

Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Статьи на сегодня:
- Efficient Document Re-Ranking for Transformers by Precomputing Term Representations; EARL: Speedup Transformer-based Rankers with Pre-computed Representation (2020)
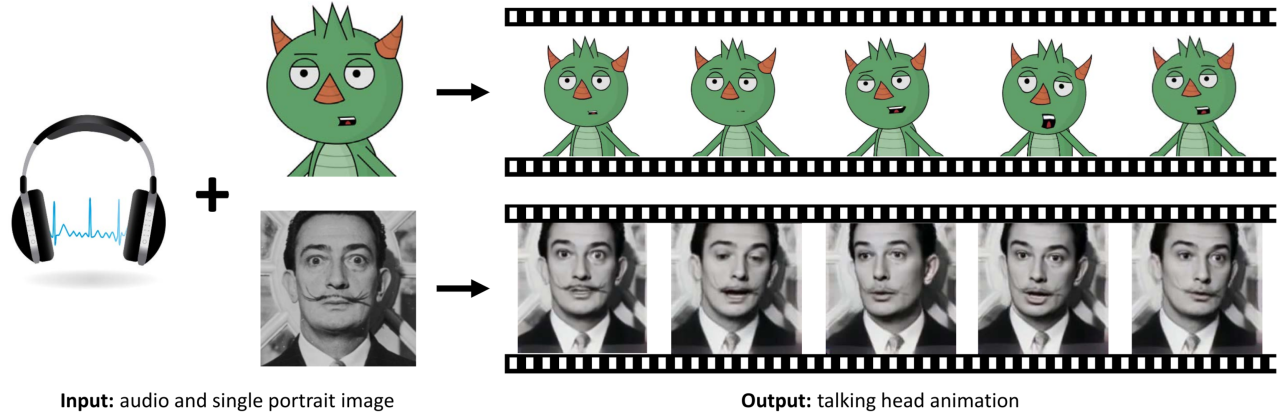
- MakeItTalk: Speaker-Aware Talking Head Animation (Adobe, University of Massachusetts Amherst, Huya, 2020)
- Jukebox: A Generative Model for Music (OpenAI, 2020)
- Recipes for building an open-domain chatbot (Facebook AI Research, 2020)
- One-Shot Object Detection without Fine-Tuning (HKUST, Hong Kong, Tencent, 2020)
- f-BRS: Rethinking Backpropagating Refinement for Interactive Segmentation (Samsung AI Center, Moscow, 2020)
- Flowtron: an Autoregressive Flow-based Generative Network for Text-to-Speech Synthesis (NVIDIA, 2020)
- 2020 год: Январь — Февраль, Март ч1, ч2, Апрель ч1, ч2
- 2019 год: Январь — Июнь, Июль — Сентябрь, Октябрь — Декабрь
- Декабрь 2017 — Январь 2018, Февраль — Март 2018
- 2017 год: Август, Сентябрь, Октябрь — Ноябрь
1. Efficient Document Re-Ranking for Transformers by Precomputing Term Representations; EARL: Speedup Transformer-based Rankers with Pre-computed Representation
Авторы статьи 1: Sean MacAvaney, Franco Maria Nardini, Raffaele Perego, Nicola Tonellotto, Nazli Goharian, Ophir Frieder (USA, Italy, 2020)
Авторы статьи 2: Luyu Gao, Zhuyun Dai, Jamie Callan (Carnegie Mellon University, USA, 2020)
Оригинал статьи 1 :: Оригинал статьи 2
Автор обзора: Владимир Бугай (в слэке smartvlad, на habr vbougay)
Две статьи с разницей в один день и простой и казалось бы очевидной идеей. Тот случай когда думаешь почему этого никто не сделал раньше.
Производительность трансформеров на инференсе уже набила оскомину, они с трудом заходят в real-time задачи такие как, например, реранжирование результатов. Масса усилий тратится на дистилляцию, прунинг, квантизацию, с результатами которые на практике не влияют качественно на скорость вывода.
Авторы статей независимо друг от друга предлагают простой подход, который позволяет ускорить реранжирование документов в поисковых задачах в несколько раз (заявляют 40x). Подход эксплуатирует особенность задачи реранжирования, когда одни и те же документы прогоняются для разных запросов много раз и наоборот для одного запроса оцениваются сотни разных документов.
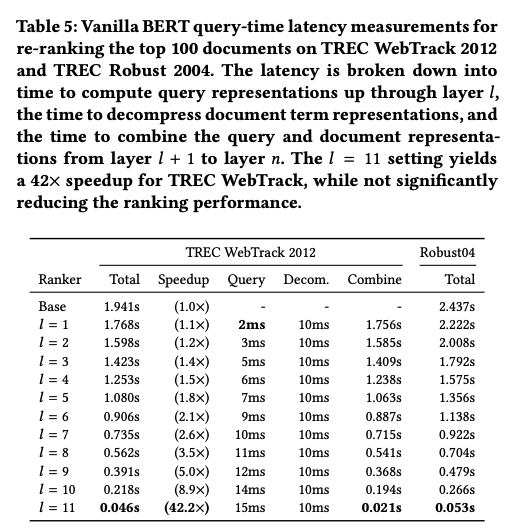
В классическом варианте для каждой пары запрос-документ формируется вход трансформера и прогоняется через все слои. Тем самым для одного и того же запроса его векторное представление рассчитывается сотни раз, а в случае множества запросов то же самое происходит для документов. Авторы предлагают немного затюнить классический трансформер и выделить в нем явно модули рассчитывающие представление запроса и документа, так, чтобы вместо их расчета каждый раз, результат можно было закешировать и использовать для повторных расчетов избегая массы ненужных вычислений. Такой подход позволил добиться ускорения реранжирования в 40 раз без заметной потери в качестве. В первой статье результаты оценивали на WebTrack 2012, во второй на MS Marco. Результаты сравнивали с Vanilla BERT.
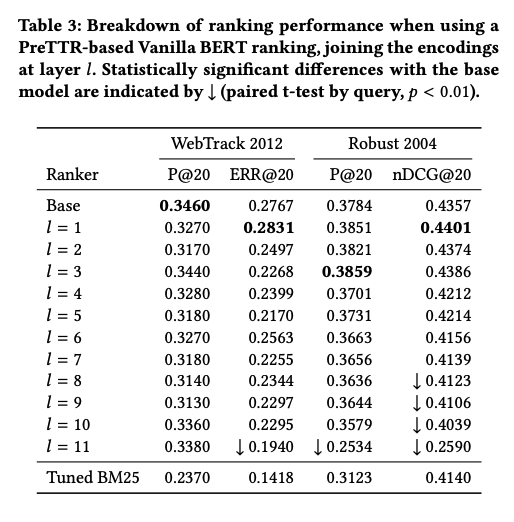
Из интересного еще эксперименты авторов с кэшированием представлений с разных слоев трансформера. Практика показала, что без ущерба для качества можно кэшировать все кроме последнего 12-го уровня.

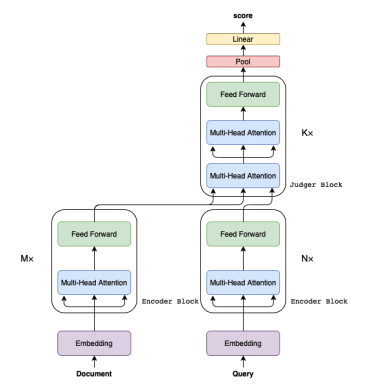
Архитектура модели PreTRR, представления документов с N-слоя просто сохраняются и кэшируются в базе и используются впоследствии для расчетов. Тот же самый трюк проделывают для представления запроса для реранжирования документа относительно него.
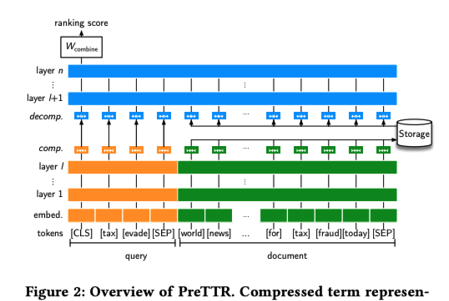
Архитектура модели EARL, тут явно выделили блоки запроса и документа (почти сиамская сетка), а дальше сводят их в блок-оценщик (Judger).
Качество модели PreTRR с кэшированием разного количества слоев, а также ее производительность при реранжировании 100 документов.
2. MakeItTalk: Speaker-Aware Talking Head Animation
Авторы статьи: Yang Zhou, DIngzeyu Li, Xintong Han, Evangelos Kalogerakis, Eli Shechtman, Jose Echevarria (Adobe, University of Massachusetts Amherst, Huya, 2020)
Оригинал статьи
Автор обзора: Евгений Кашин (в слэке digitman, на habr digitman)
Генерируют анимацию лиц по голосу и одному изображению. Особенность — разделяют входной звук на контент и "личность", что позволяет по разному анимировать один и тот же текст для разных голосов, а также двигать голову (а не только черты лица).
Из исходного лица достают 68 кейпоинтов. Входной звук процесят (мел спектрограмма) и пропускают через два разных претрейн энкодера (conv-ы c lstm). Content embedding — достает информацию о словах (фонемах), не цепляясь за "идентичность". Контент эмбединг (окнами по 300мс) идет в LSTM, а после конкатится с кейпоинтами и пропускается через MLP, для предсказания смещения начальных кейпоинтов. На этом шаге должно предсказываться новое положение лица (кейпоинтов) для текущего звука, но с нейтральным выражением лица. Важно предсказывать смещения координат, а не абсолютные, чтобы нормально работало на мультяшных лицах.
Speaker Identity embedding — извлекает личность из голоса. Использовали модель аудио верификации, которая обучалась выдавать близкие эмбединги для одного человека. В этом блоке (нижний на схеме) опять использовали контент эмбединг + LSTM (другие веса), выход которого конкатили со спикер эмбедингом и подавали в self attention (с временным окном 4 секунды, чтобы лучше учесть мотания головой). В конце выдаются также предсказания смещения кейпоинтов.
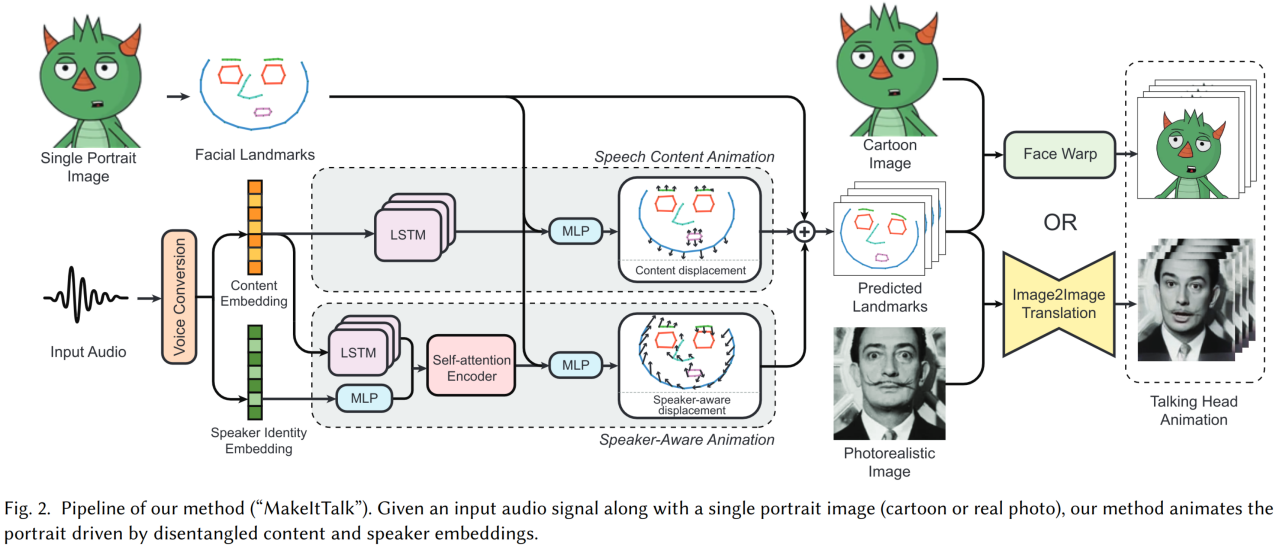
Получив новое положение кейпоинтов, нужно как то натянуть на них исходное лицо. Для мультяшных лиц делают просто варпинг на триангуляции лица по кейпоинтам. Для кейпоинтов брали специальную претрейн сетку, которая обучена на "нереалистичном" домене.

Для реальных лиц использовали image2image сетку(U-net like). На входе конкатенация исходного изображения и таргет ландмарок, полученных на предыдущем шаге. Ландмарки соединяют в группы и заливают разными цветами.
Для обучения контент ветки использовали датасет 6 часов видео с Обамой, кейпоинты выровнены, поэтому не было движения головы, а только мимика лица(как не странно, одного человека было достаточно). Лосс — l2 между кейпоинтами и l2 между локально сгруппированными кейпоинтами (respective graph Laplacian coordinates).
Для speaker aware ветки нужен был датасет с большим разнообразием людей — VoxCeleb2. Тут наоборот — не выравнивали ландмарки, чтобы оставить мотания головой. Использовали ган лосс, для того чтобы мотания и эмоциональность частей лица выглядели реалистично. Дискриминатор тоже с self attention, лосс — LSGAN. К адвесериал лоссу на кейпоинты также были лоссы из контент ветки.
Для обучения image2image тоже VoxCeleb2, для одного человека семплили случайную сорс картинку и таргет (превращенный в изображение из ландмарок). Лосс — l1 и perceptual vgg loss.
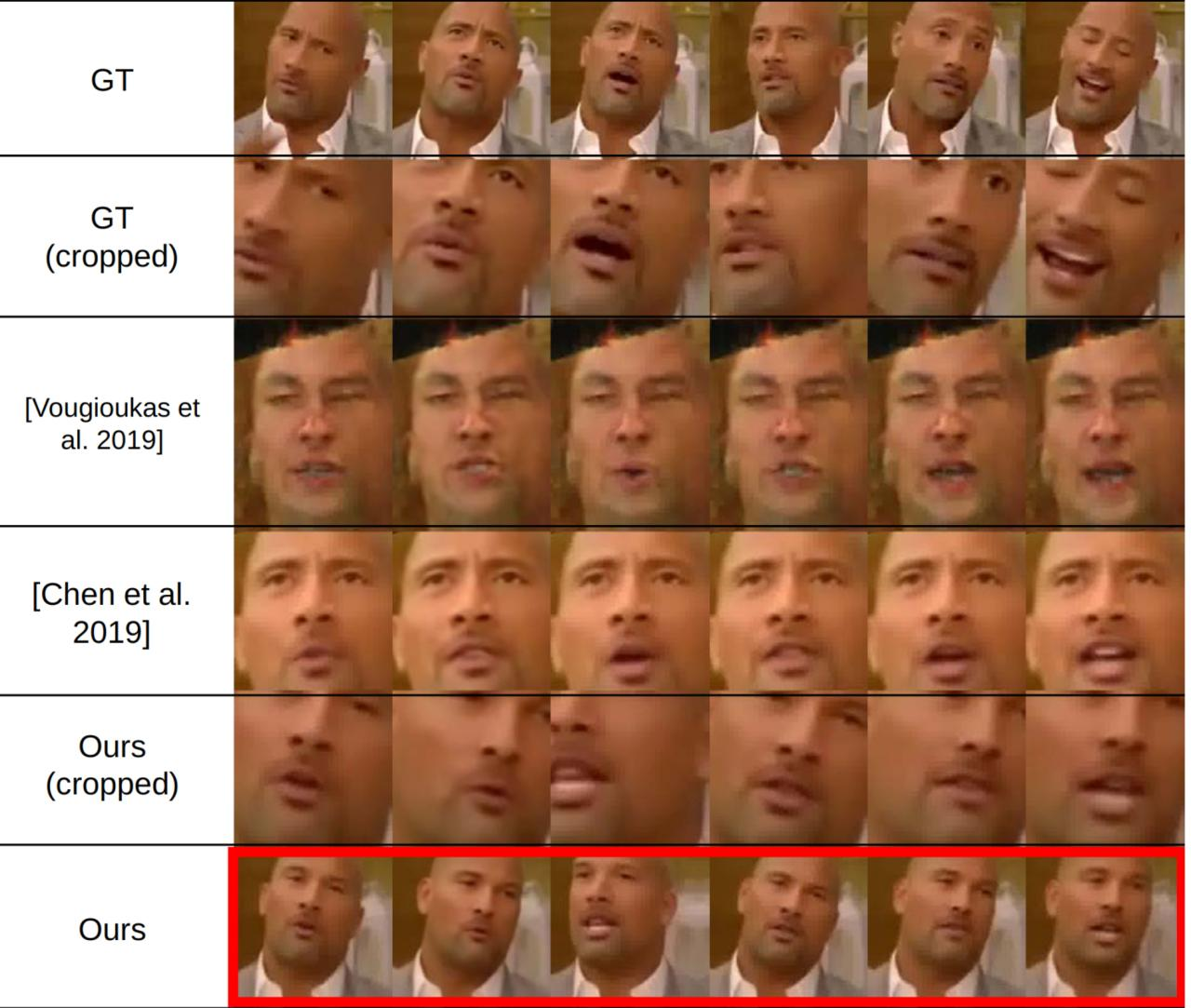
Очень хорошо посравнивались с бейзлайнами, что даже верится. Много метрик, также есть юзерстади. А для отдельного сравнения мотания головой использовали свои бейзлайны на эвристиках, т.к. предыдущие работы не предиктили это. Интересный аблейшн с использованием только одной из двух веток энкодеров.
3. Jukebox: A Generative Model for Music
Авторы статьи: Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever (OpenAI, 2020)
Оригинал статьи :: GitHub project :: Blog
Автор обзора: Александр Бельских (в слэке belskikh)
Прорывная работа от OpenAI по генерации музыки и песен.
Добились правдоподобного звучания голоса, возможности комбинации различных стилей, генерации новых гармоник и дополнения композиций.
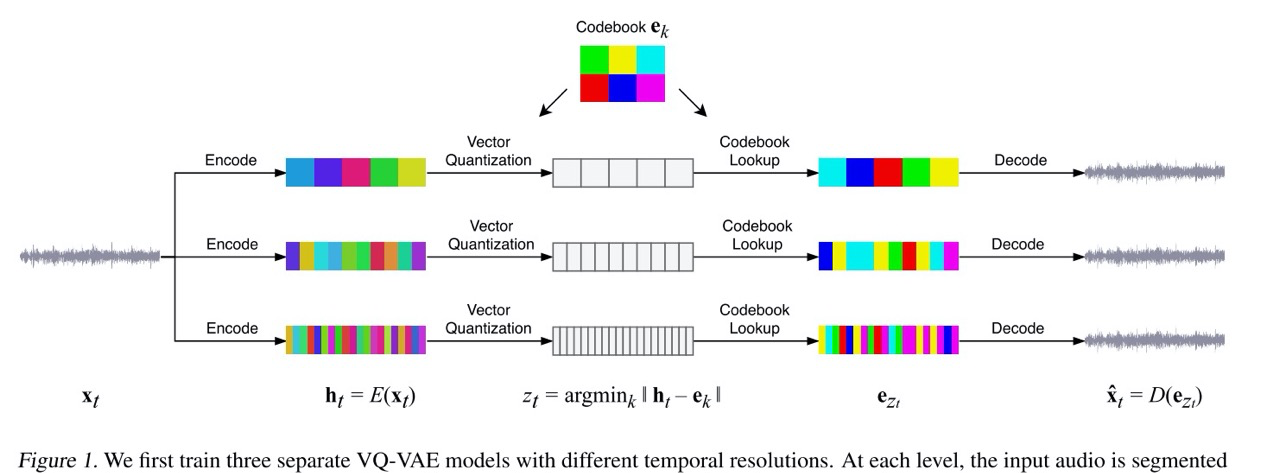
Пайплайн использует hierarchical Vector Quantized VAE (VQ-VAE), чтобы сжать аудио в дискретное пространство с лосс-функцией построенной так, чтоб сохранить максимум музыкальной информации. Поверх этого сжатого пространства используются авторегресионные Sparse Transformers, а также авторегресионные апсемплеры, чтобы расжать представления. Используется три отдельных VQ-VAE для трёх разных уровней сжатия и детализации.
Суть VQ-VAE в том, что он квантизует эмбеддинги в ботлнеке, используя Codebook — это обучаемый набор эмбеддингов. На выходе из энкодера полученных эмбеддинг сравнивается со всеми в Codebook, а в декодер затем подаётся ближайший эмбеддинг из Codebook. Такой способ уменьшения разнообразия помогает декодеру.
После обучения VQ-VAE необходимо научиться генерировать сэмплы из сжатого пространства, причем со всех трёх уровней последовательно. Для этого обучаются Transformers with sparse attention, так как они сота для авторегрессии. Для апсемплинга трансофрмерам необходимо дать conditonal информацию из кодов верхнего уровня. Для этого используют deep residual WaveNet по небольшому окну кодов верхнего уровня, их аутпут добавляют в апсемплеры.
Чтобы задать условия на артиста и жанр, для песен докидывались соответствующие лейблы. Этого не хватало, чтоб генерить внятную и различимую речь, поэтому стали дополнительно задавать условие ещё и текстом. Задать текст как условие в песню задача нетривиальная, так как нужно выровнять относительно времени текст + получить чистую разметку.
Авторы использовали Spleeter, чтобы вытащить голос из каждой песни, а затем NUS AutoLyricsAlign, чтобы получить выравнивание текста по времени на уровне слов. Использовали энкодер-декодер, чтобы задать условие на буквы текста, энкодер выдает фичи из текста, декодер через аттеншн выдает топ-левел токены музыки. Использовался Трансформер.
После того, как обучен VQ-VAE, апсемплеры и приоры топ-уровней, их можно использовать для сэмплирования. Сначала генерируется топ-левел коды по одному токену за раз: сначала генерируется первый токен, затем все предыдущие токены подаются в модель как инпуты, чтобы выдать аутпут токен, conditioned на всех предыдущих.
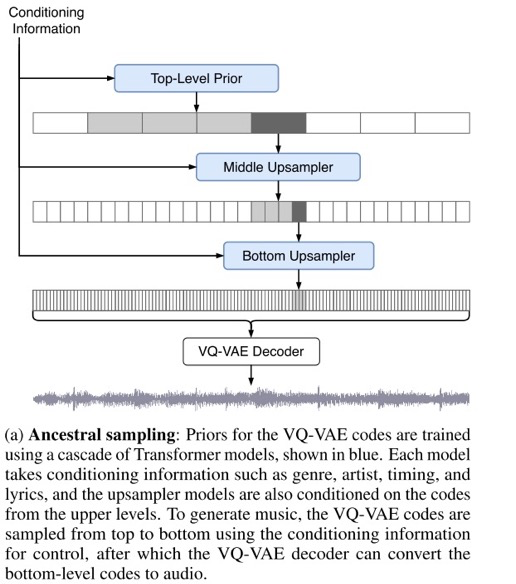
VQ-VAE обучался 3 дня на 256хV100. Апсемплеры обучались 2 недели на 128xV100. Приоры обучались 4 недели на 512xV100.
В результате получилась первая в своём роде модель, которая может генерить правдоподобно звучащие целые песни, комбинировать стили, продолжать композиции и т. п. У текущей модели генерация одной минуты топ-левел токенов занимает примерно час. И примерно 8 часов нужно, чтоб сделать апсемпл одной минуты топ-левел токенов.
Музыка хоть и звучит удивительно хорошо, но всё равно хуже созданной человеком, а голос часто невнятный и напоминает бормотание.Таким образом, применение этой модели на данный момент очень ограничено в первую очередь необходимыми вычислительными ресурсами, но в будущем ресерче авторы надеются найти более быстрые и точные способы генерации.
4. Recipes for building an open-domain chatbot
Авторы статьи: Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston (Facebook AI Research, 2020)
Оригинал статьи :: Open source :: Blog :: Colab
Автор обзора: Артем Родичев (в слэке fuckai)
Фейсбук натренировал и зарелизил SOTA open-domain чатбот модель. Лучшая модель имеет 2.7В параметров, самая большая — 9.4B. По архитектуре — трансформер. На human evaluation модель от FB получилась сильно лучше прошлой SOTA модели — Meena от гугла.
Выложили все — код, модель и датасеты для файнтюна. В дополнении к Meena показали по сути два способа увеличения качества ответов модели:
- файнтюн модели на качественном разнообразном диалоговом корпусе;
- тщательно подобранный способ декодинга ответа.
Суть
Натренировали и сравнили друг с другом разные типы диалоговых моделей:
- retrieval-based — На вход контекст и датасет респонсов, на выходе нужно выдать топ релевантных респонсов из датасета. Использовали Poly-encoder модель, по сути усовершенствованный двубашенный трансформер-енкодер, где одна башня — енкодер контекста, вторая — енкодер респонса, на выходе — dot product, показывающий релевантность респонса для данного контекста.
- генеративные — На входе контекст, на выходе нужно сгенерировать респонс. Архитектура — encoder-decoder transformer, малослойный енкодер, многослойный декодер. Натренировали три базовые модели отличающиеся количеством параметров: 90M, 2.7B (ровно как в Meena), 9.4B.
- retrieve and refine — Смесь двух подходов выше. Сначала получаем список кандидатов из retrieval-based модели, и подаем их в качестве подсказок в генеративную модель для генерации финального ответа.
Все базовые модели тренировали на огромной корпусе реддита. Финальный очищенный корпус имеет 1.5B диалоговых сообщений. Сколько учились и на каком железе не написали.
Для генеративных моделей перебирали разные способы как трейна, так и декодинга для улучшения качества ответов:
- добавление unlikelihood лосса. По сути в лосс добавляем штраф за порождение частотных нграмм, чтобы форсить разнообразие слов и коллокаций при генерации ответа.
- subsequence blocking. Выбрасываем респонсы у которых есть нграмное пересечение с контекстом, или же одна нграмма несколько раз встречается в самом ответе, т.e модель повторяет, то что уже сказала.
- файнтюн. Рассмотрели 4 небольших диалоговых корпуса, от 50K до 200K сообщений в каждом: ConvAI2, Empathetic Dialogs, Wizard of Wikipedia и BST(Blended Skill Talk) — по сути объединение трех первых корпусов. Лучше всего файнтюн заработал на BST.
- декодинг алгоритмы. Пробовали beamsearch с разными beamsize, top-k сэмплирование, sample + rank как в Meena когда вначале сэмплим N ответов, а потом выбираем лучший по log-likelihood. В итоге лучшим оказался beamsearch (beam=10) c ограничением на длину, в котором они форсят генерировать ответ минимум в 20 токенов. Показали что таким образом увеличивается как качество ответов, так и engagingness — вовлеченность человека в беседу с чатботом.
Результаты
Для финального сравнения моделей использовали способ ACUTE-Eval. Состоит из двух шагов: шаг 1 — с помощью асессоров набираем N диалогов между людьми и нашими разными моделями, шаг 2 — даем новым людям-асессором сделать side-by-side сравнение — даем прочитать два диалога с разными чатботами и просим ответить какого чатбота асессор бы предпочел для дальнейшего общения. Такой подход позволяет сравнивать модели просто имея сэмплы диалогов и не имея доступ к самой модели. Именно так и получилось с Meena, где выложили примеры диалогов, но не выложили саму модель.
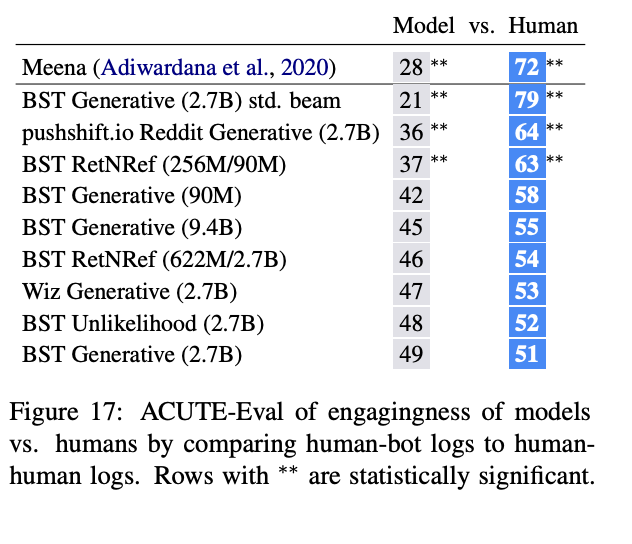
По итогу самая лучшая модель — BST Generative на 2.7B с бимсерчем = 10 и ограничением минимальной длины ответа в 20 токенов. Удивительно, что 9.4B модель проиграла 2.7B модели — на side-by-side сравнении по engagingness 54% проголосовали за 2.7B модель, хотя по perplexity 9.4B получилась лучше.

Еще удивительно, что на side-by-side сравнении диалогов их лучшей модели и диалогов человек-человек, по метрике engagingness они сматчились с человеческими. Недалек тот день, когда можно будет выбросить всех друзей и увлекательно общаться только с чатботами.
В заключении провели анализ ошибок модели, типичные факапы:
- противоречие и забывчивость. Модель в диалоге может противоречить сама себе или повторяться про те вещи, про которые говорила несколько шагов назад;
- выдумывание фактов. Модель может придумать и сгенерировать несуществующие факты о реальном мире, отсутствует понимание причинно-следственных связей;
- чрезмерное использование частотных коллокаций. Намного чаще, чем люди, употребляет безопасные и частотные фразы как “do you like”, “lot of fun”, “have any hobbies”, и другие.
5. One-Shot Object Detection without Fine-Tuning
Авторы статьи: Xiang Li, Lin Zhang, Yau Pun Chen, Yu-Wing Tai, Chi-Keung Tang (HKUST, Hong Kong, Tencent, 2020)
Оригинал статьи
Автор обзора: Александр Бельских (в слэке belskikh)
Микс сиамских сетей с anchor-free детектором FCOS, который позволяет делать детекцию объектов class-agnostic, то есть сетка получает на вход изображение с объектами + отдельный кроп с изображением нужного класса, на выходе выдаёт боксы найденных похожих объектов.
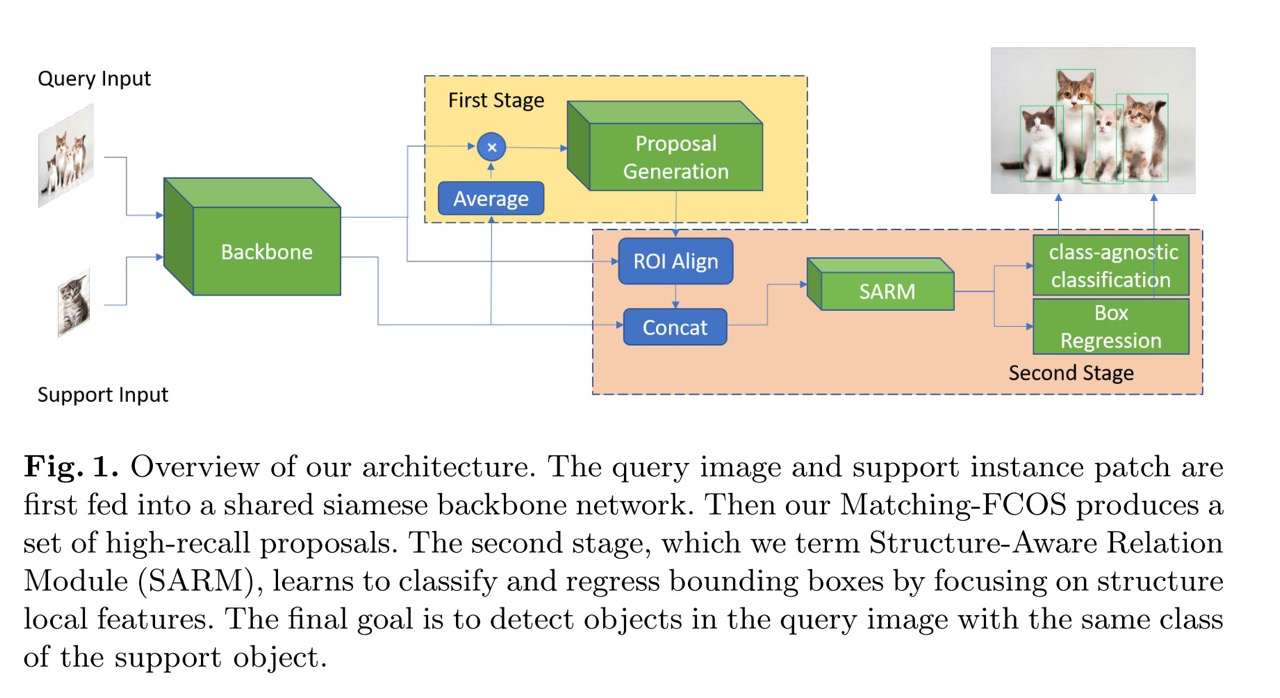
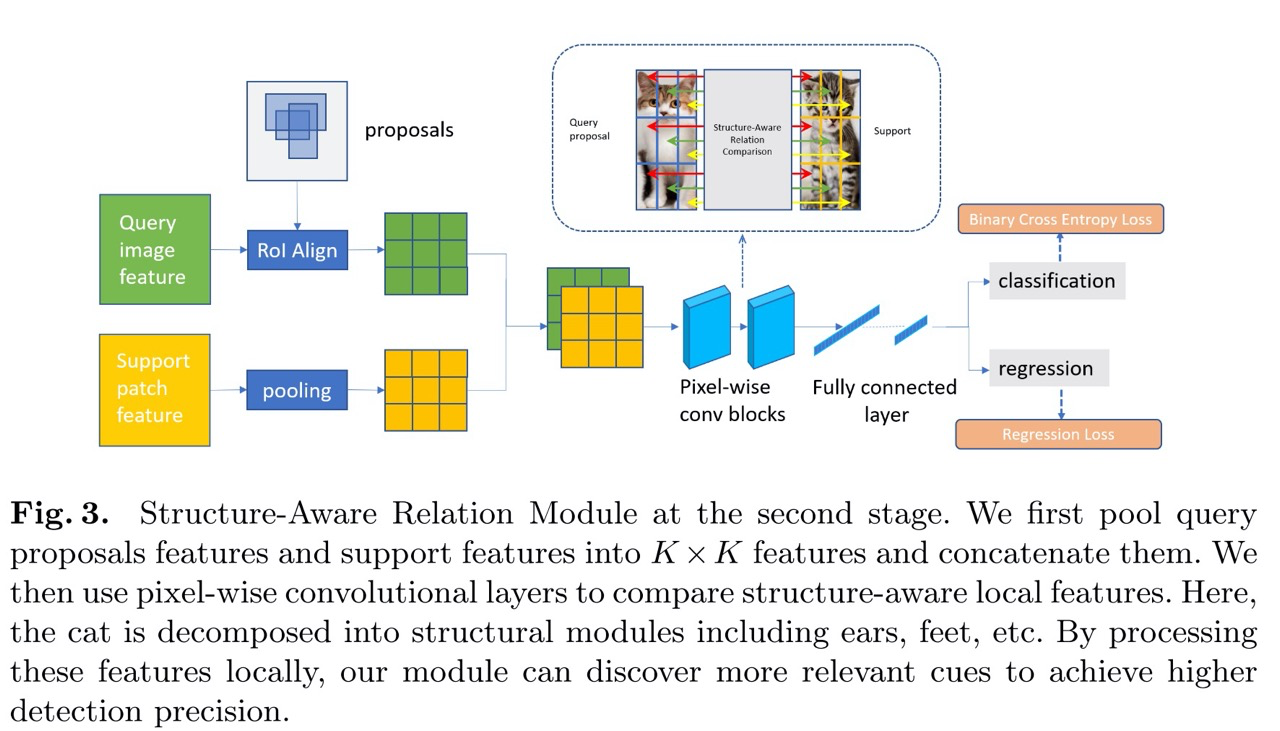
Пайплайн состоит из двух частей: Matching FCOS и Structure-Aware Relation Module.
Модифицированный в сиамскую сеть FCOS детектор, который назвали Matching FCOS.
Он пропускает через один бэкбоун (FPN энкодер-декодер) два изображения — query картинку, на которой мы ищем изображение, и support картинку, это кропнутый объект интереса.
Фичи support картинки потом превращаются в вектор с помощью global average pooling и ими делают dot product с фичами картинки query, получая similarity map. По этой мапе делают ещё несколько сверток в параллель, чтоб получить proposals объектов с помощью обычной FCOS головы (где на каждый пиксель фичемапа предиктится class score и координаты бокса).
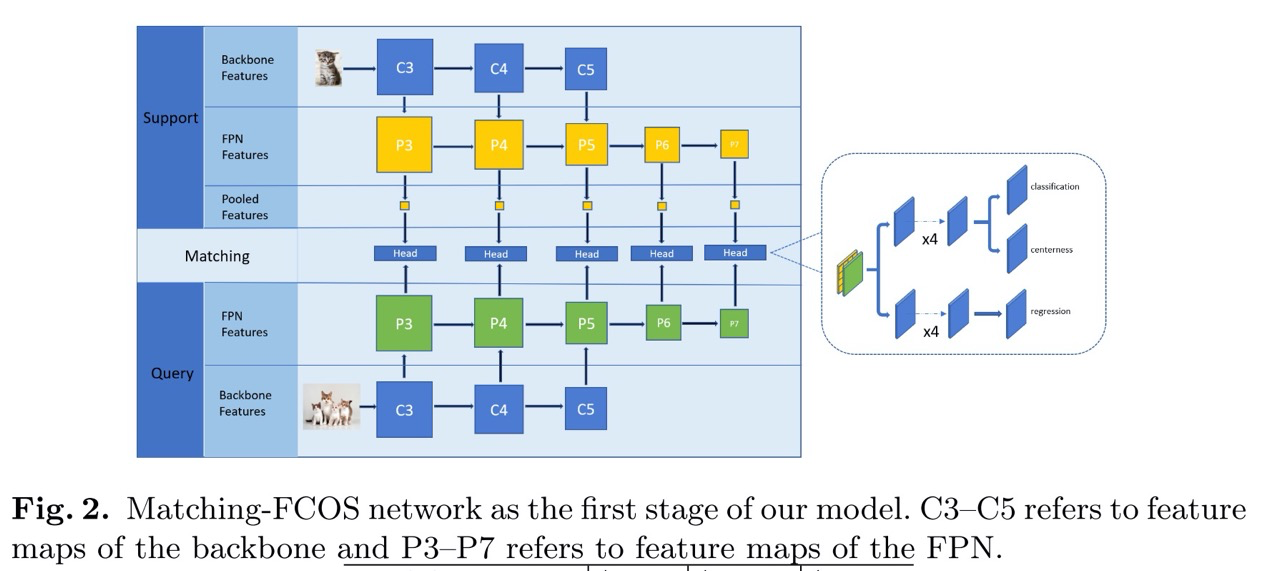
Structure-Aware Relation Module.
В этом модуле также используются фичи query и support картинок, но из query картинки фичи пулятся с помощью RoI Align по тем proposals, что были сгенерированы на этапе 1. Далее они конкатятся и по ним проезжают несколько pixel-wise сверточных слоёв, после чего снова разветвление на два бранча и предикт класса и уточнение координат бокса. Класс 1 в данном случае означает матч объекта с support, а 0 — не матч, то есть background.
По результатам сопоставимы с сотой в One Shot detection, но эту сетку не надо файнтюнить вообще, она архитектурно работает на поиск объектов по запрошенной картинке.
6. f-BRS: Rethinking Backpropagating Refinement for Interactive Segmentation
Авторы статьи: Konstantin Sofiiuk, Ilia Petrov, Olga Barinova, Anton Konushin (Samsung AI Center, Moscow, 2020)
Оригинал статьи :: GitHub project :: Video
Автор обзора: Илья Петров (в слэке ptrvilya)
tl;dr Хотим сделать сегментацию, управляемую юзером, то есть юзер может кликать по картинке, показывая какие области нужно включить в сегментацию, а какие проигнорировать. Как сделать? До нас предлагали после каждого клика просто запускать оптимизацию входа сети, минимизируя ошибку сегментации в указанных пользователем точках. Это точно, но много накладных расходов. Мы предлагаем оптимизировать только небольшой набор параметров внутри сети, а именно scale и bias для фичей фиксированного слоя (специально для этого добавили их как новые параметры) Так мы сохраним точность, сильно подняв скорость. Результат на гифке:
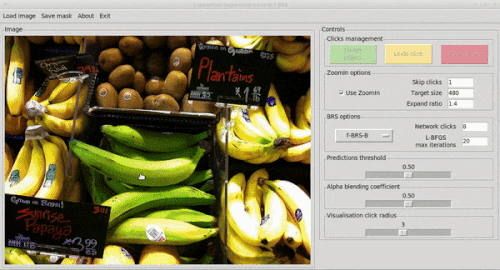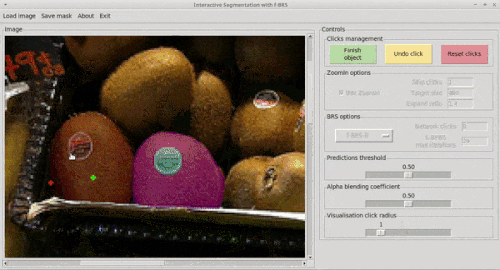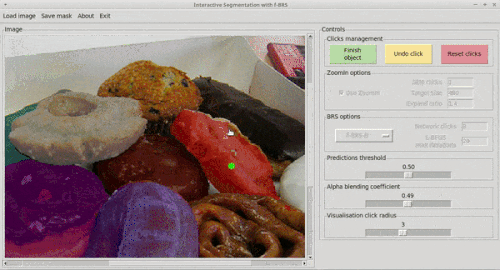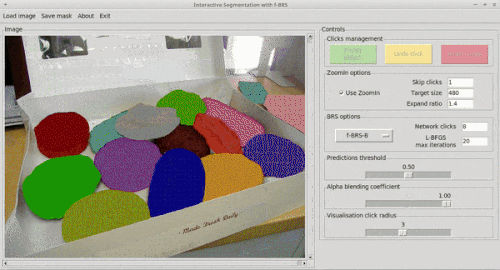
Задача.
Самая распространенная постановка: на вход клики пользователя и картинка, на выходе маска. Другие варианты: четыре экстремальные точки по краям объекта, bbox и мазки.
Клики кодируются в виде карт расстояний с фиксированным радиусом и подаются на вход сети вместе с картинкой (другие варианты — гауссианы с центром в клике или бинарные диски).
Проблема.
Даже хитрая симуляция кликов во время обучения не может заставить предсказанную маску полностью соответствовать им. Год назад предложили следующую идею: после каждого клика минимизировали L2 между предсказанной маской и картой кликов пользователя (1 в позитивных, 0 в негативных, в остальных — игнор), а целевой переменной для оптимизации сделали карты расстояний, подаваемые на вход сети. Своего рода adversarial атака с выгодой для результата. Сильная сторона такого подхода — в теории, если подать много кликов, то результат за счет оптимизации сойдется в целевой маске, раньше такого гарантировать было нельзя. С другой стороны — делать backward несколько раз после каждого клика очень накладно.
Предложенный подход.
Чтобы сохранить преимущества оптимизации, но при этом ускорить, заменили целевые переменные. Оптимизировать промежуточные фичи схожим образом не вариант, так как чем ближе к выходу, тем локальнее будут изменения, при этом вычислительно будет все еще затратно. Вместо этого решили использовать поканальные scale и bias для промежуточных фичей, так как позволяют глобально влиять на промежуточные признаки и результат, но при этом достаточно компактные и находятся близко к выходу. Использовали DeepLabV3+ и три варианта применения scale и bias.

Отдельно адресовали проблему работы с маленькими объектами. В предыдущих подходах шли скользящим окном по картинке и усредняли предсказания. Чтобы сэкономить в вычислениях мы поступили следующим образом (схожие идеи уже встречались в нескольких статьях про детекцию): после нескольких (1-3) первых кликов маска уже примерно приобретает очертания объекта и остается уточнить детали, поэтому можно сделать кроп вокруг этой маски с запасом и дальше работать с ним, расширяя или сужая область кропа при поступлении новых кликов. За счет этого получается лучше предсказывать мелкие детали.
Эксперименты.
Стандартная метрика — число кликов необходимых для достижения заданного порога по IoU, при этом каждый следующий клик ставится в центр замкнутой области с FP или FN наибольшей площади, а общее число кликов ограничено 20.
Для подтверждения того, что без дополнительной оптимизации сходимость к желаемой маске плохая (это справедливо, как минимум для стандартного датасета, используемого во всех статьях — semantic boundaries, качество ) в отдельном эксперименте повысили ограничение до 100 кликов и получили, что после 100 кликов без оптимизации до IoU 90 не сходится в 5 раз больше картинок.
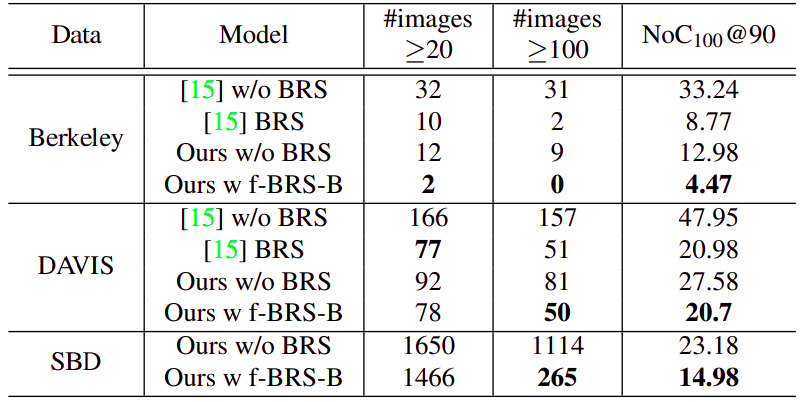
Еще один дополнительный эксперимент — начиная с некоторого момента новые клики можно использовать только в функции потерь для оптимизации, не подавая их на вход самой сети. Возможное объяснение такое: сеть не воспринимает порядок кликов, поэтому добавление слишком большого числа кликов зашумляет вход и приводит к небольшой деградации.
7. Flowtron: an Autoregressive Flow-based Generative Network for Text-to-Speech Synthesis
Авторы статьи: Rafael Valle, Kevin Shih, Ryan Prenger, Bryan Catanzaro (NVIDIA, 2020)
Оригинал статьи :: GitHub project :: Blog
Автор обзора: Александр Бельских (в слэке belskikh)
Пионерская работа от NVIDIA по использованию Flow-based модели для генерации text2speech. Основана на Tacotron2, но обладает большей вариативностью + по дефолту даёт возможность оперировать латентным пространством, давая доступ к интонациям и тембру голоса, к той информации, которая отсутствует в обычном тексте. Эта модель озвучивала ролик.
Авторы предлагают новый способ синтеза мел-спектрограмм — авторегрессионная flow-based генеративная сеть. Она выучивает обратимую функцию, которая мапит распределение по мел-спектрограмме в сферическое гауссово латентное пространство. Обучается модель, просто максимизируя правдоподобие данных.
В такой формулировке можно генерировать семплы, содержащие определенные характеристики речи, находящиеся в пространстве спектрограмм путём нахождения и сэмплирования из соответствующих регионов z-пространства.
Благодаря этому можно выполнять style transfer между семплами, менять спикера или просто делать вариации внутри одного спикера, варьируя стандартное отклонение гауссового распределения.
Модель принимает на вход последовательность кадров мел-спектрограмм, выдавая следующую спектрограмму основываясь только на предыдущей спектрограмме. Эти сэмплы проходят через серию обратимых параметризированных аффинных трансформаций, которые мапят z распределение в x (спектрограмму). Это и есть flow.
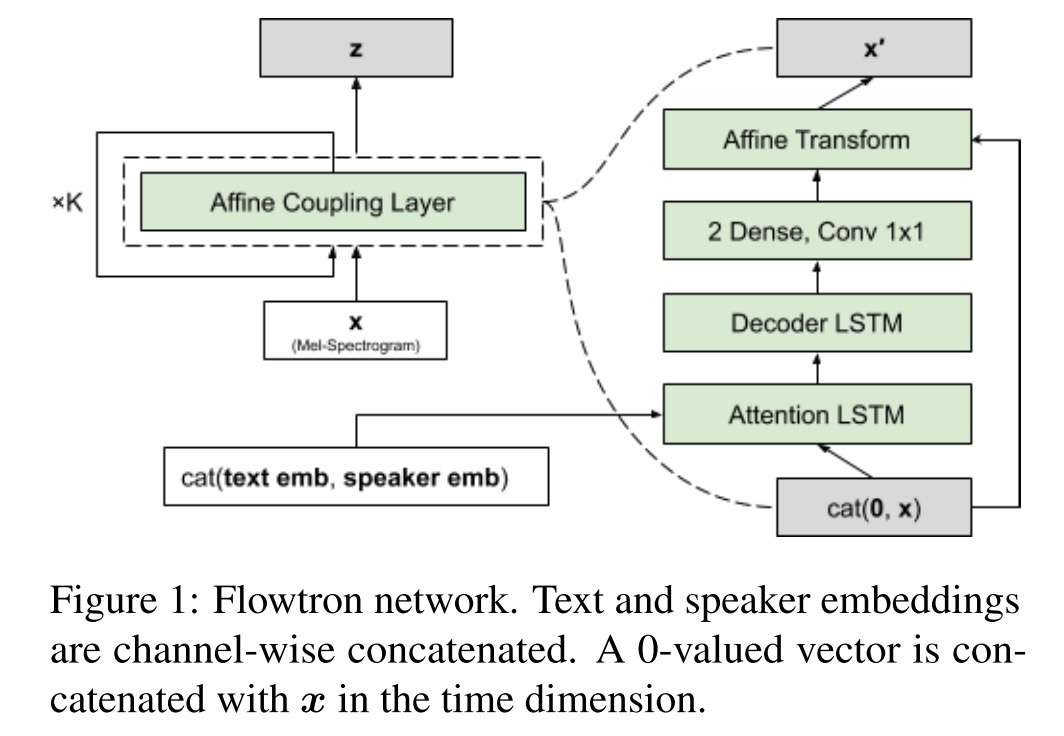
Во время форвард прохода, собираются мел-спектрограммы как вектора и прогоняются через несколько шагов flow, закондишенных на текст и айди спикера. Шагом flow является affine coupling layer, который является типичным для построения обратимых нейронных сетей. Во время инференса процесс происходит наоборот — берётся случайный вектор из Z и прогоняется через модель в обратном режиме.
Модель училась на DGX-1 8хV100.
По Mean Opinion Score модель на одном уровне с Tacotron 2, но обходит его по вариативности и возможностям манипулирования сэмплированием. Сэмплы лучше всего послушать на сайте.


IvanGroza
подборка-подборочка! Спасибо!