
Data Cleaning: Problems and Current Approaches, 2000 г.
Достаточно часто каждый аналитик сталкивается с ситуацией, когда загрузил данные в блок анализа, а в ответ – тишина, хотя в тестовом режиме все работает. Причина обычно в том, что данные недостаточно очищены, где в этой ситуации искать аналитику засаду и с чего начинать обычно задачка не из легких. Можно конечно использовать механизмы сглаживания, но каждый знает, что если из черного ящика с красными и зелеными шарами отсыпать килограмм шаров и вместо них вбросить килограмм белых, то в понимании распределения красных и зеленых это мало приблизит.
Когда находишься в ситуации «а с чего начать» помогает таксономия «грязных данных». Хотя в учебниках и дают список проблем, но он обычно неполный, вот постоянно искал исследования, которые рассматривают эту тему подробней. Попалась работа T.Gschwandtner, J.Gartner, W.Aigner, S.Miksch хотя они ее делали для рассмотрения способов очистки данных связанных с датами и временем но, на мой взгляд, это оказалось исключение, которое потребовало разобраться с правилами поглубже чем в учебниках. По собственному опыту знаю, что сопряжение дат и времени «вынос мозга» практически в прямом смысле и поэтому и зацепился за исследование этих авторов.
В своей работе они проанализировали несколько работ других авторов и составили мощный список «загрязнений данных» логика их анализа заслуживает уважения и, с другой стороны, дает возможность более «со стороны» посмотреть на любую задачу очистки данных. Все это видно когда сопоставляешь всю совокупность работ, по которым они делают сравнительный анализ. Поэтому и сделал перевод самых используемых ими 5 статей, список с ссылками на эти переводы ниже.
Это вторая статья из цикла
1. Таксономия форматов времени и дат в неочищенных данных, 2012 г.
2. Очистка данных: проблемы и современные подходы 2000 г.
3. Таксономия «грязных данных» 2003 г.
4. Проблемы, методы и вызовы комплексной очистки данных 2003 г.
5. Формульное определение проблем качества данных 2005 г.
6. Обзор инструментов качества данных 2005 г.
Предисловие
Мы классифицируем проблемы качества данных, которые решаются с помощью очистки данных, и даем обзор основных решение подходит. Очистка данных особенно необходима при интеграции разнородных источников данных и следует решать вместе с преобразованиями данных, связанных со схемой. В хранилищах данных очистка данных основная часть так называемого процесса ETL. Мы также обсуждаем текущую поддержку инструментов для очистки данных.
1. Введение
Очистка данных, также называемая очисткой или очисткой данных, занимается обнаружением и удалением ошибок и несоответствия данных в целях повышения качества данных. Проблемы с качеством данных присутствуют в единичных коллекции данных, такие как файлы и базы данных, например, из-за неправильного написания при вводе данных, отсутствующей информации или другие неверные данные. Когда необходимо интегрировать несколько источников данных, например, в хранилищах данных, объединить системы баз данных или глобальные информационные веб-системы, потребность в очистке данных возрастает существенно. Это связано с тем, что источники часто содержат избыточные данные в разных представлениях. Чтобы обеспечить доступ к точным и непротиворечивым данным, объединение различных представлений данных и устранение дублирующейся информации становится необходимо.

Хранилища данных [6] [16] требуют и предоставляют обширную поддержку для очистки данных. Они загружают и постоянно обновляют огромные объемы данных из различных источников, поэтому высока вероятность того, что некоторые из источников содержат «грязные данные». Кроме того, хранилища данных используются для принятия решений, поэтому правильность их данных жизненно важна, чтобы избежать неправильных выводов. Например, дублирующаяся или отсутствующая информация приведет к неверной или вводящей в заблуждение статистике («мусор на входе, мусор на выходе»). Из-за широкого диапазона возможных несоответствий данных и огромного объема данных очистка данных считается одной из самых больших проблем в хранилищах данных. Во время так называемого процесса ETL (извлечение, преобразование, загрузка), показанного на рис. 1, дальнейшие преобразования данных связаны с преобразованием и интеграцией схемы / данных, а также с фильтрацией и агрегированием данных, которые должны храниться в хранилище. Как показано на рис. 1, вся очистка данных обычно выполняется в отдельной промежуточной области данных перед загрузкой преобразованных данных в хранилище. Для поддержки этих задач доступно большое количество инструментов с разной функциональностью, но часто значительную часть работы по очистке и преобразованию приходится выполнять вручную или с помощью низкоуровневых программ, которые сложно писать и поддерживать.
Интегрированные системы баз данных и информационные системы на базе Интернета проходят этапы преобразования данных, аналогичные этапам преобразования хранилищ данных. В частности, обычно существует оболочка для каждого источника данных для извлечения и посредник для интеграции [32] [31]. Пока что эти системы предоставляют лишь ограниченную поддержку очистки данных, вместо этого сосредотачиваясь на преобразовании данных для преобразования схемы и интеграции схемы. Данные не интегрируются предварительно, как для хранилищ данных, но их необходимо извлекать из нескольких источников, преобразовывать и объединять во время выполнения запроса. Соответствующие задержки связи и обработки могут быть значительными, что затрудняет достижение приемлемого времени отклика. Усилия, необходимые для очистки данных во время извлечения и интеграции, еще больше увеличивают время отклика, но являются обязательными для получения полезных результатов запроса.
Подход к очистке данных должен удовлетворять нескольким требованиям. Прежде всего, он должен обнаруживать и устранять все основные ошибки и несоответствия как в отдельных источниках данных, так и при интеграции нескольких источников. Подход должен поддерживаться инструментами, ограничивающими ручную проверку и усилия по программированию, и быть расширяемым, чтобы легко охватить дополнительные источники. Кроме того, очистку данных следует выполнять не изолированно, а вместе с преобразованием данных, связанных со схемой, на основе всеобъемлющих метаданных. Функции сопоставления для очистки данных и других преобразований данных должны быть указаны декларативно и должны быть повторно использованы для других источников данных, а также для обработки запросов. Инфраструктура рабочих процессов должна поддерживаться специально для хранилищ данных, чтобы выполнять все этапы преобразования данных для нескольких источников и больших наборов данных надежным и эффективным способом.
В то время как огромное количество исследований посвящено преобразованию схемы и интеграции схемы, очистка данных получила лишь небольшое внимание в исследовательском сообществе. Ряд авторов сосредоточились на проблеме выявления и устранения дубликатов, например, [11] [12] [15] [19] [22] [23]. Некоторые исследовательские группы концентрируются на общих проблемах, не ограниченных, но относящихся к очистке данных, таких как специальные подходы к интеллектуальному анализу данных [30] [29] и преобразования данных на основе сопоставления схем [1] [21]. Совсем недавно в нескольких исследованиях предлагается и исследуется более полный и единообразный подход к очистке данных, охватывающий несколько этапов преобразования, конкретные операторы и их реализацию [11] [19] [25].
В этой статье мы даем обзор проблем, которые необходимо решить с помощью очистки данных, и их решения. В следующем разделе мы представляем классификацию проблем. В разделе 3 обсуждаются основные подходы к очистке, используемые в доступных инструментах и исследовательской литературе. В разделе 4 дается обзор коммерческих инструментов для очистки данных, включая инструменты ETL. Раздел 5 - это заключение.
2. Проблемы очистки данных
В этом разделе классифицируются основные проблемы качества данных, которые необходимо решить с помощью очистки и преобразования данных. Как мы увидим, эти проблемы тесно связаны и поэтому должны рассматриваться единообразно. Преобразования данных [26] необходимы для поддержки любых изменений в структуре, представлении или содержании данных. Эти преобразования становятся необходимыми во многих ситуациях, например, чтобы иметь дело с эволюцией схемы, миграцией устаревшей системы на новую информационную систему или когда необходимо интегрировать несколько источников данных.
Как показано на рис. 2, мы грубо различаем проблемы с одним источником и проблемы с несколькими источниками, а также проблемы, связанные со схемой и записями. Проблемы на уровне схемы, конечно, также отражаются в записях; они могут быть решены на уровне схемы за счет улучшенного проектирования схемы (эволюция схемы), преобразования схемы и интеграции схемы. С другой стороны, проблемы на уровне записи относятся к ошибкам и несоответствиям в фактическом содержании данных, которые не видны на уровне схемы. Они являются основным направлением очистки данных. На рис. 2 также показаны некоторые типичные проблемы для различных случаев. Хотя это не показано на рис. 2, проблемы с одним источником возникают (с повышенной вероятностью) и в случае с несколькими источниками, помимо конкретных проблем с несколькими источниками.

2.1 Проблемы с одним источником
Качество данных источника в значительной степени зависит от степени, в которой он управляется схемой и ограничениями целостности, контролирующими допустимые значения данных. Для источников без схемы, таких как файлы, существует несколько ограничений на то, какие данные можно вводить и хранить, что приводит к высокой вероятности ошибок и несоответствий. С другой стороны, системы баз данных устанавливают ограничения конкретной модели данных (например, реляционный подход требует простых значений атрибутов, ссылочной целостности и т.д.), А также ограничения целостности для конкретных приложений. Проблемы качества данных, связанные со схемой, таким образом, возникают из-за отсутствия соответствующих ограничений целостности, специфичных для модели или приложения, например, из-за ограничений модели данных или плохого проектирования схемы, или из-за того, что было определено только несколько ограничений целостности, чтобы ограничить накладные расходы контроль правильности. Проблемы, связанные с конкретной записью, связаны с ошибками и несоответствиями, которые невозможно предотвратить на уровне схемы (например, орфографические ошибки).
Таблица 1. Примеры проблем с одним источником на уровне схемы (нарушенные ограничения целостности)

Для проблем как на уровне схемы, так и на уровне записи можем различать различные области проблем: атрибут (поле), запись, тип записи и источник; примеры для различных случаев показаны в таблицах 1 и 2. Обратите внимание, что ограничения уникальности, указанные на уровне схемы, не предотвращают дублирование записей, например, если информация об одном и том же реальном объекте вводится дважды с разными значениями атрибутов (см. пример в таблице 2).
Таблица 2. Примеры проблем с одним источником на уровне записи

Учитывая, что очистка источников данных - дорогостоящий процесс, предотвращение ввода грязных данных, очевидно, является важным шагом для уменьшения проблемы очистки. Это требует соответствующего проектирования схемы базы данных и ограничений целостности, а также приложений для ввода данных. Кроме того, обнаружение правил очистки данных во время проектирования хранилища может предложить улучшения ограничений, налагаемых существующими схемами.
2.2 Проблемы с несколькими источниками
Проблемы, существующие в отдельных источниках, усугубляются, когда необходимо объединить несколько источников. Каждый источник может содержать грязные данные, и данные в источниках могут быть представлены по-разному, совпадать или противоречить. Это связано с тем, что источники обычно разрабатываются, развертываются и обслуживаются независимо для удовлетворения конкретных потребностей. Это приводит к большой степени неоднородности относительно. системы управления данными, модели данных, схемы и фактические данные.
На уровне схемы различия в модели данных и конструкции схемы должны быть устранены путем преобразования схемы и интеграции схемы, соответственно. Основные проблемы с w.r.t. Схема проектирования - это именование и структурные конфликты [2] [24] [17]. Конфликты имен возникают, когда одно и то же имя используется для разных объектов (омонимы) или разные имена используются для одного и того же объекта (синонимы). Структурные конфликты возникают во многих вариации и относятся к разным представлениям одного и того же объекта в разных источниках, например, атрибут или представление таблицы, разная структура компонентов, разные типы данных, разные ограничения целостности и т.д.
Помимо конфликтов на уровне схемы, многие конфликты возникают только на уровне записи (конфликты данных). Все проблемы из случая с одним источником могут возникать с разными представлениями в разных источниках (например, дублированные записи, противоречащие записи и т.д.). Более того, даже когда существуют одинаковые имена атрибутов и типы данных, могут быть разные представления значений (например, для семейного положения) или разные интерпретации значений (например, единицы измерения доллар против евро) в разных источниках. Более того, информация в источниках может предоставляться на разных уровнях агрегирования (например, продажи по продукту по сравнению с продажами по группе продуктов) или ссылаться на разные моменты времени (например, текущие продажи на вчерашний день для источника 1 по сравнению с прошлой неделей для источника 2).
Основная проблема при очистке данных из нескольких источников состоит в том, чтобы идентифицировать перекрывающиеся данные, в частности совпадающие записи, относящиеся к одному и тому же реальному объекту (например, клиенту). Эту проблему также называют проблемой идентичности объекта [11], устранением дубликатов или проблемой слияния / очистки [15]. Часто информация является лишь частично избыточной, и источники могут дополнять друг друга, предоставляя дополнительную информацию об объекте. Таким образом, дублирующаяся информация должна быть удалена, а дополнительная информация должна быть консолидирована и объединена, чтобы получить единообразное представление об объектах реального мира.

Оба источника в примере на рис. 3 имеют реляционный формат, но демонстрируют конфликты схемы и данных. На уровне схемы существуют конфликты имен (синонимы Клиент / Клиент, Cid / Cno, Пол / Пол) и структурные конфликты (разные представления имен и адресов). На уровне записи мы отмечаем, что существуют разные гендерные репрезентации («0» / «1» против «Ж» / «M») и предположительно повторяющаяся запись (Кристен Смит). Последнее наблюдение также показывает, что, хотя Cid/Cno являются идентификаторами, зависящими от источника, их содержание не сопоставимо между источниками; разные числа (11/493) могут относиться к одному и тому же человеку в то время как у разных людей может быть один и тот же номер (24). Решение этих проблем требует интеграции схемы и очистки данных; в третьей таблице показано возможное решение. Обратите внимание, что сначала необходимо разрешить конфликты схемы, чтобы обеспечить очистку данных, в частности, обнаружение дубликатов на основе единообразного представления имен и адресов и сопоставление значений Gender / Sex.
3. Подходы к очистке данных
Как правило, очистка данных включает в себя несколько этапов
Анализ данных: чтобы определить, какие виды ошибок и несоответствий необходимо удалить, требуется подробный анализ данных. В дополнение к ручной проверке данных или выборок данных следует использовать программы анализа для получения метаданных о свойствах данных и обнаружения проблем с качеством данных.
Определение рабочего процесса преобразования и правил сопоставления: в зависимости от количества источников данных, степени их неоднородности и «грязности» данных может потребоваться выполнение большого количества шагов преобразования и очистки данных. Иногда перевод схемы используется для сопоставления источников с общей моделью данных; для хранилищ данных обычно используется реляционное представление. Ранние шаги по очистке данных могут исправить проблемы с записи из одного источника и подготовить данные для интеграции. Дальнейшие шаги касаются интеграции схемы / данных и устранения проблем с записями с несколькими источниками, например, дубликатов. Для хранилищ данных управление и поток данных для этих шагов преобразования и очистки должны быть указаны в рабочем процессе, который определяет процесс ETL (рис. 1).
Преобразования данных, связанные со схемой, а также этапы очистки должны быть указаны с помощью декларативного языка запросов и сопоставления, насколько это возможно, чтобы обеспечить автоматическое создание кода преобразования. Кроме того, должна быть возможность вызывать написанный пользователем код очистки и специальные инструменты во время рабочего процесса преобразования данных. На этапах преобразования могут запрашиваться отзывы пользователей о записях данных, для которых у них нет встроенной логики очистки.
Проверка: правильность и эффективность рабочего процесса преобразования и определений преобразования следует тестировать и оценивать, например, на образце или копии исходных данных, чтобы при необходимости улучшить определения. Может потребоваться несколько итераций этапов анализа, проектирования и проверки, например, поскольку некоторые ошибки становятся очевидными только после применения некоторых преобразований.
Трансформация: выполнение шагов преобразования либо путем запуска рабочего процесса ETL для загрузки и обновления хранилища данных, либо во время ответа на запросы из нескольких источников.
Обратный поток очищенных данных: после удаления ошибок (из одного источника) очищенные данные также должны заменять грязные данные в исходных источниках, чтобы предоставить устаревшим приложениям также улучшенные данные и избежать повторения работы по очистке для будущего извлечения данных. . Для хранилищ данных очищенные данные доступны из области подготовки данных (рис. 1).
Процесс преобразования, очевидно, требует большого количества метаданных, таких как схемы, характеристики данных на уровне записи, сопоставления преобразований, определения рабочих процессов и т. Д. Для обеспечения согласованности, гибкости и простоты повторного использования эти метаданные должны храниться в репозитории на основе СУБД [ 4]. Для обеспечения качества данных должна быть записана подробная информация о процессе преобразования как в репозитории, так и в преобразованных записях, в частности информация о полноте и свежести исходных данных и информация о происхождении о происхождении преобразованных объектов и примененных изменениях. им. Например, на рис. 3 производная таблица Customers содержит атрибуты CID и Cno, позволяющие отследить исходные записи.
Далее мы более подробно описываем возможные подходы к анализу данных (обнаружению конфликтов), определению трансформации и разрешению конфликтов. Что касается подходов к трансляции схемы и интеграции схемы, мы обращаемся к литературе, поскольку эти проблемы были подробно изучены и описаны [2] [24] [26]. Конфликты имен обычно разрешаются путем переименования; структурные конфликты требуют частичной реструктуризации и объединения входных схем.
3.1 Анализ данных
Метаданных, отраженных в схемах, обычно недостаточно для оценки качества данных источника, особенно если соблюдаются лишь несколько ограничений целостности. Таким образом, важно проанализировать фактические записи, чтобы получить реальные (переработанные) метаданные о характеристиках данных или необычных шаблонах значений. Эти метаданные помогают находить проблемы с качеством данных. Более того, он может эффективно способствовать идентификации соответствий атрибутов между исходными схемами (сопоставление схем), на основе которых могут производиться автоматические преобразования данных [20] [9].
Существует два связанных подхода к анализу данных, профилированию данных и интеллектуальному анализу данных. Профилирование данных сосредоточено на анализе отдельных атрибутов записей. Он извлекает такую информацию, как тип данных, длина, диапазон значений, дискретные значения и их частота, дисперсия, уникальность, наличие нулевых значений, типичный строковый шаблон (например, для телефонных номеров) и т.д., Обеспечивая точное представление различного качества аспекты атрибута. В таблице 3 показаны примеры того, как эти метаданные могут помочь в обнаружении проблем с качеством данных.
Таблица 4. Примеры использования переработанных метаданных для решения проблем качества данных
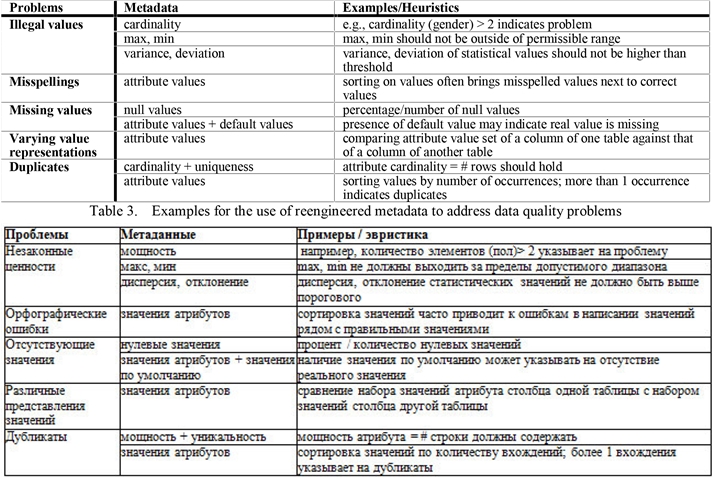
Поиск данных помогает обнаруживать определенные закономерности данных в больших наборах данных, например, взаимосвязи между нескольких атрибутов. На этом сосредоточены так называемые модели описательного интеллектуального анализа данных, включая кластеризацию, обобщение, обнаружение ассоциаций и обнаружение последовательностей [10]. Как показано в [28], ограничения целостности среди атрибутов, таких как функциональные зависимости или «бизнес-правила» для конкретных приложений, могут быть выведены, что может быть использовано для восполнения пропущенных значений, исправления недопустимых значений и выявления повторяющихся записей в источниках данных. Например, правило ассоциации с высокой степенью достоверности может указывать на проблемы с качеством данных в записи, нарушающие это правило. Таким образом, достоверность 99% для правила «всего = количество * цена за единицу» означает, что 1% записей не соответствует требованиям и может потребовать более тщательного изучения.
3.2 Определение преобразований данных
Процесс преобразования данных обычно состоит из нескольких этапов, каждый из которых может выполнять преобразования (сопоставления), связанные со схемой и записью. Чтобы позволить системе преобразования и очистки данных генерировать код преобразования и, таким образом, уменьшить объем самопрограммирования, необходимо указать необходимые преобразования на соответствующем языке, например, поддерживаемом графическим пользовательским интерфейсом.
Различные инструменты ETL (см. Раздел 4) предлагают эту функциональность, поддерживая собственные языки правил. Более общий и гибкий подход - это использование стандартного языка запросов SQL для выполнения преобразований данных и использования возможностей языковых расширений для конкретных приложений, в частности определяемых пользователем функций (UDF), поддерживаемых в SQL: 99 [13] [14]. UDF могут быть реализованы на SQL или в универсальном язык программирования со встроенными операторами SQL. Они позволяют реализовать широкий спектр преобразований данных и поддерживают простое повторное использование для различных задач преобразования и обработки запросов. Кроме того, их выполнение СУБД может снизить стоимость доступа к данным и, таким образом, повысить производительность. Наконец, UDF являются частью стандарта SQL: 99 и должны (в конечном итоге) быть переносимыми на многие платформы и СУБД.

На рис. 4 показан шаг преобразования, указанный в SQL 99. Пример ссылается на рис. 3 и охватывает часть необходимых преобразований данных, которые должны быть применены к первому источнику. Преобразование определяет представление, в котором могут выполняться дальнейшие сопоставления. Преобразование выполняет реструктуризацию схемы с дополнительными атрибутами в представлении, полученном путем разделения атрибутов имени и адреса источника. Необходимые данные извлечение осуществляется с помощью UDF (выделено жирным шрифтом). Реализации UDF могут содержать логику очистки, например, для удаления орфографических ошибок в названиях городов или предоставления отсутствующих почтовых индексов.
UDF могут по-прежнему требовать значительных усилий по реализации и не поддерживать всю необходимую схему. трансформации. В частности, простые и часто необходимые функции, такие как разделение или объединение атрибутов, в общем случае не поддерживаются, но их часто необходимо повторно реализовать в вариациях для конкретных приложений (см. Конкретные функции извлечения на рис. 4).
Более сложные реструктуризации схемы (например, сворачивание и разворачивание атрибутов) вообще не поддерживаются. Для общей поддержки преобразований, связанных со схемой, требуются языковые расширения, такие как предложение SchemaSQL [18]. Очистка данных на уровне записи также может выиграть от специальных языковых расширений, таких как оператор Match, поддерживающий «приблизительные объединения» (см. ниже). Системная поддержка таких мощных операторов может значительно упростить программирование преобразований данных и повысить производительность. Некоторые текущие исследовательские работы по очистке данных исследуют полезность и реализацию таких расширений языка запросов [11] [25].
3.3 Разрешение конфликтов
Необходимо указать и выполнить набор шагов преобразования для решения различных проблем качества данных на уровне схемы и записи, которые отражаются в имеющихся источниках данных. Для отдельных источников данных необходимо выполнить несколько типов преобразований, чтобы решить проблемы с одним источником и подготовиться к интеграции с другими источниками. Помимо возможного перевода схемы, эти подготовительные шаги обычно включают:
Извлечение значений из атрибутов произвольной формы (разделение атрибутов): атрибуты произвольной формы часто захватывают несколько отдельных значений, которые должны быть извлечены для достижения более точного представления и поддержки дальнейших шагов очистки, таких как сопоставление записей и устранение дубликатов. Типичными примерами являются поля имени и адреса (Таблица 2, Рис. 3, Рис. 4). Требуемые преобразования на этом этапе - это переупорядочивание значений в поле для работы с транспозициями слов и извлечение значений для разделения атрибутов.
Проверка и исправление: этот шаг проверяет каждый исходная запись на наличие ошибок ввода данных и пытается исправить их автоматически, насколько это возможно. Проверка орфографии на основе поиска в словаре полезна для выявления и исправления орфографических ошибок. Кроме того, словари по географическим названиям и почтовым индексам помогают исправлять адресные данные. Зависимости атрибутов (дата рождения - возраст, общая цена - цена / количество за единицу, город - код города и т. Д.) Могут использоваться для обнаружения проблем и замены отсутствующих значений или исправления неправильных значений.
Стандартизация: для облегчения сопоставления и интеграции записей значения атрибутов должны быть преобразованы в согласованный и унифицированный формат. Например, записи даты и времени должны быть приведены в конкретный формат; имена и другие строковые данные должны быть преобразованы в верхний или нижний регистр и т. д. Текстовые данные можно сжать и объединить, выполнив выделение корней, удалив префиксы, суффиксы и стоп-слова. Кроме того, сокращения и схемы кодирования следует последовательно разрешать, обращаясь к специальным словарям синонимов или применяя предопределенные правила преобразования.
Решение проблем с несколькими источниками требует реструктуризации схем для достижения интеграции схемы, включая такие шаги, как разделение, слияние, сворачивание и разворачивание атрибутов и таблиц. На уровне записи необходимо разрешить конфликтующие представления и иметь дело с перекрывающимися данными. Задача устранения дубликатов обычно выполняется после большинства других шагов преобразования и очистки, особенно после устранения ошибок единственного источника и конфликтующих представлений. Он выполняется либо на двух очищенных источниках одновременно, либо на одном уже интегрированном наборе данных. Для удаления дубликатов необходимо сначала идентифицировать (т.е. сопоставить) похожие записи, касающиеся одного и того же объекта реального мира. На втором этапе похожие записи объединяются в одну запись, содержащую все соответствующие атрибуты без избыточности. Кроме того, удаляются избыточные записи. Ниже мы обсудим ключевую проблему сопоставления записей. Более подробно об этом можно прочитать в другом месте этого выпуска [22].
В простейшем случае существует идентифицирующий атрибут или комбинация атрибутов для каждой записи, которая может использоваться для сопоставления записей, например, если разные источники используют один и тот же первичный ключ или есть другие общие уникальные атрибуты. Сопоставление записей между различными источниками затем достигается стандартным равным объединением идентифицирующих атрибутов. В случае одного набора данных совпадения могут быть определены путем сортировки по идентифицирующему атрибуту и проверки совпадения соседних записей. В обоих случаях эффективная реализация может быть достигнута даже для больших наборов данных. К сожалению, без общих ключевых атрибутов или при наличии грязных данных такие простые подходы часто бывают слишком ограничительными. Для определения большинства или всех совпадений становится необходимым «нечеткое сопоставление» (приблизительное объединение), которое находит похожие записи на основе правила сопоставления, например, заданного декларативно или реализованного с помощью определяемой пользователем функции [14] [11]. Например, такое правило может указывать, что записи о людях, скорее всего, будут соответствовать, если совпадают имя и части адреса. Степень сходства между двумя записями, часто измеряемая числовым значением от 0 до 1, обычно зависит от характеристик приложения. Например, разные атрибуты в правиле сопоставления могут вносить различный вес в общую степень сходства. Для строковых компонентов (например, имя клиента, компания name,…) точное соответствие и нечеткие подходы, основанные на подстановочных знаках, частоте символов, расстоянии редактирования, расстоянии клавиатуры и фонетическом сходстве (soundex), полезны [11] [15] [19]. Более сложные подходы к сопоставлению строк, также учитывающие сокращения, представлены в [23]. Общий подход к сопоставлению как строковых, так и текстовых данных - использование общих показателей поиска информации. WHIRL представляет собой многообещающего представителя этой категории, использующего косинусное расстояние в векторно-пространственной модели для определения степени сходства между текстовыми элементами [7].
Определение совпадающих записей с помощью такого подхода обычно является очень дорогостоящей операцией для больших наборов данных. Вычисление значения подобия для любых двух записей подразумевает оценку правила сопоставления на декартовом произведении входных данных. Кроме того, сортировка по значению сходства необходима для определения совпадающих записей, охватывающих повторяющуюся информацию. Все записи, для которых значение сходства превышает пороговое значение, могут рассматриваться как совпадения или как кандидаты на совпадение, которые должны быть подтверждены или отклонены пользователем. В [15] предлагается многопроходный подход, например согласование для уменьшения накладных расходов. Он основан на сопоставлении записей независимо по разным атрибутам и комбинировании различных результатов сопоставления. Предполагая, что входной файл один, каждый проход сопоставления сортирует записи по определенному атрибуту и проверяет только соседние записи в определенном окне на предмет того, удовлетворяют ли они заранее определенному правилу сопоставления. Это значительно сокращает количество оценок правил соответствия по сравнению с подходом декартовых произведений. Полный набор совпадений получается путем объединения пар совпадающих каждого прохода и их транзитивного замыкания.
4. Инструменты
На рынке доступно большое количество инструментов для поддержки задач преобразования и очистки данных, в частности, для хранилищ данных.1 Некоторые инструменты концентрируются на определенной области, такой как очистка имени и адресных данных, или конкретной стадии очистки, например анализ данных или устранение дубликатов. Из-за своей ограниченной области применения специализированные инструменты обычно работают очень хорошо, но их необходимо дополнять другими инструментами для решения широкого спектра задач преобразования и очистки. Другие инструменты, например инструменты ETL, предоставляют возможности комплексного преобразования и рабочего процесса, охватывающие большую часть процесса преобразования и очистки данных. Общей проблемой инструментов ETL является их ограниченная совместимость из-за проприетарных интерфейсов прикладного программирования (API) и проприетарных форматов метаданных, что затрудняет объединение функциональности нескольких инструментов [8].
Сначала мы обсудим инструменты для анализа данных и реинжиниринга данных, которые обрабатывают данные записи для выявления ошибок и несоответствий данных, а также для получения соответствующих преобразований очистки. Затем мы представляем специализированные инструменты для очистки и инструменты ETL соответственно.
4.1 Инструменты анализа данных и реинжиниринга
Согласно нашей классификации в 3.1, инструменты анализа данных можно разделить на инструменты профилирования данных и интеллектуального анализа данных. MIGRATIONARCHITECT (Evoke Software) - один из немногих коммерческих инструментов профилирования данных. Для каждого атрибута он определяет следующие реальные метаданные: тип данных, длину, количество элементов, дискретные значения и их процентное соотношение, минимальные и максимальные значения, пропущенные значения и уникальность. MIGRATIONARCHITECT также помогает в разработке целевой схемы для миграции данных. Инструменты интеллектуального анализа данных, такие как WIZRULE (WizSoft) и DATAMININGSUITE (Information Discovery), определяют отношения между атрибутами и их значениями и вычисляют степень достоверности, указывающую количество подходящих строк. В частности, WIZRULE может отображать три типа правил: математические формулы, правила «если-то» и правила на основе правописания, указывающие имена с ошибками, например, «значение Edinburgh появляется 52 раза в поле« Клиент »; 2 случая (а) содержат аналогичное (ые) значение (а) ». WIZRULE также автоматически указывает на отклонения от набора обнаруженных правил как на предполагаемые ошибки.
Инструменты реинжиниринга данных, например INTEGRITY (Vality), используют обнаруженные шаблоны и правила для определения и выполнения преобразований очистки, то есть реинжиниринга унаследованных данных. В INTEGRITY записи данных проходят несколько этапов анализа, таких как синтаксический анализ, набор данных, анализ шаблонов и частотный анализ. Результатом этих шагов является табличное представление содержимого полей, их шаблонов и частот, на основе которых можно выбрать шаблон для стандартизации данных. Для определения преобразований очистки INTEGRITY предоставляет язык, включающий набор операторов для преобразований столбцов (например, перемещения, разделения, удаления) и преобразования строк (например, слияния, разделения). ЦЕЛОСТНОСТЬ идентифицирует и объединяет записи, используя метод статистического сопоставления. Автоматические весовые коэффициенты используются для вычисления оценок для ранжирования совпадений, на основе которых пользователь может выбрать реальные дубликаты.
1 Полный список поставщиков и инструментов см. На коммерческих веб-сайтах, например, в Data Warehouse Information Center (www.dwinfocenter.org), Data Management Review (www.dmreview.com), Data Warehousing Institute (www.dwinstitute.com).
4.2 Специальные инструменты для очистки
Специализированные инструменты очистки обычно работают с определенным доменом, в основном с данными об именах и адресах, или концентрируются на устранении дубликатов. Преобразования должны предоставляться либо заранее в виде библиотеки правил, либо пользователем в интерактивном режиме. В качестве альтернативы преобразования данных могут быть автоматически получены с помощью инструментов сопоставления схем, таких как описанные в [21].
Специальная очистка домена: имена и адреса записываются во многих источниках и обычно имеют высокую мощность. Например, поиск совпадений с клиентами очень важен для управления взаимоотношениями с клиентами. Ряд коммерческих инструментов, например IDCENTRIC (FirstLogic), PUREINTEGRATE (Oracle), QUICKADDRESS (QASSystems), REUNION (PitneyBowes) и TRILLIUM (TrilliumSoftware), ориентированы на очистку таких данных. Они предоставляют такие методы, как извлечение и преобразование информации об именах и адресах в отдельные стандартные элементы, проверка названий улиц, городов и почтовых индексов в сочетании с функцией сопоставления на основе очищенных данных. Они включают в себя огромную библиотеку заранее определенных правил, касающихся проблем, обычно встречающихся при обработке этих данных. Например, модуль извлечения (парсер) и сопоставления TRILLIUM содержит более 200 000 бизнес-правил. Эти инструменты также предоставляют возможности для настройки или расширения библиотеки правил с помощью определяемых пользователем правил для конкретных нужд.
Устранение дубликатов: примеры инструментов для выявления и устранения дубликатов включают DATACLEANSER (EDD), MERGE / PURGELIBRARY (Sagent / QMSoftware), MATCHIT (HelpITSystems) и MASTERMERGE (PitneyBowes). Обычно они требуют, чтобы источники данных уже были очищены для сопоставления. Поддерживаются несколько подходов к сопоставлению значений атрибутов; такие инструменты, как DATACLEANSER и MERGE / PURGE LIBRARY, также позволяют интегрировать определенные пользователем правила сопоставления.
4.3 Инструменты ETL
Большое количество коммерческих инструментов комплексно поддерживают процесс ETL для хранилищ данных, например, COPYMANAGER (InformationBuilders), DATASTAGE (Informix / Ardent), EXTRACT (ETI), POWERMART (Informatica), DECISIONBASE (CA / Platinum), DATATRANSFORMATIONSERVICE. (Microsoft), METASUITE (Minerva / Carleton), SAGENTSOLUTIONPLATFORM (Sagent) и WAREHOUSEADMINISTRATOR (SAS). Они используют репозиторий, построенный на базе СУБД, для единообразного управления всеми метаданными об источниках данных, целевых схемах, сопоставлениях, программах-скриптах и ??т. Д. Схемы и данные извлекаются из рабочих источников данных как через собственные файловые шлюзы, так и через шлюзы СУБД, а также стандартные интерфейсы, такие как ODBC и EDA. Преобразования данных определяются с помощью простого в использовании графического интерфейса. Чтобы указать отдельные шаги сопоставления, обычно предоставляется собственный язык правил и обширная библиотека предопределенных функций преобразования. Инструменты также поддерживают повторное использование существующих решений преобразования, таких как внешние подпрограммы C / C ++, предоставляя интерфейс для их интеграции во внутреннюю библиотеку преобразования. Обработка преобразований выполняется либо механизмом, который интерпретирует указанные преобразования во время выполнения, либо скомпилированным кодом. Все инструменты на основе движка (например, COPYMANAGER, DECISIONBASE, POWERMART, DATASTAGE, WAREHOUSEADMINISTRATOR) имеют планировщик и поддерживают рабочие процессы со сложными зависимостями выполнения между заданиями сопоставления. Рабочий процесс также может вызывать внешние инструменты, например, для специализированных задач очистки, таких как очистка имени / адреса или удаление дубликатов.
Инструменты ETL обычно имеют мало встроенных возможностей очистки данных, но позволяют пользователю указать функциональность очистки через собственный API. Обычно нет поддержки анализа данных для автоматического обнаружения ошибок и несоответствий в данных. Однако пользователи могут реализовать такую логику с сохранением метаданных и определением характеристик контента с помощью функций агрегирования (сумма, количество, минимум, максимум, медиана, дисперсия, отклонение и т. Д.). Предоставленная библиотека преобразования покрывает многие потребности в преобразовании и очистке данных, такие как преобразование типов данных (например, переформатирование даты), строковые функции (например, разделение, слияние, замена, поиск подстроки), арифметические, научные и статистические функции и т. Д. Извлечение значений из атрибутов произвольной формы не является полностью автоматическим, но пользователь должен указать разделители, разделяющие вложенные значения.
Языки правил обычно охватывают конструкции if-then и case, которые помогают обрабатывать исключения в значениях данных, такие как орфографические ошибки, сокращения, пропущенные или загадочные значения и значения за пределами диапазона. Эти проблемы также можно решить, используя конструкцию поиска в таблице и функциональность соединения. Поддержка сопоставления записей обычно ограничивается использованием конструкции соединения и некоторых простых функций сопоставления строк, например, точное сопоставление или сопоставление с подстановочными знаками и soundex. Тем не менее, определяемые пользователем функции сопоставления полей, а также функции сопоставления сходств полей могут быть запрограммированы и добавлены во внутреннюю библиотеку преобразования.
5. Выводы
Мы представили классификацию проблем качества данных в источниках данных, дифференцируя их между одним и несколькими источниками, а также между проблемами на уровне схемы и на уровне записи. Мы далее обрисовали в общих чертах основные шаги по преобразованию и очистке данных и подчеркнули необходимость интегрированного охвата преобразований данных, связанных со схемой и записью. Кроме того, мы предоставили обзор коммерческих инструментов для очистки данных. Несмотря на то, что уровень развития этих инструментов является достаточно продвинутым, они обычно покрывают только часть проблемы и по-прежнему требуют значительных усилий вручную или самопрограммирования. Кроме того, их совместимость ограничена (проприетарные API и представления метаданных).
Пока что появилось лишь небольшое исследование по очистке данных, хотя большое количество инструментов указывает как на важность, так и на сложность проблемы очистки. Мы видим несколько тем, заслуживающих дальнейшего изучения. Прежде всего, требуется дополнительная работа по разработке и реализации наилучшего языкового подхода для поддержки преобразований схем и данных. Например, такие операторы, как Match, Merge или Mapping Composition, были изучены либо на уровне записи (данные), либо на уровне схемы (метаданные), но могут быть построены на аналогичных методах реализации. Очистка данных необходима не только для хранилищ данных, но и для обработки запросов к разнородным источникам данных, например, в сетевых информационных системах. Эта среда создает гораздо более жесткие ограничения производительности для очистки данных, которые необходимо учитывать при разработке подходящих подходов. Кроме того, очистка данных для полуструктурированных данных, например, на основе XML, вероятно, будет иметь большое значение, учитывая уменьшенные структурные ограничения и быстро увеличивающийся объем XML-данных.
Acknowledgments
We would like to thank Phil Bernstein, Helena Galhardas and Sunita Sarawagi for helpful comments.
References
[1] Abiteboul, S.; Clue, S.; Milo, T.; Mogilevsky, P.; Simeon, J.: Tools for Data Translation and Integration. In [26]:3-8, 1999.
[2] Batini, C.; Lenzerini, M.; Navathe, S.B.: A Comparative Analysis of Methodologies for Database Schema Integration. In Computing Surveys 18(4):323-364, 1986.
[3] Bernstein, P.A.; Bergstraesser, T.: Metadata Support for Data Transformation Using Microsoft Repository. In [26]:9-14, 1999
[4] Bernstein, P.A.; Dayal, U.: An Overview of Repository Technology. Proc. 20th VLDB, 1994.
[5] Bouzeghoub, M.; Fabret, F.; Galhardas, H.; Pereira, J; Simon, E.; Matulovic, M.: Data Warehouse Refreshment. In [16]:47-67.
[6] Chaudhuri, S., Dayal, U.: An Overview of Data Warehousing and OLAP Technology. ACM SIGMOD Record 26(1), 1997.
[7] Cohen, W.: Integration of Heterogeneous Databases without Common Domains Using Queries Based Textual Similarity. Proc. ACM SIGMOD Conf. on Data Management, 1998.
[8] Do, H.H.; Rahm, E.: On Metadata Interoperability in Data Warehouses. Techn. Report, Dept. of Computer Science, Univ. of Leipzig. http://dol.uni-leipzig.de/pub/2000-13.
[9] Doan, A.H.; Domingos, P.; Levy, A.Y.: Learning Source Description for Data Integration. Proc. 3rd Intl. Workshop The Web and Databases (WebDB), 2000.
[10] Fayyad, U.: Mining Database: Towards Algorithms for Knowledge Discovery. IEEE Techn. Bulletin Data Engineering 21(1), 1998.
[11] Galhardas, H.; Florescu, D.; Shasha, D.; Simon, E.: Declaratively cleaning your data using AJAX. In Journees Bases de Donnees, Oct. 2000. http://caravel.inria.fr/~galharda/BDA.ps.
[12] Galhardas, H.; Florescu, D.; Shasha, D.; Simon, E.: AJAX: An Extensible Data Cleaning Tool. Proc. ACM SIGMOD Conf., p. 590, 2000.
[13] Haas, L.M.; Miller, R.J.; Niswonger, B.; Tork Roth, M.; Schwarz, P.M.; Wimmers, E.L.: Transforming Heterogeneous
Data with Database Middleware: Beyond Integration. In [26]:31-36, 1999.
[14] Hellerstein, J.M.; Stonebraker, M.; Caccia, R.: Independent, Open Enterprise Data Integration. In [26]:43-49, 1999.
[15] Hernandez, M.A.; Stolfo, S.J.: Real-World Data is Dirty: Data Cleansing and the Merge/Purge Problem. Data Mining and Knowledge Discovery 2(1):9-37, 1998.
[16] Jarke, M., Lenzerini, M., Vassiliou, Y., Vassiliadis, P.: Fundamentals of Data Warehouses. Springer, 2000.
[17] Kashyap, V.; Sheth, A.P.: Semantic and Schematic Similarities between Database Objects: A Context-Based Approach. VLDB Journal 5(4):276-304, 1996.
[18] Lakshmanan, L.; Sadri, F.; Subramanian, I.N.: SchemaSQL – A Language for Interoperability in Relational Multi-Database Systems. Proc. 26th VLDB, 1996.
[19] Lee, M.L.; Lu, H.; Ling, T.W.; Ko, Y.T.: Cleansing Data for Mining and Warehousing. Proc. 10th Intl. Conf. Database and Expert Systems Applications (DEXA), 1999.
[20] Li, W.S.; Clifton, S.: SEMINT: A Tool for Identifying Attribute Correspondences in Heterogeneous Databases Using Neural Networks. In Data and Knowledge Engineering 33(1):49-84, 2000.
[21] Milo, T.; Zohar, S.: Using Schema Matching to Simplify Heterogeneous Data Translation. Proc. 24th VLDB, 1998.
[22] Monge, A. E. Matching Algorithm within a Duplicate Detection System. IEEE Techn. Bulletin Data Engineering
23 (4), 2000 (this issue).
[23] Monge, A. E.; Elkan, P.C.: The Field Matching Problem: Algorithms and Applications. Proc. 2nd Intl. Conf. Knowledge Discovery and Data Mining (KDD), 1996.
[24] Parent, C.; Spaccapietra, S.: Issues and Approaches of Database Integration. Comm. ACM 41(5):166-178, 1998.
[25] Raman, V.; Hellerstein, J.M.: Potter's Wheel: An Interactive Framework for Data Cleaning. Working Paper, 1999. http://www.cs.berkeley.edu/~rshankar/papers/pwheel.pdf.
[26] Rundensteiner, E. (ed.): Special Issue on Data Transformation. IEEE Techn. Bull. Data Engineering 22(1), 1999.
[27] Quass, D.: A Framework for Research in Data Cleaning. Unpublished Manuscript. Brigham Young Univ., 1999
[28] Sapia, C.; Hofling, G.; Muller, M.; Hausdorf, C.; Stoyan, H.; Grimmer, U.: On Supporting the Data Warehouse
Design by Data Mining Techniques. Proc. GI-Workshop Data Mining and Data Warehousing, 1999.
[29] Savasere, A.; Omiecinski, E.; Navathe, S.: An Efficient Algorithm for Mining Association Rules in Large Databases. Proc. 21st VLDB, 1995.
[30] Srikant, R.; Agrawal, R.: Mining Generalized Association Rules. Proc. 21st VLDB conf., 1995.
[31] Tork Roth, M.; Schwarz, P.M.: Don’t Scrap It, Wrap It! A Wrapper Architecture for Legacy Data Sources. Proc.23rd VLDB, 1997.
[32] Wiederhold, G.: Mediators in the Architecture of Future Information Systems. Computer 25(3): 38-49, 1992.

Shtucer
Божественный перевод. Но мне кажется, что в процессе перевода текст хорошо так "почистили" от половины слов. Очень понравилось, например, такое: "Очистка данных, также называемая очисткой или очисткой данных".