
Подкасты – канал, который активно развивается весь 2020 год. Растет объем аудитории, да и самих подкастов становится все больше. При этом единого аудиторного измерителя слушателей не существует, да и вообще с измерениями этого канала дела обстоят не очень. При этом взаимный интерес подкастеров и рекламодателей довольно высокий.
Мы в dentsu придумали Podcaster – аналитический инструмент для измерения аудитории подкастов и планирования рекламы в них. О том, как мы начали собирать данные и решили проблему распознавания аудитории, с какими трудностями столкнулись и что из этого вышло, рассказываем в этой статье.

Сейчас планирование подкастов происходит на основе данных продавцов (студий или специализированных агентств), которые связываются с авторами подкастов и запрашивают описание слушателей. Сами подкастеры получают данные либо от платформы, на которой выложен подкаст, либо из внешней системы статистики. В таком подходе есть ряд ограничений:
Для того, чтобы планирование подкастов стало более умным, мы попробовали сформировать единую систему аналитики, которая основывалась бы на данных из списка существующих подкастов и базе слушающих эти подкасты пользователей, а также в ней появилась бы возможность определить пол и возраст этих самых слушателей.
Мы быстро поняли, что сами прослушивания с привязкой к пользователям получить мы не сможем. Но есть лайки/подписки на подкасты: подобная механика работает, например, в Instagram с блогерами, когда человек подписывается на блогера, чтобы видеть его новости. Мы предположили, что такая же история происходит и с подкастами – слушатели подписываются на любимые подкасты, чтобы они были в быстром доступе и можно было следить за новыми выпусками.
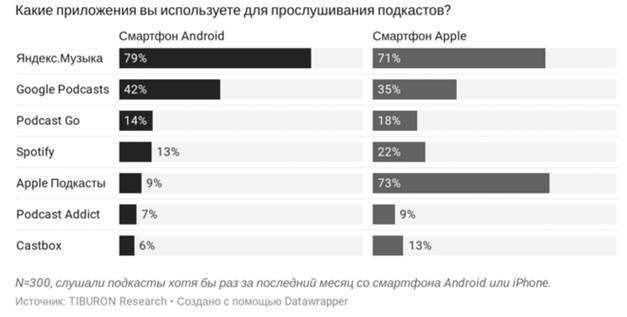
Проверить эту гипотезу мы решили с помощью популярной платформы, через которую аудитория слушает подкасты. Согласно данным Tiburon, лидером по прослушиваниям подкастов является Яндекс.Музыка.
К счастью, на Я.Музыке есть страница пользователя, на которой представлена информация о подписках на подкасты.
Пример профиля с фото и подписками на подкасты
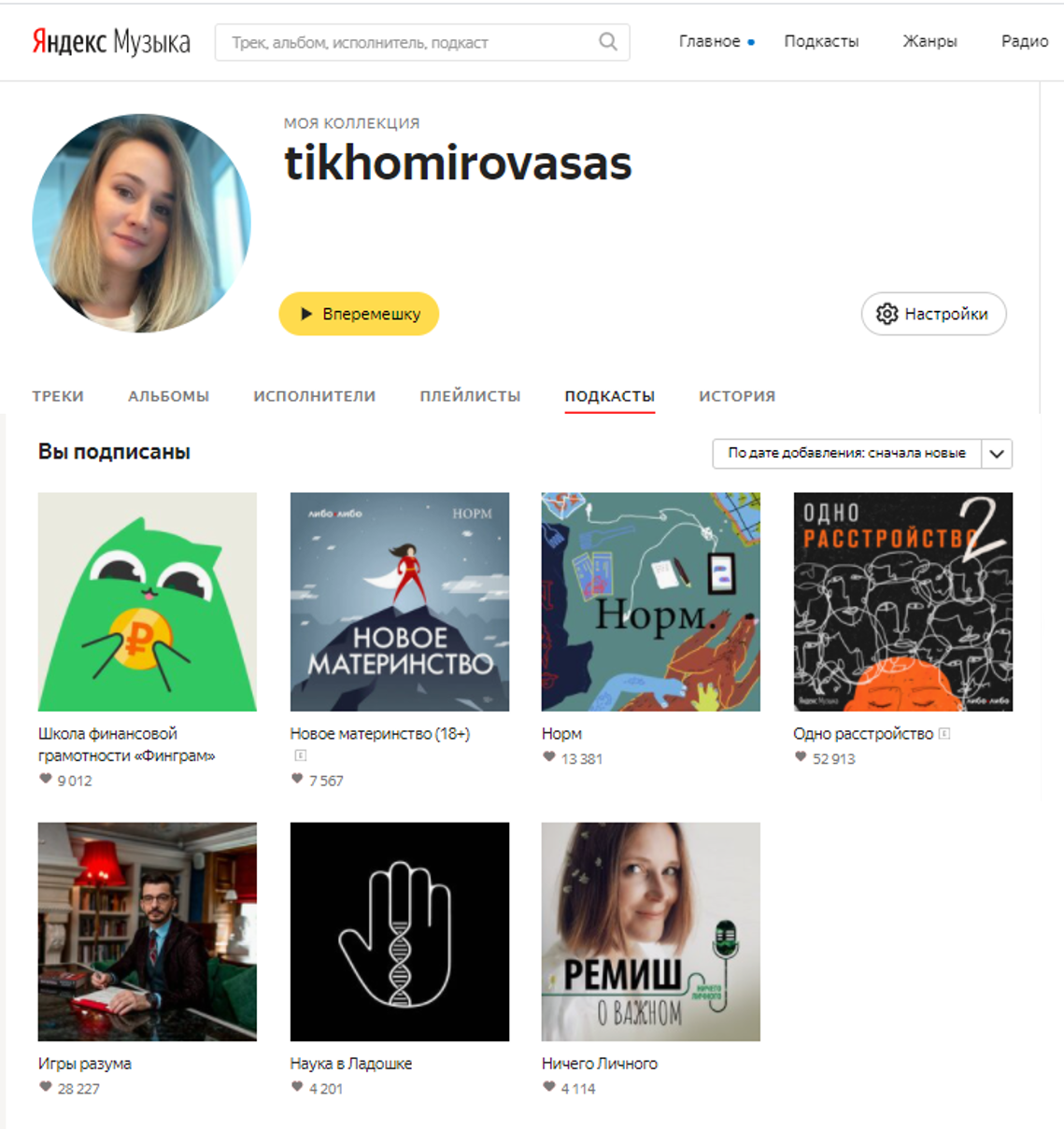
При этом помимо самой подписки в открытом доступе есть никнейм и аватар пользователя. Это уже что-то, так как по факту мы видим ядро слушателей подкастов, то есть тех, кто регулярно их слушает. Также здесь у нас есть та самая связка пользователь-подкаст, которую мы и хотели найти.
Мы начали собирать данные, а именно пользователей и подкасты, на которые слушатели подписаны. Изначально пользователей Я.Музыки с подкастами мы находили на данных сотрудников dentsu, которые предоставили свои почтовые ящики на Яндексе. Масштабировать проект не составило труда, так как мы не первый год работали с публичными данными.
Хорошая новость заключалась в том, что база подписанных на подкасты пользователей собиралась очень быстро – буквально за полтора месяца мы набрали более 10 000 пользователей, которые подписаны хотя бы на один подкаст.
Но была и плохая новость – по фото и никнейму определить пол и возраст на глаз не всегда возможно, а точнее вообще невозможно. Нам же, чтобы можно было выбирать релевантные подкасты для разных аудиторий, без пола и возраста здесь никак не обойтись.
С данной задачей определения пола и возраста по фотографии отлично справилась наша нейросеть, точность которой составляет 96%. Алгоритм простой: берем фотографию пользователя Я.Музыки, ищем лицо и по нему определяем пол и возраст.
Лицо находится библиотекой face-recognition, использующей dlib. А в основе нашей нейросети лежит предобученная модель VGGFace на базе архитектуры ResNet-50, которую мы дообучали на фотографиях пользователей VK, доступных по публичному API. Датасет состоит из миллиона фотографий, которые дополнительно аугменировались через albumentations. Следует отметить, что для обучения мы не рассматриваем фотографии пользователей до 12 и после 65 лет.
После обучения мы поняли, что примерно у 45% профилей пользователей с подкастами мы можем определить пол и возраст, так как много профилей без фото или картинкой, символом или просто с фотографией плохого качества. Но даже такой результат нас устраивает.
С учетом динамики нахождения профилей, которые подписываются на подкасты, мы ожидаем, что через несколько месяцев база слушателей составит 50 000 профилей, а у 22 500 из них мы будем знать пол и возраст.
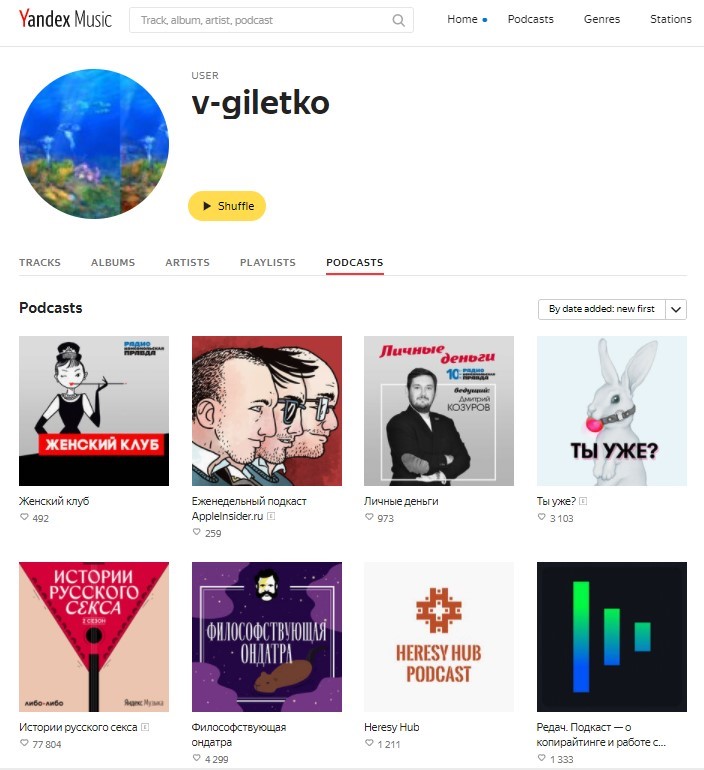
Пример профиля, по которому мы не можем определить пол и возраст
Текущие наработки позволяют нам делать выборки аффинитивных подкастов для различных аудиторных групп.
Подборка подкастов на 20-50 в тематиках, которые релевантны бренду

Affinity = ЦА среди слушателей подкаста / все слушатели подкаста) / (все слушатели подкаста / все люди с подкастами)
Также мы можем анализировать конкретный подкаст, если он интересует рекламодателя.
За счет того, что мы видим сколько людей подписаны на подкасты, мы можем давать рекомендации по пакету подкастов, которые будут строить наибольший охват.
Кривая построения охвата на 50 выбранных подкастах
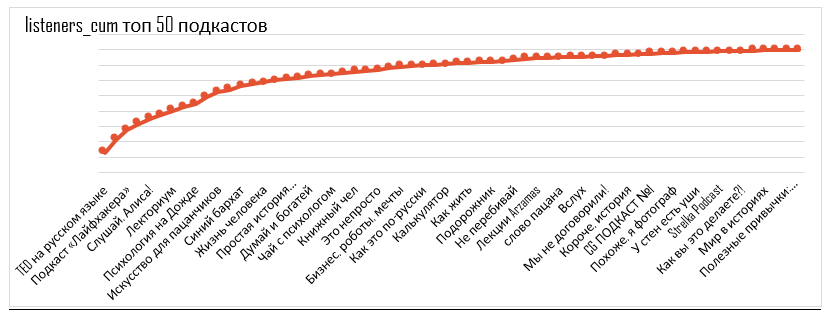
Каждая точка +1 подкаст в микс. Первая точка – подкаст с наибольшей уникальной аудиторией, последняя точка – подкаст с наименьшей уникальной аудиторией.
Сначала берем тот подкаст, у которого аудитория больше, в нашем случае это подкаст 3. Ниже представлена табличка, в которой раскрыта логика перебора, то есть принцип распределения соглашателей по подкастам.

Далее мы вычеркиваем слушателей, которых охватываем подкастом 3, и опять выбираем тот подкаст, у которого уникальной аудитории больше всего (подкаст 4). Это подкаст, который дает нам 2 новых уникальных слушателя, поэтому следующим мы рекомендуем к размещению именно его.

Проделываем упражнение еще раз, и оказывается, что больше уникальных слушателей мы не охватим, то есть размещение в 2 подкастах из 6 достаточно, чтобы охватить всю возможную уникальную аудиторию.

Мы ответили не на все вопросы, поэтому продолжаем искать данные. Например, недавно Я.Музыка начала публиковать информацию о количестве подписанной аудитории на каждый из подкастов. Теперь мы понимаем объём собранных слушателей от тотального.
Мы работаем над механикой объединения данных о подписках с данными от площадок и подкастеров, чтобы уточнить модель оценки количества и состава слушателей. Но уже сейчас наш подход помогает менять схему планирования рекламных интеграций в подкасты и исходить не из агрегированных данных продавцов или интуиции рекламодателей по поводу аудитории подкаста, а из аудитории бренда. А также составлять пакеты подкастов, релевантных именно для этой аудитории бренда и строящих максимальный для нее охват.
Автор Sasha_Kopylova
Мы в dentsu придумали Podcaster – аналитический инструмент для измерения аудитории подкастов и планирования рекламы в них. О том, как мы начали собирать данные и решили проблему распознавания аудитории, с какими трудностями столкнулись и что из этого вышло, рассказываем в этой статье.
Предыстория
Сейчас планирование подкастов происходит на основе данных продавцов (студий или специализированных агентств), которые связываются с авторами подкастов и запрашивают описание слушателей. Сами подкастеры получают данные либо от платформы, на которой выложен подкаст, либо из внешней системы статистики. В таком подходе есть ряд ограничений:
- подкасты можно выбрать из лимитированного списка, с которыми у продавца есть договоренности и есть данные по аудитории подкаста;
- нет возможности выбрать более аффинитивные подкасты (аффинитивность – отношение заданной ЦА среди слушателей ко всем слушателям подкаста), потому что, как правило, доступно описание ядра слушателей, а оно в целом одинаковое с точки зрения возраста для большинства подкастов;
- данные по каждому подкасту есть у самих подкастеров, но как пересекаются слушатели между подкастами не знают ни сами подкастеры, ни продавцы.
Для того, чтобы планирование подкастов стало более умным, мы попробовали сформировать единую систему аналитики, которая основывалась бы на данных из списка существующих подкастов и базе слушающих эти подкасты пользователей, а также в ней появилась бы возможность определить пол и возраст этих самых слушателей.
Подход
Мы быстро поняли, что сами прослушивания с привязкой к пользователям получить мы не сможем. Но есть лайки/подписки на подкасты: подобная механика работает, например, в Instagram с блогерами, когда человек подписывается на блогера, чтобы видеть его новости. Мы предположили, что такая же история происходит и с подкастами – слушатели подписываются на любимые подкасты, чтобы они были в быстром доступе и можно было следить за новыми выпусками.
Проверить эту гипотезу мы решили с помощью популярной платформы, через которую аудитория слушает подкасты. Согласно данным Tiburon, лидером по прослушиваниям подкастов является Яндекс.Музыка.
К счастью, на Я.Музыке есть страница пользователя, на которой представлена информация о подписках на подкасты.
Пример профиля с фото и подписками на подкасты
При этом помимо самой подписки в открытом доступе есть никнейм и аватар пользователя. Это уже что-то, так как по факту мы видим ядро слушателей подкастов, то есть тех, кто регулярно их слушает. Также здесь у нас есть та самая связка пользователь-подкаст, которую мы и хотели найти.
Механика
Мы начали собирать данные, а именно пользователей и подкасты, на которые слушатели подписаны. Изначально пользователей Я.Музыки с подкастами мы находили на данных сотрудников dentsu, которые предоставили свои почтовые ящики на Яндексе. Масштабировать проект не составило труда, так как мы не первый год работали с публичными данными.
Хорошая новость заключалась в том, что база подписанных на подкасты пользователей собиралась очень быстро – буквально за полтора месяца мы набрали более 10 000 пользователей, которые подписаны хотя бы на один подкаст.
Но была и плохая новость – по фото и никнейму определить пол и возраст на глаз не всегда возможно, а точнее вообще невозможно. Нам же, чтобы можно было выбирать релевантные подкасты для разных аудиторий, без пола и возраста здесь никак не обойтись.
С данной задачей определения пола и возраста по фотографии отлично справилась наша нейросеть, точность которой составляет 96%. Алгоритм простой: берем фотографию пользователя Я.Музыки, ищем лицо и по нему определяем пол и возраст.
Лицо находится библиотекой face-recognition, использующей dlib. А в основе нашей нейросети лежит предобученная модель VGGFace на базе архитектуры ResNet-50, которую мы дообучали на фотографиях пользователей VK, доступных по публичному API. Датасет состоит из миллиона фотографий, которые дополнительно аугменировались через albumentations. Следует отметить, что для обучения мы не рассматриваем фотографии пользователей до 12 и после 65 лет.
Результаты
После обучения мы поняли, что примерно у 45% профилей пользователей с подкастами мы можем определить пол и возраст, так как много профилей без фото или картинкой, символом или просто с фотографией плохого качества. Но даже такой результат нас устраивает.
С учетом динамики нахождения профилей, которые подписываются на подкасты, мы ожидаем, что через несколько месяцев база слушателей составит 50 000 профилей, а у 22 500 из них мы будем знать пол и возраст.
Пример профиля, по которому мы не можем определить пол и возраст
Текущие наработки позволяют нам делать выборки аффинитивных подкастов для различных аудиторных групп.
Подборка подкастов на 20-50 в тематиках, которые релевантны бренду
Affinity = ЦА среди слушателей подкаста / все слушатели подкаста) / (все слушатели подкаста / все люди с подкастами)
Также мы можем анализировать конкретный подкаст, если он интересует рекламодателя.
За счет того, что мы видим сколько людей подписаны на подкасты, мы можем давать рекомендации по пакету подкастов, которые будут строить наибольший охват.
Кривая построения охвата на 50 выбранных подкастах
Каждая точка +1 подкаст в микс. Первая точка – подкаст с наибольшей уникальной аудиторией, последняя точка – подкаст с наименьшей уникальной аудиторией.
Механика построения кривой и математическая модель
Сначала берем тот подкаст, у которого аудитория больше, в нашем случае это подкаст 3. Ниже представлена табличка, в которой раскрыта логика перебора, то есть принцип распределения соглашателей по подкастам.
Далее мы вычеркиваем слушателей, которых охватываем подкастом 3, и опять выбираем тот подкаст, у которого уникальной аудитории больше всего (подкаст 4). Это подкаст, который дает нам 2 новых уникальных слушателя, поэтому следующим мы рекомендуем к размещению именно его.
Проделываем упражнение еще раз, и оказывается, что больше уникальных слушателей мы не охватим, то есть размещение в 2 подкастах из 6 достаточно, чтобы охватить всю возможную уникальную аудиторию.
Выводы
Мы ответили не на все вопросы, поэтому продолжаем искать данные. Например, недавно Я.Музыка начала публиковать информацию о количестве подписанной аудитории на каждый из подкастов. Теперь мы понимаем объём собранных слушателей от тотального.
Мы работаем над механикой объединения данных о подписках с данными от площадок и подкастеров, чтобы уточнить модель оценки количества и состава слушателей. Но уже сейчас наш подход помогает менять схему планирования рекламных интеграций в подкасты и исходить не из агрегированных данных продавцов или интуиции рекламодателей по поводу аудитории подкаста, а из аудитории бренда. А также составлять пакеты подкастов, релевантных именно для этой аудитории бренда и строящих максимальный для нее охват.
Автор Sasha_Kopylova
Loxmatiymamont
Делать далеко идущие выводы по яндекс подкастам это хорошо, но есть проблема:

Sasha_Kopylova
Добрый день! а подскажите, пожалуйста, откуда такие данные?
Loxmatiymamont
С подтрека.
Sasha_Kopylova
Я же правильно понимаю, что в браузере человек может слушат через любое приложение и в подтрек этого не видит, а адутория слушает подкасты через ЯМузыка или Castbox, например?
Последне исследования Tiburon по ссылке ниже, в нем указано, что 70% аудитории слушает подкасты на смартфонах Android, где ЯМузыка является лидером.
tiburon-research.ru/cases/issledovanie-podkasty-auditoriya-reytingi-podkastov-i-podkasterov
Loxmatiymamont
Самое удивительное, что больше всего люди слушают подкасты на ютубе. Вот и живите с этим )))))
Loxmatiymamont
Я, конечно, не сомневаюсь в квалификации господ с тибурона, однако они свалили в общую кучу и подкасты, и подборки музыки от радиостанций, и всё остальное. А статистику свою получали путем опроса.
С таким подходом можно было и просто любых цифр написать.