
Привет, Хабр! Меня зовут Владислав Абрамов, я аналитик в компании Easy Commerce. Перед нами стояла задача создать алгоритм, который определяет влияние характеристик карточки товара на поисковую позицию в крупнейших российских маркетплейсах. Большинство из них не раскрывают принципы ранжирования — эту проблему нужно было решить с помощью анализа открытых данных. В этой статье расскажу, как мы прошли этот путь и проверили, что решение действительно работает.
Контекст
Продавцы соревнуются за верхние позиции в поисковой выдаче маркетплейсов. Чем выше расположена карточка, тем она заметнее и выше вероятность конверсии в покупку. Одни онлайн-ритейлеры поднимают карточку за работу с отзывами, другие предпочитают товары со скидкой, — но практически никто из них не раскрывает принцип работы своего рекомендательного алгоритма.
Компании справляются с этой неопределенностью по-разному: инвестируют огромные бюджеты в продвижение на марктеплейсах или выкупают свои же товары, чтобы отследить работу алгоритмов.
Мы пошли по другому пути: проанализировали влияние характеристик карточки на позицию в поиске методом реверсивной инженерии на основе открытых данных. Это помогло определить основные точки, на которые опираются алгоритмы ранжирования крупнейших российских торговых площадок.
Ниже разберем решение по шагам, а в конце верифицируем результат его работы на данных Ozon. Это единственный ритейлер на рынке, который в документации кратко раскрывает большинство принципов сортировки.
Стек
Прежде, чем начать, расскажем о технологиях, которые использовались в проекте. Анализ и построение модели производятся на вычислительных кластерах YandexCloud с использованием параллелизации. Поскольку категорий и маркетов достаточно много, а массивы данных огромны, мы приняли решение запускать процесс сразу на нескольких дублирующих друг друга машинах с большим запасом ОЗУ и потоков CPU (128 gb и 32 потока соответственно), тем самым сильно ускорив процесс получения коэффициентов.
Чтобы мониторить корректность работы подхода, мы настроили сохранение промежуточных файлов и логов в облачное хранилище AWS S3. Это позволяет видеть результаты отработки этапов в процессе обучения, отслеживать ошибки и аномалии. Также, для таких случаев, когда одна из машин падает, или возникает критическая ошибка в работе пайплайна настроена система алертов на базе Telegram-бота.
Анализ
Кластеризация и сегментация
В этом проекте мы пошли по пути сегментации: это позволило разбить товарные карточки на группы, которые, в свою очередь, разделены на сегменты. Внутри каждого из них находятся наиболее схожие по структуре сущности товаров, а сами кластеры явно различимы — то есть векторное расстояние между их центроидами достаточно велико.
Перед кластеризацией данные прошли предобработку: скалирование, минимизацию выбросов и нормализацию распределения.


Для каждой характеристики — например, «количество отзывов» или «глубина скидки» — строится отдельная модель сегментации. Это помогает зафиксировать группы карточек, схожих по параметрам, отличным от поисковой позиции.
Для сегментации использовались классические алгоритмы: DBSCAN, иерархическая кластеризация и k-means. В этом проекте лучше всего показал себя k-means, который в среднем выделял 8-9 кластеров по каждой группе. После группировки в каждый кластер возвращалась исключенная характеристика и строилась регрессионная модель, где целевой переменной был ранг в поисковой выдаче.
")
Регрессионная модель в данном случае помогает определить бета-коэффициент исследуемой характеристики и его степень значимости (p-value). С помощью t-теста, который оценивает степень отличия коэффициента бета от нуля, считается уверенность в значимости характеристики карточки на маркетплейсе. И, как следствие, в значении корреляции.
Бета-коэффициент показывает, как увеличится целевая переменная при изменении изучаемого параметра на единицу при условии, что остальные характеристики остаются константными. Для поиска более правдоподобных значений проводится семплирование через Bootstrap, а затем вычисление бета и p-value для каждой из 1000 выборок. Это позволило получить не зависящие от шума значения. Определение коэффициента статистической значимости p-value для проведения последующего t-test в нашем случае выглядит так:

Корреляции
Кластеры сформированы, регрессии построены, — пришло время поговорить о корреляции. Для исследования мы взяли две базовые метрики, Pearson и Spearman, которые нужны для определение линейных взаимосвязей, и Phi-k, — сравнительно новую метрику, которая позволяет обнаружить нелинейные зависимости и найти корреляции между категорийными и численными переменными.
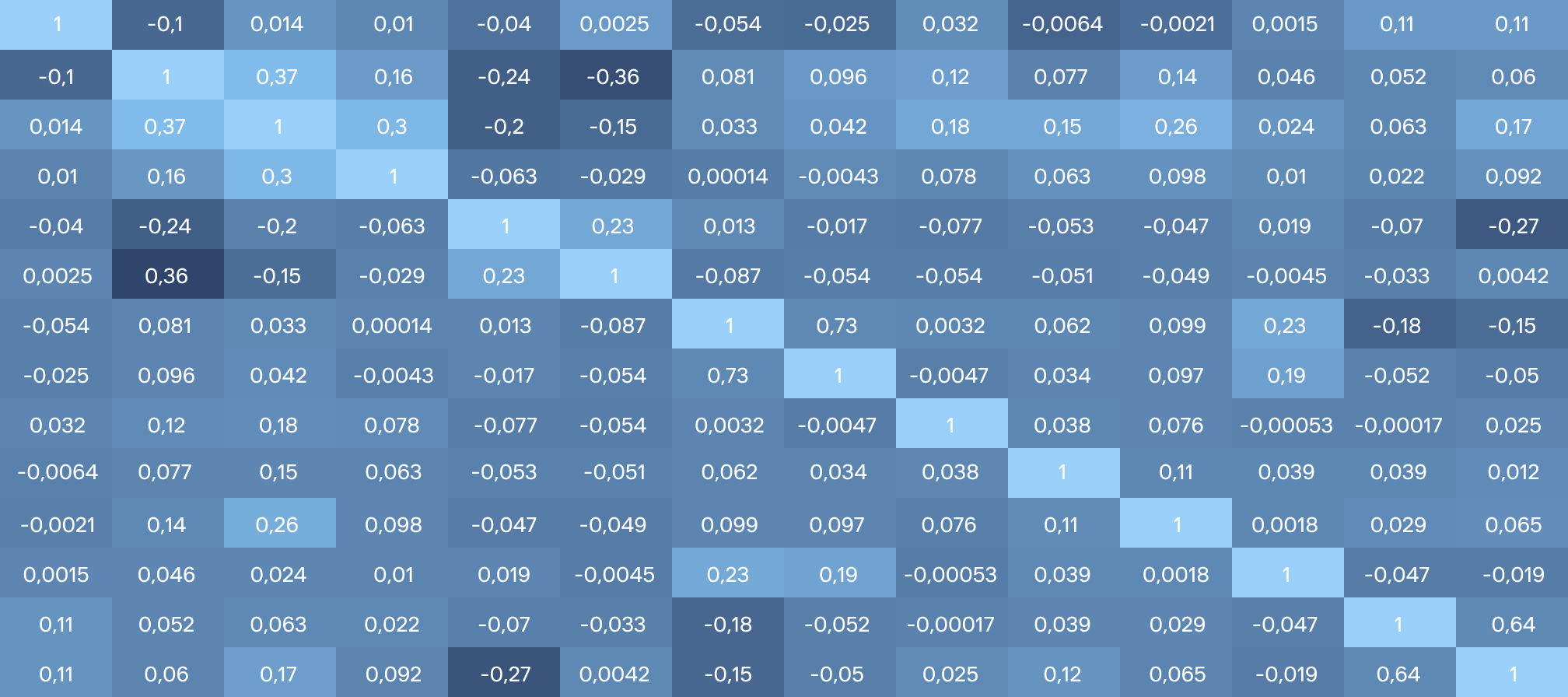
Метрики считаются отдельно для каждого кластера, а затем усредняются на всю категорию товаров. Чтобы проверить результат, мы посчитали корреляции на всю категорию товара без дробления на сегменты. По каждой категории рассчитывается сводная таблица значений корреляций двух типов: усредненных и обобщенных.

Корреляционная матрица используемых для анализа факторов Во время исследования мы также хотели проверить гипотезу, могут ли отличаться веса характеристик карточек от категории к категории. Например, фармацевтические товары или корма для домашних животных. Анализ показал, что существенных статистически значимых различий нет. Таким образом, можно провести повторную кластеризацию товарных карточек на всем маркетплейсе сразу, без дробления на категории, или усреднить значения корреляций всех полученных кластеров. Мы сделали ставку на второй способ, поскольку сочли его более чувствительным к микро-трендам внутри категорий и категорийных кластеров.
Тестирование
Для того, чтобы проверить достоверность анализа и полученных весов, мы сверили результаты с факторами ранжирования из официальной документации Ozon. Для сравнения были выбраны методы бустинга и дебустинга.
Для того, чтобы достичь наиболее близких коэффициентов, часть переменных, предоставляемых модели, пришлось пересчитать. Например, Ozon практикует необычную методику получения скидки, где разница считается между актуальной и средней ценой за последние 30 дней, вместо моментальной (цена сегодня относительно цены вчера). За каждый 1% изменения цены, как в сторону понижения, так и повышения, позиция набирает дополнительные 0.2 стимулирующих или штрафующих пункта. Так маркетплейс нивелирует ценовые спекуляции игроков на площадке.
Поскольку зависимость между изменением цены и поисковой позицией нелинейна, коэффициента корреляции Phi-k подходит лучше. Важно отметить, что анализ строится только на открытых данных о товаре: его цене, отзывах и других характеристиках. Популярность товара в количестве кликов и добавлений в корзину, количества продаж и скорости доставки узнать невозможно. Кроме того, платформы скрывают информацию о рекламном продвижении товаров.
Расчет весов производится так: каждая величина, которая трансформировалась в процентное значение, пропорциональное доли собственной корреляции от суммарной, описываемой всеми характеристиками сразу. Результат не в точности равен представленным Ozon весам, однако их отношения между собой и порядок значимости соответствуют заявленным в документации.
Таблица сравнения выглядит так:
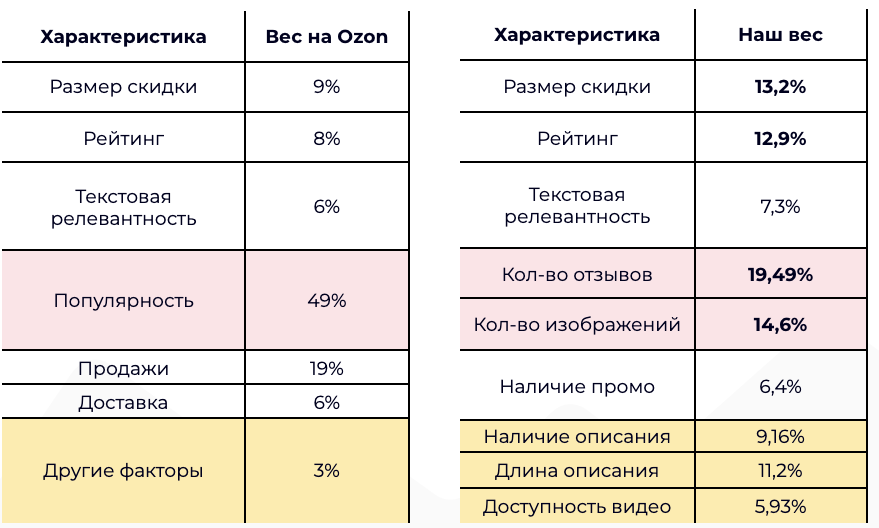

Убедившись, что модель показывает достоверные результаты по весам на одном маркетплейсе, мы протестировали ее на других крупных площадках: Wildberries, Яндекс.Маркете и Сбермегамаркете. Тестирование показало, что в условиях ограниченных ресурсов модель может выделить ряд ключевых факторов для платформы и конкретной категории, которые позволяют быстро вывести карточку в топ выдачи.
Для каждой категории на каждом маркетплейсе строится своя модель K средних:

Заключение
Как было сказано выше, грамотное наполнение продуктовых карточек улучшает видимость на площадке, а значит, и вероятность открытия карточки и последующей конверсии в покупку.
Результаты анализа позволяют понять, какие характеристики карточки нужно исправить в первую очередь, чтобы видимость бренда на каждой площадке выросла.
Технология входит в состав инструмента Commerce Analytics Tool, который мониторит различные метрики по 110 оналайн платформам. Если у вас появились вопросы о работе решения с технической или продуктовой точки зрения, пишите @vavAbramov, в комментариях или на почту ecombrief@easycomm.ru c пометкой «я с Хабра».
Комментарии (5)

Oksenija
27.10.2023 13:17+1получается - скидки - рэйтинг - ревью? Но вроде это не очень оригинально... а вот что-то удивительное или неожиданное вам удалось обнаружить? И кажется сам подход при ограниченных данных не совсем... И как вм удалось спарсить весь озон?

Robastik
27.10.2023 13:17удивительное или неожиданное
Самое удивительное и неожиданное, что кого-то могут интересовать такие результаты, хотя довольно очевидно, что хорошо надо делать всё, а не только то, что показала какая-то модель.

Awesomelizabeth
27.10.2023 13:17Интересное исследование, а применяете ли вы его каким-либо образом в САТ?

NataliaKr
27.10.2023 13:17Интересный подход!) Можно теперь эффективно оптимизировать бюджеты для продвижения карточек)
Sasha_Kopylova
Очень круто!