
Я знаю многих Data Scientist-ов — да и пожалуй сам к ним отношусь — которые работают на машинах с GPU, локальных или виртуальных, расположенных в облаке, либо через Jupyter Notebook, либо через какую-то среду разработки Python. Работая в течение 2 лет экспертом-разработчиком по AI/ML я делал именно так, при этом подготавливал данные на обычном сервере или рабочей станции, а запускал обучение на виртуалке с GPU в Azure.
Конечно, мы все слышали про Azure Machine Learning — специальную облачную платформу для машинного обучения. Однако после первого же взгляда на вводные статьи, создаётся впечатление, что Azure ML создаст вам больше проблем, чем решит. Например, в упомянутом выше обучающем примере обучение на Azure ML запускается из Jupyter Notebook, при этом сам обучающий скрипт предлагается создавать и редактировать как текстовый файл в одной из ячеек — при этом не используя автодополнение, подсветку синтаксиса и другие преимущества нормальной среды разработки. По этой причине мы долгое время всерьез не использовали Azure ML в своей работе.
Однако недавно я обнаружил способ, как начать эффективно использовать Azure ML в своей работе! Интересны подробности?

Основной секрет — это расширение Visual Studio Code для Azure ML. Оно позволяет вам разрабатывать обучающие скрипты прямо в VS Code, используя все преимущества среды — при этом вы можете даже запускать скрипт локально, а затем просто взять и отправить его на обучение в кластере Azure ML несколькими щелчками мыши. Удобно, не правда ли?
При этом вы получаете следующие преимущества от использования Azure ML:
- Можно работать большую часть времени локально на своей машине в удобном IDE, и использовать GPU только для обучения модели. При этом пул обучающих ресурсов может автоматически подстраиваться под требуемую нагрузку, и установив минимальное количество узлов в 0 вы сможете автоматически запускать виртуалку "по требованию" при наличии обучающих заданий.
- Вы можете хранить все результаты обучения в одном месте, включая достигнутые метрики и полученные модели — нет необходимости самому придумывать какую-то систему или порядок для хранения всех результатов.
- При этом над одним проектом могут работать несколько человек — они могут использовать один и тот же вычислительный кластер, все эксперименты будут при этом выстраиваться в очередь, а также они могут видеть результаты экспериментов друг друга. Одним из таких сценариев является использование Azure ML в преподавании Deep Learning, когда вместо того, чтобы давать каждому студенту виртуальную машину с GPU, вы можете создать один кластер, который будет использоваться всеми централизованно. Кроме того, общая таблица результатов с точностью модели может служить хорошим соревновательным элементом.
- С помощью Azure ML можно легко проводить серии экспериментов, например, для оптимизации гиперпараметров — это можно делать несколькими строчками кода, нет необходимости проводить серии экспериментов вручную.
Надеюсь, я убедил вас попробовать Azure ML! Вот как можно начать:
- Убедитесь, что у вас установлена Visual Studio Code, а также расширения Azure Sign In и Azure ML
- Клонируйте репозиторий https://github.com/CloudAdvocacy/AzureMLStarter — он содержит некоторый демонстрационный код для тренировки модели распознавания рукописных цифр на датасете MNIST.
- Откройте клонированный репозиторий в Visual Studio Code.
- Читайте дальше!
Azure ML Workspace и Azure ML Portal
Azure ML организован вокруг концепции рабочей области — Workspace. В рабочей области могут храниться данные, в неё отправляют эксперименты для обучения, там же хранятся результаты обучения — полученные метрики и модели. Посмотреть, что находится внутри рабочей области, можно через портал Azure ML — и оттуда же можно совершать множество операций, начиная от загрузки данных и заканчивая мониторингом экспериментов и развертыванием моделей.
Создать рабочую область можно через веб-интерфейс Azure Portal (см. пошаговые инструкции), или с использованием командной строки Azure CLI (инструкции):
az extension add -n azure-cli-ml
az group create -n myazml -l northeurope
az ml workspace create -w myworkspace -g myazmlС рабочей областью связаны также некоторые вычислительные ресурсы (Compute). Создав скрипт для обучения модели, вы можете послать эксперимент на выполнение в рабочую область, и указать compute target — при этом скрипт будет упакован, запущен в нужной вычислительной среде, а затем все результаты эксперимента будут сохранены в рабочей области для дальнейшего анализа и использования.
Обучающий скрипт для MNIST
Рассмотрим классическую задачу распознавания рукописных цифр с использованием набора данных MNIST. Аналогично в дальнейшем вы сможете выполнять любые свои обучающие скрипты.
В нашем репозитории есть скрипт train_local.py, который обучаем простейшую модель линейной регрессии с использованием библиотеки SkLearn. Конечно, я понимаю, что это не самый лучший способ решить задачу — мы используем его для примера, как самый простой.
Скрипт сначала скачивает данные MNIST из OpenML, а затем использует класс LogisticRegression для обучения модели, и затем печатает полученную точность:
mnist = fetch_openml('mnist_784')
mnist['target'] = np.array([int(x) for x in mnist['target']])
shuffle_index = np.random.permutation(len(mist['data']))
X, y = mnist['data'][shuffle_index], mnist['target'][shuffle_index]
X_train, X_test, y_train, y_test =
train_test_split(X, y, test_size = 0.3, random_state = 42)
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_hat = lr.predict(X_test)
acc = np.average(np.int32(y_hat == y_test))
print('Overall accuracy:', acc)Вы можете запустить скрипт на своём компьютере и через пару секунд получите результат.
Запускаем скрипт в Azure ML
Если же мы будем запускать скрипт на обучение через Azure ML, у нас будет два основных преимущества:
- Запуск обучения на произвольном вычислительном ресурсе, который, как правило, более производительный, чем локальный компьютер. При этом Azure ML сам позаботится о том, чтобы упаковать наш скрипт со всеми файлами из текущей директории в docker-контейнер, установить требуемые зависимости, и отправить его на выполнение.
- Запись результатов в единый реестр внутри рабочей области Azure ML. Чтобы воспользоваться этой возможностью, нам нужно добавить пару строчек кода к нашему скрипту для записи результирующей точности:
from azureml.core.run import Run
...
try:
run = Run.get_submitted_run()
run.log('accuracy', acc)
except:
passСоответствующая версия скрипта называется train_universal.py (она чуть более хитро устроена, чем написано выше, но не сильно). Этот скрипт можно запускать как локально, так и на удалённом вычислительном ресурсе.
Чтобы запустить его в Azure ML из VS Code, надо проделать следующее:
Убедитесь, что Azure Extension подключено к вашей подписке. Выберите иконку Azure в меню слева. Если вы не подключены, в правом нижнем углу появится уведомление (вот такое), нажав на которое вы сможете войти через браузер. Можно также нажать Ctrl-Shift-P для вызова командной строки VS Code, и набрать Azure Sign In.
После этого, в разделе Azure (иконка слева) найдите секцию MACHINE LEARNING:
Здесь вы должны видеть разные группы объектов внутри рабочей области: вычислительные ресурсы, эксперименты и т.д.
- Перейдите к списку файлов, нажмите правой кнопкой на скрипте
train_universal.pyи выберите Azure ML: Run as experiment in Azure.
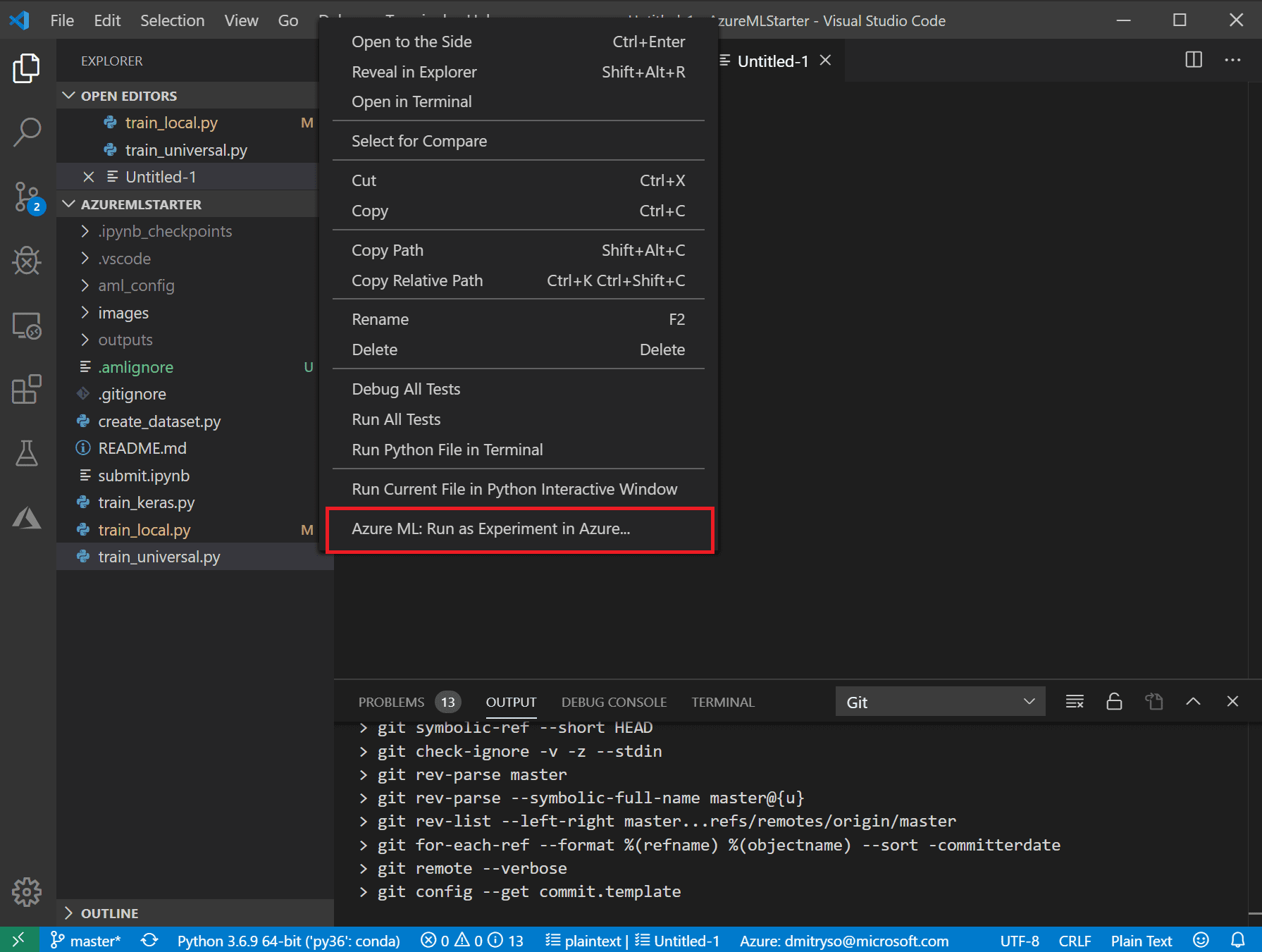
- После этого последует серия диалогов в области командной строки VS Code: подтвердите используемую подписку и рабочую область Azure ML, а также выберите Create new experiment:



Выберите создание нового вычислительного ресурса Create New Compute:
- Compute определяет вычислительный ресурс, на котором будет происходить обучение. Вы можете выбрать локальный компьютер, или облачный кластер AmlCompute. Я рекомендую создать масштабируемый кластер машин
STANDARD_DS3_v2, с минимальным числом машин 0 (а максимальное может быть 1 или больше, в зависимости от ваших аппетитов). Это можно сделать через интерфейс VS Code, или предварительно через ML Portal.

- Compute определяет вычислительный ресурс, на котором будет происходить обучение. Вы можете выбрать локальный компьютер, или облачный кластер AmlCompute. Я рекомендую создать масштабируемый кластер машин
Далее необходимо выбрать конфигурацию Compute Configuration, которая определяет параметры создаваемого для обучения контейнера, в частности, все необходимые библиотеки. В нашем случае, поскольку мы используем Scikit Learn, выбираем SkLearn, и затем просто подтверждаем предложенный список библиотек нажатием Enter. Если вы используете какие-то дополнительные библиотеки — их необходимо здесь указать.
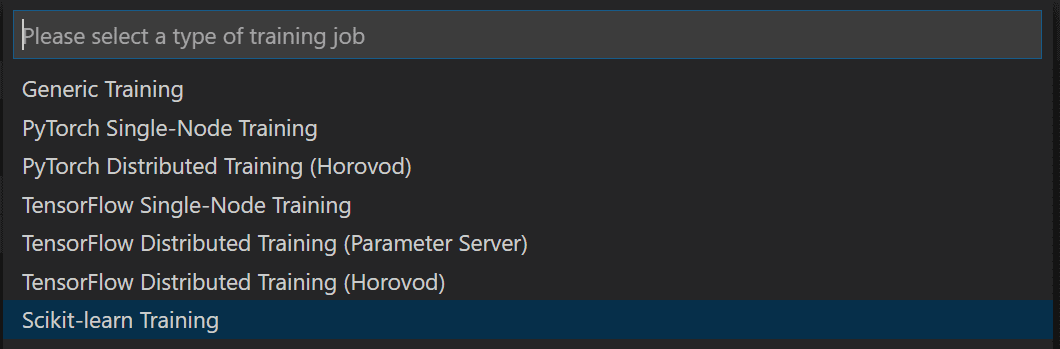

После этого откроется окно с JSON-файлом, описывающим эксперимент. В нём можно исправить некоторые параметры — например, имя эксперимента. После этого нажмите на ссылку Submit Experiment прямо внутри этого файла:
- После успешной подачи эксперимента через VS Code, справа в области уведомлений вы увидите ссылку на Azure ML Portal, на которой сможете отслеживать статус и результаты эксперимента.
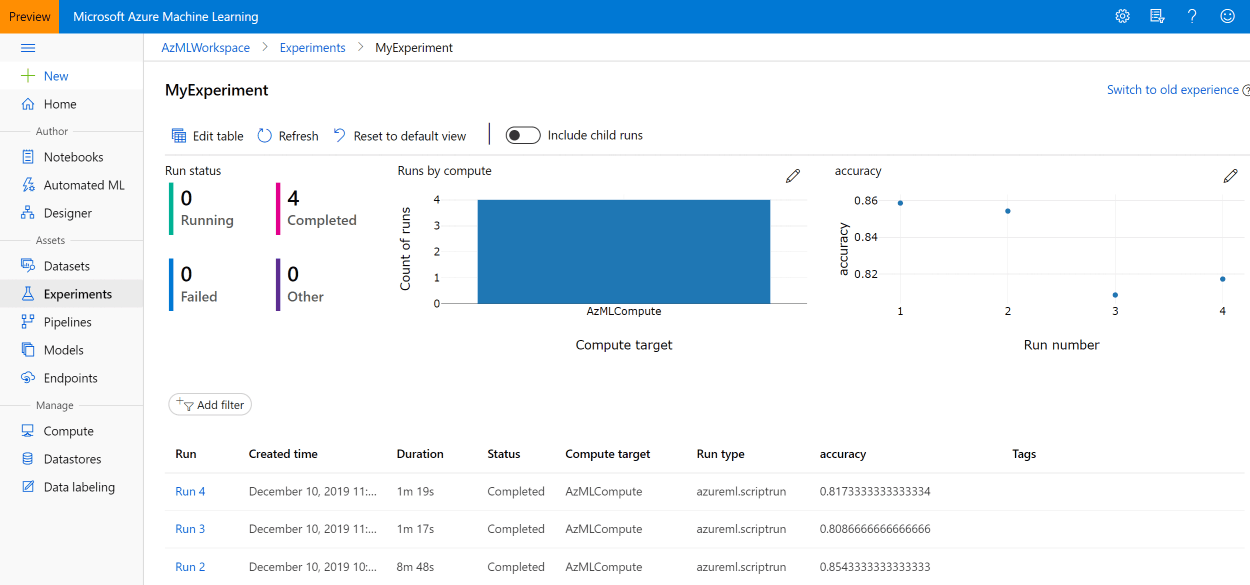
Впоследствии вы всегда сможете найти его в разделе Experiments Azure ML Portal, или в разделе Azure Machine Learning в списке экспериментов:
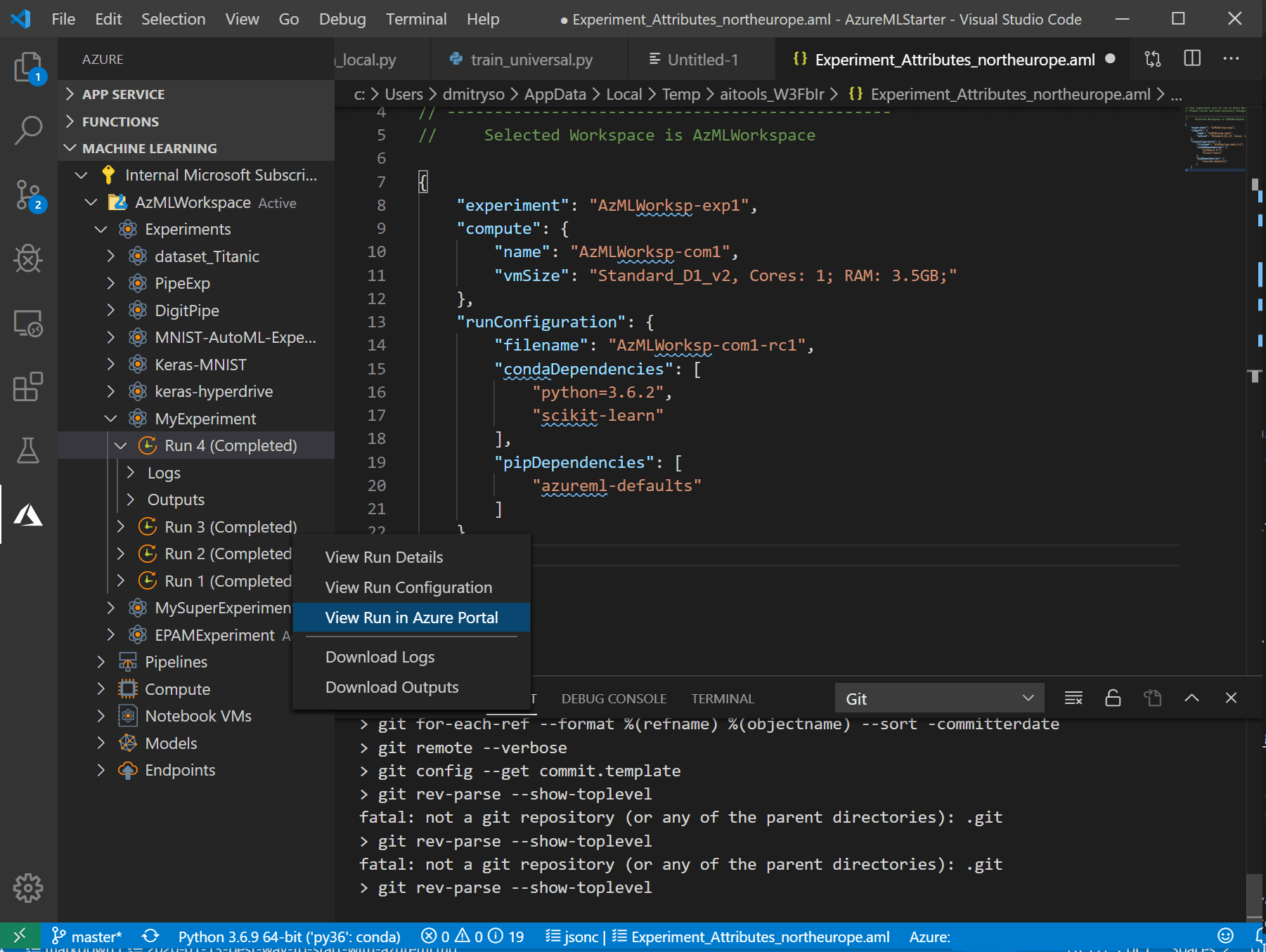
- Если вы после этого внесли в код какие-то исправления или изменили параметры — повторный запуск эксперимента будет намного быстрее и проще. Нажав правой кнопкой на файл, вы увидите новый пункт меню Repeat last run — просто выберите его, и эксперимент будет сразу же запущен:
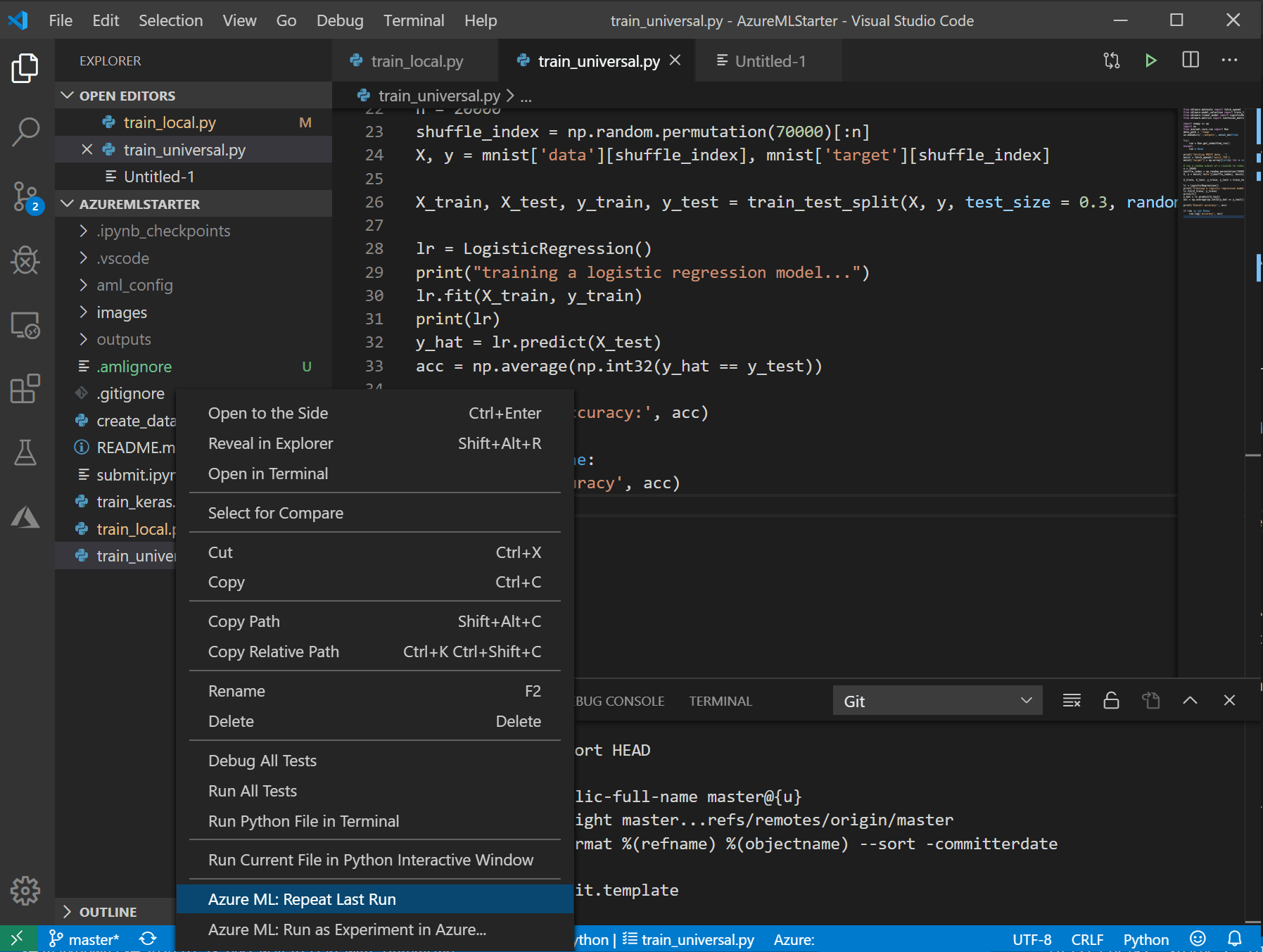
Результаты метрик от всех запусков вы всегда сможете найти на Azure ML Portal, нет необходимости их записывать.
Теперь вы знаете, что запускать эксперименты с помощью Azure ML — это просто и безболезненно, и при этом вы получаете ряд приятных преимуществ.
Но вы могли заметить и недостатки. Например, для запуска скрипта потребовалось существенно больше времени. Конечно, для упаковки скрипта в контейнер и разворачивания его на сервере требуется время. Если при этом кластер был урезан до размера в 0 узлов — потребуется ещё больше времени для запуска виртуальной машины, и всё это очень заметно, когда мы экспериментируем на простых задачах типа MNIST, которые решаются за несколько секунд. Однако, в реальной жизни, когда обучение длится несколько часов, а то и дней или недель, это дополнительное время становится несущественным, особенно на фоне сильно более высокой производительности, которую может дать вычислительный кластер.
Что дальше?
Я надеюсь, что после прочтения этой статьи вы сможете и будете использовать Azure ML в своей работе для запуска скриптов, управления вычислительными ресурсами и централизованного хранения результатов. Однако Azure ML может предоставить вам ещё больше преимуществ!
Внутри рабочей области можно хранить данные, тем самым создавая централизованное хранилище для всех своих задач, к которому легко обращаться. Кроме того, вы можете запускать эксперименты не из Visual Studio Code, а с использованием API — это может быть особенно полезно, если вам нужно совершить оптимизацию гиперпараметров, и нужно запустить скрипт много раз с разными параметрами. Более того, в Azure ML встроена специальная технология Hyperdrive, которая позволяет делать более хитрый поиск и оптимизацию гиперпараметров. Об этих возможностях я расскажу в своей следующей заметке.
Полезные ресурсы
Для более подробного изучения Azure ML, вам могут пригодиться следующие курсы Microsoft Learn:

{kind=link}
CrazyElf
Как-то не очень питоняче, лучше было бы так:
А ещё лучше так:
shwars Автор
Спасибо, последний вариант мне прямо очень нравится!