
Доброго времени суток, уважаемые хабровчане.
Сегодня речь пойдет опять и снова про mySQL. Разберемся в оптимизации и поговорим про множество параметров сервера.
Давайте приступать.
Сервер у нас пусть будет на ? CentOS?. Оптимизировать будем методом правки конфига ?my.cnf? .
Настройка некоторых параметров может повысить
производительность БД сервера в несколько раз!
Для начала давайте определимся, что мы вообще оптимизируем — т.е сколько каких таблиц на каком движке имеем, какая железка у нас есть и под какие параметры мы будем всё это дело подгонять.
Для этого возьмем ? htop? (как красивый и наглядный инструмент):
Выведем ? htop? :
Получаем нечто такое:
Запишем себе в ?my.cnf?:
Теперь давайте узнаем количество таблиц и их типы.
Для этого возьмем ?mysql tuner?:
Запустим:
Вывод примерно:
Запишем себе в ?my.cnf:
Типовой конфиг обычно рекомендуют какой-то такой:
Теперь давайте разбираться, что мы будем оптимизировать здесь, зачем, как и почему (особенно почему этих параметров маловато.
Для начала можно пролистать в конец вывода ?mysql tuner? и посмотреть, что же он там рекомендует. В нашем случае это выглядит как-то так:

Не будем заниматься бездумной подстановкой, а пройдемся по параметрам ?mysql? , которые могут нас интересовать в первую очередь. Что к чему:
skip-external-locking?, — убирает внешнюю блокировку, что быстрее;
skip-name-resolve? , — позволяет ?MySQL ? избегать ответа на запрос DNS ? при проверке подключения клиентов к серверу ?MySQL? .
Таким образом, сервер ?MySQL ? будет использовать только
IP? -адреса, а не имена хостов, что немного, но быстрее.
binlog_cache? _ ? size?, — размер кэша для хранения изменений в двоичном журнале. Задает размер только для кэша транзакций. Сделаем ? 100M? — больше не нужно.
innodb_stats_on_metadata? =? 0 (OFF),? — для ускорения работы с
INFORMATION_SCHEMA?, ? SHOW TABLE STATUS? или ? SHOW INDEX? отключим обновление статистики при выполнении таких операций
quer? y ? _cache_size ? = ? 128M ? и ? query_сache_type?
? = ? 1,? ? — ? кэши запросов. ? 1? — в принципе включен, ? 128M? ограничение. Не
рекомендуется ставить выше ? 256M? , т.к это может привести к блокировке.
Так как у нас больше?InnoDB? таблиц, то зануляем cache? _ ? size? .
С версии MySQL 5.6 ? query_cache_size? отключен, а с версии 8.0 удален
Стандартно все таблицы и индексы хранятся в одном файле, поэтому используем ? innodb_file_per_table = 1.
Значение ? innodb_open_files? и ? table_open_cache? — рекомендуется устанавливать обе опции в ? 4096 ? или ? 8192? . А вообще рассчитывается как количество таблиц во всех базах, умноженное на ? 2? , ориентировочно.
При работе с ? InnoDB ? является важнейшим параметр innodb_buffer_pool_size? , ? он устанавливается по принципу «чем больше, тем лучше». Рекомендуется выделять до ? 70-80% оперативной памяти сервера.
innodb_log_file_size? — влияет на скорость записи, устанавливает размер лога операций (операции сначала записываются в лог, а потом применяются к данным на диске). Чем больше этот лог, тем быстрее будут работать записи (т.к. их поместится больше в файл лога). Файлов всегда два, а их размер одинаковый. Значением параметра задается размер одного файла.
Установка большого размера ? innodb_log_file_size? может привести к увеличению быстродействия, но при этом увеличится время восстановления данных, выберите от ? 256M? до? 1G? .
innodb_log? _ ? buffer_size? — размер буфера транзакций. Обычно рекомендуется не применять, если не используете ? BLOB ? и ? TEXT больших размеров.
innodb_flush? _ ? method,? — определяет логику сброса данных на диск. В современных системах при использовании RAID и резервных узлов, вы будете выбирать между ? ODSYNC? и ? ODIRECT, — первый параметр быстрее, второй безопаснее.
key_buffer? _ ? size? — буфер для работы с ключами и индексами, и sort_buffer? — буфер для сортировки. Если Вы не используете MyISAM ? таблицы, рекомендуется установить размер key_buffer_size ? в ? 32Мб ? для хранения индексов временных
таблиц.
Параметр ? thread_cache? _ ? size? указывает количество тредов (threads), уходящих в кеш при отключении клиента. При новом подключении тред не создается, а берется из кеша, что позволяет экономить ресурсы при больших нагрузках.
innodb_flush_log_attrx_commit?, — может повысить пропускную способность записи данных в базу в сотни раз. Он определяет, будет ли ?Mysql ? сбрасывать каждую операцию на диск (в файл лога).
innodb_flush_log_at_trx_commit = 1? используется для случаев,
когда сохранность данных — это приоритет номер один.
innodb_flush_log_at_trx_commit = 2? для случаев, когда небольшая потеря данных не критична. Есть еще 0 (ноль) — самый производительный, но небезопасный вариант.
max_connections ? — если вы получаете ошибки "? Too many connections? ", эту опцию стоит увеличить. А так большой пользы в оптимизации от неё нет.
Количество потоков ввода/вывода файлов в InnoDB задается опциями ? innodb_read_io_threads? , ? innodbwrite_io_threads?, обычно этому параметру присваивается значение ? 4 ? или ? 8? , на быстрых ? SSD? -дисках установите в ? 16?. Значение innodb_thread_concurrency? установите в количество ядер ? * 2? .
Конфиг получается вот такой:
Ну и напоследок можно посмотреть рекомендации тюнера и последовать им.
Вот такой вот интересный конфиг получился. Если Вам сложно, то на первых порах стоит пользоваться ?mySQL ? калькулятором, который подскажет основные параметры и позволит не выходить за пределы доступной памяти — как-никак всё упирается в неё:
Спасибо за внимание. Присоединяйтесь к обсуждению.
Сегодня речь пойдет опять и снова про mySQL. Разберемся в оптимизации и поговорим про множество параметров сервера.
Давайте приступать.
Начало
Сервер у нас пусть будет на ? CentOS?. Оптимизировать будем методом правки конфига ?my.cnf? .
Настройка некоторых параметров может повысить
производительность БД сервера в несколько раз!
Для начала давайте определимся, что мы вообще оптимизируем — т.е сколько каких таблиц на каком движке имеем, какая железка у нас есть и под какие параметры мы будем всё это дело подгонять.
Для этого возьмем ? htop? (как красивый и наглядный инструмент):
yum install htopВыведем ? htop? :
htopПолучаем нечто такое:
Запишем себе в ?my.cnf?:
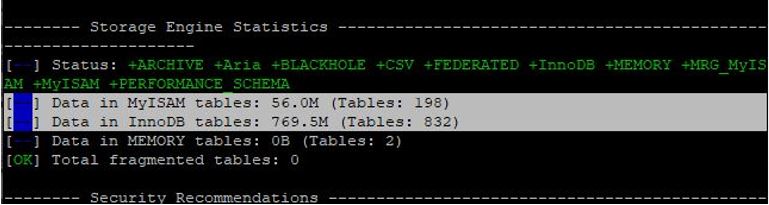
# 3 ядра, 4гб оперативной памяти Теперь давайте узнаем количество таблиц и их типы.
Для этого возьмем ?mysql tuner?:
wget https://raw.github.com/major/MySQLTuner-perl/master/mysqltuner.plЗапустим:
perl mysqltuner.plВывод примерно:
Запишем себе в ?my.cnf:
# 64M myisam, 770M innoDBТиповой конфиг обычно рекомендуют какой-то такой:
[client]
port = 3306
socket = /var/run/mysqld/mysqld.sock
[mysqld_safe]
socket = /var/run/mysqld/mysqld.sock
nice = 0
[mysqld]
user = mysql pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
port = 3306
basedir = /usr
datadir = /var/lib/mysql
tmpdir = /tmp
language = /usr/share/mysql/english
old_passwords = 0
bind-address = 127.0.0.1
skip-external-locking
max_allowed_packet = 16M
key_buffer_size = 16M
innodb_buffer_pool_size = 2048M
innodb_file_per_table = 1
innodb_flush_method = O_DIRECT
innodb_flush_log_at_trx_commit = 0
max_connections = 144 <a
href="https://ruhighload.com/query_cache_size+%d0%bf%d0%b0%d1
%80%d0%b0%d0%bc%d0%b5%d1%82%d1%80+%d0%b2+mysql"
target="_blank" style="color: rgb(232, 95, 99);">query_cache_size</a>
= 0 slow_query_log = /var/log/mysql/mysql-slow.log
long_query_time = 1
expire_logs_days = 10
max_binlog_size = 100M
[mysqldump]
quick
quote-names
max_allowed_packet = 16MТеперь давайте разбираться, что мы будем оптимизировать здесь, зачем, как и почему (особенно почему этих параметров маловато.
Оптимизация и конфиг
Для начала можно пролистать в конец вывода ?mysql tuner? и посмотреть, что же он там рекомендует. В нашем случае это выглядит как-то так:
wget
https://raw.github.com/major/MySQLTuner-perl/master/mysqltuner.pl
perl mysqltuner.plНе будем заниматься бездумной подстановкой, а пройдемся по параметрам ?mysql? , которые могут нас интересовать в первую очередь. Что к чему:
skip-external-locking?, — убирает внешнюю блокировку, что быстрее;
skip-name-resolve? , — позволяет ?MySQL ? избегать ответа на запрос DNS ? при проверке подключения клиентов к серверу ?MySQL? .
Таким образом, сервер ?MySQL ? будет использовать только
IP? -адреса, а не имена хостов, что немного, но быстрее.
binlog_cache? _ ? size?, — размер кэша для хранения изменений в двоичном журнале. Задает размер только для кэша транзакций. Сделаем ? 100M? — больше не нужно.
innodb_stats_on_metadata? =? 0 (OFF),? — для ускорения работы с
INFORMATION_SCHEMA?, ? SHOW TABLE STATUS? или ? SHOW INDEX? отключим обновление статистики при выполнении таких операций
quer? y ? _cache_size ? = ? 128M ? и ? query_сache_type?
? = ? 1,? ? — ? кэши запросов. ? 1? — в принципе включен, ? 128M? ограничение. Не
рекомендуется ставить выше ? 256M? , т.к это может привести к блокировке.
Так как у нас больше?InnoDB? таблиц, то зануляем cache? _ ? size? .
С версии MySQL 5.6 ? query_cache_size? отключен, а с версии 8.0 удален
Стандартно все таблицы и индексы хранятся в одном файле, поэтому используем ? innodb_file_per_table = 1.
Значение ? innodb_open_files? и ? table_open_cache? — рекомендуется устанавливать обе опции в ? 4096 ? или ? 8192? . А вообще рассчитывается как количество таблиц во всех базах, умноженное на ? 2? , ориентировочно.
При работе с ? InnoDB ? является важнейшим параметр innodb_buffer_pool_size? , ? он устанавливается по принципу «чем больше, тем лучше». Рекомендуется выделять до ? 70-80% оперативной памяти сервера.
innodb_log_file_size? — влияет на скорость записи, устанавливает размер лога операций (операции сначала записываются в лог, а потом применяются к данным на диске). Чем больше этот лог, тем быстрее будут работать записи (т.к. их поместится больше в файл лога). Файлов всегда два, а их размер одинаковый. Значением параметра задается размер одного файла.
ВНИМАНИЕ!?При изменении параметра innodb_log_file_size остановите MySQL, сделайте резервную копию файлов ib_logfile-n (файлы чаще всего лежат в /var/lib/mysql/), измените значение параметра innodb_log_file_size и запустите MySQL. В результате
MySQL создаст новый лог-файл указанного в конфигурации размера.
Установка большого размера ? innodb_log_file_size? может привести к увеличению быстродействия, но при этом увеличится время восстановления данных, выберите от ? 256M? до? 1G? .
innodb_log? _ ? buffer_size? — размер буфера транзакций. Обычно рекомендуется не применять, если не используете ? BLOB ? и ? TEXT больших размеров.
innodb_flush? _ ? method,? — определяет логику сброса данных на диск. В современных системах при использовании RAID и резервных узлов, вы будете выбирать между ? ODSYNC? и ? ODIRECT, — первый параметр быстрее, второй безопаснее.
key_buffer? _ ? size? — буфер для работы с ключами и индексами, и sort_buffer? — буфер для сортировки. Если Вы не используете MyISAM ? таблицы, рекомендуется установить размер key_buffer_size ? в ? 32Мб ? для хранения индексов временных
таблиц.
Параметр ? thread_cache? _ ? size? указывает количество тредов (threads), уходящих в кеш при отключении клиента. При новом подключении тред не создается, а берется из кеша, что позволяет экономить ресурсы при больших нагрузках.
innodb_flush_log_attrx_commit?, — может повысить пропускную способность записи данных в базу в сотни раз. Он определяет, будет ли ?Mysql ? сбрасывать каждую операцию на диск (в файл лога).
innodb_flush_log_at_trx_commit = 1? используется для случаев,
когда сохранность данных — это приоритет номер один.
innodb_flush_log_at_trx_commit = 2? для случаев, когда небольшая потеря данных не критична. Есть еще 0 (ноль) — самый производительный, но небезопасный вариант.
max_connections ? — если вы получаете ошибки "? Too many connections? ", эту опцию стоит увеличить. А так большой пользы в оптимизации от неё нет.
Количество потоков ввода/вывода файлов в InnoDB задается опциями ? innodb_read_io_threads? , ? innodbwrite_io_threads?, обычно этому параметру присваивается значение ? 4 ? или ? 8? , на быстрых ? SSD? -дисках установите в ? 16?. Значение innodb_thread_concurrency? установите в количество ядер ? * 2? .
Конфиг получается вот такой:
[client]
port = 3306
socket = /var/run/mysqld/mysqld.sock
[mysqld_safe]
socket = /var/run/mysqld/mysqld.sock nice = 0
[mysqld]
user = mysql
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
port = 3306
basedir = /usr
datadir = /var/lib/mysql
tmpdir = /tmp
language = /usr/share/mysql/english
old_passwords = 0
bind-address = 127.0.0.1
skip-external-locking
skip-name-resolve
binlog_cache_size = 100M
thread_cache_size = 32
innodb_stats_on_metadata = OFF
query_cache_limit = 1M
query_cache_size = 0 query_cache_type = 1
innodb_buffer_pool_size = 3G
innodb_log_file_size = 256М
innodb_log_buffer_size = 6M
innodb_additional_mem_pool_size = 16M
innodb_flush_method = O_DSYNC
innodb_flush_log_at_trx_commit = 0
innodb_thread_concurrency = 6
innodb_file_per_table = 1
key_buffer_size = 32M
tmp_table_size = 64M
max_connections = 350
sort_buffer_size = 16M read_buffer_size = 1M
read_rnd_buffer_size = 1M
join_buffer_size = 8M
thread_stack = 1M
binlog_cache_size = 8M
tmp_table_size = 128M
table_open_cache = 2048
[mysqldump] quick
quote-names
max_allowed_packet = 16MНу и напоследок можно посмотреть рекомендации тюнера и последовать им.
Заключение
Вот такой вот интересный конфиг получился. Если Вам сложно, то на первых порах стоит пользоваться ?mySQL ? калькулятором, который подскажет основные параметры и позволит не выходить за пределы доступной памяти — как-никак всё упирается в неё:
Спасибо за внимание. Присоединяйтесь к обсуждению.

Kwisatz
Такой сложный вопрос: а зачем вообще MySQL использовать? Да, база развивается, но ее безмерно тупой оптимизатор таковым и остается. Да и собственно как ушел с нее так и не смог за последние лет 8 придумать ни одной причины в ее пользу. Как один человек очень точно сказал: «PG это база данных, а MySQL — хрен с гвоздями», грубовато — но очень точно.
justhabrauser
Некоторые/многие вещи делать проще и удобнее в MySQL, чем в PG.
Поэтому разводить целый PG ради бложика на 3 таблички просто-напросто нецелесообразно и неудобно.
Так же, как утверждать «БелАЗ — это машина, а Reno Logan — это хрень с гайками».
Так-то на стоянках возле гипермаркетов БелАЗов не сильно много.
Kwisatz
пример можно?
почему?
Это скорей про оракл, в терминах которых сервер это строго монстроподобная конфигурация сходу.
Kwisatz
То есть аргументов не будет? Всегда так приятно побеседовать с коллегами)
skeletor
Когда говорят, что Postgres крут, это говорят с точки зрения программиста или DBA? Если с точки зрения программиста, то да, там фич значительно больше. Но вот с точки зрения DBA — postgres явно не лучше.
1) Репликация.
Чего стоит мучительная репликация, которая в mysql появилась, лет, наверное 10 назад, причём не тупо «всё реплицировать», а выбирать, какие базы, таблицы. Да, в postgres'e были всякие костыли типа slony, и даже в 9-ке появилась родная binary-репликация (и да, всё так же «все реплицировать») в одну сторону (на тот момент в mysql уже давно была master-master). Вроде бы в 10-ке появилась logical, где уже можно выбирать, что реплицировать. Да, это прорыв, но почему так поздно? С тех пор я перестал следить за PQ. Я не знаю, может в 12 появилась уже master-master репликация, тогда шансы уровнялись в этой части. А может PQ умеет реплицироваться сразу с нескольких источников? mysql такое умеет, как минимум года 3.
2) upgrade с версии на версию.
Это страшный сон всех PQ DBA, даже если версии минорные, особенно, если у тебя есть custom'ные exten'ы. Ну вот нельзя просто поставить новую версию, запустить скрипт upgrad'a и всё. И это mysql умеет очень давно. Но PQ до 9.Х включительно не имел такого инструмента. Как дела в PQ в 12-ой версии — я не знаю, возможно, спустя много лет, что-то появилось.
3) recovery table
Если таблица очень большая и дамп по каким-то причинам долго переносить/делать, то можно с рабочего сервера сделать копию файла ibd (если InnoDB) потом через DISCARD/IMPORT можно «подключить» таблицу в работающую базу. Тут успех, где-то 70%, но всё-равно не малый.
4) 32-ух битный номер транзакций. Это боль для высоконагруженных БД. Такое случается очень редко, но когда случилось — это катастрофа. Как чинить — непонятно (была статья на хабре, где писали за деньги патч под это дело). Вроде бы в 10 или 11 он уже 64-их битный, но что делать было раньше? Надеятся, что ты никогда с таким не столкнёшься?
Это самые большие проблемы, с которыми приходилось мириться (и надеятся, что они никогда не настанут) и мы перешли на mysql. Были ещё мелкие недочёты, но они несущественны.
Вы могли бы мне назвать причины, в чём PQ лучше MY, как для DBA?
Kwisatz
Вот, уже разговор пошел)
1. Ну во первых не пойму чем же слони костыль, да сейчас репликация есть, и мучений нет, про Master-master не в курсе, последний раз юзал bucardo, сейчас у меня нет такого типа репликаций по ряду причин.
2. Можно. pg_dump_all, create cluster, pg_restore. Да неидеальный подход, тот же оракл вроде как умеет обновлятся, но по сути — извольте ваш код переписать, сэр.
3. В голову не приходио, но любопыто, надо пошукать.
4. Раньше было раньше, ну серьезно, в этом году 14ая выходит)
Могу, он быстрее, у него куда большое возможностей по оптимизации и контролю целостности данных и развивается она быстро и есть большой запас по возможностям на вырост (например есть возможность подключить ту же TimescaleDB если нужна колоночная БД). Многих вещей в Mysql просто не завезли, я например страдаю без частичных индексов, а еще пространственные данные, trgm индексы, крутой FTS и так далее. Можно ли сказать что «для DBA»? ну тут такое себе будет обсуждение.
На самом деле вопрос кстати не праздный, я довольно давно интересуюсь у людей зачем им Mysql и большинство аргументов не приводит, да собственно как и тут, 5 минусов к комменту а обсудить чтото можно только с вами.
skeletor
1. Костыль, потому что это стороннее ПО, так же как и bucardo. У нормальной DB давно такие инструменты должны быть нативные.
2. Да, можно многими способами, но процент успешной миграции в моём случае был очень невелик. Зачем мне переписывать код, если дело в конкретном exten'e? Это глупо и неправильно. Правильно было бы во время дампа указать его, что есть такой exten и лежит там-то. Но нет, как ни подсовывал ему, ему всё не нравилось. Это первый пример. Второй пример, это функция digest из стандартного exten'a pgcrypto (он правда не подключён по умолчанию, но ведь это не должно быть проблемой при дампе). Итого, исходя из ваших слов, или не пользоваться вообще exten'aми, ибо всё, что не включено по дефолту сломается при обновлении, либо каждый раз переписывать код. Зачем тогда вообще нужны такие exten'ы, которые создают больше проблем чем профита?
3.
4. Пускай хоть 15-ая. Скажите, что из этих 4-ох пунктов имеет Postgres на текущий момент, не смотря на то, что у mysql это уже как несколько лет есть? Или назовите, чем он лучше для DBA в плане обслуживания и что имеет такого, чего нет в mysql и оно реально крутое? Я сейчас не про 100500 разных индексов, а про то, что реально может быть полезно.
Вы опять всё клоните в сторону разработчика, а не DBA. DBA в первую очередь волнует как это можно масштабировать, обновить, бэкапить и потом восстановить. То, что запросы будут выполняться быстрее или медленнее, это уже второй вопрос. Да, анализатор запросов в PQ лучше, чем в mysql, тут не спорю, но ради этого менять БД — сомнительно.
Mysql может нормально работать на HighLoad, главное правильно «приготовить». Зачем mysql? Затем, что его проще и надёжнее обслуживать.
Тут хочется вспомнить анекдот про работу пожарным: «На работе хорошо и бесплатно кормят, есть бесплатная спецодежда, можно поспать в рабочее время, хороший коллектив, но когда пожар — хоть увольняйся».
Кстати, пока писал коммент, вспомнил, что для mysql есть percona toolkit, который имеет ну очень полезную фичу, которая пару раз очень выручала: сделать консистентной реплику. То есть, предположим, что в одной из реплик часть данных пропали (как, это неважно: либо кто-то случайно удалил, либо по ошибкам не дошли, либо реплика долго была отключена, либо...). Как досинкать только недостающие данные, например, на 100Гб таблице, при этом, учитывая то, что в этот момент идёт репликация? Если для postgres'a есть такое же, я за него буду только рад.
Ещё раз повторюсь для всех, меня интересует сравнение PQ и MY ТОЛЬКО в плане DBA.
Kwisatz
Ну не могу согласится, вот никак.
Там еще был нюанс с определенным рубежом как раз в районе 9ки когда они меняли саму философию расширений и правильно сделали я считаю. Сейсас за счет расширений можно вытворять очень много всего нужного и крутого.
А про переписывание кода это уже был мой пассаж в сторону оракла, да система обновления есть, но что толку если все равно все переписывать? Это просто данность с которой нужно жить, БД как и все остальное развивается.
То что я назвал все реально нужно и полезно.
Это не второй вопрос. Поскольку на этом экономятся очень большие деньги.
Это ровно до тех пор пока ваша база не падает и не перестает подавать признаки жизни. У меня было множество обращений в стиле «ааа сайт дохлый валяется дадим любых денег аааа». И было так же множество случаев, когда кроме миграции на другую СУДБ, решения небыло.
Может, тут с вами согласен. Но ровно до того момента пока вам не понадобится писать в нее с дурной скоростью (например) или с геоданными развлекаться.
Точно не уверен, но если реплика сдохла, то мастер об этом в курсе и перестанет чистить wal, на это обычно делают алерт. Более того в зависимости от критичности можно покрутить еще сам тип репликации. А по вашим кейсам честно не скажу, я так глубоко в DBA не лез, поскольку стараюсь делать так чтобы с такими ошибками не сталкиваться
Вы уж меня простие, но если идет обсуждение об экономии процессорного времени, увеличении скорости выполнения и самой возможности работать с определенным типом данных, работа DBA как раз сделать красиво с тем что подходит под требования, а не наоборот.
skeletor
В общем, я вижу, что вы уходите от прямых ответов, поэтому спорить тут бессмысленно. У вас всё сводится к тому, что «не было, не должно быть и это должно мониториться и т.д.». Вы должны быть готовы к любым ситуациям, и, если конкретная БД этого не умеет или это будет очень и очень сложно — то зачем её использовать под эти задачи изначально?
То, что вы назвали, это реально и полезно, кому-то другому, но не DBA. Не нужно говорить, что сайт на mysql будет тормозить, а на postgres будет летать. Экономию денег посчитаете во время сбоя DB и сроков её восстановления.
Если мне нужно будет писать много-много данных с большой-большой скоростью, то это точно не должна быть mysql, ибо она для этого не годится. Тут или NoSQL выбирать или искать другие решения. И да, я выбираю по принципу: для каждой задачи должна быть DB максимально ей отвечающая. То есть я НЕ буду пихать везде MY, потому что она мне больше симпатизирует. Если объективно она туда не подходит — то зачем её там использовать? Доказать, что что-то может работать на MY? Смысл?
Насчёт скорости: посмотрите на работу банков, особенно их личных кабинетов. Нигде нет супер-пупер скорости отдачи страниц, особенно, когда идут какие-то оплаты. Вы можете ждать и 5 и 10 секунд, и это нормально. Нет, я не говорю о каких-то минутах. Им надёжнее отдать вам страницу позже, чем потом разбираться с тем, у кого сколько денег пропало. Это если вы говорите об экономии больших денег. Я на 99% уверен, что у них oracle, но даже в этом ключе они не стремятся к быстродействию ради милисекунд.
PS. Я прекращаю дальнейшую дискуссию.
Kwisatz
даже не пытаюсь
Именно так, я адепт предсказания проблем и принятия мер по недопущению.
Могу вспомнить порядка 10-15 таких случаев на внушительных объемах данных.
Все верно, поэтому я и ставлю во главу угла непрерывность и стабильность реплики и разворачиваемость бекапа.
У банков объем данных недостижимый для 99,9% проектов. Однако же сейчас идет тенденция к тому, что у многих интернет магазинов ровно такие же проблемы.
нет не нормально. Начните считать это нормальным и скоро будете ждать по 30-60 минут.
Деньги можно экономить по разному. Хранилища, например, тоже денег стоят.
он самый, но не чистый а с ЦФТшным продуктом поверху.
стремятся, иначе эти миллисекунды потом в часы и дни выливаются
ЗЫ и вам всего доброго.
arheops
Mysql работает «оптимистически», а постгресс «пессимистически».
Перевожу. Если у вас атомарные запросы или транзакции, которые не выполняют rollback то mysql работает в разы быстрее. Если у вас есть rollbacks, то ровно наоборот, ибо откат большой транзакции в mysql может выполнятся часами.
Это просто другой подход к видению базы.
mysql рассчитан на относительно простые системы написанные людьми незнающими про транзакции и оптимизацию. И да, это работает.
Kwisatz
Даже примерно это не так и опять же, молчу про оптимизатор который требует танцев с бубном (ну или при кривых руках за угол заводится запросто).
Совершенно ничего не мешает те же простые вещи писать на PG. Дело то вот в чем, потом бац и уперлись. Вот только недавно видел ка краз ситуацию с uid, 3 поля, естественно текстовые и на определенном объеме это просто все сдохло, и пошли очень увлекательные танцы сначала с попытками оптимизации, потом с попытками глубокой оптимизации а потом с переездом на другую базу.