
У меня сегодня формат похожий на «читаем статьи за вас» от ODS, только я взяла несколько связанных.
Отправной точкой служит статья под названием “Searching Central Difference Convolutional Networks for Face Anti-Spoofing” (2020 г) и мое желание посмотреть немного вглубь на историю методов, в ней использованных.
Я пройдусь по исходному тексту, изложу алгоритмы, углубляясь по ходу в упоминаемые темы.

Может быть, получилось слишком подробно – формат экспериментальный. Можно писать свои замечания, я их обязательно учту в будущем.
Сама я face anti-spoofing не занимаюсь, но экспериментировала с альтернативами стандартных сверток для других CV-задач (впрочем, об этом я пока не пишу, возможно напишу позже).
Ключевые слова/темы: Local Binary Patterns, Local Binary Convolution, Central Difference Convolution, DepthNet, Neural Architecture Search, Differentiable ARchiTecture Search, Multiscale Attention Fusion Module.
Задача верификации живого человека в системах распознавания лиц носит название face anti-spoofing (FAS) или liveness detection. Основные атаки на системы распознавания лиц – это 3D маски, фото-распечатки или видеозаписи. Предположительно их можно отличить по специфическим рисункам текстуры и шумов. Обычные свертки устроены так, что лучше подходят для нахождения семантических признаков: с увеличением глубины нейронной сети свертки неизбежно переходят от мелких элементов к более общим структурам и паттернам.
Было предложено использовать для антиспуфинга свертки на основе градиентов, которые лучше подходят для сохранения информации о текстуре изображения. Для этого авторы статьи предложили новый вид свертки: Central Difference Convolution (CDC).
Вдохновлен он оператором Local Binary Patterns, придуманным аж в 1996 г… Про него много и подробно рассказано, но я дам вводную здесь, потому что это важно для понимания последующего материала. LBP имеют много полезных приложений в тех задачах CV, где текстура оказывается важнее более крупной семантики. Это восстановление поврежденных фото и видео, анализ биомедицинских или аэрофотоснимков, распознавание отпечатков пальцев, и в антиспуфинге они также находили применение.
Суть в том, что изображение переводится в ч/б, а затем каждый пиксель сравнивается с его восемью соседями в окрестности какого-то размера, например 3х3, путем вычитания значения центрального пикселя. Результат вычитания кодируется 0, если полученное значение отрицательное (т.е. Если этот пиксель темнее центрального) и 1 в противном случае. Говорим, что последовательность 0 и 1 это просто двоичное число, которое кодирует центральный пиксель. Пройдясь так по всем пикселям получим LBP-представление исходного изображения.
Проблема в том, что такой оператор захватывает только очень мелкие текстуры, но радиус окружности можно расширить.

Оператор устойчив к изменению освещения, поскольку реагирует на производные яркости, а не на абсолютные значения, но чувствителен к поворотам паттерна, так как изменение последовательности бит меняет значение числа.
Вроде разобрались с Local Binary Patterns, приступим к Local Binary Convolution.
LBP — оператор простой и необучаемый, все его параметры (диаметр, шаг, порядок кодирования) выбираются эмпирически. К тому же, несмотря на желание использовать способность LBP к репрезентации паттернов, непонятно, как интегрировать этот оператор в нейросеть. К счастью, действие LBP можно смоделировать несколькими свертками. Действительно, LBP — это по сути функция разности, нелинейный активатор, а затем взвешенная сумма. Можно использовать восемь сверток c binary step функцией активации. После чего, чтобы смоделировать LBP, остаётся только взять взвешенную сумму, в которой все веса известны заранее – это степени двойки.

В формульном виде оно будет выглядеть как:

Назовем полученную конструкцию модулем LBCNN и посмотрим на неё подробнее. По сравнению с LBP изменена функция активации на ReLU или сигмоиду просто ради дифференцируемости, и веса финальной взвешенной суммы сделаны обучаемыми. Притом фильтры свертки остаются фиксированными. Взвешенную сумму можно реализовать как свертку размером 1x1.

Нейросеть с такими свертками работает сравнимо по качеству с обычной CNN, но значительно дешевле в плане вычислений. Стандартный сверхточный слой размером h x w имеет ((h * w * d)+1)* k) обучаемых параметров. У LBC обучаемых параметров m x q (в 1 x1 свертке), где m – количество промежуточных фильтров (8 в наших визуализированных примерах), а q – количество выходных каналов. Примерная экономия по параметрам в 9 раз по сравнению со стандартными свертками (3x3 conv).
Теперь переключимся на то, с чего начали: Central Difference Convolution (CDC).
Сформулируем простую известную нам свертку в таком формальном виде.
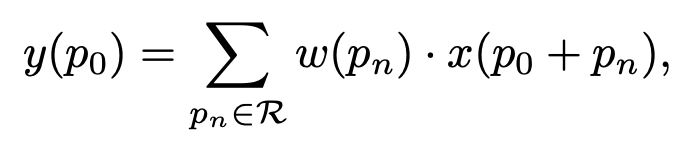
Где буквой p обозначается позиция текущего обрабатываемого пикселя. P_0 — это и позиция результирующей точки и одновременно центральной точки текущего receptive field. LBP вдохновляет на мысль вычесть значение центрального пикселя, впрочем, часть с обычной свёрткой тоже остается.

В чём отличие от LBCNN? LBC полностью заменяет обычную свертку более быстрой модификацией. CDC не заботится об ускорении обучения сети или ускорении инференса, но только о расширении возможностей стандартных сверток, потому содержит в себе как разностный компонент так и компонент идентичный обычной свертке.
Ниже на схеме представлена архитектура DepthNet, которую в сатье берут в качестве базовой, заменяя обычные свертки на CDC.

Выход сети — это одноканальная «картинка» размером 32х32 со значениями глубины (для входного изображения разрешением 256х256х3).
Статья про contrastive depth loss. Его подробный разбор оставлю за скобками (или до другого раза).
Попробуем расширить архитектуру CDCN с помощью NAS и Multiscale Attention Fusion Module (MAFM).
Neural Architecture Search (NAS) – это автоматический поиск/построение архитектур нейросетей. Такой поиск позволяет вычислить оптимальную архитектуру сети, однако вычислительно сложен и требует большого времени. Кроме того, поиск обычно осуществляется методами оптимизации черного ящика, что заставляет перебирать множество вариантов.
Метод под названием DARTS (Differentiable ARchiTecture Search) вместо поиска по дискретному набору архитектур использует непрерывное поле поиска, чтобы можно было оптимизироваться на нем градиентным спуском. Идея не нова, но от предыдущих работ есть отличия: предыдущие решения искали определенные аспекты архитектуры (форма фильтров, например), DARTS может осуществлять поиск в сложной топологии.
Задача формулируется как нахождение вычислительной ячейки (cell), которую в итоге или стакается со сверточной сетью или рекурсивно соединяется с рекуррентной. Ячейка – направленный ацикличный граф из N узлов (node). Каждый узел это латентное представление (feature map сверточной сети), а каждое ребро этого графа – некое преобразование латентного представления (операция над ним).
Считаем, что каждая ячейка имеет два входных и один выходной узел. Для сверточных ячеек входом будут выходы двух предыдущих слоев. Для рекуррентных это будет вход текущего шага и состояние, сохранённое с предыдущего.
В список операций добавляется вспомогательная «обнуляющая» операция, что позволяет просто соединить ребрами все узлы со всем. Каждый узел получается применением соответствующих операций ко всем предыдущим узлам и применении некой редукционной операции (например, конкатенации). Останется только для каждого ребра выбрать операцию из списка (convolution, max pooling, обнуление).
Чтобы сделать пространство поиска непрерывным будем не выбирать одну операцию, а возьмем взвешенную сумму из всех возможных, а веса пусть будут softmax-функцией. После оптимизации можно будет заменить взвешенную сумму на одну наиболее весомую операцию.
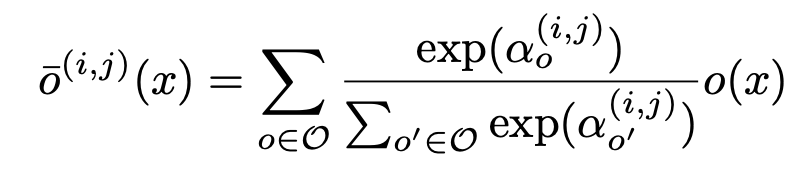
Для каждой конкретной архитектуры есть оптимальный набор весов (оптимальный с точки зрения минимизации ошибки на трейне). Задача выбрать такую архитектуру и соответствующей ей набор весов (оптимизированных на трейне), чтобы на валидационном наборе данных получить минимальную ошибку.
Такая штука носит название bilevel optimization problem – двухуровневая оптимизация, когда одна задача вложена в другую.
Оптимизируется это двухшаговым градиентным спуском, с поочередной оптимизацией параметров архитектуры (коэффициентов операций) и весов. Краткое изложение алгоритма на псевдокоде ниже, где дзета – learning rate внутренней оптимизации.

Впрочем, первый шаг может быть слишком дорогостоящим по вычислениям. Потому решение: делать по одному шагу без решения внутренней оптимизационной задачи до сходимости.

Теоретического обоснования сходимости такой схемы нет, но на практике при верном выборе learning rate значение функции потерь при обучении падает.
Познакомившись с Neural Architecture Search, вернемся к исходной задаче: мы хотим усложнить исходную сетку, взяв три ее уровня и каждый представив как ячейку с четырьмя узлами (плюс по одному входному и выходному).Найдем операции между ними с помощью NAS. В отличие от статьи выше здесь вход у каждой ячейки только один. В остальном же у нас та же схема: ориентированный граф узлов, набор операций, поиск их взвешенной суммы. Слои stem и head используют CDC с ядром 3?3 и ? = 0.7. Список операций состоит из восьми вариантов, где CDC_2_r означает использование двух CDC сверток, первая из которых увеличивает количество каналов в r раз, а вторая возвращает к исходному числу.

Второй используемый механизм — это Attention-стратегия, которая используется, чтобы определить веса промежуточных узлов. Выходной узел ячейки — это взвешенная сумма всех промежуточных узлов, где для ? опять же берется softmax функция.

Финальная дискретная архитектура после оптимизации тоже получается так же, как описано в статье выше. С коэффициентами attention в итоге поступаем так же.
Рассмотрим Multiscale Attention Fusion Module (MAFM) как еще один шаг по усложнению системы: объединим с помощью функции attention разные уровни (low-mid-high) нашей архитектуры
Механизм Attention (внимания) призван подсказывать сети, куда смотреть, но также и улучшать представление того, на чем фокусируется. Поскольку конволюция, извлекая признаки, смешивает канальную и пространственную информацию, мы применим модуль, чтобы выделить важное по этим двум направлениям отдельно (два отдельных модуля внимания еще и требует меньше дополнительных параметров и вычислений).
Модуль получается легким и широко применимым, при этом он заметно улучшает результаты по сравнению с обычными сверточными сетями.
Получая на вход feature map размерности C?H?W модуль производит C?1?1 карту внимания для каналов (Mc) и 1?H?W карту внимания для пространственных данных (Ms). Общий механизм работы внимания представлен на картинке (умножение поэлементное).

Channel attention module
Используются два дескриптора: max-pooling и average-pooling. Результаты дескрипторов подаются на общую MLP-сеть с одним скрытым слоем. Пропустив оба дескриптора через сеть мы поэлементно суммируем результаты. Схема выглядит так (где ? — сигмоида).

Spatial attention module
Применяем average-pooling и max-pooling вдоль оси каналов (получим размерность 1?H?W) и конкатенируем выходы для получения дескриптора, и затем применяем к нему свертку. Размер ядра свертки 7х7.

После этого краткого экскурса вернемся к исходному алгоритму. Здесь по сути используем тот же пространственный модуль внимания. Вот как это все выглядит в итоге.

A и M обозначают avg и max pool слои. Сигмоида – ?, а C – обозначает сверточный слой (с ядрами 7?7, 5?5 и 3?3 для low, mid и high уровней соответственно).
Собрав все части вместе, перейдем к тестированию.
Для экспериментальной оценки CDCN++ были взяты шесть датасетов: OULU-NPU, SiW, CASIA-MFSD, Replay-Attack, MSU-MFSD and SiW-M. Среди которых есть данные в высоком разрешении, разные типы атак и сложные условия такие как незнакомые источники освещения и фоны.
В наборе метрик есть обыкновенные Attack Presentation Classification Error Rate (APCER) и Bona Fide Presentation Classification Error Rate (BPCER), которые по сути есть False Positive Rate и False Negative Rate с разделением по определенному типу атаки (presentation attack instrument или PAI). Также equal error rate (EER) – точка пересечения графиков этих матрик, и AUC.
Одна из задач тестирования заключалась в том, чтобы выяснить, правда ли CDC в подобных задачах имеет преимущество по сравнению со стандартными свертками. Гипотеза гласит, что свертки на основе градиентов лучше способны уловить артефакты текстуры порожденные спуфингом. В тестах CDC сравнивалась как с ванильными свертками так и со своими аналогами: GaborConv и LBConv. По результатам CDC победила с большим отрывом: выигрыш составил больше 2% от ошибки по метрике ACER (от исходных 3.8% ACER для VanilaConv).
Следующим пунктом идет проверка NAS архитектуры, и ее влияния на результат. Использовался абляционный тест (с удалением компонент), где брались различные комбинации с вариацией ячеек и без, с модулем внимания и без. Результаты показывают, что обе эти модификации позволяют улучшить результат: с той же метрикой ACER получаем падение ошибки на 0.4% по сравнением с конфигурацией без вышеобозначенных улучшений.
Далее проводилось общее тестирование на OULU-NPU и SiW датасетах с соблюдением всех OULU-NPU протоколов
В результате на OULU-NPU при тестах по всем четырем протоколам CDCN++ занял первое место, что показывает результативность метода при разных видах атак. К тому же в отличии от других state-of-the-art методов (таких как STASN, GRADIANT и FAS-T) описанный здесь CDCN++ не требует сбора динамических данных из нескольких кадров, а работает на одном кадре. Аналогичные же результаты показывает тест на SiW датасете. Кроме того, была проведена cross-type и cross-dataset проверка, чтобы убедиться в обобщающей способности модели.
Несмотря на очевидное качество модели авторы планируют доработки модели такие как, например, контекстно-зависимые CDC-свертки. А также адаптацию модели к другим CV-задачам (например, оценка качества изображения).
Спасибо за внимание, надеюсь, было интересно!
Отправной точкой служит статья под названием “Searching Central Difference Convolutional Networks for Face Anti-Spoofing” (2020 г) и мое желание посмотреть немного вглубь на историю методов, в ней использованных.
Я пройдусь по исходному тексту, изложу алгоритмы, углубляясь по ходу в упоминаемые темы.
Может быть, получилось слишком подробно – формат экспериментальный. Можно писать свои замечания, я их обязательно учту в будущем.
Сама я face anti-spoofing не занимаюсь, но экспериментировала с альтернативами стандартных сверток для других CV-задач (впрочем, об этом я пока не пишу, возможно напишу позже).
Ключевые слова/темы: Local Binary Patterns, Local Binary Convolution, Central Difference Convolution, DepthNet, Neural Architecture Search, Differentiable ARchiTecture Search, Multiscale Attention Fusion Module.
Немного о задаче
Задача верификации живого человека в системах распознавания лиц носит название face anti-spoofing (FAS) или liveness detection. Основные атаки на системы распознавания лиц – это 3D маски, фото-распечатки или видеозаписи. Предположительно их можно отличить по специфическим рисункам текстуры и шумов. Обычные свертки устроены так, что лучше подходят для нахождения семантических признаков: с увеличением глубины нейронной сети свертки неизбежно переходят от мелких элементов к более общим структурам и паттернам.
Было предложено использовать для антиспуфинга свертки на основе градиентов, которые лучше подходят для сохранения информации о текстуре изображения. Для этого авторы статьи предложили новый вид свертки: Central Difference Convolution (CDC).
Local Binary Patterns
Вдохновлен он оператором Local Binary Patterns, придуманным аж в 1996 г… Про него много и подробно рассказано, но я дам вводную здесь, потому что это важно для понимания последующего материала. LBP имеют много полезных приложений в тех задачах CV, где текстура оказывается важнее более крупной семантики. Это восстановление поврежденных фото и видео, анализ биомедицинских или аэрофотоснимков, распознавание отпечатков пальцев, и в антиспуфинге они также находили применение.
Суть в том, что изображение переводится в ч/б, а затем каждый пиксель сравнивается с его восемью соседями в окрестности какого-то размера, например 3х3, путем вычитания значения центрального пикселя. Результат вычитания кодируется 0, если полученное значение отрицательное (т.е. Если этот пиксель темнее центрального) и 1 в противном случае. Говорим, что последовательность 0 и 1 это просто двоичное число, которое кодирует центральный пиксель. Пройдясь так по всем пикселям получим LBP-представление исходного изображения.
Проблема в том, что такой оператор захватывает только очень мелкие текстуры, но радиус окружности можно расширить.
Оператор устойчив к изменению освещения, поскольку реагирует на производные яркости, а не на абсолютные значения, но чувствителен к поворотам паттерна, так как изменение последовательности бит меняет значение числа.
Вроде разобрались с Local Binary Patterns, приступим к Local Binary Convolution.
LBP — оператор простой и необучаемый, все его параметры (диаметр, шаг, порядок кодирования) выбираются эмпирически. К тому же, несмотря на желание использовать способность LBP к репрезентации паттернов, непонятно, как интегрировать этот оператор в нейросеть. К счастью, действие LBP можно смоделировать несколькими свертками. Действительно, LBP — это по сути функция разности, нелинейный активатор, а затем взвешенная сумма. Можно использовать восемь сверток c binary step функцией активации. После чего, чтобы смоделировать LBP, остаётся только взять взвешенную сумму, в которой все веса известны заранее – это степени двойки.
В формульном виде оно будет выглядеть как:
Назовем полученную конструкцию модулем LBCNN и посмотрим на неё подробнее. По сравнению с LBP изменена функция активации на ReLU или сигмоиду просто ради дифференцируемости, и веса финальной взвешенной суммы сделаны обучаемыми. Притом фильтры свертки остаются фиксированными. Взвешенную сумму можно реализовать как свертку размером 1x1.
Нейросеть с такими свертками работает сравнимо по качеству с обычной CNN, но значительно дешевле в плане вычислений. Стандартный сверхточный слой размером h x w имеет ((h * w * d)+1)* k) обучаемых параметров. У LBC обучаемых параметров m x q (в 1 x1 свертке), где m – количество промежуточных фильтров (8 в наших визуализированных примерах), а q – количество выходных каналов. Примерная экономия по параметрам в 9 раз по сравнению со стандартными свертками (3x3 conv).
Central Difference Convolution (CDC)
Теперь переключимся на то, с чего начали: Central Difference Convolution (CDC).
Сформулируем простую известную нам свертку в таком формальном виде.
Где буквой p обозначается позиция текущего обрабатываемого пикселя. P_0 — это и позиция результирующей точки и одновременно центральной точки текущего receptive field. LBP вдохновляет на мысль вычесть значение центрального пикселя, впрочем, часть с обычной свёрткой тоже остается.
В чём отличие от LBCNN? LBC полностью заменяет обычную свертку более быстрой модификацией. CDC не заботится об ускорении обучения сети или ускорении инференса, но только о расширении возможностей стандартных сверток, потому содержит в себе как разностный компонент так и компонент идентичный обычной свертке.
Ниже на схеме представлена архитектура DepthNet, которую в сатье берут в качестве базовой, заменяя обычные свертки на CDC.
Выход сети — это одноканальная «картинка» размером 32х32 со значениями глубины (для входного изображения разрешением 256х256х3).
Статья про contrastive depth loss. Его подробный разбор оставлю за скобками (или до другого раза).
CDCN++
Попробуем расширить архитектуру CDCN с помощью NAS и Multiscale Attention Fusion Module (MAFM).
Differentiable ARchiTecture Search
Neural Architecture Search (NAS) – это автоматический поиск/построение архитектур нейросетей. Такой поиск позволяет вычислить оптимальную архитектуру сети, однако вычислительно сложен и требует большого времени. Кроме того, поиск обычно осуществляется методами оптимизации черного ящика, что заставляет перебирать множество вариантов.
Метод под названием DARTS (Differentiable ARchiTecture Search) вместо поиска по дискретному набору архитектур использует непрерывное поле поиска, чтобы можно было оптимизироваться на нем градиентным спуском. Идея не нова, но от предыдущих работ есть отличия: предыдущие решения искали определенные аспекты архитектуры (форма фильтров, например), DARTS может осуществлять поиск в сложной топологии.
Задача формулируется как нахождение вычислительной ячейки (cell), которую в итоге или стакается со сверточной сетью или рекурсивно соединяется с рекуррентной. Ячейка – направленный ацикличный граф из N узлов (node). Каждый узел это латентное представление (feature map сверточной сети), а каждое ребро этого графа – некое преобразование латентного представления (операция над ним).
Считаем, что каждая ячейка имеет два входных и один выходной узел. Для сверточных ячеек входом будут выходы двух предыдущих слоев. Для рекуррентных это будет вход текущего шага и состояние, сохранённое с предыдущего.
В список операций добавляется вспомогательная «обнуляющая» операция, что позволяет просто соединить ребрами все узлы со всем. Каждый узел получается применением соответствующих операций ко всем предыдущим узлам и применении некой редукционной операции (например, конкатенации). Останется только для каждого ребра выбрать операцию из списка (convolution, max pooling, обнуление).
Чтобы сделать пространство поиска непрерывным будем не выбирать одну операцию, а возьмем взвешенную сумму из всех возможных, а веса пусть будут softmax-функцией. После оптимизации можно будет заменить взвешенную сумму на одну наиболее весомую операцию.
Для каждой конкретной архитектуры есть оптимальный набор весов (оптимальный с точки зрения минимизации ошибки на трейне). Задача выбрать такую архитектуру и соответствующей ей набор весов (оптимизированных на трейне), чтобы на валидационном наборе данных получить минимальную ошибку.
Такая штука носит название bilevel optimization problem – двухуровневая оптимизация, когда одна задача вложена в другую.
Оптимизируется это двухшаговым градиентным спуском, с поочередной оптимизацией параметров архитектуры (коэффициентов операций) и весов. Краткое изложение алгоритма на псевдокоде ниже, где дзета – learning rate внутренней оптимизации.
Впрочем, первый шаг может быть слишком дорогостоящим по вычислениям. Потому решение: делать по одному шагу без решения внутренней оптимизационной задачи до сходимости.
Теоретического обоснования сходимости такой схемы нет, но на практике при верном выборе learning rate значение функции потерь при обучении падает.
Снова к CDCN++
Познакомившись с Neural Architecture Search, вернемся к исходной задаче: мы хотим усложнить исходную сетку, взяв три ее уровня и каждый представив как ячейку с четырьмя узлами (плюс по одному входному и выходному).Найдем операции между ними с помощью NAS. В отличие от статьи выше здесь вход у каждой ячейки только один. В остальном же у нас та же схема: ориентированный граф узлов, набор операций, поиск их взвешенной суммы. Слои stem и head используют CDC с ядром 3?3 и ? = 0.7. Список операций состоит из восьми вариантов, где CDC_2_r означает использование двух CDC сверток, первая из которых увеличивает количество каналов в r раз, а вторая возвращает к исходному числу.
Второй используемый механизм — это Attention-стратегия, которая используется, чтобы определить веса промежуточных узлов. Выходной узел ячейки — это взвешенная сумма всех промежуточных узлов, где для ? опять же берется softmax функция.
Финальная дискретная архитектура после оптимизации тоже получается так же, как описано в статье выше. С коэффициентами attention в итоге поступаем так же.
Рассмотрим Multiscale Attention Fusion Module (MAFM) как еще один шаг по усложнению системы: объединим с помощью функции attention разные уровни (low-mid-high) нашей архитектуры
Convolutional block attention module
Механизм Attention (внимания) призван подсказывать сети, куда смотреть, но также и улучшать представление того, на чем фокусируется. Поскольку конволюция, извлекая признаки, смешивает канальную и пространственную информацию, мы применим модуль, чтобы выделить важное по этим двум направлениям отдельно (два отдельных модуля внимания еще и требует меньше дополнительных параметров и вычислений).
Модуль получается легким и широко применимым, при этом он заметно улучшает результаты по сравнению с обычными сверточными сетями.
Получая на вход feature map размерности C?H?W модуль производит C?1?1 карту внимания для каналов (Mc) и 1?H?W карту внимания для пространственных данных (Ms). Общий механизм работы внимания представлен на картинке (умножение поэлементное).
Channel attention module
Используются два дескриптора: max-pooling и average-pooling. Результаты дескрипторов подаются на общую MLP-сеть с одним скрытым слоем. Пропустив оба дескриптора через сеть мы поэлементно суммируем результаты. Схема выглядит так (где ? — сигмоида).
Spatial attention module
Применяем average-pooling и max-pooling вдоль оси каналов (получим размерность 1?H?W) и конкатенируем выходы для получения дескриптора, и затем применяем к нему свертку. Размер ядра свертки 7х7.
И снова к CDCN++
После этого краткого экскурса вернемся к исходному алгоритму. Здесь по сути используем тот же пространственный модуль внимания. Вот как это все выглядит в итоге.
A и M обозначают avg и max pool слои. Сигмоида – ?, а C – обозначает сверточный слой (с ядрами 7?7, 5?5 и 3?3 для low, mid и high уровней соответственно).
Собрав все части вместе, перейдем к тестированию.
Экспериментальная проверка
Для экспериментальной оценки CDCN++ были взяты шесть датасетов: OULU-NPU, SiW, CASIA-MFSD, Replay-Attack, MSU-MFSD and SiW-M. Среди которых есть данные в высоком разрешении, разные типы атак и сложные условия такие как незнакомые источники освещения и фоны.
В наборе метрик есть обыкновенные Attack Presentation Classification Error Rate (APCER) и Bona Fide Presentation Classification Error Rate (BPCER), которые по сути есть False Positive Rate и False Negative Rate с разделением по определенному типу атаки (presentation attack instrument или PAI). Также equal error rate (EER) – точка пересечения графиков этих матрик, и AUC.
Одна из задач тестирования заключалась в том, чтобы выяснить, правда ли CDC в подобных задачах имеет преимущество по сравнению со стандартными свертками. Гипотеза гласит, что свертки на основе градиентов лучше способны уловить артефакты текстуры порожденные спуфингом. В тестах CDC сравнивалась как с ванильными свертками так и со своими аналогами: GaborConv и LBConv. По результатам CDC победила с большим отрывом: выигрыш составил больше 2% от ошибки по метрике ACER (от исходных 3.8% ACER для VanilaConv).
Следующим пунктом идет проверка NAS архитектуры, и ее влияния на результат. Использовался абляционный тест (с удалением компонент), где брались различные комбинации с вариацией ячеек и без, с модулем внимания и без. Результаты показывают, что обе эти модификации позволяют улучшить результат: с той же метрикой ACER получаем падение ошибки на 0.4% по сравнением с конфигурацией без вышеобозначенных улучшений.
Далее проводилось общее тестирование на OULU-NPU и SiW датасетах с соблюдением всех OULU-NPU протоколов
В результате на OULU-NPU при тестах по всем четырем протоколам CDCN++ занял первое место, что показывает результативность метода при разных видах атак. К тому же в отличии от других state-of-the-art методов (таких как STASN, GRADIANT и FAS-T) описанный здесь CDCN++ не требует сбора динамических данных из нескольких кадров, а работает на одном кадре. Аналогичные же результаты показывает тест на SiW датасете. Кроме того, была проведена cross-type и cross-dataset проверка, чтобы убедиться в обобщающей способности модели.
Несмотря на очевидное качество модели авторы планируют доработки модели такие как, например, контекстно-зависимые CDC-свертки. А также адаптацию модели к другим CV-задачам (например, оценка качества изображения).
Спасибо за внимание, надеюсь, было интересно!