
Всем привет. Сегодня я хотел бы поделиться рецептом по обрезанию большой таблицы PostgreSQL в production. Пример: мы имеем в продовой БД достаточно большую таблицу с именем task (несколько сотен миллионов строк) с устаревшими данными, которые нам уже не нужны. Точнее, они мешают — БД долго дампится, а индексы становятся неэффективными. Мы хотим обрезать эту таблицу (удалить старые строки ранее определенной даты). Для простоты предположим, что в базе нет входящих foreign key на таблицу task (при их наличии решение задачи немного усложняется).
Структура таблицы такая (упрощенный пример):
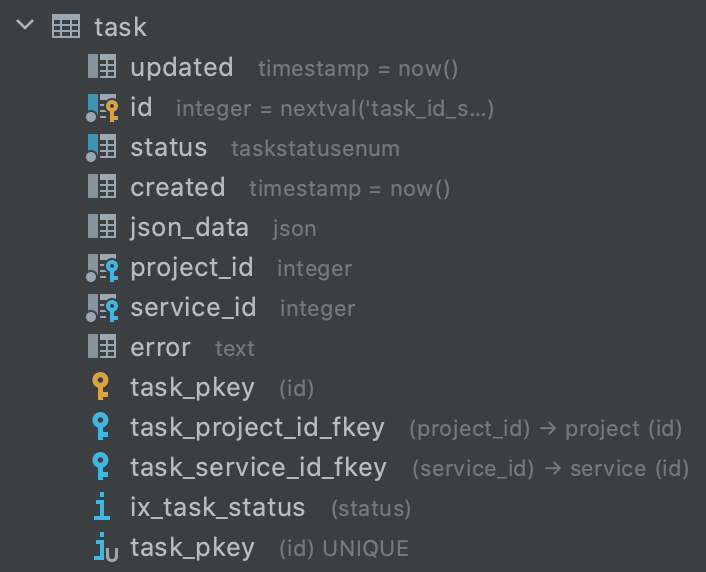
Решение в лоб (delete from task where id < 1234567) работает очень долго из-за большого количества индексов и ограничений в таблице и нас не устраивает. В нашем случае скорость удаления составляла 10 000 строк в минуту (нужно было удалить около 100 млн строк).
С учетом того, что данные запросы мы могли бы выполнять только в ночное время, чистка таблицы этим способом заняла бы около месяца.
Более быстрый алгоритм (который позволил достичь нам очистить таблицу всего за час):
Создаем новую таблицу task_new, в которую перенесем актуальные строки:
CREATE TABLE task_new LIKE tasks;
ALTER TABLE task_new ADD PRIMARY KEY (id);Запускаем триггер для обновления новой таблицы.
Запускаем скрипт для переноса актуальных строк.
Добавляем индексы и ограничения для новой таблицы.
Меняем таблицы местами.
Шаг 1. Создание новой таблицы
Новую таблицу создаем на основе текущей (вместе с типами данных, ограничениями на NULL и значениями по умолчанию). Индексы и ограничения навесим позднее, чтобы не замедлять копирование данных.
CREATE TABLE task_new (LIKE task INCLUDING DEFAULTS);
ALTER TABLE task_new ADD PRIMARY KEY (id);Шаг 2. Запуск триггера
Далее нам нужно задать триггер, который будет обновлять данные в соответствии с исходной таблицей (команды insert/update/delete).
create or replace function task_replication_trg_func()
returns trigger
AS $func$
begin
if TG_OP = 'INSERT' then
insert into task_new(
id,
created,
updated,
status,
json_data,
project_id,
service_id,
error
)
values (
NEW.id,
NEW.created,
NEW.updated,
NEW.status,
NEW.json_data,
NEW.project_id,
NEW.service_id,
NEW.error
);
elsif TG_OP = 'UPDATE' then
update task_new set
created = NEW.created,
updated = NEW.updated,
status = NEW.status,
json_data = NEW.json_data,
project_id = NEW.project_id,
service_id = NEW.service_id,
error = NEW.error
where id = NEW.id;
elsif TG_OP = 'DELETE' then
delete from task_new
where id = OLD.id;
end if;
return NULL;
end;
$func$ LANGUAGE plpgsql;
create trigger task_replication_trg
after insert or update or delete on task
for each row EXECUTE PROCEDURE task_replication_trg_func();Шаг 3. Запуск скрипта для переноса строк
После запуска триггера нам нужно запустить скрипт, который перенесет остальные актуальные данные из текущей таблицы в новую.
Скрипт (написан на Python 3) доступен под катом.
import time
from argparse import Namespace, ArgumentParser
from urllib.parse import urlparse
import psycopg2
def main():
args = parse_args()
copy_rows_to_new_table(
args.table_name,
args.conn_str,
args.first_row_id,
args.first_trigger_id,
args.sleep_ms,
args.chunk_size
)
def copy_rows_to_new_table(table_name: str,
conn_str: str,
first_row_id: int,
first_trigger_id: int,
sleep_ms: int = 1000,
chunk_size: int = 10000):
"""
Алгоритм работы:
1. создаем table_name_new (на основании table_name) - без индексов и констрейнтов
create table if not exists table_name_new (like table_name);
добавляем индекс и ограничние на PK
Алгоритм шага переноса (на вход - start_id и first_trigger_id)
1. Получаем start_id - id записи для текущего цикла переноса
select max(id) from table_name_new where id < %first_trigger_id%
Если start_id - null, start_id = first_row_id - 1
2. выбираем 10к записей по условие start_id < id < first_trigger_id
with rows as (
insert into table_name_new (
select * from table_name
where id > :start_id: and id < :first_trigger_id:
limit :chunk_size:
) returning 1
) select count(*) from rows;
3. Если кол-во вставленных строк из п.2 < chunk_size - выходим
:return:
"""
new_table_name = f"{table_name}_new"
conn = None
try:
conn = get_connection(conn_str)
create_table(conn, table_name, new_table_name)
total_inserted = 0
while True:
time.sleep(sleep_ms / 1000)
start_id = get_start_id(conn, new_table_name, first_row_id, first_trigger_id)
inserted_rows = insert_chunk_rows(conn, table_name, new_table_name, start_id, first_trigger_id, chunk_size)
total_inserted += inserted_rows
print(f'inserted {total_inserted} rows')
if inserted_rows < chunk_size:
return
finally:
if conn:
conn.close()
def insert_chunk_rows(conn,
table_name: str,
new_table_name: str,
start_id: int,
first_trigger_id: int,
chunk_size: int) -> int:
query = f"""
with rows as (
insert into {new_table_name} (
select * from {table_name}
where id > %(start_id)s and id < %(first_trigger_id)s
limit {chunk_size}
) returning 1
) select count(*) from rows;
"""
with conn:
with conn.cursor() as cursor:
cursor.execute(query, {'start_id': start_id, 'first_trigger_id': first_trigger_id})
result = cursor.fetchone()
return result[0]
def get_start_id(conn, new_table_name: str, first_row_id: int, first_trigger_id: int) -> int:
query = f"select max(id) from {new_table_name} where id < %(last_id)s;"
with conn.cursor() as cursor:
cursor.execute(query, {'last_id': first_trigger_id})
result = cursor.fetchone()
return result[0] or first_row_id
def create_table(conn, table_name: str, new_table_name: str):
with conn:
with conn.cursor() as cursor:
cursor.execute(f"SELECT EXISTS (SELECT FROM information_schema.tables WHERE table_name = '{new_table_name}');")
res = cursor.fetchone()
table_exists = res[0]
if not table_exists:
cursor.execute(f"create table {new_table_name} (like {table_name});")
cursor.execute(f"ALTER TABLE {new_table_name} ADD PRIMARY KEY (id);")
def get_connection(connection_str: str):
result = urlparse(connection_str)
username = result.username
password = result.password
database = result.path[1:]
hostname = result.hostname
port = result.port
connection = psycopg2.connect(
database=database,
user=username,
password=password,
host=hostname,
port=port
)
return connection
def parse_args() -> Namespace:
"""
table_name: str,
conn_str: str,
first_row_id: int,
first_trigger_id: int,
sleep_ms: int = 1000,
chunk_size: int = 10000
:return:
"""
parser = ArgumentParser()
parser.add_argument(
"table_name",
type=str,
help=f"target table",
)
parser.add_argument(
"--conn_str",
type=str,
help="connection string (i.e. postgresql://postgres:postgres@localhost/postgres)",
required=True,
)
parser.add_argument(
"--first_row_id",
type=int,
help="start row id to copy",
required=True,
)
parser.add_argument(
"--first_trigger_id",
type=int,
help="first row id, inserted by trigger",
required=True,
)
parser.add_argument(
"--sleep_ms",
type=int,
default=1000,
help="to sleep milliseconds",
)
parser.add_argument(
"--chunk_size",
type=int,
default=10_000,
help="count of rows to insert by loop",
)
args = parser.parse_args()
return args
if __name__ == "__main__":
main()Входные параметры скрипта:
conn_str — строка для подключения к БД;
first_row_id — начиная с этого идентификатора мы переносим строки в новую таблицу (можно получить запросом select id from task where created::date = '2020-01-01'::date - interval '1 day' limit 1;);
first_trigger_id — идентификатор первой строки, созданной в новой таблице триггером (можно получить запросом select id from task_new order by id limit 1);
sleep_ms — сколько миллисекунд должен спать скрипт между итерациями;
chunk_size — количество строк, переносимых за один раз.
Команда для запуска скрипта:
pip3 install psycopg2-binary~=2.8
python3 mastersber_transfer.py task --conn_str=postgresql://{username}:{password}@{host}:{port}/{db_name} --first_row_id={first_row_id} --first_trigger_id={first_trigger_id} Шаг 4. Добавляем индексы и ограничения
Теперь нам нужно навесить на новую таблицу индексы и ограничения в соответствии со старой.
Получаем запросы для добавления индексов в текущую таблицу (кроме PK):
SELECT pg_get_indexdef(indexrelid) || ';' AS idx
FROM pg_index
WHERE indrelid = 'task'::regclass and not indisprimary;Получили набор команд:
CREATE INDEX ix_task_status ON public.task USING btree (status);
CREATE INDEX task_project_id_index ON public.task USING btree (project_id);Команды нужно немного преобразовать: добавить ключевое слово CONCURRENTLY, заменить название таблицы на новую и добавить префикс или суффикс “_new” к названиям индексов:
CREATE INDEX CONCURRENTLY new_ix_task_status ON public.task_new USING btree (status);
CREATE INDEX CONCURRENTLY new_task_project_id_index ON public.task_new USING btree (project_id);Теперь получим команды для добавления ограничения для новой таблицы:
SELECT 'ALTER TABLE task_new ADD CONSTRAINT ' || conname || ' ' || pg_get_constraintdef(oid) || ';'
FROM pg_constraint
WHERE contype = 'f' AND conrelid::regclass::text = 'task'
ORDER BY conrelid::regclass::text, conname;Получили набор команд (в них ничего менять не нужно):
ALTER TABLE task_new ADD CONSTRAINT task_project_id_fkey FOREIGN KEY (project_id) REFERENCES project(id);
ALTER TABLE task_new ADD CONSTRAINT task_service_id_fkey FOREIGN KEY (service_id) REFERENCES service(id);Теперь нужно выполнить в транзакции эти команды:
BEGIN;
CREATE INDEX CONCURRENTLY new_ix_task_status ON public.task_new USING btree (status);
CREATE INDEX CONCURRENTLY new_task_project_id_index ON public.task_new USING btree (project_id);
ALTER TABLE task_new ADD CONSTRAINT task_project_id_fkey FOREIGN KEY (project_id) REFERENCES project(id);
ALTER TABLE task_new ADD CONSTRAINT task_service_id_fkey FOREIGN KEY (service_id) REFERENCES service(id);
COMMIT;Шаг 5. Меняем таблицы местами
Последний этап: нужно поменять таблицы местами, переключить sequence со старой таблицы на новую и удалить триггер.
BEGIN;
set statement_timeout = 3000;
set deadlock_timeout = '3s';
ALTER TABLE task_new ALTER COLUMN id SET DEFAULT nextval('task_id_seq');
ALTER SEQUENCE task_id_seq OWNED BY task_new.id;
ALTER TABLE task RENAME TO task_old;
ALTER TABLE task_new RENAME TO task;
DROP TRIGGER IF EXISTS task_replication_trg ON task_old CASCADE;
COMMIT;
-- Если не нужна старая таблица - удаляем ее:
DROP TABLE task_old CASCADE;Заключение
Таким образом можно быстро очистить большую таблицу от устаревших данных, которые уже не нужны, но ухудшают производительность базы данных.
Если на таблицу есть входящие foreign keys, перед чисткой основной таблицы аналогично чистим ссылающиеся на нее (по условию на колонку c foreign key на нужную).
Если есть вопросы - пишите в комментариях.





onix74
А «create table as select» не пробовали? Если пробовали, на сколько медленнее внешнего скрипта?
olegborzov Автор
Цель — наполнять новую таблицу чанками, для большей отказоустойчивости и уменьшения нагрузки на боевую базу