
Автор: Иннокентий Сенновский (rumata888)
Как заинтересовать студента скучным предметом? Придать учебе форму игры. Довольно давно кто-то придумал такую игру в области безопасности — Capture the Flag, или CTF. Так ленивым студентам было интереснее изучать, как реверсить программы, куда лучше вставить кавычки и почему проприетарное шифрование — это как с разбегу прыгнуть на грабли.
Студенты выросли, и теперь в этих «играх» участвуют и взрослые прожженные специалисты с детьми и ипотекой. Они многое успели повидать, поэтому сделать таск для CTF, чтобы «старики» не ныли, не самая простая задача.
А переборщишь с хардкором — и взвоют команды, у которых это непрофильная предметная область или первый серьезный CTF.
В статье я расскажу, как наша команда нашла баланс между «хм, нечто новенькое» и «это какая-то жесть», разрабатывая таск по крипте для финала CTFZone в этом году.
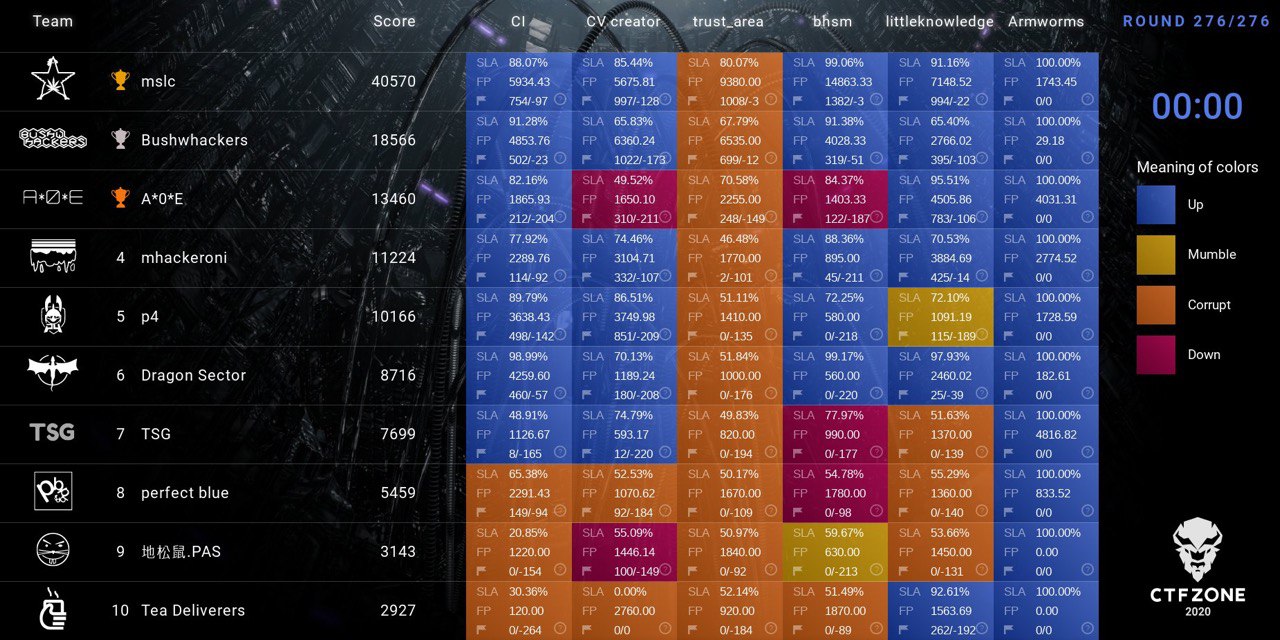
Финальный scoreboard CTFZone 2020
Содержание
- Необязательное введение: объясняем CTF за 2 минуты
- Как мы поняли, что нам нужна крипта
- Как мы выбрали стек
- Как мы нашли идею для задания
4.1. А. Что такое Гамильтоновость графов
4.2. Б. Как идентифицировать себя с помощью Гамильтонова цикла - Как мы построили задание
5.1. Протокол: вид сверху
5.2. Протокол: внутренности
5.3. Последняя уязвимость - Как мы разрабатывали таск
- Как мы тестировали таск
- Как мы боролись с читерством
- Заключение
Необязательное введение: объясняем CTF за 2 минуты
Для тех, кто не знаком с CTF, — это соревнования среди специалистов по практической кибербезопасности. Их проводят профильные организации, CTF-команды и университеты.
Различают два вида турниров: jeopardy и attack-defense.
Турниры jeopardy проходят онлайн. Он устроены по формату американской телевикторины «Jeopardy!», в российской версии известной как «Своя игра». Участникам предлагают разнообразные задания, за выполнение которых начисляют очки. Чем сложнее задание, тем «дороже» правильный ответ. Выигрывает команда, у которой больше всего очков.
Турниры attack-defense (AD) немного сложнее. Участники соревнуются в предоставленной организатором инфраструктуре, поэтому такие соревнования обычно проводят офлайн — например на конференциях. Часто в этом формате проходят финалы: для участия в attack-defense командам нужно попасть в топ-10 или топ-20 по итогам отборочного турнира jeopardy.
На старте соревнования AD команды получают vulnboxes — виртуальные машины или хосты с уязвимыми сервисами, которые необходимо защищать. У всех команд vulnboxes одинаковые. Задача участников — защитить свои хосты, при этом сохранить их доступность для сервера проверки (checker). То есть нельзя обеспечить безопасность хоста, просто закрыв к нему доступ.
Одновременно нужно атаковать хосты соперников, чтобы захватить флаги — уникальные идентификаторы, которые сервер проверки размещает на хостах на каждом раунде. Как правило, раунд длится 5 минут. За захват флага команды получают очки. Если vulnbox не доступен для сервера проверки, очки отнимаются.
Итак, перед каждой командой стоят следующие цели:
- поддержать функционирование vulnbox;
- устранять ошибки, чтобы защитить его от атак;
- атаковать хосты соперников, чтобы захватить флаги.
Если вы когда-либо принимали участие в CTF, то наверняка помните, что задания разделяются на несколько категорий:
- web,
- pwn,
- misc,
- PPC,
- forensic,
- reverse,
- crypto (то есть криптография, а не криптовалюта).
Бывают и миксы, и задания вне категорий, но вообще этот список скорей описывает задания для турниров jeopardy. У некоторых тасков нет интерактивного компонента, и для AD они плохо подходят. В категории «Криптография» тоже есть свои нюансы, из-за которых мы долго сомневались, включать ли крипту в финал нашего соревнования CTFZone.
Как мы поняли, что нам нужна крипта
Планируя финал CTFZone, мы обсуждали, есть ли смысл разрабатывать криптографический таск для турнира AD.
Дело в том, что ошибки на каждом уязвимом хосте в рамках AD, как правило, имеют разный уровень сложности. Простые ошибки закладывают, чтобы их смогли обнаружить более слабые команды и порадоваться маленькой победе. Сильным командам такие ошибки позволяют быстрее захватить флаги соперников, и это придает состязанию динамичности.
К сожалению, в случае с криптографией уже на первой ошибке команды могут застрять. Придумывать новые простые криптографические уязвимости довольно сложно. В результате приходится использовать широко известные уязвимости, например повторное использование nonce в ECDSA, которые опытные команды обнаруживают сходу, а новички не могут найти вовсе.
Если исключить простые ошибки, можно сделать еще хуже. Как-то я участвовал в AD-состязании со сложными и интересными криптографическими заданиями, где простых тасков не было совсем. Но проблема была в том, что в каждом раунде захватить флаг удавалось только одной команде: кража по сути стирала флаг. Такая схема разочарует атакующих, которые потратили время на продумывание атаки, а в результате ничего не получили.
Иными словами, криптографические задания довольно часто разочаровывают либо организаторов (потому что команды недостаточно углубляются в задание), либо участников. Поэтому у нас были большие сомнения, стоит ли вообще делать крипту.
Однако вскоре стало понятно, что без криптографического компонента у нас окажется слишком много веба, а в CTF важно разнообразие. Так что выбора не осталось — нужно было делать таск.
Таск должен был быть сложным, но одновременно под силу новичкам, но чтобы решение стоило потраченных усилий. Элементарно, не правда ли? :)
Как мы выбрали стек
Как правило, найти и устранить ошибки при выполнении криптозаданий достаточно просто, потому что они чаще всего написаны на скриптовых языках типа Python. Читаешь код, замечаешь ошибку и устраняешь ее.
Мы подумали, что для квалификационного этапа DEF CON это несерьезно, поэтому для нашего стека решили использовать Python + C (звучит убийственно, знаю). Большая часть функциональности была реализована на языке C, тогда как Python обеспечивал удобную обертку для манипуляций с сокетами, а также функциональность сервера.
После того, как мы определились со стеком, надо было понять, какие системы использовать и какие ошибки предусмотреть в этих системах.
Как мы нашли идею для задания
Мы не хотели, чтобы в задании было много уязвимостей, известных любому участнику CTF, поэтому решили остановиться на менее стандартном решении — Zero Knowledge Proofs of Knowledge (ZKPoK), то есть протоколе доказательства с нулевым разглашением. Идея заключается в том, чтобы доказать, что вам известна какая-либо секретная информация, не раскрывая эту информацию. Было решено использовать ZKPoK в качестве схемы идентификации: если сервер проверки сможет что-либо доказать, он получает флаг. В основу нашей схемы была положена гамильтоновость графов.
А. Что такое Гамильтоновость графов
Оговорка. Я не математик и не криптограф. Нижеприведенные утверждения могут быть неверными с математической точки зрения и не учитывать все детали. Моя цель — рассказать о концепции, не перегружая читателя излишними подробностями.
Итак, допустим, есть некий граф. Цикл, который проходит через каждую вершину этого графа ровно по одному разу, называется Гамильтоновым.
Найти Гамильтонов цикл для графа — сложная задача. С другой стороны, создать граф с Гамильтоновым циклом проще простого. Я покажу, как это сделать.
Но сначала немного вводной информации.
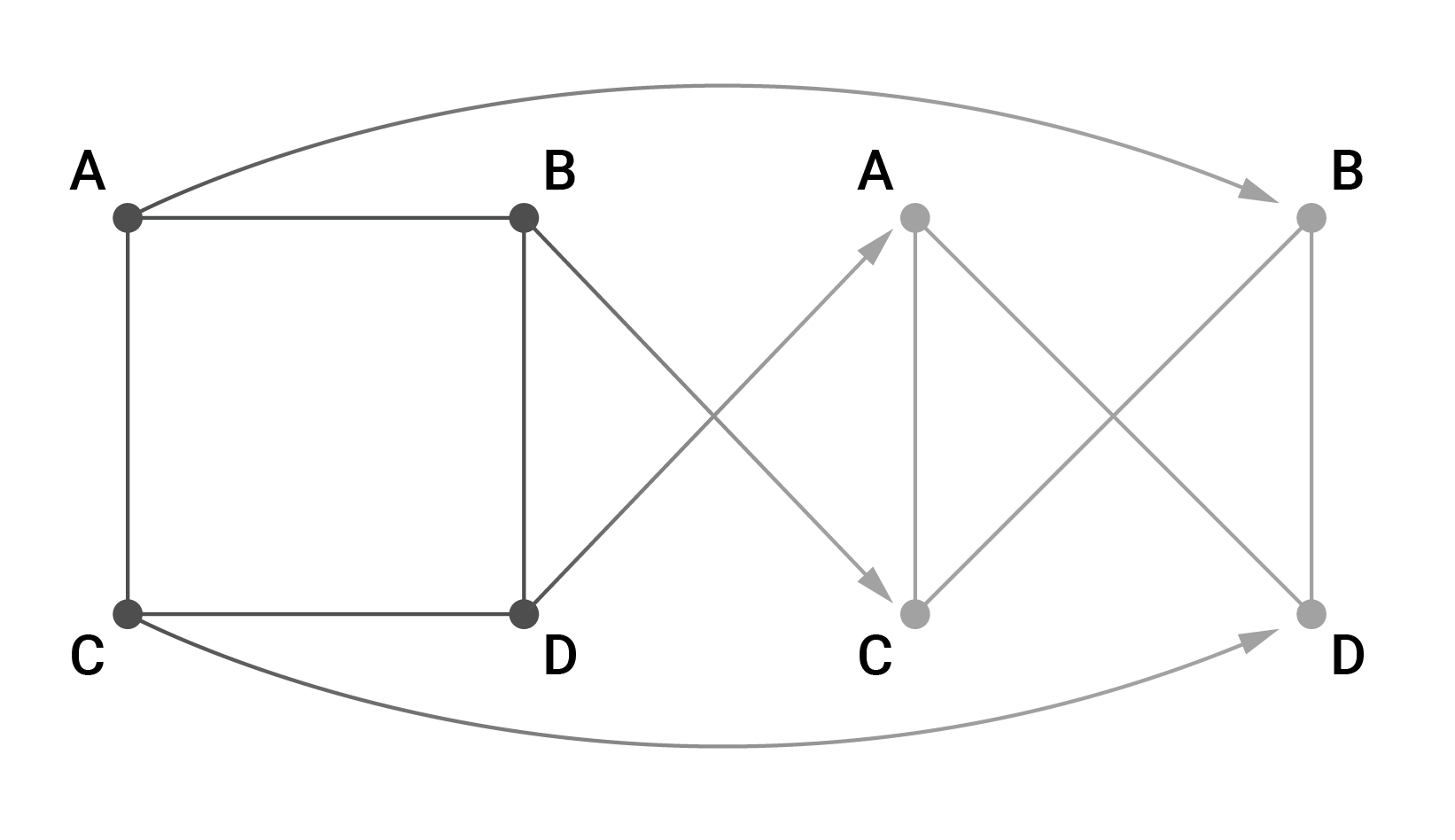
Мы решили представить наши графы с помощью матриц смежности. Это квадратные матрицы, в которых две вершины, соединенные ребром, обозначаются единицей в соответствующей ячейке, и нулем, если они не соединяются. Например, имеется 4 вершины: A, B, C, D. A соединена с B, C соединена с D.
Матрица будет выглядеть следующим образом:
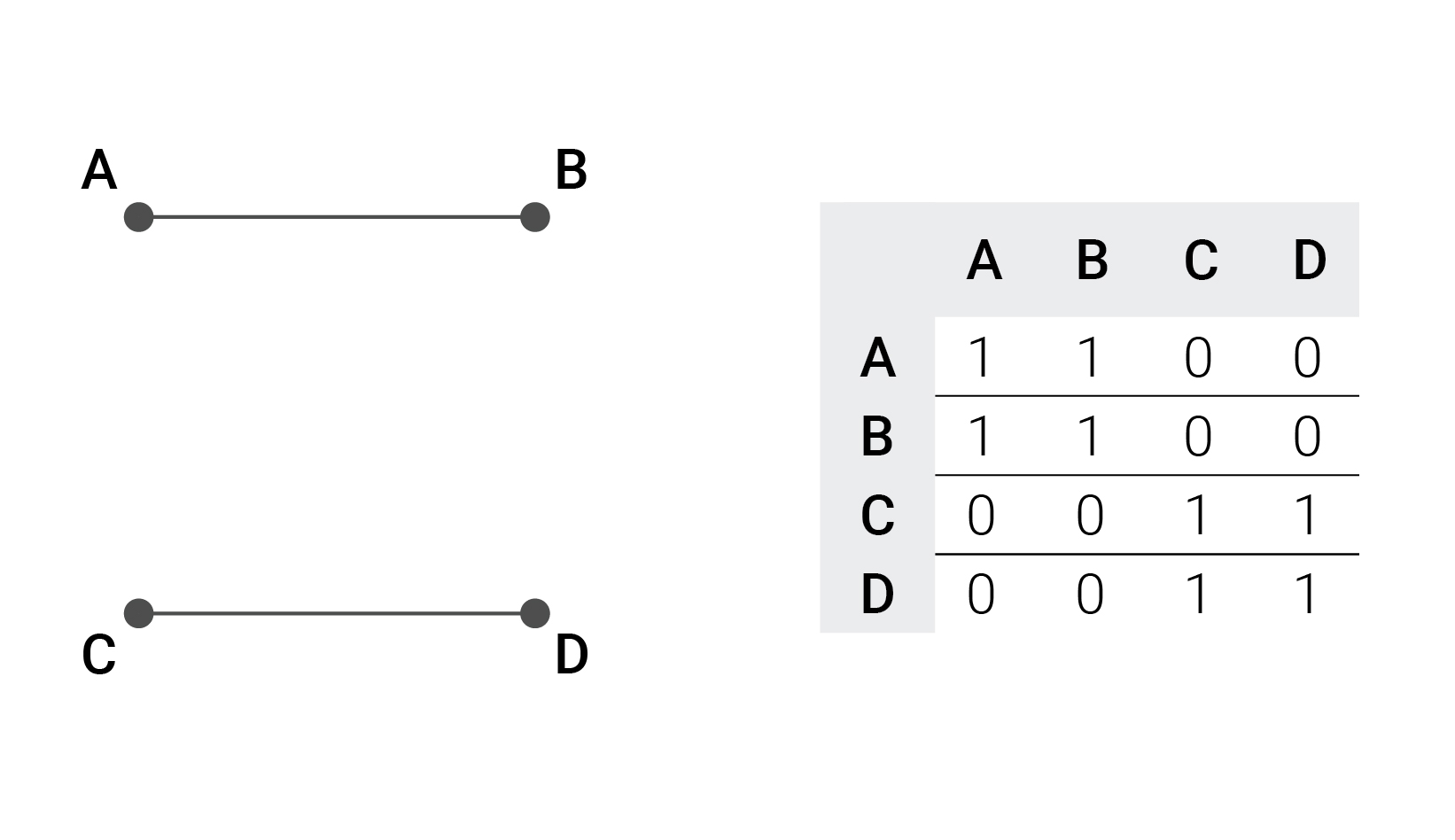
В зависимости от того, какие задачи вы решаете с помощью графа, диагональ можно заполнить нулями или единицами.
Итак, если вы создаете граф с известным Гамильтоновым циклом, первым делом нужно перемешать массив вершин: например, ABCD > BADC. Из этого массива вы определяете циклический порядок следования вершин (контур): B>A>D>C>B.
Далее вы отображаете эту зависимость при помощи матрицы. На первом шаге все ячейки в матрице заполнены нулями. Затем для каждого направленного ребра графа вы заменяете текущее значение в ячейке на единицу. Ряд этой ячейки определяется индексом начальной вершины этого ребра, а столбец — индексом конечной вершины. Получаем следующее:
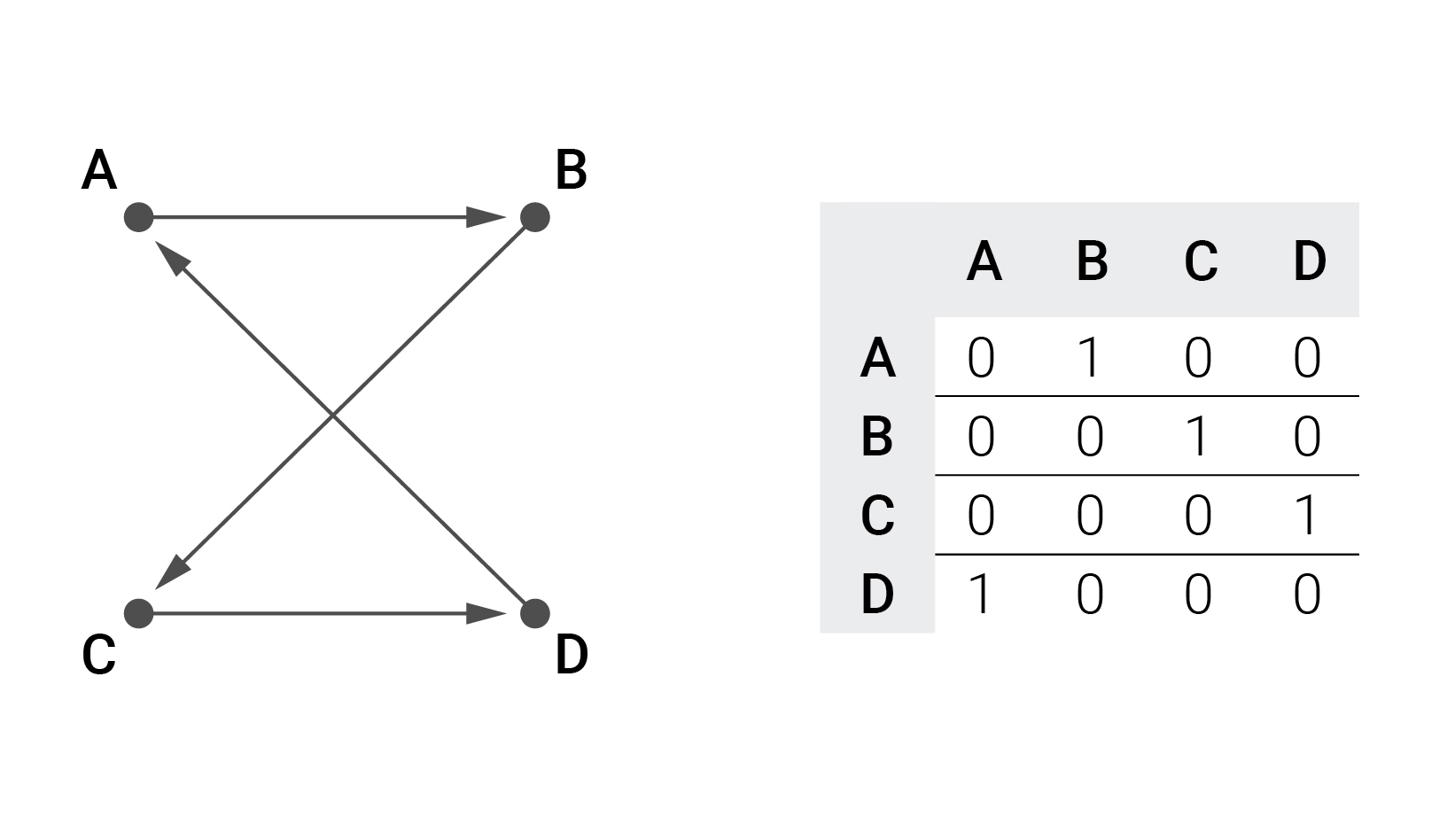
В результате получаем матрицу, у которой в каждом столбце и в каждом ряду по одной единице. Теперь у нас есть Гамильтонов цикл.
На основе полученного цикла мы легко можем создать граф, добавив произвольные ребра. Нам удобнее будет использовать симметричные графы, поэтому для ребра добавляем симметричное ему, если оно еще не существует.
Один из возможных результатов таких действий — это следующая матрица смежности:
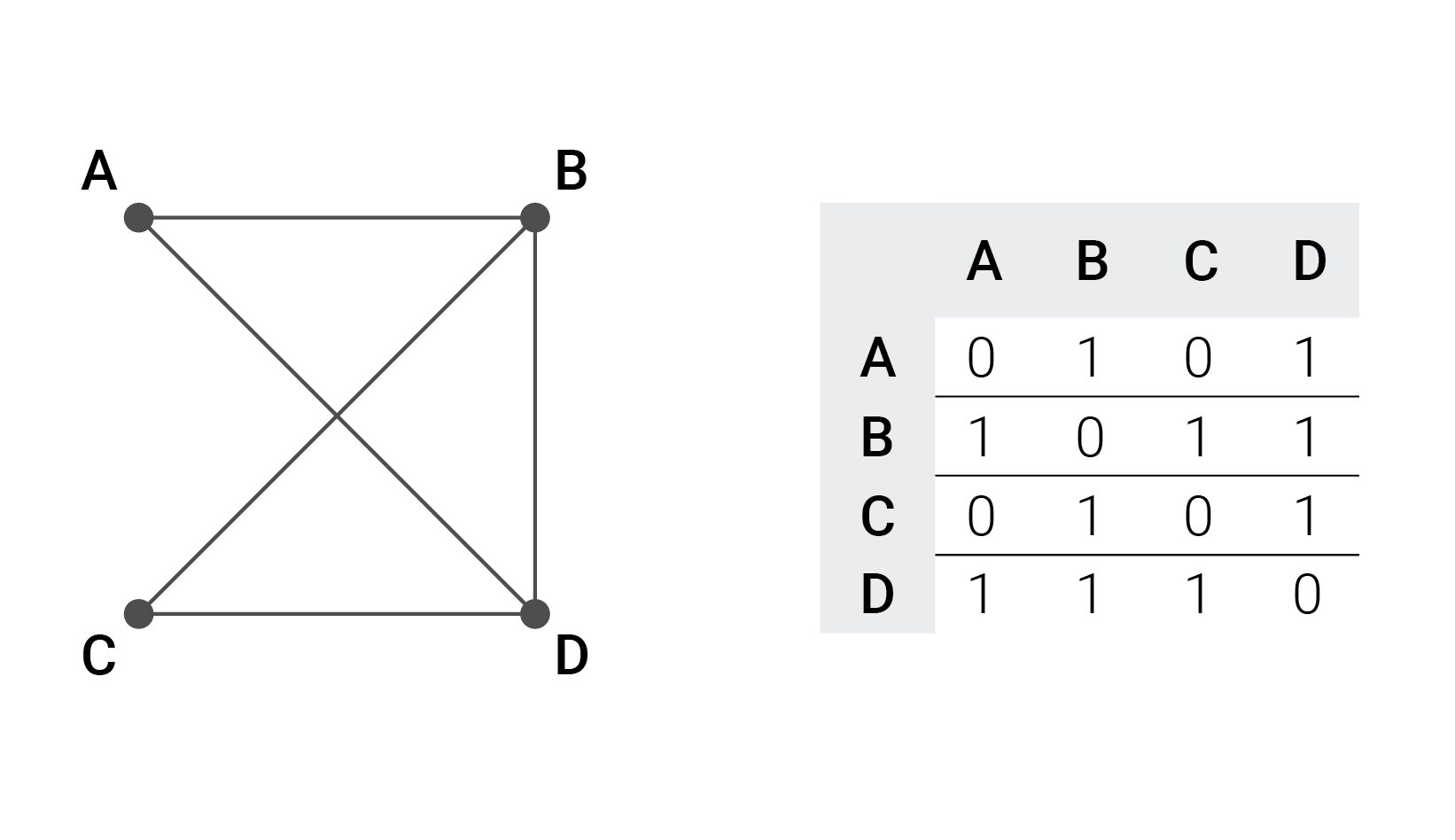
Как видно, каждому ребру (x, y) соответствует (y, x), и я добавил ребро между B и D.
Б. Как идентифицировать себя с помощью Гамильтонова цикла
Схема простая:
- каким-нибудь другим методом публикуем граф, который содержит Гамильтонов цикл. Он в открытом доступе и виден всем;
- подключаемся к серверу команды и доказываем, что нам известен цикл, не раскрывая сам цикл.
Часть с доказательством проходит в три этапа, не считая подготовительного, при этом мы принимаем роль Доказывающего (Prover), а сервер выполняет роль Проверяющего (Verifier).
0. Подготовительный этап. Мы переставляем вершины графа в случайном порядке, например: A>B>C>D>A. Используя эту перестановку, мы получаем новый граф, который будет изоморфным (т. е. все отношения между элементами сохранятся) по отношению к первому. Это достигается за счет представления перестановки в виде графа и выполнения нескольких операций по умножению и транспонированию (симметричному отображению элементов относительно диагонали) матриц.
Далее мы вычисляем Гамильтонов цикл на новом графе, применяя такие же перестановки к матрице инцидентности этого цикла. В качестве результата мы получаем новый граф с Гамильтоновым циклом — тоже изоморфный по отношению к исходному.
1. Этап обязательства. Получив новый граф, мы отправляем на сервер так называемое обязательство (commitment). В нашем случае обязательство содержит граф, созданный путем перестановки вершин, и два закрытых контейнера: первый содержит созданную нами перестановку, а второй — цикл, полученный в результате перестановки. Проверяющий получает оба контейнера в запечатанном виде, поэтому он не может заглянуть внутрь, но Доказывающий может раскрыть их содержимое в любое время.
Обязательства должны обладать двумя важными свойствами:
- скрывать данные. У Проверяющего не должно быть возможности открыть контейнеры без помощи Доказывающего;
- носить обязательный характер. Если Доказывающий принял на себя обязательство, у него не должно быть возможности изменить содержимое контейнеров. У него есть только один выбор: оставить крышку открытой или закрытой.
2. Этап вызова. После того как Доказывающий направил свои обязательства, Проверяющий произвольно выбирает бит вызова (challenge) и отправляет Доказывающему. В ответ на это Доказывающий направляет информацию, в которой открывается или первый (если ) или второй (если ) контейнер обязательства.
Случайный бит вызова нужен, чтобы Доказывающий не знал заранее, какой контейнер придется открыть — иначе он легко обманет Проверяющего.
3. Этап проверки. Теперь, в зависимости от выбранного бита вызова, Проверяющий может узнать либо перестановку, при помощи которой Доказывающий создал новый граф, либо Гамильтонов цикл на новом графе. То есть Доказывающий убеждает Проверяющего либо в том, что он знает цикл на новом графе, либо в том, что новый граф изоморфен опубликованному.
Вся прелесть состоит в том, что предоставить доказательства для обоих утверждений может только честный Доказывающий, которому действительно известен Гамильтонов цикл на оригинальном графе. Без этих знаний можно лишь пытаться обмануть Проверяющего, угадав, какой бит вызова он сгенерирует.
Последнее можно легко доказать путем моделирования. Представим, что мы как Доказывающий можем обратить часть этапов в протоколе и изменить обязательство уже после получения бита вызова . Зная , мы всегда можем обмануть Проверяющего: если , сгенерировать случайную перестановку и изоморфный граф на ее основе, а если , сгенерировать граф с новым гамильтоновым циклом. Далее мы принимаем обязательства в отношении первого или второго согласно известному , Проверяющий выпускает такой же бит вызова еще раз и проверяет открытое обязательство. Так как в этом случае доказательства были сгенерированы не на основе гамильтонового цикла на изначальном графе, Проверяющий не может выжать какую-либо информацию из доказательства (в случае с реальным Доказывающим, то есть не в ходе моделирования).
Как вы, наверное, поняли, всегда есть 50-процентная вероятность, что злонамеренный Доказывающий успешно проведет атаку, не имея информации об исходном цикле. Если это выполнить только один раз, о безопасности не будет и речи. Но такая последовательность и не предполагает разового выполнения. Цель состоит в том, чтобы Проверяющий и Доказывающий проделали все этапы несколько раз. При одном повторе вероятность обмана составит 25%, при двух — уже 12,5% и т. д. Всегда можно задать количество повторов, которые вписываются в ваши границы риска.
Вот такую систему мы решили внедрить в качестве схемы идентификации для сервера проверки.
P.S. Если вы мало что поняли из сказанного выше или хотите больше узнать о Zero Knowledge, почитайте блог д-ра Мэтью Грина Zero Knowledge Proofs: An illustrated primer. Он объясняет концепцию куда понятнее меня.
Как мы построили задание
Примечание. Далее по тексту «сервер команды» = «Проверяющий», «сервер проверки» = «Доказывающий», «атакующая команда» = «злонамеренный Доказывающий».
Протокол: вид сверху
Мы решили, что количество вершин графа будут определять сами команды, поэтому мы не могли использовать один и тот же граф для всех. Чтобы решить эту проблему, в начале каждого раунда сервер проверки уточнял у сервера каждой команды, насколько большой граф ему нужен, и создавал граф с требуемым количеством вершин и известным Гамильтоновым циклом. Далее он направлял серверу команды:
- граф;
- флаг для соответствующего раунда;
- 16-байтовую произвольную строку RANDOMR, полученную с сервера команды;
- RSA-подпись всех вышеуказанных величин.
Величина RANDOMR была необходима, чтобы команда не могла повторно использовать пакет с валидной подписью для построения такого же графа на серверах других команд.
Кстати, здесь и была заложена первая ошибка: флаг таким способом нельзя было украсть, но можно было произвести DoS-атаку на команду противника. Мы выбрали схему подписи PKCS#1 v1.5. Она в целом не является уязвимой, за исключением некоторых ее реализаций, которые могут быть уязвимы к атаке Блейхенбахера на подпись с экспонентой 3 (Bleichenbacher's e=3 signature attack). Чтобы создать возможности для проведения такой атаки, мы выбрали значение 3 для открытой экспоненты открытого ключа и реализовали уязвимый алгоритм снятия дополнения (очевидно, что SAFE_VERSION macro не был определен):
uint8_t* badPKCSUnpadHash(uint8_t* pDecryptedSignature, uint32_t dsSize){
uint32_t i;
if (dsSize<MIN_PKCS_SIG_SIZE) return NULL;
if ((pDecryptedSignature[0]!=0)||(pDecryptedSignature[1]!=1))return NULL;
i=2;
while ((i<dsSize) && (pDecryptedSignature[i]==0xff)) i=i+1;
if (i==2 || i>=dsSize) return NULL;
if (pDecryptedSignature[i]!=0) return NULL;
i=i+1;
if ((i>=dsSize)||((dsSize-i)<SHA256_SIZE)) return NULL;
#ifdef SAFE_VERSION
//Check that there are no bytes left, apart from hash itself
//(We presume that the caller did not truncate the signature afteк exponentiation
// and the dsSize is the equal to modulus size in bytes
if ((dsSize-i)!=SHA256_SIZE) return NULL;
#endif
return pDecryptedSignature+i;
}После настройки графа сервер проверки каждые 30 секунд делал следующее:
- подключался к серверу каждой команды;
- запрашивал число проверок, которые хочет провести сервер команды;
- доказывал, что ему точно известен Гамильтонов цикл.
Предполагалось, что в случае верного доказательства сервер команды отдает флаг.
Примечание. Чтобы сократить количество циклов в раунде, мы предусмотрели одновременные, а не последовательные доказательства. Однако стоит принять во внимание, что в реальных условиях это может быть проблематичным, так как такие изменения могут нарушать математические доказательства протоколов.
Протокол: внутренности
Мы рассмотрели общий протокол, а теперь обратимся к уязвимостям, которые мы предусмотрели.
Наш языковой стек — Python + C. Мы создали библиотеку C, содержащую 95% функциональности приложения. Затем мы создали классы поддержки на Python для Доказывающего и Проверяющего. Они включали указатели на соответствующие структуры и обертывали вызовы библиотеки. (Кстати, будьте внимательны при работе с void_p в ctypes. В 64-битных системах он может быть урезан до 32 бит при передаче в качестве аргумента в функцию).
Основной скрипт сервера команды на Python содержал инициализацию Проверяющего:
verifier=Verifier(4,4,7)Аргументы были следующие:
- Желательное количество вершин в графе.
- Количество одновременных доказательств.
- Выбранные алгоритмы обязательств.
Разберем их по порядку.
Число вершин в графе. Как можно догадаться, четырех вершин, как в примерах выше, совсем не достаточно для безопасной конфигурации: все возможные циклы можно с легкостью перебрать.
Что касается максимально разрешенного количества вершин, то мы остановились на 256. Не стали увеличивать его по двум причинам:
- Во-первых, чтобы установить изоморфизм графов с таким параметром, требовалось 2 часа на обычном ноутбуке (по крайней мере, так показала наша проверка). Вероятность того, что атакующие команды найдут цикл быстрее чем за 5 минут, представлялась при нашей модели злоумышленника как минимум оптимистичной.
- Во-вторых, зависимость между размером доказательства в байтах и количеством вершин является квадратичной, а нагружать сеть особого желания не было.
Количество одновременных доказательств. Как и в случае с вершинами, четырех параллельных доказательств недостаточно, чтобы говорить о какой-то безопасности. Вероятность правильного угадывания битов доказательства составляет . Можно пробовать несколько раз и после ряда попыток все получится.
Максимальное значение, поддерживаемое функцией инициализации, составляло 64, что означало вероятность читерства . При наших времени раунда и мощностях злоумышленника — практически никаких шансов.
Итак, вторая ошибка — уязвимая конфигурация количества вершин и числа доказательств.
Алгоритмы обязательств. Этот параметр по сути является битовой маской, 3 возведенных бита которой означают, что на сервере команды доступны все три реализованных алгоритма обязательства:
- обязательства, в основе которых лежат "хеши" CRC32;
- обязательства, в основе которых лежат хеши SHA-256;
- обязательства, в основе которых лежит шифрование при помощи AES-128 в режиме CBC.
Правильными значениями для данной битовой маски будут , так что командам необходимо выбрать хотя бы один алгоритм. Сервер проверки выбирает их в следующей последовательности: CRC32, SHA-256, AES. Так, если доступны CRC32 и AES, приоритетным будет CRC32.
Прежде чем углубиться в алгоритмы обязательства, давайте вкратце остановимся на реализованном протоколе доказательства:
- Доказывающий запрашивает конфигурацию доказательства у Проверяющего (количество доказательств и поддерживаемые алгоритмы).
- Проверяющий в ответ направляет конфигурацию.
- Доказывающий создает доказательства, обязательства из доказательств и отправляет 1. Доказывающему обязательства по количеству доказательств proof_count.
- Проверяющий направляет Доказывающему вызов (случайные биты в количестве proof_count).
- В ответ Доказывающий направляет информацию, которая раскрывает обязательства в соответствии с вызовом.
- Проверяющий проверяет корректность доказательств и, если все верно, возвращает флаг.
- Доказывающий на этом останавливается либо начинает заново с шага 3.
И вот тут есть хитрая деталь. Доказывающий может попытаться начать с любого шага доказательства в любой момент (например, запросить вызов до получения обязательства). В большинстве случаев Проверяющий выдаст ошибку. Однако у всех команд по умолчанию был активирован режим симуляции (simulation mode), и это было третьей ошибкой. Соответствующий бит конфигурации настраивался во время инициализации Проверяющего внутри скомпилированной библиотеки. Для его поиска и замены командам необходимо было произвести обратную разработку скомпилированного бинарного файла. В режиме симуляции, после сохранения обязательства и получения вызова от Проверяющего, Доказывающий мог снова направить обязательство, уже основанное на известном вызове. Это полностью нарушало протокол, но исправить это было очень легко. К сожалению, насколько нам известно, эту ошибку никто не обнаружил
Теперь вернемся к алгоритмам обязательств. Они работают следующим образом.
В случае с обязательствами CRC32 и SHA-256 перестановка, графы с перестановленными вершинами и перестановленные циклические матрицы упаковываются. Упаковывание состоит в том, что размер квадратной матрицы размещается в пределах одного двухбайтного слова (uint16_t), а битовый поток плотно упаковывается в байты таким образом, чтобы каждый байт содержал 8 бит из ячеек исходного представления матрицы. После того, как матрицы упакованы, к каждому упакованному массиву применяется выбранная хеш-функция. В итоге на одно доказательство приходится три хеша:
Данные хеши далее направляются Проверяющему в качестве обязательства. Как только Проверяющий отправляет бит вызова , в ответ ему направляются исходные упакованные матрицы либо для перестановки и графа с перестановленными вершинами, либо для графа с перестановленными вершинами и перестановочным циклом. Проверяющий может проверить, что хеши соответствуют полученным значениям, а значения удовлетворяют условиям обязательства. Если этап успешно завершается, Проверяющий удостоверяется, что матрица отвечает требованиям к доказательству.
Если это обязательство AES, Доказывающий создает два ключа: и . Он упаковывает матрицы тем же способом, как и в случае с другими обязательствами, но затем он шифрует упакованную перестановку при помощи и упакованный перестановочный цикл при помощи . Он отправляет оба шифротекста и упакованный граф с перестановленными вершинами в виде открытого текста:
После получения бита вызова от Проверяющего Доказывающий направляет ему . Проверяющий дешифрует соответствующий зашифрованный текст и проверяет достоверность доказательства.
Как видите, обязательство, основанное на AES, успешно скрывает доказательство и не дает Доказывающему себя нарушить (невозможно получить перестановку и перестановленный цикл без ключей, и Доказывающий не может найти другой ключ, который бы позволил ему обмануть Проверяющего). Обязательство, основанное на SHA-256, также носит обязательный характер с точки зрения расчетов (нужно обнаружить коллизию), а так как мы по факту направляем не сами матрицы в каком-либо виде или форме, они действительно удовлетворяют свойству скрытия.
CRC32, однако, не в полной мере удовлетворяет условиям скрытия, и это четвертая ошибка. Для поиска противоречия можно подобрать CRC32 с ориентировочным уровнем сложности . Но его можно обнаружить еще быстрее при помощи подхода Meet-in-the-Middle («Встреча посередине»), ориентировочный уровень сложности которого составляет .
Обновление: Как мне подсказали, можно еще быстрее. Пример здесь. Но узнать про MitM всё равно полезно, т.к. этот метод можно применить и в других местах.
Атака Meet-in-the-Middle может быть использована, потому что можно обратить раунды CRC32. Допустим, у нас есть
и надо найти некое таким образом, чтобы
Давайте зафиксируем длину искомого , пусть она будет 6 байтов (позже это нам пригодится). CRC32 состоит из трех фаз:
- Инициализация .
- Цикл прохода по байтам сообщения , где ( — внутреннее состояние, а — байт).
- Постпроцессинг .
Итак, для 6 байтов:
или произведение функций от :
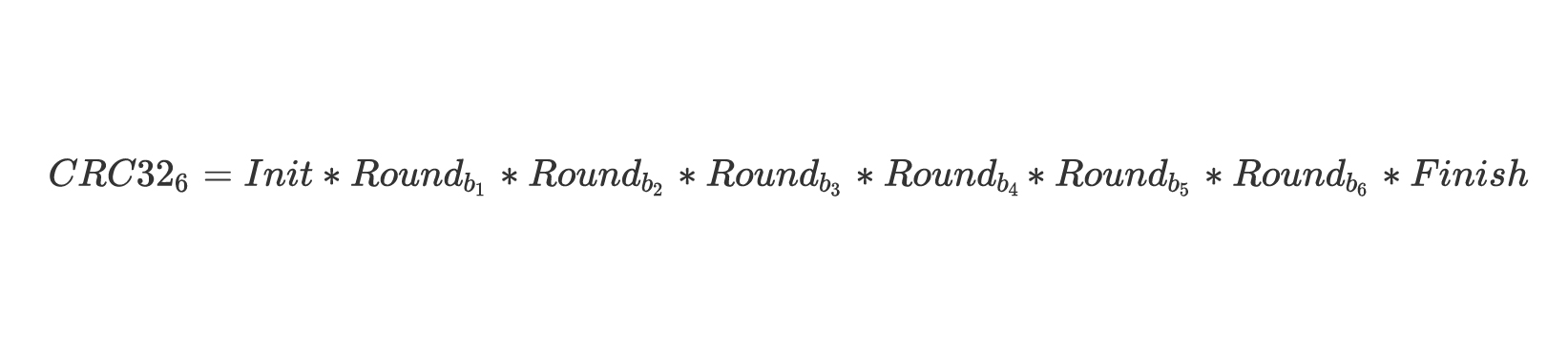
Теперь можно разбить на две части:
где
Мы разделили CRC32 пополам. Более того, функции и являются обратимыми, что делает тоже обратимой:
Теперь вместо подбора мы:
- Рассчитываем около значений с различными и помещаем эти значения в хеш-таблицу, чтобы можно было посмотреть результаты для каждого значения за константное время.
- Рассчитываем значения для различных . После расчета каждого значения проверяем, отражено ли оно в хеш-таблице. Как только мы найдем одно из них, прекращаем процесс. Шанс найти одно значение при каждой попытке находится в диапазоне .
- Получаем значение: , и это означает, что , и мы обнаружили коллизию.
Я уже слышу: «Все это, конечно, замечательно, но наши данные не должны быть случайными — это должна быть одна из тех матриц, и она должна пройти всяческие проверки, так что все это напрасно». Все было бы именно так — если бы мы не написали распаковывание матриц таким образом, чтобы оно позволяло добавлять мусорные байты. Вспомните, как мы упаковываем матрицы:
Очень важно, что при проверке HASHES Проверяющий хеширует весь этот объект — но, когда матрицы распаковываются, алгоритм принимает только биты из , и все лишнее отбрасывается. Итак, мы можем добавить еще 6 байтов:
И произвести такую же атаку, но теперь будет обрабатывать
тогда как будет обрабатывать
После обнаружения противоречий злонамеренный Доказывающий может передать результаты проверки Проверяющего и получить флаг.
Последняя уязвимость
Мы рассказали о работе всей системы и рассмотрели 4 запланированных уязвимости. Однако была еще и пятая ошибка. Биты вызова, предоставляемые Доказывающим, были из небезопасного источника — ГПСЧ (PRNG или генератор псевдослучайных чисел).
Обычно в таких случаях выбор падает на небезопасный примитив языка C rand, но нам хотелось чего-то более интересного. В последние годы было опубликовано несколько исследований о Legendre PRF, поэтому мы решили реализовать его в качестве ГПСЧ вместо избитого Вихря Мерсенна.
Идея, положенная в основу этого ГПСЧ, это поле Галуа , то есть фактор-модулей простого числа . Каждый элемент этого поля либо является квадратичным вычетом, либо нет. Таким образом, в поле квадратичных вычетов (если исключить 0) и столько же неквадратичных вычетов.
Если вы случайным образом выбираете какой-либо элемент этого поля, за исключением элемента , вероятность того, что он представляет собой квадратичный вычет, будет равна . Довольно легко проверить, является ли данный элемент (исключая нулевой — ) квадратичным вычетом или нет. Для этого необходимо вычислить его символ Лежандра. Если для элемента выполняется равенство , тогда он является квадратичным вычетом. Так как вероятность для каждого элемента представлять собой квадратичный вычет составляет 50%, а квадратичные вычеты соседствуют с неквадратичными в случайном порядке, то можно создать искомый ГПСЧ.
Мы инициализируем ГПСЧ с произвольным элементом . Алгоритм в Python будет выглядеть следующим образом:
def LegendrePRNG(a,p):
if a==0:
a+=1
while True:
next_bit=pow(a,(p-1)//2,p)
if next_bit==1:
yield 1
else:
yield 0
a=(a+1)%p
if a==0:
a+=1Мы специально выбрали 32-битный , чтобы команды смогли его использовать в атаке Meet-in-the-Middle. Идея заключается в том, чтобы получить бит из ГПСЧ, направляя постоянные запросы на вызовы. Как только вы их получите, можно конвертировать этот битовый поток в 32-битовых целых чисел, преобразуя каждую последовательность из 32 бит внутри потока в целое число. Неважно, какой порядок использовать — big-endian или little-endian, — главное использовать один и тот же везде.
Поместите эти целые числа в словарь в виде ключей, а значения будут означать их позиции в битовом потоке. Теперь инициализируйте свой собственный экземпляр Legendre PRNG. Выберите и сгенерируйте 32 псевдослучайных бита при помощи ГПСЧ. Преобразуйте эти биты в целое число и проверьте, есть ли оно в словаре (предполагается, что алгоритмическая сложность поиска будет приближаться к константе).
Если его там нет, измените инициализацию на и повторите. Увеличивайте шагом до тех пор, пока не найдете совпадение. Когда вы его обнаружите, то узнаете, каким было значение внутреннего состояния ГПСЧ Проверяющего несколько шагов назад. Обновите так, чтобы оно соответствовало текущему внутреннему состоянию ГПСЧ — и вы успешно клонировали ГПСЧ Проверяющего. Если вы заранее знаете, какие будут вызовы, то обмануть Проверяющего не составит труда.
Возможно, вы подумали, что при нескольких одновременных атаках могут возникнуть проблемы. Мы предвидели это и спроектировали сервис так, что отдельные подключения порождают независимые состояния ГПСЧ. Таким образом, команды не могли влиять на подключения друг друга.
Итак, в сервисе присутствуют следующие уязвимости:
- Атака через подделку подписи Bleichenbacher’s e=3.
- Небезопасные параметры Проверяющего.
- Включенный режим симуляции.
- Обязательство CRC32.
- Небезопасный ГПСЧ.
Как мы разрабатывали таск
Писать задание было довольно весело, так как некоторые задачи пришлось решать нестандартно.
Например, на ранних этапах мы решили, что не будем добавлять никаких зависимостей, за исключением стандартных библиотек. Из-за этого нам пришлось использовать Linux Usermode Kernel CryptoAPI для хеширования и шифрования.
Поскольку мы писали библиотеку матриц с нуля, то вскоре столкнулись с проблемами с быстродействием: умножение матриц занимало слишком много времени. Мы не использовали SIMD, и это накладывало ограничения на скорость работы. К счастью, мы быстро заметили, что на самом деле умножение матриц в общем виде нам не нужно: у нас был особый случай. Нам требовалось умножение только для вырожденного случая расчета матриц графов и циклов с переставленными вершинами.
Допустим, имеется граф или циклическая матрица и матрица перестановки . Чтобы найти перестановленную матрицу , нужно произвести следующий расчет: . Матрицы перестановки — это особый случай. В каждом ряду и каждом столбце матрицы перестановки встречается только одна ячейка со значением , во всех остальных ячейках значение равно . То же самое относится к транспонированной матрице перестановки. Давайте умножим такую матрицу на , .
Как известно, ряды матрицы умножаются на столбцы. Следовательно, зная, что в каждом ряду и в каждом столбце значение встречается только один раз, мы можем:
- Взять первую строку .
- Искать положение , скажем, это будет .
- Взять -й ряд и скопировать в первый ряд .
- Повторить эти действия с другими рядами.
Давайте попробуем на примере:
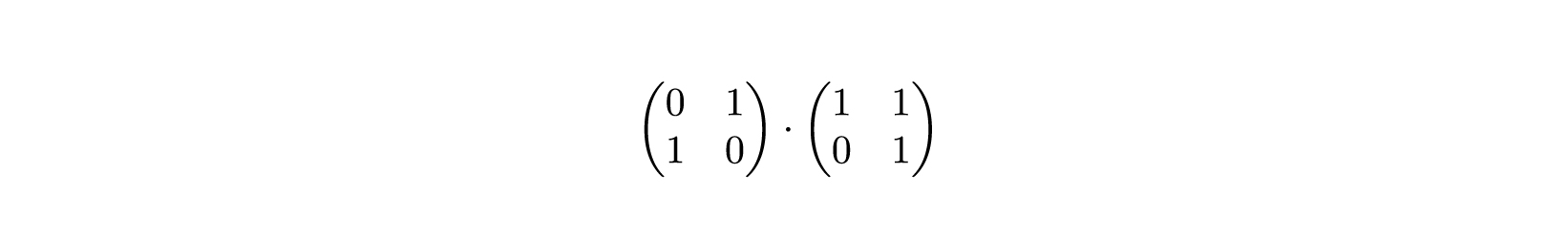
Сначала мы ищем в первой строке матрицы (той, что слева) первую и единственную единицу.
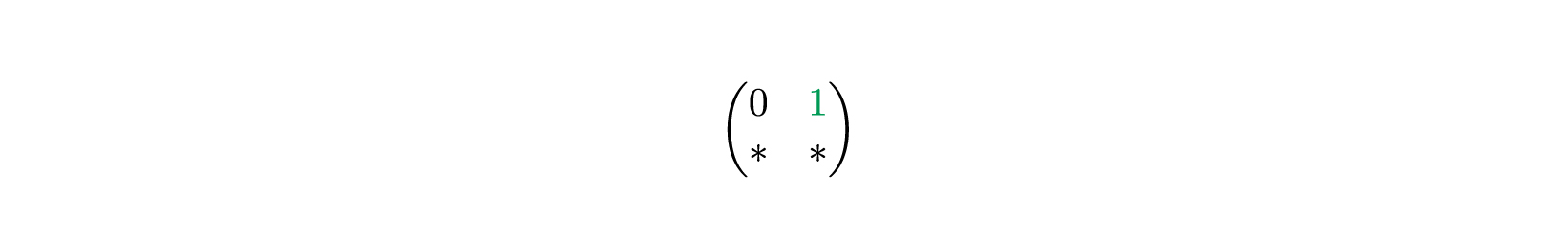
Единица находится на второй позиции, считая с единицы. Поэтому берем вторую строку и копируем в первую строку итоговой матрицы .
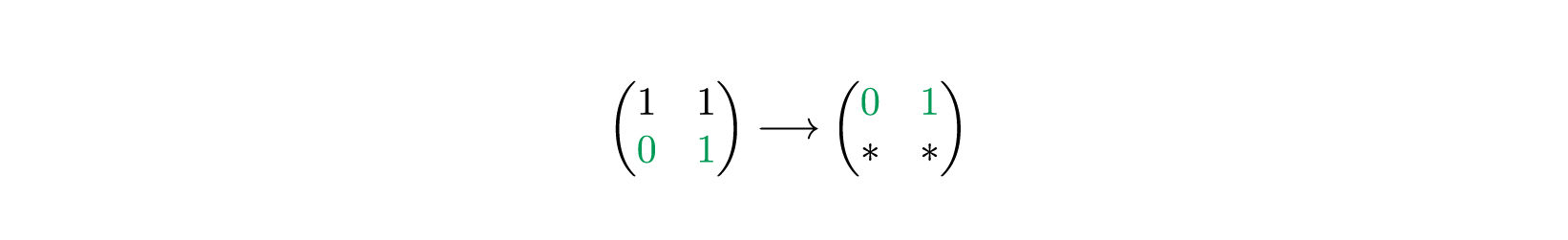
Повторяем то же самое со второй строкой . Ищем единицу.
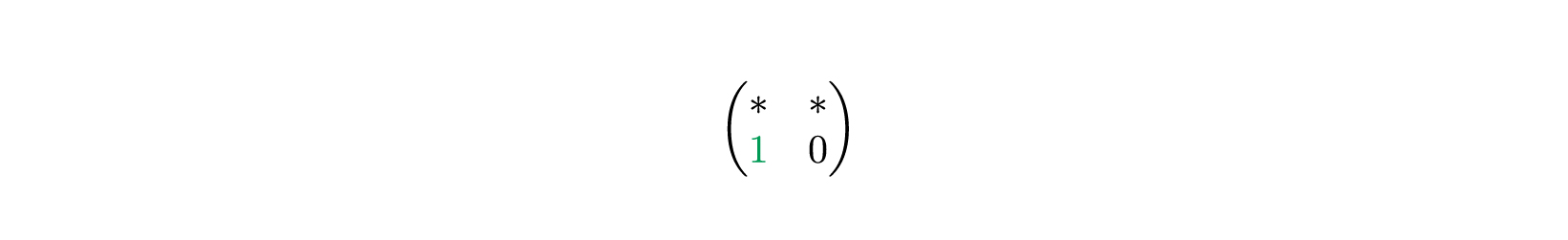
Она на первой позиции, поэтому берем первую строку и кладем на место второй строки в итоговой матрице.
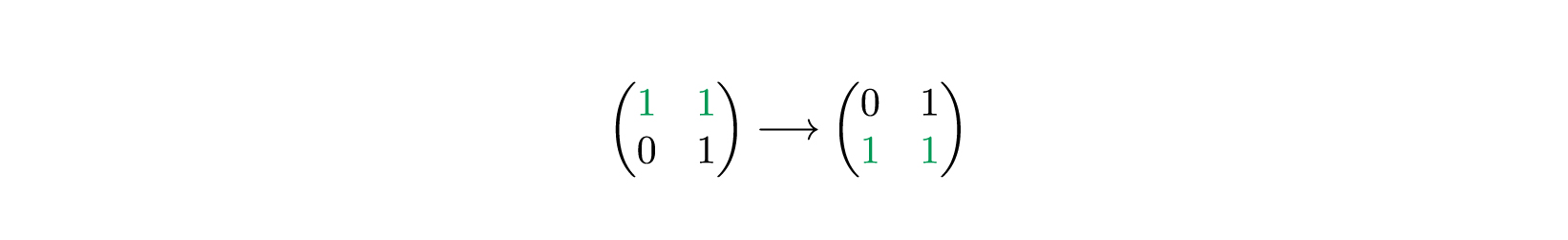
Так можно легко получить итоговую матрицу.
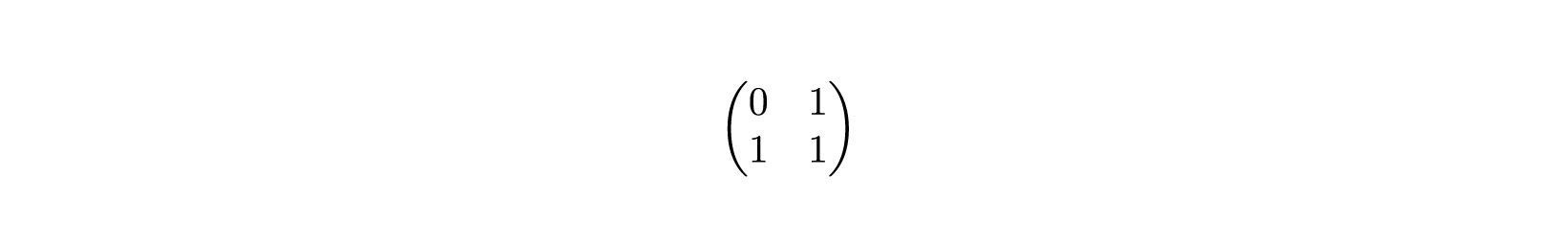
Поскольку мы знаем, что в каждом ряду значение встречается только один раз, нам также известно, что только -е значение каждого столбца будет влиять на полученную в результате ячейку. Кроме того, используя memcpy для копирования, мы ускоряем умножение с помощью SIMD, так как memcpy задействует его для более быстрого копирования. Этот метод позволил значительно ускорить вычисления.
Финальная версия сервиса была встроена в докер-контейнер в два этапа. Сначала библиотека Zero Knowledge собиралась отдельно, затем скомпилированная библиотека копировалась в финальную версию контейнера вместе с оберткой на Python, серверным скриптом и открытым ключом сервера проверки в формате PEM. Все символы, за исключением импорта и экспорта, были удалены из библиотеки, чтобы командам пришлось реверсить основную функциональность.
Как мы тестировали таск
Как вы догадываетесь, задание нужно было тщательно протестировать.
Сначала мы запустили непрерывное нагрузочное тестирование серверов команды и проверки на 24 часа, убрав интервалы между запросами, при этом сервер проверки направлял сервису несколько сотен запросов в секунду. Так мы выявили сложную для обнаружения ошибку в использовании CryptoAPI: я забыл закрыть один из сокетов AF_ALG, в результате чего у сервиса быстро закончились доступные дескрипторы файлов.
Мы также протестировали каждую задуманную уязвимость и обнаружили пару проблем в реализации, из-за которых эти уязвимости было невозможно эксплуатировать. В результате нам пришлось вносить изменения в некоторые части приложения за несколько часов до начала соревнования.
Кроме того, мы попросили коллег посмотреть задание, чтобы убедиться в отсутствии непредвиденных ошибок в логике.
Но больше всего мы опасались, что останутся случайные ошибки в скомпилированных бинарных файлах, которые можно было бы использовать в атаках на удаленное исполнение. Нам не хотелось, чтобы без нашего ведома появилось еще одно задание на pwn :)
Вот что мы сделали, чтобы снизить этот риск:
- Во-первых, мы полностью воссоздали взаимодействие между Доказывающим и Проверяющим на языке C со всеми обязательствами, с наименьшим и наибольшим возможным количеством вершин и доказательств. Тест создавался с использованием ASAN (Address Sanitizer), с помощью которого мы нашли несколько утечек.
- Во-вторых, мы выписали все интерфейсы, которые будут принимать входные данные из недоверенных источников, будь то на стороне Проверяющего или Доказывающего. Для каждого из этих интерфейсов мы сохранили входные значения, получаемые при взаимодействии сервера проверки с сервером команды. Затем мы написали обвязки под Libfuzzer для каждой точки входа, включая всю необходимую инициализацию и очистку.
Однако невозможно было так просто подготовить нашу библиотеку к фаззингу: при данном виде тестирования все должно быть по максимуму детерминировано. Поэтому мы заменили получение значений из /dev/urandom вызовами к randrand, а также заменили инициализацию ГПСЧ (не Legendre PRF, а основного) на srand(0). Также было очевидно, что в ходе фаззинга нельзя получить правильный хеш или шифротекст с корректными матрицами. Поэтому мы выключили все хеш-проверки и заменили AES-шифрование простым копированием данных для фаззинга.
В общей сложности фаззинг длился несколько дней, и за это время мы обнаружили множество ошибок. Но после этого мы чувствовали себя немного уверенней, когда отдавали нашу библиотеку на анализ соревнующимся командам.
Итак, мы сделали все от нас зависящее, чтобы протестировать устойчивость сервиса к непредвиденным атакам. Единственное, что оставалось, — предусмотреть меры против читерства: участникам должно быть невыгодно прибегать к заурядным средствам защиты, которые позволили бы устранить ряд уязвимостей легче, чем это было задумано.
Как мы боролись с читерством
Для эксплуатации Legendre PRNG нужно отправлять множество запросов Доказывающему. Нам не хотелось, чтобы командные серверы обрывали соединения в случае нескольких последовательных запросов на получение вызова. Чтобы команды отказались от реализации таких простых и скучных способов митигации, мы разнообразили функциональность сервера проверки.
В начале каждого раунда сервер проверки размещал флаг и матрицу для соответствующего раунда на сервере команды и сразу же запускал экземпляр протокола Proof of Knowledge, чтобы получить флаг обратно. После этого сервер проверки вызывался каждые тридцать секунд для подтверждения, что флаг не поврежден, а поведение сервера не отклоняется от нормы. Для этого мы предусмотрели, чтобы сервер проверки выбирал одну из трех стратегий при каждом вызове:
- Простое доказательство. Сервер проверки просто доказывает, что знает цикл. Если что-то идет неправильно, то у команды отнимаются очки SLA (соглашения об уровне сервиса).
- Сервер проверки создает валидные обязательства, но перед отправкой на сервер команды повреждает их случайным образом, чтобы Доказывающий счел полученное обязательство ошибочным. Он повторяет цикл неверных доказательств в течение нескольких секунд. Затем он реализует правильное взаимодействие и получает флаг. Если в какой-то момент от сервера команды придет неожиданный ответ или сервер оборвет соединение, то команда теряет очки SLA.
- Сервер проверки инициализирует протокол и направляет валидное обязательство. Далее он дает команду Проверяющему на отправку вызова в цикле на протяжении пары секунд. По истечении этого времени он выбирает последний вызов, создает пакет, который раскрывает обязательство, и направляет его на сервер команды. Если сервер отдает флаг, значит, все сделано правильно. За любые отклонения от ожиданий сервера проверки отнимаются очки SLA.
У одной из команд (Bushwhackers) показатель SLA составил только 65%, потому что они провалили вторую стратегию. Кстати, все причины неудач выводились на scoreboard, чтобы команды могли сделать вывод об ошибочности определенных стратегий защиты.
Заключение
Когда я начал писать статью, я не думал, что она настоооооолько затянется. Но мне не хотелось упустить ни одной важной детали.
Составлять задание было увлекательно, и мне приятно осознавать, что оно нас ни разу не подвело за все время соревнований. Как и ожидалось, командам не удалось найти все уязвимости, но они проявили себя весьма достойно. Надеюсь, что решать наше задание участникам понравилось.
Если у вас будет желание, можно собрать и запустить наш таск самостоятельно по ссылке https://github.com/bi-zone/CTFZone-2020-Finals-LittleKnowledge. Мы выложили его в открытый доступ, чтобы любой мог попробовать его решить. Там есть подробные комментарии по всем функциям внутри библиотеки, так что вы можете пойти путем команд (без информации о внутренностях библиотеки) либо посмотреть исходный код. Также доступна примитивная реализация сервера проверки. Учитывая все усилия, надеемся, что этот труд не пропадет. Возможно, кто-нибудь возьмет наш материал на вооружение при подготовке к CTF.
Спасибо, что прочитали до конца, и удачи!
knstqq
Годный таск! Есть статистика как много команд починило сколько уязвимостей в нём и сколько команд успешно эксплуатировало их/какие?
Rumata888
Всего было 10 команд и ответили только пара из них. Точно эксплуатировали RSA для доса и плохие параметры. Причем одна команда ломала другие команды, которые выставили количество вершин в 50, потому что граф был достаточно связный.