Поэтому вы не можете для зависимого фрейма получить картинку, пока не задекодите немножечко.
Все, о чем мы будем с вами сейчас говорить, — keyframe- и intraframe-компрессия. Это то, как вы сжимаете картинку внутри keyframe.
Давайте посмотрим на абстрактный кодек в вакууме и сравним его с JPEG. Пока кажется — зачем это делать? Все станет понятнее, trust me.
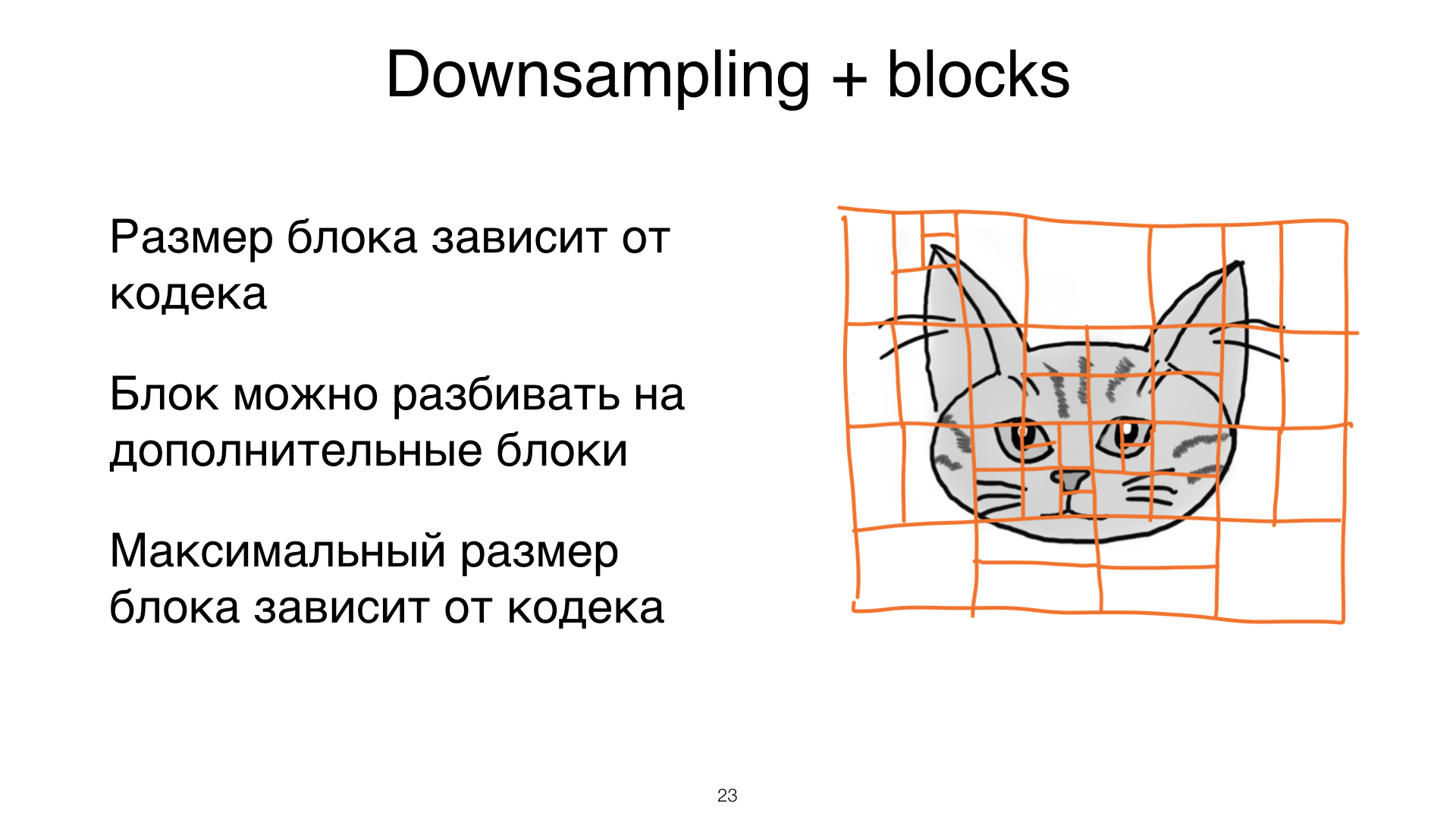
Повторим еще раз то же самое, что мы делаем с JPEG,. Вы берете картинку, делаете ей разбиение на каналы, делаете каналам Downsampling. Та же история здесь. Дальше вы вот эту картинку разбиваете на блоки. Но тут уже есть особенности. В первую очередь, размер блока, на которые вы разбиваете, зависит от вашего кодека. И эти блоки могут быть очень большими. Для JPEG — 8 на 8. Для видеокодеков — может быть, например, 128 на 128.
Дальше. Если у вас получились какие-то очень маленькие детали на вашей картиночке, на которую вы хотите обратить внимание, вы можете еще немножко подразбить блоки, примерно до размера 4 на 4. То, как вы разбиваете блоки, этот алгоритм разбиения зависит от кодека.
И самое последнее — максимальный размер блока, опять же, специфичен для вашего кодека. Энкодер — это часть кодека, чтобы было понятно по терминологии. Тут мы пока похожи на JPEG.
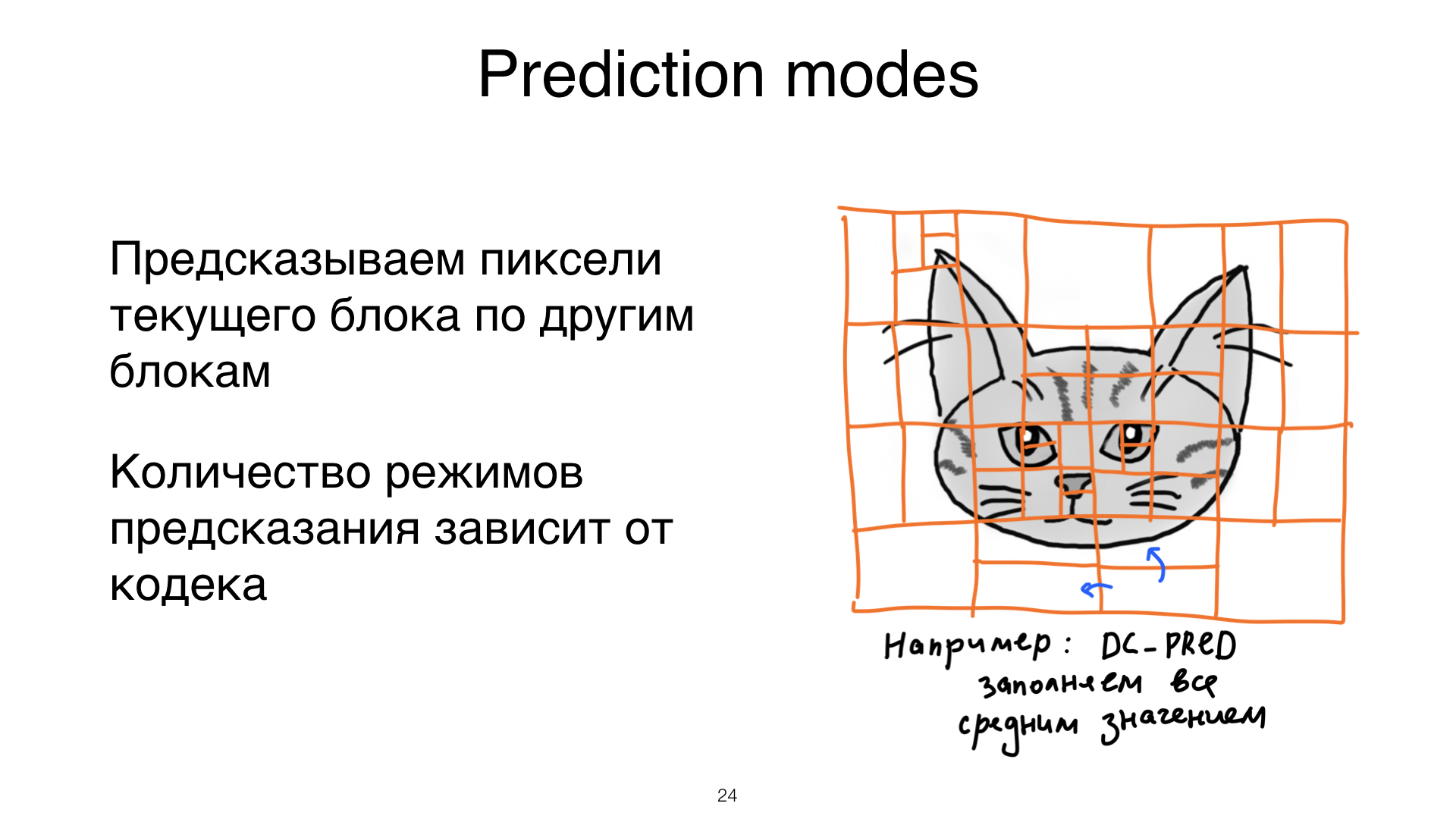
Что на JPEG не похоже, так это predictive coding. Мы о нем поговорили в части про пээнгэшки. Intraframe-компрессия видео оказывается такой классной и эффективной ровно из-за этого. Что здесь происходит?
Мы пытаемся предсказать пиксели каждого блока на основе предыдущих. То есть мы не храним пиксели в сыром виде, мы их предсказываем. Вариантов предсказания очень много. В рамках одного кодека мы можем разные варианты предсказаний использовать. Причем, для таких всяких затейливых кодеков этих вариантов аж 35, например. Как вы можете это делать. Давайте посмотрим на какой-нибудь пример.
Вот у вас есть блок. Вы говорите: хочу там пиксели предсказать. Вы смотрите налево, вы смотрите наверх и запоминаете, что там слева и сверху. Дальше вы берете все значения пикселей, которые нашли, усредняете и заполняете им блок, и говорите: я предсказал. Если вы угадали, а, кстати, на картиночке, где есть синие стрелочки, вы угадали, то вы молодцы, вам больше ничего не надо делать. Но, если вы не угадали, то вам нужно сохранить разницу между тем, что есть на самом деле, и тем, что вы предсказали. Вот эта разница сжимается намного-намного лучше, чем чисто значение пикселей.

Дальше все абсолютно точно так же, как в JPEG. Вы преобразуете получившийся блок. Но особенностями всяких разных кодеков является то, что вы можете использовать не DCT (дискретное косинусное преобразование), а что-нибудь еще. Что использовать — зависит от кодека.

Дальше опять те же самые таблички, но в отличие от JPEG вы можете использовать не одну табличку на весь ваш файл, а вы можете использовать несколько разных табличек для разных блоков. Представьте — у вас есть человек, например, на фоне неба. Возможно, так как небо голубое, вам там особенное качество не нужно, вы можете использовать для неба одно качество, одни таблички. А для человека, у которого всякая текстурка, одежда, используют другое качество, и получается классно и эффективно.

Самое последнее — то, чего нет у JPEG, и чего JPEG сильно-сильно не хватает. Это применение фильтров. Когда мы все пожали, у нас после сжатия возникают такие мерзкие артефакты. Если вы когда-нибудь сжимали JPEG на маленькое качество, вы должны видеть, как JPEG разваливаются просто на кошмарные ужасные блоки. В общем, чтобы от этих артефактов избавиться, видеокодеки используют специальную штуку. Они применяют фильтры, и грани этих блоков сглаживают. Технологии древних, которые позволяли то же самое сделать с JPEG, были такие. Вы берете ваш JPEG, сильно-сильно его сжимаете, потом подбрюлливаете вот так, чтобы не заметно было ничего. В общем, это примерно то же самое, но это уже сделано на уровне кодека. Замечательно.

Естественно, когда мы постарались и вот это все сделали, полученные блоки нам теперь надо обязательно сжать без потерь. Мы сжали, мы молодцы. При этом алгоритм сжатия похож на JPEG, но все-таки отличается. Тут надо понимать, что сжатие без потерь ограничено природным лимитом. Мы к нему очень хотим приблизиться, и лучше всего приблизиться к нему получается, если мы используем алгоритм, который называется Arithmetic coding. Причем там тоже есть всякие вариации. Это вновь зависит от энкодера, но давайте просто считать, что там сжатие без потерь и ок.
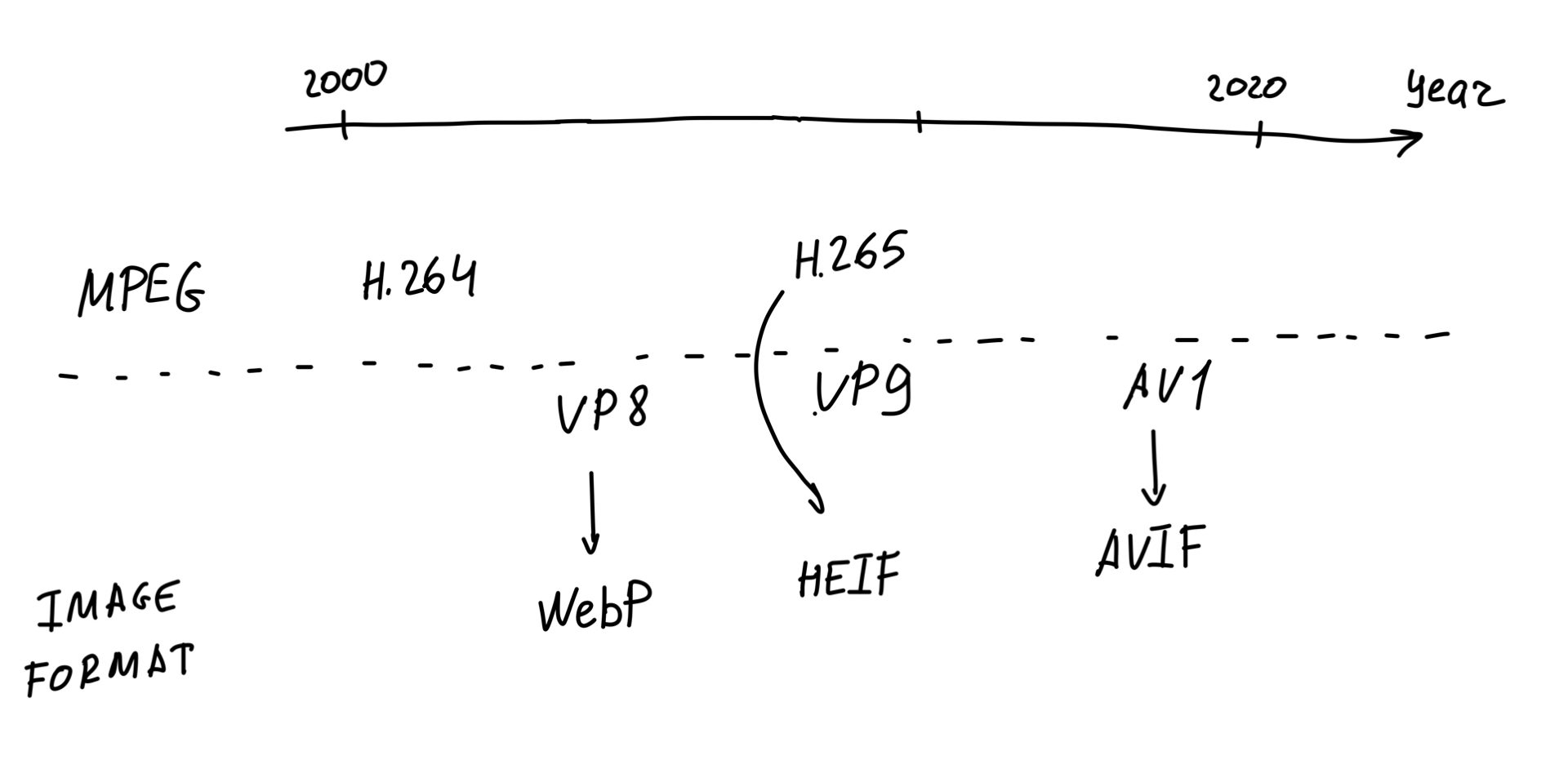
Я давно хотела назвать эти абстрактные кодеки в вакууме своими именами. Небольшой исторический экскурс. Что произошло за 20 лет? Я говорю только о тех видеокодеках, которые в вебе хотя бы как-то поддерживаются. H.264 — кодек, который поддерживает все и вся. Это дефолтное решение для всего видео. Через некоторое количество времени, через несколько лет появляется видеокодек VP8.
Тут начинаются дикие войны, холивары на тему, какой из этих кодеков лучше. Я очень долго гуглила — ответа нет. Про это написаны большие научные статьи, но в среднем, если я сейчас скажу одинаковые — в меня помидор полетит. Но, ладно, они одинаковые. В среднем. Тогда зачем нужен второй?
Второй нужен затем, что он бесплатный. Если вы используете H.264, вам надо нести денежку MPEG при некоторых обстоятельствах. Для VP8 вам денежку нести не надо. Это хорошо. Так вот, VP8 keyframe — это и есть WebP. Действительно, зачем нам изобретать новый формат изображения? Мы берем keyframe, мы так постарались, все это сжали. Обзываем все это новым форматом картинок, и вуаля!
Что происходит дальше? Дальше через некоторое количество лет появляются практически одновременно еще два крутых видеокодека, от MPEG и от Google. От Google — VP9, от MPEG — H.265. Рядом с H.265 появляется новый картиночный стандарт, который называется HEIF. Его не поддерживают браузеры, ни один вообще. Но его поддерживают ваши Apple-устройства. Стандарт HEIF — безумно интересная штука, потому что это просто абстракция над вот этой идеей. В HEIF-контейнер вы можете запихнуть keyframe практически из любого кодека. То есть VP8 — это не современный формат. А вот HEIF — современный.
Что происходит дальше? Сейчас в очень большой организации, в которую входят Mozilla и Google, пилится видеокодек, который называется AV1. Организация называется Alliance for Open Media. Качество AV1-видео в разы превышает все, что было раньше. Он бесплатный, он royalty free, он очень классный. У нас есть такой хороший HEIF-контейнер. Все, что нам осталось, — запихнуть в него AV1 keyframe. И это сделано. Новый формат запихивания AV1 keyframe в HEIF-контейнер называется AVIF. Это то, что ждет нас в будущем. Может быть, когда-нибудь мы это будем нативно использовать.
Но мы можем использовать это и сейчас. Мы просто кладем один фрейм из видео на страничку и говорим: вуаля, у вас картинка.

Как это сделано в WebP? WebP — это, как я сказала, VP8 keyframe, запакованный в контейнер, который называется riff. В riff-контейнере есть такой заголовочек. Там, не поверите, написано, что это WebP. Кто бы сомневался. PNG говорит, что он PNG WebP, и вот.
Но у WebP есть интересная особенность: внутри него может лежать VP8 keyframe, и это то, что обычно называют WebP. Но VP8 keyframe может и не быть. В общем, WebP поддерживает lossless-компрессию. WebP lossless — абсолютно другой формат, не имеющий никакого отношения к VP8, к сжатию с потерями и т. д. Поэтому когда вам кто-то говорит, что WebP эффективнее, чем что-то другое, первый вопрос, который нужно задать — а какой WebP-то? Потому что если говорить о сжатии без потерь, то существует природный придел, к которому мы можем стремиться. Эти разницы, «60% эффективнее, чем...», — это скорее не lossless, а WebP с потерями.
Окей, хватит теории, надоело, давайте уже посмотрим на что-нибудь.

Кликабельно
Начнем вот с чего. Берем фоточку, снятую профессиональной камерой. Вырезаем из нее кусок 1000 на 1000 пикселей. Это, кстати, очень прикольно выглядит на проекторе. Начинаем рассматривать мелкие детальки. При этом мы сжимаем этот кусок так, чтобы у нас получилось ровно 15 килобайт.

Кликабельно
Смотрите, что получается. JPEG развалился на блоки сразу. Действительно, низкое качество, мы этого и ожидали.
Вот так выглядит WebP. Он на блоки тоже развалился, но эти блоки не так явно видны. Когда вы используете WebP-энкодер и контролируете его руками, то можете контролировать силу фильтра, который используется в WebP. И если выкрутить этот фильтр посильнее, то от большого количества блочных артефактов можно избавиться. Поэтому чисто теоретически эти блоки тоже можно убрать.
А вот AV1. Давайте мы просто молча восхитимся. Смотрите, какой он классный, ровненький. AV1 поддерживается в Firefox, в Chrome, поэтому вы можете использовать AV1-видео вместо картиночки, если вдруг захотите.

Кликабельно
Тут есть спойлер, зря я его добавила. Ситуация, когда PNG побеждает WebP. Да, PNG в этом случае оказывается эффективнее, чем WebP. Это происходит потому, что я использовала lossy WebP.

Кликабельно
Что я сделала с пээнгэшкой? Я сделала режим indexed color, то есть обрезала палитру, по-моему, до 16 цветов. Это довольно эффективно для черно-белой картиночки. Получилось хорошо, сжалось очень сильно. Для качества lossy WebP мы получили размер больше. Однако для lossless это ожидаемо, он поэффективнее, чем пээнгэшка. Мы получили выигрыш.
Резюмирую. Очень круто пожатые пээнгэшки могут побеждать форматы сжатия с потерями и не побеждают lossless WebP. Печально, грустно.
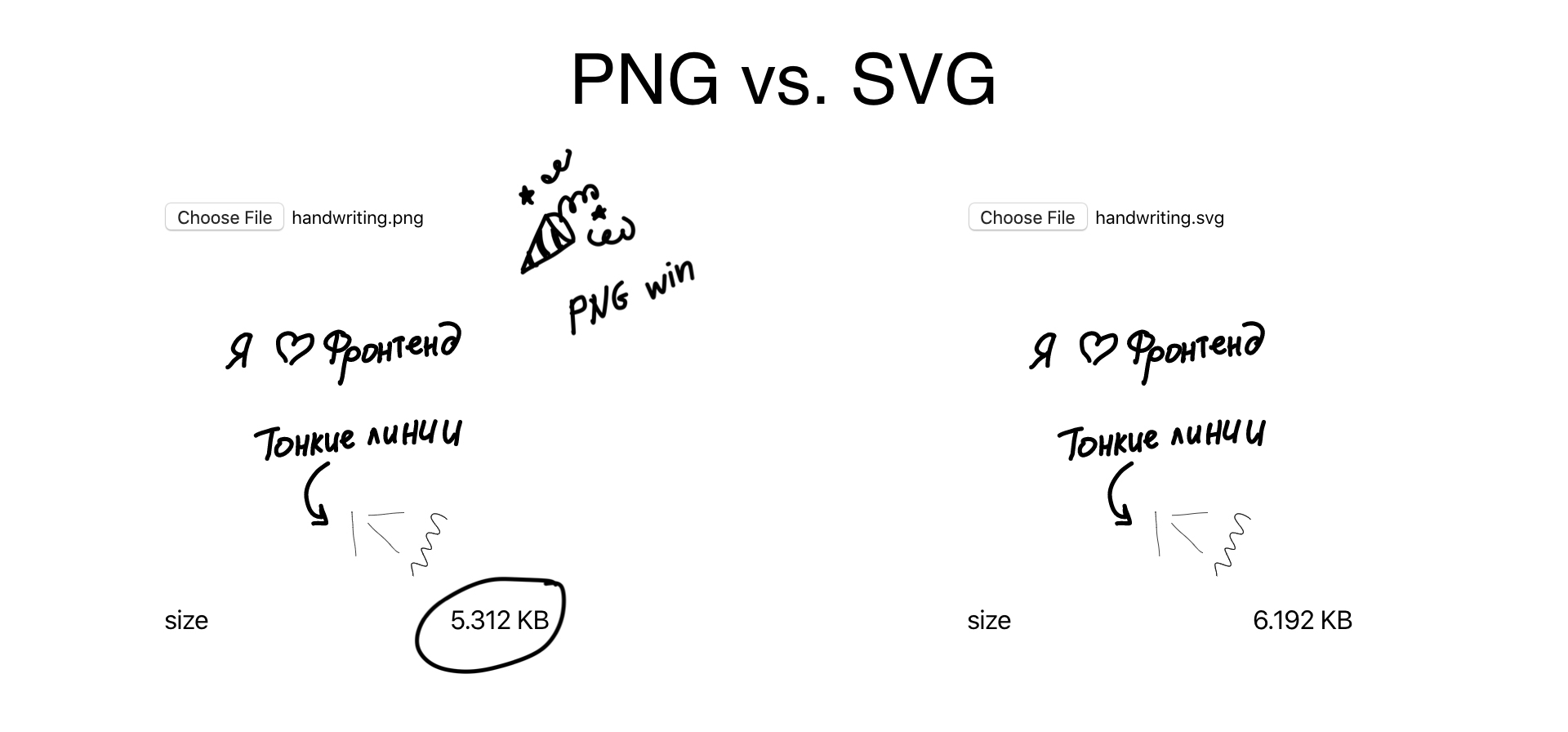
Кликабельно
Может быть, вас мучает вопрос: зачем ты занимаешься этим, мы же знаем, что есть SVG? И я знаю, но для некоторых размеров PNG оказывается эффективнее. Вот эта картиночка оказывается эффективнее SVG для размеров типа 200 на 200. Дальше SVG, конечно, побеждает.

Кликабельно
Теперь давайте посмотрим на Майка. Это Майк. Размеры у него 3000 на 3000 пикселей. JPEG против WebP. Тут очевидно было, что JPEG здесь побеждает. Но в данном случае у меня получилось примерно для одного и того же визуального качества победа всего на шесть процентов. Это особенность фоточки и того, как я эту фоточку готовила. Вы потом можете меня спросить, как я это делала.

Кликабельно
Еще все очень сильно зависит от параметров энкодера. Если очень сильно постараться и выкрутить параметры энкодера особым образом, то JPEG начнет побеждать WebP по размеру для одного и того же визуального качества. Я хотела бы сделать вывод, что коты сжимаются лучше JPEG, но нет. Это просто пример того, что вы, если захотите, можете выкрутить так, как вам нравится.

Кликабельно
Это очень низкое качество. JPEG тут разваливается на блоки. Особенно это хорошо видно как раз на проекторе — у пса посинел нос, он стал квадратным. WebP таким не болеет. Вроде бы все круто и хорошо, но штука в том, что для очень-очень низких качеств WebP дает примерно в два, а может быть, и в три раза больший размер файла, чем JPEG. Так что тут тоже надо подумать, какое качество вы хотите.

Кликабельно
Это самое честное сравнение. Так и надо сравнивать, потому что H.264 и WebP похожи. Как вы думаете, кто здесь победил? H.264. Но если честно, эксперимент был не совсем чистым. По-хорошему и в WebP, и в H.264 кадр видео примерно однозначен.

Кликабельно
А вот с AV1 все уже абсолютно ясно. Тридцатипроцентный выигрыш на том же визуальном качестве. Ура!

Кликабельно
Очень важно понимать, какую картинку вы кладете и как тот или иной формат отзывается на качестве картинки. Вот здесь пес в формате WebP на качестве около 75% весит 79 килобайт против 56 килобайт в JPEG. Почему это происходит?
Потому, что ни один видеокодек, ни один формат не умеет нормально сжимать шум. Если на вашей картинке много таких резких искажений, точечек и чего-то еще, то, скорее всего, у вас будут проблемы со сжатием. Если вы можете взять какую-нибудь другую картинку и этот шум убрать — уберите.
Итак, картинки — это сложная штука. Могут ли они тормозить ваш интерфейс? Важный и хороший вопрос.

Ответ: скорее всего, нет. Почему так происходит? Потому что когда картинку декодят, это происходит в отдельном потоке. Но есть исключение — если вы что-то рисуете на canvas, надо помнить, что декодинг изображения будет происходить в основном потоке и кнопочки могут в этот момент не нажиматься.

Если очень сильно хочется это подебажить, открывайте Chrome, ищите соответствующие rasterize threads и событие Image Decode, вы его найдете.

Если вы совсем-совсем любознательные, можете зайти на вкладочку tracing и посмотреть там с подробностями, что происходит при декодинге изображения.
Самое важное — инструменты оптимизации. Мы теперь примерно знаем, чего хотим. Осталось понять, как нам это сделать.

Самый главный инструмент оптимизации изображения — дизайнер, как бы это странно ни звучало. Только этот прекрасный человек знает, какую задачу вы вместе с ним хотите решить. Мы добавляем изображение на страницы не ради того, чтобы их классно оптимизировать, а чтобы пользователи впечатлились. Чтобы сохранить баланс между степенью оптимизации и впечатлениями пользователя, используйте дизайнера, отлично помогает.

Ссылка со слайда
Второй инструмент — наш марсианский open source, о котором я обещала рассказать. Эта штука называется imgproxy и решает вообще все наши проблемы. На своих проектах я использую только imgproxy, эта штука может практически все, что я хочу.
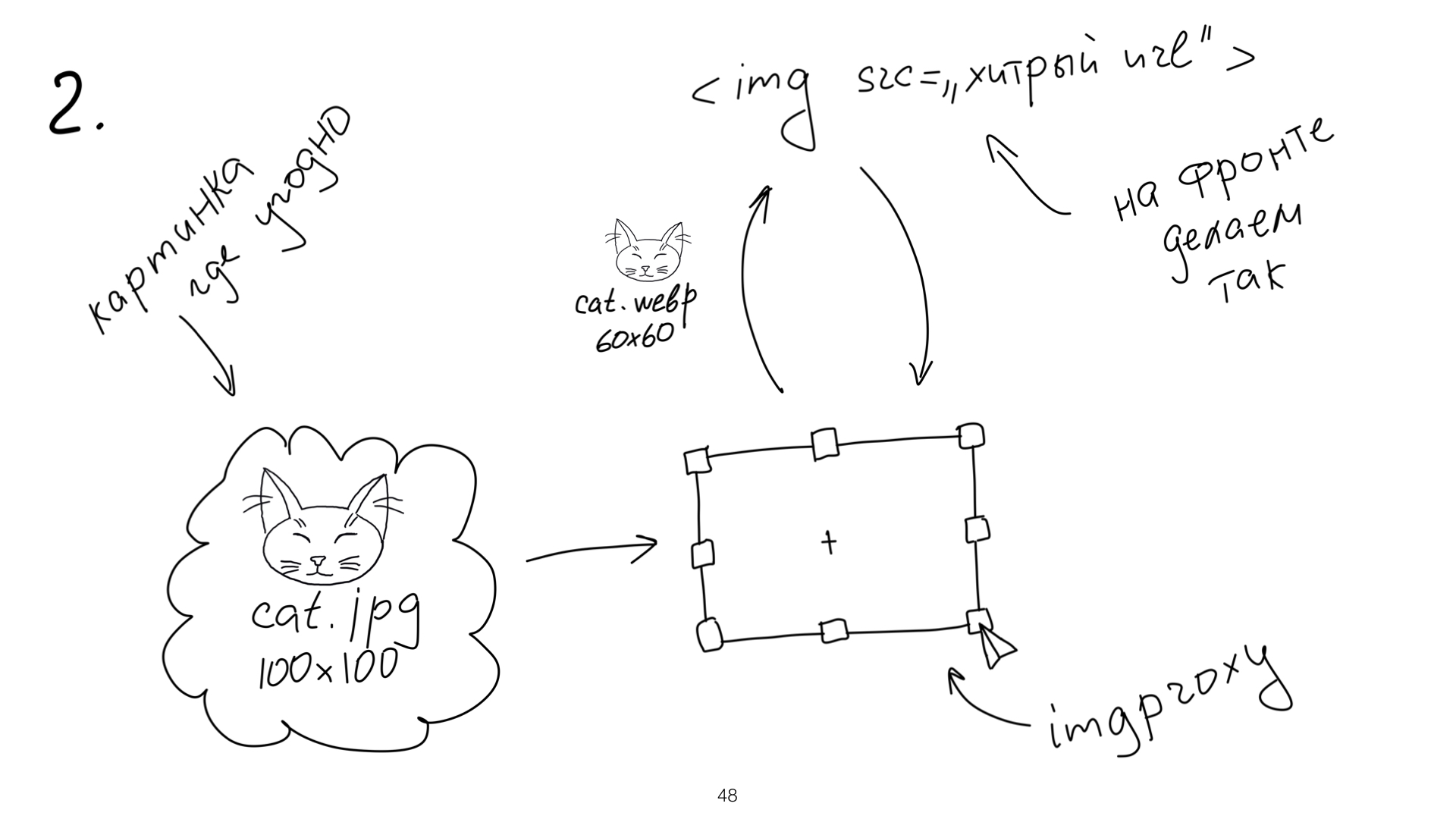
Как это работает? У вас есть какое-то пожелание по картинке. Вы хотите картинку определенного размера с определенной оптимизацией. И у вас где-то далеко есть картинка какого угодно разрешения — может, на локальном компьютере, а может, где-то у пользователя или вообще где угодно. Вам надо только сформировать специальный url и попросить imgproxy вашу картинку сресайзить. Это такой сервис, он может быть в облаке или где-то еще. То есть у вас был огромный котик, вы шлете специальный урл в imgproxy. Он на лету делает вам все, что вы хотите.

Если звучит непонятно, давайте посмотрим, как выглядит запрос к imgproxy. Во-первых, вам нужно сказать, где находится imgproxy. Во-вторых, если вы не хотите, чтобы вас агрессивно задосили, то урл, который вы просите, неплохо бы подписать цифровой подписью. Можете этого не делать, это просто дополнительная мера защиты.
Дальше, если вы хотите ресайзить, то прямо в url передаете параметры ресайза. Если хотите оптимизировать — то же самое. Вам осталось передать только оригинальный адрес вашей картинки.

Если вы хотите ручных оптимизаций, тут огромный сет инструментов. Я не буду сейчас их все описывать. В материалах к докладу, которые я с вами пошарю, все есть.

Вот самое-самое классное и полезное. Эти все изображения устроены не так сложно. Я думаю, мне удалось это до вас донести. Если вам интересно, берёте свой любимый язык программирования — наверное, JavaScript, хотя далеко не факт — и начинаете это все разбирать.
Если вы хотите сделать это в браузере — пожалуйста. Вам, наверное, понадобится обвязка, которая, скорее всего, написана на плюсах или на C. Но что вам мешает скомпилить это все в WebAssembly? Есть классное приложение, которое называется Squoosh. Оно делает ровно это. Вы тоже можете, попробуйте, будет прикольно. Мне очень нравится.
Всем большое спасибо за ваше внимание. Материалы к докладу — по ссылочке.
Полина Гуртовая из компании «Злые марсиане» выступила на нашей конференции
— Всем привет. Меня зовут Полина, я фронт в компании «Злые марсиане».
Может быть, вы знаете марсиан по нашему многочисленному open source. Я вам про него немножечко расскажу попозже. И наверное, надо сказать, что мы еще продукты разрабатываем, а не только пилим open source.
Материалы к докладу будет доступны вам по чудесной ссылочке в репозитории на GitHub.
Давайте немножечко поговорим про оптимизации. Когда мы ими занимаемся, проблема в том, что они получаются хорошо, если мы понимаем, что мы делаем. Если не понимаем — получается плохо. Когда дело доходит до оптимизации изображений, к сожалению, тут все совсем-совсем не круто. Мы можем вообще не оптимизировать изображения, и тогда будут двухметровые монстры на проде, это все грустно и печально.
Если же мы все-таки оптимизируем, то что мы делаем? Мы думаем: вот у нас есть картинка, это какой-то таинственный черный ящик, и программа-оптимизатор с этой картинкой что-то делает, какое-то черное шаманство. Качество оптимизации, которое у нас получается, немножко сомнительное.
Давайте посмотрим на пример. У меня есть котик в формате PNG. Я думаю, надо его оптимизировать. Что я делаю? Я создаю WebP-вариант и заботливо складываю оба изображения в тег <picture>. Как вы думаете, я молодец здесь или нет? Почему так мало рук? Я правда молодец!
Я сделала все правильно, но WebP-вариант получился на два килобайта больше, чем оригинал. Это немножко не то, чего я хотела.?
Еще одна оптимизация, попытка №2. У меня есть маленький контейнер на страничке и большой-большой котик. Я хочу большого котика в маленький контейнер вложить. Что я делаю? Я делаю ресайз, потому что глупо гонять байты по сети, если у меня размер моего контейнера маленький. Я, конечно, учитываю device pixel ratio своего устройства. Как вы думаете, здесь я молодец или нет? Я молодец! А смотрите, что у меня получилось.
Я использую библиотеку libvips. Она очень классная и популярная, и из моего огромного, но довольного легкого котика получился маленький и очень тяжелый. В 2,5 раза увеличился (в байтах) котик при ресайзе (в пикселях) в меньшую сторону. Круто, да?
В общем, чтобы с нами такого не происходило, чтобы мы понимали, как нам правильно оптимизировать свои картинки под свою задачу, и, вообще, чтобы мы хоть понимали, что происходит, давайте-ка заглянем в коробку и поймем, что же там внутри.
Заглядывать начнем с такого интересного формата, как PNG. Примерно на каждом сайте где-то спрятана маленькая пээнгэшечка. Это раз. Поэтому их надо понимать. Второе: PNG — формат сжатия без потерь. Это значит, мы гарантируем идеальное совпадение с оригиналом по пикселям, но при этом мы, увы, ограничены природой, мы не можем сжать меньше, чем насколько-то.
Пээнгэшка складывается в контейнер, как и любой картиночный формат. Одна из первых вещей, которые нам надо сообщить программе, если она это все будет читать, — что же там внутри лежит. Если вы предполагаете, что ваши декодеры определяют картинки по расширению, — это не так.
Пээнгэшка сообщает, что она PNG, первыми восемью байтами в своем контейнере. Там написано «PNG». Дальше — опять же, это характерно для любого контейнера — у вас есть некоторый layout чанков. То есть инфа упакована в чанки, они как-то устроены. Как — определяет контейнер. В PNG это выглядит так: у вас есть четыре байта, которые отвечают за длину, и четыре байта, которые отвечают за тип чанка. Какие типы — мы поговорим чуть попозже. ?
Если у чанка ненулевая длина, у него есть payload. Кроме этого, есть такая штука, как контрольная сумма. Вы проверяете, не побилось ли там чего. Дальше идут следующие чанки.
Разобрать не только PNG-файл, но и практически любой довольно легко. Берем FileReader, это браузерный API. Читаем файл с помощью FileReader. Как только мы прочитали, мы режем этот файлик на чанки. Я не буду приводить здесь код функции split to chunks, но вы можете догадаться, что там затейливое сочетание if и for. ?
Окей, нарезали, смотрим, что получается. У нас есть несколько типов чанков, и они очень-очень характерны практически для любого формата. Первый называется IHDR. Есть некоторое количество чанков, которые называются IDAT. Эти названия могут показаться вам немножко странными, но мы сейчас разберемся, что это такое. Когда все заканчивается, мы видим чанк end.
Давайте повнимательнее посмотрим внутрь чанков. IHDR — мета-чанк, и такой мета-чанк есть практически у любой картинки. Он называется по-другому, он устроен по-другому, но он, скорее всего, есть. Без него ваш декомпрессор — штука, которая показывает вам пээнгэшки или не пээнгэшки, — не сможет вам ничего показать. Что лежит в этом чанке? Опять же, содержимое характерно для большинства форматов. Это высота и ширина. Высота и ширина зашита в ваш файл, она вам приходит. Дальше тут типичные пээнгэшные флаги: bitDepth, colorType и interlacing. ?
Перед тем, как мы поговорим, что значат эти флаги и почему они так сильно-сильно нам важны, давайте посмотрим, как мы храним в пээнгэшках пиксели. В пээнгэшках пиксели хранятся внутри чанка, который называется IDAT. При хорошем раскладе пиксели — некоторое количество чисел, которые запакованы в чанк, и этот чанк сжат алгоритмом сжатия Deflate. Кто пользовался алгоритмом сжатия Deflate? Окей, а когда вы последний раз что-нибудь зипали? Вы знаете, что Deflate это и есть gzip? Так что я думаю — пользовались многие.
Но в пээнгэшках появляется еще одна интересная штуковина, которая используется в огромном количестве форматов, но наверное, что во всех. Эта штуковина называется predictive coding. Дело в том, что наши изображения — это не рандомные пиксели. То, что нарисовано на нашей картиночке, как-то связано друг с другом. Есть какие-то темные области, светлые области и так далее.
Мы пытаемся заэксплойтить этот факт, и вместо того, чтобы в этих синих ячейках хранить значение пикселей, мы пытаемся эти пиксели предсказать на основе предыдущих. В PNG эти предсказания очень простые, и они пакуются в самый-самый первый байтик перед строчкой с пикселями. Предсказание может быть таким, например, давайте ничего не предсказывать и просто положим все, как есть. Или, например, мы можем сказать так: а давайте мы будем хранить только разницу между текущим пикселем и предыдущим.
Если у вас один и тот же цвет в вашей строке у вас будут все нули, все прекрасно сжалось, это очень круто.
Но теперь давайте поговорим что, собственно, значит пиксель. Пиксель представляется в пээнгэшке как некоторое количество чиселок. Манипулируя тем, какое количество чиселок есть, вы можете очень и очень сильно сжимать ваше PNG — раза в три.
Какие тут есть варианты? Первое — True Color и alpha. У нас есть три канала, три цвета, три числа за цвет. Плюс канал, который отвечает за прозрачность.
Размер этой чиселки в битах — это bitDepth, тот самый флаг, который мы видели в чанке IHDR. Чем меньше ваш bitDepth, — тем меньше файл, но тем меньше цветов вы сможете им представлять. Типичная чиселка — 8. Это сколько? По-моему, будет 16 млн с чем-то.
Окей, первая оптимизация, которую вы можете сделать, — выкинуть alpha-каналы в своей пээнгэшке. Это будет уже другой colorType.
Вы можете еще круче оптимизировать и вместо четырех чисел использовать всего одно. Но проблема в том, что тогда ваша пээнгэшка должна быть черно-белой.
Если вы все-таки хотите только одно число, а цвета оставить, то так тоже можно сделать. Что здесь происходит? Вы берете все цвета внутри вашей пээнгэшки и вырезаете их в отдельный чанк. Называете его палитрой. Дальше внутри сэмпла, который отвечает за пиксель внутри чанка IDAT, вы храните просто индекс этой палитры. Если у вас какой-нибудь скриншот без затейливого бэкграунда или какой-нибудь чертежик, вот эта штука заходит просто идеально. Она сжимает пээнгэшки прямо ух!
Еще одна важная вещь, про которую нужно сказать, — это Interlacing. Что такое Interlacing? Это когда вы грузите свою пээнгэшку постепенно. У вас не одна пээнгэшка, а несколько изображений. Каждое это изображение называется скан.
При этом внутри пээнгэшки вы сортируете пиксели таким образом, что часть пикселей выдрана из картинок, из специальных мест идет одно изображение. Следующая часть — другое и так далее. Казалось бы, крутая техника, как прогрессивный JPEG.
Но выглядит это вот так. Я не уверена, хотите ли вы, чтобы ваши пользователи это видели, хотя, может быть, для вашей задачи это может быть полезно.
Вторая и очень серьезная проблема Interlaced PNG заключается в том, что как только вы интерлейсите свою пээнгэшку, размер вашей пээнгэшки становится больше. Причем не слабецки так больше, где-то на пару килобайт ваша шести-килобайтная пээнгэшка вырастет, если вы выключите Interlaced. Поэтому подумайте внимательно, хотите вы этого или нет.
Мы поговорили всего-навсего о PNG, но уже из этой штуки можно сделать важные и полезные выводы. Первый вывод: размер вашего файла, вы не поверите, зависит от того, что там нарисовано. Черный квадрат сжимается лучше, чем котик, не буду тут никакой рекомендации давать. Второе, более важное: размер вашего файла очень сильно зависит от энкодера и от его параметров, которые вы передаете.
Если вы хотите посмотреть, как работают ужасные энкодеры, воспользуйтесь браузерными. Как это делается? Берете PNG-файл, рисуете его на canvas, потом нажимаете save as и сравниваете то, что было, с тем, что получилось. В общем, Chrome вам увеличит размер файла в 2,5 раза, Firefox — в 1,6.
От формата, кстати, это тоже всегда зависит, то есть не только PNG надо пользоваться. Давайте разбираться, почему все зависит от формата и какие у нас еще есть интересные варианты.
Для этого мы поговорим о технологии древних, о JPEG. Нельзя, конечно, преуменьшить важность JPEG. Они встречаются везде. Они такие классные, хорошие, и тем более, котики в JPEG — довольно частая история. Но JPEG — довольно сложная штука, и сложна она за счет того, что JPEG — это сжатие с потерями. Причем JPEG — это всегда сжатие с потерями. JPEG 100% quality все равно сжимает с потерями.
Как мы получаем сжатие с потерями? Очень просто. Мы берем какой-то источник, выкидываем из него данные, а потом сжимаем без потерь. То есть плюс один шаг.
Давайте разберемся, как мы вносим потери в наши JPEG. Итак, у вас есть котик размером 32 на 32. Чтобы нам сделать первый шаг с потерями, нужно поменять у него каналы. Обычно мы рассуждаем о картинках в терминах RGB. Но мы воспринимаем цвета немножечко затейливо. Наш мозг — это вообще большая проблема, хотя он нам очень сильно помогает сжимать JPEG.
Мы очень хорошо воспринимаем черно-белое изображение. Даже если вы присмотритесь, вы обратите внимание, что детальки на черно-белом изображении вы различаете лучше. Мы просто выносим это черно-белое изображение в отдельный канал. Он называется Y. На самом деле, Y-штрих. Мы с ним ничего не делаем, просто оставляем его как есть.
Есть еще два канала, которые отвечают за цвет. Это CB и CR. С этими каналами мы уже можем немножечко развлекаться. Здесь с этими каналами мы производим такую прикольную процедуру, которая называется Downsampling. Мы берем и уменьшаем разрешение этого канала. Для JPEG типично уменьшать в два раза. То есть, по сути, у вас получилось три картинки — одна оригинальная и две в два раза меньше. Ура!
Что мы делаем дальше? Мы не сжимаем JPEG, не как целый файлик. Мы разбиваем его на блоки и дальше сжимать мы начинаем уже блоки. Блоки в JPEG размером 8 на 8, и смотрите, что с ними происходит. Давайте смотреть только на канал Y. CB и CR — все то же самое.
Итак, блок — это не картинка, а чиселки. Нам нужно внести потери в JPEG. Этот блок 8 на 8, 64 пикселя, какой выкинуть? Тот, что слева, тот, что справа, тот, что посередине? Непонятно. Но есть классная математика, которая позволяет нам порешать эту проблему.
Эта математика называется — сейчас, пожалуйста, не нервничайте, если кто вспомнит страшное институтское прошлое — дискретное косинусное преобразование. Так вот, при помощи этого дискретного косинусного преобразования вы можете эти чиселки в вашем блоке преобразовать так, чтобы среди них были важные и неважные.
Важно: в верхней левой части блока после преобразования остаются важные чиселки. В нижней правой остаются не важные чиселки.
Дальше вам нужно внести в ваши JPEG потери. Это тоже очень просто сделать. Этот трюк называется квантизацией. Простите, если вам сейчас хочется спать, но это важно, поверьте мне. Так вот, эта самая квантизация работает довольно простым образом. Вы берете ваш блок и специально придуманную табличку. Эта табличка определяется вашей программой-энкодером. Те чиселки, которые получились в вашем блоке, вы на эту табличку делите почленно и целочисленно. Что у вас получится в результате?
Так как в нижней правой части таблички цифры большие, там будут одни нули.
И при этом ваш JPEG, ваш блок отлично сожмется. У вас останется небольшое количество чисел, которое вы вот таким затейливым зигзагом обойдете, нули все уйдут, и, ура, наш блок готов к сжатию. Дальше нам осталось только сжать его алгоритмом сжатия без потерь. В JPEG используется Huffman Coding, чем бы это ни было.
Как это пакуется в контейнер? Контейнеры JPEG выглядят немножечко стремно, я их боюсь. Потому что вы видите первые два байта и там написано, что, скорее всего, это JPEG. Но пока непонятно.
Дальше вам надо поискать два мета-чанка. Почему два? Потому что JPEG — это очень большой сет разных стандартов. То, что мы называем JPEG, по стандарту называется JIFF. Это специальное расширение стандарта JPEG. Дальше я продолжать не буду — в общем, там два мета-чанка, просто поверьте мне. В этих мета-чанках лежит информация о ширине и высоте вашего файлика и о версии JPEG. Представляете, у JPEG еще версии есть! И, кроме того, прогрессивный ли это JPEG? Это важный флаг. Он говорит о том, как ваши блоки будут распределены дальше.
Если JPEG не прогрессивный, то что вам нужно, чтобы раскодировать ваши блоки? Качество JPEG, вот эта самая табличка. Табличка, на которую вы делите ваши блоки, и есть качество. Но у JPEG качеств два. Первое качество отвечает за канал Y, второе — за каналы CB и CR, это то, что определяет цвет. Так как качество мы положили в файлик и все сжали алгоритмом сжатия без потерь, нам нужен еще специальный словарик Huffman Tables, чтобы это все поразжимать.
Дальше идут ваши блоки, и дальше ваш JPEG закончился.
Окей, прогрессивная история. Все абсолютно точно так же. В самом начале у вас идет мета-чанк. Дальше идет ваше качество в виде 64 чиселок, плюс 64 чиселок. А дальше просто те же самые блоки, но просто немножечко по-другому с распределенными чиселками. Сначала часть блоков, потом еще одна часть, еще одна часть и так далее. По мере получения этих блоков браузер отрисовывает вам приближение вашего JPEG, потому что, по сути, вот эти числа — это некоторое приближение вашего файла.
Про JPEG мы закончили, можно выдохнуть, все хорошо. Давайте поговорим по такую интересную вещь, как JPEG 2000. Кто-нибудь из вас в продакшене использует JPEG 2000? Окей, а кто про это что-то когда-нибудь слышал? А кто из вас в Lighthouse прочитал — «используйте современные форматы»?
В общем, JPEG 2000 — классный интересный формат, который, во-первых, эффективней JPEG. Во-вторых, вы не поверите, он в некоторых случаях эффективнее еще и WebP, о котором поговорим попозже.
Он умеет быть прозрачным, умеет сжиматься без потерь. Просто идеальный формат. Но, к сожалению, да, работает он только в Safari.
Еще стоит сказать, что JPEG 2000 устроен очень затейливым образом и работает на классной математике, которая называется wavelet transform. Если вам вдруг интересно, погуглите, а мы пойдем дальше.
Дальше нам неожиданно надо поговорить про видео. Весь этот доклад — он про оптимизации изображений и про изображения. Но видео здесь очень важно, вы сейчас увидите, почему. Когда мы думаем о видео, первое слово, которое приходит нам в голову, — «кодек». Видео надо как-то энкодить, и чтобы видео показать, нам надо его задекодить. Если мы декодим видеопоток, что мы получаем?
В первую очередь, у нас набор фреймов. Но не надо думать об этих фреймах как о картиночках в гифке. Все не так. То, какие фреймы бывают, очень сильно зависит от кодека. Но в общем случае можно считать, что у вас есть keyframe. Из keyframe можно вытащить котика — в смысле, любую картинку, которая на этом keyframe есть. И есть зависимые фреймы. Вот из зависимого фрейма котика вытащить нельзя, потому что в зависимом фрейме хранится не только информация не об изображении, если она там вообще есть, а о том, как блоки предыдущего или предпредыдущего фрейма подвинулись на этом. Поэтому вы не можете для зависимого фрейма получить картинку, пока не задекодите немножечко.
Все, о чем мы будем с вами сейчас говорить, — keyframe- и intraframe-компрессия. Это то, как вы сжимаете картинку внутри keyframe.
Давайте посмотрим на абстрактный кодек в вакууме и сравним его с JPEG. Пока кажется — зачем это делать? Все станет понятнее, trust me.
Повторим еще раз то же самое, что мы делаем с JPEG,. Вы берете картинку, делаете ей разбиение на каналы, делаете каналам Downsampling. Та же история здесь. Дальше вы вот эту картинку разбиваете на блоки. Но тут уже есть особенности. В первую очередь, размер блока, на которые вы разбиваете, зависит от вашего кодека. И эти блоки могут быть очень большими. Для JPEG — 8 на 8. Для видеокодеков — может быть, например, 128 на 128.
Дальше. Если у вас получились какие-то очень маленькие детали на вашей картиночке, на которую вы хотите обратить внимание, вы можете еще немножко подразбить блоки, примерно до размера 4 на 4. То, как вы разбиваете блоки, этот алгоритм разбиения зависит от кодека.
И самое последнее — максимальный размер блока, опять же, специфичен для вашего кодека. Энкодер — это часть кодека, чтобы было понятно по терминологии. Тут мы пока похожи на JPEG.
Что на JPEG не похоже, так это predictive coding. Мы о нем поговорили в части про пээнгэшки. Intraframe-компрессия видео оказывается такой классной и эффективной ровно из-за этого. Что здесь происходит?
Мы пытаемся предсказать пиксели каждого блока на основе предыдущих. То есть мы не храним пиксели в сыром виде, мы их предсказываем. Вариантов предсказания очень много. В рамках одного кодека мы можем разные варианты предсказаний использовать. Причем, для таких всяких затейливых кодеков этих вариантов аж 35, например. Как вы можете это делать. Давайте посмотрим на какой-нибудь пример.
Вот у вас есть блок. Вы говорите: хочу там пиксели предсказать. Вы смотрите налево, вы смотрите наверх и запоминаете, что там слева и сверху. Дальше вы берете все значения пикселей, которые нашли, усредняете и заполняете им блок, и говорите: я предсказал. Если вы угадали, а, кстати, на картиночке, где есть синие стрелочки, вы угадали, то вы молодцы, вам больше ничего не надо делать. Но, если вы не угадали, то вам нужно сохранить разницу между тем, что есть на самом деле, и тем, что вы предсказали. Вот эта разница сжимается намного-намного лучше, чем чисто значение пикселей.
Дальше все абсолютно точно так же, как в JPEG. Вы преобразуете получившийся блок. Но особенностями всяких разных кодеков является то, что вы можете использовать не DCT (дискретное косинусное преобразование), а что-нибудь еще. Что использовать — зависит от кодека.
Дальше опять те же самые таблички, но в отличие от JPEG вы можете использовать не одну табличку на весь ваш файл, а вы можете использовать несколько разных табличек для разных блоков. Представьте — у вас есть человек, например, на фоне неба. Возможно, так как небо голубое, вам там особенное качество не нужно, вы можете использовать для неба одно качество, одни таблички. А для человека, у которого всякая текстурка, одежда, используют другое качество, и получается классно и эффективно.
Самое последнее — то, чего нет у JPEG, и чего JPEG сильно-сильно не хватает. Это применение фильтров. Когда мы все пожали, у нас после сжатия возникают такие мерзкие артефакты. Если вы когда-нибудь сжимали JPEG на маленькое качество, вы должны видеть, как JPEG разваливаются просто на кошмарные ужасные блоки. В общем, чтобы от этих артефактов избавиться, видеокодеки используют специальную штуку. Они применяют фильтры, и грани этих блоков сглаживают. Технологии древних, которые позволяли то же самое сделать с JPEG, были такие. Вы берете ваш JPEG, сильно-сильно его сжимаете, потом подбрюлливаете вот так, чтобы не заметно было ничего. В общем, это примерно то же самое, но это уже сделано на уровне кодека. Замечательно.
Естественно, когда мы постарались и вот это все сделали, полученные блоки нам теперь надо обязательно сжать без потерь. Мы сжали, мы молодцы. При этом алгоритм сжатия похож на JPEG, но все-таки отличается. Тут надо понимать, что сжатие без потерь ограничено природным лимитом. Мы к нему очень хотим приблизиться, и лучше всего приблизиться к нему получается, если мы используем алгоритм, который называется Arithmetic coding. Причем там тоже есть всякие вариации. Это вновь зависит от энкодера, но давайте просто считать, что там сжатие без потерь и ок.
Я давно хотела назвать эти абстрактные кодеки в вакууме своими именами. Небольшой исторический экскурс. Что произошло за 20 лет? Я говорю только о тех видеокодеках, которые в вебе хотя бы как-то поддерживаются. H.264 — кодек, который поддерживает все и вся. Это дефолтное решение для всего видео. Через некоторое количество времени, через несколько лет появляется видеокодек VP8.
Тут начинаются дикие войны, холивары на тему, какой из этих кодеков лучше. Я очень долго гуглила — ответа нет. Про это написаны большие научные статьи, но в среднем, если я сейчас скажу одинаковые — в меня помидор полетит. Но, ладно, они одинаковые. В среднем. Тогда зачем нужен второй?
Второй нужен затем, что он бесплатный. Если вы используете H.264, вам надо нести денежку MPEG при некоторых обстоятельствах. Для VP8 вам денежку нести не надо. Это хорошо. Так вот, VP8 keyframe — это и есть WebP. Действительно, зачем нам изобретать новый формат изображения? Мы берем keyframe, мы так постарались, все это сжали. Обзываем все это новым форматом картинок, и вуаля!
Что происходит дальше? Дальше через некоторое количество лет появляются практически одновременно еще два крутых видеокодека, от MPEG и от Google. От Google — VP9, от MPEG — H.265. Рядом с H.265 появляется новый картиночный стандарт, который называется HEIF. Его не поддерживают браузеры, ни один вообще. Но его поддерживают ваши Apple-устройства. Стандарт HEIF — безумно интересная штука, потому что это просто абстракция над вот этой идеей. В HEIF-контейнер вы можете запихнуть keyframe практически из любого кодека. То есть VP8 — это не современный формат. А вот HEIF — современный.
Что происходит дальше? Сейчас в очень большой организации, в которую входят Mozilla и Google, пилится видеокодек, который называется AV1. Организация называется Alliance for Open Media. Качество AV1-видео в разы превышает все, что было раньше. Он бесплатный, он royalty free, он очень классный. У нас есть такой хороший HEIF-контейнер. Все, что нам осталось, — запихнуть в него AV1 keyframe. И это сделано. Новый формат запихивания AV1 keyframe в HEIF-контейнер называется AVIF. Это то, что ждет нас в будущем. Может быть, когда-нибудь мы это будем нативно использовать.
Но мы можем использовать это и сейчас. Мы просто кладем один фрейм из видео на страничку и говорим: вуаля, у вас картинка.
Как это сделано в WebP? WebP — это, как я сказала, VP8 keyframe, запакованный в контейнер, который называется riff. В riff-контейнере есть такой заголовочек. Там, не поверите, написано, что это WebP. Кто бы сомневался. PNG говорит, что он PNG WebP, и вот.
Но у WebP есть интересная особенность: внутри него может лежать VP8 keyframe, и это то, что обычно называют WebP. Но VP8 keyframe может и не быть. В общем, WebP поддерживает lossless-компрессию. WebP lossless — абсолютно другой формат, не имеющий никакого отношения к VP8, к сжатию с потерями и т. д. Поэтому когда вам кто-то говорит, что WebP эффективнее, чем что-то другое, первый вопрос, который нужно задать — а какой WebP-то? Потому что если говорить о сжатии без потерь, то существует природный придел, к которому мы можем стремиться. Эти разницы, «60% эффективнее, чем...», — это скорее не lossless, а WebP с потерями.
Окей, хватит теории, надоело, давайте уже посмотрим на что-нибудь.
Кликабельно
Начнем вот с чего. Берем фоточку, снятую профессиональной камерой. Вырезаем из нее кусок 1000 на 1000 пикселей. Это, кстати, очень прикольно выглядит на проекторе. Начинаем рассматривать мелкие детальки. При этом мы сжимаем этот кусок так, чтобы у нас получилось ровно 15 килобайт.
Кликабельно
Смотрите, что получается. JPEG развалился на блоки сразу. Действительно, низкое качество, мы этого и ожидали.
Вот так выглядит WebP. Он на блоки тоже развалился, но эти блоки не так явно видны. Когда вы используете WebP-энкодер и контролируете его руками, то можете контролировать силу фильтра, который используется в WebP. И если выкрутить этот фильтр посильнее, то от большого количества блочных артефактов можно избавиться. Поэтому чисто теоретически эти блоки тоже можно убрать.
А вот AV1. Давайте мы просто молча восхитимся. Смотрите, какой он классный, ровненький. AV1 поддерживается в Firefox, в Chrome, поэтому вы можете использовать AV1-видео вместо картиночки, если вдруг захотите.
Кликабельно
Тут есть спойлер, зря я его добавила. Ситуация, когда PNG побеждает WebP. Да, PNG в этом случае оказывается эффективнее, чем WebP. Это происходит потому, что я использовала lossy WebP.
Кликабельно
Что я сделала с пээнгэшкой? Я сделала режим indexed color, то есть обрезала палитру, по-моему, до 16 цветов. Это довольно эффективно для черно-белой картиночки. Получилось хорошо, сжалось очень сильно. Для качества lossy WebP мы получили размер больше. Однако для lossless это ожидаемо, он поэффективнее, чем пээнгэшка. Мы получили выигрыш.
Резюмирую. Очень круто пожатые пээнгэшки могут побеждать форматы сжатия с потерями и не побеждают lossless WebP. Печально, грустно.
Кликабельно
Может быть, вас мучает вопрос: зачем ты занимаешься этим, мы же знаем, что есть SVG? И я знаю, но для некоторых размеров PNG оказывается эффективнее. Вот эта картиночка оказывается эффективнее SVG для размеров типа 200 на 200. Дальше SVG, конечно, побеждает.
Кликабельно
Теперь давайте посмотрим на Майка. Это Майк. Размеры у него 3000 на 3000 пикселей. JPEG против WebP. Тут очевидно было, что JPEG здесь побеждает. Но в данном случае у меня получилось примерно для одного и того же визуального качества победа всего на шесть процентов. Это особенность фоточки и того, как я эту фоточку готовила. Вы потом можете меня спросить, как я это делала.
Кликабельно
Еще все очень сильно зависит от параметров энкодера. Если очень сильно постараться и выкрутить параметры энкодера особым образом, то JPEG начнет побеждать WebP по размеру для одного и того же визуального качества. Я хотела бы сделать вывод, что коты сжимаются лучше JPEG, но нет. Это просто пример того, что вы, если захотите, можете выкрутить так, как вам нравится.
Кликабельно
Это очень низкое качество. JPEG тут разваливается на блоки. Особенно это хорошо видно как раз на проекторе — у пса посинел нос, он стал квадратным. WebP таким не болеет. Вроде бы все круто и хорошо, но штука в том, что для очень-очень низких качеств WebP дает примерно в два, а может быть, и в три раза больший размер файла, чем JPEG. Так что тут тоже надо подумать, какое качество вы хотите.
Кликабельно
Это самое честное сравнение. Так и надо сравнивать, потому что H.264 и WebP похожи. Как вы думаете, кто здесь победил? H.264. Но если честно, эксперимент был не совсем чистым. По-хорошему и в WebP, и в H.264 кадр видео примерно однозначен.
Кликабельно
А вот с AV1 все уже абсолютно ясно. Тридцатипроцентный выигрыш на том же визуальном качестве. Ура!
Кликабельно
Очень важно понимать, какую картинку вы кладете и как тот или иной формат отзывается на качестве картинки. Вот здесь пес в формате WebP на качестве около 75% весит 79 килобайт против 56 килобайт в JPEG. Почему это происходит?
Потому, что ни один видеокодек, ни один формат не умеет нормально сжимать шум. Если на вашей картинке много таких резких искажений, точечек и чего-то еще, то, скорее всего, у вас будут проблемы со сжатием. Если вы можете взять какую-нибудь другую картинку и этот шум убрать — уберите.
Итак, картинки — это сложная штука. Могут ли они тормозить ваш интерфейс? Важный и хороший вопрос.
Ответ: скорее всего, нет. Почему так происходит? Потому что когда картинку декодят, это происходит в отдельном потоке. Но есть исключение — если вы что-то рисуете на canvas, надо помнить, что декодинг изображения будет происходить в основном потоке и кнопочки могут в этот момент не нажиматься.
Если очень сильно хочется это подебажить, открывайте Chrome, ищите соответствующие rasterize threads и событие Image Decode, вы его найдете.
Если вы совсем-совсем любознательные, можете зайти на вкладочку tracing и посмотреть там с подробностями, что происходит при декодинге изображения.
Инструменты оптимизации
Самое важное — инструменты оптимизации. Мы теперь примерно знаем, чего хотим. Осталось понять, как нам это сделать.
Самый главный инструмент оптимизации изображения — дизайнер, как бы это странно ни звучало. Только этот прекрасный человек знает, какую задачу вы вместе с ним хотите решить. Мы добавляем изображение на страницы не ради того, чтобы их классно оптимизировать, а чтобы пользователи впечатлились. Чтобы сохранить баланс между степенью оптимизации и впечатлениями пользователя, используйте дизайнера, отлично помогает.
Ссылка со слайда
Второй инструмент — наш марсианский open source, о котором я обещала рассказать. Эта штука называется imgproxy и решает вообще все наши проблемы. На своих проектах я использую только imgproxy, эта штука может практически все, что я хочу.
Как это работает? У вас есть какое-то пожелание по картинке. Вы хотите картинку определенного размера с определенной оптимизацией. И у вас где-то далеко есть картинка какого угодно разрешения — может, на локальном компьютере, а может, где-то у пользователя или вообще где угодно. Вам надо только сформировать специальный url и попросить imgproxy вашу картинку сресайзить. Это такой сервис, он может быть в облаке или где-то еще. То есть у вас был огромный котик, вы шлете специальный урл в imgproxy. Он на лету делает вам все, что вы хотите.
Если звучит непонятно, давайте посмотрим, как выглядит запрос к imgproxy. Во-первых, вам нужно сказать, где находится imgproxy. Во-вторых, если вы не хотите, чтобы вас агрессивно задосили, то урл, который вы просите, неплохо бы подписать цифровой подписью. Можете этого не делать, это просто дополнительная мера защиты.
Дальше, если вы хотите ресайзить, то прямо в url передаете параметры ресайза. Если хотите оптимизировать — то же самое. Вам осталось передать только оригинальный адрес вашей картинки.
Если вы хотите ручных оптимизаций, тут огромный сет инструментов. Я не буду сейчас их все описывать. В материалах к докладу, которые я с вами пошарю, все есть.
Вот самое-самое классное и полезное. Эти все изображения устроены не так сложно. Я думаю, мне удалось это до вас донести. Если вам интересно, берёте свой любимый язык программирования — наверное, JavaScript, хотя далеко не факт — и начинаете это все разбирать.
Если вы хотите сделать это в браузере — пожалуйста. Вам, наверное, понадобится обвязка, которая, скорее всего, написана на плюсах или на C. Но что вам мешает скомпилить это все в WebAssembly? Есть классное приложение, которое называется Squoosh. Оно делает ровно это. Вы тоже можете, попробуйте, будет прикольно. Мне очень нравится.
Всем большое спасибо за ваше внимание. Материалы к докладу — по ссылочке.