
В такой области глубокого обучения, как обработка изображений, библиотека Keras играет ключевую роль, радикально упрощая обучение transfer learning и использование предварительно обученных моделей. В области обработки естественного языка (NLP) для решения достаточно сложных задач, таких как ответы на вопросы или классификация намерений, приходится комбинировать серию моделей. В этой статье мы расскажем, как библиотека DeepPavlov упрощает построение цепочек моделей для NLP. На основе DeepPavlov и с помощью Azure ML мы построим вопросно-ответную нейросеть, обученную на наборе данных COVID-19.

За последние пару лет мы стали свидетелями значительного прогресса во многих задачах, связанных с обработкой естественного языка, в основном благодаря новым архитектурам, таким как трансформеры и BERT. BERT, например, может эффективно использоваться в задачах классификации текста, извлечения именованных сущностей, контекстного прогнозирования маскированных слов и ответов на вопросы.
Обучение модели BERT с нуля очень ресурсоемко, поэтому большинство приложений используют предварительно обученные модели, применяют BERT в качестве извлекателей признаков или для более тонкого дообучения. Часто бывает так, что исходная задача обработки естественного языка, которую мы решаем, может быть разложена на последовательность из более простых шагов, один из которых — извлечение признаков, другой — токенизация, применение TF-IDF ранжирования к набору документов или (на последнем этапе) обычная классификация.
Эту последовательность можно рассматривать как конвейер, каждый этап в котором реализуется различными нейросетевыми моделями. Взяв за пример задачу классификации текста, мы можем выделить следующие этапы:
- препроцессор BERT, который извлекает признаки
- классификатор, который определяет класс документа
Эта серия шагов может быть объединена в одну нейронную архитектуру и обучена на наборе текстовых данных.
Библиотека DeepPavlov
DeepPavlov как раз позволяет строить и обучать такие конвейеры нейросетевых моделей. Её стоит использовать по ряду причин:
- поставляется с предварительно обученными моделями;
- позволяет декларативно описывать конвейер обработки текста как последовательность шагов, используя config-файлы;
- предоставляет ряд предопределенных конфигов, которые можно использовать для решения типовых задач;
- можно выполнять обучение конвейера и применять его посредством Python SDK или из интерфейса командной строки.
Библиотека поддерживает несколько способов взаимодействия с NLP моделями. Существует возможность запускать ее в режиме REST API или в качестве коннектора для Microsoft Bot Framework. В этой статье мы сосредоточимся на основной функциональности, которая делает библиотеку DeepPavlov столь же полезной для обработки естественного языка, как Keras для обработки изображений.
Познакомиться с основной функциональностью DeepPavlov проще всего с помощью веб-демонстрации на demo.deeppavlov.ai.
BERT классификация с использованием DeepPavlov
Вернемся к задаче классификации текста с использованием BERT. DeepPavlov содержит несколько предобученных конфигураций для этой задачи, например, классификация настроений в Twitter. В этом файле раздел chainer описывает конвейер, который состоит из следующих шагов:
simple_vocabиспользуется для преобразования ожидаемого вывода (y), который является именем класса, в числовой идентификатор (y_ids);transformers_bert_preprocessorпринимает входной текстxи выдает набор данных для последующей сети BERT;transformers_bert_embedderсоздает BERT-эмбеддинги для входного текстаone_hotterкодируетy_idsв one-hot encoding, необходимое для финального слоя классификатора;keras_classification_model— модель классификации, представляющая собой многослойную CNN с определенными параметрами;proba2labels— финальный слой, преобразующий выходные данные сети в соответствующую метку.
В конфигурации также определяются:
- в разделе
dataset_reader— описание формата и пути к входным данным; - в разделе
train— параметры обучения; - а также некоторый другие характеристики.
Определив конфигурацию, мы можем обучить соответствующий конвейер из командной строки следующим образом:
python -m deeppavlov install sentiment_twitter_bert_emb.json
python -m deeppavlov download sentiment_twitter_bert_emb.json
python -m deeppavlov train sentiment_twitter_bert_emb.jsonКоманда install устанавливает все необходимые зависимости (например, Keras, transformers и т.д.), download скачивает все необходимые файлы предварительно обученных моделей, а последняя строка непосредственно выполняет обучение.
Как только модель обучилась, мы можем взаимодействовать с ней с помощью командной строки:
python -m deeppavlov interact sentiment_twitter_bert_emb.jsonТакже можно использовать обученную модель с помощью Python SDK:
model = build_model(configs.classifiers.sentiment_twitter_bert_emb)
result = model(["This is input tweet that I want to analyze"])Ответы на вопросы на открытом домене: ODQA
Одна из наиболее интересных задач, которую можно реализовать с помощью архитектуры BERT, называется Ответы на вопросы на открытом домене или, если коротко, ODQA (Open Domain Question Answering). ODQA в идеале должен давать конкретные ответы на общие вопросы по большому объему текстового материала, наподобие Wikipedia. Основная проблема связана с тем, что мы ссылаемся не на один единственный документ, а на очень обширную область знаний. Сеть BERT же способна генерировать ответы по достаточно коротким документам.
Для решения этой проблемы, ODQA чаще всего работает в два этапа:
- сначала отдельная модель пытается найти наиболее подходящий к запросу документ из коллекции, т.е. решается задача поиска;
- затем найденный документ обрабатывается с помощью BERT-модели, чтобы получить конкретный ответ из него — решается задача машинного понимания.
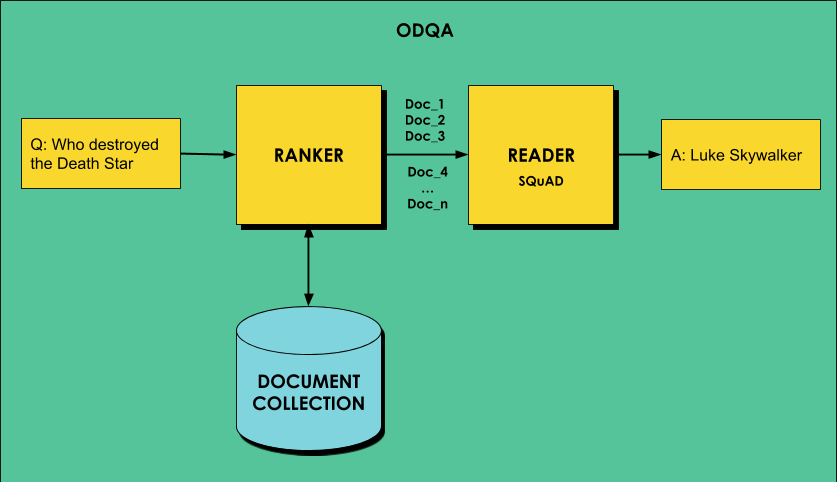
Подробное руководство по реализации ODQA с помощью DeepPavlov содержится в блоге, однако для реализации второго этапа в описанном примере используется R-NET, а не BERT. Как мы увидим, это не даёт достаточно хороших результатов, поэтому в этой заметке мы опишем ODQA на основе BERT. В качестве "подопытного" датасета будем использовать COVID-19 OpenResearch Dataset, который содержит более 52 000 научных статей по COVID-19. Это позволит нам построить нейросетевую модель, которая умеет отвечать на вопросы про коронавирус.
Получение данных с помощью Azure ML
Для обучения мы будем использовать Azure Machine Learning, в частности имеющиеся в её составе Notebooks. Самый простой способ получить данные в AzureML — создать Dataset. Все доступные в исходном датасете данные по COVID-19 можно найти на странице Semantic Scholar. Мы будем использовать некоммерческую выборку, расположенную здесь в виде упакованного набора JSON-документов.
Для начала определим Azure ML Dataset. Проще всего это сделать через Azure ML Portal, перейти в раздел Datasets и выбрать создание нового датасета from web files. В качестве типа выберем file, поскольку данные в нашем случае слабо структурированы. В случае файлов табличного формата мы могли бы выбрать tabular, и сразу получить табличное представление. В заключение создания датасета мы вводим URL, по которому набор находится в интернете.
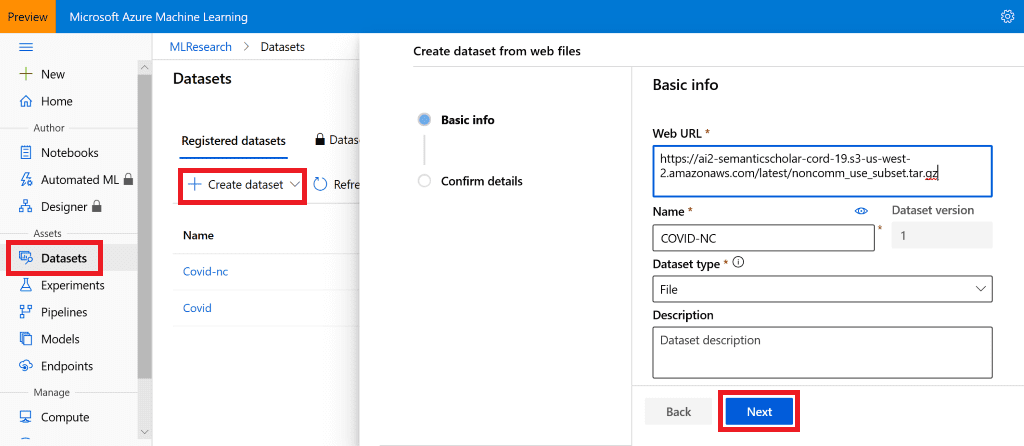
Файловый датасет, который мы определили, содержит в себе запакованные данные. Чтобы подготовить их к использованию, нам потребуется notebook и compute, на котором мы будем выполнять вычисления. Поскольку задача ODQA довольно затратна и требуется много памяти, мы сразу рекомендуем создать в Azure ML вычислительный узел на основе виртуальной машины типа NC12 с 112 Гб оперативной памяти. Процесс создания вычислительного ресурса и ноутбука описан здесь.
Для доступа к датасету нам потребуется следующий код:
from azureml.core import Workspace, Dataset
workspace = Workspace.from_config()
dataset = Dataset.get_by_name(workspace, name='COVID-NC')Датасет содержит один сжатый файл .tar.gz. Чтобы распаковать его, мы смонтируем датасет как каталог и выполним команду UNIX:
mnt_ctx = dataset.mount('data')
mnt_ctx.start()
!tar -xvzf ./data/noncomm_use_subset.tar.gz
mnt_ctx.stop()Теперь все данные распакованы в наше текущее хранилище. Весь текст содержится в каталоге noncomm_use_subset в виде файлов.json, которые содержат абстракт и полный текст статьи в полях abstract иbody_text. Чтобы извлечь только текст в отдельный файл, исполним следующий несложный Python-код:
from os.path import basename
def get_text(s):
return ' '.join([x['text'] for x in s])
os.makedirs('text',exist_ok=True)
for fn in glob.glob('noncomm_use_subset/pdf_json/*'):
with open(fn) as f:
x = json.load(f)
nfn = os.path.join('text',basename(fn).replace('.json','.txt'))
with open(nfn,'w') as f:
f.write(get_text(x['abstract']))
f.write(get_text(x['body_text']))Теперь мы имеем каталог с именем text, содержащий все статьи в текстовом виде. Избавимся от оригинального каталога:
!rm -fr noncomm_use_subsetНастройка модели ODQA
Прежде всего, давайте настроим предварительно обученную модель ODQA от DeepPavlov. Загрузим конфигурацию с именем en_odqa_infer_wiki:
import sys
!{sys.executable} -m pip --quiet install deeppavlov
!{sys.executable} -m deeppavlov install en_odqa_infer_wiki
!{sys.executable} -m deeppavlov download en_odqa_infer_wikiЗагрузка занимает довольно много времени. За это время вы поймете, как вам повезло, что вы используете облачные ресурсы, а не свой собственный компьютер. Загрузка в облако происходит намного быстрее!
Чтобы взаимодействовать с моделью, нам просто нужно построить модель из файла конфигурации и задать вопрос:
from deeppavlov import configs
from deeppavlov.core.commands.infer import build_model
odqa = build_model(configs.odqa.en_odqa_infer_wiki)
answers = odqa([ "Where did guinea pigs originate?",
"When did the Lynmouth floods happen?" ])В ответ мы получим:
['Andes of South America', '1804']В данном случае мы используем модель, обученную на тексте Wikipedia. Поэтому мы можем задавать достаточно общие вопросы, и можем попробовать спросить о коронавирусе:
- What is coronavirus? — a strain of a particular virus
- What is COVID-19? — nest on roofs or in church towers
- Where did COVID-19 originate? — northern coast of Appat
- When was the last pandemic? — 1968
Конечно, далеко от идеала… Эти ответы взяты из старого текста Википедии, на котором обучалась исходная модель, поэтому она ничего не знает про текущую эпидемию. Теперь наша задача — переучить модель на наших собственных данных.
Обучение модели на собственных данных
Нам необходимо обучить ранжирующую модель (ranker), чтобы она генерировала ссылки на правильные документы. Процесс обучения на собственных данных описан в блоге DeepPavlov. Поскольку модель ODQA использует модель en_ranker_tfidf_wiki, мы можем загрузить ее конфигурацию отдельно и заменить путьdata_path, который указывает на путь, где находятся файлы данных модели:
from deeppavlov.core.common.file import read_json
model_config = read_json(configs.doc_retrieval.en_ranker_tfidf_wiki)
model_config["dataset_reader"]["data_path"] = os.path.join(os.getcwd(),"text")
model_config["dataset_reader"]["dataset_format"] = "txt"
model_config["train"]["batch_size"] = 1000Мы также уменьшаем размер батча, иначе процесс обучения не поместится в памяти.
Теперь обучим модель и посмотрим, как она работает:
doc_retrieval = train_model(model_config)
doc_retrieval(['hydroxychloroquine'])Эта команда позволяет получить полный список файлов, которые имеют отношение к указанному ключевому слову.
Теперь запустим актуальную модель ODQA и посмотрим, как она работает:
# Download all the SQuAD models
squad = build_model(configs.squad.multi_squad_noans_infer, download = True)
# Do not download the ODQA models, we've just trained it
odqa = build_model(configs.odqa.en_odqa_infer_wiki, download = False)
odqa(["what is coronavirus?","is hydroxychloroquine suitable?"])В ответ мы получим:
['an imperfect gold standard for identifying King County influenza admissions',
'viral hepatitis']Все еще не идеально…
Использование BERT для Q&A
DeepPavlov имеет две предобученные модели для ответов на вопросы, обученные на Stanford Question AnsweringDataset (SQuAD): R-NET и BERT. В предыдущем примере использовалась модель с R-NET. Теперь мы переключим ее на BERT. Конфигурация squad_bert_infer является хорошей отправной точкой для построения вопрос-ответной модели на основе BERT:
!{sys.executable} -m deeppavlov install squad_bert_infer
bsquad = build_model(configs.squad.squad_bert_infer, download = True)Если посмотреть на файл конфигурации ODQA, то следующая его часть отвечает за ответы на вопросы:
{
"class_name": "logit_ranker",
"squad_model":
{"config_path": ".../multi_squad_noans_infer.json"},
"in": ["chunks","questions"],
"out": ["best_answer","best_answer_score"]
}Изначально используется модель, задаваемая конфигурационным файлом multi_squad_noans_infer. Чтобы изменить механизм ответа на вопрос в модели ODQA, необходимо просто заменить поле squad_model в конфигурации на squad_bert_infer:
odqa_config = read_json(configs.odqa.en_odqa_infer_wiki)
odqa_config['chainer']['pipe'][-1]['squad_model']['config_path'] =
'{CONFIGS_PATH}/squad/squad_bert_infer.json'Теперь попробуем взаимодействовать с моделью точно так же, как делали раньше:
odqa = build_model(odqa_config, download = False)
odqa(["what is coronavirus?",
"is hydroxychloroquine suitable?",
"which drugs should be used?"])Ниже приведены некоторые вопросы и ответы, полученные с помощью обновленной модели:
| Вопрос | Ответ |
|---|---|
| what is coronavirus? | respiratory tract infection |
| is hydroxychloroquine suitable? | well tolerated |
| which drugs should be used? | antibiotics, lactulose, probiotics |
| what is incubation period? | 3-5 days |
| is patient infectious during incubation period? | MERS is not contagious |
| how to contaminate virus? | helper-cell-based rescue system cells |
| what is coronavirus type? | enveloped single stranded RNA viruses |
| what are covid symptoms? | insomnia, poor appetite, fatigue, and attention deficit |
| what is reproductive number? | 5.2 |
| what is the lethality? | 10% |
| where did covid-19 originate? | uveal melanocytes |
| is antibiotics therapy effective? | less effective |
| what are effective drugs? | M2, neuraminidase, polymerase, attachment and signal-transduction inhibitors |
| what is effective against covid? | Neuraminidase inhibitors |
| is covid similar to sars? | All coronaviruses share a very similar organization in their functional and structural genes |
| what is covid similar to? | thrombogenesis |
Заключение
В этом посте мы описали, как использовать Azure Machine Learning вместе с NLP библиотекой DeepPavlov для создания вопросно-ответной системы. DeepPavlov можно использовать аналогичным образом для выполнения других задач на описанном датасете, например, для извлечения именованных сущностей, разбвки статьи на тематические блоки или для умной индексации статей. Мы рекомендуем ознакомиться с соревнованием COVID на Kaggle и посмотреть, сможете ли вы придумать оригинальную идею, которую можно реализовать с помощью DeepPavlov и Azure Machine Learning. И не забывайте, что у DeepPavlov есть форум – задавайте свои вопросы относительно библиотеки и моделей.
Azure ML и библиотека DeepPavlov помогли выполнить описанный эксперимент всего за несколько часов. Взяв этот пример за основу, вы сможете достигнуть существенно лучших результатов. Попробуйте и поделитесь своими идеями с сообществом. Data Science может делать удивительные вещи, тем более, когда над задачей работает не один человек, а целое сообщество!