

Пару дней назад мы подводили ИИ итоги 2020-го года в мире машинного обучения. 2021-й год только начался, но мы определенно видим одну из важнейших работ в области ИИ текущего года.
Итак, исследователи в области искусственного интеллекта из openai создали нейронную сеть под названием DALL·E, которая генерирует изображения из текстового описания на естественном языке.
Если тебе интересно машинное обучение, то приглашаю в «Мишин Лернинг» — мой субъективный телеграм-канал об искусстве глубокого обучения, нейронных сетях и новостях из мира искусственного интеллекта.
DALL·E представляет собой версию GPT-3 с 12 миллиардами параметров, обученную генерировать изображения из текстовых описаний на датасете из пар текст-изображение. Исследователи обнаружили, что DALL·E обладает огромным репертуаром генеративных возможностей, включая возможность создания антропоморфных животных и других необычных объектов, комбинирующих совершенно нетривиальные свойства, например "кресло в форме авокадо."

Можно сказать, что уже были все предпосылки к созданию DALL·E: прошлогодний триумф GPT-3 и успешное создание Image GPT сети, способной к генерации изображений на основе текста, использующей языковую модель трансформер GPT-2. Все уже подходило к тому, чтобы создать новую модель, взяв в этот раз за основу GPT-3. И теперь DALL·E показывает невиданные доселе чудеса манипулирования визуальными концепциями с помощью естественного языка!
Как и GPT-3, DALL·E — это языковая модель-трансформер, принимающая на вход текст и изображение, как последовательность размером до 1280 токенов. Модель обучена максимизировать правдоподобие при генерации токенов, следующих один за другим.
Также, сотрудники из openai выразили озадаченность тем, что уровень реалистичности и результаты работы современных генеративных моделей могут оказать сильное влияние на общество. И опасаются за возможные неоднозначные социальные и экономические последствия использования подобных технологий.
Давайте посмотрим на примеры, которые говорят сами за себя. Исследователи утверждают, что не использовали ручной "cherry picking". Примерами являются изображения, полученные при помощи DALL·E, в которых используются 32 лучших примера из 512-ти сгенерированных, отобранных созданным ранее (теми же openai) нейронным ранжированием CLIP.
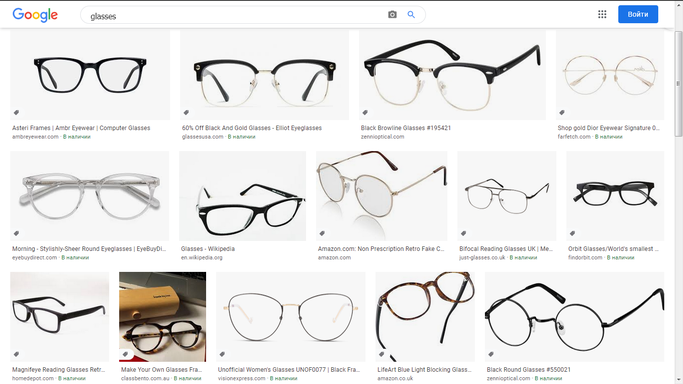
Text: a collection of glasses sitting on the table

Забавно, что алгоритм способен к мультимодальности, и справляется с неоднозначностью слова glasses в английском языке.
Text: an emoji of a baby penguin wearing a blue hat, red gloves, green shirt, and yellow pants


DALL·E может не только генерировать изображение с нуля, но и регенерировать (достраивать) любую прямоугольную область существующего изображения, вплоть до нижнего правого угла изображения, в соответствии с текстовым описанием. В качестве примера за основу взяли верхнюю часть фотографии бюста Гомера. Модель принимает на вход это изображение и текст: a photograph of a bust of homer
Text: a photograph of a bust of homer

Особенно поражает то, что DALL·E выучил исторический и географический контекст. Модель способна к обобщению тенденций в дизайне и технологиях. Вот пример того, как DALL·E генерирует телефонные аппараты разных десятилетий двадцатого века.
Text: a photo of phone from the ...

DALL·E попросили сгенерировать изображение по следующему описанию: "гостиная с двумя белыми креслами и картиной Колизея, картина установлена ??над современным камином". Как оказалось DALL·E может создавать картины на самые разные темы, включая реальные локации, такие как «Колизей», и вымышленных персонажей, таких как «йода». Для каждого объекта DALL·E предлагает множество вариантов. В то время как картина почти всегда присутствует на изображении, DALL·E иногда не может нарисовать камин или правильное количество кресел.
Text: a living room with two white armchairs and painting of the colosseum. the painting is mounted above a modern fireplace

Название модели DALL·E (DALL-E, DALL E) является словослиянием имени художника Сальвадора Дали и робота WALL·E от Pixar. Вышел такой своеобразный Вали-Дали. Вообще в мире ИИ "придумывание" таких оригинальных названий — это некий тренд. Что определенно радует, и делает эту область еще более оригинальной.

Для пущего сюрреализма и оправдания своего названия DALL·E "попросили" сгенерировать животных, синтезированных из множества понятий, включая музыкальные инструменты, продукты питания и предметы домашнего обихода. Хотя это не всегда удавалось, исследователи обнаруживали, что DALL·E иногда принимает во внимание формы двух объектов при решении о том, как их объединить. Например, когда предлагается нарисовать «улитку-арфу».
Text: a snail made of harp

Вывод
DALL·E — это декодер-трансформер, который принимает и текст, и изображение в виде единой последовательности токенов (1280 токенов = 256 для текста + 1024 для изображения) и далее генерирует изображения авторегрессивном режиме. По-видимому, авторегрессивный режим работы трансформера создает дискретную репрезентацию в разрешении 32х32, после чего VQVAE предобученный энкодер-декодер "завершает генерацию" до разрешения 256x256. Оговорюсь, что последнее предложение — это мое предположение, нужно подождать выхода самого пейпера.
Что можно сказать? Наступает эра "великого объединения" языковых моделей, компьютерного зрения и генеративных сетей. То что мы видим сейчас, уже поражает воображение своими результатами, не говоря уже о том, насколько подобные подходы могут изменить процесс генерации контента.
Как будет возможность, подготовлю уже технический разбор самой модели DALL·E, учитывая, что ребята из openai обещают предоставить более подробную информацию об архитектуре и обучении модели в ближайшее время.
Что ты думаешь о DALL·E и подобных генеративных нейронных моделях, способных создавать визуальный контент по текстовому описанию? Где может быть полезна такая технология? Насколько тебя впечатлили результаты? Давай обсудим в комментариях.



 «Постоянство памяти» (исп. La persistencia de la memoria, 1931)
«Постоянство памяти» (исп. La persistencia de la memoria, 1931)













SinsI
Очень хотелось бы веб-морду, чтобы каждый мог поиграться с этой нейросетью самостоятельно…
Без этого как-то даже не верится, что это действительно результаты работы не человека.
Или это действительно нейросеть, но авторы вручную отфильтровали 99% шлака…
Dirac Автор
И мне мы хотелось поиграть с моделью. По поводу качества результатов, у меня нет поводов не доверять ребятам из openai. Они написали, что не делали ручной «cherry picking»:
То есть, по сути, это и есть cherry picking, но не ручной, а при помощи другой модели. Я считаю, что это вполне честно. Мы же не пишем и не говорим все то, что пришло к нам в голову, а фильтруем и выбираем, что говорить и что писать.Tarson
Надо вторую нейросеть, которая выделит 32 лучших примера из 512 сгенерированных первой сетью…
Dirac Автор
Так и есть. CLIP это вторая
DALL · Eenclis
Не похоже, что они тщательно отбирали результаты. К примеру, a living room with two red armchairs and a painting of yoda. the painting is mounted behind a ceiling fan:

Я конечно сам делал «cherry picking» самых плохих вариантов. В остальных случаях оно заметно лучше. А вообще, года бы 3-4 назад даже такой результат считался бы просто сногшибательным.
Dirac Автор
Спасибо за примеры! Действительно, с Йодой далеко не все изображения. Тоже выбрал этот вариант, не лучшие примеры выходят.
Dirac Автор
Видно DALL · E лучше сформировал скрытую репрезентацию Дарта Вейдера чем Йоды.
Dirac Автор
Dirac Автор
Вставил два раза одно и тоже… Хотел это: