
Свою карьеру в области разработки я начал с позиции администратора баз данных, DBA, и в то время, еще до AWS RDS, Azure, Google Cloud и прочих облачных сервисов, DBA делились на два типа:
Infrastructure DBA отвечал за настройку баз данных, конфигурацию хранилищ, работу с резервным копированием и восстановлением. После настройки базы данных Infrastructure DBA появлялся лишь изредка и «донастраивал инстансы», например корректировал размер кэшей.
Application DBA получал в свои руки чистую, только что настроенную базу данных от Infrastructure DBA и отвечал за дизайн схемы: создание таблиц, индексов, ограничений и донастройку SQL. ETL процессы и миграция данных тоже ложилась на плечи Application DBA, равно как и хранимые процедуры (если ими пользовались).
Обычно Application DBA состояли в команде разработчиков, и зачастую из-за необходимости глубоко понимать все тонкости проекта они работали всего над одним или двумя, тогда как Infrastructure DBA сидели в какой-нибудь IT команде и работали сразу над несколькими проектами.
Моя должность — Application DBA
Меня никогда не прельщало работать с резервными данными или настраивать хранилища (уверен, это очень интересно!). По сей день я говорил и говорить буду: я DBA, который умеет разрабатывать приложения, а не разработчик, который может разобраться в базах данных.
В этой статье я поделюсь некоторыми нетривиальными приемами в работе с базами данных, которые я почерпнул в ходе моей карьеры.
Сама по себе
Довольно невинный запрос, который обновляет почту у миллиона и десяти тысяч пользователей, не правда ли? Но действительно ли мы хотим обновить каждую строку?
Теперь почта обновится только у десяти тысяч пользователей. Сократив число затрагиваемых строк, мы успешно сократили время исполнения запроса с 1.5 секунд до менее 300 миллисекунд. Кроме того, в долгосрочной перспективе обновление меньшего числа строк упрощает обслуживание базы данных.

Обновляйте только необходимые элементы
В скриптах миграции данных подобные массивные обновления встречаются очень часто, так что когда вы в следующий раз напишите миграционный скрипт, не забудьте обновить только необходимые элементы.
В реляционных базах данных ограничения очень важны, так как они поддерживают согласованность и надежность данных. Однако при обновлении очень большого числа строк проявляются связанные с производительностью особенности. Для примера, давайте создадим небольшую схему для магазина:
Эта схема определяет различные типы ограничений, например «not null», а так же уникальные ограничения. Для начала мы добавим в таблицу
После определения ограничений и индексов, загрузка миллиона строк в таблицу заняла приблизительно 15.4 секунды. Теперь попробуем сначала загрузить данные в таблицу, и лишь затем добавить ограничения и индексы:
Загрузка данных в таблицу без индексов и ограничений оказалась значительно быстрей, 2.27 секунды по сравнению с 15.4 секундами в прошлом примере. Создание индексов и ограничений после загрузки данных в таблицу заняло чуть больше времени, однако в итоге весь процесс прошел намного быстрее, за 3.1 секунды по сравнению с 15.4.
К несчастью, в PostgreSQL для индексов похожий простой вариант не предусмотрен, и индексы приходится полностью сбрасывать и пересоздавать. В других базах данных, например Oracle, вы можете включать и выключать индексы без необходимости их пересоздавать.
Когда вы модифицируете данные в PostgreSQL, изменения записываются в журнал WAL (write ahead log). WAL используется для быстрой передачи данных при восстановлении и для поддержания репликации.
Несмотря на всю важность записей в WAL, порой возникают ситуации, когда для ускорения процессов вы захотите отказаться от некоторых применений журнала. Помочь в подобной ситуации могут промежуточные таблицы.
Промежуточные таблицы это одноразовые таблицы, с временными данными для поддержания некоторых процессов. Например, в ETL процессах типичным случаем будет загрузка данных из CSV файла во временную таблицу, очистка данных, и затем загрузка оных в целевую таблицу. В данном случае промежуточная таблица используется всего один раз, и для резервного копирования или репликации в ней нет необходимости.

Таблица
Не требующие восстановления (при несчастном случае) или репликации промежуточные таблицы можно настроить как нелогируемые, UNLOGGED:
ВНИМАНИЕ: Перед использованием
Предположим, что у нас есть таблица пользователей, и мы замечаем несколько повторов:
Пользователь haki benita зарегистрировался дважды, один раз через почту ME@hakibenita.com и затем еще раз через почту me@hakibenita.com. Так как при вставке почты в таблицу мы не нормализовали адреса, нам теперь придется разбираться с повторами.
Для корректного объединения дублирующихся пользователей нам потребуется:
Провести такую операцию мы можем с помощью промежуточных таблиц:
В промежуточной таблице хранится отображение всех дублированных пользователей. Каждый пользователь, который проявляется в таблице больше чем один раз с одной и той же нормализованной почтой, получает тот же простейший ID, что и пользователь, в которого сведут все повторы. Остальные пользователи хранятся в столбце массива, и все ссылки на этих пользователей будут обновлены.
С помощью промежуточной таблицы мы можем обновить ссылки на дублированных пользователей в таблице
Теперь, когда ссылок больше нет, мы можем спокойно удалить повторы из таблицы
Обратите внимание, что мы воспользовались функцией
Отлично, все случаи пользователя 3 (ME@hakibenita.com) сведены к пользователю 2 (me@hakibenita.com).
Мы можем проверить, что все повторы из таблицы
Теперь промежуточная таблица нам больше не нужна:
Метод получился хороший, но слишком долгий, да и потом еще порядок наводить приходится. Существует ли более удобный метод?
С помощью обобщенных табличных выражений (Common Table Expressions, CTE), также известных как условие
Вместо создания промежуточной таблицы мы создаем табличное выражение, которым пользуемся несколько раз.
Удобной особенностью при выполнении DML внутри условия
Результат:
В первую очередь этот метод привлекателен тем, что весь процесс выполняется единственной командой, так что нет необходимости контролировать обмен данными или приводить в порядок промежуточную таблицу при нарушении процесса.
ВНИМАНИЕ: Пользователь на Реддите указал мне на возможное непредсказуемое поведение исполняемой DML в табличных выражениях:
Выходит, что полагаться на порядок исполнения независимых под-инструкций не получится. Похоже что при наличии зависимости между под-инструкциями, как в примере выше, можно ожидать исполнения зависимой под-инструкции еще до того как ей воспользуются.
Допустим, что у вас есть метод регистрации, в котором пользователи предоставляют свою почту, и для активации аккаунта им необходимо ее подтвердить. Ваша таблица будет выглядеть следующим образом:
Предположим, что большинство аккаунтов у вас зарегистрированы добропорядочными пользователями интернета, и они указали корректную почту и сразу активировали свои аккаунты. Давайте наполним таблицу данными так, чтобы где-то 90% пользователей уже были активированы.
У вас может возникнуть желание создать индекс на столбец
Когда мы пробуем запрашивать неактивированные аккаунты, база данных пользуется индексом:
База данных полагает, что под фильтр попадут 102567 аккаунтов, то есть приблизительно 10% от всей базы. Это совпадает с предоставленными нами данными, а значит база данных хорошо «ощущает» данные. Тем не менее, когда мы пробуем запрашивать активные аккаунты, база данных не пользуется индексом:
Отказ базы данных работать с индексом часто сбивает с толку многих разработчиков. Тем не менее, индекс это не всегда лучший инструмент, и полезно задать себе следующий вопрос: если вам необходимо прочесть всю таблицу, воспользуетесь ли вы индексом?
Ответ звучит как «нет наверное», поскольку «а зачем?». Чтение с диска тратит много ресурсов и считывать мы хотим как можно меньше. Если, например, у нас есть таблица в 10MB и индекс в 1MB, для чтения всей таблицы вам потребуется прочесть 10MB с диска, а для чтения таблицы с индексом – 11 MB, что попросту расточительно.
Теперь, когда мы это понимаем, давайте посмотрим на статистику, которую PostgreSQL собирает с таблицы:
Проанализировав таблицу, PostgreSQL обнаружил у столбца
С такой статистикой на руках PostgreSQL считает 90% строк таблицы удовлетворяющими условия и решает, что лучше всего просканировать всю таблицу целиком. Порог, после которого база данных может воспользоваться или не воспользоваться индексом, зависит от множества факторов, и ориентироваться на что-то однозначное нет возможности.
Индексы для столбца с малой и большой корреляцией
В предыдущей главе мы создали индекс булевого столбца где ~90% значений были истинными (активный аккаунт). Когда мы запрашивали активные аккаунты, база данных не пользовалась индексом, однако когда мы запрашивали неактивированные аккаунты, база данных индексом пользовалась.
Возникает следующий вопрос: если база данных не собирается пользоваться индексом для фильтрации активных аккаунтов, для чего нам вообще их индексировать?
Прежде чем мы ответим на этот вопрос, давайте посмотрим, каков объем полного индекса столбца
Индекс занимает 21MB, тогда как вся таблица
В PostgreSQL метод по созданию индекса, который охватывает только часть таблицы, называется частичным индексом:
Условие
Превосходно, база данных оказалась достаточно умной и поняла, что утверждение в нашем запросе удовлетворяется частичным индексом.
У частичных индексов есть еще одна удобная особенность – их размер:
Размер частичного индекса – всего 2.2 MB, тогда как у полного индекса 21MB. Частичный индекс составляет 10% от полного и совпадает с соотношением неактивированных аккаунтов в таблице.
При ревью кода я чаще всего оставляю комментарии про загрузку отсортированных данных. Данный прием не настолько интуитивно понятен и может оказать сильное влияние на производительность. Допустим, у вас есть большая таблица продаж:
Каждую ночь в ходе ETL процессов вы загружаете данные в таблицу:
Для симуляции процесса загрузки мы воспользуемся случайными данными. Мы вставили сто тысяч строк со случайными пользователями и датами продаж с первого января 2020 года на два года вперед.
Таблица чаще всего используется для обобщенных отчетов о продажах. Большинство отчетов выдают данные о продажах за конкретный период и потому фильтруются по дате. Чтобы ускорить сканирование мы создаем индекс по
Давайте взглянем на план исполнения запроса по выдаче всех продаж за июнь 2020 года:
Мы исполняем запрос несколько раз подряд и приходим к выводу, что общее время исполнения оказывается в районе 6 миллисекунд.
Посмотрев на план исполнения, мы видим, что база данных провела bitmap scan, сканирование битовой карты. Bitmap scan работает в два шага:
В страницах может быть сразу по несколько строк. На первом шаге мы пользуемся индексом чтобы найти страницы. На втором шаге мы проводим проверку на строки в этих страницах, поэтому в плане исполнения имеется операция «Recheck Cond».
К этому моменту многие DBA и разработчики удовлетворенно остановятся и перейдут к следующему запросу. Однако этот запрос еще можно улучшить.
Для этого мы внесем небольшие изменения в процесс считывания данных:
В этот раз мы загрузили данные, отсортированные через
Исполнив запрос несколько раз, мы получаем стабильное время исполнения в районе 2.3 миллисекунды. По сравнению с прошлым результатом в 6 миллисекунд, мы сохранили около 60% времени.
Кроме того, мы можем заметить, что в этот раз база данных воспользовалась «обычным» index scan вместо bitmap scan. Почему же?
Когда база данных анализирует таблицу, она собирает все возможные виды статистики, включая корреляцию:
Как можно прочесть в официальной документации, корреляция измеряет насколько «отсортированы» значения конкретного столбца на диске.

Корреляция = 1
Когда корреляция равна или близка к 1, страницы таблицы хранятся на диске приблизительно в том же порядке что и в самой таблице (ситуация достаточно частая). Например, автоматическое возрастание ID обычно ведет к корреляции, близкой к 1. У столбцов даты и времени, которые отслеживают время создания строк, корреляция тоже близка к 1. Если корреляция равна -1, страницы таблицы отсортированы в порядке обратном к порядку столбца.

Корреляция ~ 0
Когда корреляция близка к 0, значения в столбце имеют мало (или даже никакого) отношения к порядку, в котором страницы хранятся в таблице.
Вернемся к нашей таблице
У автоматически сгенерированного столбца
Когда мы загрузим отсортированные данные в таблицу, корреляция окажется следующей:
Корреляция столбца
Так почему же база данных провела bitmap scan при малой корреляции, и index scan при корреляции близкой к 1?
Когда вы в следующий раз будете загружать данные в таблицу, задумайтесь над тем, как вы будете запрашивать данные, и убедитесь, что вы сортируете данные удобным для индексации методом.
Еще один вариант «сортировки таблицы на диске» конкретным индексом это команда
Мы загрузили данные в таблицу в случайном порядке и в результате получили корреляцию
Чтобы «перестроить» таблицу по
Как мы можем видеть, после работы команды корреляция
Команда
Требующие внимания особенности команды
По этим двум причинам лучше всего загружать заранее отсортированные данные и не полагаться на команду
Когда ведутся разговоры об индексах, большинство разработчиков думают о B-Tree, однако PostgreSQL предоставляет и другие типы индексов, например BRIN:
Аббревиатура BRIN расшифровывается как Block Range Index, и в соответствии со своей документацией, этот индекс лучше всего подходит для столбцов с высокой корреляцией. Как мы уже успели убедиться в предыдущих разделах, некоторые поля, например автоматически возрастающие ID и метки времени, естественным образом коррелируют с физической структурой таблицы, и таким образом становятся лучшими кандидатами под индексацию BRIN.
В некоторых случаях индекс BRIN оказывается эффективнее аналогичных B-Tree индексов с точки зрения размера и производительности.
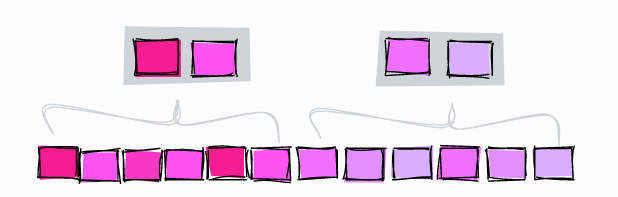
Индекс BRIN
Индекс BRIN работает через сохранение диапазона значений в наборе смежных страниц таблицы. Допустим, у нас в столбце есть три значения, каждое на отдельной странице таблицы:
Индекс BRIN работает над диапазоном смежных страниц в таблице. Если набор смежных страниц равен 3, индекс разделит таблицу на следующие диапазоны:
Затем индекс BRIN сохраняет минимальное и максимальное значение для каждого диапазона:
Пользуясь индексом выше, попробуем найти значение 5:
Индексом BRIN мы ограничили наши поиски до блоков 4-6.
Возьмем другой пример, на этот раз корреляция значений в столбцах будет близка к 0, то есть они не отсортированы:
Индексация трех соседних блоков приводит к следующим диапазонам:
Попробуем поискать значение 5:
В данном случае индекс совершенно бесполезен, поскольку никак не ограничивает поиск.
Понимание работы
Количество смежных страниц определяется параметром
Стандартный размер

Индекс BRIN с малым числом «страниц на диапазон»
Для примера создадим индекс BRIN в диапазоне двух смежных страниц и отыщем значение 5:
С индексом в две страницы на диапазон мы смогли ограничить поиск до блоков 5 и 6. С диапазоном в три страницы поиск был ограничен до блоков 4,5 и 6.
Другое отличие двух индексов это их размеры: при числе смежных страниц в три нам необходимо было поддерживать всего 3 диапазона, тогда как при числе смежных страниц в две нам пришлось поддерживать 5 диапазонов, то есть более крупный индекс.
Мы можем снова воспользоваться таблицей
Давайте создадим запрос на диапазон времени продаж:
База данных воспользовалась нашим индексом BRIN чтобы получить диапазон времени продаж, но в этом плане исполнения есть кое-что поинтереснее…
В соответствии с планом исполнения, база данных исключила 23130 строк со страниц, которые она обнаружила при помощи индекса. Это может значить, что диапазон индекса несколько великоват для конкретно этого запроса. Давайте попробуем создать индекс с меньшим числом страниц на диапазон:
С 64 страницами на диапазон база данных исключила через индекс меньше строк со страниц, всего 9434 по сравнению с 23130 при диапазоне в 128 страниц. В итоге таблице пришлось проводить меньше I/O и запрос оказался чуть быстрее, ~5.5 мс по сравнению с ~8.9 мс.
Тестирование индекса с различными значениями pages_per_range привело к следующим результатам:
Как мы видим, с уменьшением
Обратите внимание, что мы оптимизировали конкретный запрос. Это нормально для демонстрационных задач, однако в реальной жизни лучше всего пользоваться значениями, подходящими для большинства используемых запросов.
Следующей важной особенностью индекса BRIN является его размер. В предыдущих разделах мы создали индекс B-Tree на поле
Размер индекса BRIN также зависит от
В PostgreSQL есть удобная особенность под названием «транзакционный язык описания данных», или transactional DDL (transactional Data Definition Language). После многих лет работы с Oracle я успел привыкнуть ко многим DDL командам в конце транзакции, например
Как я недавно обнаружил, использование транзакционного DLL позволяет делать индексы невидимыми! Очень удобный прием, когда хочется увидеть план исполнения без индекса.
Например, в таблице
Чтобы увидеть план исполнения если бы индекс
Мы начинаем транзакцию через
Теперь убедимся, что индекс все еще существует:
Другие базы данных, в которых нет поддержки транзакционных DDL, предоставляют иные пути по достижению той же цели. Например, Oracle позволяет отмечать индекс как невидимый, и оптимизатор его игнорирует.
ОСТОРОЖНО: Сброс индекса внутри транзакции заблокирует наши последовательные
Среди инвесторов давно известен следующий факт: при достижении акциями удобных круглых цен, например 10, 100, 1000 и так далее случаются разные странности. Цитируя следующую статью:
В этом отношении разработчики мало отличаются от инвесторов. Когда им необходимо запланировать длительный процесс, обычно они назначают его на округленное время (чаще всего ровно какой-нибудь час, например 5:00).
Типичная нагрузка на систему посреди ночи
Тенденция по планированию задач на округленное время может привести в эти часы к неожиданным нагрузкам, поэтому если вам необходимо запланировать некий длительный процесс, лучше ориентироваться на другое время. Еще одна хорошая идея – настройка случайного сдвига в графике задачи, чтобы она не проводилась каждый раз в одно и то же время. Таким образом, даже если другая задача запланирована на тот же самый час, серьезной проблемы из этого не возникнет. Если вы планируете ваши задачи через
Эта статья затрагивает некоторые тривиальные и нетривиальные приемы из моего личного опыта. Некоторые из них легко имплементировать, другие же требуют глубоко понимания работы баз данных. Базы данных это основа большинства современных систем, так что выделить время для понимания их работы будет полезно любому разработчику.
Infrastructure DBA отвечал за настройку баз данных, конфигурацию хранилищ, работу с резервным копированием и восстановлением. После настройки базы данных Infrastructure DBA появлялся лишь изредка и «донастраивал инстансы», например корректировал размер кэшей.
Application DBA получал в свои руки чистую, только что настроенную базу данных от Infrastructure DBA и отвечал за дизайн схемы: создание таблиц, индексов, ограничений и донастройку SQL. ETL процессы и миграция данных тоже ложилась на плечи Application DBA, равно как и хранимые процедуры (если ими пользовались).
Обычно Application DBA состояли в команде разработчиков, и зачастую из-за необходимости глубоко понимать все тонкости проекта они работали всего над одним или двумя, тогда как Infrastructure DBA сидели в какой-нибудь IT команде и работали сразу над несколькими проектами.
Моя должность — Application DBA
Меня никогда не прельщало работать с резервными данными или настраивать хранилища (уверен, это очень интересно!). По сей день я говорил и говорить буду: я DBA, который умеет разрабатывать приложения, а не разработчик, который может разобраться в базах данных.
В этой статье я поделюсь некоторыми нетривиальными приемами в работе с базами данных, которые я почерпнул в ходе моей карьеры.
Обновляйте только необходимые элементы
Сама по себе
UPDATE это относительно ресурсозатраная операция, и для ускорения процесса нам не помешает убедиться, что обновляем мы только самое необходимое. Например, взгляните на следующий нормализующий колонку почты запрос:db=# UPDATE users SET email = lower(email);
UPDATE 1010000
Time: 1583.935 ms (00:01.584)Довольно невинный запрос, который обновляет почту у миллиона и десяти тысяч пользователей, не правда ли? Но действительно ли мы хотим обновить каждую строку?
db=# UPDATE users SET email = lower(email)
db-# WHERE email != lower(email);
UPDATE 10000
Time: 299.470 ms
Теперь почта обновится только у десяти тысяч пользователей. Сократив число затрагиваемых строк, мы успешно сократили время исполнения запроса с 1.5 секунд до менее 300 миллисекунд. Кроме того, в долгосрочной перспективе обновление меньшего числа строк упрощает обслуживание базы данных.
Обновляйте только необходимые элементы
В скриптах миграции данных подобные массивные обновления встречаются очень часто, так что когда вы в следующий раз напишите миграционный скрипт, не забудьте обновить только необходимые элементы.
Отключайте ограничения и индексы при массовой загрузке
В реляционных базах данных ограничения очень важны, так как они поддерживают согласованность и надежность данных. Однако при обновлении очень большого числа строк проявляются связанные с производительностью особенности. Для примера, давайте создадим небольшую схему для магазина:
DROP TABLE IF EXISTS product CASCADE;
CREATE TABLE product (
id serial PRIMARY KEY,
name TEXT NOT NULL,
price INT NOT NULL
);
INSERT INTO product (name, price)
SELECT random()::text, (random() * 1000)::int
FROM generate_series(0, 10000);
DROP TABLE IF EXISTS customer CASCADE;
CREATE TABLE customer (
id serial PRIMARY KEY,
name TEXT NOT NULL
);
INSERT INTO customer (name)
SELECT random()::text
FROM generate_series(0, 100000);
DROP TABLE IF EXISTS sale;
CREATE TABLE sale (
id serial PRIMARY KEY,
created timestamptz NOT NULL,
product_id int NOT NULL,
customer_id int NOT NULL
);Эта схема определяет различные типы ограничений, например «not null», а так же уникальные ограничения. Для начала мы добавим в таблицу
sale внешние ключи, а затем загрузим в нее немного данных:db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 18.413 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 5.464 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 12.605 ms
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 15410.234 ms (00:15.410)
После определения ограничений и индексов, загрузка миллиона строк в таблицу заняла приблизительно 15.4 секунды. Теперь попробуем сначала загрузить данные в таблицу, и лишь затем добавить ограничения и индексы:
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 2277.824 ms (00:02.278)
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 169.193 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 185.633 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 484.244 msЗагрузка данных в таблицу без индексов и ограничений оказалась значительно быстрей, 2.27 секунды по сравнению с 15.4 секундами в прошлом примере. Создание индексов и ограничений после загрузки данных в таблицу заняло чуть больше времени, однако в итоге весь процесс прошел намного быстрее, за 3.1 секунды по сравнению с 15.4.
К несчастью, в PostgreSQL для индексов похожий простой вариант не предусмотрен, и индексы приходится полностью сбрасывать и пересоздавать. В других базах данных, например Oracle, вы можете включать и выключать индексы без необходимости их пересоздавать.
Для промежуточных данных пользуйтесь UNLOGGED таблицами.
Когда вы модифицируете данные в PostgreSQL, изменения записываются в журнал WAL (write ahead log). WAL используется для быстрой передачи данных при восстановлении и для поддержания репликации.
Несмотря на всю важность записей в WAL, порой возникают ситуации, когда для ускорения процессов вы захотите отказаться от некоторых применений журнала. Помочь в подобной ситуации могут промежуточные таблицы.
Промежуточные таблицы это одноразовые таблицы, с временными данными для поддержания некоторых процессов. Например, в ETL процессах типичным случаем будет загрузка данных из CSV файла во временную таблицу, очистка данных, и затем загрузка оных в целевую таблицу. В данном случае промежуточная таблица используется всего один раз, и для резервного копирования или репликации в ней нет необходимости.
Таблица
UNLOGGEDНе требующие восстановления (при несчастном случае) или репликации промежуточные таблицы можно настроить как нелогируемые, UNLOGGED:
CREATE UNLOGGED TABLE staging_table ( /* table definition */ );ВНИМАНИЕ: Перед использованием
UNLOGGED убедитесь, что вы осознаете все возможные последствия.Введите полные процессы через WITH и RETURNING
Предположим, что у нас есть таблица пользователей, и мы замечаем несколько повторов:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
email TEXT UNIQUE
);
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
user_id INT,
CONSTRAINT orders_user_fk
FOREIGN KEY (user_id)
REFERENCES USERS(id)
);
INSERT INTO users (email) VALUES
('foo@bar.baz'),
('me@hakibenita.com'),
('ME@hakibenita.com');
INSERT INTO orders (user_id) VALUES
(1),
(1),
(2),
(3),
(3);db=# SELECT u.id, u.email, o.id as order_id
FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
3 | ME@hakibenita.com | 4
3 | ME@hakibenita.com | 5
Пользователь haki benita зарегистрировался дважды, один раз через почту ME@hakibenita.com и затем еще раз через почту me@hakibenita.com. Так как при вставке почты в таблицу мы не нормализовали адреса, нам теперь придется разбираться с повторами.
Для корректного объединения дублирующихся пользователей нам потребуется:
- Идентифицировать повторы по почте в нижнем регистре
- Обновить порядок, чтобы ссылаться на одного из дублированных пользователей
- Убрать все повторы из таблицы
Провести такую операцию мы можем с помощью промежуточных таблиц:
db=# CREATE UNLOGGED TABLE duplicate_users AS
db-# SELECT
db-# lower(email) AS normalized_email,
db-# min(id) AS convert_to_user,
db-# array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
db-# FROM
db-# users
db-# GROUP BY
db-# normalized_email
db-# HAVING
db-# count(*) > 1;
CREATE TABLE
db=# SELECT * FROM duplicate_users;
normalized_email | convert_to_user | convert_from_users
-------------------+-----------------+--------------------
me@hakibenita.com | 2 | {3}В промежуточной таблице хранится отображение всех дублированных пользователей. Каждый пользователь, который проявляется в таблице больше чем один раз с одной и той же нормализованной почтой, получает тот же простейший ID, что и пользователь, в которого сведут все повторы. Остальные пользователи хранятся в столбце массива, и все ссылки на этих пользователей будут обновлены.
С помощью промежуточной таблицы мы можем обновить ссылки на дублированных пользователей в таблице
orders:db=# UPDATE
db-# orders o
db-# SET
db-# user_id = du.convert_to_user
db-# FROM
db-# duplicate_users du
db-# WHERE
db-# o.user_id = ANY(du.convert_from_users);
UPDATE 2Теперь, когда ссылок больше нет, мы можем спокойно удалить повторы из таблицы
users:db=# DELETE FROM
db-# users
db-# WHERE
db-# id IN (
db(# SELECT unnest(convert_from_users)
db(# FROM duplicate_users
db(# );
DELETE 1Обратите внимание, что мы воспользовались функцией
unnest для «перестановки» массива, то есть превращения каждого элемента массива в строку, со следующим результатом:db=# SELECT u.id, u.email, o.id as order_id
db-# FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
2 | me@hakibenita.com | 4
2 | me@hakibenita.com | 5
Отлично, все случаи пользователя 3 (ME@hakibenita.com) сведены к пользователю 2 (me@hakibenita.com).
Мы можем проверить, что все повторы из таблицы
users удалены:db=# SELECT * FROM users;
id | email
----+-------------------
1 | foo@bar.baz
2 | me@hakibenita.comТеперь промежуточная таблица нам больше не нужна:
db=# DROP TABLE duplicate_users;
DROP TABLEМетод получился хороший, но слишком долгий, да и потом еще порядок наводить приходится. Существует ли более удобный метод?
Обобщенные табличные выражения
С помощью обобщенных табличных выражений (Common Table Expressions, CTE), также известных как условие
WITH, мы сможем проводить целые процессы всего одним SQL высказыванием:WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
)
DELETE FROM
users
WHERE
id IN (
SELECT
unnest(convert_from_users)
FROM
duplicate_users
);Вместо создания промежуточной таблицы мы создаем табличное выражение, которым пользуемся несколько раз.
Возврат результатов из CTE
Удобной особенностью при выполнении DML внутри условия
WITH является возврат данных через кейворд RETURNING. Для примера, давайте определим число обновленных и удаленных строк:WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
RETURNING o.id
),
delete_duplicate_user AS (
DELETE FROM
users
WHERE
id IN (
SELECT unnest(convert_from_users)
FROM duplicate_users
)
RETURNING id
)
SELECT
(SELECT count(*) FROM update_orders_of_duplicate_users) AS orders_updated,
(SELECT count(*) FROM delete_duplicate_user) AS users_deleted
;
Результат:
orders_updated | users_deleted
----------------+---------------
2 | 1В первую очередь этот метод привлекателен тем, что весь процесс выполняется единственной командой, так что нет необходимости контролировать обмен данными или приводить в порядок промежуточную таблицу при нарушении процесса.
ВНИМАНИЕ: Пользователь на Реддите указал мне на возможное непредсказуемое поведение исполняемой DML в табличных выражениях:
Под-инструкции внутри условия WITH исполняются одновременно и друг с другом, и с основным массивом. Таким образом, при использовании меняющих данные инструкций внутри условия WITH мы не можем предсказать порядок, в котором эти изменения произойдут.
Выходит, что полагаться на порядок исполнения независимых под-инструкций не получится. Похоже что при наличии зависимости между под-инструкциями, как в примере выше, можно ожидать исполнения зависимой под-инструкции еще до того как ей воспользуются.
Избегайте индексы в колонках с малой селективностью
Допустим, что у вас есть метод регистрации, в котором пользователи предоставляют свою почту, и для активации аккаунта им необходимо ее подтвердить. Ваша таблица будет выглядеть следующим образом:
db=# CREATE TABLE users (
db-# id serial,
db-# username text,
db-# activated boolean
db-#);
CREATE TABLEПредположим, что большинство аккаунтов у вас зарегистрированы добропорядочными пользователями интернета, и они указали корректную почту и сразу активировали свои аккаунты. Давайте наполним таблицу данными так, чтобы где-то 90% пользователей уже были активированы.
db=# INSERT INTO users (username, activated)
db-# SELECT
db-# md5(random()::text) AS username,
db-# random() < 0.9 AS activated
db-# FROM
db-# generate_series(1, 1000000);
INSERT 0 1000000
db=# SELECT activated, count(*) FROM users GROUP BY activated;
activated | count
-----------+--------
f | 102567
t | 897433
db=# VACUUM ANALYZE users;
VACUUMУ вас может возникнуть желание создать индекс на столбец
activated для запроса данных по активированным и неактивированным аккаунтам:db=# CREATE INDEX users_activated_ix ON users(activated);
CREATE INDEXКогда мы пробуем запрашивать неактивированные аккаунты, база данных пользуется индексом:
db=# EXPLAIN SELECT * FROM users WHERE NOT activated;
QUERY PLAN
--------------------------------------------------------------------------------------
Bitmap Heap Scan on users (cost=1923.32..11282.99 rows=102567 width=38)
Filter: (NOT activated)
-> Bitmap Index Scan on users_activated_ix (cost=0.00..1897.68 rows=102567 width=0)
Index Cond: (activated = false)
База данных полагает, что под фильтр попадут 102567 аккаунтов, то есть приблизительно 10% от всей базы. Это совпадает с предоставленными нами данными, а значит база данных хорошо «ощущает» данные. Тем не менее, когда мы пробуем запрашивать активные аккаунты, база данных не пользуется индексом:
db=# EXPLAIN SELECT * FROM users WHERE activated;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on users (cost=0.00..18334.00 rows=897433 width=38)
Filter: activatedОтказ базы данных работать с индексом часто сбивает с толку многих разработчиков. Тем не менее, индекс это не всегда лучший инструмент, и полезно задать себе следующий вопрос: если вам необходимо прочесть всю таблицу, воспользуетесь ли вы индексом?
Ответ звучит как «нет наверное», поскольку «а зачем?». Чтение с диска тратит много ресурсов и считывать мы хотим как можно меньше. Если, например, у нас есть таблица в 10MB и индекс в 1MB, для чтения всей таблицы вам потребуется прочесть 10MB с диска, а для чтения таблицы с индексом – 11 MB, что попросту расточительно.
Теперь, когда мы это понимаем, давайте посмотрим на статистику, которую PostgreSQL собирает с таблицы:
db=# SELECT attname, n_distinct, most_common_vals, most_common_freqs
db-# FROM pg_stats
db-# WHERE tablename = 'users' AND attname='activated';
------------------+------------------------
attname | activated
n_distinct | 2
most_common_vals | {t,f}
most_common_freqs | {0.89743334,0.10256667}Проанализировав таблицу, PostgreSQL обнаружил у столбца
activated два различных значения. Значение t в столбце most_common_vals коррелирует с частотой 0.89743334 в столбце most_common_freqs, а значение f коррелирует с частотой 0.10256667. Выходит, что после анализа таблицы база данных считает 89.74% таблицы активированными аккаунтами, а остальные 10.26% неактивированными.С такой статистикой на руках PostgreSQL считает 90% строк таблицы удовлетворяющими условия и решает, что лучше всего просканировать всю таблицу целиком. Порог, после которого база данных может воспользоваться или не воспользоваться индексом, зависит от множества факторов, и ориентироваться на что-то однозначное нет возможности.
Индексы для столбца с малой и большой корреляцией
Пользуйтесь частичными индексами
В предыдущей главе мы создали индекс булевого столбца где ~90% значений были истинными (активный аккаунт). Когда мы запрашивали активные аккаунты, база данных не пользовалась индексом, однако когда мы запрашивали неактивированные аккаунты, база данных индексом пользовалась.
Возникает следующий вопрос: если база данных не собирается пользоваться индексом для фильтрации активных аккаунтов, для чего нам вообще их индексировать?
Прежде чем мы ответим на этот вопрос, давайте посмотрим, каков объем полного индекса столбца
activated:db=# \di+ users_activated_ix
Schema | Name | Type | Owner | Table | Size
--------+--------------------+-------+-------+-------+------
public | users_activated_ix | index | haki | users | 21 MBИндекс занимает 21MB, тогда как вся таблица
users занимает 65MB, то есть размер индекса составляет ~32%, почти треть таблицы. Кроме того, мы знаем что в 90% случаев индекс, скорее всего, не используется.В PostgreSQL метод по созданию индекса, который охватывает только часть таблицы, называется частичным индексом:
db=# CREATE INDEX users_unactivated_partial_ix ON users(id)
db-# WHERE not activated;
CREATE INDEXУсловие
WHERE задает рамки для индексации строк. Давайте проверим, что у нас все работает корректно:db=# EXPLAIN SELECT * FROM users WHERE not activated;
QUERY PLAN
------------------------------------------------------------------------------------------------
Index Scan using users_unactivated_partial_ix on users (cost=0.29..3493.60 rows=102567 width=38)Превосходно, база данных оказалась достаточно умной и поняла, что утверждение в нашем запросе удовлетворяется частичным индексом.
У частичных индексов есть еще одна удобная особенность – их размер:
db=# \di+ users_unactivated_partial_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+------------------------------+-------+-------+-------+---------
public | users_unactivated_partial_ix | index | haki | users | 2216 kBРазмер частичного индекса – всего 2.2 MB, тогда как у полного индекса 21MB. Частичный индекс составляет 10% от полного и совпадает с соотношением неактивированных аккаунтов в таблице.
Всегда загружайте отсортированные данные
При ревью кода я чаще всего оставляю комментарии про загрузку отсортированных данных. Данный прием не настолько интуитивно понятен и может оказать сильное влияние на производительность. Допустим, у вас есть большая таблица продаж:
db=# CREATE TABLE sale_fact (id serial, username text, sold_at date);
CREATE TABLEКаждую ночь в ходе ETL процессов вы загружаете данные в таблицу:
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000);
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUMДля симуляции процесса загрузки мы воспользуемся случайными данными. Мы вставили сто тысяч строк со случайными пользователями и датами продаж с первого января 2020 года на два года вперед.
Таблица чаще всего используется для обобщенных отчетов о продажах. Большинство отчетов выдают данные о продажах за конкретный период и потому фильтруются по дате. Чтобы ускорить сканирование мы создаем индекс по
sold_at:db=# CREATE INDEX sale_fact_sold_at_ix ON sale_fact(sold_at);
CREATE INDEXДавайте взглянем на план исполнения запроса по выдаче всех продаж за июнь 2020 года:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
-----------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=108.30..1107.69 rows=4293 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Heap Blocks: exact=927
-> Bitmap Index Scan on sale_fact_sold_at_ix (cost=0.00..107.22 rows=4293 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.191 ms
Execution Time: 5.906 msМы исполняем запрос несколько раз подряд и приходим к выводу, что общее время исполнения оказывается в районе 6 миллисекунд.
Bitmap Scan
Посмотрев на план исполнения, мы видим, что база данных провела bitmap scan, сканирование битовой карты. Bitmap scan работает в два шага:
- Bitmap Index Scan: на первом шаге проводится анализ всего индекса
sale_fact_sold_at_ixи создается карта, на которой отмечаются страницы таблицы с интересующими нас строками. - Bitmap Heap Scan: на втором шаге проводится считывание страницы с нужными строками и в них обнаруживаются удовлетворяющие условиям строки.
В страницах может быть сразу по несколько строк. На первом шаге мы пользуемся индексом чтобы найти страницы. На втором шаге мы проводим проверку на строки в этих страницах, поэтому в плане исполнения имеется операция «Recheck Cond».
К этому моменту многие DBA и разработчики удовлетворенно остановятся и перейдут к следующему запросу. Однако этот запрос еще можно улучшить.
Index Scan
Для этого мы внесем небольшие изменения в процесс считывания данных:
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
db-# ORDER BY sold_at;
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUMВ этот раз мы загрузили данные, отсортированные через
sold_at. Давайте посмотрим, как теперь будет выглядеть план исполнения для точно такого же (как и в прошлый раз) запроса:db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.29..184.73 rows=4272 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.145 ms
Execution Time: 2.294 msИсполнив запрос несколько раз, мы получаем стабильное время исполнения в районе 2.3 миллисекунды. По сравнению с прошлым результатом в 6 миллисекунд, мы сохранили около 60% времени.
Кроме того, мы можем заметить, что в этот раз база данных воспользовалась «обычным» index scan вместо bitmap scan. Почему же?
Корреляция
Когда база данных анализирует таблицу, она собирает все возможные виды статистики, включая корреляцию:
Статистическое соотношение между физической строкой и логическим порядком значений столбца. Значения разнятся между -1 и +1. Когда значение приближается к -1 или +1, index scan будет считаться эффективнее, чем когда значение близко к 0, в связи с уменьшением случайного доступа к диску.
Как можно прочесть в официальной документации, корреляция измеряет насколько «отсортированы» значения конкретного столбца на диске.
Корреляция = 1
Когда корреляция равна или близка к 1, страницы таблицы хранятся на диске приблизительно в том же порядке что и в самой таблице (ситуация достаточно частая). Например, автоматическое возрастание ID обычно ведет к корреляции, близкой к 1. У столбцов даты и времени, которые отслеживают время создания строк, корреляция тоже близка к 1. Если корреляция равна -1, страницы таблицы отсортированы в порядке обратном к порядку столбца.
Корреляция ~ 0
Когда корреляция близка к 0, значения в столбце имеют мало (или даже никакого) отношения к порядку, в котором страницы хранятся в таблице.
Вернемся к нашей таблице
sale_fact. Когда мы загрузили данные в таблицу без предварительной сортировки, корреляция оказалась следующей:db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db=# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale | id | 1
sale | username | -0.005344716
sale | sold_at | -0.011389783У автоматически сгенерированного столбца
id корреляция равна 1. У столбца sold_at корреляция очень мала: последовательные значения раскиданы по всей таблице.Когда мы загрузим отсортированные данные в таблицу, корреляция окажется следующей:
tablename | attname | correlation
-----------+----------+----------------
sale_fact | id | 1
sale_fact | username | -0.00041992788
sale_fact | sold_at | 1Корреляция столбца
sold_at теперь равна 1.Так почему же база данных провела bitmap scan при малой корреляции, и index scan при корреляции близкой к 1?
- Когда корреляция равнялась 1, база данных предполагала что строки в запрашиваемом диапазоне, скорее всего, расположены в последовательных страницах. В таком случае index scan вероятнее всего прочтет очень малое число страниц.
- Когда корреляция была близка к 0, база данных предполагала что строки в запрашиваемом диапазоне, скорее всего, раскиданы по всей таблице. В таком случае логичнее всего воспользоваться bitmap scan, чтобы разметить страницы таблицы, в которых есть строки, и только затем подтянуть их для применения условия запроса.
Когда вы в следующий раз будете загружать данные в таблицу, задумайтесь над тем, как вы будете запрашивать данные, и убедитесь, что вы сортируете данные удобным для индексации методом.
Команда CLUSTER
Еще один вариант «сортировки таблицы на диске» конкретным индексом это команда
CLUSTER. Пример:b=# TRUNCATE sale_fact;
TRUNCATE TABLE
-- Insert rows without sorting
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
INSERT 0 100000
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+-----------+----------------
sale_fact | sold_at | -5.9702674e-05
sale_fact | id | 1
sale_fact | username | 0.010033822Мы загрузили данные в таблицу в случайном порядке и в результате получили корреляцию
sold_at близкую к 0.Чтобы «перестроить» таблицу по
sold_at, мы воспользовались командой CLUSTER для сортировки таблицы на диске в соответствии с индексом sale_fact_sold_at_ix:db=# CLUSTER sale_fact USING sale_fact_sold_at_ix;
CLUSTER
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale_fact | sold_at | 1
sale_fact | id | -0.002239401
sale_fact | username | 0.013389298Как мы можем видеть, после работы команды корреляция
sold_at равняется 1.Команда
CLUSTERТребующие внимания особенности команды
CLUSTER:- Группировка таблицы по конкретным столбцам может затронуть корреляцию других столбцов. Например, взгляните на корреляцию в столбце
idпосле того как мы сгруппировали таблицу поsold_at. CLUSTERэто тяжелая, блокирующая другие операция, так что убедитесь что вы не исполняете ее на продакшене.
По этим двум причинам лучше всего загружать заранее отсортированные данные и не полагаться на команду
CLUSTER.Колонки индексов с высокой корреляцией через BRIN
Когда ведутся разговоры об индексах, большинство разработчиков думают о B-Tree, однако PostgreSQL предоставляет и другие типы индексов, например BRIN:
BRIN разработан для работы с очень большими таблицами, в которых у некоторых столбцов есть естественная корреляция со своим физическим расположением в таблице.
Аббревиатура BRIN расшифровывается как Block Range Index, и в соответствии со своей документацией, этот индекс лучше всего подходит для столбцов с высокой корреляцией. Как мы уже успели убедиться в предыдущих разделах, некоторые поля, например автоматически возрастающие ID и метки времени, естественным образом коррелируют с физической структурой таблицы, и таким образом становятся лучшими кандидатами под индексацию BRIN.
В некоторых случаях индекс BRIN оказывается эффективнее аналогичных B-Tree индексов с точки зрения размера и производительности.
Индекс BRIN
Индекс BRIN работает через сохранение диапазона значений в наборе смежных страниц таблицы. Допустим, у нас в столбце есть три значения, каждое на отдельной странице таблицы:
1, 2, 3, 4, 5, 6, 7, 8, 9Индекс BRIN работает над диапазоном смежных страниц в таблице. Если набор смежных страниц равен 3, индекс разделит таблицу на следующие диапазоны:
[1,2,3], [4,5,6], [7,8,9]Затем индекс BRIN сохраняет минимальное и максимальное значение для каждого диапазона:
[1–3], [4–6], [7–9]Пользуясь индексом выше, попробуем найти значение 5:
- [1–3] – Точно не здесь
- [4–6] – Возможно здесь
- [7–9] – Точно не здесь
Индексом BRIN мы ограничили наши поиски до блоков 4-6.
Возьмем другой пример, на этот раз корреляция значений в столбцах будет близка к 0, то есть они не отсортированы:
[2,9,5], [1,4,7], [3,8,6]Индексация трех соседних блоков приводит к следующим диапазонам:
[2–9], [1–7], [3–8]Попробуем поискать значение 5:
- [2–9] – Может быть здесь
- [1–7] – Может быть здесь
- [3–8] – Может быть здесь
В данном случае индекс совершенно бесполезен, поскольку никак не ограничивает поиск.
Понимание работы pages_per_range
Количество смежных страниц определяется параметром
pages_per_range. Количество страниц на диапазон влияет на размер и точность индекса BRIN:- Большой
pages_per_rangeсоздаст небольшой и менее точный индекс - Малый
pages_per_rangeсоздаст крупный и более точный индекс
Стандартный размер
pages_per_range равен 128.Индекс BRIN с малым числом «страниц на диапазон»
Для примера создадим индекс BRIN в диапазоне двух смежных страниц и отыщем значение 5:
- [1–2] – Точно не здесь
- [3–4] – Точно не здесь
- [5–6] – Может быть здесь
- [7–8] – Точно не здесь
- [9] – Точно не здесь
С индексом в две страницы на диапазон мы смогли ограничить поиск до блоков 5 и 6. С диапазоном в три страницы поиск был ограничен до блоков 4,5 и 6.
Другое отличие двух индексов это их размеры: при числе смежных страниц в три нам необходимо было поддерживать всего 3 диапазона, тогда как при числе смежных страниц в две нам пришлось поддерживать 5 диапазонов, то есть более крупный индекс.
Создание индекса BRIN
Мы можем снова воспользоваться таблицей
sales_fact и создать индекс BRIN по столбцу sold_at с базовым pages_per_range в 128:db=# CREATE INDEX sale_fact_sold_at_bix ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 128);
CREATE INDEXДавайте создадим запрос на диапазон времени продаж:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.11..1135.61 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 23130
Heap Blocks: lossy=256
-> Bitmap Index Scan on sale_fact_sold_at_bix (cost=0.00..12.03 rows=12500 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 8.877 msБаза данных воспользовалась нашим индексом BRIN чтобы получить диапазон времени продаж, но в этом плане исполнения есть кое-что поинтереснее…
Оптимизация pages_per_range
В соответствии с планом исполнения, база данных исключила 23130 строк со страниц, которые она обнаружила при помощи индекса. Это может значить, что диапазон индекса несколько великоват для конкретно этого запроса. Давайте попробуем создать индекс с меньшим числом страниц на диапазон:
db=# CREATE INDEX sale_fact_sold_at_bix64 ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 64);
CREATE INDEX
db=# EXPLAIN (ANALYZE)
db- SELECT *
db- FROM sale_fact
db- WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.10..1048.10 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 9434
Heap Blocks: lossy=128
-> Bitmap Index Scan on sale_fact_sold_at_bix64 (cost=0.00..12.02 rows=6667 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 5.491 msС 64 страницами на диапазон база данных исключила через индекс меньше строк со страниц, всего 9434 по сравнению с 23130 при диапазоне в 128 страниц. В итоге таблице пришлось проводить меньше I/O и запрос оказался чуть быстрее, ~5.5 мс по сравнению с ~8.9 мс.
Тестирование индекса с различными значениями pages_per_range привело к следующим результатам:
PAGES_PER_RANGE ИСКЛЮЧЕННЫЕ ИНДЕКСОМ СТРОКИ
128 23,130
64 9,434
8 874
4 446
2 446Как мы видим, с уменьшением
pages_per_range индекс становится все точнее и исключает все меньшее число строк. Обратите внимание, что мы оптимизировали конкретный запрос. Это нормально для демонстрационных задач, однако в реальной жизни лучше всего пользоваться значениями, подходящими для большинства используемых запросов.
Оценка размера индекса
Следующей важной особенностью индекса BRIN является его размер. В предыдущих разделах мы создали индекс B-Tree на поле
sold_at. Размер индекса составил 2224kB. Размер индекса BRIN при pages_per_range равном 128 составляет всего 48kB, что в 46 раз меньше индекса B-Tree. Schema | Name | Type | Owner | Table | Size
--------+-----------------------+-------+-------+-----------+-------
public | sale_fact_sold_at_bix | index | haki | sale_fact | 48 kB
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kBРазмер индекса BRIN также зависит от
pages_per_range. Например, индекс BRIN при pages_per_range равном 2 составляет 56kB, что лишь незначительно больше 48kB.Делайте индексы «невидимыми»
В PostgreSQL есть удобная особенность под названием «транзакционный язык описания данных», или transactional DDL (transactional Data Definition Language). После многих лет работы с Oracle я успел привыкнуть ко многим DDL командам в конце транзакции, например
CREATE, DROP и ALTER, однако в PostgreSQL DDL команды можно проводить посреди транзакции, а перемены вступят в силу только по ее завершении.Как я недавно обнаружил, использование транзакционного DLL позволяет делать индексы невидимыми! Очень удобный прием, когда хочется увидеть план исполнения без индекса.
Например, в таблице
sale_fact из предыдущего раздела мы создали индекс по sold_at. План исполнения для получения проведенных в июле продаж выглядел следующим образом:db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.42..182.80 rows=4319 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))PЧтобы увидеть план исполнения если бы индекс
sale_fact_sold_at_ix не существовал, мы можем скинуть индекс в транзакцию и тут же произвести откат:db=# BEGIN;
BEGIN
db=# DROP INDEX sale_fact_sold_at_ix;
DROP INDEX
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on sale_fact (cost=0.00..2435.00 rows=4319 width=41)
Filter: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
db=# ROLLBACK;
ROLLBACKМы начинаем транзакцию через
BEGIN, а затем скидываем индекс и создаем план исполнения. Обратите внимание, что в плане теперь применяется полное сканирование таблицы, как если бы индекса не существовало. На текущий момент транзакция все еще в процессе и индекс еще не сброшен. Для завершения транзакции без сбрасывания индекса мы откатываем транзакцию через команду ROLLBACK.Теперь убедимся, что индекс все еще существует:
db=# \di+ sale_fact_sold_at_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+----------------------+-------+-------+-----------+---------
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kBДругие базы данных, в которых нет поддержки транзакционных DDL, предоставляют иные пути по достижению той же цели. Например, Oracle позволяет отмечать индекс как невидимый, и оптимизатор его игнорирует.
ОСТОРОЖНО: Сброс индекса внутри транзакции заблокирует наши последовательные
select, insert, update и delete в таблице на время работы транзакции. С осторожностью пользуйтесь этим функционалом в тестовых условиях, и избегайте работы с ним в продакшене.Не планируйте длительные процессы с округлением времени
Среди инвесторов давно известен следующий факт: при достижении акциями удобных круглых цен, например 10, 100, 1000 и так далее случаются разные странности. Цитируя следующую статью:
[…] цена актива с трудом может пересечь круглое значение, например 50 или 100 долларов за акцию. Большинство неопытных трейдеров пробуют приобретать активы, когда их цена достигает таких значений, поскольку подобные числа кажутся им более честными.
В этом отношении разработчики мало отличаются от инвесторов. Когда им необходимо запланировать длительный процесс, обычно они назначают его на округленное время (чаще всего ровно какой-нибудь час, например 5:00).
Типичная нагрузка на систему посреди ночи
Тенденция по планированию задач на округленное время может привести в эти часы к неожиданным нагрузкам, поэтому если вам необходимо запланировать некий длительный процесс, лучше ориентироваться на другое время. Еще одна хорошая идея – настройка случайного сдвига в графике задачи, чтобы она не проводилась каждый раз в одно и то же время. Таким образом, даже если другая задача запланирована на тот же самый час, серьезной проблемы из этого не возникнет. Если вы планируете ваши задачи через
systemd, вам поможет опция RandomizedDelaySec.Заключение
Эта статья затрагивает некоторые тривиальные и нетривиальные приемы из моего личного опыта. Некоторые из них легко имплементировать, другие же требуют глубоко понимания работы баз данных. Базы данных это основа большинства современных систем, так что выделить время для понимания их работы будет полезно любому разработчику.

Sergey-S-Kovalev
Недавно ж читал это же. Что за дежавю.
upd:
ну да вот же: Трюки с SQL от DBA. Небанальные советы для разработчиков БД
somurzakov
а еще это раньше появилось на hackernews. Вообще платные посты на хабре от корпоративных аккаунтоа превратились в:
edo1h
А так ли это плохо? )