
Я второй десяток лет участвую в разработке приложений для бизнеса на .NET и каждый раз вижу одни и те же проблемы — быдлокод и беспорядок. Месиво из сервисов, UoW, DTO-шек, классов-хелперов. В иных местах и прямой доступ в базу данных руками, логика в статических классах, километровые портянки конфигурации IoC.
Когда я был молодым и резвым мидлом — я тоже так писал. Потом бил кулаком в стену с криками: "Хватит! В следующий раз сделаю по-другому". Следующий раз действительно начинался "по-другому" — с холодной головой и строгим подходом к архитектуре — а на выходе все равно получалась та же субстанция, лучше на пару миллиметров.
Однако, эволюция — беспощадная штука: моя последняя система показалась мне более-менее близкой к идеалу. Сложность не сильно росла, скорость разработки не падала довольно долго, в систему худо-бедно въезжают новые сотрудники. Эти результаты я взял за основу, улучшил и теперь анонсирую вам свою новую разработку: Reinforced.Tecture.
Откуда берётся бардак
Вопрос, откуда в наших приложениях текут реки зловонного кода, я задавал огромному количеству людей. Говорят, мест много и вообще пенять надо на бизнес, постоянно меняющиеся требования, нанятых за копейку джунов, ошибки управления проектом, сжатые сроки… Это всё правда, но бизнес мы изменить никогда не сможем, а вот приспособить код наших приложений к подобным условиям и страдать чуть меньше — вполне в наших силах.
Если отбросить человеческие аспекты и оставить технически-архитектурные, то откуда берется весь бардак?
— Это IoC!
Нет, вы только поймите правильно: инверсия зависимостей и лайфтайм-менеджмент из одной точки приложения — это прекрасно. Но что лежит в наших контейнерах? Connection к базе данных (один на подключение), пачка каких-нибудь параметров и credentials, надёрганных из web.config (обычно синглтон) и огромные, бескрайние километры разнообразных сервисов-UoW-репозиториев. В худшем случае в формате интерфейс-реализации.
Мы это делаем, чтобы наши приложения в любой момент можно было разобрать на составные кусочки — например, для тестирования или отдачи подсистемы на разработку другой команде. Цель благородная! Ради неё, наверное, можно хранить портянки IoC-конфигурации и по два файла для каждого компонента (интерфейс-реализация).
Или нет? И тут я хочу помолиться за команды, которые догадываются использовать механизм модулей, предоставляемый почти любым IoC-фреймворком: парни, вы делаете ну хоть что-то, крепитесь.
— Это потому что нет unit-тестов!
Я вам расскажу почему их нет.
Вот давайте по чесноку: все же пробовали писать unit-тесты для традиционных C#-проектов, сделанных по методологии "UoW и Repository"? На всё вышеупомянутое содержимое контейнера надо написать заглушки и вбить тестовые данные (руками). Ну или пойти попросить себе виртуалку под тесты, на которую надо вкатить БД и залить данные, заботливо украденные с продакшена. И подчищать их после каждого прогона тестов.
В итоге на один честный тест одного метода бизнес-логики у вас уходит хорошо если день времени. А потом он начинает периодически падать потому что инфраструктура поменялась (базу переместили в другое место), коннекшн отвалился по таймауту, данные пришли позже и т.д. Стандартным ответом на это является всеми нами любимое "Билд упал? Да ерунда, перезапусти".
Такими темпами вы постепенно забиваете на написание тестов, ограничиваясь проверками каких-нибудь тривиальных хреновин вроде того, что метод копирования полей в класс из 10 строчек — действительно, блин, копирует поля! Такие тесты остаются в системе навечно и всегда выполняются "для галочки", падая, может, раз в год, когда неопытный джун сдуру сотрёт строчку при мердже. Всё остальное время они представляют собой театр безопасности кода. Все прекрасно понимают что реальное тестирование происходит "вручную", QA-отделом (в лучшем случае автоматизировано, end-to-end), а пользователи вроде не жалуются.
Опытные разработчики, которым надо релизить по фиче в неделю и закрывать по 5 тасков в день этой чушью категорически маяться не хотят — и в этом бизнес их поддерживает. Овчинка выделки не стоит. Дай боже, если на тесты набирают зелёненьких джуниоров QA Automation — их время почти ничего не стоит — нехай ковыряются.
— Это потому что мы лезем в базу руками!
Да неужели? А я-то думал что вы, как настоящие мужики, терпите, пока O/RM удаляет 3000 объектов. Все, кто хочет чтобы их приложение более-менее сносно работало по скорости — рано или поздно лезут в базу руками. Ну потому что она — база. Потому что объектная модель натягивается на реляционную как сова на глобус — долго, медленно и со слезами (см. “object-relational impedance mismatch”). А тут ещё и O/RM поощряет такие кренделя, оставляя доступ напрямую к базе (ибо как если этого не делать — его пользователи с потрохами сожрут). Как же тут не соблазниться возможностью решить задачу быстро и просто, когда нужно медленно и сложно. Безусловно, любители посылать базе SQL из приложения сами виноваты. Однако делают это не от хорошей жизни.
Это не только базы касается — имейлы тоже часто отправляют прямо из логики. И запросы ко внешним вёб-сервисам, и сообщения в очередь пихают. Очень смешно, кстати, получается, если транзакция в БД по каким-то причинам упала, а e-mail ушёл. Транзакцию-то можно откатить, а вот письмо уже обратно не всосёшь.
— Это потому что мы не следуем паттернам!
Да кто ж вам мешает — пожалуйста, следуйте. Но давайте, попробуем реализовать простую фичу. Что там надо? Написать репозиторий пользователей. Интерфейс + реализация, сделать то же самое для заказов, на основе них создать Unit of Work. Разумеется, тоже побив на интерфейс и реализацию. Потом сделать две DTOшки (а возможно больше), потом сервис, в котором использовать описанный Unit of Work, тоже разбив на две части.
Пол-дня прошло, у вас уже 10 файлов, описывающие 10 новых типов, а к разработке фичи вы ещё даже и не приступали. Потом созвон с заказчиком, обсуждение ТЗ, собеседование джуна и багфиксы. Фича же занимает своё место в долгом ящике.
Круто, если вам посчастливилось работать в огромной компании, где на IT выделяют чемодан золотых слитков в месяц, у вас 50 подопечных джунов-мидлов, а дедлайн проекта — в следующем тысячелетии. Но вообще-то есть до чёрта маленьких команд, которые себе такой роскоши позволить не могут и делают как придётся.
И их продукты иногда стреляют, после чего переписывать прототип уже нет времени — надо фичи деливерить! И если повезёт, то продукт разрастается, получает прибыль и инвестиции. А после нескольких таких фазовых переходов превращается в ту самую огромную IT-компанию, где золотые слитки и джуниоры.
— Это потому что у нас нет архитектора!
Ну а что вы хотели? Тут и крепкого мидла днём с огнём не сыщешь, а в вашей компании едва ли умеют собеседовать архитекторов. А если и умеют, то по деньгам не потянут. Вот и пускают на эту должность всяких шарлатанов, знания которых ограничиваются в лучшем случае пониманием SOLID.
Да и не готовят особо нигде этих ваших архитекторов. Сами учатся ковырять UML, бедняги. Только вот нарисовать сколь угодно красивый дизайн, декомпозировать всё на классы и подсистемы, задействовать десяток бриджей, проксей и стратегий — можно. И ревьюить весь код, самолично отрывая руки тем, кто посмеет нарушить целостность системы — можно. И жарко спорить на созвонах о том, что выделить в интерфейс и куда положить метод — тоже можно. Но это всё до первого дедлайна.
Выясняется, что красивая и грамотная архитектура (в 99% случаев) требует кучи телодвижений для решения простейших задач и внесения простейших правок. В итоге на красивый дизайн кладётся моржовый хрен и пишется так, чтобы быстрее решить задачу, учесть правки, пофиксить баг. Вершина пост-иронии — если на самого архитектора падает 50 тикетов. Ах это незабываемое зрелище, ах эти незабываемые звуки! Принципиальный блюститель паттернов и правил сам начинает писать портянки попахивающего кода в обход всякой архитектуры. Пыхтит, корчится, шаблон трещит на весь офис — лишь бы начальство по жопе не дало за сорванные сроки. Словами не передать: блажен, кто видел мир в его минуты роковые.
Жизнь сурова — между "правильно, но долго" и "быстро, но неправильно" в критических условиях всегда выбирается второй вариант. Архитекторов, которые могут сделать так, чтобы правильно было проще, чем неправильно, я не встречал. Коль скоро оно так — происходящее печально, но не удивительно.
— Это потому что фрейморк XXX — фигня!
Да, блин, большинство технологий — фигня. Опенсорс работает плохо, платные решения — тоже не без проблем. Только вот если вы откажетесь от XXX и всё перепишете — это не спасёт. Но по другой, более фундаментальной причине.
Обычно тезис из подзаголовка идёт в комплекте с "давайте всё перепишем на YYY"! Именно такие сентенции выдают розовощёкие детишки, протерев лицо от печенек с конференционного кофе-брейка. Зуб даю, именно там они про волшебный YYY и услышали.
И если бы эти ребята поглощали печенья чуть меньше, а своей головой думали чуть больше — они бы заметили, что YYY, который сделала для себя компания GGG ориентирован на решение проблем GGG. В выпуске подкаста "Мы обречены" со мной, Фил хорошо сформулировал на примере redux: "redux — это фреймворк для управления состоянием… Но не твоим состоянием!". И пусть вдохновляющие примеры а-ля "делаем на YYY приложение для подсчёта коров за 5 минут" не вводят вас в заблуждение. Между подсчётом коров и вашей условной системой автоматизации похоронного бизнеса всё же есть некоторая разница.
То есть вы увидели исключительно тот факт, что YYY хорошо ведёт себя на простых задачах, характерных для компании GGG. Надо обладать имплантированным электронным мозгом, подключённым параллельно с вашим, чтобы точно предсказать как YYY поведёт себя при решении сложных задач, характерных для вашей системы. Будет ли он так же хорош?
Очень часто технология YYY предсказуемо рвётся от несовместимости себя любимой с объективными реалиями вашей системы. А ещё бывает так, что YYY — ещё незрелый, страдает от детских болезней и будет готов к production-использованию спустя пару лет. Если его использовать прямо сейчас, то проект или благополучно подохнет, или всё вернётся на круги своя, а розовощёкие мальчики поедут кушать ещё больше печенья и искать очередную серебряную пулю.
Как прибрать весь этот мусор
Впрочем, довольно хаять объективную реальность. Ныть всякий может. Лично я хочу иметь инструмент, который я могу взять при старте проекта, просто использовать его, и оно просто будет работать. Давайте формализуем моё "просто работать" в конкретные пункты, что хочется видеть в результате:
Жизнеспособность в долгосрочной перспективе
Я уже несколько раз в одно рыло апдейтил 2000 файлов в проекте (один раз даже с помощью VB.NET-C# транслятора), больше не хочу. Хочу видеть архитектурно такую систему, которая без разрывов в паху будет резаться на части и горизонтально расширяться логически.
Минимум кода, максимум логики
Ну не желаю я создавать по 100500 классов, чтобы соблюсти принципы дизайна. Вот просто нет. Хочу фигачить фичи с космической скоростью. И при этом не ронять maintainability, проламывая им пол и пришибая соседей снизу.
Я хочу так, чтобы сделать правильно было просто. То есть требовало меньше усилий, чем сделать неправильно. Вроде довольно чёткое и благородное стремление (хотя кому-то покажется взаимоисключающим).
Чёткая организация
Задолбало думать куда положить очередной сервис, в какую сборку поместить интерфейс, в какой неймспейс кинуть DTO-шку. Так и ладно я — мне эти размышления просто замедляют работу. А придёт на проект сотня джуниоров — они ведь начнут кидать всё, куда ни попадя потому что Вася у нас художник, Вася так видит. А умудрённых сединами дедов на них на всех не хватит, чтобы в каждом отдельном случае давать ценные указания. Хочу чтобы архитектурный каркас предусматривал чёткие, понятные даже обезьяне правила и форсировал их соблюдение. Можно выпендриться и сказать "формируя у разработчика императив поведения", но я скромный.
Сюда же — грануляция. Очень хочу чтобы проблемы с грануляцией (как разложить функциональность по сервисам) мне помогала решать сама архитектура, толкая на правильные решения и выставляя разумные ограничения.
Строгая типизация
Больше строгой типизации! Нам дали в руки компилятор — так давайте выжмем из него по-максимуму! Пусть трудится на благо бизнеса. Собрать ваши интерфейсы, написанные по образу и подобию Java-вских, компилятор всегда сможет. Другое дело что пишем-то мы на C# и языковых возможностей у нас куда как больше — дженерики вон хорошие, лямбды, разные модификаторы доступа, экстеншны, ковариантность!
Разумеется, я не поддерживаю на голову стукнутых ФП-шников, которые хотят валидировать на этапе компиляции вообще все на свете и стремятся к полному автоматизированному доказательству корректности. Особенно когда они предлагают делать это через стрёмные и непонятные абстракции. Однако, стоит признать за ними определённую правоту и убойную годноту некоторых подходов. Учить новый язык ради этого я, само собой, не стану, но концепции под покровом тихой украинской ночи, перепрячу.
Удобная абстракция от внешних систем
Не хочу писать логику, полагаясь на то, что у нас есть конкретная база данных, конкретная очередь сообщений, конкретный почтовый клиент. А вот чтобы поменять базу (даже сам движок), очередь и почтовый клиент при необходимости можно было без изменений логики. Обычно для таких кренделей нужно самостоятельно выделять нужные интерфейсы и фаршировать ими DI-контейнер. Здесь же мне хочется иметь общие интерфейсы работы заранее, из коробки. В идеале — чтобы не делать эту работу заново из проекта в проект.
Проблемы с логикой — это одно, а проблемы с внешними системами — совсем другое. Большинство багов случается не потому что что-то не так с моей логикой (обычно она упирается в требования), а потому что какая-то внешняя по отношению к моему коду система повела себя не так, как я ожидал. В базе не те данные, веб-запрос падает каждую вторую пятницу каждого третьего месяца, в очередь сообщений дикпики приходят.
Я к тому, что к багам в логике у меня один подход, к багам с внешними системами — другой. Хочется чтобы дизайн системы как-то… ну я не знаю… Эксплицитно обыгрывал этот момент.
Кстати ещё хочу чтобы архитектура хорошо подстраивалась под работу с несколькими базами данных одновременно. Решить, так сказать, проблему абстрактно.
Решение проблем с тестированием
Тесты — штука нужная и важная. Не компилятором единым. Мой опыт подсказал, что регрессионного unit-тестирования на кейсах более чем достаточно. Если делать и поддерживать такие тесты будет дёшево, то их можно будет сделать много. А тут уже можно взять количеством. Как говорится, главное завалить — а там ногами запинаем.
Категорически необходимо как-то решить проблему с хранением тестовых данных. Тестовая база для разработки у меня есть, конечно же. Но поднимать её в рамках CI-билда категорически не хочется. Да и потом — я не хочу тестировать сервер баз данных! Его уже тестируют умные дяденьки за большие деньги. Надо чтобы тестировался мой код, который я написал. А всё остальное — не надо.
Вбивать руками тестовые данные, которые уже, блин, лежат в базе — тоже не хочу. Разве умная машина не может сделать это сама?
Разумеется, это должны быть честные meaningful-тесты, которые будут падать при критических изменениях в функциональности, сигнализируя что надо поправить. А ещё будет совсем хорошо если на их написание не будет уходить по полдня времени.
Тут ещё вот что надо заметить: как мы разрабатываем? Заводим тестовые данные, что-то пишем, запускаем-дебажим, уточняем требования, снова что-то пишем, снова дебажим… Потом в какой-то момент коммитим задачу, пропускаем через QA, мерджим бренч, после чего задача считается решённой. Это логично, все так делают. Так вот, хочется впаять автоматизированное тестирование в этот процесс так, чтобы после приёмки, когда все — от QA до бизнеса сказали "да, это работает правильно", настрогать тестов, не меняя функциональность и кинуть в общую кучу, дабы прогонялись каждый билд. Можно даже какой-нибудь code coverage замутить. Меняешь логику — видишь что упало. Ну круто же!
А вот TDD — на фиг если честно. Невозможно загодя написать тесты для фичи, функциональность которой толком не известна до момента её сдачи. Поэтому ориентироваться на TDD я не стану.
И таким образом...
И таким образом, мы имеем на руках примерное представление о том, что хотим получить от идеальной архитектуры приложения. В следующей статье я поделюсь с вами тем, к чему мне удалось прийти и расскажу почему такое решение мне кажется правильным. А так же расскажу и покажу на примере маленького проекта как Tecture может сделать жизнь лучше.
Оставляйте пока что комментарии — мне интересно услышать ваше мнение, даже если оно будет негативным.
UPD: Здесь была ссылка на репозиторий проекта, но я её удалил потому что она провоцировала нерелевантные пока обсуждения.














marshinov
Из статьи и исходников не вполне понятно:
pnovikov Автор
Спрашивали — отвечаем:
marshinov
3. Ну так не годится. Зачем мне давать денег на исследования, если есть продукты-субституты? Вы же попросили подискутировать. Я судя по ответам на 1 и 2 — ваша ЦА. Вам выгодно, чтобы ЦА интересовалась продуктом, контрибьютила может даже. Иначе зачем публиковать наработки?
4. Таки прям никакого…
pnovikov Автор
3. Сожалею, у меня нет богатых родственников, готовых меня кормить полгода пока я пишу огромную документацию, у меня нет компании, готовой выделять команду под разработку и обкатку моих проектов, я делаю всё сам. Поэтому боюсь что у вас нет опций кроме как ждать. Ну или клонировать репозиторий, потыкать код и оценить границы применимости используя свою собственную квалификацию.
4. Вы открыли плейграунд-проект, который используется для обкатки фреймвока с группой добровольцев. Этот проект иллюстрирует возможность применения фреймворка для web-приложений. После обкатки этот кусок уйдёт в отдельный репозиторий.
pnovikov Автор
Окей, понял. Вот развёрнутый ответ:
3. Я ориентируюсь на два критерия: количество фич в условную единицу времени — в неделю там, в месяц или сколько там длится спринт… И на стабильность/верифицируемость получающегося решения в долгосрочной перспективе — предотвращение багов и сокращение регрессии.
Повышение количества фич достигается базово путём сокращения количества кода, необходимого для реализации требуемой функциональности и раннего устранения багов посредством некоторого числа compile-time проверок благодаря активному использованию системы типов C#. Конкретно же это достигается путём упрощения структуры приложения для разработчика, сведения к минимуму количества нерелевантных абстракций при сохранении необходимого уровня контроля, гибкости и создания удобных точек расширения во всех местах, в которых расширение может потребоваться. Таким образом, задача создания инфраструктурного кода с разработчика снимается настолько, насколько это возможно, позволяя сконцентрироваться непосредственно на бизнес-логике.
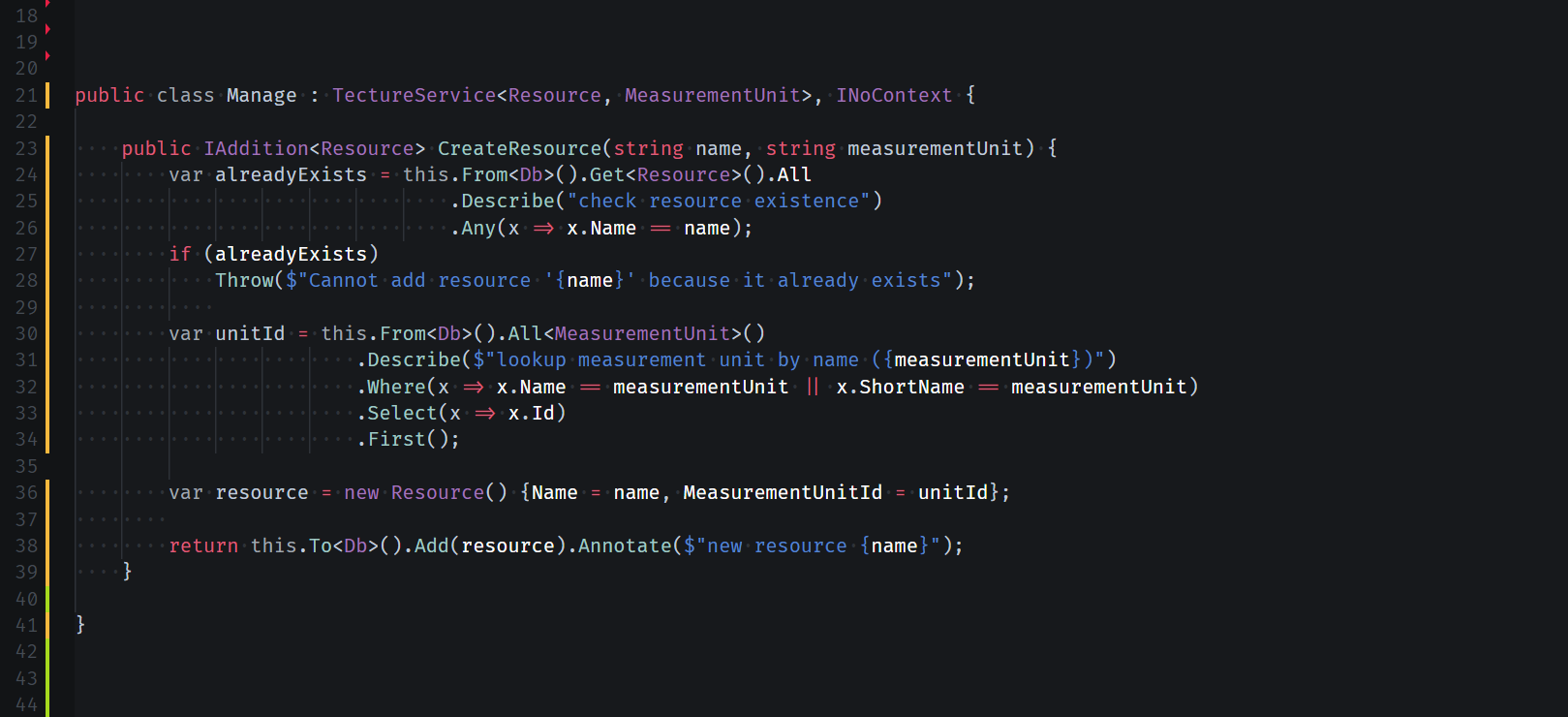
Простота структуры обуславливается разделением всего приложения на команды и запросы: эту концепцию я позаимствовал из CQRS, только адаптировал под внутреннее использование в приложении. Команды складываются в очередь исполнения, которая начинает раскручиваться при вызове `Save`, а запросы производятся непосредственно. За счёт правильного абстрагирования тулинга запросов у источников данных — отпадает необходимость строить леса абстракций для запросов (e.g. репозитории) в пользу написания оных в форм-факторе метода расширения для источника данных (своеобразная условно-чистая функция). Методы запросов могут быть generic (даже с констрейнтами): по задумке они должны цепляться к «запросному» концу канала благодаря — опять же — системе типов C#. Вот так я убираю примерно половину абстракций и IoC-записей у системы — путём вынесения запросной функциональности в бесконтекстное пространство. Идея диктуется самим LINQ в C# (методы .Where, .Any и т.п.), которую я немного модифицировал, обыграв абстракцию для запроса (хорошо наблюдается на примере ORM-фичи).
При том Tecture не пытается инкапсулировать в себе весь окружающий мир, реализовать свой собственный ORM, или там очередь сообщений, whatever. Он — просто удобная абстрактная прокладка между бизнес-логикой и внешним миром, которая ни коим образом не запрещает вам использовать фичи любого существующего фреймворка, если вдруг у вас возникнет такая необходимость. Точек расширения оставлено достаточно, чтобы вы без разрыва головы могли сами впаять поддержку того, что считаете нужным. Я вот сделал поддержку ORM и реализацию к ней на EF.Core. Не стану скрывать что основные абстракции и внешний дизайн EF.Core мне импонируют, поэтому при разработке ORM-фичи я смотрел именно на него, плюс немного на Dapper и маленький ORM от ServiceStack. SqlStroke — моя авторская задумка, так же хорошо зарекомендовавшая себя в ряде проектов.
Повышение стабильности решения достигается посредством генерации data-driven регрессионных unit-тестов с автоматическим захватом тестовых данных. Фактически, стоимость создания и обслуживания подобных тестов при использовании фрейморка — нулевая. По задумке это должно побудить разработчиков писать больше meaningful-юнит тестов, которые прекрасно будут встраиваться в code coverege и live coverage-тулы вроде NCrunch, что позволяет в удобной форме сохранять метаинформацию о работоспособности бизнес-логики на конкретных кейсах, а портянки тестов при необходимости можно перегенерировать.
О конкретных цифрах говорить пока рано: некий прототип этого решения уже использовался на живом проекте для одного заказчика и показал себя весьма эффективно. Из нашего кода исчезло 90% репозиториев, но появились длинные бесконтекстные extension-методы, с которыми, тем не менее, было достаточно легко работать просто потому что они располагались целиком в отдельном файле и были названы правильно. Это всё, что я могу сказать на эту тему на текущий момент. Именно с этой целью в репозитории есть Playground-проект, дабы все желающие могли попробовать фреймворк «в деле». Это общая песочница, в которой нет никаких ограничений на чистоту кода и корректность используемых подходов, ибо как целью ставится — поставить фреймворк в неудобное положение. Сейчас на этот проект по мере наличия свободного времени и желания смотрят мои коллеги — я добавил их как контрибьюторов, но в виду добровольности всего происходящего время выделяется по остаточному принципу, поэтому быстрых результатов ждать не стоит. Глупо на этой страдии требовать полного отчёта с цифрами, сравнения с другими фреймворками, детальной документации и упаси б-же записей выступления с конференций, например — просто потому что бюджета на проект нет никакого, разрабатывается он моими силами.
Вот чтобы осветить эти подробности я и хотел сделать следующую статью, иначе размеры комментариев становятся совершенно неприличными.
4. Нет нет и ещё раз нет. К web-у проект не имеет СОВЕРШЕННО никакого отношения. Ни к web, ни к микросервисам, ни к чему. Он может использоваться и в web-приложениях, и в консольных, и в десктопных (хотя в основном задумывался для backend-части приложений), но в дизайне решения не предусмотрено эксплицитно никаких специальных для этого инструментов. Зависимостей у ядра проекта — 0. Он не требует от вас установки yarn, node, использования ASP.NET MVC и вообще ничего за собой не тянет, потому как не пытается быть комбайном-для-всего, коим является, скажем, Spring. Целью ставилось создать минимально-необходимый набор абстракций, от которого будет удобно плясать и попытаться поплясать в каком-то конкретном направлении — например в направлении работы с БД и оценить возможность использования разработки, скажем, в web-е.
Playground-проект, на который вы смотрите — это попытка понять насколько дорого выходит прикрутить Tecture к шаблонному ASP.NET MVC-приложению. Насколько удобно использовать его оттуда, составить общее понимание о том, как меняется внешний вид кода и его логика, да и просто чтобы попробовать сделать что-либо законченное-энд-юзерское а не ковыряться в абстракциях до посинения. Playground-проект, само собой не является частью поставки решения и создан в исследовательских и калибровочных целях. Сторонний же наблюдатель может пощупать его руками, дабы оценить на практике преимущества и недостатки. У меня стали просить ссылку на «пощупать» — я её и дал. Однако сейчас я понимаю что без контекста она не то чтобы сильно полезна.