
В современных дата-центрах установлены сотни активных устройств, покрытых разными видами мониторингов. Но даже идеальный инженер с идеальным мониторингом в руках сможет правильно отреагировать на сетевой сбой лишь за несколько минут. В докладе на конференции Next Hop 2020 я представил методологию дизайна сети ДЦ, у которой есть уникальная особенность — дата-центр лечит себя сам за миллисекунды. Точнее, инженер спокойно чинит проблему, в то время как сервисы ее просто не замечают.
— Для начала я дам достаточно подробную вводную для тех, кто, может быть, не в курсе устройства современного ДЦ.
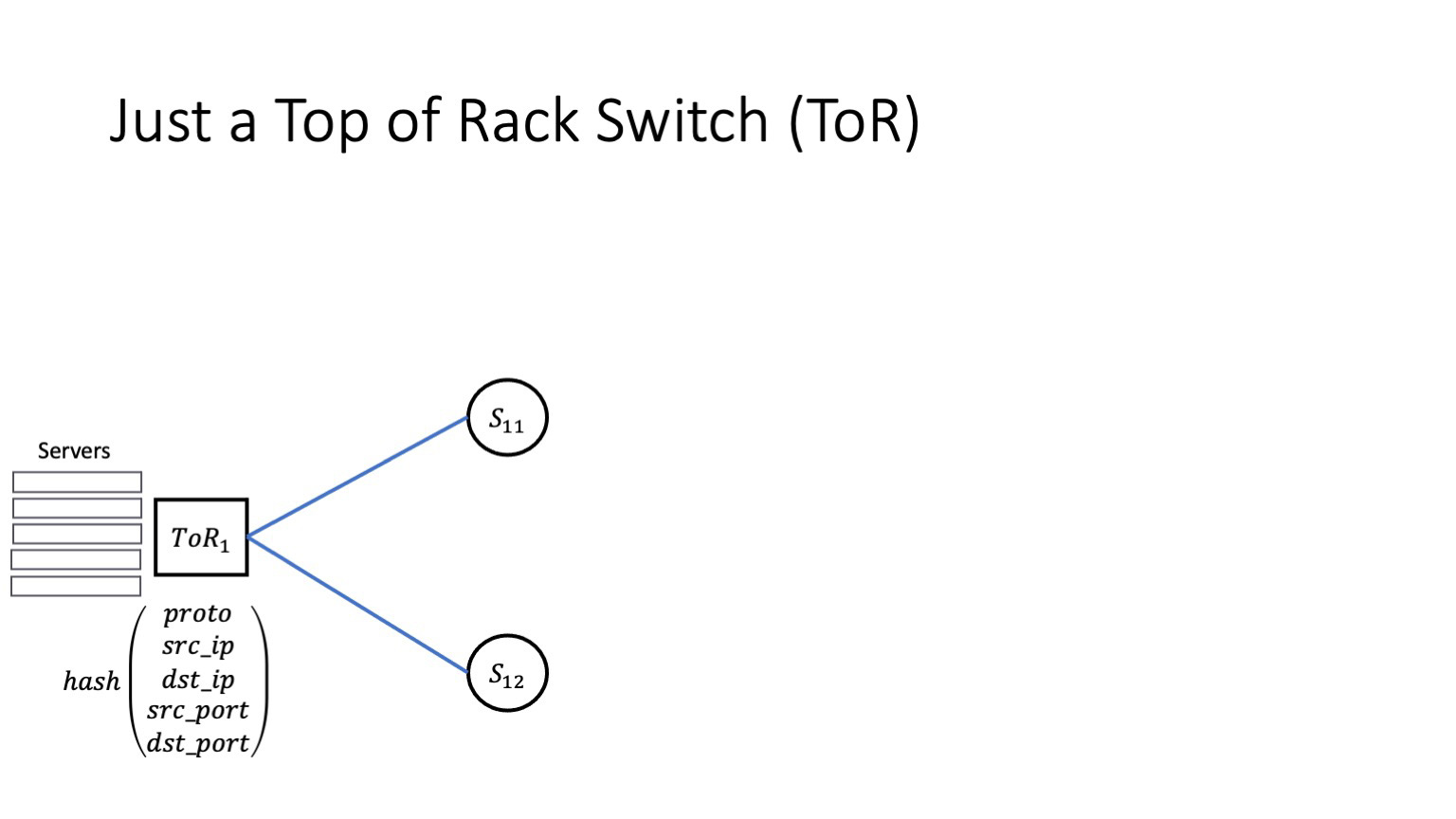
Для многих сетевых инженеров сеть дата-центра начинается, конечно, с ToR, со свитча в стойке. ToR обычно имеет два типа линков. Маленькие идут к серверам, другие — их в N раз больше — идут в сторону спайнов первого уровня, то есть к его аплинкам. Аплинки обычно считаются равнозначными, и трафик между аплинками балансируется на основе хеша от 5-tuple, в который входят proto, src_ip, dst_ip, src_port, dst_port. Здесь никаких сюрпризов.
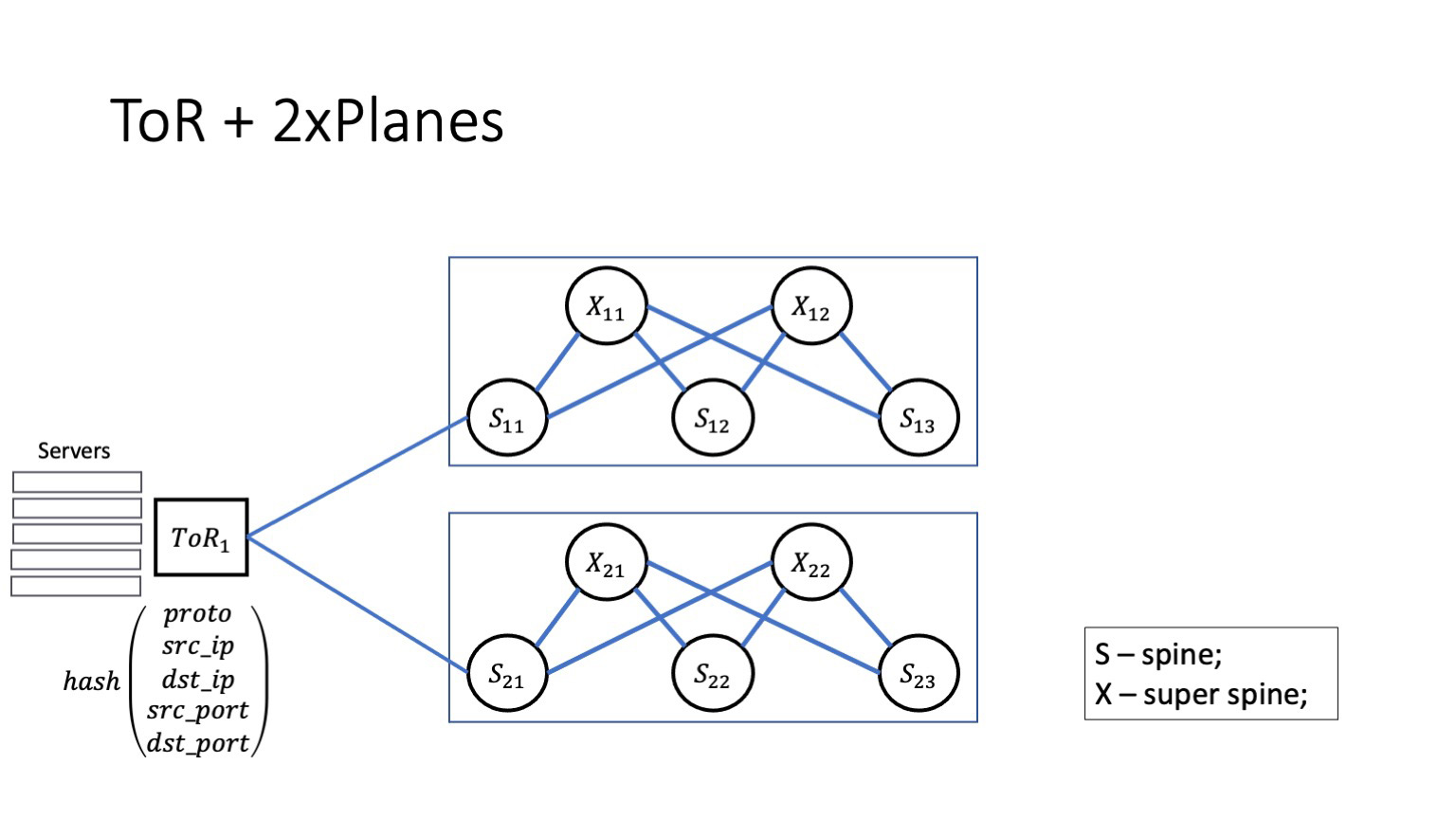
Дальше, как выглядит архитектура плейнов? Спайны первого уровня между собой не соединены, а соединяются посредством суперспайнов. За суперспайны у нас будет отвечать буква X, она практически как кроссконнект.
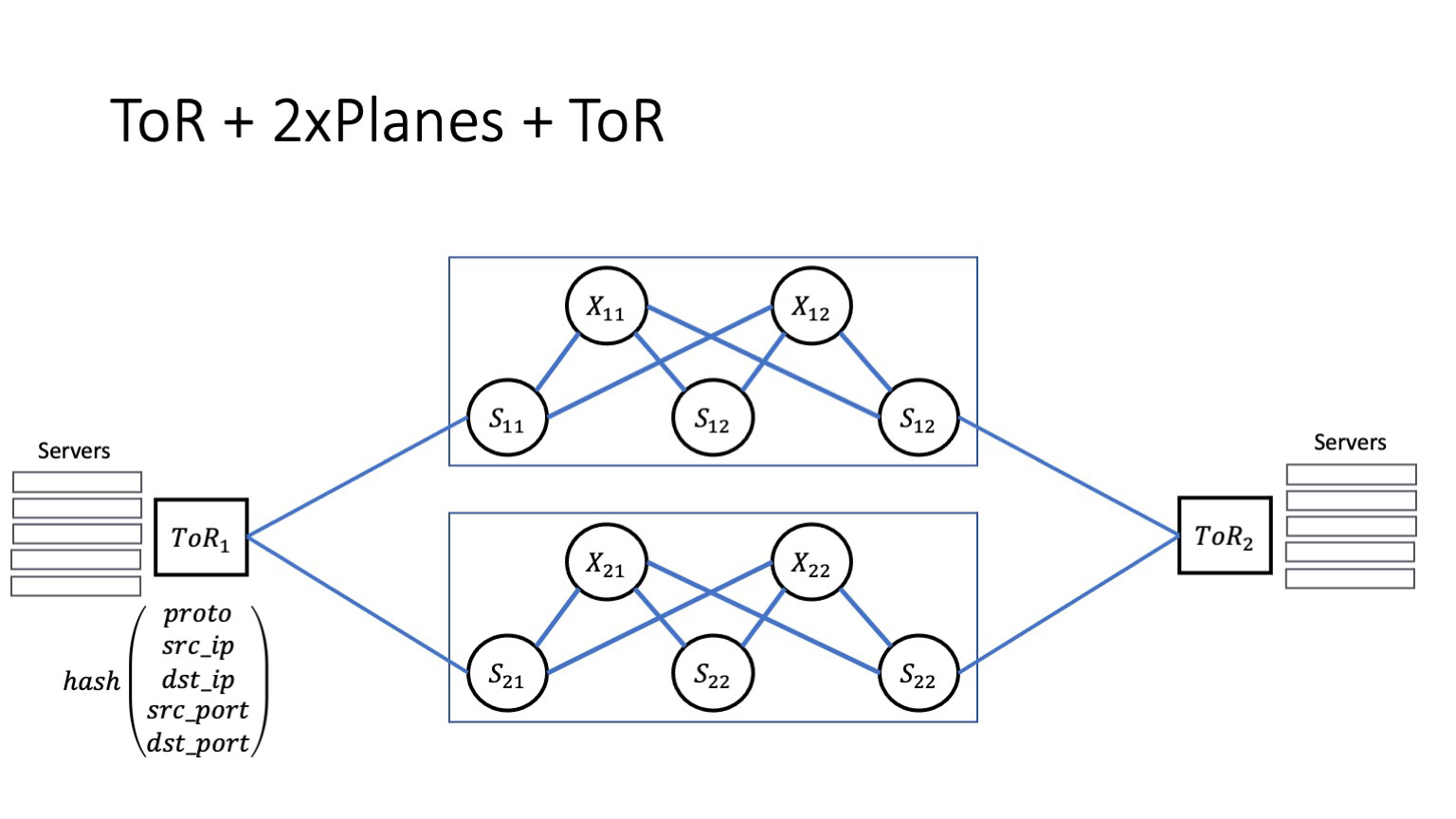
И понятное дело, что с другой стороны ко всем спайнам первого уровня подключены торы. Что важно на этой картинке? Если у нас идет взаимодействие внутри стойки, то взаимодействие, понятное дело, идет через ToR. Если взаимодействие идет внутри модуля, то взаимодействие идет через спайны первого уровня. Если взаимодействие межмодульное — как здесь, ToR 1 и ToR 2, — то взаимодействие пойдет через спайны как первого, так и второго уровня.
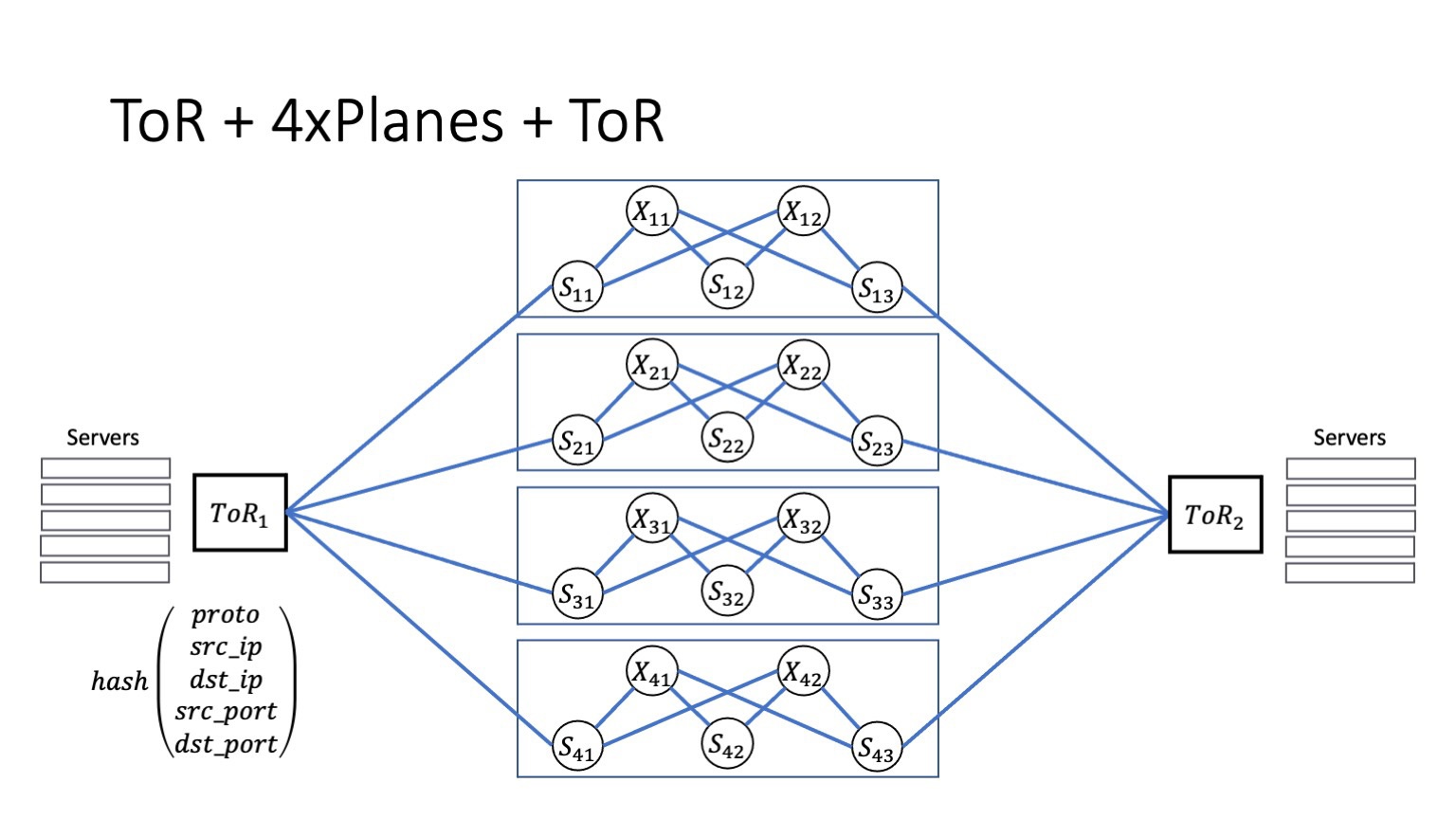
Теоретически такая архитектура легко масштабируется. Если у нас есть портовая емкость, запас места в дата-центре и заранее проложенное волокно, то всегда количество плейнов можно нарастить, тем самым повышая общую емкость системы. На бумаге сделать такое очень легко. Было бы так в жизни. Но сегодняшний рассказ не об этом.

Я хочу, чтобы были сделаны правильные выводы. У нас внутри дата-центра много путей. Они условно независимы. Один путь внутри дата-центра возможен только внутри ToR. Внутри модуля у нас количество путей равно количеству плейнов. Количество путей между модулями равно произведению числа плейнов на число суперспайнов в каждом плейне. Чтобы было понятнее, чтобы почувствовать масштаб, я дам цифры, которые справедливы для одного из дата-центров Яндекса.

Плейнов восемь, в каждом плейне 32 суперспайна. В итоге получается, что внутри модуля восемь путей, а при межмодульном взаимодействии их уже 256.

То есть если мы разрабатываем Cookbook, пытаемся научиться тому, как строить отказоустойчивые дата-центры, которые лечат себя самостоятельно, то плейновая архитектура — правильный выбор. Она позволяет решить задачу масштабирования, и теоретически это легко. Есть множество независимых путей. Остается вопрос: как такая архитектура переживает сбои? Бывают разные сбои. И мы сейчас это обсудим.
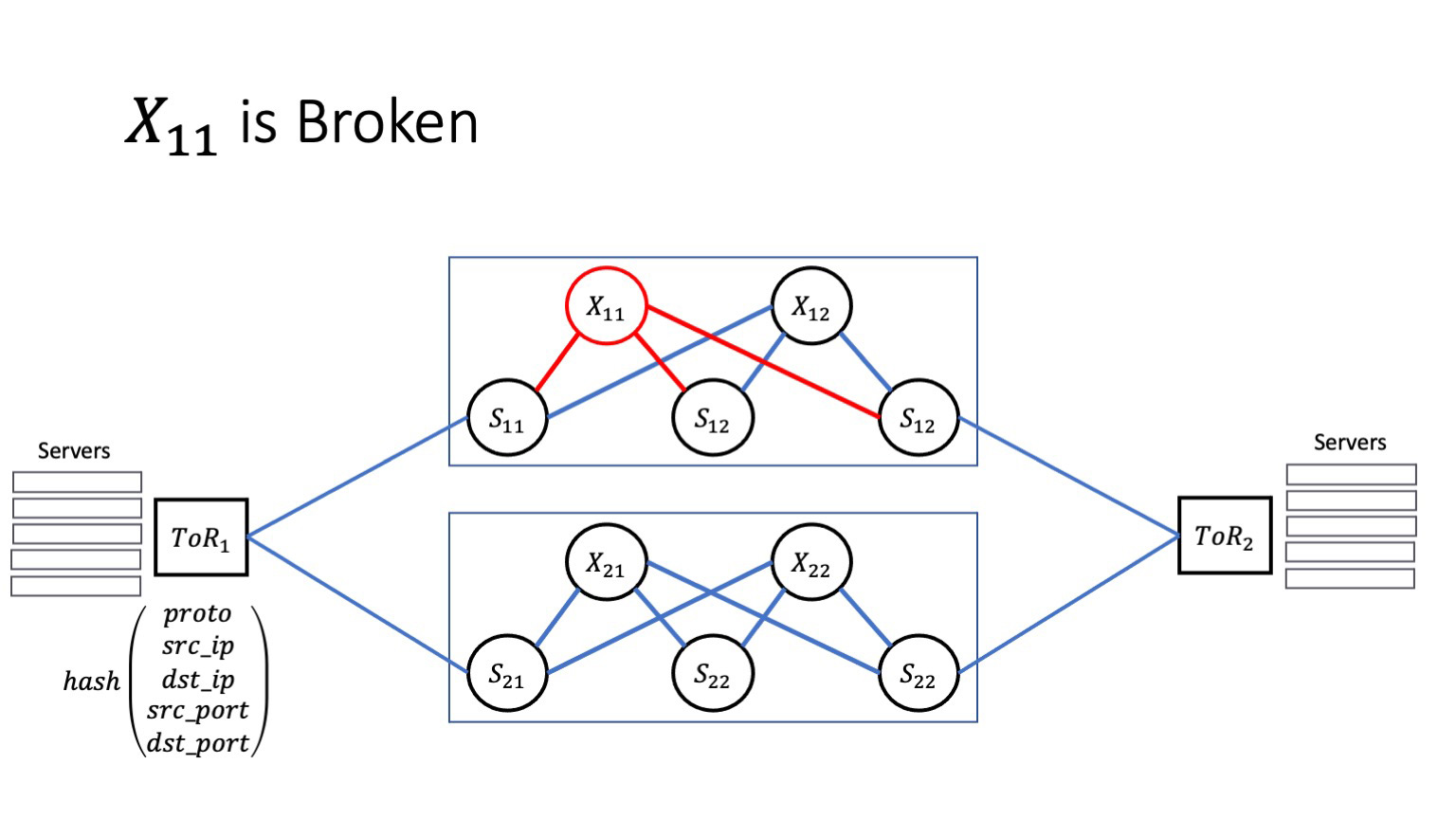
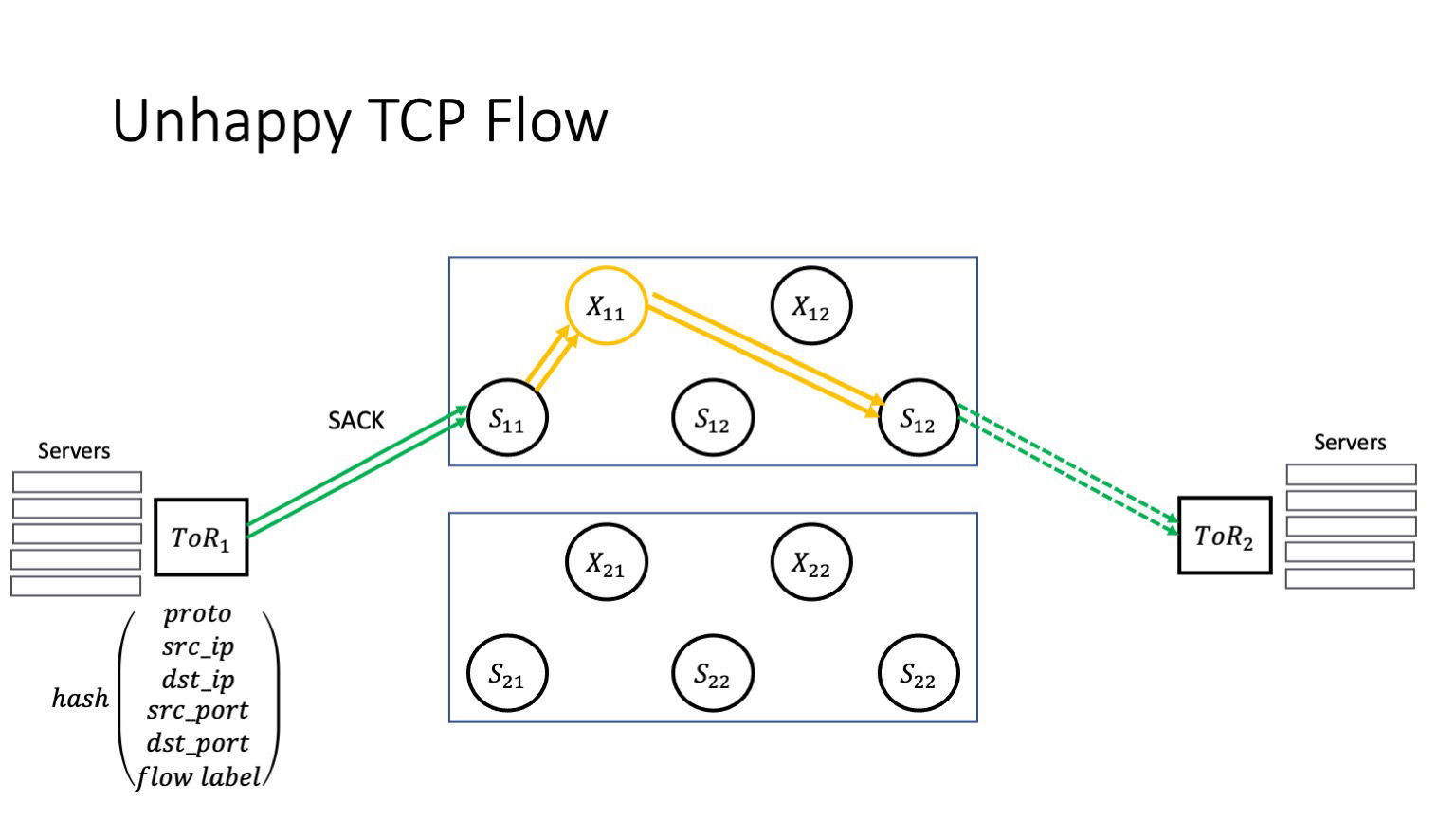
Пусть у нас один из суперспайнов «заболел». Я здесь вернулся к архитектуре двух плейнов. В качестве примера мы остановимся на них, потому что здесь попросту будет легче видеть, что происходит, с меньшим числом движущихся частей. Пусть X11 заболел. Как это повлияет на сервисы, которые живут внутри дата-центров? Очень многое зависит от того, как сбой выглядит на самом деле.
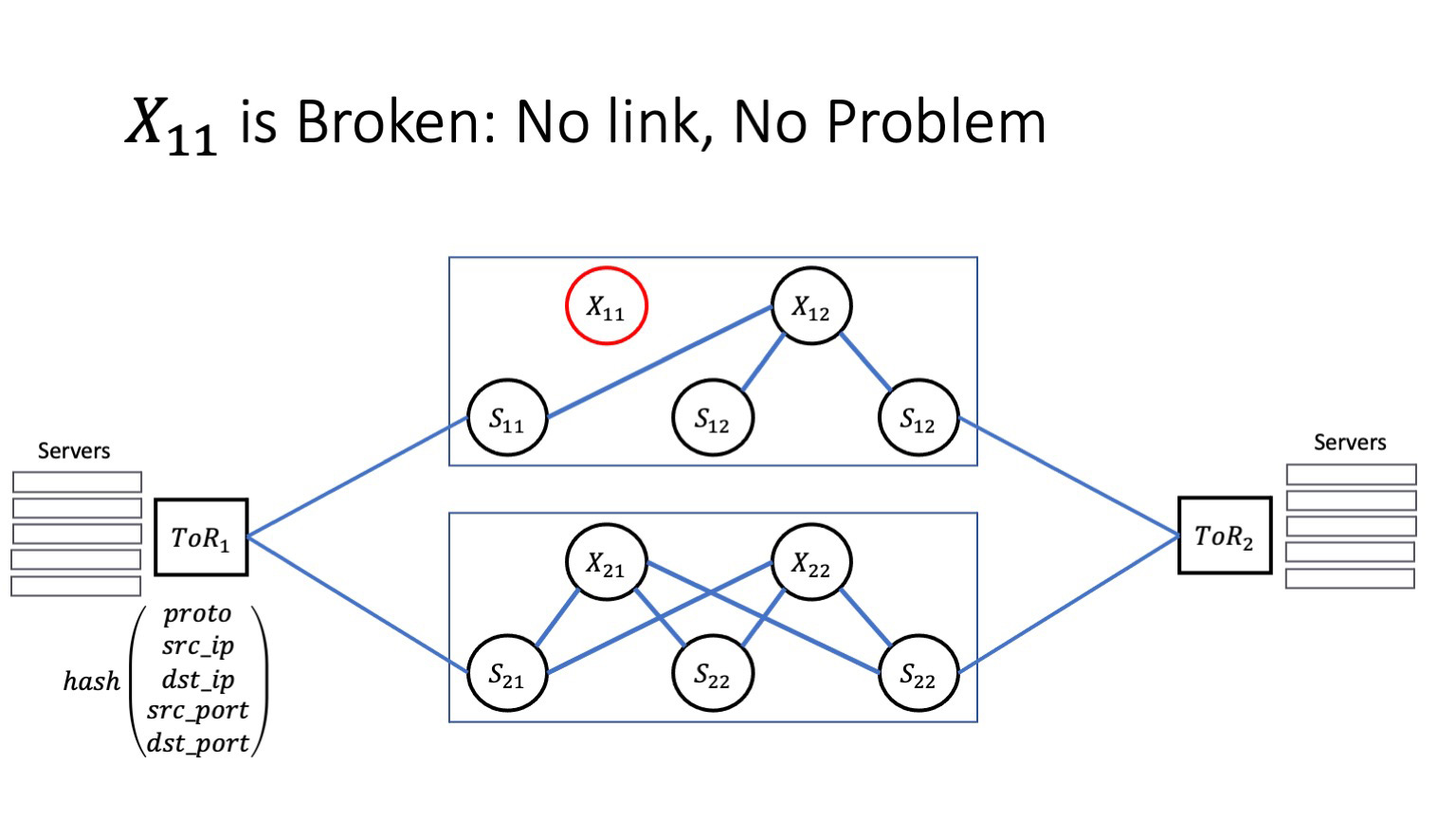
Если сбой хороший, ловится на уровне автоматики того же BFD, автоматика радостно кладет проблемные стыки и изолирует проблему, то все хорошо. У нас множество путей, трафик моментально перемаршрутизируется на альтернативные маршруты, и сервисы ничего не заметят. Это хороший сценарий.
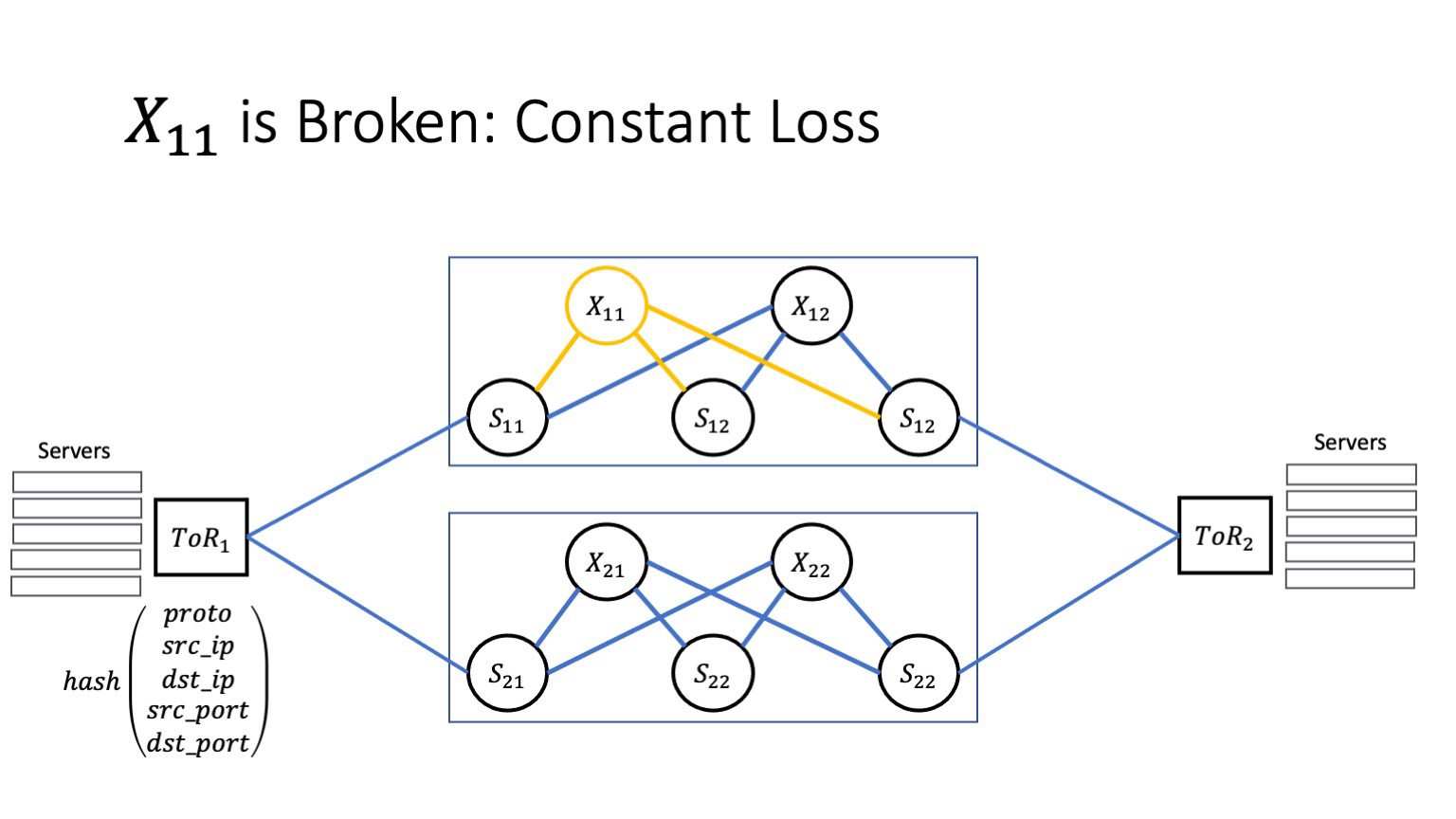
Плохой сценарий — если у нас возникают постоянные потери, и автоматика проблемы не замечает. Чтобы понять, как это влияет на приложение, нам придется потратить немного времени на обсуждение того, как работает протокол TCP.
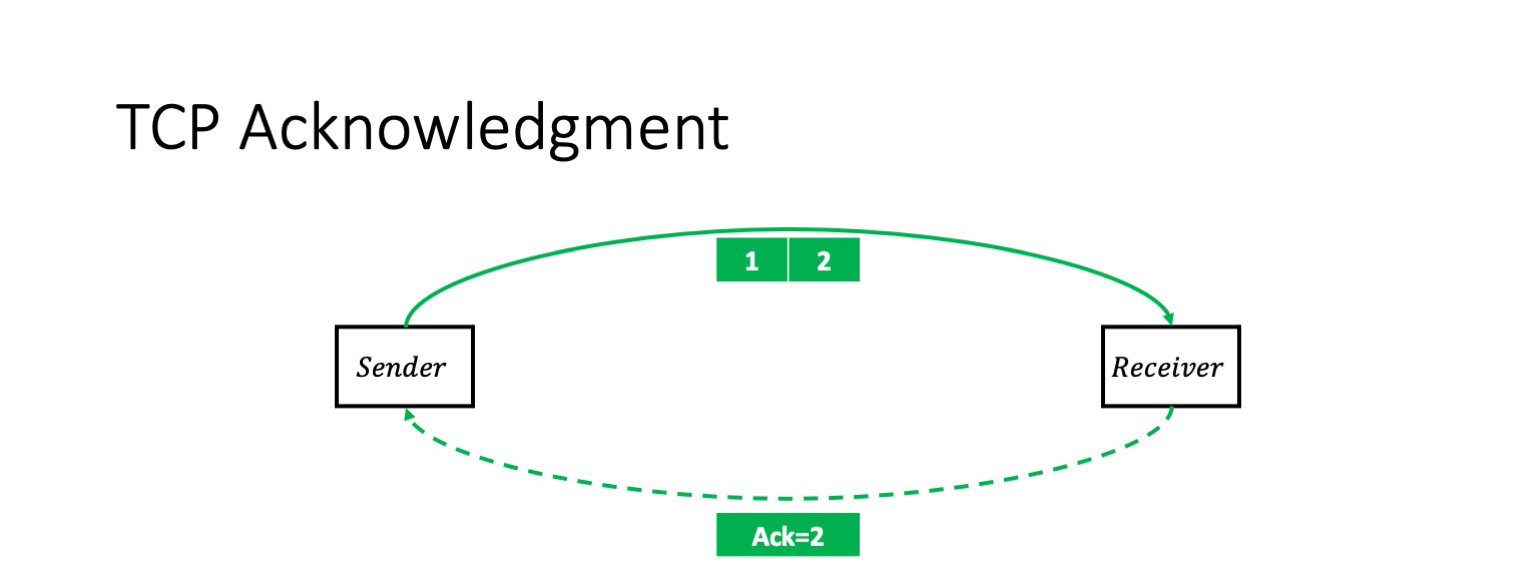
Я надеюсь, что никого не шокирую этой информацией: TCP — протокол с подтверждением передачи. То есть в простейшем случае у нас отправитель отправляет два пакета, и получает на них кумулятивный ack: «Я получил два пакета».
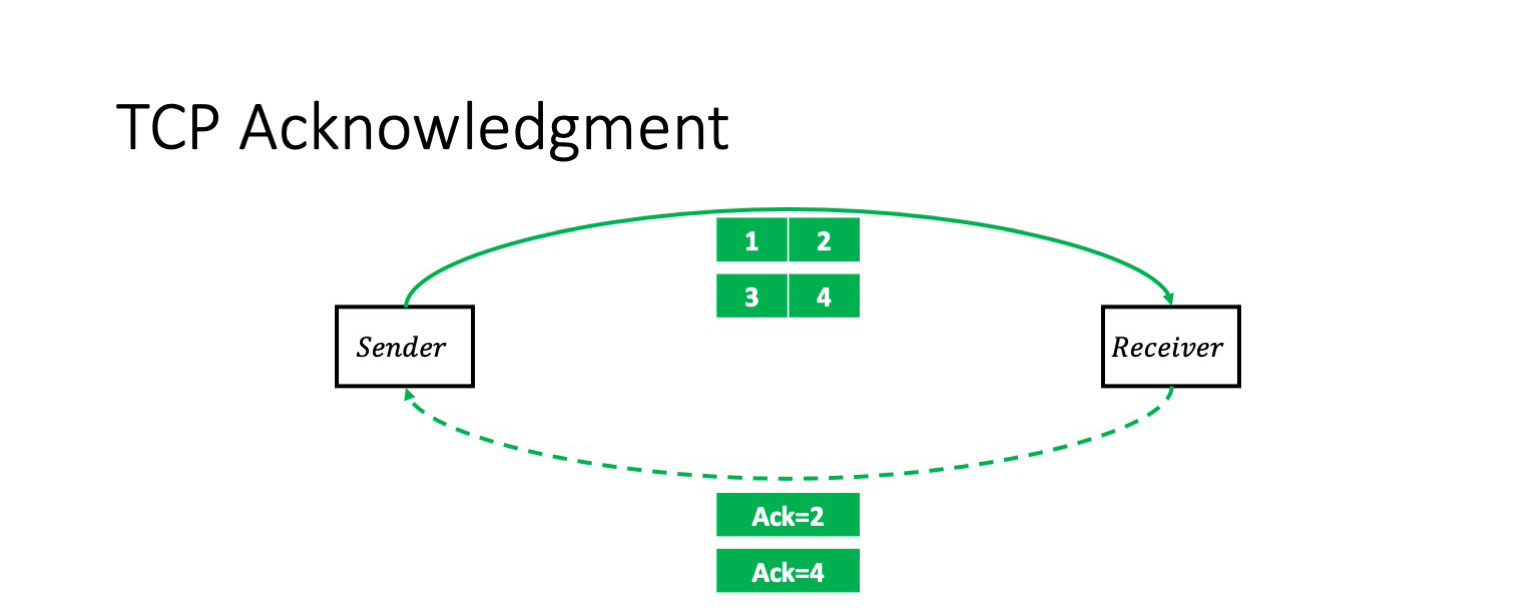
После этого он отправит еще два пакета, и ситуация повторится. Я заранее прошу прощения за некоторое упрощение. Такой сценарий верный, если окно (число пакетов в полете) равно двум. Конечно, в общем случае это необязательно так. Но на контекст перепосылки пакетов размер окна не влияет.
Что будет, если мы потеряем пакет 3? В этом случае получатель получит пакеты 1, 2 и 4. И он в явном виде с помощью опции SACK сообщит отправителю: «Ты знаешь, три дошло, а середка потерялась». Он говорит: «Ack 2, SACK 4».
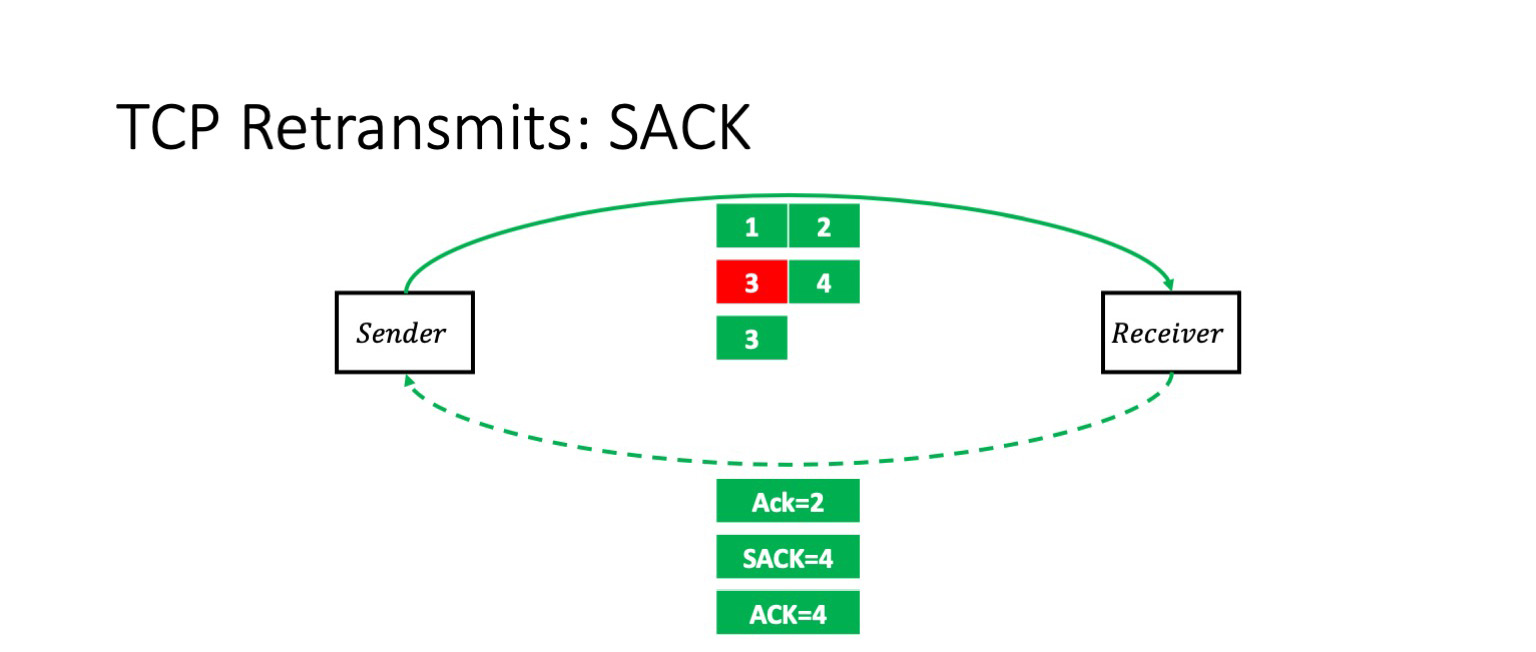
Отправитель в этот момент без проблем повторяет именно тот пакет, который потерялся.
Но если потеряется последний пакет в окне, ситуация будет выглядеть совсем иначе.
Получатель получает первые три пакета и прежде всего начинает ждать. Благодаря некоторым оптимизациям в TCP-стека ядра Linux он будет ждать парного пакета, если нет явного указания во флагах, что это последний пакет либо что-то подобное. Он подождет, пока истечет Delayed ACK таймаут, и после этого отправит подтверждение на первые три пакета. Но теперь уже отправитель будет ждать. Он же не знает, потерялся четвертый пакет или вот-вот дойдет. А чтобы не перегружать сеть, он будет пытаться дождаться момента явного указания, что пакет потерян, или истечения RTO timeout.
Что такое RTO timeout? Это максимум от высчитанного TCP-стеком RTT и некоторой константы. Что это за константа, мы сейчас обсудим.
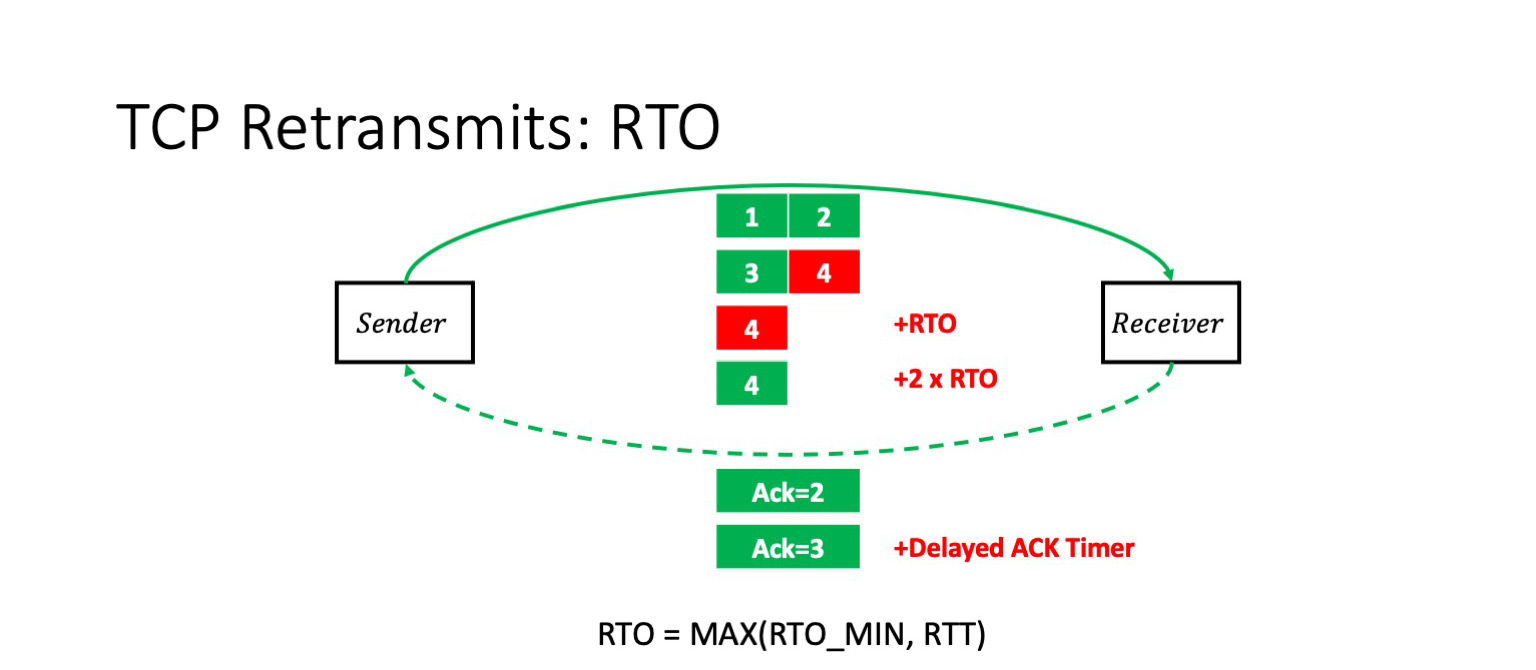
Но важно, что если нам снова не везет и четвертый пакет снова теряется, то RTO удваивается. То есть каждая неудачная попытка — это удвоение таймаута.
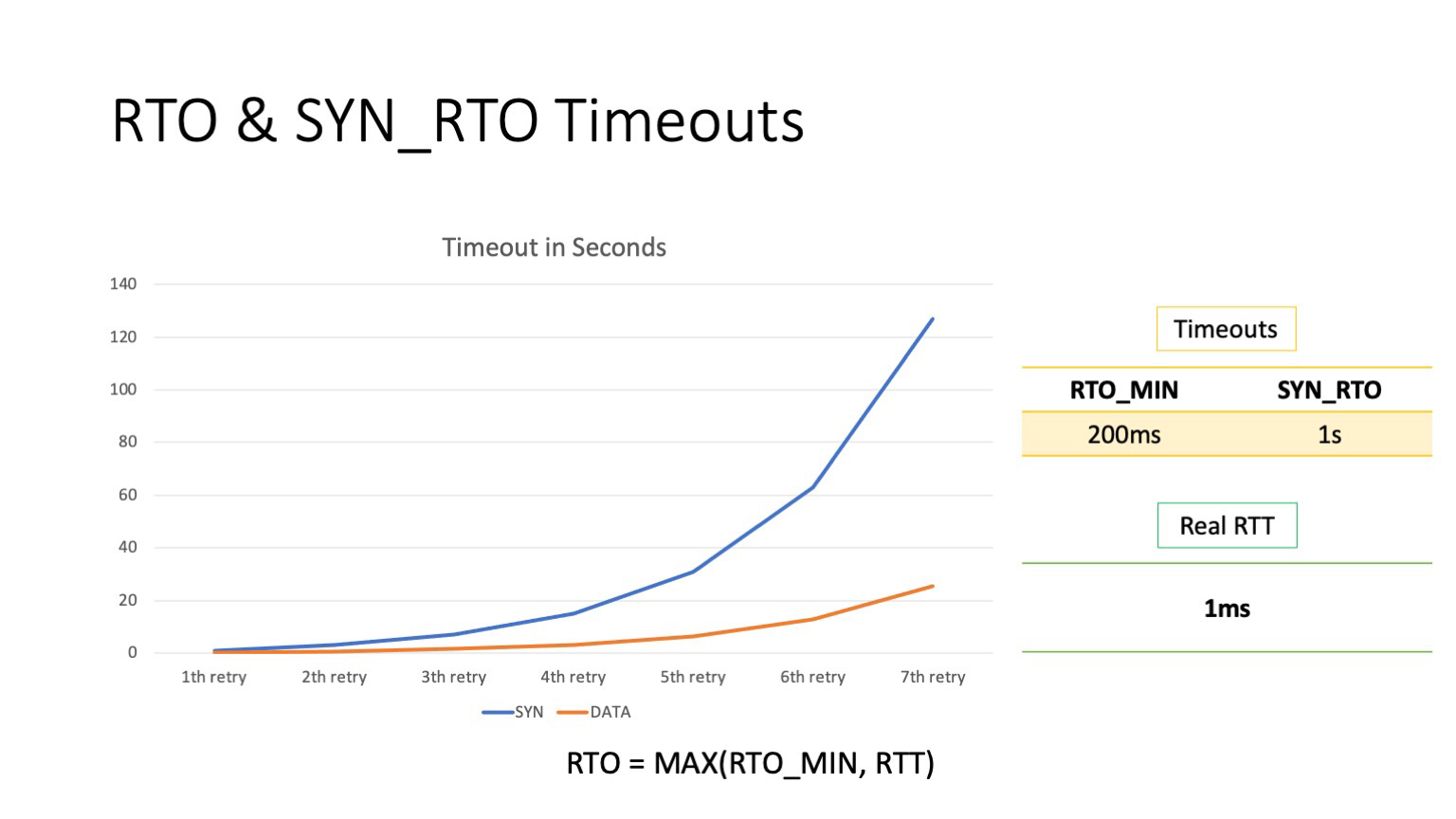
Теперь посмотрим, чему же равна эта база. По дефолту минимальный RTO равен 200 мс. Это минимальный RTO для дата-пакетов. Для SYN-пакетов он другой, 1 секунда. Как можно видеть, даже первая попытка перепослать пакеты будет по времени занимать в 100 раз больше, чем RTT внутри дата-центра.
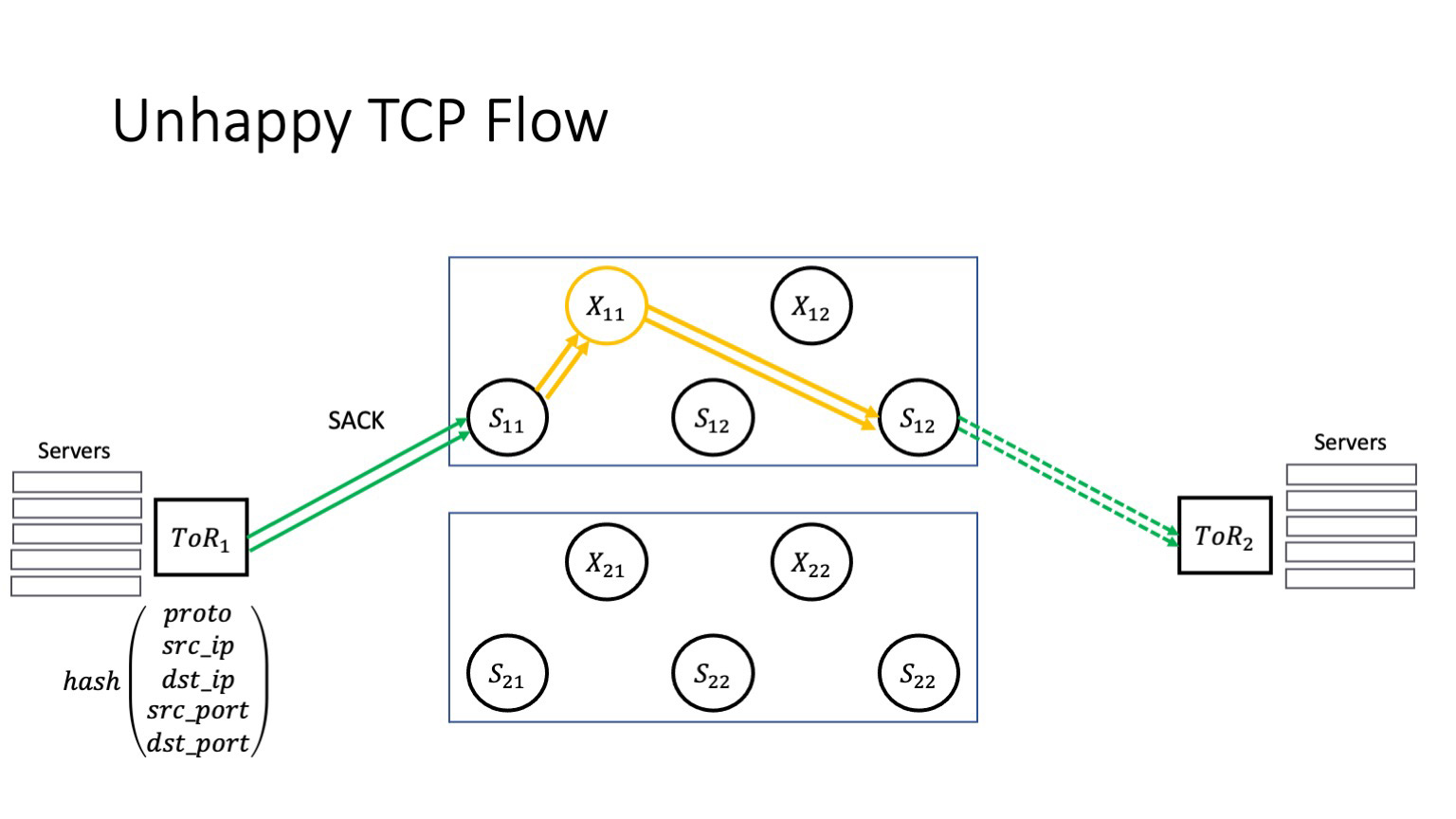
Теперь вернемся к нашему сценарию. Что происходит у сервиса? Сервис начинает терять пакеты. Пусть сервису вначале условно везет и теряется что-то в середине окна, тогда он получает SACK, перепосылает пакеты, которые потерялись.
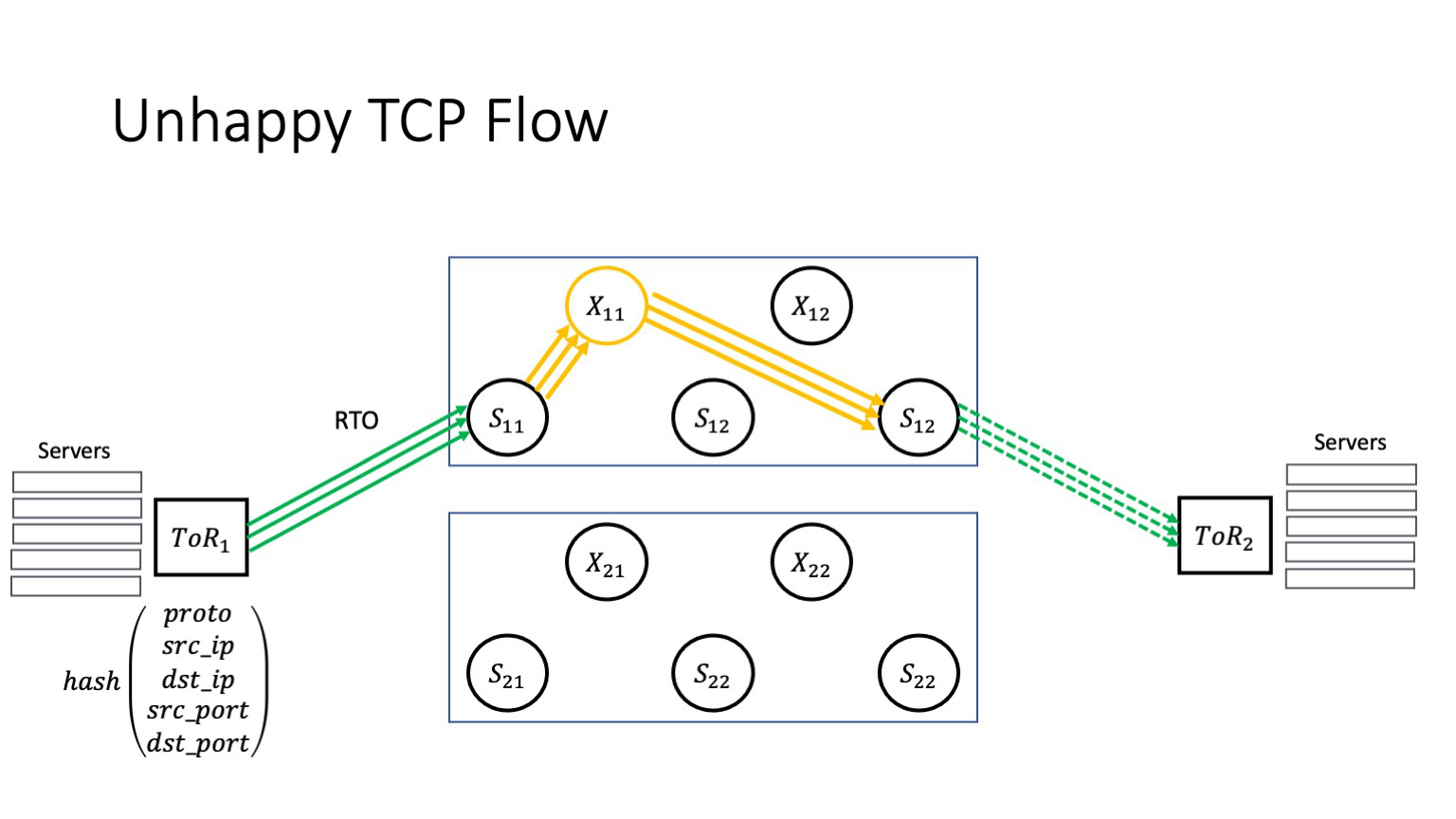
Но если невезение повторяется, то у нас случается RTO. Что здесь важно? Да, у нас в сети очень много путей. Но TCP-трафик одного конкретного TCP-соединения будет продолжать идти через один и тот же битый стек. Потери пакетов при условии, что этот наш волшебный X11 не гаснет самостоятельно, не приводят к тому, что трафик перетекает в участки, которые не являются проблемными. Мы пытаемся доставить пакет через тот же самый битый стек. Это приводит к каскадному отказу: дата-центр — это множество взаимодействующих приложений, и часть TCP-соединений всех этих приложений начинают деградировать — потому что суперспайн затрагивает вообще все приложения, которые есть внутри ДЦ. Как в поговорке: не подковали лошадь — конь захромал; конь захромал — донесение не доставили; донесение не доставили — проиграли войну. Только здесь счет идет на секунды с момента возникновения проблемы до стадии деградации, которую начинают чувствовать сервисы. А значит что-то где-то могут недополучить пользователи.

Есть два классических решения, которые друг друга дополняют. Первое — это сервисы, которые пытаются подложить соломки и решить проблему так: «А давайте мы подкрутим что-нибудь в TCP-стеке. А давайте мы сделаем таймауты на уровне приложения или долго живущие TCP-сессии с внутренними health checks». Проблема в том, что такие решения: а) вообще не масштабируются; б) очень плохо проверяются. То есть даже если сервис случайно настроит TCP-стек так, чтобы ему стало лучше, во-первых, это вряд ли будет применимо для всех приложений и всех дата-центров, а во-вторых, скорее всего, он не поймет, что сделано правильно, а что нет. То есть оно работает, но работает плохо и не масштабируется. И если возникает сетевая проблема, кто виноват? Конечно, NOC. Что делает NOC?

Многие сервисы считают, что в NOC работа происходит примерно так. Но если говорить честно, не только.

NOC в классической схеме занимается разработкой множества мониторингов. Это как black box-мониторинги, так и white box. О примере black box-мониторинга спайнов рассказывал Александр Клименко на прошлом Next Hop. Кстати, этот мониторинг работает. Но даже идеальный мониторинг будет иметь лаг во времени. Обычно это несколько минут. После того, как он срабатывает, дежурным инженерам необходимо время, чтобы перепроверить его работу, локализовать проблему и после этого погасить проблемный участок. То есть в лучшем случае лечение проблемы занимает 5 минут, в худшем 20 минут, если сходу оказывается не очевидно, где же возникают потери. Понятное дело, что все это время — 5 или 20 минут — у нас будут продолжать болеть сервисы, что, наверное, нехорошо.
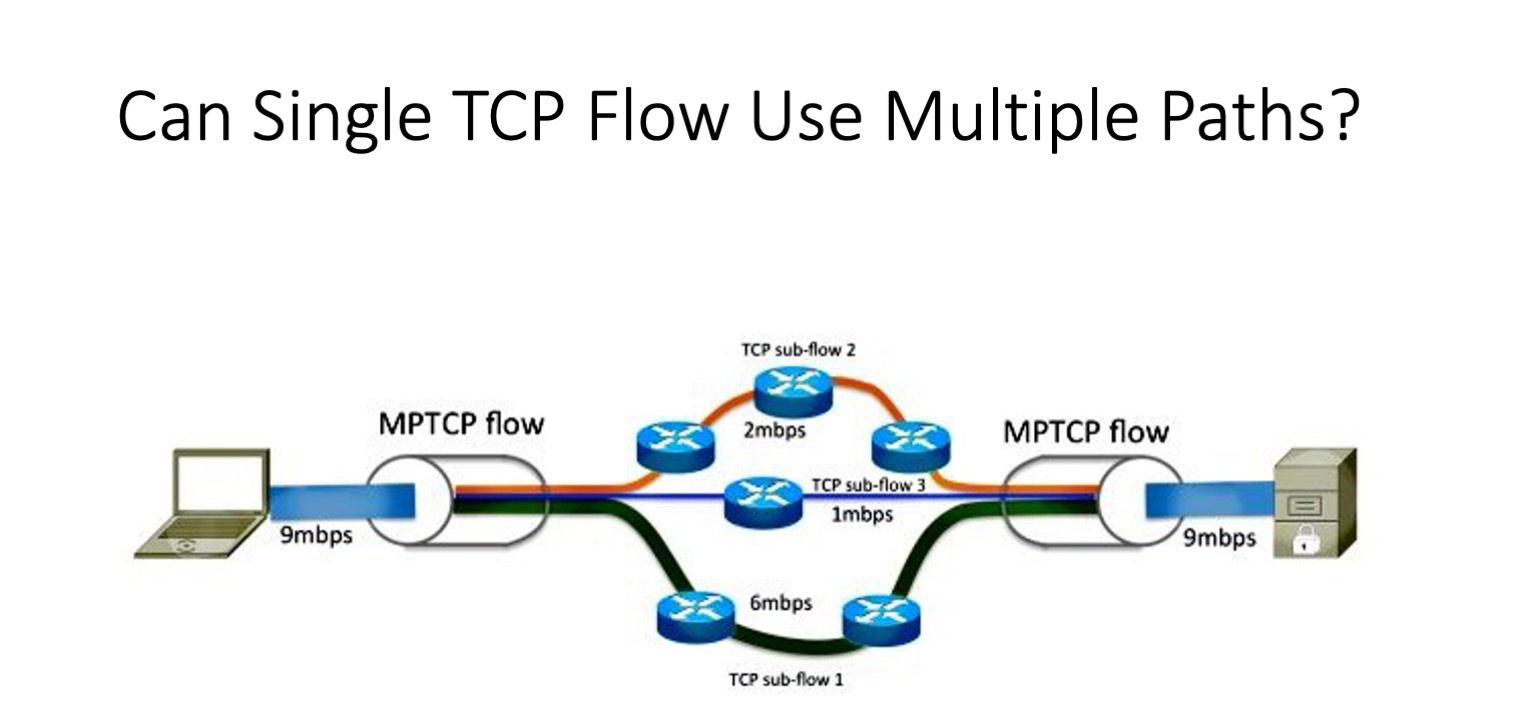
Что очень бы хотелось получить? У нас же столько путей. А проблемы возникают ровно потому, что TCP-потоки, которым не везет, продолжают использовать один и тот же маршрут. Нужно что-то, что позволит нам использовать множество маршрутов в рамках одного TCP-соединения. Казалось бы, у нас есть решение. Есть TCP, который так и называется — multipath TCP, то есть TCP для множества путей. Правда, разрабатывался он для совершенно другой задачи — для смартфонов, которые имеют несколько сетевых устройств. Чтобы максимизировать передачу или сделать режим primary/backup, был разработан механизм, который прозрачно для приложения создает несколько потоков (сеансов) и позволяет в случае возникновения сбоя переключаться между ними. Или, как я сказал, максимизировать полосу.
Но здесь есть нюанс. Чтобы понять, в чем он, нам придется посмотреть, как устанавливаются потоки.
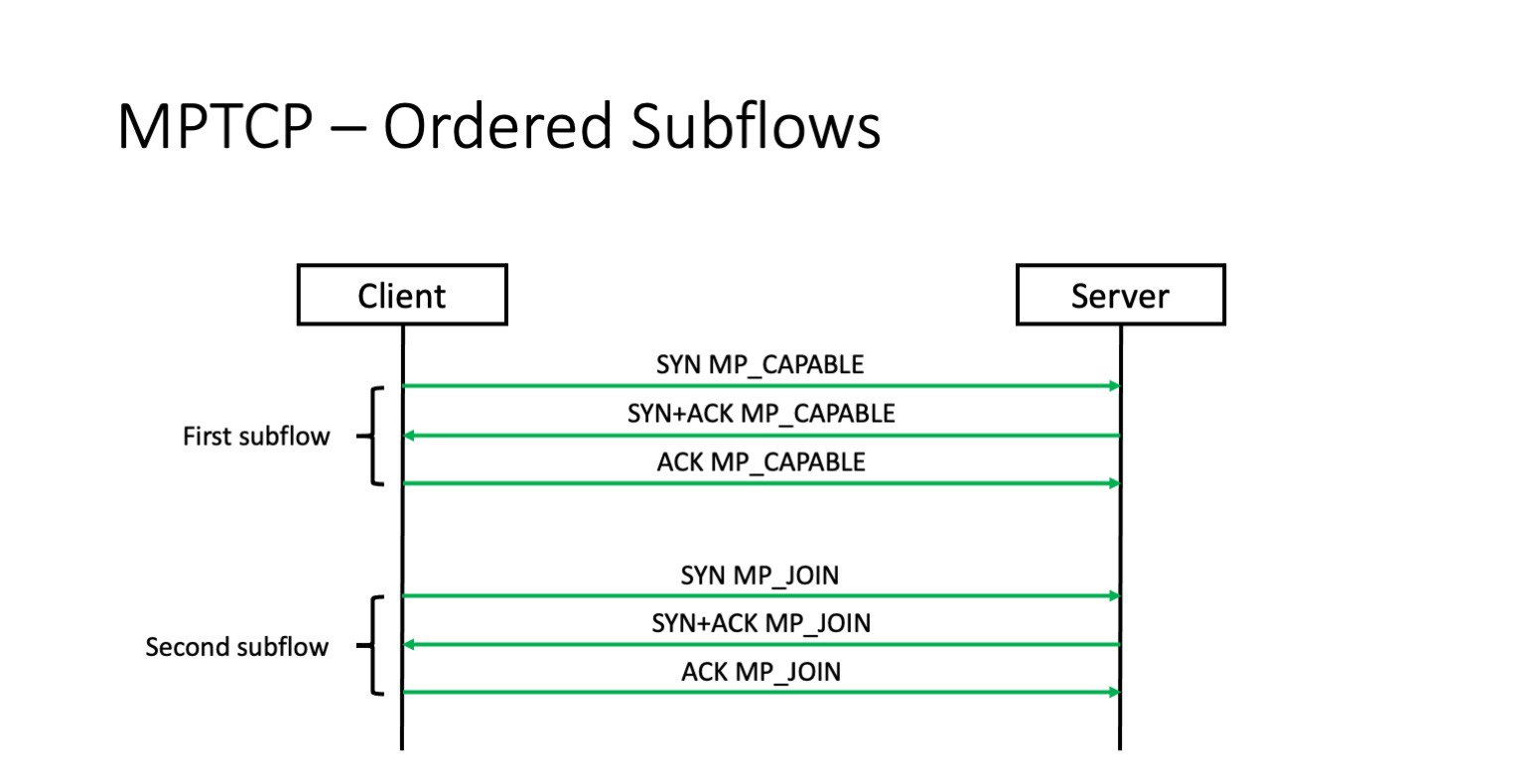
Потоки устанавливаются последовательно. Вначале устанавливается первый поток. Потом с использованием куки, которая уже согласована в рамках этого потока, устанавливаются последующие потоки. И здесь проблема.

Проблема в том, что если первый поток не установится, вторые и третьи потоки никогда и не возникнут. То есть multipath TCP никак не решает потерю SYN пакета у первого потока. И если SYN теряется, multipath TCP превращается в обычный TCP. А значит, в среде дата-центра не поможет нам решить проблему потерь в фабрике и научиться использовать множество путей в случае сбоя.
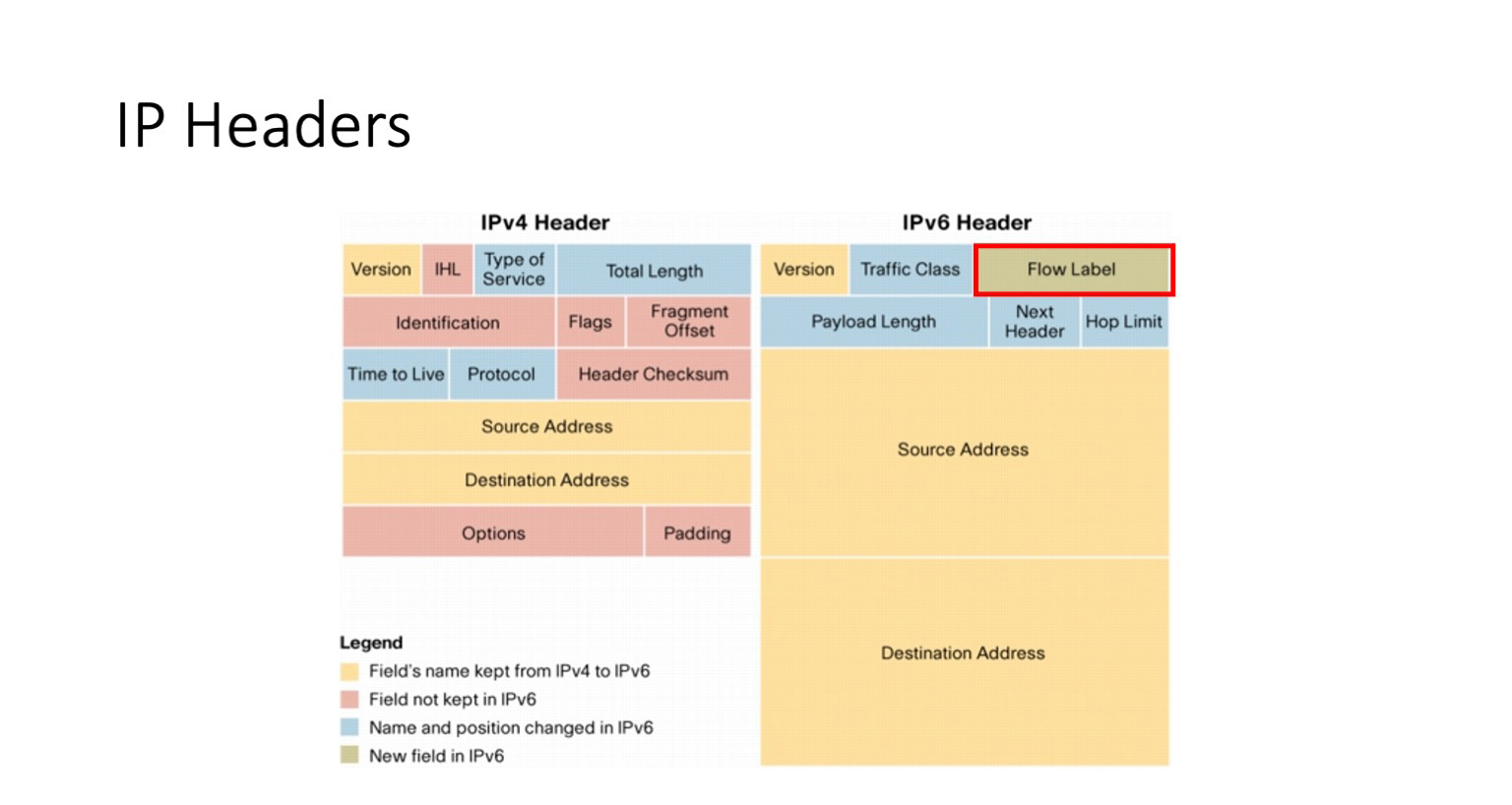
Что может нам помочь? Некоторые из вас уже догадались из названия, что важным полем в нашем дальнейшем рассказе станет поле заголовка IPv6 flow label. И правда, это поле, которое появляется в v6, его нет в v4, оно занимает 20 бит, и по поводу его использования долгое время шли споры. Это очень интересно — споры шли, что-то фиксировалось в рамках RFC, а в Linux-ядре в то же время появилась реализация, которая так нигде и не задокументирована.

Я предлагаю вам вместе со мной отправиться на небольшое расследование. Давайте посмотрим, что происходило в ядре Linux за последние несколько лет.

2014 год. Инженер из одной крупной и уважаемой компании добавляет в функциональность ядра Linux зависимость значения flow label от хеша сокета. Что здесь пытались починить? Это связано с RFC 6438, в котором обсуждалась следующая проблема. Внутри дата-центра зачастую инкапсулируется IPv4 в пакеты IPv6, потому что сама фабрика — IPv6, но наружу как-то надо отдать IPv4. Долгое время были проблемы со свичами, которые не могли заглянуть под два IP-заголовка, чтобы добраться до TCP или UDP и найти там src_ports, dst_ports. Получалось, что хеш, если смотреть на два первые IP-заголовка, оказывался чуть ли не фиксированным. Чтобы этого избежать, чтобы балансировка этого инкапсулированного трафика работала корректно, предложили в значение поля flow label добавить хеш от 5-tuple инкапсулированного пакета. Примерно то же самое было сделано и для других схем инкапсуляции, для UDP, для GRE, в последнем использовалось поле GRE Key. Так или иначе, здесь цели понятны. И по крайней мере, на тот момент времени они были полезны.

В 2015 году от этого же уважаемого инженера приходит новый патч. Он очень интересный. В нем говорится следующее — мы будем рандомизировать хеш в случае негативного события маршрутизации. Что такое негативное событие маршрутизации? Это RTO, которое мы с вами ранее обсуждали, то есть потеря хвоста окна — событие, которое действительно негативное. Правда, относительно сложно догадаться, что это именно оно.
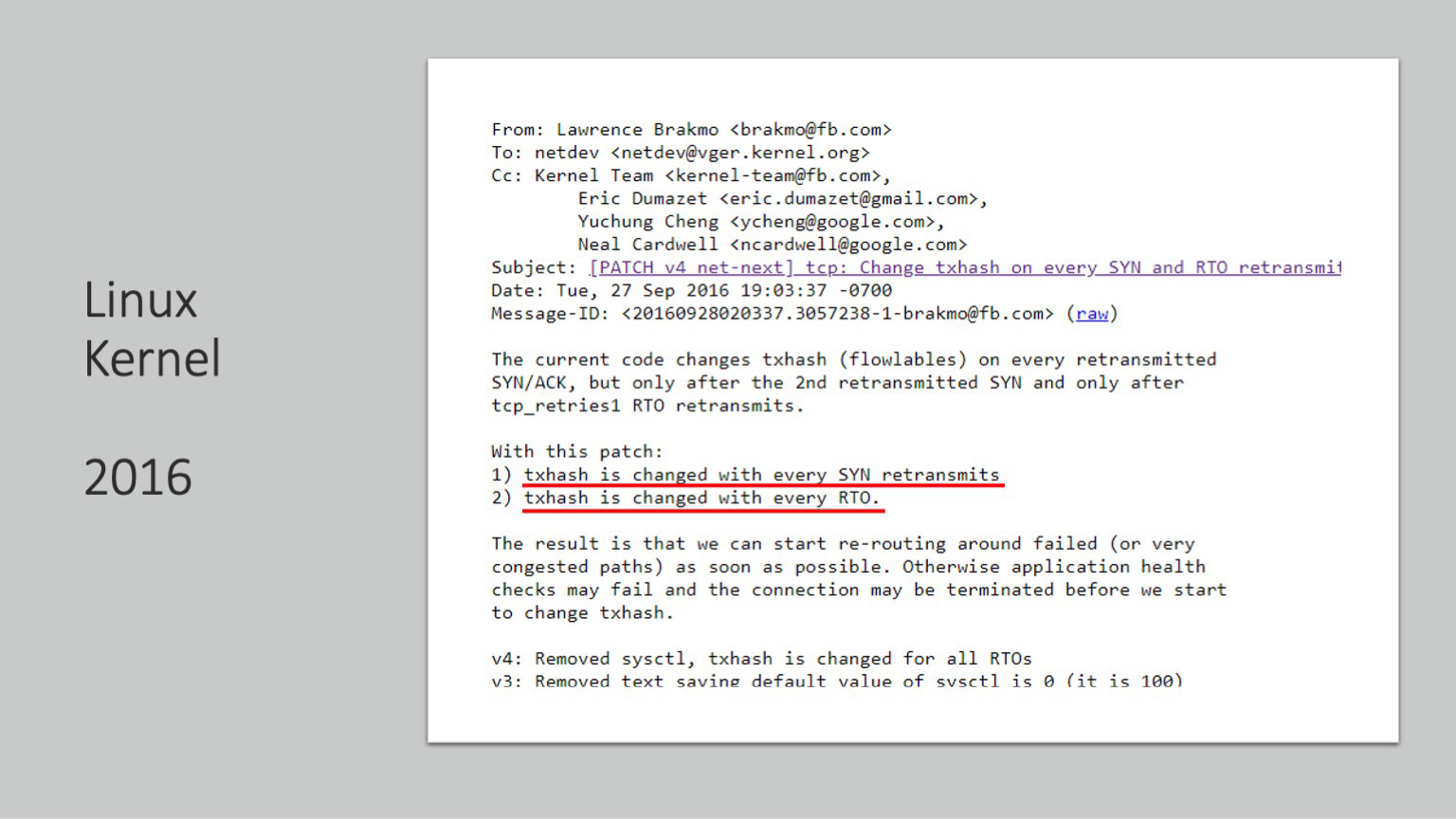
2016 год, другая уважаемая компания, тоже большая. Она разбирает последние костыли и делает так, что хеш, который мы ранее сделали рандомизированным, теперь меняется на каждый ретрансмит SYN и после каждого RTO таймаута. И в этом письме в первый и последний раз звучит конечная цель — сделать так, чтобы трафик в случае возникновения потерь или перегрузки каналов имел возможность мягкой перемаршрутизации, использования множества путей. Конечно, после этого была масса публикаций, вы легко их сможете найти.
Хотя нет, не сможете, потому что ни одной публикации на эту тему не было. Но мы-то знаем!

И если вы не до конца поняли, что же было сделано, я вам сейчас расскажу.

Что же было сделано, какую функциональность добавили в ядро Linux? txhash меняется на рандомное значение после каждого события RTO. Этот тот самый негативный результат маршрутизации. Хеш зависит от этого txhash, а flow label зависит от skb hash. Здесь есть некоторые выкладки по функциям, на один слайд все детали не поместить. Если кому-то любопытно, можно пройти по коду ядра и проверить.
Что здесь важно? Значение поля flow label меняется на случайное число после каждого RTO. Как это влияет на наш несчастливый TCP-поток?
В случае возникновения SACK ничего не изменилось, потому что мы пытаемся перепослать известный потерянный пакет. Пока все относительно хорошо.

Но в случае RTO, при условии, что мы добавили flow label в хеш-функцию на ToR, трафик может пойти другим маршрутом. И чем больше плейнов, тем больше шансов, что он найдет путь, который не затронут сбоем на конкретном устройстве.

Остается одна проблема — RTO. Другой маршрут, конечно, находится, но уж очень много на это тратится времени. 200 мс — это много. Секунда — это вообще дикость. Раньше я рассказывал про таймауты, которые настраивают сервисы. Так вот, секунда — это таймаут, который обычно настраивает сервис на уровне приложения, и в этом сервис будет даже относительно прав. Притом, что, повторюсь, настоящий RTT внутри современного дата-центра — в районе 1 миллисекунды.

Что можно сделать с RTO-таймаутами? Таймаут, который отвечает за RTO в случае потери пакетов с данными, относительно легко можно настроить из user space: есть утилита IP, и в одном из ее параметров есть тот самый rto_min. Учитывая, что крутить RTO, безусловно, нужно не глобально, а для заданных префиксов, такой механизм выглядит вполне рабочим.

Правда, с SYN_RTO всё несколько хуже. Он натурально прибит гвоздями. В ядре зафиксировано значение — 1 секунда, и всё. Из user space дотянуться туда нельзя. Есть только один способ.

На помощь приходит eBPF. Если говорить упрощенно, это небольшие программы на C. Их можно вставить в хуки в разных местах исполнения стека ядра и TCP-стека, с помощью которого можно менять очень большое количество настроек. Вообще, eBPF — это долгосрочный тренд. Вместо того чтобы пилить десятки новых параметров sysctl и расширять утилиту IP, движение идет именно в сторону eBPF и расширения его функциональности. С помощью eBPF можно динамически менять congestion controls и другие разнообразные настройки TCP.
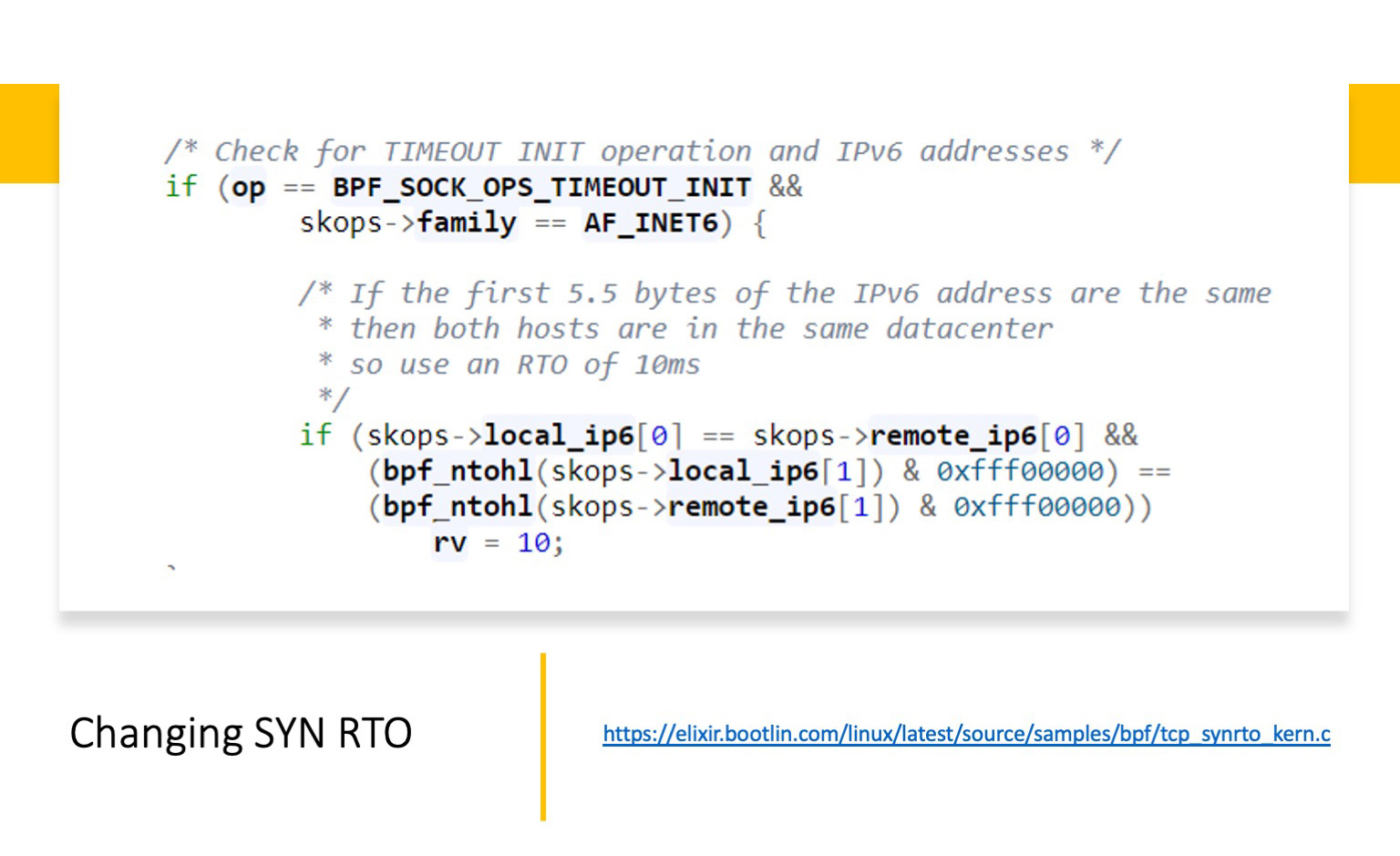
Но нам важно, что с помощью него можно крутить значения SYN_RTO. Причем есть публично выложенный пример: https://elixir.bootlin.com/linux/latest/source/samples/bpf/tcp_synrto_kern.c. Что здесь сделано? Пример рабочий, но сам по себе очень грубый. Здесь предполагается, что внутри дата-центра мы сравниваем первые 44 бита, если они совпадают, значит, мы оказываемся внутри ДЦ. И в этом случае мы меняем значение SYN_RTO timeout на 4ms. Ту же самую задачу можно сделать куда изящней. Но этот простой пример показывает, что такое а) возможно; б) относительно просто.

Что мы уже знаем? Что плейновая архитектура позволяет масштабироваться, она оказывается нам чрезвычайно полезной, когда мы включаем flow label на ToR и получаем возможность обтекать проблемные участки. Самый лучший способ снизить значения RTO и SYN-RTO — использовать eBPF-программы. Остается вопрос: а безопасно ли использовать flow label для балансировки? И здесь есть нюанс.
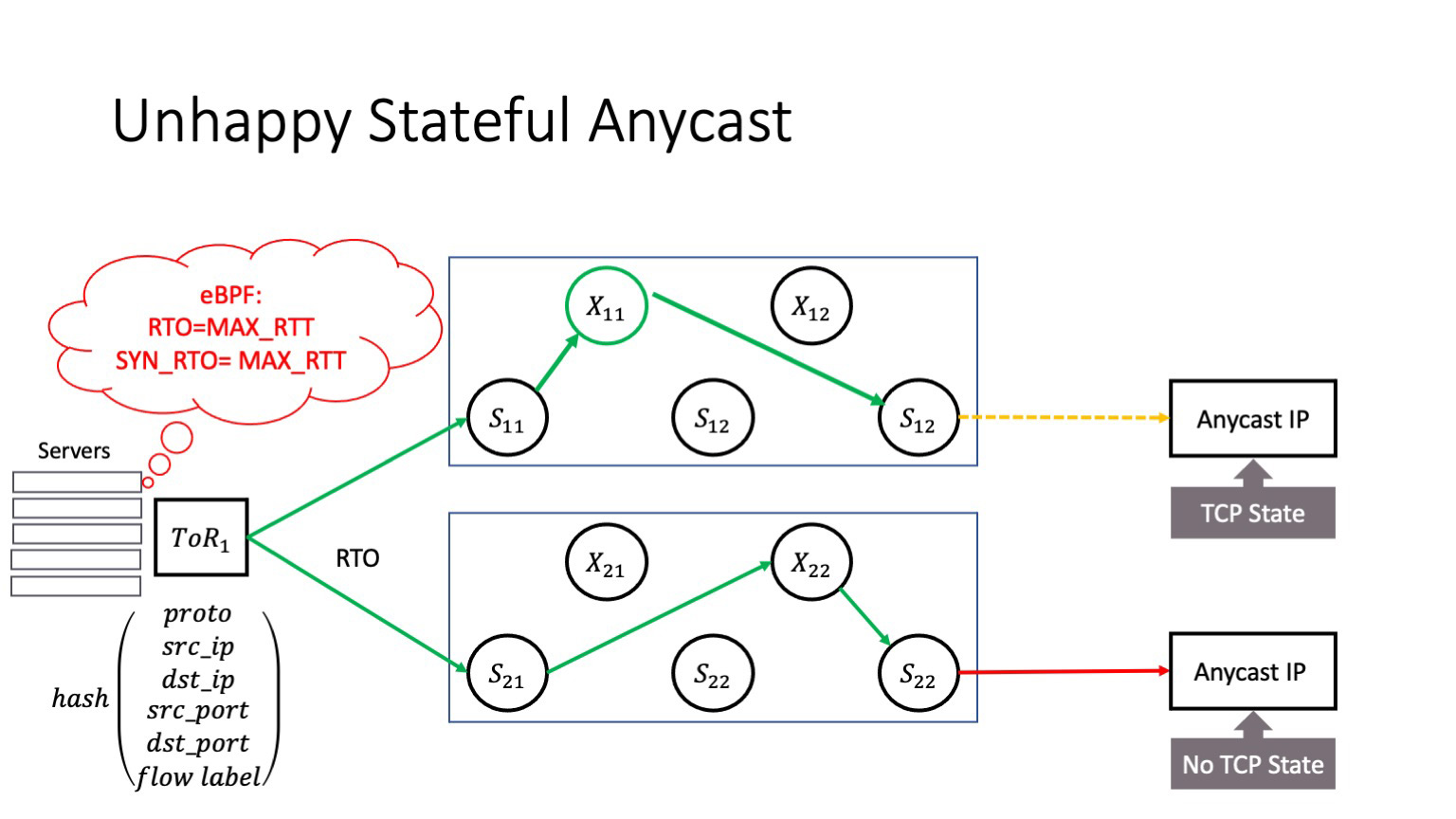
Пусть у вас в сети есть сервис, который живет в anycast. К сожалению, у меня нет времени подробно рассказывать, что такое anycast, но это распределенный сервис, разные физические сервера которого доступны по одному и тому же IP-адресу. И здесь возможна проблема: событие RTO может возникнуть не только при прохождении трафика через фабрику. Оно может возникнуть и на уровне буфера ToR: когда случается incast-событие, оно может возникнуть даже на хосте, когда хост что-то проливает. Когда происходит событие RTO, и оно меняет flow label. В этом случае трафик может попасть на другой anycast instance. Предположим, это stateful anycast, он держит в себе connection state — это может быть L3 Balancer или еще какой-то сервис. Тогда возникает проблема, потому что после RTO TCP-соединение прилетает на сервер, который об этом TCP-соединении ничего не знает. И если у нас нет шеринга стейтов между anycast-серверами, то такой трафик будет сброшен и TCP-соединение порвется.
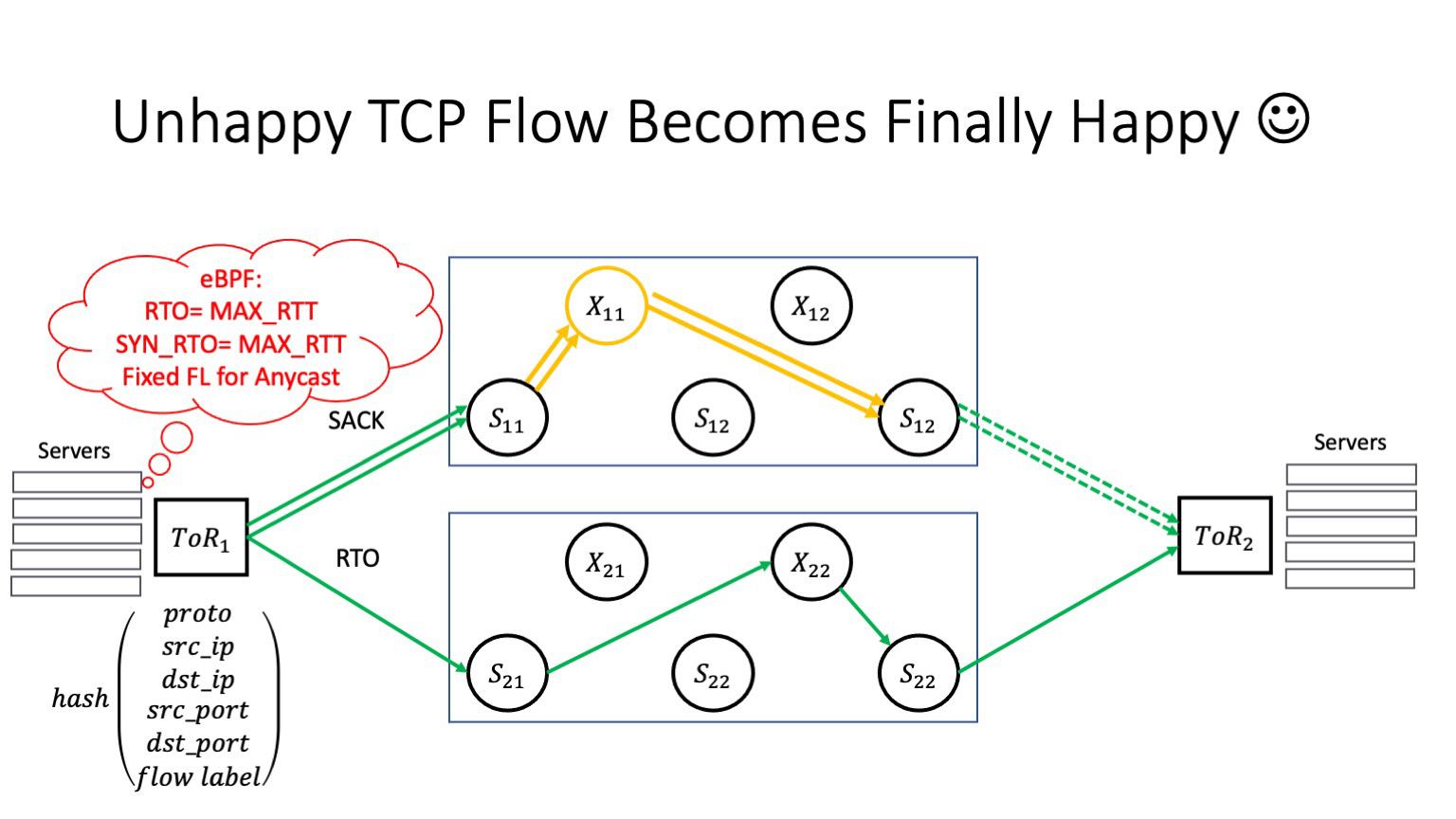
Что здесь можно сделать? Внутри вашей контролируемой среды, где вы включаете балансировку flow label, необходимо фиксировать значение flow label при обращении к anycast-серверам. Самый простой способ — сделать это через ту же eBPF-программу. Но здесь очень важный момент — что делать, если вы оперируете не сетью дата-центра, а являетесь оператором связи? Это и ваша проблема тоже: начиная с определенных версий Juniper и Arista включают flow label в хеш-функции по дефолту — честно говоря, по непонятной мне причине. Это может приводить к тому, что вы будете рвать TCP-соединения пользователей, идущих через вашу сеть. Поэтому я настоятельно рекомендую проверить настройки ваших маршрутизаторов в этом месте.
Так или иначе, мне кажется, что мы готовы перейти к экспериментам.
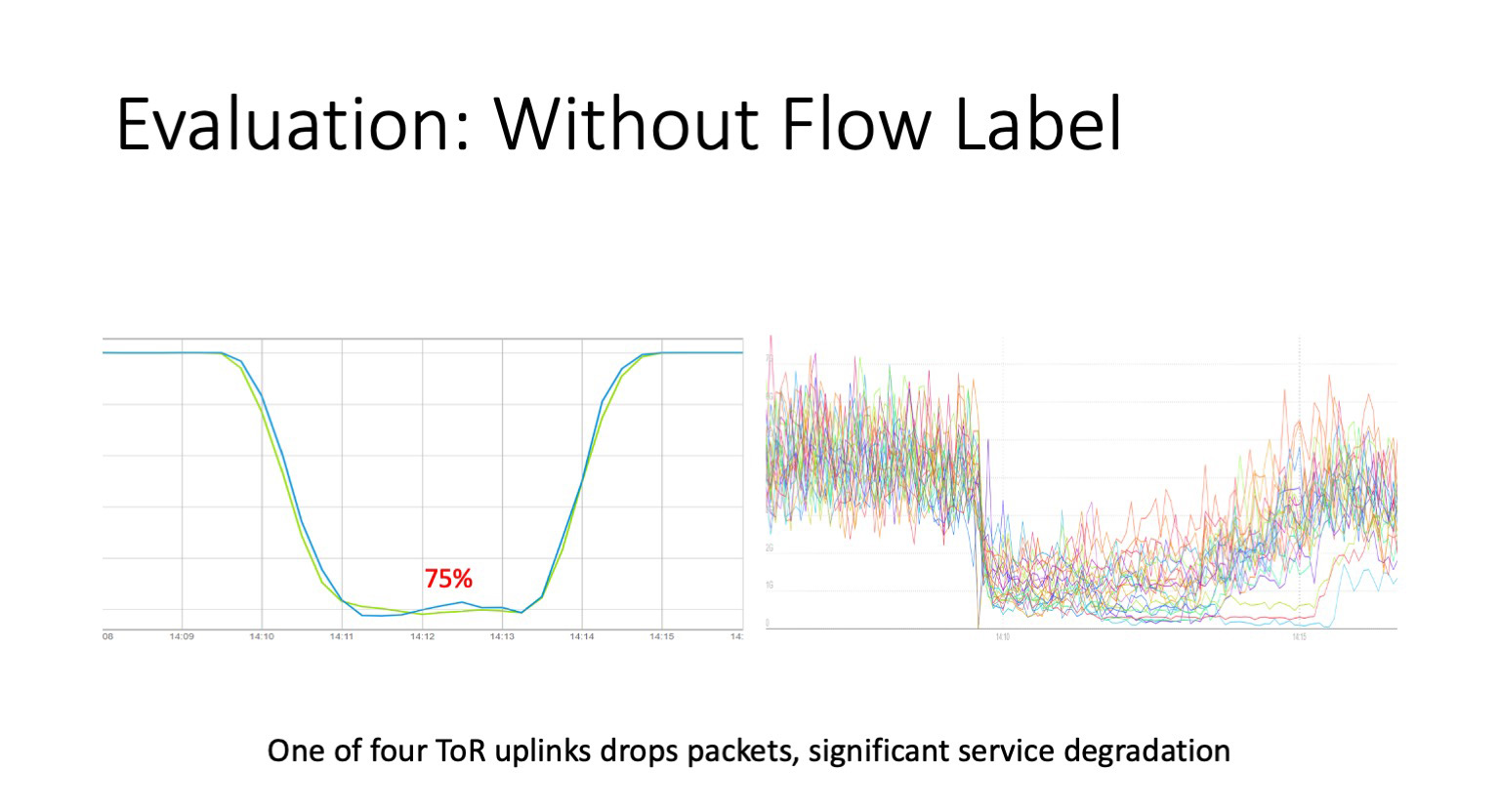
Когда мы включили flow label на ToR, подготовили eBPF агента, который теперь живет на хостах, мы решили не дожидаться следующего большого сбоя, а провести контролируемые взрывы. Мы взяли ToR, у которого четыре аплинка, и на одном из них устроили дропы. Нарисовали правило, сказали — теперь ты теряешь все пакеты. Как можно видеть слева, у нас per-packet monitoring, который просел до значения 75%, то есть 25% пакетов теряются. Справа графики сервисов, живущих за этим ToR. По сути это графики трафика стыков с серверами внутри стойки. Как можно видеть, они просели даже ниже. Почему они просели ниже — не на 25%, а в некоторых случаях в 3–4 раза? Если TCP-соединению не везет, оно продолжает пробовать достучаться через битый стык. Это усугубляется типовым поведением сервиса внутри ДЦ — на один запрос пользователя генерируется N запросов к внутренним сервисам, и ответ уйдет к пользователю, либо когда ответят все источники данных, либо когда сработает таймаут на уровне приложения, который еще должен быть настроен. То есть все весьма и весьма плохо.

Теперь тот же самый эксперимент, но с включенным значением flow label. Как можно видеть, слева наш пакетный мониторинг просел на те же самые 25%. Это абсолютно корректно, потому что он ничего не знает о ретрансмитах, он отправляет пакеты и просто считает отношение количества доставленных и потерянных пакетов.
А справа находится график сервисов. Вы здесь не найдете эффекта от проблемного стыка. Трафик за те самые миллисекунды перетек из проблемного участка в три оставшихся аплинка, не затронутых проблемой. Мы получили сеть, которая лечит себя сама.

Это мой последний слайд, время подвести итоги. Теперь, я надеюсь, вы знаете, как строить сеть дата-центра, способную к самолечению. Вам не нужно будет ходить по архиву ядра Linux и выискивать там специальные патчи, вы знаете, что Flow label в данном случае решает проблему, но подходить к этому механизму нужно осторожно. И я еще раз подчеркиваю, что если вы оператор связи, вы не должны использовать flow label в качестве хеш-функции, иначе вы будете рвать сессии ваших пользователей.
У сетевых инженеров должен произойти концептуальный сдвиг: сеть начинается не с ToR, не с сетевого устройства, а с хоста. Достаточно яркий пример — то, как мы используем eBPF и для изменения RTO, и для фиксации flow label в сторону anycast-сервисов.
Механика flow label, безусловно, подходит и для других применений внутри контролируемого административного сегмента. Это может быть трафик между дата-центрами, а можно особым способом использовать такую механику и для управления исходящим трафиком. Но об этом я расскажу, надеюсь, в следующий раз. Спасибо большое за внимание.
— Для начала я дам достаточно подробную вводную для тех, кто, может быть, не в курсе устройства современного ДЦ.
Для многих сетевых инженеров сеть дата-центра начинается, конечно, с ToR, со свитча в стойке. ToR обычно имеет два типа линков. Маленькие идут к серверам, другие — их в N раз больше — идут в сторону спайнов первого уровня, то есть к его аплинкам. Аплинки обычно считаются равнозначными, и трафик между аплинками балансируется на основе хеша от 5-tuple, в который входят proto, src_ip, dst_ip, src_port, dst_port. Здесь никаких сюрпризов.
Дальше, как выглядит архитектура плейнов? Спайны первого уровня между собой не соединены, а соединяются посредством суперспайнов. За суперспайны у нас будет отвечать буква X, она практически как кроссконнект.
И понятное дело, что с другой стороны ко всем спайнам первого уровня подключены торы. Что важно на этой картинке? Если у нас идет взаимодействие внутри стойки, то взаимодействие, понятное дело, идет через ToR. Если взаимодействие идет внутри модуля, то взаимодействие идет через спайны первого уровня. Если взаимодействие межмодульное — как здесь, ToR 1 и ToR 2, — то взаимодействие пойдет через спайны как первого, так и второго уровня.
Теоретически такая архитектура легко масштабируется. Если у нас есть портовая емкость, запас места в дата-центре и заранее проложенное волокно, то всегда количество плейнов можно нарастить, тем самым повышая общую емкость системы. На бумаге сделать такое очень легко. Было бы так в жизни. Но сегодняшний рассказ не об этом.
Я хочу, чтобы были сделаны правильные выводы. У нас внутри дата-центра много путей. Они условно независимы. Один путь внутри дата-центра возможен только внутри ToR. Внутри модуля у нас количество путей равно количеству плейнов. Количество путей между модулями равно произведению числа плейнов на число суперспайнов в каждом плейне. Чтобы было понятнее, чтобы почувствовать масштаб, я дам цифры, которые справедливы для одного из дата-центров Яндекса.
Плейнов восемь, в каждом плейне 32 суперспайна. В итоге получается, что внутри модуля восемь путей, а при межмодульном взаимодействии их уже 256.
То есть если мы разрабатываем Cookbook, пытаемся научиться тому, как строить отказоустойчивые дата-центры, которые лечат себя самостоятельно, то плейновая архитектура — правильный выбор. Она позволяет решить задачу масштабирования, и теоретически это легко. Есть множество независимых путей. Остается вопрос: как такая архитектура переживает сбои? Бывают разные сбои. И мы сейчас это обсудим.
Пусть у нас один из суперспайнов «заболел». Я здесь вернулся к архитектуре двух плейнов. В качестве примера мы остановимся на них, потому что здесь попросту будет легче видеть, что происходит, с меньшим числом движущихся частей. Пусть X11 заболел. Как это повлияет на сервисы, которые живут внутри дата-центров? Очень многое зависит от того, как сбой выглядит на самом деле.
Если сбой хороший, ловится на уровне автоматики того же BFD, автоматика радостно кладет проблемные стыки и изолирует проблему, то все хорошо. У нас множество путей, трафик моментально перемаршрутизируется на альтернативные маршруты, и сервисы ничего не заметят. Это хороший сценарий.
Плохой сценарий — если у нас возникают постоянные потери, и автоматика проблемы не замечает. Чтобы понять, как это влияет на приложение, нам придется потратить немного времени на обсуждение того, как работает протокол TCP.
Я надеюсь, что никого не шокирую этой информацией: TCP — протокол с подтверждением передачи. То есть в простейшем случае у нас отправитель отправляет два пакета, и получает на них кумулятивный ack: «Я получил два пакета».
После этого он отправит еще два пакета, и ситуация повторится. Я заранее прошу прощения за некоторое упрощение. Такой сценарий верный, если окно (число пакетов в полете) равно двум. Конечно, в общем случае это необязательно так. Но на контекст перепосылки пакетов размер окна не влияет.
Что будет, если мы потеряем пакет 3? В этом случае получатель получит пакеты 1, 2 и 4. И он в явном виде с помощью опции SACK сообщит отправителю: «Ты знаешь, три дошло, а середка потерялась». Он говорит: «Ack 2, SACK 4».
Отправитель в этот момент без проблем повторяет именно тот пакет, который потерялся.
Но если потеряется последний пакет в окне, ситуация будет выглядеть совсем иначе.
Получатель получает первые три пакета и прежде всего начинает ждать. Благодаря некоторым оптимизациям в TCP-стека ядра Linux он будет ждать парного пакета, если нет явного указания во флагах, что это последний пакет либо что-то подобное. Он подождет, пока истечет Delayed ACK таймаут, и после этого отправит подтверждение на первые три пакета. Но теперь уже отправитель будет ждать. Он же не знает, потерялся четвертый пакет или вот-вот дойдет. А чтобы не перегружать сеть, он будет пытаться дождаться момента явного указания, что пакет потерян, или истечения RTO timeout.
Что такое RTO timeout? Это максимум от высчитанного TCP-стеком RTT и некоторой константы. Что это за константа, мы сейчас обсудим.
Но важно, что если нам снова не везет и четвертый пакет снова теряется, то RTO удваивается. То есть каждая неудачная попытка — это удвоение таймаута.
Теперь посмотрим, чему же равна эта база. По дефолту минимальный RTO равен 200 мс. Это минимальный RTO для дата-пакетов. Для SYN-пакетов он другой, 1 секунда. Как можно видеть, даже первая попытка перепослать пакеты будет по времени занимать в 100 раз больше, чем RTT внутри дата-центра.
Теперь вернемся к нашему сценарию. Что происходит у сервиса? Сервис начинает терять пакеты. Пусть сервису вначале условно везет и теряется что-то в середине окна, тогда он получает SACK, перепосылает пакеты, которые потерялись.
Но если невезение повторяется, то у нас случается RTO. Что здесь важно? Да, у нас в сети очень много путей. Но TCP-трафик одного конкретного TCP-соединения будет продолжать идти через один и тот же битый стек. Потери пакетов при условии, что этот наш волшебный X11 не гаснет самостоятельно, не приводят к тому, что трафик перетекает в участки, которые не являются проблемными. Мы пытаемся доставить пакет через тот же самый битый стек. Это приводит к каскадному отказу: дата-центр — это множество взаимодействующих приложений, и часть TCP-соединений всех этих приложений начинают деградировать — потому что суперспайн затрагивает вообще все приложения, которые есть внутри ДЦ. Как в поговорке: не подковали лошадь — конь захромал; конь захромал — донесение не доставили; донесение не доставили — проиграли войну. Только здесь счет идет на секунды с момента возникновения проблемы до стадии деградации, которую начинают чувствовать сервисы. А значит что-то где-то могут недополучить пользователи.
Есть два классических решения, которые друг друга дополняют. Первое — это сервисы, которые пытаются подложить соломки и решить проблему так: «А давайте мы подкрутим что-нибудь в TCP-стеке. А давайте мы сделаем таймауты на уровне приложения или долго живущие TCP-сессии с внутренними health checks». Проблема в том, что такие решения: а) вообще не масштабируются; б) очень плохо проверяются. То есть даже если сервис случайно настроит TCP-стек так, чтобы ему стало лучше, во-первых, это вряд ли будет применимо для всех приложений и всех дата-центров, а во-вторых, скорее всего, он не поймет, что сделано правильно, а что нет. То есть оно работает, но работает плохо и не масштабируется. И если возникает сетевая проблема, кто виноват? Конечно, NOC. Что делает NOC?
Многие сервисы считают, что в NOC работа происходит примерно так. Но если говорить честно, не только.
NOC в классической схеме занимается разработкой множества мониторингов. Это как black box-мониторинги, так и white box. О примере black box-мониторинга спайнов рассказывал Александр Клименко на прошлом Next Hop. Кстати, этот мониторинг работает. Но даже идеальный мониторинг будет иметь лаг во времени. Обычно это несколько минут. После того, как он срабатывает, дежурным инженерам необходимо время, чтобы перепроверить его работу, локализовать проблему и после этого погасить проблемный участок. То есть в лучшем случае лечение проблемы занимает 5 минут, в худшем 20 минут, если сходу оказывается не очевидно, где же возникают потери. Понятное дело, что все это время — 5 или 20 минут — у нас будут продолжать болеть сервисы, что, наверное, нехорошо.
Что очень бы хотелось получить? У нас же столько путей. А проблемы возникают ровно потому, что TCP-потоки, которым не везет, продолжают использовать один и тот же маршрут. Нужно что-то, что позволит нам использовать множество маршрутов в рамках одного TCP-соединения. Казалось бы, у нас есть решение. Есть TCP, который так и называется — multipath TCP, то есть TCP для множества путей. Правда, разрабатывался он для совершенно другой задачи — для смартфонов, которые имеют несколько сетевых устройств. Чтобы максимизировать передачу или сделать режим primary/backup, был разработан механизм, который прозрачно для приложения создает несколько потоков (сеансов) и позволяет в случае возникновения сбоя переключаться между ними. Или, как я сказал, максимизировать полосу.
Но здесь есть нюанс. Чтобы понять, в чем он, нам придется посмотреть, как устанавливаются потоки.
Потоки устанавливаются последовательно. Вначале устанавливается первый поток. Потом с использованием куки, которая уже согласована в рамках этого потока, устанавливаются последующие потоки. И здесь проблема.
Проблема в том, что если первый поток не установится, вторые и третьи потоки никогда и не возникнут. То есть multipath TCP никак не решает потерю SYN пакета у первого потока. И если SYN теряется, multipath TCP превращается в обычный TCP. А значит, в среде дата-центра не поможет нам решить проблему потерь в фабрике и научиться использовать множество путей в случае сбоя.
Что может нам помочь? Некоторые из вас уже догадались из названия, что важным полем в нашем дальнейшем рассказе станет поле заголовка IPv6 flow label. И правда, это поле, которое появляется в v6, его нет в v4, оно занимает 20 бит, и по поводу его использования долгое время шли споры. Это очень интересно — споры шли, что-то фиксировалось в рамках RFC, а в Linux-ядре в то же время появилась реализация, которая так нигде и не задокументирована.
Я предлагаю вам вместе со мной отправиться на небольшое расследование. Давайте посмотрим, что происходило в ядре Linux за последние несколько лет.
2014 год. Инженер из одной крупной и уважаемой компании добавляет в функциональность ядра Linux зависимость значения flow label от хеша сокета. Что здесь пытались починить? Это связано с RFC 6438, в котором обсуждалась следующая проблема. Внутри дата-центра зачастую инкапсулируется IPv4 в пакеты IPv6, потому что сама фабрика — IPv6, но наружу как-то надо отдать IPv4. Долгое время были проблемы со свичами, которые не могли заглянуть под два IP-заголовка, чтобы добраться до TCP или UDP и найти там src_ports, dst_ports. Получалось, что хеш, если смотреть на два первые IP-заголовка, оказывался чуть ли не фиксированным. Чтобы этого избежать, чтобы балансировка этого инкапсулированного трафика работала корректно, предложили в значение поля flow label добавить хеш от 5-tuple инкапсулированного пакета. Примерно то же самое было сделано и для других схем инкапсуляции, для UDP, для GRE, в последнем использовалось поле GRE Key. Так или иначе, здесь цели понятны. И по крайней мере, на тот момент времени они были полезны.
В 2015 году от этого же уважаемого инженера приходит новый патч. Он очень интересный. В нем говорится следующее — мы будем рандомизировать хеш в случае негативного события маршрутизации. Что такое негативное событие маршрутизации? Это RTO, которое мы с вами ранее обсуждали, то есть потеря хвоста окна — событие, которое действительно негативное. Правда, относительно сложно догадаться, что это именно оно.
2016 год, другая уважаемая компания, тоже большая. Она разбирает последние костыли и делает так, что хеш, который мы ранее сделали рандомизированным, теперь меняется на каждый ретрансмит SYN и после каждого RTO таймаута. И в этом письме в первый и последний раз звучит конечная цель — сделать так, чтобы трафик в случае возникновения потерь или перегрузки каналов имел возможность мягкой перемаршрутизации, использования множества путей. Конечно, после этого была масса публикаций, вы легко их сможете найти.
Хотя нет, не сможете, потому что ни одной публикации на эту тему не было. Но мы-то знаем!
И если вы не до конца поняли, что же было сделано, я вам сейчас расскажу.
Что же было сделано, какую функциональность добавили в ядро Linux? txhash меняется на рандомное значение после каждого события RTO. Этот тот самый негативный результат маршрутизации. Хеш зависит от этого txhash, а flow label зависит от skb hash. Здесь есть некоторые выкладки по функциям, на один слайд все детали не поместить. Если кому-то любопытно, можно пройти по коду ядра и проверить.
Что здесь важно? Значение поля flow label меняется на случайное число после каждого RTO. Как это влияет на наш несчастливый TCP-поток?
В случае возникновения SACK ничего не изменилось, потому что мы пытаемся перепослать известный потерянный пакет. Пока все относительно хорошо.
Но в случае RTO, при условии, что мы добавили flow label в хеш-функцию на ToR, трафик может пойти другим маршрутом. И чем больше плейнов, тем больше шансов, что он найдет путь, который не затронут сбоем на конкретном устройстве.
Остается одна проблема — RTO. Другой маршрут, конечно, находится, но уж очень много на это тратится времени. 200 мс — это много. Секунда — это вообще дикость. Раньше я рассказывал про таймауты, которые настраивают сервисы. Так вот, секунда — это таймаут, который обычно настраивает сервис на уровне приложения, и в этом сервис будет даже относительно прав. Притом, что, повторюсь, настоящий RTT внутри современного дата-центра — в районе 1 миллисекунды.
Что можно сделать с RTO-таймаутами? Таймаут, который отвечает за RTO в случае потери пакетов с данными, относительно легко можно настроить из user space: есть утилита IP, и в одном из ее параметров есть тот самый rto_min. Учитывая, что крутить RTO, безусловно, нужно не глобально, а для заданных префиксов, такой механизм выглядит вполне рабочим.
Правда, с SYN_RTO всё несколько хуже. Он натурально прибит гвоздями. В ядре зафиксировано значение — 1 секунда, и всё. Из user space дотянуться туда нельзя. Есть только один способ.
На помощь приходит eBPF. Если говорить упрощенно, это небольшие программы на C. Их можно вставить в хуки в разных местах исполнения стека ядра и TCP-стека, с помощью которого можно менять очень большое количество настроек. Вообще, eBPF — это долгосрочный тренд. Вместо того чтобы пилить десятки новых параметров sysctl и расширять утилиту IP, движение идет именно в сторону eBPF и расширения его функциональности. С помощью eBPF можно динамически менять congestion controls и другие разнообразные настройки TCP.
Но нам важно, что с помощью него можно крутить значения SYN_RTO. Причем есть публично выложенный пример: https://elixir.bootlin.com/linux/latest/source/samples/bpf/tcp_synrto_kern.c. Что здесь сделано? Пример рабочий, но сам по себе очень грубый. Здесь предполагается, что внутри дата-центра мы сравниваем первые 44 бита, если они совпадают, значит, мы оказываемся внутри ДЦ. И в этом случае мы меняем значение SYN_RTO timeout на 4ms. Ту же самую задачу можно сделать куда изящней. Но этот простой пример показывает, что такое а) возможно; б) относительно просто.
Что мы уже знаем? Что плейновая архитектура позволяет масштабироваться, она оказывается нам чрезвычайно полезной, когда мы включаем flow label на ToR и получаем возможность обтекать проблемные участки. Самый лучший способ снизить значения RTO и SYN-RTO — использовать eBPF-программы. Остается вопрос: а безопасно ли использовать flow label для балансировки? И здесь есть нюанс.
Пусть у вас в сети есть сервис, который живет в anycast. К сожалению, у меня нет времени подробно рассказывать, что такое anycast, но это распределенный сервис, разные физические сервера которого доступны по одному и тому же IP-адресу. И здесь возможна проблема: событие RTO может возникнуть не только при прохождении трафика через фабрику. Оно может возникнуть и на уровне буфера ToR: когда случается incast-событие, оно может возникнуть даже на хосте, когда хост что-то проливает. Когда происходит событие RTO, и оно меняет flow label. В этом случае трафик может попасть на другой anycast instance. Предположим, это stateful anycast, он держит в себе connection state — это может быть L3 Balancer или еще какой-то сервис. Тогда возникает проблема, потому что после RTO TCP-соединение прилетает на сервер, который об этом TCP-соединении ничего не знает. И если у нас нет шеринга стейтов между anycast-серверами, то такой трафик будет сброшен и TCP-соединение порвется.
Что здесь можно сделать? Внутри вашей контролируемой среды, где вы включаете балансировку flow label, необходимо фиксировать значение flow label при обращении к anycast-серверам. Самый простой способ — сделать это через ту же eBPF-программу. Но здесь очень важный момент — что делать, если вы оперируете не сетью дата-центра, а являетесь оператором связи? Это и ваша проблема тоже: начиная с определенных версий Juniper и Arista включают flow label в хеш-функции по дефолту — честно говоря, по непонятной мне причине. Это может приводить к тому, что вы будете рвать TCP-соединения пользователей, идущих через вашу сеть. Поэтому я настоятельно рекомендую проверить настройки ваших маршрутизаторов в этом месте.
Так или иначе, мне кажется, что мы готовы перейти к экспериментам.
Когда мы включили flow label на ToR, подготовили eBPF агента, который теперь живет на хостах, мы решили не дожидаться следующего большого сбоя, а провести контролируемые взрывы. Мы взяли ToR, у которого четыре аплинка, и на одном из них устроили дропы. Нарисовали правило, сказали — теперь ты теряешь все пакеты. Как можно видеть слева, у нас per-packet monitoring, который просел до значения 75%, то есть 25% пакетов теряются. Справа графики сервисов, живущих за этим ToR. По сути это графики трафика стыков с серверами внутри стойки. Как можно видеть, они просели даже ниже. Почему они просели ниже — не на 25%, а в некоторых случаях в 3–4 раза? Если TCP-соединению не везет, оно продолжает пробовать достучаться через битый стык. Это усугубляется типовым поведением сервиса внутри ДЦ — на один запрос пользователя генерируется N запросов к внутренним сервисам, и ответ уйдет к пользователю, либо когда ответят все источники данных, либо когда сработает таймаут на уровне приложения, который еще должен быть настроен. То есть все весьма и весьма плохо.
Теперь тот же самый эксперимент, но с включенным значением flow label. Как можно видеть, слева наш пакетный мониторинг просел на те же самые 25%. Это абсолютно корректно, потому что он ничего не знает о ретрансмитах, он отправляет пакеты и просто считает отношение количества доставленных и потерянных пакетов.
А справа находится график сервисов. Вы здесь не найдете эффекта от проблемного стыка. Трафик за те самые миллисекунды перетек из проблемного участка в три оставшихся аплинка, не затронутых проблемой. Мы получили сеть, которая лечит себя сама.
Это мой последний слайд, время подвести итоги. Теперь, я надеюсь, вы знаете, как строить сеть дата-центра, способную к самолечению. Вам не нужно будет ходить по архиву ядра Linux и выискивать там специальные патчи, вы знаете, что Flow label в данном случае решает проблему, но подходить к этому механизму нужно осторожно. И я еще раз подчеркиваю, что если вы оператор связи, вы не должны использовать flow label в качестве хеш-функции, иначе вы будете рвать сессии ваших пользователей.
У сетевых инженеров должен произойти концептуальный сдвиг: сеть начинается не с ToR, не с сетевого устройства, а с хоста. Достаточно яркий пример — то, как мы используем eBPF и для изменения RTO, и для фиксации flow label в сторону anycast-сервисов.
Механика flow label, безусловно, подходит и для других применений внутри контролируемого административного сегмента. Это может быть трафик между дата-центрами, а можно особым способом использовать такую механику и для управления исходящим трафиком. Но об этом я расскажу, надеюсь, в следующий раз. Спасибо большое за внимание.

alex_www
Один из «кратких» отвтов почему нужен IPv6