
Прим. перев.: в конце января Percona опубликовала результаты своего небольшого сравнения производительности для СУБД PostgreSQL, запущенной на x86- и ARM-инстансах AWS. Результаты получились интересными даже с учетом всех допущений, сделанных самими авторами и отмеченных комментаторами оригинальной статьи. А чтобы вы могли сделать собственные выводы, предлагаем вниманию перевод этого материала.
Ожидаемый рост количества ARM-процессоров в дата-центрах уже довольно давно является горячей темой для обсуждения, и нам было любопытно узнать, как они справятся с PostgreSQL. Основным препятствием на этом пути была недоступность в целом серверов на базе ARM-чипов для тестирования и оценки. Все изменилось после того, как в 2018 году AWS представила линейку инстансов на основе ARM-процессоров. Впрочем, особого ажиотажа не последовало: многие посчитали их «экспериментальным» предложением. Мы тоже опасались рекомендовать эти инстансы для критически значимого применения и не прилагали особых усилий для их оценки. Но когда в мае 2020 было анонсировано второе поколение инстансов на основе Graviton2, решили пересмотреть свое отношение. Нужно было объективно взглянуть на показатель цена/производительность новых машин при работе с PostgreSQL.
Важно: Обратите внимание, что неверно (хотя и заманчиво) воспринимать результаты как сравнение производительности PostgreSQL на x86 и ARM-процессорах. В этих тестах сравнивается производительность PostgreSQL в двух виртуальных облачных инстансах, и это подразумевает гораздо большее число движущихся частей, нежели только CPU. Мы в первую очередь фокусируемся на соотношении цены и производительности двух конкретных экземпляров AWS EC2, основанных на двух разных архитектурах.
Тестовый стенд
Для теста мы выбрали два похожих инстанса. Первый — более старый m5d.8xlarge, второй — новый m6gd.8xlarge с Graviton2 на борту. Оба инстанса идут с локальным эфемерным хранилищем, которое мы и задействуем. Использование весьма быстрых локальных дисков должно помочь выявить отличия в других частях системы и избежать влияния облачного хранилища. Инстансы нельзя назвать идентичными (это видно из их характеристик, приведенных ниже), но они достаточно близки, чтобы считаться принадлежащими к одному и тому же классу. Мы использовали AMI Ubuntu 20.04 и PostgreSQL 13.1 из репозитория PGDG (PostgreSQL Global Development Group). Тесты проводились с маленькими (in-memory) и большими (io-bound) базами данных.
Инстансы
Спецификации и стоимость on-demand для инстансов приведены согласно прайсу AWS для Linux в регионе Northern Virginia. При текущих ценах m6gd.8xlarge обходится на 25% дешевле.
Инстанс Graviton2 (ARM)
Инстанс: m6gd.8xlarge
Виртуальные CPU: 32
Память: 128 Гб
Хранилище: 1 x 1900 NVMe SSD (1,9 Тб)
Цена: 1,4464 USD в час
Обычный инстанс (x86)
Инстанс: m5d.8xlarge
Виртуальные CPU: 32
Память: 128 Гб
Хранилище: 2 x 600 NVMe SSD (1,2 Тб)
Цена: 1,808 USD в час
Настройки ОС и PostgreSQL
В качестве операционной системы для инстансов выбран образ Ubuntu 20.04.1 LTS AMI (Amazon Machine Image) — на стороне системы ничего не менялось. На m5d.8xlarge два локальных диска NVMe объединены в одно RAID0-устройство. PostgreSQL устанавливался из DEB-пакетов из репозитория PGDG.
Строка с версией PostgreSQL подтверждает архитектуру ОС:
postgres=# select version();
version
----------------------------------------------------------------------------------------------------------------------------------------
PostgreSQL 13.1 (Ubuntu 13.1-1.pgdg20.04+1) on aarch64-unknown-linux-gnu, compiled by gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0, 64-bit
(1 row)NB: aarch64 расшифровывается как 64-битная ARM-архитектура.
Для тестирования использовалась следующая конфигурация PostgreSQL:
max_connections = '200'
shared_buffers = '32GB'
checkpoint_timeout = '1h'
max_wal_size = '96GB'
checkpoint_completion_target = '0.9'
archive_mode = 'on'
archive_command = '/bin/true'
random_page_cost = '1.0'
effective_cache_size = '80GB'
maintenance_work_mem = '2GB'
autovacuum_vacuum_scale_factor = '0.4'
bgwriter_lru_maxpages = '1000'
bgwriter_lru_multiplier = '10.0'
wal_compression = 'ON'
log_checkpoints = 'ON'
log_autovacuum_min_duration = '0'Тесты pgbench
Прежде всего мы провели предварительное тестирование с помощью pgbench — инструмента категории «micro-benchmarking», доступного в PostgreSQL. Он позволяет протестировать различные комбинации числа клиентов и заданий, например:
pgbench -c 16 -j 16 -T 600 -rЗдесь 16 клиентских соединений и, соответственно, 16 заданий, которые эти соединения обслуживают.
Чтение/запись без контрольной суммы
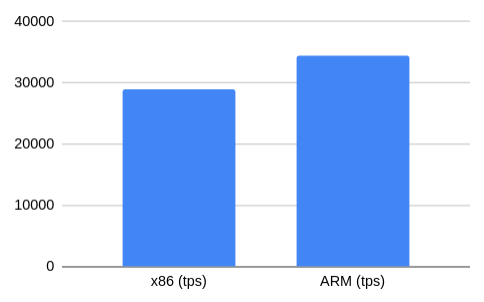
По умолчанию pgbench создает нагрузку на чтение и запись, аналогичную TPC-B. С ее помощью мы протестировали экземпляр PostgreSQL с отключенными контрольными суммами.
ARM-инстанс оказался быстрее на 19%.
x86 (tps): 28878
ARM (tps): 34409
Чтение/запись с контрольной суммой
Было интересно, оказывает ли подсчет контрольных сумм какое-либо влияние на производительность из-за различий в архитектуре в случае активации подсчета контрольной суммы на уровне PostgreSQL. Для версий PostgreSQL, начиная с 12-й, включить такой подсчет можно с помощью утилиты pg_checksum:
pg_checksums -e -D $PGDATAx86 (tps): 29402
ARM (tps): 34701

К нашему удивлению, результаты оказались чуть лучше! Поскольку разница составляет всего 1,7%, мы рассматриваем ее как обычный шум. По крайней мере, можно сделать вывод, что активация подсчета контрольных сумм не приводит к какому-либо заметному снижению производительности на этих современных процессорах.
Чтение без контрольной суммы
Считается, что read-only-нагрузки требовательны с процессору. Поскольку размер базы данных позволяет целиком разместить ее в оперативной памяти, можно исключить факторы, связанные с IO.
x86 (tps): 221436,05
ARM (tps): 288867,44

Результаты показывают рост числа tps ARM-инстанса на 30% по сравнению с x86.
Чтение с контрольной суммой
Хотелось проверить, сможет ли включение подсчета контрольных сумм повлиять на значения tps, когда нагрузка становится ориентированной чисто на процессор.
x86 (tps): 221144,3858
ARM (tps): 279753,1082
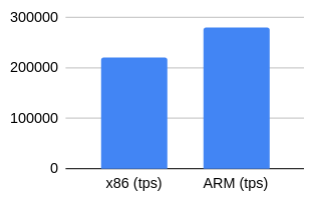
Результаты оказались очень близки к предыдущим — преимущество ARM составило 26,5%.
Тесты pgbench показали, что разрыв между архитектурами увеличивается с ростом ориентированности нагрузки на процессор. Какого-либо снижения производительности после активации контрольных сумм замечено не было.
Примечание по контрольным суммам
PostgreSQL вычисляет и записывает контрольную сумму страниц, когда те записываются в буферный пул (буферный массив) и считываются из него (подробную статью об этом см. здесь — прим. перев.). Кроме того, hint bits всегда журналируются при включении контрольных сумм, что увеличивает давление WAL на IO. Для точной оценки общего вклада контрольных сумм в снижение производительности потребуется более длительное и масштабное тестирование, подобное тому, которое было проведено с sysbench-tpcc…
Тестирование с помощью sysbench-tpcc
Мы решили сделать более детальное сравнение с помощью утилиты sysbench-tpcc. Больше всего интересовал случай, когда база данных помещается в память. Кстати, сама PostgreSQL без проблем работала на ARM-сервере, а вот sysbench оказался гораздо более привередливым (в сравнении с запуском этой утилиты на x86).
Каждый раунд тестирования состоял из нескольких шагов:
Восстановить каталог данных нужного размера (10/200).
Провести 10-минутный разогревочный тест с теми же параметрами, что и у основного.
Создать контрольную точку на стороне PG.
Провести основной тест.
In-memory, 16 потоков:
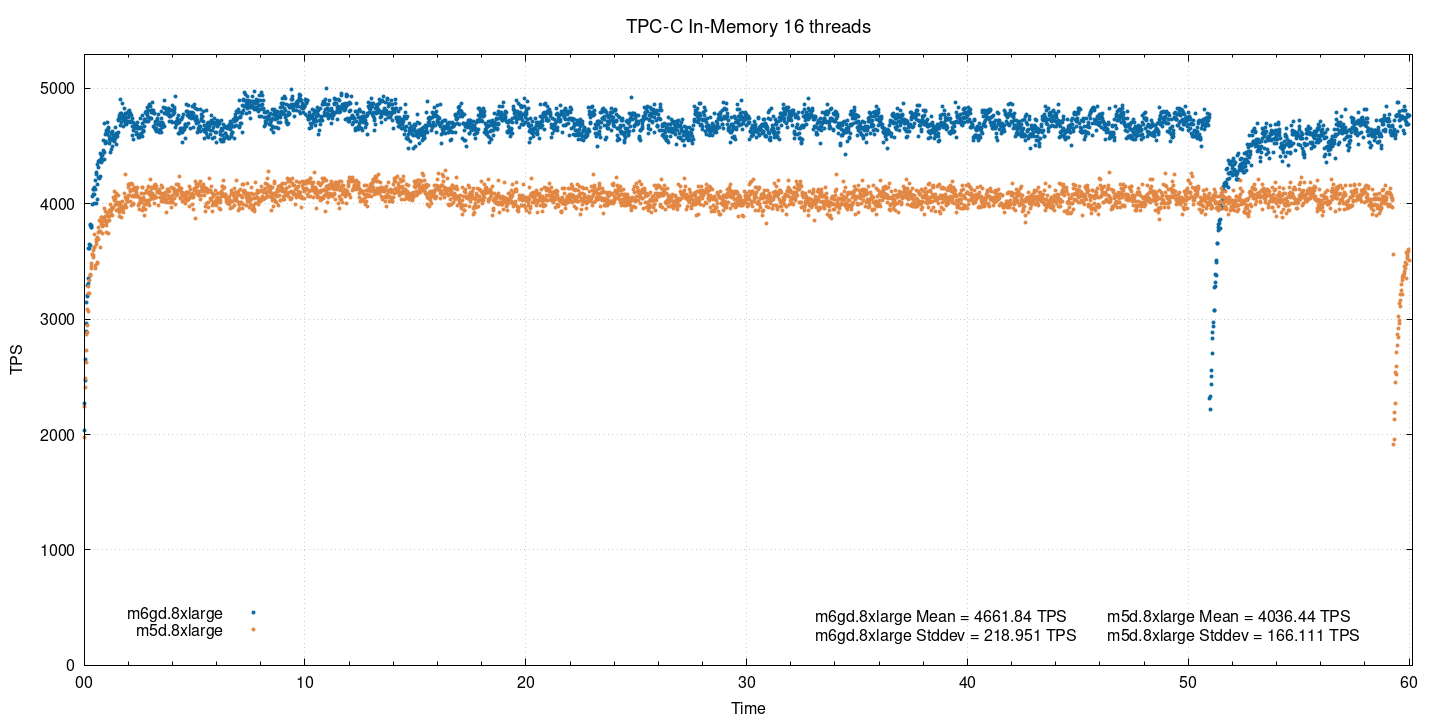
При такой умеренной нагрузке ARM-инстанс примерно на 15,5% опережает х86. Здесь и далее процентная разница основана на среднем значении tps.
Вам, наверное, интересно, с чем связан внезапный провал в производительности ближе к концу теста. Все дело в checkpoint'инге из-за full_page_writes. Хотя при проведении in-memory-тестирования использовалось распределение Парето, значительный объем страниц записывался после каждой контрольной точки. В данном случае инстанс с большей производительностью раньше активировал механизм контрольной точки WAL, чем его более медленный «товарищ». Эти провалы будут присутствовать во всех проведенных тестах.
In-memory, 32 потока:
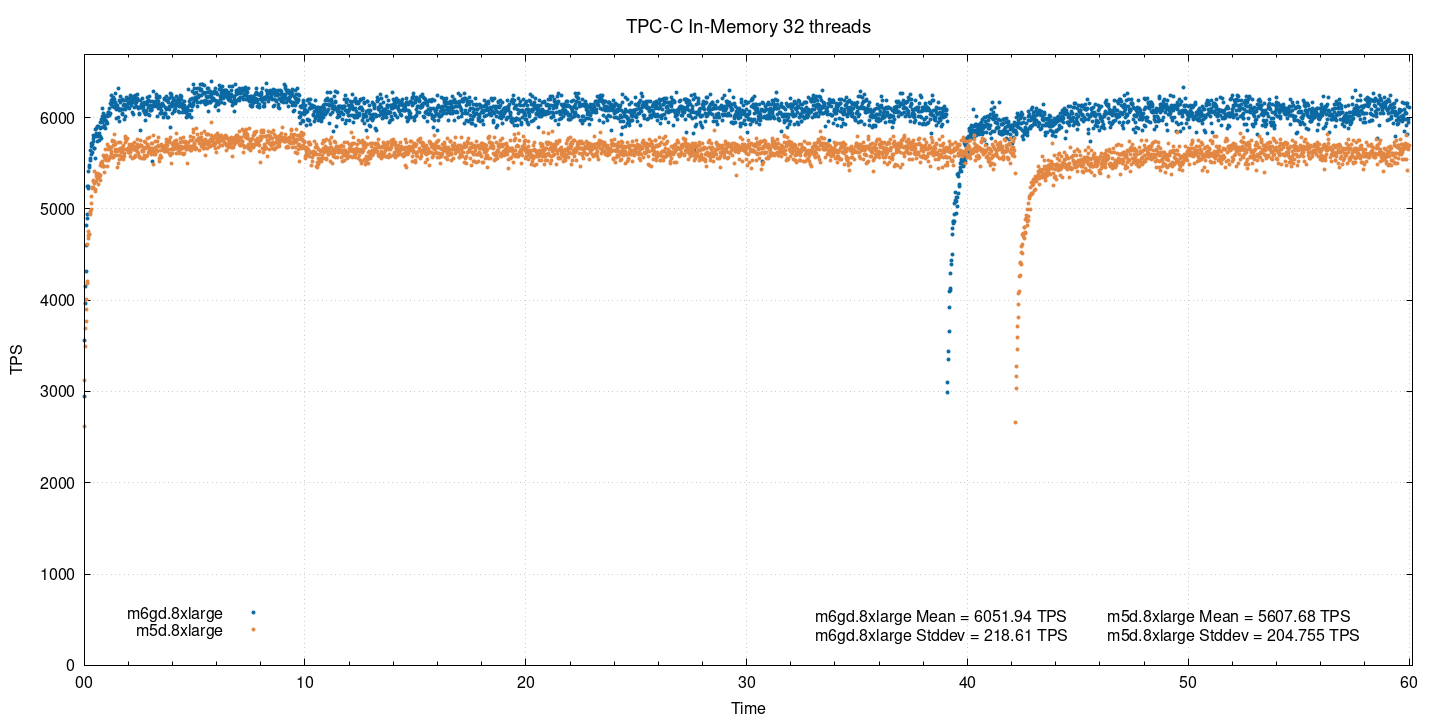
Когда параллелизм увеличился до 32, разница в производительности сократилась почти до 8%.
In-memory, 64 потока:
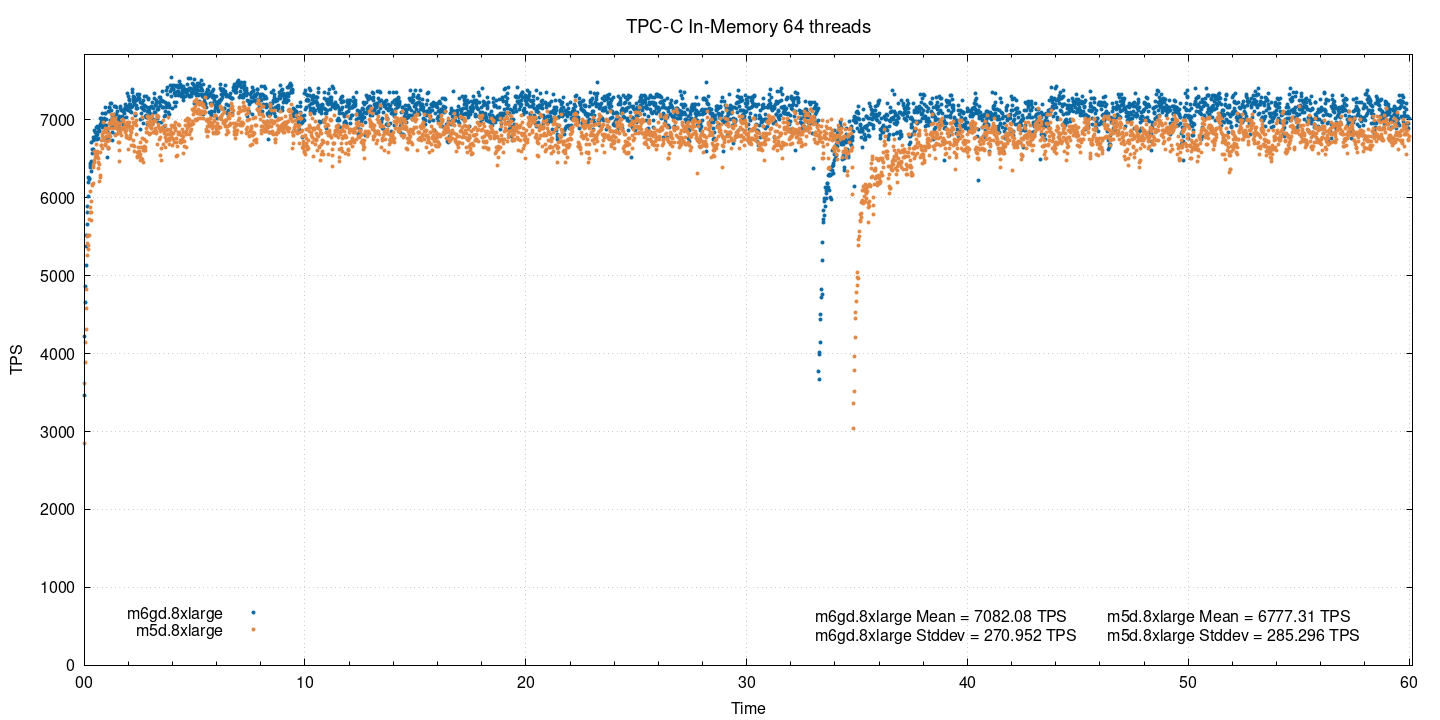
Подталкивая инстансы к точке насыщения (как помните, в обоих по 32 CPU), мы наблюдаем дальнейшее сокращение разницы (до 4,5%).
In-memory, 128 потоков:
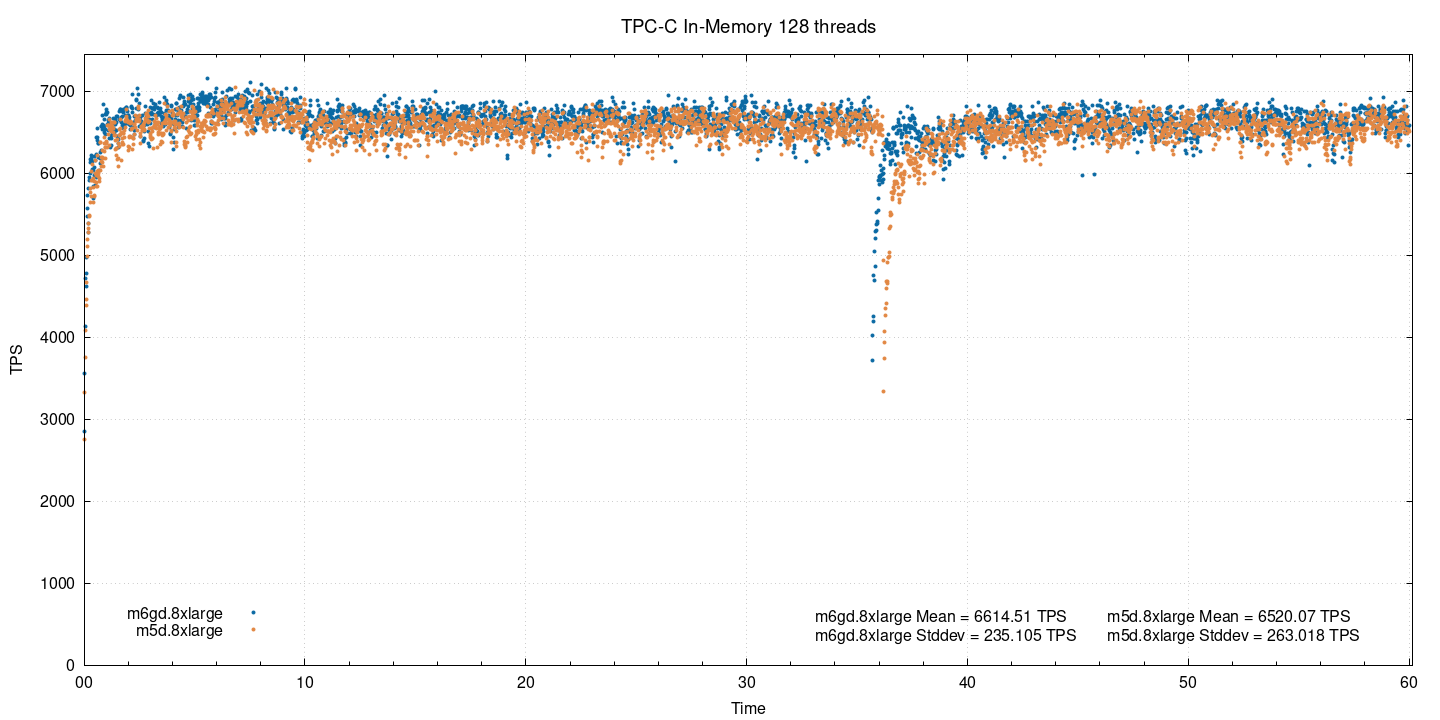
Когда оба инстанса проходят точку насыщения, разница в производительности становится минимальной (1,4%). Кроме того, наблюдается снижение пропускной способности (tps) на 6-7% в случае ARM и на 4% — в случае х86, при увеличении числа потоков с 64 до 128 на машинах с 32 vCPU.
Однако не все замеры оказались в пользу инстанса с Graviton2. В тестах, завязанных на IO (IO-bound) (набор данных ~ 200Гб, 200 хранилищ, равномерное распределение), разница между инстансами оказалась не столь большой, а при 64 и 128 потоках обычные m5d оказались лучше. Это можно увидеть на совмещенных графиках, приведенных ниже:
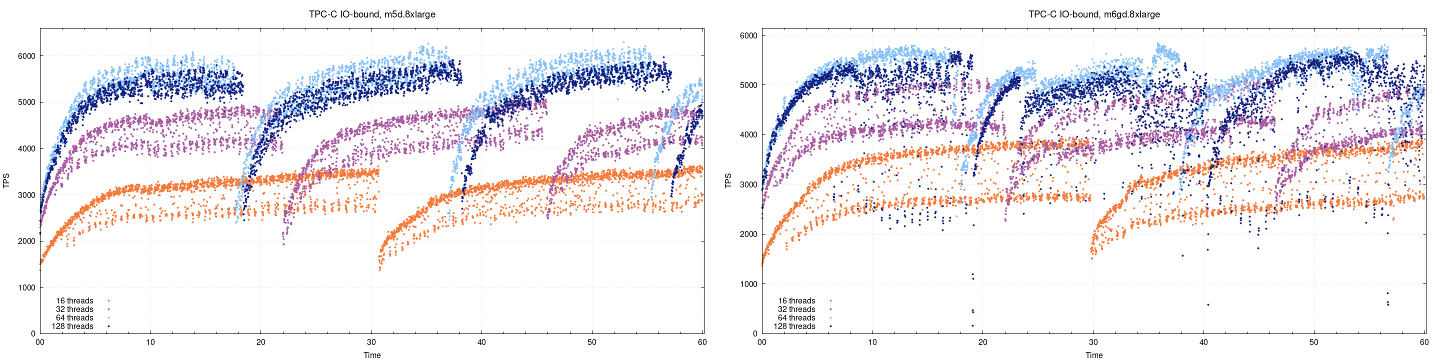
Возможная причина этого (особенно значительный разброс при 128 потоках для m6gd.8xlarge) состоит в том, что у ARM-инстанса, в отличие от m5d.8xlarge, не было второго диска. На данный момент не существует идеально сопоставимой пары инстансов, поэтому мы считаем наше сравнение достаточно объективным; каждый тип инстансов имеет свои преимущества. Для более точного определения причины [преимущества x86 в данном случае] необходимо дальнейшее тестирование и профилирование, поскольку ожидалось, что локальные диски не окажут значительного влияния на результаты тестов. Чтобы устранить вклад локальных дисков из уравнения, можно попробовать выполнить IO-bound-тестирование на EBS.
Подробности о стенде, результатах тестов, использованных скриптах и данных, полученных в ходе тестирования, доступны в репозитории на GitHub.
Резюме
По итогам тестов было зафиксировано не так много случаев, когда ARM-инстанс оказывался медленнее инстанса х86. Результаты тестов были последовательными на протяжении всего тестирования в течение пары дней. ARM-инстанс обходится на 25% дешевле, при этом в большинстве тестов он показал прирост производительности на 15-20% по сравнению с соответствующими инстансами на базе х86. Таким образом, ARM-инстансы убедительно превосходят х86 по соотношению цена/производительность во всех аспектах. В будущем следует ожидать пополнения списка облачных провайдеров, предлагающих виртуальные машины на базе ARM-процессоров. Пожалуйста, дайте нам знать, какие еще типы бенчмарков вам было бы интересно увидеть.
P.S. от переводчика
В комментариях к статье Yuriy Safris указывает на разницу в CPU: хотя у обоих инстансов по 32 виртуальных CPU, у m6gd.8xlarge — 32 физических ядра, а у m5d.8xlarge — 16. А Franck Pachot, автор pgbench, напоминает, что его тест на основе TPC-B полон сторонних операций (переключений контекста и сетевых вызовов), которые препятствуют точным измерениям производительности именно для CPU. Кроме того, есть обсуждение этой статьи и на Hacker News.
Читайте также в нашем блоге: