
Сегодня я буду писать о Django — фреймворке, который верно служит мне на протяжении последних пяти лет. Он помог мне преуспеть в разработке высоконагруженных решений, используемых сегодня миллионами пользователей.
Действительно, Python не очень «быстрый» язык программирования, однако он прост, удобен и люди его любят. С точки зрения производительности, он не может быть таким же быстрым, как Go или Node.js, но это становится несущественным, если рассматривать современные инфраструктуры и модульную разработку.
Поскольку я уже несколько лет варюсь в этом «котле разработки на Django», я пришел к нескольким ценным выводам, которыми собираюсь с вами поделиться.

1. Инфраструктура решает
Помимо производительности приложения, первое, что вам нужно — это инфраструктура, которая позволяет вам осуществлять масштабирование, когда приложение достигает своего предела, и Django может легко масштабироваться, если следовать следующим правилам:
- Разделяйте свое приложение на микросервисы, но учитывайте объем данных, передаваемых между ними, тем более, что избыточность данных и частая синхронизация становятся причиной увеличения серверных ресурсов и коммуникаций, а следовательно, и более высоких затрат;
- Используйте Docker-контейнеры, чтобы отправлять свой код в эксплуатацию (прим. пер.: в продакшн);
- Контейнеризации с помощью Docker не достаточно, следовательно, используйте Kubernetes, чтобы управлять контейнерами и контролировать количество реплик;
- Проектируйте свою инфраструктуру с учетом технического обслуживания: правильная позволит вам увеличивать/уменьшать ресурсы сервера без необходимости останавливать работу вашего сервиса;
- Собирайте важные показатели и осуществляйте их мониторинг: количество запросов по какому-либо микросервису и по каждой конечной точке обработки запросов, использование процессора на каждом поде (прим. пер.: под — абстрактный объект Kubernetes), использование процессора на узлах Kubernetes, входящий и выходящий трафик, использование процессора при работе с базой данных и хранилищем. Последнее из перечисленного позволит обнаруживать и решать проблемы на лету — шаг от традиционной диагностики к упреждающему техническому обслуживанию.
2. База данных — вероятная причина проблем
Какое бы ускорение выполнения кода вы не получили, скорее всего оно будет потеряно на стороне базы данных. А именно, скорость ответа конечной точки обработки запросов зависит от того, насколько быстро обрабатывается запрос к базе данных, следовательно, следует проверить следующее:
- С умом выбирайте движок базы данных и сосредоточьтесь на его производительности. Я предпочитаю PostgreSQL, потому что он заработал хорошую репутацию за проверенную архитектуру, надежность, безотказность, целостность данных и производительность;
- При развертывании слоя хранения данных сфокусируйтесь преимущественно на быстрых хранилище и процессоре. Вам наверняка нужно выбрать наилучший вариант количества операций ввода-вывода в секунду (IOPS) и количества доступных ядер процессора;
- Проверьте, что вы создали все необходимые индексы для всех запросов;
- Помните, что слишком много индексов — это плохо, поэтому удалите неиспользуемые или лишние: каждый созданный индекс может улучшить показатели длительности поиска по соответствующему столбцу (оператор SELECT), но снизит скорость записи (операторы INSERT, UPDATE). Django может создать некоторые повторяющиеся индексы, следовательно, вы должны проверить и удалить их.
3. Включите журналы отладки в Django ORM
При разработке чрезвычайно важно следить за тем, какие запросы генерирует ORM, а также за скоростью ответа. Когда вы создаете конечную точку обработки запросов, вы должны убедиться, что время ее ответа менее 100 миллисекунд — именно поэтому запросы должны выполняться не дольше 20 миллисекунд.
Чтобы включить логи и увидеть, за какое время выполняется каждый запрос, используйте следующие строки кода в settings.py:
LOGGING = {
'version': 1,
'handlers': {
'console': {
'class': 'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'level': 'DEBUG',
},
},
'root': {
'handlers': ['console'],
}
}И после перезапуска вы должны увидеть запросы в таком формате:

Первое число представляет собой время выполнения запроса
Если ваш выбор — PostgreSQL, то я рекомендую для просмотра медленных запросов и повторяющихся индексов использовать панель мониторинга производительности pghero.
4. Включите постоянные соединения
Если приложению нужно обрабатывать большое количество запросов, включите поддержку постоянных соединений с базой данных. По умолчанию Django закрывает соединение в конце каждого запроса, а постоянные соединения предотвращают подобную нагрузку на базу данных из-за каждого запроса.
Эти соединения контролируются параметром CONN_MAX_AGE — показателем, который определяет максимальное время существования соединения. Установите подходящее значение в зависимости от вашего объема запросов к точке обработки запросов приложения. Обычно я ограничиваю это время 5 минутами. Убедитесь, что база данных не ограничена в числе одновременных соединений, которое, как правило, по умолчанию установлено в 100 соединений, а этого чаще всего не достаточно в случае высокой нагрузки.
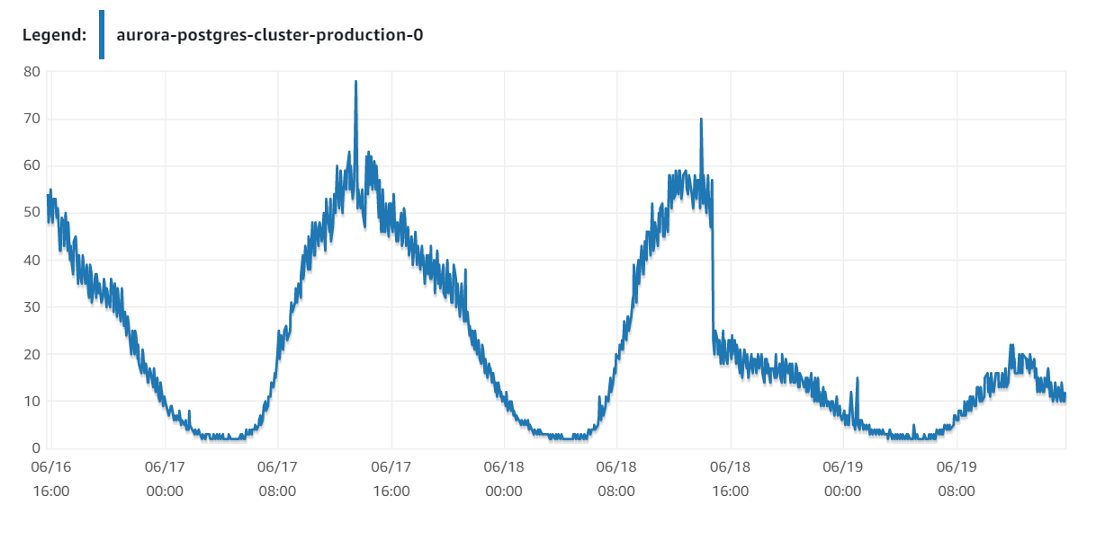
Например, в одном из моих введенных в эксплуатацию проектов после установки этого параметра с 0 до 300 секунд я вдвое уменьшил нагрузку на базу данных. Я воспользовался движком базы данных AWS Aurora с инстансом db.r5.8xlarge, переходя на менее мощный db.r5.4xlarge, чтобы сократить расходы, но, в то же время, обеспечить достаточный уровень производительности.
5. Отключите неиспользуемые приложения и промежуточные слои (middlewares)
По умолчанию у фреймворка есть несколько включенных приложений, которые могут быть бесполезны, особенно если вы используете Django как REST API. Обратите внимание на сессии (sessions) и сообщения (messages) — в таком сценарии работы они бесполезны и просто тратили бы ресурсы и уменьшали скорость обработки. Чем меньше промежуточных слоев вы объявили, тем быстрее будет обрабатываться каждый запрос.

6. Используйте bulk-запросы
Используйте bulk-запросы, чтобы эффективно запрашивать большие наборы данных и уменьшать количество запросов к базе данных. Django ORM может выполнять несколько операций вставки или обновления в одном SQL-запросе.
Если вы собираетесь вставлять более 5000 объектов, задайте batch_size (прим. пер.: размер пакета). Большие пакеты также снизят время обработки и высокое потребление памяти в Python, следовательно, вы должны найти оптимальное количество элементов, в зависимости от размера объекта.

Пример bulk-запроса в Django
7. Уменьшите количество операций выборки с помощью select_related
Если у вас есть две связанные модели и нужно извлечь определенные свойства из обеих, то сделайте предварительную выборку записей через оператор JOIN.
Вот печальный пример, который иллюстрирует генерацию 11 ненужных запросов к базе данных:

С другой стороны, вот правильный способ, с генерацией только одного запроса:

Использование select_related зависит от размеров таблицы, поскольку ORM генерирует SQL-запрос с JOIN. Чтобы добиться оптимизации, условие в операторе WHERE должно возвращать небольшое количество строк.
8. Уменьшите передачу данных между данными и слоем приложения
Сфокусируйтесь на существенно важной информации из базы данных. Выборка необязательных столбцов увеличивает время ответа от базы данных, приводя к расходам на передачу данных.
В Django ORM у класса QuerySet есть функция .only() для выбора определенных полей, или же вы можете вызвать .defer(), чтобы сообщить Django о том, что некоторые поля из базы данных извлекать не нужно:

Выборка имени и электронной почты из таблицы
9. Уменьшите передачу данных между своим API и клиентами
Подобно строгой выборке из базы данных, очень важно возвращать необходимую информацию из API. Поскольку JSON не самый эффективный способ отправки данных, нужно уменьшать его размер с помощью исключения полей, которые не используются клиентом приложения.
Например: размер ответа от определенной конечной точки обработки запросов составляет 1 КБ, но если он вызывается 1 миллион раз в день, то ежедневно будет передаваться 1 ГБ данных, что означает 30 ГБ в месяц — довольно большая цена за использование (прим. пер.: вашего) ресурса.
Заключение
Конечно, легко винить Django или Python, однако, как говорят мои коллеги: «Не вините пианино — вините пианиста».
При разработке высоконагруженного проекта на Django важна любая мелочь. Проблемы тоньше волоса, помноженные на миллионы, приводят к весьма ужасному (прим. пер.: или «мохнатому») положению дел, и вам придется заняться «стрижкой» всех этих проблем.
Любая лишняя миллисекунда, умноженная на миллионы запросов, может привести к чрезмерному потреблению ресурсов. Если приложение уже оптимизировано или хорошо выстроено, увеличение аппаратных ресурсов не спасет положение.
Возьмите пример с Instagram, Pinterest или Disqus — они начали с Django «как есть», и подняли его на следующий уровень. Конечно, это, быть может, уже не тот же самый фреймворк, однако, если в основе лежит здравый смысл, то это только на пользу.
Пишите код эффективно и используйте его повторно, пользуйтесь bulk-запросами, делайте мониторинг, замеряйте и оптимизируйте. Скоро увидимся.



NLO
НЛО прилетело и опубликовало эту надпись здесь