
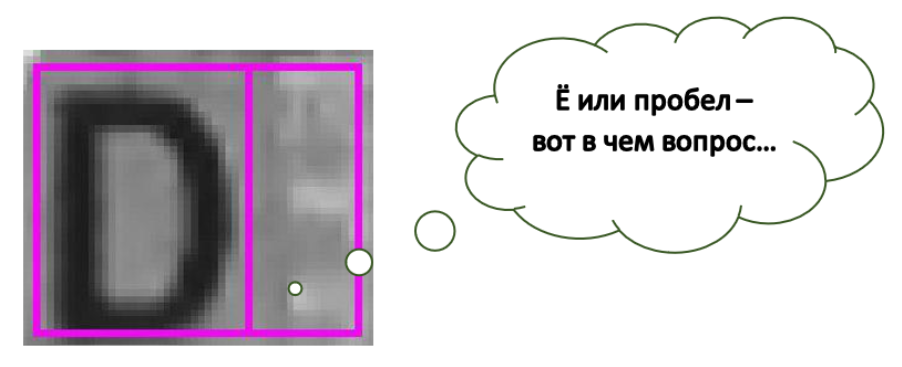
Всем привет! Как вы уже знаете, мы в SE занимаемся распознаванием текста (и не только) на разных документах. Сегодня мы хотели бы рассказать еще об одной проблеме при распознавании текста на сложных фонах — о распознавании пробелов. Вообще, мы будем говорить об имени на банковских картах, но для начала пример с «призраком» буквы Ё. Как видите, тут справа от D искажения и фон сформировали достаточно четкую Ё. При этом, если показать эту ячейку отдельно от всего остального, человек (или нейронная сеть) уверенно скажет, что буква есть.
Как видно на картинке — мы работаем на исходном изображении со сложными фонами, поэтому пробелы наши весьма разнообразны. На них бывают узоры, логотипы, а иногда и текст. Например, VISA или MAESTRO на карточках. И нам интересны именно такие «сложные пробелы», а не просто белые прямоугольники. А в своих системах мы рассматриваем именно отдельно вырезанные прямоугольники символов [1].
Пробел — это символ без особых признаков. На сложных фонах, например, как на изображении, отдельно вырезанный пробел бывает сложно отличить даже человеку.

С другой стороны, по своей сути пробел отличается от остальных символов. Если в имени вместо ASIA распознается ABIA, то есть шанс исправить это пост-обработкой. Но, если там возникнет A IA — вряд ли уже что-то поможет.
Часто пробелы фильтруют с помощью статистик, посчитанных по картинке. Например, считают среднее абсолютное значение градиента по картинке или дисперсию интенсивностей пикселей и по пороговому значению делят картинки на пробелы и буквы. Однако, как видно по графикам, такие методы не годятся для серых картинок со сложными фонами. А из-за явной корреляции значений даже комбинация этих методов не справится.

Всеми любимая бинаризация тут тоже не поможет. Например, вот на такой картинке:

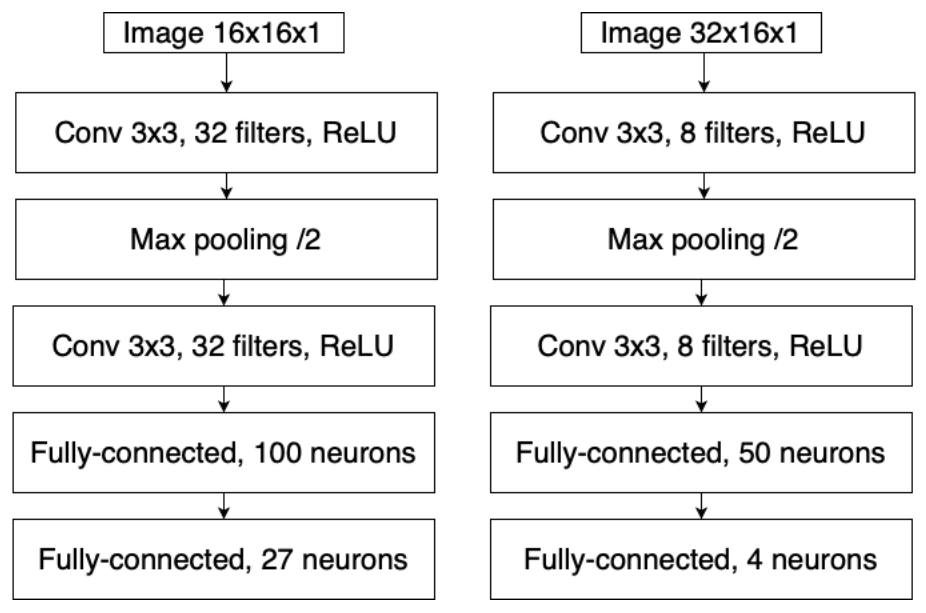
Раз человеку нужно окружение пробела, чтобы его увидеть, то логично и сети показывать хотя бы два соседних символа. Мы не хотим увеличивать вход распознающей сети, которая, в общем-то, неплохо работает (и многие пробелы распознает). Так что мы заведем еще одну сеть — попроще. Новая сеть будет предсказывать, что на картинке: два пробела, две буквы, пробел и буква или буква и пробел. Соответственно, такая сеть используется вместе с распознающей сетью. На изображении представлены используемые архитектуры: слева — архитектура распознающей сети, справа — архитектура предложенной сети. Распознающая сеть работает на картинке с одним символом, а новая — на картинке двойной ширины, содержащей два соседних символа.
Для тестирования у нас было 4320 строк с именами, содержащие 130149 символов, из которых 68246 пробелов. Для начала, у нас есть два метода. Базовый метод: нарежем строку на символы и распознаем каждый символ по отдельности. Новый метод: также нарежем строку символы, найдем все пробелы новой сетью, а оставшиеся символы распознаем обычной. Из таблицы видно, что качество распознавания пробелов, как и общее качество, растет, но качество распознавания букв слегка проседает.
Однако наша базовая сеть тоже умеет распознавать пробелы (пусть и хуже, чем нам бы хотелось). И мы можем попробовать этим воспользоваться. Посмотрим, на ошибки обоих методов. А также — на качество нового метода на ошибках базового и наоборот.
Для базового метода:
Для нового метода:
Из трех последних таблиц видно, что для улучшения системы стоит использовать взвешенную комбинацию оценок сетей. При этом, посимвольное качество — это интересно, но построчное — интереснее.
Пробел — большая проблема на пути к 100%-ному качеству распознавания документов =) На примере пробелов отлично видно, как важно смотреть не только на отдельные символы, но и на их сочетания. Однако не стоит сразу хвататься за тяжелую артиллерию и учить гигантские сети, обрабатывающие строки целиком. Иногда достаточно просто еще одной маленькой сети.
Данный пост сделан с использованием материалов доклада с европейской конференции по моделированию ECMS 2015 (Болгария, г. Варна): Sheshkus, A. & Arlazarov, V.L. (2015). Space symbol detection on complex background using visual context.
Как видно на картинке — мы работаем на исходном изображении со сложными фонами, поэтому пробелы наши весьма разнообразны. На них бывают узоры, логотипы, а иногда и текст. Например, VISA или MAESTRO на карточках. И нам интересны именно такие «сложные пробелы», а не просто белые прямоугольники. А в своих системах мы рассматриваем именно отдельно вырезанные прямоугольники символов [1].
А в чем сложность?
Пробел — это символ без особых признаков. На сложных фонах, например, как на изображении, отдельно вырезанный пробел бывает сложно отличить даже человеку.
С другой стороны, по своей сути пробел отличается от остальных символов. Если в имени вместо ASIA распознается ABIA, то есть шанс исправить это пост-обработкой. Но, если там возникнет A IA — вряд ли уже что-то поможет.
Не нами используемые методы
Часто пробелы фильтруют с помощью статистик, посчитанных по картинке. Например, считают среднее абсолютное значение градиента по картинке или дисперсию интенсивностей пикселей и по пороговому значению делят картинки на пробелы и буквы. Однако, как видно по графикам, такие методы не годятся для серых картинок со сложными фонами. А из-за явной корреляции значений даже комбинация этих методов не справится.
Всеми любимая бинаризация тут тоже не поможет. Например, вот на такой картинке:
Итак, как же можно улучшить распознавание?
Раз человеку нужно окружение пробела, чтобы его увидеть, то логично и сети показывать хотя бы два соседних символа. Мы не хотим увеличивать вход распознающей сети, которая, в общем-то, неплохо работает (и многие пробелы распознает). Так что мы заведем еще одну сеть — попроще. Новая сеть будет предсказывать, что на картинке: два пробела, две буквы, пробел и буква или буква и пробел. Соответственно, такая сеть используется вместе с распознающей сетью. На изображении представлены используемые архитектуры: слева — архитектура распознающей сети, справа — архитектура предложенной сети. Распознающая сеть работает на картинке с одним символом, а новая — на картинке двойной ширины, содержащей два соседних символа.
А протестировать?
Для тестирования у нас было 4320 строк с именами, содержащие 130149 символов, из которых 68246 пробелов. Для начала, у нас есть два метода. Базовый метод: нарежем строку на символы и распознаем каждый символ по отдельности. Новый метод: также нарежем строку символы, найдем все пробелы новой сетью, а оставшиеся символы распознаем обычной. Из таблицы видно, что качество распознавания пробелов, как и общее качество, растет, но качество распознавания букв слегка проседает.
| Пробелы | Буквы | Итого | |
| Базовый метод | 93.6% | 99.8% | 96.5% |
| Новый метод | 94.3% | 99.6% | 96.8% |
Однако наша базовая сеть тоже умеет распознавать пробелы (пусть и хуже, чем нам бы хотелось). И мы можем попробовать этим воспользоваться. Посмотрим, на ошибки обоих методов. А также — на качество нового метода на ошибках базового и наоборот.
Для базового метода:
| Пробелы | Символы | Итого | |
| Ошибки базового метода | 4392 | 141 | 4533 |
| Распознано новым методом | 44.7% | 29.8% | 44.3% |
Для нового метода:
| Пробелы | Символы | Итого | |
| Ошибки базового метода | 3893 | 241 | 4134 |
| Распознано новым методом | 37.6% | 58.9% | 38.9% |
Из трех последних таблиц видно, что для улучшения системы стоит использовать взвешенную комбинацию оценок сетей. При этом, посимвольное качество — это интересно, но построчное — интереснее.
| Качество | |
| Базовый метод | 96.39% |
| С новой сетью | 96.46% |
| Комбинация методов | 97.07% |
Заключение
Пробел — большая проблема на пути к 100%-ному качеству распознавания документов =) На примере пробелов отлично видно, как важно смотреть не только на отдельные символы, но и на их сочетания. Однако не стоит сразу хвататься за тяжелую артиллерию и учить гигантские сети, обрабатывающие строки целиком. Иногда достаточно просто еще одной маленькой сети.
Данный пост сделан с использованием материалов доклада с европейской конференции по моделированию ECMS 2015 (Болгария, г. Варна): Sheshkus, A. & Arlazarov, V.L. (2015). Space symbol detection on complex background using visual context.
Список используемых источников
1. Y. S. Chernyshova, A. V. Sheshkus and V. V. Arlazarov, “Two-step CNN framework for text line recognition in camera-captured images,” IEEE Access, vol. 8, pp. 32587-32600, 2020, DOI: 10.1109/ACCESS.2020.2974051.


unwrecker
А нельзя ли улучшить качество исходного фото? Для карточек можно использовать подсветку сбоку чтоб проявлять рельеф букв.
Alexufo
Да вообще можно в ИК снимать. Все машиночитаемых документы в ИК без подложек. Беда в том что это речь про мобильные камеры.
SmartEngines Автор
Для машиночитаемых зон — это, конечно, правда. Но тут речь в основном про банковские карты, и ИК не поможет. Даже если бы он был на смартфоне.
Alexufo
Да, там это эмбосирование посеребреное и глазами плохо читается. Однако, ИК бы помог все равно, снизив большое количество цветной типографской графики, если она конечно не черная. Я как то проверял смартфон на чувствительность к ИК. У него заметно большая чувствительность чем у фотокамер. По крайней мере пульты от телевизора так показывают)
Более того, мне кажется что это сделано специально, так как борьба за освещение мобильных камер требует брать максимум любого источника, лишь бы был.
SmartEngines Автор
Как правило, нет. Во-первых, никогда неизвестно как именно пользователь сфотографирует карточку, и в каких условиях ему придется это делать. Во-вторых, не на всех картах рельефный шрифт.
tolstov
Но есть же карточки, где буквы «нацарапаны» лазером, есть, где вообще просто краской нанесены…