
Глубокое обучение иногда выглядит как чистая магия, особенно тогда, когда компьютер учится делать что-то действительно креативное, например, рисовать картины! Используемая для этого технология называется GAN — генеративно-состязательная сеть, и в этой заметке мы рассмотрим, как такие сети устроены, и как натренировать их для генерации картин с помощью Azure Machine Learning.

Этот пост является частью инициативы AI April. Каждый день апреля мои коллеги из Microsoft пишут интересные статьи на тему AI и машинного обучения. Посмотрите на календарь — вдруг вы найдёте там другие интересующие вас темы. Статьи преимущественно на английском.
Если вы читали мои предыдущие посты про использование Azure ML с VS Code и оптимизацию гиперпараметров), то вы должно быть уже вдохновились тем, как удобно использовать Azure ML. Однако, рассмотренные мною примеры касались "игрушечного" датасета MNIST. Сегодня же мы рассмотрим применение Azure ML для решения практической задачи — создания искусственного искусства, например, таких картин:
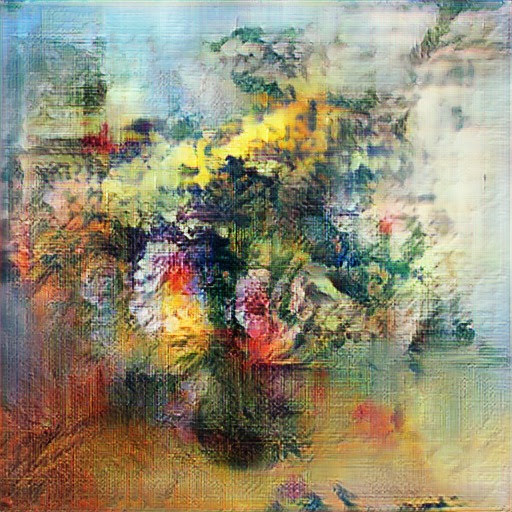 |
 |
|---|---|
| Цветы, 2019, Art of the Artificial keragan на наборе WikiArt: цветы |
Королева хаоса, 2019, keragan на наборе WikiArt: портреты |
Эти картины получены после обучения сети на наборе изображений из проекта WikiArt. Если вы захотите воспроизвести мои результаты, вы можете собрать данные самостоятельно, например, с использованием WikiArt Retriever, или взяв существующие коллекции из WikiArt Dataset или проекта GANGogh.
Я буду предполагать, что вы поместили все изображения для тренировки в директорию dataset. Эти изображения могут выглядеть, например, так:
Нейронная сеть, обучаясь на таких изображениях, должна научиться как базовым приёмам рисования (мазки краски, текстура холста), так и более крупным элементам (цветы, ваза) и особенностям композиции.
Генеративно-состязательные сети
Для генерации картин используются генеративно-состязательные сети (GAN).
Для упрощения работы с GAN я реализовал простую библиотеку keragan на базе Keras, и ниже опишу основные фрагменты кода в немного упрощённом виде.
GAN состоит из двух сетей:
- Генератор, способный генерировать изображения по входному вектору шума
- Дискриминатор, который различает настоящую картину и "поддельную" (сгенерированную генератором)
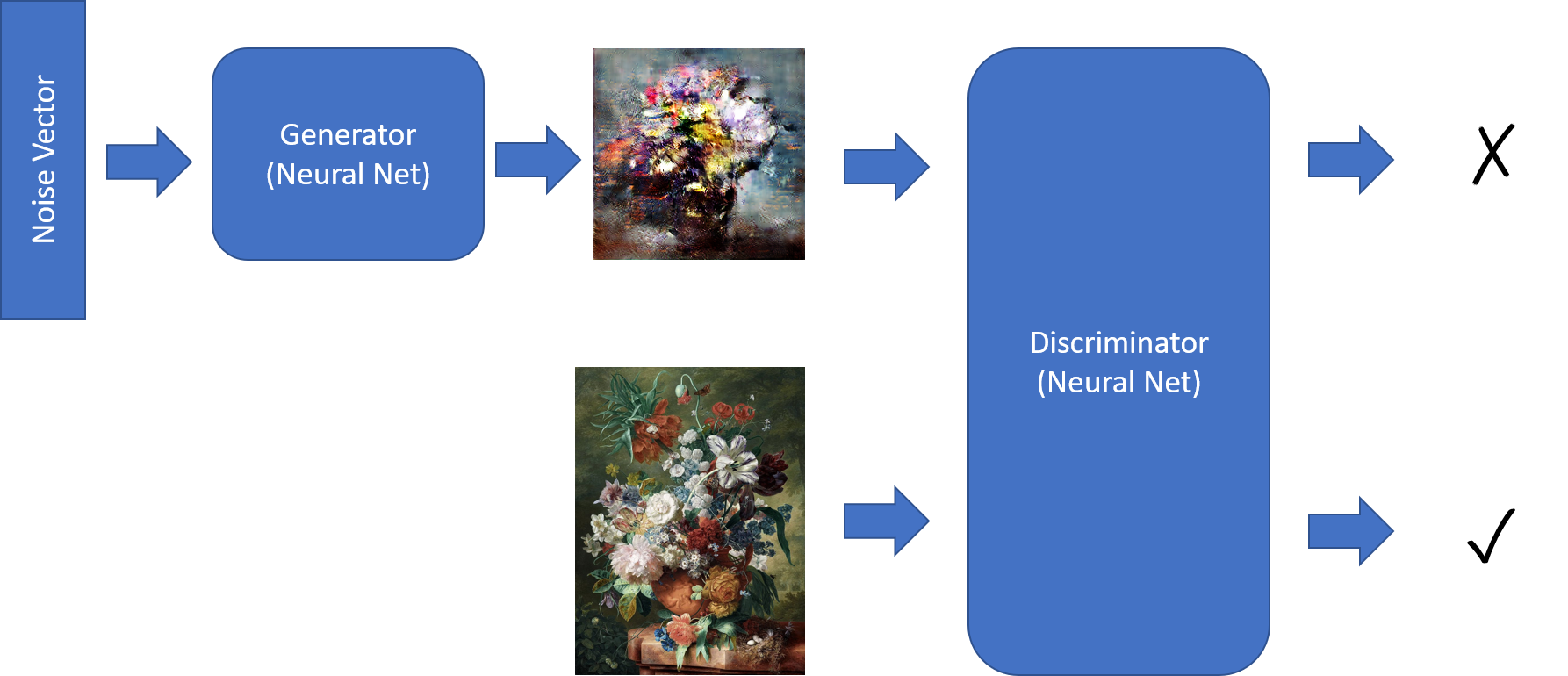
Обучение GAN происходит следующим образом:
- Получаем набор настоящих и сгенерированных изображений:
noise = np.random.normal(0, 1, (batch_size, latent_dim)) gen_imgs = generator.predict(noise) imgs = get_batch(batch_size) - Обучаем дискриминатор лучше различать оригинал и подделку. В качестве ожидаемого выхода мы передаём вектор единиц
onesи нулейzerosсоответственно:
d_loss_r = discriminator.train_on_batch(imgs, ones) d_loss_f = discriminator.train_on_batch(gen_imgs, zeros) d_loss = np.add(d_loss_r , d_loss_f)*0.5 - Тренируем комбинированную модель, состоящую из обоих сетей, чтобы улучить работу генератора:
g_loss = combined.train_on_batch(noise, ones)
На этом шаге дискриминатор не обучается, поскольку его веса в явном виде заморожены — это мы делаем при создании комбинированной модели:
discriminator = create_discriminator()
generator = create_generator()
discriminator.compile(loss='binary_crossentropy',optimizer=optimizer,
metrics=['accuracy'])
discriminator.trainable = False
z = keras.models.Input(shape=(latent_dim,))
img = generator(z)
valid = discriminator(img)
combined = keras.models.Model(z, valid)
combined.compile(loss='binary_crossentropy', optimizer=optimizer)Архитектура дискриминатора
Чтобы отличать настоящее изображение от подделки, мы используем классическую архитектуру свёрточной сети (CNN). Для изображения размером 64x64 она может выглядеть так:
discriminator = Sequential()
for x in [16,32,64]: # number of filters on next layer
discriminator.add(Conv2D(x, (3,3), strides=1, padding="same"))
discriminator.add(AveragePooling2D())
discriminator.addBatchNormalization(momentum=0.8))
discriminator.add(LeakyReLU(alpha=0.2))
discriminator.add(Dropout(0.3))
discriminator.add(Flatten())
discriminator.add(Dense(1, activation='sigmoid'))У нас используются 3 свёрточных слоя:
- Исходное изображение размером 64x64x3 обрабатывается 16-ю фильтрами, что даёт (после применения
AveragePooling2Dдля понижения размерности) тензор 32x32x16. - На следующем шаге тензор 32x32x16 превращается в 16x16x32
- После финального свёрточного слоя мы получаем размерность 8x8x64.
Наконец, поверх свёрточной базы мы размещаем обычный классификатор в виде логистической регрессии (иными словами — Dense слой из одного нейрона).
Архитектура генератора
Генератор устроен чуть более сложно. Для начала, представим, что мы хотим преобразовать изображение во внутреннее представление — вектор размерности latent_dim=100. Для этого мы стали бы использовать свёрточную сеть примерно такой же архитектуры, как описанный выше дискриминатор, только размерность последнего полносвязного слоя была бы 100..
Генератор решает обратную задачу — преобразует вектор размерности 100 в изображение. Для этого используется процесс под названием обратная свёртка. Вместе со слоями повышения размерности UpSampling2D они применяются для перехода ко всё большей размерности на следующем слое, вместе с уменьшением числа фильтров:
generator = Sequential()
generator.add(Dense(8 * 8 * 2 * size, activation="relu",
input_dim=latent_dim))
generator.add(Reshape((8, 8, 2 * size)))
for x in [64;32;16]:
generator.add(UpSampling2D())
generator.add(Conv2D(x, kernel_size=(3,3),strides=1,padding="same"))
generator.add(BatchNormalization(momentum=0.8))
generator.add(Activation("relu"))
generator.add(Conv2D(3, kernel_size=3, padding="same"))
generator.add(Activation("tanh"))На последнем слое мы получаем тензор размерности 64x64x3, что по размерности соответствует нашему изображению. Используемая функция активации tanh даёт нам выходной сигнал в диапазоне [-1;1] — а это означает, что входные изображения нам тоже необходимо привести к этому интервалу. Все шаги по подготовке данных, включая масштабирование и приведение в требуемому диапазону, выполняет класс ImageDataset, на котором я не буду подробно останавливаться.
Обучающий скрипт для Azure ML
Теперь когда все фрагменты генеративно-состязательной сети собраны, нам надо подготовить обучающий скрипт и запустить его на Azure ML в виде эксперимента!
Есть, однако, одна важная деталь. При запуске экспериментов на Azure ML мы обычно отслеживаем некоторые числовые метрики, типа точности (accuracy) и значения функции потерь (loss). Мы логируем эти значения во время эксперимента вызывая run.log, как описано в моей заметке, и затем можем наблюдать за ними на портале Azure ML.
В нашем случае числовые метрики имеют мало смысла, и вместо этого нам интересно отслеживать изображения, которые наша сеть (а точнее генератор) может генерировать на каждой эпохе обучения. Визуально оценивая эти изображения мы можем принять решение, стоит ли досрочно прервать эксперимент, т.к. что-то пошло не так и обучение зашло в тупик, или надо продолжать обучение.
К счастью, Azure ML поддерживает логирование изображений, и это описано в документации. Для этого используется функция log_image, в качестве аргумента которой может быть изображение в виде numpy-массива, или же график, построенный с помощью matplotlib. В нашем примере мы используем последний вариант, и передадим график, содержащий три сгенерированных сетью изображения. За процесс логирования отвечает функция callbk, которая вызывается обучающим циклом keragan после каждой эпохи:
def callbk(tr):
if tr.gan.epoch % 20 == 0:
res = tr.gan.sample_images(n=3)
fig,ax = plt.subplots(1,len(res))
for i,v in enumerate(res):
ax[i].imshow(v[0])
run.log_image("Sample",plot=plt)Сам по себе обучающий код выглядит так:
gan = keragan.DCGAN(args)
imsrc = keragan.ImageDataset(args)
imsrc.load()
train = keragan.GANTrainer(image_dataset=imsrc,gan=gan,args=args)
train.train(callbk)Код получился компактный, поскольку keragan поддерживает автоматический парсинг большинства параметров командной строки, и нам достаточно передать в конструкторы структуру args, чтобы заполнить такие параметры, как количество эпох, размерность изображений, learning rate и т.д.
Запускаем эксперимент
Для запуска эксперимента на Azure ML мы можем воспользоваться либо VS Code, как описано тут, либо программным SDK, как описано в прошлом посте про Azure ML. Соответствующий код находится в файле submit_gan.ipynb, и он начинается с привычного кода:
- Поключаемся к рабочей области:
ws = Workspace.from_config() - Подключаемся к вычислительному кластеру:
cluster = ComputeTarget(workspace=ws, name='My Cluster'). Для нашего примера понадобятся машины с GPU, такие как [NC6][AzureVMNC]. - Загружаем набор картинок в хранилище данных по умолчанию для нашей рабочей области:
ds.upload(...).
После того, как предварительные шаги выполнены, мы запускаем эксперимент:
exp = Experiment(workspace=ws, name='KeraGAN')
script_params = {
'--path': ws.get_default_datastore(),
'--dataset' : 'faces',
'--model_path' : './outputs/models',
'--samples_path' : './outputs/samples',
'--batch_size' : 32,
'--size' : 512,
'--learning_rate': 0.0001,
'--epochs' : 10000
}
est = TensorFlow(source_directory='.',
script_params=script_params,
compute_target=cluster,
entry_script='train_gan.py',
use_gpu = True,
conda_packages=['keras','tensorflow','opencv','tqdm','matplotlib'],
pip_packages=['git+https://github.com/shwars/keragan@v0.0.1']
run = exp.submit(est)Нам необходимо передать параметры model_path=./outputs/models и samples_path=./outputs/samples, чтобы записать результаты обучения (примеры изображений и модели) в поддиректории каталога outputs. Всё содержимое этой директории сохраняется в истории эксперимента, и ко всем файлам можно будет потом получить доступ программно, или визуально через портал Azure ML.
Для создания объекта Estimator, который без проблем будет работать на GPU, мы используем класс Tensorflow. Он очень похож на стандартный класс Estimator, но также "из коробки" поддерживает некоторые опции распределённого обучения. Подробнее про использование различных Estimator-ов можно прочитать в официальной документации.
Ещё один интересный момент — это то, как мы устанавливаем библиотеку keragan непосредственно из исходников на GitHub. Можно безусловно устанавливать её из репозитория PyPI как стадартный pip-пакет, но я хотел показать, что установка исходников из GitHub также поддерживается, с возможностью указать конкретный тэг или commit ID. При создании этого примера мне удобнее было каждый раз подтягивать свежую версию библиотеки прямо из репозитория, без необходимости перевыпускать новую версию на PyPI.
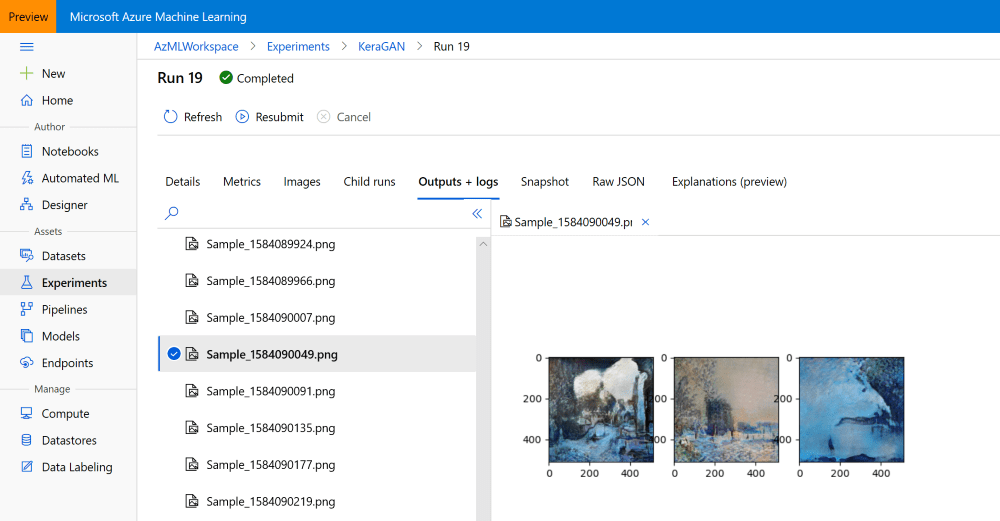
Когда мы успешно запустим эксперимент и немного подождем, мы должны увидеть сгенерированные образцы изображений на страничке нашего эксперимента в Azure ML Portal:
Запускаем много экспериментов
После первого запуска обучения GAN мы можем получить не слишком хороший результат, по нескольким причинам. Во-первых, важное значение играет learning rate: слишком большое значение может привести к плачевным результатам, а слишком маленькое — к очень длительному обучению. Для подбора оптимальных гиперпараметров нам возможно придётся запустить несколько экспериментов.
Имеет смысл поэкспериментировать со следующими параметрами:
--sizeопределяет размер картинки, и он должен быть степенью двойки. Небольшие размеры (64 или 128) позволяют проводить относительно быстрые эксперименты, в то время как размер побольше (до 1024) позволяют получить более детализированное изображение. Всё что больше 1024 скорее всего не даст хороших результатов, и для этого обычно используют специальные приёмы, например progressive growing--learning_rateприобретает особо важное значение на высоких разрешениях. Меньшее значение даёт лучшие результаты, но ценой роста времени на обучение.--dateset. Мы можем загрузить картинки, соответствующие различным стилям, в различные папки в Azure ML datastore, и запустить на обучение сразу несколько параллельных экспериментов.
Поскольку мы уже умеем запускать эксперименты программно, должно быть несложно обернуть код для запуска в один или несколько циклов for, для перебора возможных параметров. Затем можно вручную проверить на портале какие эксперименты дают плохие результаты, и остановить их для снижения расходов. Использование кластера из нескольких виртуалок позволяет нам запустить сразу несколько экспериментов.
Получаем результаты эксперимента
После получения достаточно симпатичных изображений, вы скорее всего заходите использовать созданные картинки, либо загрузить обученные файлы моделей. В ходе обучения наш скрипт сохраняет модели в папку outputs/models, а сгенерированные примеры изображений — в outputs/samples. Содержимое этих папок можно посмотреть и загрузить через Azure ML Portal вручную:
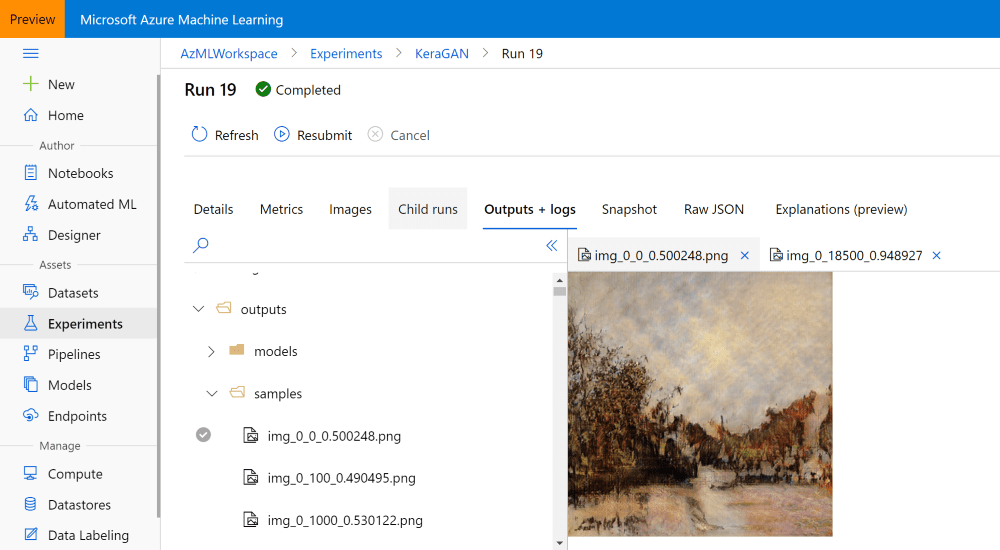
Можно также сделать это программно, особенно если вы хотите скачать все изображения, сгенерированные на всех эпохах обучения. Переменная run, полученная в процессе запуска эксперимента, даёт нам доступ ко всем файлам, сохранённым вместе с экспериментом (а точнее с данным конкретным запуском эксперимента):
run.download_files(prefix='outputs/samples')Такая команда создаст в текущей директории папку outputs/samples, и скачает туда все файлы из удалённой директории с тем же именем.
Если значение переменной run потерялось или изменилось (это часто случается, поскольку большинство экспериментов выполняются долго), вы можете всегда восстановить его, зная run id, который в свою очередь можно посмотреть на портале:
run = Run(experiment=exp,run_id='KeraGAN_1584082108_356cf603')Также имеет смысл скачать сами модели. Например, давайте скачаем финальную модель генератора, которая может быть использована для генерации новых и новых художественных шедевров. Для этого получим список всех связанных с экспериментом файлов, и отфильтруем названия моделей генератора (они начинаются с gen_):
fnames = run.get_file_names()
fnames = filter(lambda x : x.startswith('outputs/models/gen_'),fnames)Эти имен будут иметь такой вид: outputs/models/gen_0.h5, outputs/models/gen_100.h5 и т.д. Найдём максимальный номер эпохи и скачаем файл с соответствующим именем:
no = max(map(lambda x: int(x[19:x.find('.')]), fnames))
fname = 'outputs/models/gen_{}.h5'.format(no)
fname_wout_path = fname[fname.rfind('/')+1:]
run.download_file(fname)При этом файл модели скачается в текущую директорию, и имя файла останется в переменной fname_wout_path.
Генерируем новые изображения
Получив модель, мы можем просто загрузить её в Keras, извлечь из неё размерность входного вектора, после чего, подавая на вход случайные вектора нужной размерности, генерировать изображения в нужном количестве:
model = keras.models.load_model(fname_wout_path)
latent_dim=model.layers[0].input.shape[1].value
res = model.predict(np.random.normal(0,1,(10,latent_dim)))Напомню, что выход генератора находится в диапазоне [-1,1], и его необходимо привести к диапазону [0,1], чтобы корректно отобразить результат в matplotlib:
res = (res+1.0)/2
fig,ax = plt.subplots(1,10,figsize=(15,10))
for i in range(10):
ax[i].imshow(res[i])Вот пример результата работы сети:

А вот несколько лучших картинок, сгенерированных такой сетью:
 |
 |
|---|---|
| Colourful Spring, 2020 | Countryside, 2020 |
 |
 |
| Through the Icy Glass, 2020 | Summer Landscape, 2020 |
Чтобы каждый (или почти каждый) день получать свежие картины, нарисованные нейросетью — подпишитесь на инстаграм @art_of_artificial, который мы специально для этого создали с моей дочерью.
Процесс обучения сети
Также очень интересно посмотреть на то, как генеративно-состязательная сеть постепенно учится. Я исследовал процесс того, как сеть учится рисовать, в моей серии экспонатов искусство искусственного. Вот пара видео, которые демонстрируют процесс в динамике:
Пища для размышлений
В этой заметке я кратко описал принципы работы генеративно-состязательных сетей, и как можно обучать такие сети в службе машинного обучения Azure. Это открывает много возможностей для экспериментов, но также и даёт пищу для рамышлений. В процессе экспериментов, мы — а точнее искусственный интеллект — создали оригинальные художественные работы. Можно ли считать их искусством? Об этом я поговорю в одном из своих следующих постов...
Благодарности
При создании библиотеки keragan, я во многом вдохновлялся этой статьёй, а также реализацией DCGAN, сделанной Maxime Ellerbach, а также проектом GANGogh. Много различных архитектур GAN на базе Keras также приведены здесь.
Другие заметки из серии про Azure ML
- Лучший способ начать использовать Azure ML
- Используем Azure ML для оптимизации гиперпараметров
- Тренируем генеративно-состязательную сеть для рисования картин на Azure ML (этот пост)
ChePeter
Любая картина, это некая эмоция, выраженная цветом, формой. Это некая мысль, может страсть художника, которой он вызывает в нас наши эмоции, а не набор мазков на холсте.
Выражение «Картина искусственного интеллекта», на мой взгляд, сродни выражению «Любовь резиновой женщины».
Atreides07
Не совсем. Взять те же книги. Книга выражает некую мысль, страсть автора. Книга вызывает эмоции. Тем не менее книги выпускаются огромным тиражом. И ценность от этого не падает. Ценность картин определяется оригинальностью картины, даже если отличить копию от оригинала можно только радиоуглеродным анализом. Копия, по какой то причине, выражает огромное количество эмоций пока покупатель не обнаружит что это копия. Т.е. ценность картины сугуба субъективна и эмоции вызывает, к примеру, в зависимости от того знаем ли мы что это копия или оригинал. Что же касается картины искусственного интеллекта, то это по сути такой же холст, такие же кисти конкретного автора. Здесь автором является Дмитрий, а картина — результат который автор выразил с помощью инструмента. Чем ЭТА картина отличается от тех же фотографий который делались целый день с определенным интервалом, а потом выбирались самые удачные кадры и вешались на всяких галерееях?
shwars Автор
Какая прекрасная дискуссия! Я специально в этой статье достаточно грубо написал про "картины, нарисованные ИИ", не вдаваясь в подробности. В ближайшее время напишу отдельный пост про то, насколько можно считать это искусством, где как раз отвечу на соображения про резиновую женщину и про интервальное фото!
igordata
вот это очень интересно было бы почитать, т.к. фантазия у ИИ уже появилась, а ценность — ещё почему-то нет
shwars Автор
Мне почему-то кажется как раз наоборот :) Обсудим скоро!
Thoth777
Из всех сгенеренных картин, создатель сети может выбрать то, что нравится ему.
Это будет его вкладом, если из 100500 картин он выставит 2-3, которые что-то зацепили в нем.