
Привет Хабр! В этой статье я хочу поговорить о достаточно мало рассматриваемой теме анализа кода систем повышенной надежности. На хабре много статей о том, что такое хороший статический анализ, но в этой статье я бы хотел рассказать о том, что такое формальная верификация кода, а также объяснить опасность бездумного применения статических анализаторов и стандартов кодирования.
Достаточно много было споров о том, как создавать программное обеспечение повышенной надежности, обсуждались методологии, подходы к организации разработки, инструменты. Но среди всех этих обсуждений теряется то, что разработка софта — это процесс, причем достаточно хорошо изученный и формализованный. И если посмотреть на этот процесс, то можно заметить, что данный процесс фокусируется не только на том, как пишется/генерируется код, а на том, как этот код проверяется. А самое важное то, что для разработки требуется использовать инструменты, которым можно «доверять».
Краткий экскурс завершен, и давайте посмотрим как доказывается надежность кода. Сначала надо разобраться с характеристиками кода, соответствующего требованиям по надежности. Сам термин «надежность кода» выглядит достаточно расплывчато и противоречиво. Поэтому я предпочитаю ничего не придумывать, и при оценке надежности кода руководствуюсь отраслевыми стандартами, например ГОСТ Р ИСО 26262 или КТ-178С. Формулировки в них разные, но идея одинакова: надежный код разработан по единому стандарту (так называемому стандарту кодирования) и количество ошибок времени исполнения в нем минимизировано. Однако, тут не все так просто — стандартами предусмотрены ситуации, когда например соблюдение стандарта кодирования не представляется возможным и такое отступление требуется задокументировать
Стандарты кодирования предназначены для того, чтобы ограничить использование конструкций языка программирования, которые могут быть потенциально опасны. По идее, это должно повышать качество кода, верно? Да, это обеспечивает качество кода, но всегда важно помнить, что 100% соответствие правилам кодирования не является самоцелью. Если код на 100% соответствует правилам какой-нибудь MISRA, то это совсем не значит, что он хороший и правильный. Можно потратить кучу времени на рефакторинг, вычищение нарушений стандарта кодирования, но все это будет впустую если код в итоге будет работать неправильно или содержать ошибки времени исполнения. Тем более, что правила из MISRA или CERT — это обычно только часть стандарта кодирования, принятого на предприятии.
Стандарты предписывают проведение систематических код-ревью для того, чтобы найти дефекты в коде и проанализировать код на стандарты кодирования.
Инструменты статического анализа, обычно используемые для этой цели, хороши в обнаружении недостатков, но они не доказывают, что исходный код не содержит ошибок времени выполнения. А еще многое количество ошибок, обнаруживаемых статическими анализаторами — это на самом деле ложные срабатывания инструментов. В результате, применение этих инструментов не слишком сокращает временные затраты на проверку кода из-за необходимости проверки результатов проверки. Еще хуже, что они могут не обнаружить ошибки времени исполнения, что является неприемлемым для приложений, которые требуют высокой надежности.
Итак, статические анализаторы не всегда в состоянии отловить ошибки времени исполнения. А как их тогда обнаружить и устранить? В этом случае требуется применять формальную верификацию исходного кода.
Прежде всего требуется понять, что же это за зверь? Формальная верификация — это доказательство безошибочности кода при помощи формальных методов. Звучит страшно, но на самом деле — это как доказательство теоремы из матана. Никакой магии тут нет. Данный метод отличается от традиционного статического анализа, так как используется абстрактная интерпретация, а не эвристики. Это дает нам следующее: мы можем доказать, что в коде нет определенных ошибок времени исполнения. Что это за ошибки? Это всякие выходы за границы массива, деление на ноль, переполнение целых и так далее. Их подлость заключается в том, что компилятор соберет код, содержащий такие ошибки (так как такой код синтаксически корректен), но зато при запуске этого кода они проявятся.
Посмотрим на пример. Ниже в спойлерах представлен код для простого ПИ-регулятора:
Запустим проверку при помощи Polyspace Bug Finder, сертифицируемого и квалифицируемого статического анализатора и получим такие результаты:
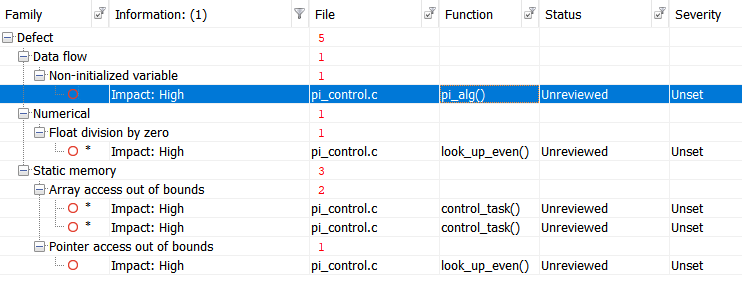
Для удобства, сведем результаты в таблицу:
А теперь верифицируем этот же код при помощи инструмента формальной верификации Polyspace Code Prover:
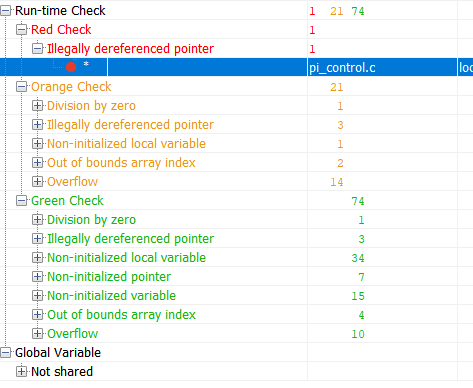
Зеленый цвет в результатах — это код, для которого отсутствие ошибок времени выполнения было доказано. Красный — доказана ошибка. Оранжевый — инструменту не хватило данных. Результаты, помеченные зеленым цветом — самые интересные. Если для части кода доказано отсутствие ошибки времени выполнения, то для этой части кода можно значительно сократить объем тестирования (например, тестирование на робастность уже можно не проводить) А теперь, посмотрим на сводную таблицу потенциальных и доказанных ошибок:
Эта таблица говорит мне о следующем:
На строке 93 была обнаружена ошибка времени выполнения, которая гарантированно произойдет. Остальные предупреждения говорят мне о том, что я либо неправильно настроил верификацию, либо мне надо написать защитный код или побороть их иным способом.
Может показаться что формальная верификация — это очень круто и следует неудержимо верифицировать весь проект. Однако, как и у любого инструмента тут есть ограничения, касающиеся в первую очередь временных затрат. Если коротко — формальная верификация — это медленно. Очень медленно. Быстродействие упирается в математическую сложность как самой абстрактной интерпретации, так и объема верифицируемого кода. Поэтому не стоит пытаться с наскоку верифицировать ядро Linux. Все проекты верификации в Polyspace могут быть разбиты на модули, которые могут быть верифицированы независимо друг от друга, а также у каждого модуля есть своя конфигурация. То есть мы можем настраивать тщательность верификации для каждого модуля отдельно.
Когда вы имеете дело с отраслевыми стандартами, типа КТ-178С или ГОСТ Р ИСО 26262, то вы постоянно сталкиваетесь с такими штуками как «доверие к инструменту» или «квалификация инструмента». Что же это такое? Это такой процесс, в ходе которого вы показываете, что результатам работы инструментов разработки или тестирования, которые были использованы в проекте можно доверять и их ошибки задокументированы. Этот процесс ? тема отдельной статьи, так как не все очевидно. Главное здесь следующее: инструменты, применяющиеся в индустрии всегда идут вместе с набором документов и тестов которые помогают в этом процессе.
На простом примере мы посмотрели на различие между классическим статическим анализом и формальной верификацией. Можно ли применять ее вне проектов требующих следования отраслевым стандартам? Да, конечно, можно. Можно даже попросить пробную версию тут.
К слову, если вам интересно, можно сделать отдельную статью про сертификацию инструментов. Напишите в комментариях, нужна ли такая статья.
Достаточно много было споров о том, как создавать программное обеспечение повышенной надежности, обсуждались методологии, подходы к организации разработки, инструменты. Но среди всех этих обсуждений теряется то, что разработка софта — это процесс, причем достаточно хорошо изученный и формализованный. И если посмотреть на этот процесс, то можно заметить, что данный процесс фокусируется не только на том, как пишется/генерируется код, а на том, как этот код проверяется. А самое важное то, что для разработки требуется использовать инструменты, которым можно «доверять».
Краткий экскурс завершен, и давайте посмотрим как доказывается надежность кода. Сначала надо разобраться с характеристиками кода, соответствующего требованиям по надежности. Сам термин «надежность кода» выглядит достаточно расплывчато и противоречиво. Поэтому я предпочитаю ничего не придумывать, и при оценке надежности кода руководствуюсь отраслевыми стандартами, например ГОСТ Р ИСО 26262 или КТ-178С. Формулировки в них разные, но идея одинакова: надежный код разработан по единому стандарту (так называемому стандарту кодирования) и количество ошибок времени исполнения в нем минимизировано. Однако, тут не все так просто — стандартами предусмотрены ситуации, когда например соблюдение стандарта кодирования не представляется возможным и такое отступление требуется задокументировать
Опасная трясина MISRA и подобных
Стандарты кодирования предназначены для того, чтобы ограничить использование конструкций языка программирования, которые могут быть потенциально опасны. По идее, это должно повышать качество кода, верно? Да, это обеспечивает качество кода, но всегда важно помнить, что 100% соответствие правилам кодирования не является самоцелью. Если код на 100% соответствует правилам какой-нибудь MISRA, то это совсем не значит, что он хороший и правильный. Можно потратить кучу времени на рефакторинг, вычищение нарушений стандарта кодирования, но все это будет впустую если код в итоге будет работать неправильно или содержать ошибки времени исполнения. Тем более, что правила из MISRA или CERT — это обычно только часть стандарта кодирования, принятого на предприятии.
Статический анализ не панацея
Стандарты предписывают проведение систематических код-ревью для того, чтобы найти дефекты в коде и проанализировать код на стандарты кодирования.
Инструменты статического анализа, обычно используемые для этой цели, хороши в обнаружении недостатков, но они не доказывают, что исходный код не содержит ошибок времени выполнения. А еще многое количество ошибок, обнаруживаемых статическими анализаторами — это на самом деле ложные срабатывания инструментов. В результате, применение этих инструментов не слишком сокращает временные затраты на проверку кода из-за необходимости проверки результатов проверки. Еще хуже, что они могут не обнаружить ошибки времени исполнения, что является неприемлемым для приложений, которые требуют высокой надежности.
Формальная верификация кода
Итак, статические анализаторы не всегда в состоянии отловить ошибки времени исполнения. А как их тогда обнаружить и устранить? В этом случае требуется применять формальную верификацию исходного кода.
Прежде всего требуется понять, что же это за зверь? Формальная верификация — это доказательство безошибочности кода при помощи формальных методов. Звучит страшно, но на самом деле — это как доказательство теоремы из матана. Никакой магии тут нет. Данный метод отличается от традиционного статического анализа, так как используется абстрактная интерпретация, а не эвристики. Это дает нам следующее: мы можем доказать, что в коде нет определенных ошибок времени исполнения. Что это за ошибки? Это всякие выходы за границы массива, деление на ноль, переполнение целых и так далее. Их подлость заключается в том, что компилятор соберет код, содержащий такие ошибки (так как такой код синтаксически корректен), но зато при запуске этого кода они проявятся.
Посмотрим на пример. Ниже в спойлерах представлен код для простого ПИ-регулятора:
Посмотреть код
pictrl.c
#include "pi_control.h"
/* Global variable definitions */
float inp_volt[2];
float integral_state;
float duty_cycle;
float direction;
float normalized_error;
/* Static functions */
static void pi_alg(float Kp, float Ki);
static void process_inputs(void);
/* control_task implements a PI controller algorithm that ../
*
* - reads inputs from hardware on actual and desired position
* - determines error between actual and desired position
* - obtains controller gains
* - calculates direction and duty cycle of PWM output using PI control algorithm
* - sets PWM output to hardware
*
*/
void control_task(void)
{
float Ki;
float Kp;
/* Read inputs from hardware */
read_inputs();
/* Convert ADC values to their respective voltages provided read failure did not occur, otherwise do not update input values */
if (!read_failure) {
inp_volt[0] = 0.0048828125F * (float) inp_val[0];
inp_volt[1] = 0.0048828125F * (float) inp_val[1];
}
/* Determine error */
process_inputs();
/* Determine integral and proprortional controller gains */
get_control_gains(&Kp,&Ki);
/* PI control algorithm */
pi_alg(Kp, Ki);
/* Set output pins on hardware */
set_outputs();
}
/* process_inputs computes the error between the actual and desired position by
* normalizing the input values using lookup tables and then taking the difference */
static void process_inputs(void)
{
/* local variables */
float rtb_AngleNormalization;
float rtb_PositionNormalization;
/* Normalize voltage values */
look_up_even( &(rtb_AngleNormalization), inp_volt[1], angle_norm_map, angle_norm_vals);
look_up_even( &(rtb_PositionNormalization), inp_volt[0], pos_norm_map, pos_norm_vals);
/* Compute error */
normalized_error = rtb_PositionNormalization - rtb_AngleNormalization;
}
/* look_up_even provides a lookup table algorithm that works for evenly spaced values.
*
* Inputs to the function are...
* pY - pointer to the output value
* u - input value
* map - structure containing the static lookup table data...
* valueLo - minimum independent axis value
* uSpacing - increment size of evenly spaced independent axis
* iHi - number of increments available in pYData
* pYData - pointer to array of values that make up dependent axis of lookup table
*
*/
void look_up_even( float *pY, float u, map_data map, float *pYData)
{
/* If input is below range of lookup table, output is minimum value of lookup table (pYData) */
if (u <= map.valueLo )
{
pY[1] = pYData[1];
}
else
{
/* Determine index of output into pYData based on input and uSpacing */
float uAdjusted = u - map.valueLo;
unsigned int iLeft = uAdjusted / map.uSpacing;
/* If input is above range of lookup table, output is maximum value of lookup table (pYData) */
if (iLeft >= map.iHi )
{
(*pY) = pYData[map.iHi];
}
/* If input is in range of lookup table, output will interpolate between lookup values */
else
{
{
float lambda; // fractional part of difference between input and nearest lower table value
{
float num = uAdjusted - ( iLeft * map.uSpacing );
lambda = num / map.uSpacing;
}
{
float yLeftCast; // table value that is just lower than input
float yRghtCast; // table value that is just higher than input
yLeftCast = pYData[iLeft];
yRghtCast = pYData[((iLeft)+1)];
if (lambda != 0) {
yLeftCast += lambda * ( yRghtCast - yLeftCast );
}
(*pY) = yLeftCast;
}
}
}
}
}
static void pi_alg(float Kp, float Ki)
{
{
float control_output;
float abs_control_output;
/* y = integral_state + Kp*error */
control_output = Kp * normalized_error + integral_state;
/* Determine direction of torque based on sign of control_output */
if (control_output >= 0.0F) {
direction = TRUE;
} else {
direction = FALSE;
}
/* Absolute value of control_output */
if (control_output < 0.0F) {
abs_control_output = -control_output;
} else if (control_output > 0.0F) {
abs_control_output = control_output;
}
/* Saturate duty cycle to be less than 1 */
if (abs_control_output > 1.0F) {
duty_cycle = 1.0F;
} else {
duty_cycle = abs_control_output;
}
/* integral_state = integral_state + Ki*Ts*error */
integral_state = Ki * normalized_error * 1.0e-002F + integral_state;
}
}
pi_control.h
/* Lookup table structure */
typedef struct {
float valueLo;
unsigned int iHi;
float uSpacing;
} map_data;
/* Macro definitions */
#define TRUE 1
#define FALSE 0
/* Global variable declarations */
extern unsigned short inp_val[];
extern map_data angle_norm_map;
extern float angle_norm_vals[11];
extern map_data pos_norm_map;
extern float pos_norm_vals[11];
extern float inp_volt[2];
extern float integral_state;
extern float duty_cycle;
extern float direction;
extern float normalized_error;
extern unsigned char read_failure;
/* Function declarations */
void control_task(void);
void look_up_even( float *pY, float u, map_data map, float *pYData);
extern void read_inputs(void);
extern void set_outputs(void);
extern void get_control_gains(float* c_prop, float* c_int);
Запустим проверку при помощи Polyspace Bug Finder, сертифицируемого и квалифицируемого статического анализатора и получим такие результаты:
Для удобства, сведем результаты в таблицу:
Посмотреть результаты
| Дефект |
Описание |
Строка |
| Non-initialized variable |
Local variable 'abs_control_output' may be read before being initialized. |
159 |
| Float division by zero |
Divisor is 0.0. |
99 |
| Array access out of bounds |
Attempt to access element out of the array bounds. Valid index range starts at 0. |
38 |
| Array access out of bounds |
Attempt to access element out of the array bounds. Valid index range starts at 0. |
39 |
| Pointer access out of bounds |
Attempt to dereference pointer outside of the pointed object at offset 1. |
93 |
А теперь верифицируем этот же код при помощи инструмента формальной верификации Polyspace Code Prover:
Зеленый цвет в результатах — это код, для которого отсутствие ошибок времени выполнения было доказано. Красный — доказана ошибка. Оранжевый — инструменту не хватило данных. Результаты, помеченные зеленым цветом — самые интересные. Если для части кода доказано отсутствие ошибки времени выполнения, то для этой части кода можно значительно сократить объем тестирования (например, тестирование на робастность уже можно не проводить) А теперь, посмотрим на сводную таблицу потенциальных и доказанных ошибок:
Посмотреть результаты
| Проверка |
Строка |
Описание |
| Out of bounds array index |
38 |
Warning: array index may be outside bounds: [array size undefined] |
| Out of bounds array index |
39 |
Warning: array index may be outside bounds: [array size undefined] |
| Overflow |
70 |
Warning: operation [-] on float may overflow (on MIN or MAX bounds of FLOAT32) |
| Illegally dereferenced pointer |
93 |
Error: pointer is outside its bounds |
| Overflow |
98 |
Warning: operation [-] on float may overflow (result strictly greater than MAX FLOAT32) |
| Division by zero |
99 |
Warning: float division by zero may occur |
| Overflow |
99 |
Warning: operation [conversion from float32 to unsigned int32] on scalar may overflow (on MIN or MAX bounds of UINT32) |
| Overflow |
99 |
Warning: operation [/] on float may overflow (on MIN or MAX bounds of FLOAT32) |
| Illegally dereferenced pointer |
104 |
Warning: pointer may be outside its bounds |
| Overflow |
114 |
Warning: operation [-] on float may overflow (result strictly greater than MAX FLOAT32) |
| Overflow |
114 |
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32) |
| Overflow |
115 |
Warning: operation [/] on float may overflow (on MIN or MAX bounds of FLOAT32) |
| Illegally dereferenced pointer |
121 |
Warning: pointer may be outside its bounds |
| Illegally dereferenced pointer |
122 |
Warning: pointer may be outside its bounds |
| Overflow |
124 |
Warning: operation [+] on float may overflow (on MIN or MAX bounds of FLOAT32) |
| Overflow |
124 |
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32) |
| Overflow |
124 |
Warning: operation [-] on float may overflow (on MIN or MAX bounds of FLOAT32) |
| Overflow |
142 |
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32) |
| Overflow |
142 |
Warning: operation [+] on float may overflow (on MIN or MAX bounds of FLOAT32) |
| Non-uninitialized local variable |
159 |
Warning: local variable may be non-initialized (type: float 32) |
| Overflow |
166 |
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32) |
| Overflow |
166 |
Warning: operation [+] on float may overflow (on MIN or MAX bounds of FLOAT32) |
Эта таблица говорит мне о следующем:
На строке 93 была обнаружена ошибка времени выполнения, которая гарантированно произойдет. Остальные предупреждения говорят мне о том, что я либо неправильно настроил верификацию, либо мне надо написать защитный код или побороть их иным способом.
Может показаться что формальная верификация — это очень круто и следует неудержимо верифицировать весь проект. Однако, как и у любого инструмента тут есть ограничения, касающиеся в первую очередь временных затрат. Если коротко — формальная верификация — это медленно. Очень медленно. Быстродействие упирается в математическую сложность как самой абстрактной интерпретации, так и объема верифицируемого кода. Поэтому не стоит пытаться с наскоку верифицировать ядро Linux. Все проекты верификации в Polyspace могут быть разбиты на модули, которые могут быть верифицированы независимо друг от друга, а также у каждого модуля есть своя конфигурация. То есть мы можем настраивать тщательность верификации для каждого модуля отдельно.
«Доверие» к инструментам
Когда вы имеете дело с отраслевыми стандартами, типа КТ-178С или ГОСТ Р ИСО 26262, то вы постоянно сталкиваетесь с такими штуками как «доверие к инструменту» или «квалификация инструмента». Что же это такое? Это такой процесс, в ходе которого вы показываете, что результатам работы инструментов разработки или тестирования, которые были использованы в проекте можно доверять и их ошибки задокументированы. Этот процесс ? тема отдельной статьи, так как не все очевидно. Главное здесь следующее: инструменты, применяющиеся в индустрии всегда идут вместе с набором документов и тестов которые помогают в этом процессе.
Итоги
На простом примере мы посмотрели на различие между классическим статическим анализом и формальной верификацией. Можно ли применять ее вне проектов требующих следования отраслевым стандартам? Да, конечно, можно. Можно даже попросить пробную версию тут.
К слову, если вам интересно, можно сделать отдельную статью про сертификацию инструментов. Напишите в комментариях, нужна ли такая статья.


Gryphon88
Здравствуйте. Можете чуть подробнее рассмотреть непосредственно процесс верификации? Я пытался разобраться в TLA+ и его применении к МК (книжка Formal Development of a Network-Centric RTOS), там на вход подаётся совсем не сишный код.
rusted_mind Автор
Добрый день! Действительно, в Formal Development of a Network-Centric RTOS верифицировался не код RTOS, а, скорее, спецификация на нее. В статье я показывал верификацию именно кода, так как спецификации могут быть и недоступны (легаси-код, сторонние библиотеки). В современных реалиях, впрочем, для создания систем повышенной надежности применяют модельно-ориентированное проектирование, где модель и есть спецификация системы, и существуют инструменты для формальной верификации моделей (Simulink Design Verifier).
Касательно самого процесса — требуется уточнить, что именно вас интересует: математика под капотом Polyspace Code Prover или процесс верификации софта в целом?
Gryphon88
И то, и другое. Когда я пытался разобраться в предмете, все писали, что из кода верификации нельзя сгенерировать исполняемый код, неважно, темпоральная логика или абстрактные автоматы, обратное на тот момент (2015) тоже было верно. Вот мне и интересно: как (математически) можно подать на верификацию код или симулинковскую модель и получить оценку логической консистентности. Предполагается, что на входе мы имеем спецификации (текстовый ТЗ), а на выходе исполняемый код. Как построен процесс в TDD и откуда берутся артефакты в виде тестов понятно, про TLA+ тоже понятно, там в качестве артефакта спецификация на TLA, а как у вас и как генерируются артефакты?
rusted_mind Автор
С моделью Simulink все достаточно просто, Simulink Design Verifier интегрируется бесшовно в Simulink и умеет парсить модели для создания верифицируемого представления. То же самое и с Code Prover — сначала код «компилируется» (раскрываются дефайны, токены и т.д.), потом результаты такой «компиляции» распарсиваются самим движком инструмента.
>> на входе мы имеем спецификации (текстовый ТЗ), а на выходе исполняемый код
Текстовое ТЗ в код сложно конвертировать, обычно по ТЗ строят модель в Simulink, а потом из модели получают исходный код с помощью генератора исходного кода
Теперь, что касается верификации софта в целом — это долгий процесс, включающий в себя не только статический анализ или формальную верификацию кода, но и юнит-тестирование со сбором покрытия, интеграционное тестирование со сбором покрытия, тестирование на робастность. А еще есть отдельные сверхкритичные системы, для верификации софта которых надо собирать покрытие тестами ассемблера. И конечно, каждый тест должен быть привязан к требованию, как и любая строка кода.