
Прим. перев.: эту статью написал старший DevOps-инженер американской компании Olark, главный продукт которой — live chat — используют тысячи организаций. Автор делится размышлениями о проблеме потребляемых ресуров при сборе логов и результатами своего эксперимента с fluentd, что позволил ему добиться лучшей производительности для некоторых сценариев.

Журналирование – одна из тех вещей, о которых вспоминают только тогда, когда они ломаются. И это вовсе не критика. Дело в том, что логи как таковые не приносят денег. Они позволяют получать представление о том, что делают (или делали) программы, помогая поддерживать работу того, что приносит нам деньги. На малых масштабах (или при разработке) необходимую информацию можно получить, просто выводя сообщения в
С первых дней появления контейнеров и публикации манифеста Twelve-Factor сформировался некий общий паттерн при обработке логов, генерируемых контейнерами:
Популярный переадресатор логов fluentd является проектом CNCF (как и containerd). Со временем он стал стандартом де-факто по чтению, преобразованию, передаче и индексированию логов. При создании кластера Kubernetes на GKE с подключенным Cloud Logging (ранее Stackdriver) вы получите практически тот же самый паттерн — только с разновидностью fluentd от Google.
Именно этот паттерн проявился, когда Olark (компания, в которой работает автор статьи — прим. перев.) впервые начала проводить миграцию сервисов на K8s в виде GKE четыре года назад. И когда мы переросли logging-as-a-service, именно этому паттерну следовали, создавая собственную систему агрегации логов, способную обрабатывать 15-20 тыс. строк в секунду при пиковой нагрузке.
Существуют причины, по которым этот подход хорошо работает и по которым принципы 12-Factor непосредственно рекомендуют выводить логи в стандартные потоки. Дело в том, что он позволяет приложению не заботиться о маршрутизации логов и делает контейнеры легко «наблюдаемыми» (речь про observability) при разработке или в production. И если ваша система логирования навернется, по крайней мере есть некоторая вероятность, что логи останутся на дисках хоста узла кластера.
Недостатком такого подхода является то, что tailing логов сравнительно дорого обходится с точки зрения загрузки процессора. Мы стали обращать внимание на это после того, как в ходе очередной оптимизации logging-системы выяснилось, что fluentd потребляет 1/8 всей квоты запросов CPU в production:
Нам захотелось узнать, во сколько это все обходится: ведь есть же и другие способы направить логи в fluentd. Например, можно воспользоваться forward-портом (речь про использование типа
Чтобы выделить расходы на получение строк логов с помощью tailing'а, я собрал небольшой испытательный стенд. В него вошли следующие компоненты:
Примечания по этой схеме:
Подбор параметров для сравнения проводился достаточно субъективно. Я написал еще одну утилиту для оценки объема логов, которые генерируют узлы из нашего кластера. Не удивительно, что он варьируется в широких пределах: от нескольких десятков строк в секунду до 500 и более на самых загруженных узлах.
Это еще один источник проблем: если использовать DaemonSet, то fluentd должен быть настроен так, чтобы обрабатывать самые загруженные узлы в кластере. В принципе, можно избежать дисбаланса, присваивая соответствующие метки главным генераторам логов и используя мягкие правила раздельного существования (anti-affinity), чтобы равномерно распределить их, но это выходит за рамки данной статьи. Изначально я планировал провести сравнение различных механизмов «доставки» логов при нагрузке в 500/1000 строк в секунду, используя от 1 до 10 log writers.
Первые тесты показали, что главный вклад в загрузку процессора при tailing'е вносило количество строк в секунду — независимо от того, за каким числом лог-файлов мы наблюдали. На двух графиках ниже сравнивается загрузка при 1000 стр/с от одного log writer'а и от 10. Видно, что они почти не отличаются:
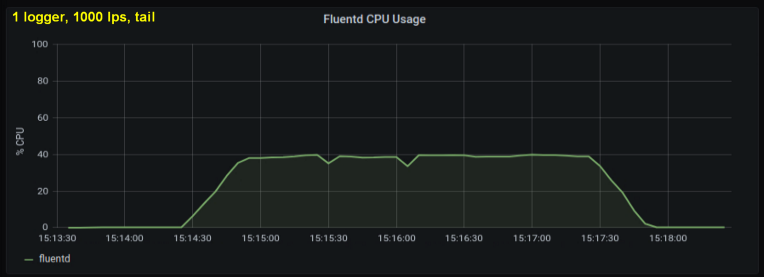
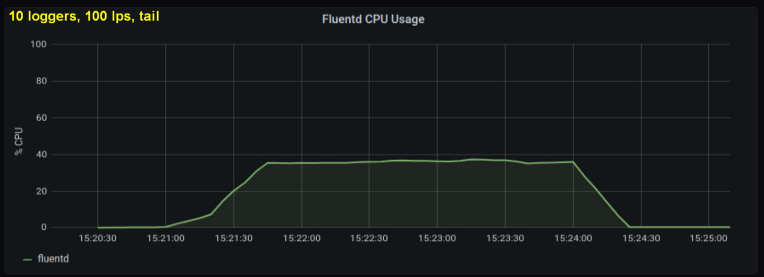
Небольшое отступление: я не включил сюда соответствующий график, но на моей машине оказалось, что десять лог-процессов, пишущих по 100 строк в секунду, демонстрируют более высокую совокупную пропускную способность, нежели один процесс, пишущий по 1000 строк в секунду. Это может быть связано со спецификой моего кода – специально не стал разбираться в этом вопросе.
В любом случае я ожидал, что число открытых лог-файлов будет значимым фактором, но оказалось, что он не особо влияет на результаты. Другой подобной малозначащей переменной стала длина строки. В тесте выше использовалась стандартная длина строки в 100 символов. Я делал прогоны со строками в десять раз длиннее, однако это не оказало заметного влияния на загрузку процессора за время теста, которое во всех случаях составляло 180 секунд.
Учитывая вышесказанное, я решил протестировать 2 writer'а, поскольку один процесс, как мне показалось, упирался в некий внутренний предел. С другой стороны, большее количество процессов тоже не было нужно. Провел тесты с 500 и 1000 строк в секунду. Следующий набор графиков показывает результаты как для tailing'а файлов, так и для forward-порта:

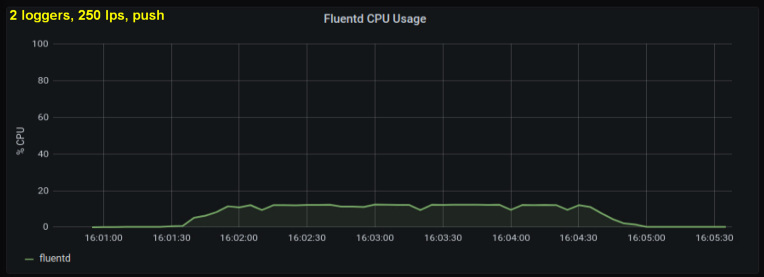
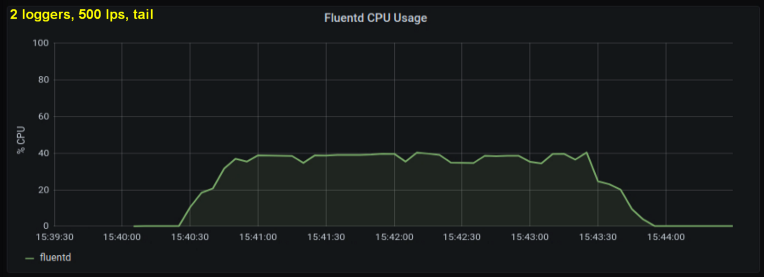

В течение недели я запускал эти тесты множеством разных способов и в итоге пришел к двум ключевым выводам:
Означают ли эти результаты, что нам всем следует писать логи в сокет вместо файлов? Очевидно, все не так просто…
Если бы мы могли так легко изменить способ сбора логов, то большинство из существующих проблем не были бы проблемами. Вывод логов в
Пожалуй, более практичной интерпретацией этих результатов стала бы рекомендация укрупнить узлы. Поскольку fluentd приходится настраивать на работу с самыми загруженными («шумными») узлами, логично сократить их количество. В сочетании с механизмом anti-affinity, который бы равномерно распределял основных генераторов логов, получилась бы отличная стратегия. Увы, изменение размера узлов сопряжено со множеством нюансов и компромиссов, которые выходят далеко за рамки потребностей системы логирования.
Масштаб, очевидно, также имеет значение. На малых масштабах неудобства и дополнительная сложность, пожалуй, нецелесообразны. Кроме того, обычно существуют более насущные проблемы. Если вы только начинаете и «запах свежей краски» еще не выветрился с инженерных процессов, можно заранее стандартизировать формат ведения логов и сократить затраты, воспользовавшись методом с сокетом, при этом не слишком загружая разработчиков.
Для тех же, кто работает с масштабными проектами, выводы этой статьи неуместны, поскольку компании уровня Google провели гораздо более тщательный и наукоемкий анализ проблемы (по сравнению с моим). При таких масштабах, очевидно, вы разворачиваете собственные кластеры и можете делать все что угодно с logging-пайплайном (другими словами, воспользоваться преимуществами обоих подходов).
В заключение позвольте предвосхитить пару вопросов и заранее дать на них ответы. Первый: «Разве эта статья не про fluentd на самом деле? И какое вообще отношение она имеет к Kubernetes?». Ответ на обе части этого вопроса: «Что ж, пожалуй».
Наконец, несколько слов о другом расходуемом ресурсе – памяти. Изначально я собирался включить ее в статью: специально подготовленный для неё dashboard показывает использование памяти fluentd. Но в итоге оказалось, что этот фактор не важен. По результатам тестов максимальный объем используемой памяти не превышал 85 МБ, причем разница между отдельными тестами редко превышала 10 МБ. Такое довольно низкое потребление памяти, очевидно, объясняется тем, что я не использовал плагины вывода с буфером. Важнее то, что оно оказалось почти одинаковым для обоих методов. Да и статья уже становилась слишком объемной…
Следует отметить, что есть еще множество «углов», в которые можно заглянуть, если хочется провести более глубокое тестирование. Например, можно выяснить, в каких состояниях процессора и системных вызовах fluentd проводит больше всего времени, но для этого придется сделать для него соответствующую обертку.
Читайте также в нашем блоге:
Журналирование – одна из тех вещей, о которых вспоминают только тогда, когда они ломаются. И это вовсе не критика. Дело в том, что логи как таковые не приносят денег. Они позволяют получать представление о том, что делают (или делали) программы, помогая поддерживать работу того, что приносит нам деньги. На малых масштабах (или при разработке) необходимую информацию можно получить, просто выводя сообщения в
stdout. Но стоит перейти к распределенной системе, и сразу возникает потребность агрегировать эти сообщения и направлять в некое центральное хранилище, где они принесут наибольшую пользу. Это потребность еще более актуальна, если вы имеете дело с контейнерами на платформе вроде Kubernetes, где процессы и локальное хранилище эфемерны.Привычный подход к обработке логов
С первых дней появления контейнеров и публикации манифеста Twelve-Factor сформировался некий общий паттерн при обработке логов, генерируемых контейнерами:
- процессы выводят сообщения в
stdoutилиstderr, -
containerd(Docker) перенаправляет стандартные потоки в файлы за пределами контейнеров, - а переадресатор (log forwarder) tail'ит эти файлы (т.е. получает последние строки из них) и пересылает данные в базу данных.
Популярный переадресатор логов fluentd является проектом CNCF (как и containerd). Со временем он стал стандартом де-факто по чтению, преобразованию, передаче и индексированию логов. При создании кластера Kubernetes на GKE с подключенным Cloud Logging (ранее Stackdriver) вы получите практически тот же самый паттерн — только с разновидностью fluentd от Google.
Именно этот паттерн проявился, когда Olark (компания, в которой работает автор статьи — прим. перев.) впервые начала проводить миграцию сервисов на K8s в виде GKE четыре года назад. И когда мы переросли logging-as-a-service, именно этому паттерну следовали, создавая собственную систему агрегации логов, способную обрабатывать 15-20 тыс. строк в секунду при пиковой нагрузке.
Существуют причины, по которым этот подход хорошо работает и по которым принципы 12-Factor непосредственно рекомендуют выводить логи в стандартные потоки. Дело в том, что он позволяет приложению не заботиться о маршрутизации логов и делает контейнеры легко «наблюдаемыми» (речь про observability) при разработке или в production. И если ваша система логирования навернется, по крайней мере есть некоторая вероятность, что логи останутся на дисках хоста узла кластера.
Недостатком такого подхода является то, что tailing логов сравнительно дорого обходится с точки зрения загрузки процессора. Мы стали обращать внимание на это после того, как в ходе очередной оптимизации logging-системы выяснилось, что fluentd потребляет 1/8 всей квоты запросов CPU в production:
- Частично это связано с топологией кластера: fluentd размещается на каждом узле для tailing'а локальных файлов (как DaemonSet, выражаясь языком K8s), у вас четырехядерные узлы и приходится резервировать 50% ядра на обработку логов, и… ну, вы поняли.
- Другая часть ресурсов тратится на текстовую обработку, которую также возлагаем на fluentd. В самом деле, кто откажется от возможности подчистить запутанные записи логов?
- Оставшаяся часть идет на inotifywait, который мониторит файлы на диске, обрабатывает считывания и ведет отслеживание.
Нам захотелось узнать, во сколько это все обходится: ведь есть же и другие способы направить логи в fluentd. Например, можно воспользоваться forward-портом (речь про использование типа
forward в source — прим. перев.). Будет ли это дешевле?Практический эксперимент
Чтобы выделить расходы на получение строк логов с помощью tailing'а, я собрал небольшой испытательный стенд. В него вошли следующие компоненты:
- программа на Python для создания определенного количества потоков записи в логи (log writers) с настраиваемыми частотой и размером сообщений;
- файл для docker compose, запускающий:
- fluentd для обработки логов,
- cAdvisor для мониторинга контейнера fluentd,
- Prometheus для сбора метрик cAdvisor,
- Grafana для визуализации данных в Prometheus.
Примечания по этой схеме:
- Log writers генерируют сообщения в едином формате JSON (который использует и containerd) и могут либо записывать их в файлы, либо направлять на forward-порт fluentd.
- При записи в файлы используется класс
RotatingFileHandler, чтобы лучше имитировать условия кластера. - Fluentd настроен «выбрасывать» все записи через
nullи не обрабатывать регулярные выражения или проверять записи на соответствие тегам. Таким образом, основная его работа будет заключаться в получении строк логов. - Кроме того, Prometheus собирает не только метрики cAdvisor, но и показатели пропускной способности с fluentd.
Подбор параметров для сравнения проводился достаточно субъективно. Я написал еще одну утилиту для оценки объема логов, которые генерируют узлы из нашего кластера. Не удивительно, что он варьируется в широких пределах: от нескольких десятков строк в секунду до 500 и более на самых загруженных узлах.
Это еще один источник проблем: если использовать DaemonSet, то fluentd должен быть настроен так, чтобы обрабатывать самые загруженные узлы в кластере. В принципе, можно избежать дисбаланса, присваивая соответствующие метки главным генераторам логов и используя мягкие правила раздельного существования (anti-affinity), чтобы равномерно распределить их, но это выходит за рамки данной статьи. Изначально я планировал провести сравнение различных механизмов «доставки» логов при нагрузке в 500/1000 строк в секунду, используя от 1 до 10 log writers.
Результаты тестирования
Первые тесты показали, что главный вклад в загрузку процессора при tailing'е вносило количество строк в секунду — независимо от того, за каким числом лог-файлов мы наблюдали. На двух графиках ниже сравнивается загрузка при 1000 стр/с от одного log writer'а и от 10. Видно, что они почти не отличаются:
Небольшое отступление: я не включил сюда соответствующий график, но на моей машине оказалось, что десять лог-процессов, пишущих по 100 строк в секунду, демонстрируют более высокую совокупную пропускную способность, нежели один процесс, пишущий по 1000 строк в секунду. Это может быть связано со спецификой моего кода – специально не стал разбираться в этом вопросе.
В любом случае я ожидал, что число открытых лог-файлов будет значимым фактором, но оказалось, что он не особо влияет на результаты. Другой подобной малозначащей переменной стала длина строки. В тесте выше использовалась стандартная длина строки в 100 символов. Я делал прогоны со строками в десять раз длиннее, однако это не оказало заметного влияния на загрузку процессора за время теста, которое во всех случаях составляло 180 секунд.
Учитывая вышесказанное, я решил протестировать 2 writer'а, поскольку один процесс, как мне показалось, упирался в некий внутренний предел. С другой стороны, большее количество процессов тоже не было нужно. Провел тесты с 500 и 1000 строк в секунду. Следующий набор графиков показывает результаты как для tailing'а файлов, так и для forward-порта:
Выводы
В течение недели я запускал эти тесты множеством разных способов и в итоге пришел к двум ключевым выводам:
- Метод с forward-сокетом стабильно потребляет на 30-50% меньше процессорной мощности, чем чтение строк из файлов логов при том же объеме. Одно возможное объяснение (по крайней мере, для части наблюдаемого различия) состоит в том, что сериализацией данных в messagepack теперь занимается лог-клиент вместо fluentd. Когда fluentd читает записи логов с диска, он получает текст и вынужден конвертировать его в messagepack. С другой стороны, когда мой Python-клиент отправляет логи на forward-порт, записи конвертируются перед отправкой. Даже если бы вся разница в результатах объяснялась этой особенностью, преимущество такого подхода сохранялось бы: выполнение подобной работы на уровне клиента могло бы оказаться более эффективным, нежели резервирование процессорных мощностей под fluentd, чтобы тот делал это на каждом узле.
- Вторым важным выводом стало осознание того, что основной вклад в загрузку CPU вносит число строк в секунду, а не количество отдельных источников. И этот вывод оказался справедлив как для tailing'а, так и метода с forward-портом. Эти два графика показывают результаты теста, аналогичного первому (1000 строк от одного writer'а и от 10 writer'ов), но в этот раз для forward-порта:


Означают ли эти результаты, что нам всем следует писать логи в сокет вместо файлов? Очевидно, все не так просто…
Если бы мы могли так легко изменить способ сбора логов, то большинство из существующих проблем не были бы проблемами. Вывод логов в
stdout сильно упрощает наблюдение за контейнерами и работу с ними в процессе разработки. Вывод логов обоими способами в зависимости от контекста сильно увеличит сложность — аналогично её увеличит и настройка fluentd для визуализации логов при разработке (например, с помощью плагина вывода в stdout).Пожалуй, более практичной интерпретацией этих результатов стала бы рекомендация укрупнить узлы. Поскольку fluentd приходится настраивать на работу с самыми загруженными («шумными») узлами, логично сократить их количество. В сочетании с механизмом anti-affinity, который бы равномерно распределял основных генераторов логов, получилась бы отличная стратегия. Увы, изменение размера узлов сопряжено со множеством нюансов и компромиссов, которые выходят далеко за рамки потребностей системы логирования.
Масштаб, очевидно, также имеет значение. На малых масштабах неудобства и дополнительная сложность, пожалуй, нецелесообразны. Кроме того, обычно существуют более насущные проблемы. Если вы только начинаете и «запах свежей краски» еще не выветрился с инженерных процессов, можно заранее стандартизировать формат ведения логов и сократить затраты, воспользовавшись методом с сокетом, при этом не слишком загружая разработчиков.
Для тех же, кто работает с масштабными проектами, выводы этой статьи неуместны, поскольку компании уровня Google провели гораздо более тщательный и наукоемкий анализ проблемы (по сравнению с моим). При таких масштабах, очевидно, вы разворачиваете собственные кластеры и можете делать все что угодно с logging-пайплайном (другими словами, воспользоваться преимуществами обоих подходов).
В заключение позвольте предвосхитить пару вопросов и заранее дать на них ответы. Первый: «Разве эта статья не про fluentd на самом деле? И какое вообще отношение она имеет к Kubernetes?». Ответ на обе части этого вопроса: «Что ж, пожалуй».
- Мое общее представление и опыт подсказывают, что этот инструмент – обычное явление при tailing'е файлов в Linux в ситуациях, когда у вас много дискового I/O. Я не делал тесты с другим переадресатором логов вроде Logstash, но было бы интересно посмотреть на их результаты.
- Что касается Kubernetes, разница в загрузке CPU, которая наблюдалась, не имеет к нему никакого отношения. Думаю, что аналогичные результаты вы получите независимо от того, где будете запускать своих сборщиков и обработчиков логов. Эта статья скорее выступает конкретным предостережением для тех, кто работает с Kubernetes, поскольку метод с tailing'ом используется по умолчанию в большинстве кластеров Kubernetes-as-a-Service.
Наконец, несколько слов о другом расходуемом ресурсе – памяти. Изначально я собирался включить ее в статью: специально подготовленный для неё dashboard показывает использование памяти fluentd. Но в итоге оказалось, что этот фактор не важен. По результатам тестов максимальный объем используемой памяти не превышал 85 МБ, причем разница между отдельными тестами редко превышала 10 МБ. Такое довольно низкое потребление памяти, очевидно, объясняется тем, что я не использовал плагины вывода с буфером. Важнее то, что оно оказалось почти одинаковым для обоих методов. Да и статья уже становилась слишком объемной…
Следует отметить, что есть еще множество «углов», в которые можно заглянуть, если хочется провести более глубокое тестирование. Например, можно выяснить, в каких состояниях процессора и системных вызовах fluentd проводит больше всего времени, но для этого придется сделать для него соответствующую обертку.
P.S. от переводчика
Читайте также в нашем блоге:




drakmail
На относительно небольших масштабах (примерно 300 записей в секунду) при поверхностном анализе потребления ресурсов заметил, что fluentbit гораздо более скромный в потреблении CPU
iwram
Да, fluentbit потребляет меньше ресурсов, но в прод так его не пустил т.к. вроде агент работает, а фактически данные не собирает и не отправляет — перезапустишь, работает, пройдет немного времени снова тоже самое. с агентом fluentd такого не наблюдал.
n_bogdanov Автор
Стоит экспортер настроить на это дело