

Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Статьи на сегодня:
- ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks (China, 2020)
- TAPAS: Weakly Supervised Table Parsing via Pre-training (Google, 2020)
- DeepFaceLab: A simple, flexible and extensible faceswapping framework (2020)
- End-to-End Object Detection with Transformers (Facebook AI, 2020)
- Language Models are Few-Shot Learners (OpenAI, 2020)
- TabNet: Attentive Interpretable Tabular Learning (Google Cloud AI, 2020)
- 2020 год: Январь — Февраль, Март ч1, ч2, Апрель ч1, ч2, Май ч1
- 2019 год: Январь — Июнь, Июль — Сентябрь, Октябрь — Декабрь
- Декабрь 2017 — Январь 2018, Февраль — Март 2018
- 2017 год: Август, Сентябрь, Октябрь — Ноябрь
1. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
Авторы статьи: Qilong Wang, Banggu Wu, Pengfei Zhu, Peihua Li, Wangmeng Zuo, Qinghua Hu (China, 2020)
Оригинал статьи | GitHub project
Автор обзора: Эмиль Закиров (в слэке bonlime)
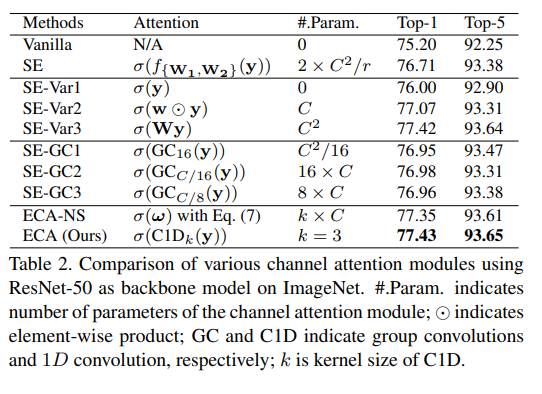
Очередной вариант self-attention для computer vision. Авторы внимательно посмотрели на известный squeeze-and-excitation (SE), который сейчас используют во многих SOTA сеточках и его аналоги, попробовав понять почему же именно оно работает. Потом предложили свой супер легкий attention block, который практически не увеличивает количество параметров, быстрее чем SE и при этом лучше работает.

Все последние attention блоки обладают одним из двух свойств, они либо используют уменьшение количества каналов, либо включают какое-то взаимодействие между каналами. SE, к примеру, делает и то и то.

Хочется понять насколько эти две составляющие влияют на итоговое качество. Для этого авторы предлагают несколько слегка модифицированных вариантов SE block:
- SE-Var1 — просто делаем GlobalAvgPool + sigmoid. Даже такой просто attention даёт прирост к качеству.
- SE-Var2 — GlobalAvgPool + каждый канал умножается на какой-то параметр + sigmoid. В отличие от дефолтного SE нет dimensionality reduction (DR) и нет cross-channel interaction, а качество выше! Вывод авторов — избегание dimensionality reduction важнее чем какие-то cross-channel interactions.
- SE-Var3 — как SE, но без уменьшения количества каналов в середине. Работает лучше, но добавляет очень много параметров и сильно замедляет обучение.
- SE-GC — попытки делать attention через групповые свертки. Работает лучше чем SE, но group convs медленно обучаются.
- ECA — вариант авторов. GlobalAvgPool + Conv1d (kernel size=3). Операция Conv1d дешевая, при этом удалось избежать dimensionality reduction и добавить какое-то cross-channel interaction.
Attention block авторов в деталях
Размер ядра после GlobalAvgPool можно пытаться определять с помощью каких-то эвристик. У авторов она такая — чем больше каналов, тем больше ядро. Для 128 каналов ядро будет 3, а для 1024 — 7. Но как видно из последних двух строчек на таблице выше — это не особо влияет на качество.

Проведено сравнение использования разных размеров ядра для 1d свертки vs adaptive. т.к. разница на уровне погрешности, можно остановиться на самом простом случае — ядре размера 3. В коде авторов так и сделано, везде захардкожено 3.
Проведено сравнение для задачи детекции. На фоне практически незаметного увеличения количества параметров дает прирост метрик на 1-2%, что выглядит очень убедительно.
Пара практических заметок
Хотя Conv1d на порядки быстрее, чем две FC в SE блоке, ускорение на практике получается только ~5% потому что самая дорогая операция это GlobalAvgPool, а не последующие свертки.
Проведено сравнение весов для каналов, выученных SE блоком и ECA блоком для 4х разных классов. Прогоняют все картинки этого класса из валидации и записывают среднее для разных каналов. SE выучивает очень похожие attention для разных классов, в том время как у ECA они "have better discriminative ability".
Заметка от автора обзора
Зачем верить авторам на слово, если можно проверить. У меня на Imagenet за 90 эпох обычный SE даёт Acc@1 78.988 Acc@5 94.440, а ECA даёт Acc@1 79.281 Acc@5 94.664. Там была небольшая разница в конфигах обучения — SE учился на 4хV100, а ECA на 3хV100, и у них был разный lr. Т.е. не могу пока точно утверждать что ECA > SE, но как минимум не хуже точно, при том что быстрее и практически не добавляет параметров.
2. TAPAS: Weakly Supervised Table Parsing via Pre-training
Авторы статьи: Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Muller, Francesco Piccinno, Julian Martin Eisenschlos (Google, 2020)
Оригинал статьи | GitHub project | Colab
Автор обзора: Александр Бельских (в слэке belskikh)
Новая модель от гугла, основанная на BERT, которая парсит таблички в режиме question answering наравне или лучше, чем существующие аналоги, но способна выпонять больше задач + хорошо файнтюнится, что означает, что можно использовать гугловый претрейн для своих задач.

Авторы спарсили большой датасет для претрейна из WikiTable и Infobox, собрав оттуда таблички с различными данными. Модельку завели на основе BERT, добавив туда различных эмбеддингов, специфичных для табличных данных. На вход модель получает последовательность токенов вопроса и табличных данных, а на выходе у неё два классификационных слоя — один для выбора ячеек сети (если ответ является просто какой-то ячейкой сети) и один для операции агрегации выбранных ячеек (COUNT, SUM, AVG). Все эмбеддинги токенов комбинируются с наборов специфичных для табличных данных:
- Position ID — индекс токена в табличке (таблица представлена во flatten виде).
- Segment ID — 0 для сегмента с вопросом и 1 для сегмента с табличными данными.
- Column / Row ID.
- Rank ID — если данные как-то можно упорядочить (дата, число, время) то указывается ранг, как относительный порядок.
- Previous Answer — в некоторых сетапах модель работает в conversational режиме, поэтому добавляют отдельный эмбеддинг, является ли токен аутпутом модели с предыдущей стадии.
Во время инференса выбираются из классификационного слоя ячейки с вероятностью больше 0.5 и над ними проводится предсказанная операция агрегации (NONE, COUNT, SUM, AVG). Претрейн проводится на собранном из WikiTable и Infobox датасете, используется masked language model pre-training objective, как в BERT. Затем модель обучили на датасетах WIKISQL, WIKITQ, SQA, получив выше или на уровне с СОТА-аналогами.
Претрейн проходил на 32 Cloud TPUv3 в течение трёх дней, а файнтюнинг на нужный датасет там же от 10 до 20 часов. Модель примерно такого же размера, как и BERT-large.
Полученная модель позволяет отвечать на вопросы по таблицам, но при этом архитектурно значительно проще существующих аналогов. Более того, она показала хорошие результаты на файнтюнинге под новые схожие данные, что, возможно, станет новым прорывом в работе с табличными данными. Модель на данный момент ограничена тем, что не может процессить слишком большие таблички и не может сформулировать ответ по некоторому сабсету ячеек таблицы. Например, запрос “number of actors with an average rating higher than 4” не может быть обработан правильно.

3. DeepFaceLab: A simple, flexible and extensible faceswapping framework
Авторы статьи: Ivan Perov, Daiheng Gao, Nikolay Chervoniy, Kunlin Liu, Sugasa Marangonda, Chris Ume, Mr. Dpfks, Carl Shift Facenheim, Luis RP, Jian Jiang, Sheng Zhang, Pingyu Wu, Bo Zhou, Weiming Zhang (2020)
Оригинал статьи | GitHub project
Автор обзора: Евгений Кашин (в слэке digitman, на habr digitman)
Автор самой популярной репы на гитхабе (14к+ звездочек) по дипфейкам решил закинуть свое творение к академикам и написал статью с кучей "фрилансеров" в авторах. Сам подход достаточно простой и давно известный, но у них настроенные пайплайны, легкая кастомизация, большое комьюнити. Ну и конечно результаты по моему у них на данный момент самые "приятные".
Естественно это подается под соусом "дипфейки это плохо, но лучшая защита это нападение". Что интересно в авторах есть Ctrl Shift Face — очень популярные видосы на ютубе с дипфейками, а также Mr. dpfks, который, наверное, делает MrDeepFakes сайт — порнхаб с селебами на дипфейках.
Код на TF, но автор написал свой велосипед для TF — Leras(Lighter Keras), который вроде проще (куда еще) и быстрее. В любом случае, большинство кто использует сидят на винде и все что им надо — создать две папки с картинками двух людей.
Пайплайн из трех частей — extraction, training, conversion. Подход ограничен конвертацией "one-to-one" — под каждую пару людей нужно все переучивать.
Extraction состоит из:
- детекции лица и кейпоинтов (S3FD, но можно заменить на RetinaFace);
- выравнивание лица — сглаживают по времени кейпоинты и применяют трансформацию (Umeyama), чтобы привести лицо к нормальному положению;
- сегментация лица(TernausNet).

Сегментация лица часто не очень точная, поэтому они сделали свою тулзу XSeg — которая помогает интерактивно подправить плохие маски и дозакинуть их заново в обучение, такой active learning. Говорят достаточно доразметить 50 фоток руками.
Training. На вход две папки — в каждой выровненные лица и маски для отдельного человека. У них два пайплайна, первый — DF, по сути простой автоэнкодер. Энкодер и ботлнек (Inter), которые зашарены для двух людей, а также два декодера с разными весами для каждого человека.

Второй — LIAE. Энкодер также зашарен, а ботлнека два разных. InterAB генерит эмбединг и для source и для target, а InterB — только для target. На вход зашаренному декодеру подается конкат двух эмбедингов. Для source просто конкатится InterAB эмбединг сам с собой, для target — InterAB с InterB. Вроде InterAB должен вытаскивать общую для двух доменов инфу, а InterB детали target домена.

Во время "автоэнкодерного" обучения давали разный вес лосам за реконструкцию разных частей лица, например у глаз был самый большой вес. Лоссы: DSSIM + MSE. На гпу — обучение пару часов.
Conversion. По сути берется лицо из source и просто прогоняется или через Decoder dst в случае DF или через InterAB и InterB в случае LIAE. Сгенеренное лицо реалайнится по кейпоинтам таргет лица. Результат матчится по цветовой схеме с таргетом одним из 5 алгоритмов на выбор. Блендинг границ лица по сегментационной маске делают через Poisson blending optimization. После этого еще прогоняют результат через суперрез для четкости.

По метрикам конечно сота.

Также есть Ablation Study в котором они тестили немного разные архитектуры, добавление ган лосса и TrueFace. Примеры работы подхода представлены ниже.

4. End-to-End Object Detection with Transformers
Авторы статьи: Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko (Facebook AI, 2020)
Оригинал статьи | GitHub project
Автор обзора: Андрей Лукьяненко (в слэке artgor, на habr artgor)
Классный новый подход к object detection от facebook! Они предлагают работать с этой с задачей, как с прямым предсказанием сета и использовать трансформер. Базовая модель даёт 42 AP на COCO! Но тренируется 3 дня на 16 V100.
Основная суть DETR заключается в том, то он сразу предсказывает все объекты и тренируется с лоссом, который делает двустороннее соответствие (performs bipartite) между предсказанными боксами и разметкой. Получается, что нам не нужны ни якоря, ни non-maximal supression. Есть один минус: авторы признают, что DETR отлично работает на больших объектах, то хуже на мелких. И для тренировки нужно, цитирую "extra-long training schedule", а также дополнительные лоссы. С другой стороны, подход можно использовать и для других задач, например, сегментации.

DETR Model
Для прямого предсказания сетов нужны две составные части: лосс, который делает уникальный матчинг между предсказанными и размеченными боксами, и архитектура, которая за один проход предсказывает сеты объектов и моделирует их взаимосвязи.
Object detection set prediction loss
Модель предсказывает N объектов за один раз. Обычно число значительно выше, чем количество реальных объектов. Лосс делает двусторонний матчинг и оптимизирует лоссы для боксов.
В формуле y — ground truth, y-hat — предсказания. Поскольку "y" меньше размером, то делают паддинг со значениями "no object". По факту ищем пермутации объектов с минимальным костом.
Lmatch — pair-wise matching cost between ground truth and prediction. Считают с помощью Hungarian algorithm. Он учитывает классы и схожесть между боксами.
Теперь считаем Венгерский лосс для всех пар, которые получились на предыдущем шаге. Для "no object" делим лог-вероятность на 10, чтобы компенсировать дисбаланс классов.
Bounding box loss
Просто использовать L1 не вариант, ибо будут разные масштабы значений для мелких и больших боксов. Поэтому добавляют IoU. Лямбды — гиперпараметры. И лосс делят на количество объектов в батче.
DETR Architecture: CNN + transformer + FNN.
Backbone: можно использовать любую. На выходе авторы хотят иметь feature maps с 2048 каналами, высота и ширина картонок в 32 раза меньше оригинальных.

Трансформер
Энкодер и декодер инвариантны к перестановкам.
Энкодер. Вначале используем 1x1 convolution, чтобы уменьшить количество каналов до d. Поскольку энкодеру надо на вход подавать последовательности, мы преобразуем данные и получаем размерность dxHW. В энкодере используется multi-head attention + FNN. К каждому attention добавляются positional embeddings.
Декодер. Декодирует объекты параллельно в каждом слое. На вход дополнительно подают N эмбеддингов — это тренируемые positional encodings, которые добавляются на каждом слое. Им дали название object queries.
На выходе эмбеддинги независимо друг от друга декодируются в координаты боксов и классы с помощью FNN. Благодаря attention модель может учитывать взаимосвязи между объектами.
FNN. Голова — просто трехслойный перцептрон. Предсказывает координаты центра боксов и их размеры, линейный слой предсказывает классы с помощью softmax.

Auxiliary decoding losses
В каждом слое декодера добавляют prediction FFNs, параметры которых шарятся, и Hungarian loss. И дополнительно используют layer-norm для нормализации входов в prediction FNN с каждого слоя декодера.
Эксперименты на COCO
Параметры обучения: AdamW, начальный LR трансформера 10^-4, backbone's — 10^-5, weight decay 10^-4. Попробовали ResNet-50 and ResNet-101 в качестве backbones — модели назвали DETR and DETR-101.
Попробовали ещё улучшить архитектуру: улучшить разрешение с помощью добавления dilation на последней стадии backbone и убирания stride на этой же стадии. Модели назвали DETR-DC5 and DETR-DC5-R101. Требует в 2 раза больше вычислений, но улучшает результаты для мелких объектов.
Scale augmentation — поресайзили картинки так, чтобы минимальная сторона была от 480 до 800, а максимальная не больше 1333. Random crop augmentation (+1 AP). И постпроцессинг — если модель предсказывает пустые классы, взять следующий класс по вероятности. +2 AP. Обучение: 300 эпох — 3 дня на 16 V100. Тренировка на 500 эпох дает + 1.5 AP.

Сравнение с Faster R-CNN
Попробовали улучшить Faster R-CNN:
- добавить IoU в лосс;
- random crop augmentations;
- дольше тренировка.
В таблице выше обычный Faster R-CNN тренировался в 3 раза дольше обычного. Значок "+"означает тренировку в 9 раз дольше (109 эпох). DETR тащит почти все AP — кроме AP75 и APs
Ablation
Энкодер по своей сути global scene reasoning и это помогает разъединять объекты. Увеличение количества слоев энкодера и декодера помогает.
FNN внутри трансформера можно интерпретировать как 1 ? 1 convolutional, то есть получается нечто похожее на attention augmented convolutional. Без этого AP падает на 2.3.

DETR for panoptic segmentation
Просто добавляет голову с маской после декодера (бинарно на каждый класс). Но боксы все равно надо предсказывать — для лосса.
И классы предсказываются с помощью argmax по каждому пикселю. Так защищаемся от потенциального перекрытия масок разных классов.


И последнее — картинка про качество, для тех, кто очень обрадовался. Чем больше объектов, тем хуже работает модель.

5. Language Models are Few-Shot Learners
Авторы статьи: Tom B. Brown et.al. (OpenAI, 2020)
Оригинал статьи | GitHub with examples and statistics
Автор обзора: Вадим Петров (в слэке graviton, на habr belgraviton)
До сих пор, использование предобученных трансформеров в прикладных задачах (например, questions answering) требовало дообучения. Большая группа ученых из OpenAI продемонстрировала, что при увеличении размера языковой модели GPT-3 (до 175B весов), достигается хорошая точность на специфических задачах без дообучения, сравнимая с моделями, которые файнтюнились на них (см. график ниже). Для задачи генерации новостей достигнуто качество, сложно отличимое от новостей, написанных людьми.
Авторы изучали модель применительно к разным задачам на основе подходов zero-shot, one-shot и few-shot. Случай дообучения под задачи они оставили на будущее. Для случая few-shot на графике снизу видно значительное увеличение точности при росте числа параметров модели.

Авторы пытались решить следующие задачи:
- Специфичные задачи в NLP требуют сбора датасетов под них. Это иногда довольно затратно.
- Решение проблемы с генерализацией под новые задачи, где данных может быть слишком мало для больших моделей трансформеров.
- Люди требуют очень мало информации для решения смежных NLP задач. Хорошие NLP модели должны также демонстрировать аналогичное поведение.
Архитектура
Использована архитектура GPT-2 с модифицированной инициализацией, преднормализацией и обратимой токенизацией. Отличием является использование плотных и локально разреженных "attention patterns" в слоях трансформера. Обучено 8 моделей от 125M до 175B параметров.

Замечу, что архитектура GPT-2 тоже лишь незначительно отличается от GPT-1, которая представлена ниже.

Тренировка
Были использованы 5 датасетов: Common Crawl, WebText2, Books1, Books2 и Wikipedia. Всего около 300 млрд токенов.
Для тренировки использовали идею, что для больших моделей нужен больший размер батча и меньшая скорость обучения. Список моделей с параметрами архитектуры и обучения выше.
Использован Adam, с ограничением градиента в 1.0, cosine learning rate decay и warmup. Обучение GPT-3 заняло 3640 PetaFlops-days на кластере из V100 GPU’s, предоставленном Microsoft.
Результаты
Тестирование проводилось на большом наборе датасетов. В большей части из них удалось с помощью few shot подхода получить результаты схожие с fine tune SOTA подходами. Примером, такого случая является перевод, результаты для которого представлены в таблице ниже. При этом, для нескольких задач удалось достичь даже значительного улучшения SOTA. Об этом ниже.

На задаче предсказания последнего слова в параграфе SOTA улучшена на 8 %, а в тесте с ответами на вопросы о физических процессах модель превзошла предыдущую SOTA (fine-tuned RoBERTa) на 1% даже в zero-shot режиме!


Арифметические операции
Для задачи выполнения арифметических операций сгенерировали датасет, на котором продемонстрировали способность модели (few-shot) решать данную задачу с точностью больше 90% для 2-х и 3-х значных чисел. Датасет обещают выложить.
Генерация новостей
Анализировался режим few-shot. Модели для генерации новости показывалось 3 новости по выбранной теме и заголовок с подзаголовком для новой статьи. Качество статей проверялось 80 людьми. Точность идентификации источника новостей заметно снижается при увеличении модели и достигает для GPT-3 только 52%, что очень близко к уровню случайного выбора (50%) несмотря на то, что люди тратили больше времени на оценку результатов больших моделей.

Имеющиеся проблемы
В то же время разработчики нашли ряд задач, в которых модель была неуспешна (оценка связи двух выражений -ANLI dataset, сжатие текста — RACE, QuAC).
Из-за ошибки в пайплайне очистки тренировочного датасета от тестовых примеров, остались перекрытия. Авторы провели анализ влияния перекрытий на результаты.
Также имеются проблемы с генерацией текстов: иногда имеются повторения и несогласованность для длинных текстов, нелогичные заключения.
6. TabNet: Attentive Interpretable Tabular Learning
Авторы статьи: Sercan O. Arik, Tomas Pfister (Google Cloud AI, 2020)
Оригинал статьи | GitHub project
Автор обзора: Александр Бельских (в слэке belskikh)
Работа от Google, в которой представлена архитектура нейросети для табличных данных, превосходящая доминирующие до этого подходы на ансамблях деревьев, сохраняя свойства интерпретируемости и легковесности. Дополнительно обладает возможностью предобучения в режиме self-supervising, что открывает большие возможности для дообучения и обучения на маленьких датасетах.
В отличии от tree-based подходов, на вход TabNet поступают сырые табличные данные, а обучается она через обычный градиентный спуск, выучивая хорошие репрезентации данных.
В архитектуре использован sequential attention механизм, который определяет, какие признаки будут использованы во время текущего decision step, что позволяет получить интерпретируемость предсказания.
Для выбора признаков на следующий шаг в архитектуре используется выучиваеммая sparse маска, которая поэлементно умножается на эмбеддинги признаков, чтоб получить взвешенные эмбеддинги.

Дискретные признаки классически приводятся к виду таблицы выучиваемых эмбеддингов. Сами признаки прогоняются через специальный модуль feature transformer (ничего общего с архитектурой Transformer не имеет).
В режиме self-supervised pretraining модель учится предсказывать пропущенные признаки из таблицы входных данных, где эти признаки случайным образом маскируются.

Модель показала себя наравне или лучше чем текущие SOTA модельки для табличных данных.

