
Периодически возникали проблемы, что конфиг генерился синтаксически неправильным — и после рестарта сервис падал. Добавили в скрипт рестарта проверку синтаксиса (dhcpd -t), падения прекратились. Ну и со стороны билинга обвешано проверками — на наличие адреса, мака, и т.п.
Пару раз столкнулись с ситуацией, когда из сети приходят запросы, а ответы в сеть не доходят. Оказался виноват агрегатор, полечили. Все это время не хватало простого графического анализа — как работает DHCP сервер. Как показал опыт разборок с проблемами — банальным просмотром логов и оценкой, сколько каких сообщений принимает и отсылает сервер — можно уже примерно оценить наличие проблемы в сети. Ну и в принципе график можно показать ночному оператору с инструкцией — если здесь резкое изменение показателей — звони админам.
Итак, формулируем перед собой задачу. Согласно стандарту, в протоколе DHCP существуют следующие типы сообщений:
DHCPDISCOVER — запрос клиента на наличие адресов
DHCPOFFER — предложение сервера на получение адреса
DHCPREQUEST — запрос клиента на получение адреса (предложенного сервером в DHCPOFFER)
DHCPACK — подтверждение сервера о выдаче адреса
DHCPDECLINE — отказ клиента в получении предложенного адреса
DHCPNAK — отказ сервера в выдаче запрошенного адреса
DHCPRELEASE — уведомление клиента об освобождении адреса
DHCPINFORM — запрос клиента о дополнительных параметрах
Мы хотим построить график к-ва каждого типа сообщений.
В качестве источника информации можно использовать log файл сервера. Другого источника я не нашел, да и его не может быть особо — если предположить, что dhcp умеет где то у себя накапливать эту информацию — то во первых были бы средства извлечения такой статистики, А во вторых — постоянные рестарты процесса сводят ее полезность к нулю.
В нашей сети dhcp сервера — это отдельные виртуалки, машина, которая строит графики (называется mrtg) — тоже отдельная виртуалка. Т.е. нужен способ передачи информации между машинами.
В результате я реализовал вот такую схему. На dhcp сервере добавляем в конфиг:
log-facility local6
В syslog (эти виртуалки до сих пор работают на centos 5, аптайм машин год, было бы больше, если бы в нашем городе год назад свет не выключали на месяц) добавляем следующее:
*.info;mail.none;authpriv.none;cron.none;local6.none /var/log/messages
local6.* /var/log/dhcpd.log
local6.* /var/log/dhcpd-stat.log
Т.е. запрещаем local6 выводится в общий файл /var/log/messages, а выводим его в два файла одновременно.
Следующим шагом учим mrtg ходить на dhcp по ключу без пароля. Ну и вот такой скриптик на mrtg:
#!/bin/bash
for HOST in dhcp1 dhcp2
do
TARGET=/srv/www/noc.lds.net.ua/dhcp/$HOST
mkdir -p $TARGET
cd $TARGET
scp $HOST:/var/log/dhcpd-stat.log ./
ssh $HOST "echo -n > /var/log/dhcpd-stat.log"
if [ ! -f dhcpqueries.rrd ]
then
/usr/bin/rrdtool create dhcpqueries.rrd DS:request:GAUGE:600:0:10000000 DS:ack:GAUGE:600:0:10000000 DS:decline:GAUGE:600:0:10000000 DS:discover:GAUGE:600:0:10000000 DS:release:GAUGE:600:0:10000000 DS:nak:GAUGE:600:0:10000000 DS:info:GAUGE:600:0:10000000 DS:offer:GAUGE:600:0:10000000 RRA:AVERAGE:0.5:1:800 RRA:AVERAGE:0.5:6:800 RRA:AVERAGE:0.5:24:800 RRA:AVERAGE:0.5:288:800 RRA:MAX:0.5:1:800 RRA:MAX:0.5:6:800 RRA:MAX:0.5:24:800 RRA:MAX:0.5:288:800
fi
out=$(awk '
BEGIN {request=0;ack=0;decline=0;discover=0;release=0;nak=0;info=0;offer=0}
{
if($6 == "DHCPREQUEST") {request = request + 1}
if($6 == "DHCPACK") {ack = ack + 1}
if($6 == "DHCPDECLINE") {decline = decline + 1}
if($6 == "DHCPDISCOVER") {discover = discover + 1}
if($6 == "DHCPRELEASE") {release = release + 1}
if($6 == "DHCPNAK") {nak = nak + 1}
if($6 == "DHCPINFORM") {info = info + 1}
if($6 == "DHCPOFFER") {offer = offer + 1}
}
END {print request ":" ack ":" decline ":" discover ":" release ":" nak ":" info ":" offer}
' dhcpd-stat.log)
/usr/bin/rrdtool update dhcpqueries.rrd --template request:ack:decline:discover:release:nak:info:offer N:$out
/usr/bin/rrdtool graph dhcprequest.png -v "Requests/Minute" --rigid -l 0 --start -86400 DEF:a=dhcpqueries.rrd:request:AVERAGE DEF:b=dhcpqueries.rrd:ack:AVERAGE DEF:c=dhcpqueries.rrd:decline:AVERAGE DEF:d=dhcpqueries.rrd:discover:AVERAGE DEF:e=dhcpqueries.rrd:release:AVERAGE DEF:f=dhcpqueries.rrd:nak:AVERAGE DEF:g=dhcpqueries.rrd:info:AVERAGE DEF:h=dhcpqueries.rrd:offer:AVERAGE CDEF:cdefa=a,5,/ CDEF:cdefb=b,5,/ CDEF:cdefc=c,5,/ CDEF:cdefd=d,5,/ CDEF:cdefe=e,5,/ CDEF:cdeff=f,5,/ CDEF:cdefg=g,5,/ CDEF:cdefh=h,5,/ LINE1:cdefa#9C7BBD:DHCPREQUEST GPRINT:cdefa:LAST:" Cur\:%8.1lf" GPRINT:cdefa:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefa:MAX:"Max\:%8.1lf\n" LINE1:cdefb#3152A5:DHCPACK GPRINT:cdefb:LAST:" Cur\:%8.1lf" GPRINT:cdefb:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefb:MAX:"Max\:%8.1lf\n" LINE1:cdefc#750F7D:DHCPDECLINE GPRINT:cdefc:LAST:" Cur\:%8.1lf" GPRINT:cdefc:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefc:MAX:"Max\:%8.1lf\n" LINE1:cdefd#157419:DHCPDISCOVER GPRINT:cdefd:LAST:" Cur\:%8.1lf" GPRINT:cdefd:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefd:MAX:"Max\:%8.1lf\n" LINE1:cdefe#6DC8FE:DHCPRELEASE GPRINT:cdefe:LAST:" Cur\:%8.1lf" GPRINT:cdefe:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefe:MAX:"Max\:%8.1lf\n" LINE1:cdeff#FFAB00:DHCPNAK GPRINT:cdeff:LAST:" Cur\:%8.1lf" GPRINT:cdeff:AVERAGE:"Ave\:%8.1lf" GPRINT:cdeff:MAX:"Max\:%8.1lf\n" LINE1:cdefg#FF0000:DHCPINFORM GPRINT:cdefg:LAST:" Cur\:%8.1lf" GPRINT:cdefg:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefg:MAX:"Max\:%8.1lf\n" LINE1:cdefh#00FF00:DHCPOFFER GPRINT:cdefh:LAST:" Cur\:%8.1lf" GPRINT:cdefh:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefh:MAX:"Max\:%8.1lf\n"
/usr/bin/rrdtool graph dhcprequest-weekly.png -v "Requests/Minute" --rigid -l 0 --start -604800 DEF:a=dhcpqueries.rrd:request:AVERAGE DEF:b=dhcpqueries.rrd:ack:AVERAGE DEF:c=dhcpqueries.rrd:decline:AVERAGE DEF:d=dhcpqueries.rrd:discover:AVERAGE DEF:e=dhcpqueries.rrd:release:AVERAGE DEF:f=dhcpqueries.rrd:nak:AVERAGE DEF:g=dhcpqueries.rrd:info:AVERAGE DEF:h=dhcpqueries.rrd:offer:AVERAGE CDEF:cdefa=a,5,/ CDEF:cdefb=b,5,/ CDEF:cdefc=c,5,/ CDEF:cdefd=d,5,/ CDEF:cdefe=e,5,/ CDEF:cdeff=f,5,/ CDEF:cdefg=g,5,/ CDEF:cdefh=h,5,/ LINE1:cdefa#9C7BBD:DHCPREQUEST GPRINT:cdefa:LAST:" Cur\:%8.1lf" GPRINT:cdefa:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefa:MAX:"Max\:%8.1lf\n" LINE1:cdefb#3152A5:DHCPACK GPRINT:cdefb:LAST:" Cur\:%8.1lf" GPRINT:cdefb:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefb:MAX:"Max\:%8.1lf\n" LINE1:cdefc#750F7D:DHCPDECLINE GPRINT:cdefc:LAST:" Cur\:%8.1lf" GPRINT:cdefc:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefc:MAX:"Max\:%8.1lf\n" LINE1:cdefd#157419:DHCPDISCOVER GPRINT:cdefd:LAST:" Cur\:%8.1lf" GPRINT:cdefd:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefd:MAX:"Max\:%8.1lf\n" LINE1:cdefe#6DC8FE:DHCPRELEASE GPRINT:cdefe:LAST:" Cur\:%8.1lf" GPRINT:cdefe:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefe:MAX:"Max\:%8.1lf\n" LINE1:cdeff#FFAB00:DHCPNAK GPRINT:cdeff:LAST:" Cur\:%8.1lf" GPRINT:cdeff:AVERAGE:"Ave\:%8.1lf" GPRINT:cdeff:MAX:"Max\:%8.1lf\n" LINE1:cdefg#FF0000:DHCPINFORM GPRINT:cdefg:LAST:" Cur\:%8.1lf" GPRINT:cdefg:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefg:MAX:"Max\:%8.1lf\n" LINE1:cdefh#00FF00:DHCPOFFER GPRINT:cdefh:LAST:" Cur\:%8.1lf" GPRINT:cdefh:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefh:MAX:"Max\:%8.1lf\n"
/usr/bin/rrdtool graph dhcprequest-monthly.png -v "Requests/Minute" --rigid -l 0 --start -2592000 DEF:a=dhcpqueries.rrd:request:AVERAGE DEF:b=dhcpqueries.rrd:ack:AVERAGE DEF:c=dhcpqueries.rrd:decline:AVERAGE DEF:d=dhcpqueries.rrd:discover:AVERAGE DEF:e=dhcpqueries.rrd:release:AVERAGE DEF:f=dhcpqueries.rrd:nak:AVERAGE DEF:g=dhcpqueries.rrd:info:AVERAGE DEF:h=dhcpqueries.rrd:offer:AVERAGE CDEF:cdefa=a,5,/ CDEF:cdefb=b,5,/ CDEF:cdefc=c,5,/ CDEF:cdefd=d,5,/ CDEF:cdefe=e,5,/ CDEF:cdeff=f,5,/ CDEF:cdefg=g,5,/ CDEF:cdefh=h,5,/ LINE1:cdefa#9C7BBD:DHCPREQUEST GPRINT:cdefa:LAST:" Cur\:%8.1lf" GPRINT:cdefa:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefa:MAX:"Max\:%8.1lf\n" LINE1:cdefb#3152A5:DHCPACK GPRINT:cdefb:LAST:" Cur\:%8.1lf" GPRINT:cdefb:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefb:MAX:"Max\:%8.1lf\n" LINE1:cdefc#750F7D:DHCPDECLINE GPRINT:cdefc:LAST:" Cur\:%8.1lf" GPRINT:cdefc:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefc:MAX:"Max\:%8.1lf\n" LINE1:cdefd#157419:DHCPDISCOVER GPRINT:cdefd:LAST:" Cur\:%8.1lf" GPRINT:cdefd:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefd:MAX:"Max\:%8.1lf\n" LINE1:cdefe#6DC8FE:DHCPRELEASE GPRINT:cdefe:LAST:" Cur\:%8.1lf" GPRINT:cdefe:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefe:MAX:"Max\:%8.1lf\n" LINE1:cdeff#FFAB00:DHCPNAK GPRINT:cdeff:LAST:" Cur\:%8.1lf" GPRINT:cdeff:AVERAGE:"Ave\:%8.1lf" GPRINT:cdeff:MAX:"Max\:%8.1lf\n" LINE1:cdefg#FF0000:DHCPINFORM GPRINT:cdefg:LAST:" Cur\:%8.1lf" GPRINT:cdefg:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefg:MAX:"Max\:%8.1lf\n" LINE1:cdefh#00FF00:DHCPOFFER GPRINT:cdefh:LAST:" Cur\:%8.1lf" GPRINT:cdefh:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefh:MAX:"Max\:%8.1lf\n"
/usr/bin/rrdtool graph dhcprequest-yearly.png -v "Requests/Minute" --rigid -l 0 --start -31536000 DEF:a=dhcpqueries.rrd:request:AVERAGE DEF:b=dhcpqueries.rrd:ack:AVERAGE DEF:c=dhcpqueries.rrd:decline:AVERAGE DEF:d=dhcpqueries.rrd:discover:AVERAGE DEF:e=dhcpqueries.rrd:release:AVERAGE DEF:f=dhcpqueries.rrd:nak:AVERAGE DEF:g=dhcpqueries.rrd:info:AVERAGE DEF:h=dhcpqueries.rrd:offer:AVERAGE CDEF:cdefa=a,5,/ CDEF:cdefb=b,5,/ CDEF:cdefc=c,5,/ CDEF:cdefd=d,5,/ CDEF:cdefe=e,5,/ CDEF:cdeff=f,5,/ CDEF:cdefg=g,5,/ CDEF:cdefh=h,5,/ LINE1:cdefa#9C7BBD:DHCPREQUEST GPRINT:cdefa:LAST:" Cur\:%8.1lf" GPRINT:cdefa:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefa:MAX:"Max\:%8.1lf\n" LINE1:cdefb#3152A5:DHCPACK GPRINT:cdefb:LAST:" Cur\:%8.1lf" GPRINT:cdefb:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefb:MAX:"Max\:%8.1lf\n" LINE1:cdefc#750F7D:DHCPDECLINE GPRINT:cdefc:LAST:" Cur\:%8.1lf" GPRINT:cdefc:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefc:MAX:"Max\:%8.1lf\n" LINE1:cdefd#157419:DHCPDISCOVER GPRINT:cdefd:LAST:" Cur\:%8.1lf" GPRINT:cdefd:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefd:MAX:"Max\:%8.1lf\n" LINE1:cdefe#6DC8FE:DHCPRELEASE GPRINT:cdefe:LAST:" Cur\:%8.1lf" GPRINT:cdefe:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefe:MAX:"Max\:%8.1lf\n" LINE1:cdeff#FFAB00:DHCPNAK GPRINT:cdeff:LAST:" Cur\:%8.1lf" GPRINT:cdeff:AVERAGE:"Ave\:%8.1lf" GPRINT:cdeff:MAX:"Max\:%8.1lf\n" LINE1:cdefg#FF0000:DHCPINFORM GPRINT:cdefg:LAST:" Cur\:%8.1lf" GPRINT:cdefg:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefg:MAX:"Max\:%8.1lf\n" LINE1:cdefh#00FF00:DHCPOFFER GPRINT:cdefh:LAST:" Cur\:%8.1lf" GPRINT:cdefh:AVERAGE:"Ave\:%8.1lf" GPRINT:cdefh:MAX:"Max\:%8.1lf\n"
if [ ! -f index.shtml ]
then
cat > ./index.shtml << END
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<HTML>
<HEAD>
<TITLE>$HOST</TITLE>
<META HTTP-EQUIV="Refresh" CONTENT="300">
<META HTTP-EQUIV="Cache-Control" content="no-cache">
<META HTTP-EQUIV="Pragma" CONTENT="no-cache">
<META HTTP-EQUIV="Expires" CONTENT="Mon, 04 Feb 2008 16:28:46 GMT">
<style type="text/css">
</style>
</HEAD>
<BODY bgcolor="#ffffff" text="#000000" link="#000000" vlink="#000000" alink="#000000">
<!--#include virtual="/menu.shtml" -->
<CENTER><H1><B>$HOST</B></H1></CENTER>
<TABLE BORDER=0 CELLPADDING=0 CELLSPACING=0 align="center">
<tbody>
<tr><td align="center"><b><h2>Query types</h2></b></td></tr>
<tr>
<td align="center">
<b>daily</B><br>
<IMG BORDER=0 SRC="dhcprequest.png"><br>
</td>
</tr>
<tr>
<td align="center">
<b>weekly</B><br>
<IMG BORDER=0 SRC="dhcprequest-weekly.png"><br>
</td>
</tr>
<tr>
<td align="center">
<b>monthly</B><br>
<IMG BORDER=0 SRC="dhcprequest-monthly.png"><br>
</td>
</tr>
<tr>
<td align="center">
<b>yearly</B><br>
<IMG BORDER=0 SRC="dhcprequest-yearly.png"><br>
</td>
</tr>
</tbody>
</table>
</BODY>
</HTML>
END
fi
done
Расскажу, как этот скрипт работает.
Для каждого dhcp сервера создается отдельный каталог на веб сервере. Затем, мы по scp забираем текущий dhcpd-stat.log с сервера, и следующей командой его очищаем. Для того, чтобы в следующий раз забрать лог файл за прошедшее время работы. Так как скрипт вызывается из крона каждые 5 минут, то наша статистика обрабатывает логи за 5 минут работы. Я более чем уверен, что за то время, которое проходит между командами копирования и очистки — в лог попадают какие то данные, которые я теряю. Но думаю, что несколько строк погоды не делают.
Заодно отвечу на вопрос — почему логи dhcp выводятся в два файла. Первый — это обычный лог, он ротейтится стандартным logrotate, не переписывается постоянно, предназначен для человека — если надо будет его почитать. Второй — для скрипта, каждые 5 минут очищается.
Ну а дальше в скрипте в принципе все должно быть понятно: инициализируем rrd базу, при ее отсуствии, с помощью awk считаем количество каждого типа сообщений, заносим в rrd базу, затем строим стандартную 4-ку картинок — дневной график, недельный график, месячный график, годовой график. Ну и создаем index.shtml, если его нету.
Скриптик начал работать, графики рисуются. Теперь видно сразу — работает dhcp, или нет…
Вот как выглядит график:
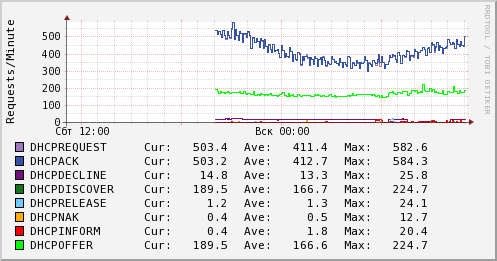
Комментарии (32)

gotch
21.09.2015 17:28Не для разжигания, разрешите рассказать, как это делается в Windows Server.
Запускаем Perfmon и добавляем счетчик DHCP Server-Request sec.
icCE
21.09.2015 18:04Я еще добавлю, что с 2012 там и failover нормальный и вполне работают вместе два dhcp.
Вообще способов решение такой проблемы много, включая всякие коммутаторы L3 или L2+ уровня.
martin74ua
23.09.2015 10:17Да не нужен мне файловер.
А какую проблему с построением графиков мы будем решать с помощью L3 коммутатора? А то у меня там пачка стоит в серверной, кошки всякие, экстримы… А графики не рисуют…icCE
23.09.2015 18:10>А какую проблему с построением графиков мы будем решать с помощью L3 коммутатора?
А какая там проблема есть?
Извините, но у вас чисто колхозный подход. Хренак хренак и в продакшен.
Я не хочу ходить со своим уставом в чужой монастырь, если у вас это все работает и устраивает — то ok.
Если у вас есть кошки и кошки нормальные и вызнаете как их готовить, то логично было бы использовать их.
Еще и NetFlow задействовать и собирать все в одно место типа zabbix.martin74ua
23.09.2015 18:20Какая проблема говорите… А вот неизвестно, какая проблема и есть ли.
Вот например — админ с кошки обращается ко мне и говорит — у меня тут второй час проц почти на полочке, а почему — непонятно. Искали долго. Но в конце концов добрался до лога dhcp. И просто смотрю его по tail -f, пытаясь понять — почему relay процесс на кошке проц кушает. И обращаю внимание, что чаще всего мне в логе DHCPOFFER попадается. Почитал повнимательней — нашел влан, в котором DHCPOFFER и сыпались. Ну и дальше нашли проблему — свичик с ума в городе сошел маленько. Причем ни штормконтроль, никто не реагировали…
И чем вас мой подход не устраивает? Я не обсуждаю структуру своей сети, не обсуждаю методику раздачи интернета. Я привел способ решения одной маленькой задачи в мониторинге. Прежде чем я начал писать все это — я сначала искал в интернетах, как люди поступают. И пришел к выводу, что никак. Судя по всему работоспособность DHCP принимается за аксиому. Т.е. запустили dhcp сервер — значит работает ;). Честно говоря я и сам так считал. Но подобного графика мне не хватало. Сейчас вот рисуется, смотрим. Если этот график мне через год поможет найти ровно одну проблему — значит я не зря его рисовал…icCE
23.09.2015 18:40>И чем вас мой подход не устраивает?
Направление верное, инструменты не те. Но опять же, тут личное мнение каждого. Если выбирать между никак и как то, лучше как то чем никак ;) Тут я с вами спорить вообще не буду.
На тему железок ситуация разные и много чего надо принимать в расчет. Приходилось помогать интегратору, у которого каждое утро DHCP молча умирал. Клиентов больше 2000. Если коротко, то машина просто не справлялась. Решили в приделах широковищательного домена поднимать DHCP на L2+, а запросы уже перенаправлять на умирающий сервер через option 82.
И да мониторинга там не было, поэтому я вашу боль прекрасно понимаю.martin74ua
23.09.2015 19:31Кхм. всего то 2к клиентов и dhcp сервер не справляется????? Или это единственный сервер во всей инфраструктуре, и на нем все крутится, или я даже не представляю. У меня просто на порядок больше, и LA на dhcp — не выше 0.1
А вот решение ваше я даже не понял. Ну добавили вы relay. А что для сервера то изменилось?
martin74ua
23.09.2015 10:16А дальше? Ну вот добавил. Но мне абсолютно неинтересно ходить на какой то сервер, и смотреть там какой то один график. Все нужные мне графики объединены на едином сервере. Как мне из этого «Perfmon» данные то получить? snmp подойдет, вот только где об этом почитать?
ЗЫ. Ну не ориентируюсь я в винде.icCE
23.09.2015 18:13У меня не было такой задачи, но решается она точно. Как минимум в винде есть snmp,wmi, а zabiix умеет Windows Event Log.

blind_oracle
21.09.2015 17:50+3В результате я реализовал вот такую схему.
Почему не отправлять логи сразу на нужный сервер через Syslog? Зачем лишний геморрой с SCP?
На целевом сервере можно уже либо методом аналогичным tail -f читать из скрипта логфайл в режиме реального времени, либо по крону.
Ну и вообще ни разу не энтерпрайзно. Правильный подход — написать скрипт, который будет готовить данные для единой системы мониторинга (заббикс, нагиос, кактус), а не рисовать на коленке графики сам.
Соответственно, в мониторинге нужно сделать триггеры чтобы он рассылал уведомления если что-то не так, а не оператор сидел и в графиках искал смысл жизни в ночи.
Ну и наконец, в ISC DHCP есть встроенный failover механизм, который отлично работает.
Городить два независимых сервера с идентичными конфигами мне кажется странным, тем более если это виртуалки.icCE
21.09.2015 18:06>ISC DHCP есть встроенный failover
а давно он там? РУками ISC DHCP давно не трогал.
Ну и ссылку на доку если ткнете, буду только рад почитать. (хотя думаю и сам найду)blind_oracle
21.09.2015 18:19Давно, несколько лет точно.
kb.isc.org/article/AA-00502/0/A-Basic-Guide-to-Configuring-DHCP-Failover.htmlicCE
21.09.2015 22:54ох время летит. Я как раз к этому моменту бросил ISC DHCP и перешел на dnsmasq, так как проще и быстрее.
martin74ua
21.09.2015 19:24не нужен файловер в dhcp. Двух серверов с идентичными конфигами хватает более чем.
Мониторинг есть, графики реализовал больше для себя — чтобы оценить нагрузку на сервера и посмотреть, как там оно работает ;)blind_oracle
21.09.2015 20:03не нужен файловер в dhcp. Двух серверов с идентичными конфигами хватает более чем.
И как они работают?
Обслуживают разные броадкаст домены?
Или оба слушают одинаковые домены и отвечают в режиме кто первый встал — того и тапки?
Раздают адреса из разных пулов?
В общем, не понятно зачем делать криво, если есть встроенный failover-функционал, который настраивается в несколько строчек в конфиге.martin74ua
21.09.2015 20:51сервера стоят за релеем. Оба слушают одинаковые домены — около 700 вланов. В каждом влане абоненты привязаны к маку. Т.е. в любом случае ответ от обоих серверов — одинаков. Для новых абонентов, поменянных устройств и т.п. — в каждом влане есть выделенный диапазон в 16 адресов. В этом диапазоне ответы идут по принципу кто первый встал, того и тапки. Судя по логам — ни разу не видел попытки выдать два разных адреса на один запрос. Обычно отвечает какой то один сервер, второй молчит, но отмечает у себя занятие адреса. Длительность аренды у меня установлена в 10 минут. На самом деле не имеет принципиального значения, какой именно адрес в гостевом диапазоне выдан — абонент заходит в личный кабинет и прописывает себе новый мак, после чего в течении 2 минут происходит перегенерация конфига dhcp, раз в 5 минут он разливается на сервера и примерно через час (винда не хочет добровольно освобождать адрес раньше, хоть лиза и выдается на 10 минут) у абонента уже закрепленный за ним адрес. Интернет мы раздаем по pppoe, работать он начинает сразу после указания абонентом мака в личном кабинете.
blind_oracle
21.09.2015 21:11Да уж, про механизм предоставления интернета я промолчу :) В наше-то время использовать привязку к маку, да ещё и с PPPoE наверченым поверх…
По серверам. У тебя получается, что сервера клиенту отвечают оба одновременно и клиент из них уже выбирает того, чей ответ пришёл первым и дальше с ним говорит уже по уникасту. В итоге у тебя куча лишнего траффика в сети получается.
Если сделать failover, то сервера между собой будут договариваться насчёт того кто будет выдавать аренду и отвечать клиенту будет только один из них.martin74ua
21.09.2015 22:08ну не такая уж и куча, как показывает практика ;)
имеем в среднем около 10-20 запросов в секунду. Из них отвечают оба сервера — это DHCPOFFER и DHCPACK. DHCPINFORM, которым запрашиваются доп параметры — уже не широковещательный.
failover я пробовал изначально. В результате на вторые-третьи сутки dhcp становились раком. Почему — уже не знаю, это было лет так 8 назад ;). С тех пор стоят два сервера, паралелльно они же еще и dns сервера для клиентов. Самые нетребовательные и беспроблемные виртуалки. Либо ошибка в конфиге, либо проблемы в транспорте. Других причин ошибок DHCP и не припомню за эти годы ;)blind_oracle
21.09.2015 22:21failover я пробовал изначально. В результате на вторые-третьи сутки dhcp становились раком. Почему — уже не знаю, это было лет так 8 назад ;)
У меня уже лет, наверное, пять пашет ОК, ни разу с нимм проблем не было.
Конфиги тоже генерятся централизованно и раскидываются по обоим серверам (за исключением failover блока в конфиге всё общее). Так что вполне юзабельно.martin74ua
21.09.2015 22:24Если честно — пока не вижу повода менять. Посмотрю на работу failover конечно, но не знаю, чем он мне пригодится ;)
blind_oracle
21.09.2015 22:38Конечно, менять просто ради того чтобы менять не надо. Но новые проекты логично делать по-правильному.
icCE
21.09.2015 22:56Так его как раз лет 5 назад нормально и сделали, а вот лет 8 назад действительно была попа боль.

Antti
21.09.2015 18:06Неужели еще кто-то делает такие скрипты «на коленке»?
Как мне казалось уже все давно перешли или на logstash+kibana, или sensu+grafana или на худой конец cacti/zabbix.
Hesed
21.09.2015 19:29Иногда. В моём случае «наколенный велосипед» предназначен для OpenNMS (тот же zabbix, только в профиль) и получение данных статистики идёт по SNMP. Единая система мониторинга, триггеры-алармы на всякие случаи и прочие плюшки.
Подтверждая слова blind_oracle об эффективности мониторинга только в случае возможности прописывать реакцию на отклонения от нормы, могу сказать, что не только о failover нужно заботится. Вот, например, так выглядит плохое поведение одного роутера Canyon, который генерирует DHCPDISCOVER изо всех своих щенячьих сил. Узенькая полосочка внизу графика — это нормальный ритм работы сетки на 10к хостов.

blind_oracle
21.09.2015 20:17«Наколенных велосипедов» приходится делать очень много, ибо встроенного функционала (SNMP, агенты в ОС) хватает лишь для небольшого круга задач.
Например:
- Мониторинг серверов через IPMI-over-LAN. В заббиксе достаточно давно была поддержка IPMI, но до последнего времени она не поддерживала дискретные сенсоры. Поэтому на базе freeipmi был написан комплекс скриптов в auto-discoverу сенсоров и преферансом
- RAID-контроллеры и их подмножества (физ диски, массивы, дисковые полки с inband-мониторингом, суперконденсаторы, ...) — тоже пришлось писать самому скрипты, которые всё это в нужном формате отдают заббиксу
- Промышленное добро типа кондиционеров через шлюзы RS485-Ethernet
- Всякие линуксовые подсистемы типа DRBD/MDRAID/Pacemaker/SCST/MySQL+Galera
и многое многое другое
icCE
21.09.2015 22:58Вы не поверите. От безисходности в крупных ынтерпрайсах и не такое увидишь, а как увидишь начинают шевелится волосы в разных местах и срочно хочется развидить.

DoMoVoY
21.09.2015 20:28Используем счетчики iptables с комментарием для легкого парсинга. Шаг 30 секунд для оперативности. Lease time 10 минут.
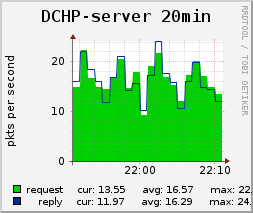


gotch
23.09.2015 09:29Microsoft делает службы, и покрывает их счетчиками производительности и WMI классами (а сейчас и обертками Powershell) для управления.
Разрабочикам Open Source стоило бы всегда реализовывать в базе как минимум мониторинг по SNMP, чтобы Linux-адмнистратор не мучался с sed/awk парсингом, а просто подключал очередной сервис к имеющейся системе мониторинга.
martin74ua
23.09.2015 10:05/me немного плохо в винде ориентируется, можно уточнить?
Вот есть у нас perfmon со счетчиками производительности по dhcp серверу. А добраться то до них как? Через тот же старый добрый snmp?
WorksIsGone
Почему не сразу в кактус?
martin74ua
Не люблю кактус и заббикс. В качестве оперативного мониторинга используем centreon.