
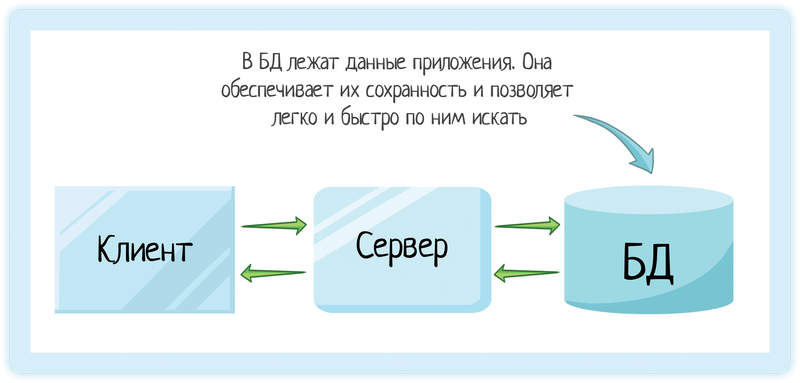
База данных — это место для хранения данных. Используется в клиент-серверной архитектуре. Это все интернет-магазины, сайты кинотеатров или авиабилетов... Вы делаете заказ, а система сохраняет ваши данные в базе.

В этой статье я на простых примерах расскажу, что такое база данных, как она выглядит, и чем она лучше хранения информации в простых текстовых файликах. Статья рассчитана на начинающих тестировщиков, идёт как доп материал моим студентам, которые только входят в мир ИТ и многого не знают. Статья даёт общее понимание «а что это вообще такое».
Содержание
Что такое база данных
База данных — хранилище, куда приложение складывает свои данные. Если приложение небольшое, отдельная база не нужна. Но потом это становится удобнее и выгоднее с точки зрения памяти.
Катя решила открыть свой магазинчик. Она нашла хорошую марку обуви, которую «днем с огнем» не сыскать в ее городе. Заказала оптовую партию и стала потихоньку распродавать через знакомых. Пришлось освободить половину шкафа под коробки, но вроде всё поместилось.

Обувь хорошая, в розницу заказывать в других местах невыгодно — и вот уже у Кати есть постоянные клиенты, которые приводят друзей. Как только какая-то пара заканчивается, Катя делает новый заказ.
Но покупатели хотят новинок, разных размеров. Да и самих покупателей становится все больше и больше. В шкаф коробки уже не влезают!

Теперь, если покупатель просит определенную пару, Катьке сложно её найти. Пока коробок было мало, она помнила наизусть, где что лежит. А теперь уже нет, да и все попытки организовать систему провалились. Места мало, да и детки любят с коробками поиграть.

Тогда Катька решила арендовать складское помещение. И вот теперь красота! Не надо теснить своих домашних, дома чисто и свободно! И на складе место есть, появилась система — тут босоножки, тут сапоги...

Чем больше объемы производства, тем больше нужно места. Если в начале пути склад не нужен, всё поместится дома, то потом это будет оправданно.
Тоже самое и в приложениях. Если приложение маленькое, то все данные можно хранить в памяти. Но учтите, что это память на вашем компьютере, вашем телефоне. И чем больше данных туда пихать, тем медленнее будет работать программа.
Место в памяти ограничено. Поэтому когда данных много, их нужно куда-то сложить. Можно писать в файлики, а можно сохранять информацию в базу данных (сокращенно БД). Выбор за вами. А точнее, за вашим разработчиком.
Как она выглядит
Да примерно как excel-табличка! Есть колонки с заголовками, и информация внутри:
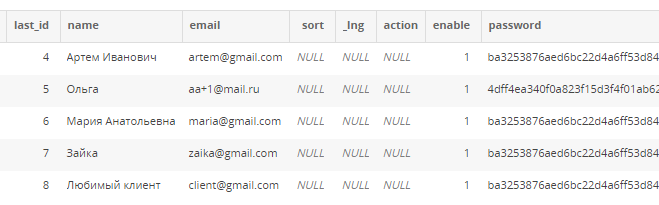
Это называется реляционная база данных — набор таблиц, хранящихся в одном пространстве.
Что за пространство? Ну вот представьте, что вы храните все данные в excel. Можно запихать всю-всю-всю информацию в одну огро-о-о-о-мную таблицу, но это неудобно. Обычно табличек несколько: тут информация по клиентам, там по заказам, а тут по адресам. Эти таблицы удобно хранить в одном месте, поэтому кладем их в отдельную папочку:
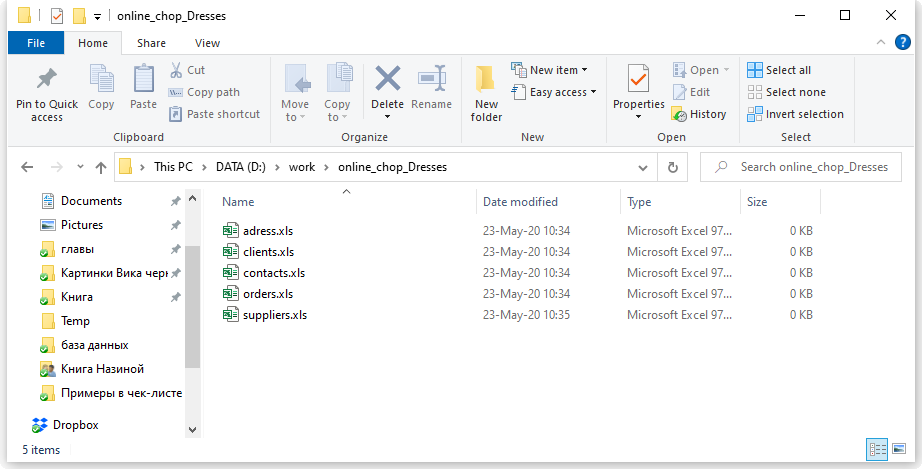
Так вот пространство внутри базы данных — это та же самая папочка в винде. Место, куда мы сложили свои таблички, чтобы они все были в одном месте.

Цель та же — выделить отдельное место, чтобы у вас не была одна большая свалка:
заходишь в папку в винде > видишь файлики только из этой папки
заходишь в пространство > видишь только те таблицы, которые в нем есть
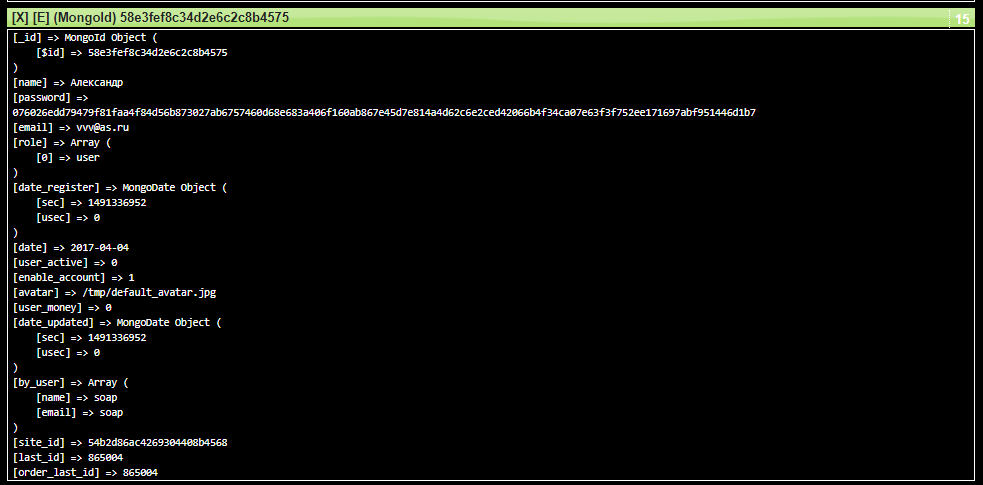
Хранение данных в виде табличек — это не единственно возможный вариант. Вот вам для примера запись из таблицы в системе Users. Там используется MongoDB база данных, она не реляционная. Поэтому вместо таблички «словно в excel» каждая запись хранится в виде объекта, вот так:
А еще есть файловые базы — когда у вас вся информация хранится в файликах. Да-да, простых текстовых файликах!
Почитать о разных видах баз данных можно в википедии. Я не буду в этой статье углубляться в эту тему, потому что моя задача — объяснить «что это вообще такое» для ребят, которые базу в глаза не видели. А на работе они скорее всего столкнутся именно с реляционной базой данных, поэтому о ней и речь.
Да, базы бывают разные. Классификацию можно изучить, можно выучить. Но по факту от начинающего тестировщика обычно нужно уметь достать информацию из реляционной БД («обычно» != «всегда», если что).
Как получить информацию из базы
Нужно записать свой запрос в понятном для базы виде — на SQL. SQL (Structured Query Language) — язык общения с базой данных. В нем есть ключевые слова, которые помогут вам сделать выборку:
select — выбери мне такие-то колонки...
from — из такой-то таблицы базы...
where — такую-то информацию...
Например, я хочу получить информацию по клиенту «Назина Ольга». Составляю в уме ТЗ:
Дай мне информацию по клиенту, у которого ФИО = «Назина Ольга»Переделываю в SQL:
select * from clients where name = 'Назина Ольга';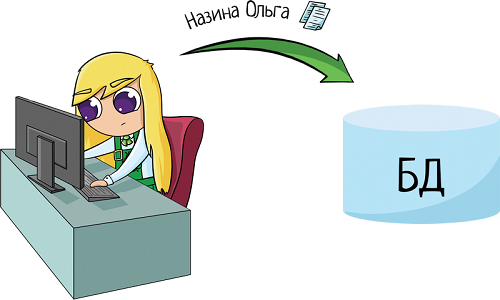
В дословном переводе:
select -- выбери мне
* -- все колонки (можно выбирать конкретные, а можно сразу все)
from clients -- из таблицы clients
where name = 'Назина Ольга'; -- где поле name имеет значение 'Назина Ольга'См также:
Комментарии в Oracle/PLSQL — мой перевод остается работающим запросом, потому что я убрала «лишнее» в комментарии
Если бы у меня была не база данных, а простые excel-файлики, то же действие было бы:
Открыть файл с нужными данными (clients)
Поставить фильтр на колонку «ФИО» — «Назина Ольга».
То есть нам в любом случае надо знать название таблицы, где лежат данные, и название колонки, по которой фильтруем. Это не что-то страшное, что есть только в базе данных. Тоже самое есть в простом экселе.
Бывают запросы и сложнее — когда надо достать данные не из одной таблицы, а из разных. В базе это будет выглядеть даже лучше, чем в эксельке. В экселе вам нужно открыть 1-2-3 таблицы и смотреть в каждую. Неудобно.
А в базе данных вы внутри запроса SQL указываете, какие колонки из каких таблиц вам нужны. И результат запроса их отрисовывает. Скажем, мы хотим увидеть заказ, который сделал клиент, ФИО клиента, и его номер телефона. И всё это в разных таблицах! А мы написали запрос и увидели то, что нам надо:
id_order | order (таблица order) | fio (таблица client) | phone (таблица contacts) |
1 | Пицца «Маргарита» | Иванова Мария | +7 (926) 555-33-44 |
2 | Комбо набор 1 | Петров Павел | +7 (926) 555-22-33 |
И пусть в таблице клиентов у нас будет 30 колонок, а в таблице заказов 50, в результате выборки мы видим ровно 4 запрошенные. Удобно, ничего лишнего!
Конечно, написать такой запрос будет немного сложнее обычного селекта. Это уже select join, почитать о нем можно тут. И я рекомендую вам его изучить, потому что он входит в «базовое знание sql», которое требуется на собеседованиях.
Результаты выборки можно группировать, сортировать — это следующий уровень сложности. См раздел «статьи и книги по теме» для получения большей информации.
Как связать данные между собой
Вот например, у нас есть интернет-магазин по доставке пиццы. Так выглядит его база данных:
В таблице «client» лежат данные по клиентам: ФИО, пол, дата рождения и т.д.
last_name | first_name | birthdate | VIP |
Иванов | Иван | 01.02.1977 | true |
Петрова | Мария | 02.04.1989 | false |
Сидоров | Павел | 03.02.1991 | false |
Иванов | Вася | 04.04.1987 | false |
Ромашкина | Алина | 16.11.2000 | true |
В таблице «orders» лежат данные по заказам. Что заказали (пиццу, суши, роллы), когда, насколько довольны доставкой?
order | addr | date | time |
Пицца «Маргарита» | ул Ленина, д5 | 05.05.2020 | 06:00 |
Роллы «Филадельфия» и «Канада» | Студеный пр-д, д 10 | 15.08.2020 | 10:15 |
Пицца 35 см, роллы комбо 1 | Заревый, д10 | 08.09.2020 | 07:13 |
Пицца с сосиками по краям | Турчанинов, 6 | 08.09.2020 | 08:00 |
Комбо набор 3, обед №4 | Яблочная ул, 20 | 08.09.2020 | 08:30 |
Но как понять, где чей был заказ? Сколько раз заказывал Вася, а сколько Алина?
Тут есть несколько вариантов:
1. Запихать все данные в одну таблицу: тут и заказы, и информация по клиентам... В целом удобно, открыл табличку и сразу видишь — ага, это Васин заказ, а это Машин.
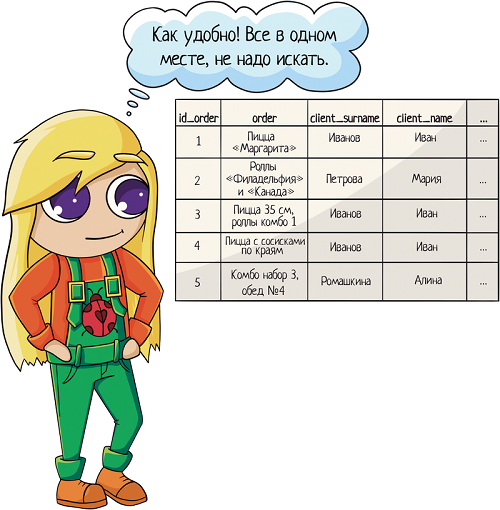
Но есть минусы:
Таблица все растет и растет, в итоге получается просто огромной! А когда данных много, легкость чтения пропадает, придется листать до нужной колонки.
Поиск будет работать медленнее. Чем меньше информации в таблице, тем быстрее поиск. Когда у нас много строк, количество колонок становится существенным.
Много дублей — один человек может сделать хоть сотню заказов. И вся информация по нему будет продублирована сто раз. Неоптимальненько!
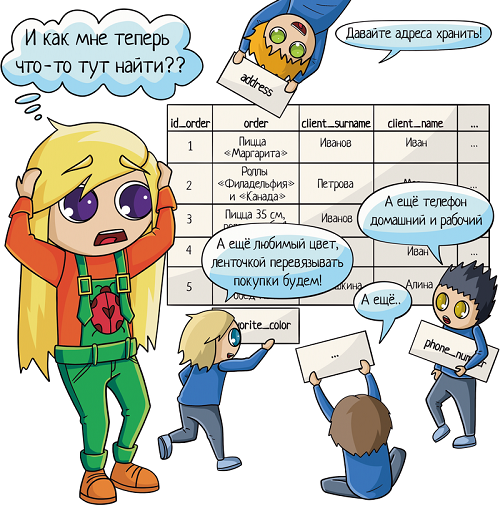
Чтобы избежать дублей, таблицы принято разделять:
Клиенты отдельно
Заказы отдельно
Новые объекты отдельно
Но надо при этом их как-то связать между собой, мы ведь всё еще хотим знать, чей конкретно был заказ. Для связи таблиц используется foreign key, внешний ключ.
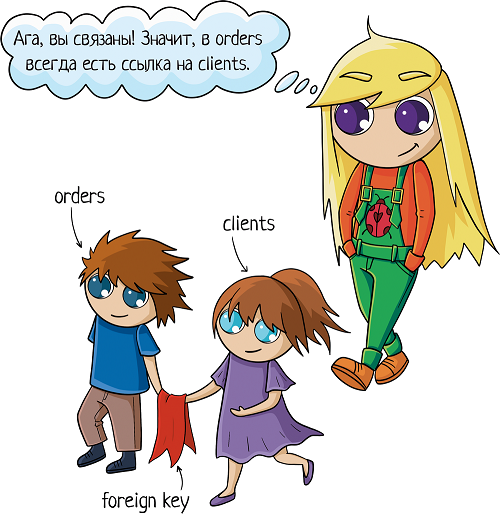
Нам надо у заказа сделать отметку о клиенте. Значит, таблица «orders» будет ссылаться на таблицу «clients». Ключ можно поставить на любую колонку таблицы (в некоторых базах колонка должна быть уникальной, сначала её нужно такой указать). Какую бы выбрать?
Можно ссылаться на имя. А что, миленько, в таблице заказов будем сразу имя видеть! Но минуточку... А если у нас два клиента Ивана? Или три Маши? Десять Саш... Ну вы поняли =) И как тогда разобраться, где какой клиент? Не подходит!
Можно вешать foreign key на несколько колонок. Например, на фамилию + имя, или фамилию + имя + отчество. Но ведь и ФИО бывают неуникальные! Что тогда? Можно добавить в связку дату рождения. Тогда шанс ошибиться будет минимален, хотя и такие ребята существуют. И чем больше клиентов у вас будет, тем больше шанс встретить дубликат.

А можно не усложнять! Вместо того, чтобы делать внешний ключ на 10 колонок, лучше создать в таблице клиентов primary key, первичный ключ. Первичный ключ отвечает за то, чтобы каждое значение в поле было уникальным, никаких дублей. При попытке добавить в таблицу запись с неуникальным первичным ключом получаешь ошибку:

Вот на него и нужно ссылаться! Обычно таким ключом является ID, идентификатор записи. Его можно сделать автоинкрементальным — это значит, что он генерируется сам по алгоритму «прошлое значение + 1».
Например, у нас гостиница для котиков. Это когда хозяева едут в отпуск, а котика оставить не с кем — оставляем в гостинице!
Есть таблица постояльцев:
ID | name | year |
1 | Барсик | 2 |
2 | Пупсик | 1 |
Тут привозят еще одного Барсика. Добавляем его в таблицу:
— Имя Барсик, 5 лет! (мы не указываем ID)
Система добавляет:
ID | name | year |
1 | Барсик | 2 |
2 | Пупсик | 1 |
3 | Барсик | 5 |

ID сгенерился автоматически. Последнее значение было 2, значит, новый Барсик получил номер 3. Обратите внимание — Барсиков уже два, но их легко различить, ведь у них разные идентификаторы!
Теперь, если в другой таблице надо будет сослаться на котика, мы будем делать это именно через уникальный идентификатор. Например, у нас есть таблица комнат для постояльцев, куда мы заносим информацию о том, кто там живет:
id_room | square | id_cat (ссылка на id в таблице котиков) |
1 | 5 | 11 |
2 | 10 | 2 |
3 | 10 |
|
Мы видим, что в первой комнате живет котик с id = 1, а во второй — с id = 2. В третьей комнате пока никто не живет. Так, благодаря связке таблиц, мы всегда можем понять, что именно за котофей там проживает.
Итак, теперь мы знаем, что идентификатор лучше делать первичным ключом, дабы обеспечить его уникальность. Можно сделать поле автоинкрементальным, чтобы оно заполнялось само. Так и поступим в таблице клиентов:

И в таблице заказов! «id_order» пусть генерится сам и всегда будет уникален. А еще в таблицу заказов мы добавим колонку «id_client» и повесим на нее foreign key, ссылку на «id_client» в таблице клиентов.
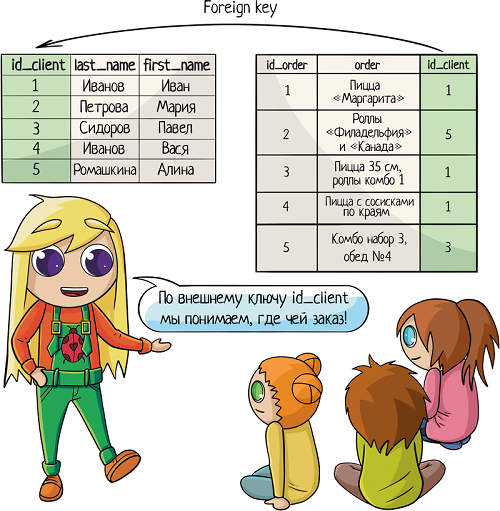
Ключей может быть несколько. Одна таблица может ссылаться на несколько других. Скажем, в заказе мы ссылаемся на клиента и поставщика.
И наоборот, несколько таблиц могут ссылаться на одну и ту же колонку текущей таблицы. ID клиента мы можем указывать в таблице адресов, телефонов, email адресов, документов, заказов... Ограничений на это нет.
Зачем в базе индексы
Давайте представим, что у нас есть табличка excel. Если она небольшая (пара строк, пара колонок), то найти нужную ячейку не составит труда:
Открыли файлик — открывается моментально (если нет проблем с жестким диском)
Нажали «Ctrl + F», ввели запрос — тут же нашли результат.

Но что, если у нас сотни колонок и миллионы строк в файлике? Тогда начинаются тормоза. Файл открывается долго, в поиск значение ввели и система подвисла, обрабатывая результат...
Всё то же самое и в базе данных. Если табличка маленькая, любой запрос к ней отработает моментально. Если же таблица будет большая и с кучей данных, то результата запроса можно ждать минут по 15. А иногда и пару часов!

Если вы заранее знаете, что данных в базе будет много, нужно продумать основные сценарии поиска. И на колонки, по которым будете искать, нужно повесить индексы.
Индекс — это как алфавитный указатель в библиотеке. Вот представьте, заходите вы в библиотеку и хотите найти «Преступление и наказание» Достоевского. А все книги стоят «от балды», никакого порядка. Чтобы найти нужную, надо обойти все стелажи и просмотреть все полки!

Совсем другое дело, если книги отсортированы по авторам. А внутри автора — по названию. Тогда найти нужную книгу будет легко!

Индекс играет ту же роль для базы данных. Если повесить его на колонку таблицы, поиск по ней пойдет быстрее!
А можно повесить индекс на несколько нужных колонок (автор + название). Тут главное — не забывать порядок поиска в индексе. Если у нас индекс сначала по автору, а потом по названию, он будет бесполезен для поиска по названию, придется все равно пересматривать все книги. Поэтому, если нам часто нужно искать по названию и почти никогда — только по автору, имеет смысл поменять порядок в индексе — сначала название, потом автор.
Что делать, если запрос к БД тормозит
Если мы говорим о тестировщиках (а статья написана в первую очередь для них), то тут есть 2 варианта:
Вы работаете с базой напрямую, составляете запросы к ней. И эти запросы работают медленно.
Медленно работает система, но уже поняли, что тормозит выборка из БД (например, увидели в логах).
Первый вариант мы разбирать не будем. Потому что это не про базу, а про SQL. И, если вы работаете с базой, то должны уметь писать сложные запросы, применять хинты там, где нужно, и так далее. Это не тема базовой статьи.
А вот что делать во втором случае? Это не задача тестировщика — разбираться в том, почему запрос работает медленно. Этим занимаются DBA (администраторы баз данных) или разработчики.
Зато задача тестировщика — предоставить разработчику всю нужную информацию. Иногда её можно запросить у заказчика и его админов, а иногда нужно достать самому. Обычно для этого нужно:
Получить план запроса
Пересобрать статистику и проверить, продолжает ли тормозить
План запроса
Смотрите, когда вы выполняете любой запрос, что делает система:
Строит план выполнения запроса (как ей кажется, оптимальный)
Выполняет его
Посмотреть план можно через ключевые слова. В Oracle это EXPLAIN PLAN:
EXPLAIN PLAN FOR -- построй мне план для...
SELECT last_name FROM employees; -- вот такого запроса!А если вы работаете через графический интерфейс, то там обычно можно просто выделить запрос и нажать горячую клавишу. Выглядит ответ примерно так:

Сверху на картинке идёт запрос. А снизу — план его выполнения. Нас сейчас не сильно волнует, что значит информация из первых колонок (то, как именно запрос обходит базу, в данном случае фулл-скан по таблице), нас интересует последняя колонка, «COST». Это стоимость запроса — 857 ms.
А теперь изменим запрос, сделав выборку по одному конкретному человеку по колонке с индексом:

Оп, цена запроса уже 5 ms. Это, на минуточку, в 170 раз быстрее!
И это простейший запрос на тестовой базе. В реальной базе данных будет сильно больше, поэтому проход таблицы по индексированной колонке существенно сократит время выполнения запроса.
Вот пример плана чуть более сложного запроса, когда мы делаем выборку из двух таблиц:

Вы не обязаны понимать, «что тут вообще происходит», но вам нужно уметь получать этот план. Пригодится.
Допустим, поступает жалоба от заказчика — клиент открывает карточку в вебе, а она открывается минуту. Что-то где-то тормозит! Но что и где? Начинаем разбираться. Причины бывают разные:
Тормозит на уровне БД — тут или сам запрос долго отрабатывает, или статистику давно не пересобирали, или диски подыхают.
Тормозит на уровне приложения — тогда надо копаться внутри кода функции «открыть карточку», что она там делает, получив ответ от Базы (и снова есть вариант «подыхают диски, на которых установлено ПО»).
Тормозит на уровне сети — сервер приложения и сервер БД обычно размещают на разных машинах. Значит, есть общение между ними по интернету. А интернет может тупить.
Если есть подозрение, что тормозит сам select, разработчик попросит прислать план его выполнения на реальной базе. Конечно, если «с той стороны» грамотные админы, они это сделают сами. Но иногда это нужно уметь вам. Например, если вас отправили в банк разбираться на месте, что пошло не так. Вы проверяете разные гипотезы и собираете информацию для разработчика.

Собираете план, сохраняете в файлик и прикладываете в задачу в джире. Или отправляете по почте.
У меня бывало, что именно так находился баг — на тестовой базе запрос идет по правильному пути, а на боевой — нет. И на боевой идет не по индексам, что сильно его тормозит. Тут уже дальше разработчик думает, почему так получилось и как именно это исправить.
Статистика в БД
Именно статистика позволяет базе данных выбрать оптимальный план выполнения запроса. Почему вообще возникают проблемы вида «на тестовой базе один план, на боевой другой»?
Да потому, что один и тот же запрос можно выполнить несколькими способами. Например, у нас есть таблица клиентов и таблица телефонов, и мы пишем такой запрос:
Найди мне всех клиентов, созданных в этом году,
У которых оператор связи в телефоне — Мегафон
Как можно выполнить запрос? Можно сначала обойти таблицу клиентов и поискать тех, кто создан в этом году. А потом уже для них проверять телефоны. Можно наоборот, проверить все телефоны на оператора и потом уже для связанных клиентов проверять дату создания.
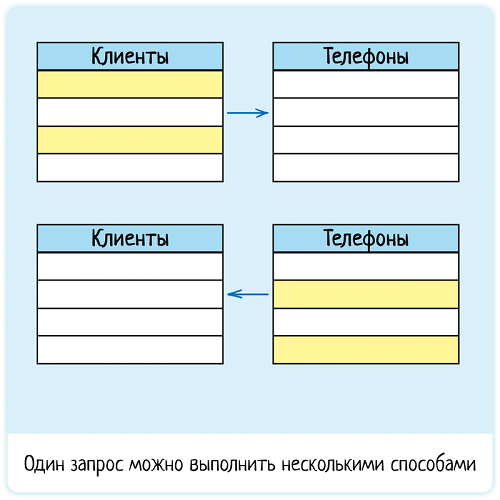
Какой вариант будет лучше? Никто не скажет без данных по таблицам. Может, у нас мало клиентов, но кучи телефонов (база перекупщиков), тогда быстрее будет начать с клиентов. А может, у нас куча миллионы клиентов, но всего пара сотен телефонов, тогда мы начнем с них.
Так вот, в статистике по БД хранится в том числе информация о распределении данных и характеристики хранения таблиц и индексов. И когда вы запускаете запрос, база (а точнее, оптимизатор внутри нее) строит возможные планы выполнения. Для каждого плана рассчитывает примерное время выполнения, а потом выбирает лучшее.
Время же он рассчитывает, ориентируясь на статистику:
Сколько данных находится в таблице?
Есть ли индекс по колонке, по которой я буду искать?

Именно поэтому просто пересбор статистики иногда убирает проблему «у нас тут тормозит». Прилетело в таблицу много данных, а статистика об этом не знает, и чешет по таблице через фуллскан, считая, что информации там мало.
См также:
Ручной и автоматический сбор статистики оптимизатора в базе данных Oracle
Практические методы оптимизации запросов в Apache Spark — подробнее об оптимизации запросов, в том числе и про индексы
Преимущества базы данных
Почему используют базу, а не сохраняют данные в файликах? Потому что:
Базы поддерживают требования ACID (по крайней мере транзакционные БД)
Это единый синтаксис SQL, который используется повсеместно
Требования ACID
ACID — это аббревиатура из требований, которые обеспечивают сохранность ваших данных:
Atomicity — Атомарность
Consistency — Согласованность
Isolation — Изолированность
Durability — Надёжность
Если база данных не поддерживает их, то могут быть печальные последствия из серии «Деньги с одного счета ушли, на другой не пришли? Ну сорян, бывает».
См также:
Требования ACID на простом языке — подробнее об этих требованиях
Единый синтаксис SQL
Я спросила знакомого разработчика:
— Ну и что, что единый синтаксис? В чем его плюшка то?
Ответ прекрасен, так что делюсь с вами:
— Почему в школе все преподают на русском? Почему не каждый свой язык? Одна школа — один, другая — другой. А ещё лучше не школа, а для каждого человека. Почему вавилонскую башню недостроили?

Как разработчик пишет код? Написал, проверил на коленке. Если не работает — думает, почему. Если непонятно, идет гуглить похожие ошибки. А что проще нагуглить? Ошибку распространенной БД, или сделанный на коленке костыль для работы с файлами? Вот то-то и оно...
Что знать для собеседования
Для начала я хочу уточнить, что я сама тестировщик. И мои статьи в первую очередь для тестировщиков ))
Так вот, тестировщика на собеседовании не будут спрашивать про базы данных. Разработчика ещё могут спросить, а вас то зачем? Вполне достаточно понимания, что это вообще такое. И про ключи могут спросить — что такое primary или foreign key, зачем они вообще нужны.
Зато тестировщика спрашивают про SQL. Вот вам обсуждение из чатика выпускников, пригодится для повторения материала:
— В вакансии написано: уметь составлять простые SQL запросы. А простые это какие в народном понимании?
— (inner, outer) join, select, insert, update, create, последнее время популярны индексы, group by, having, distinct.
SQL выходит за рамки данной статьи, здесь я лишь пояснила, что это вообще такое. А дальше читайте статьи / книги из следующего раздела, или гуглите каждое слово из цитаты выше.
Статьи и книги по теме
База данных
SQL
Книги:
Изучаем SQL. Линн Бейли — Обожаю эту линейку книг, серию Head First O`Reilly. И всем рекомендую)) Просто и доступно даже о сложном пишут.
Статьи:
Как изучить основы SQL за 2 дня
Тренажеры:
http://www.sql-ex.ru/ — Бесплатный тренажер для практики
Ресурсы и инструменты для практики с базами данных | SQL
Задачка по SQL. Найти объединенные данные
Резюме
База данных — это место для хранения данных. Они бывают самых разных видов, даже файловые! Но самые распространенные — реляционные базы данных, где данные хранятся в виде таблиц.
Если посмотреть на информацию о таблице в БД, мы можем увидеть ее ключи и индексы. Что это такое:
1. PK — primary key, первичный ключ. Гарантирует уникальность данных, часто используется для колонки с ID. Если ключ наложен на одну колонку — каждое значение в ячейках этой колонки уникальное. Если на несколько — комбинации строк по колонкам уникальны.
2. FK — foreign key, внешний ключ. Нужен для связки двух таблиц в разных соотношениях (1:1, 1:N, N:N). Этот ключ указываем в "дочерней" таблице, то есть в той, которая ссылается на родительскую (в таблице с данными по лицевому счету отсылка на client_id из таблицы клиентов).
3. Индекс. Нужен для ускорения выборки из таблицы.
Транзакционные базы данных выполняют требования ACID:
Atomicity — Атомарность
Consistency — Согласованность
Isolation — Изолированность
Durability — Надежность
См также:
И за это их выбирают разработчики. Мы получаем не просто хранилище данных. Наши данные защищены от неприятностей типа отключения электричества на середине бизнес-операции (с одного счета деньги списать, на другой записать). А еще по ним можно быстро искать, ведь разработчики баз данных оптимизируют свои приложения для этого.
Поэтому логика приложения — отдельно, база — отдельно. Так и получается клиент-серверная архитектура =)
См также:
Чтобы достать данные из базы, надо написать запрос к ней на языке SQL (Structured Query Language). Разработчики пишут SQL-запросы внутри кода приложения. А тестировщики используют SQL для:
Поиска по базе — правильно ли данные сохранились? В нужные таблицы легли? Это select-запросы.
Подготовки тестовых данных — а что, если это значение будет пустое? А что, если у меня будет 2 лицевых счета на одной карточке? Можно готовить данные через графический интерфейс, но намного быстрее отправить несколько запросов в базу. Когда есть к ней доступ и вы знаете SQL =)
План-минимум для изучения: select, join, insert, update, create, delete, group by, having, distinct.
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
suffix_ixbt
Картинки в статье шикарные !
DIXI
mSnus
На вкус и на цвет.. дыры в голове вместо глаз и общий уровень объяснений "детсад, группа \"Кроха\"".. Барсик, 5 лет, id:3. Никак не понять без картинки, а с картинкой сразу предельно ясно становится.
OMG
unsignedchar
Настины комиксы. Не надо так (ц)
avttrue
От картинок просто тошнит :)
mSnus
Да если бы вопрос был только в стилистике… тут в погоне за гламурностью ещё и смысл теряется, иногда — полностью.
Берём картинку, которая в статье аж два раза — в начале и в конце:

Какого ещё приложения? Нет у меня никакого приложения, а данные и БД — есть. Смысл сводится к "в базе данных лежат данные"? Отлично, очень ценный постулат, а то мы сомневались, может, там дрова лежат. Здесь бы написать, что делает кучу данных базой, ан нет: главное — гламур.
Сохранность обеспечивает хороший бэкап. А здесь явно не про сценарии с репликацией. В общем случае — нет, не обеспечивает.
В общем случае — нет, не позволяет, или не легко, или не быстро. Поиск по данным не является неотъемлемым свойством БД.
Получается, что на заглавной картинке написана чепуха, а этого никто не замечает? Да, именно так, потому что гламур и "звёздные дыры" отвлекают внимание. И именно поэтому не надо знания превращать в комикс, фигня получается.
Например, дальше про foreign key и primary index — просто ерунда написана, такая "околоправда", которая выглядит натурально и способна задурить мозги новичкам, но на деле — чушь.
Что? Как, а главное — зачем??
Ооо, мой мозг! В "внешний ключ" и "первичный ключ" только слово "ключ" одинаковые, а так они вообще разные и для разного — кому вообще пришло в голову пытаться заменить одно другим?
https://habrastorage.org/getpro/habr/upload_files/d86/dbd/cd6/d86dbdcd629a8787f2c042cff72d4753.png
varanio
господи, сколько неуместных придирок
mSnus
Было бы неплохо аргументировать..
bigdata-dev
я статью не читал, но про сохранность все верно. в data lake запросто можно столкнутся с тем, что кусок данных вроде вчера был записан, а сегодня нету. и фиг расковыряешь как так вышло. из полновесной базы данных так просто данные не пропадут, она просигнализирует если с файлами данных что-то нехорошее произойдет и многие субд отслеживают целостность каждого блока в бд.
mSnus
СУБД может эти заниматься, но совершенно не обязана. SQLite, например, очень даже СУБД. А так -- можно и Clarion взять в качестве образца СУБД, и ещё кучу фич запихнуть в определение.
bigdata-dev
полновесные субд этим занимаются. жонглировать терминами можно, но суть от этого не изменится.
mSnus
Если даётся общее определение, оно не должно содержать лишнего. А в общем случае это не предусмотрено и собственно к БД отношения не имеет никакого. Это конкретная особенность конкретных СУБД. Как функции вывода на экран текста разных цветов -- где-то есть, но это не повод писать подобное в определении.
maxzh83
Ага, зрачки у персонажей такие, как будто уронили базу и осознали, что бэкап сделать не успели.
GennPen
Ну вот зачем так? Когда статью смотрел особо не обращал внимания, а после вашего коммента только эти огромнейшие глаза и вижу. =)
А еще брови поверх волос.
Molechka Автор
Спасибо)
AzIdeaL
Согласен с вами - глаз радует!
sshikov
Вот про текстовые файлики это вы зря. Физический формат хранения вполне может быть CSV, и это не перестанет быть базой данных. Базой набор файлов скорее делает наличие метаданных (что отлично демонстрирует скажем Hive).
Molechka Автор
Почему зря? Я же писала в статье, что такое тоже может быть)
sshikov
Потому что мешанина из уровней абстракции
unsignedchar
Когда-то в институте нам читали курс про эти самые базы данных. Это было ужасно и непонятно. Но, как и положено студентам, сдали и забыли. А через пару лет мне попалась книга про MS Access. И я был потрясен. Как же можно так непонятно, но наукообразно, объяснять такие простые вещи?
Так вот, переход от склада с коробками к плану выполнения запросов в oracle я тоже не понял, ЕВПОЧЯ.
apapacy
Это вы еще не сдушали курс дискретной математики где это все объятснаялоь с терминах полное функциональное отношения и т.п.
unsignedchar
Я не о том.
Статья про базы данных на языке комиксов - ок. На языке математики - тоже ок. Про специфические оракловские штучки - тоже ок. Если все вместе в одной статье - непонятно, для кого она написана.
apapacy
Это уже вторая такая статья автора у самого вопрос а зачем?
Molechka Автор
Это далеко не вторая статья автора из серии «Что такое...» :)
dimuska139
Внешний ключ нужен не «для связки двух таблиц в разных соотношениях», а лишь для ограничения целостности (в том числе для всяких каскадных удалений данных и т.п.). То есть связь-то можно сделать и без внешнего ключа, просто прописав в одной таблице id из другой. В таком случае тоже можно всякие join'ы без проблем делать, только не будет гарантий целостности. То есть не гарантируется то, что id, вписанные в поле таблицы, будут реально присутствовать в другой, но логическая связь между таблицами при этом есть же.
apapacy
Вы сильно привязываетесб к реализации. Внешний ключ это просто внешний ключ. Как и первичный ключ. Это свойство отношения. Реалищация может быть самая разная. Например в MySQL по каждому ключу создается индекс а в PostgreSQL нет.
dimuska139
Я и не про его реализацию, а про то, что внешний ключ — это не связь, а ограничение целостности. Связь — это наличие идентификатора из одной таблицы в другой. Связь может быть и без внешнего ключа.
Akina
Внешний ключ — это вообще ПРАВИЛО. Правило контроля целостности и непротиворечивости данных, которое будет применяться соответствующей подсистемой СУБД. Кстати, кроме записи в структуре таблицы (и скорее всего в служебных системных таблицах — ну не бегать же каждый раз подсистеме контроля в таблицу за правилом), внешний ключ в БД вообще не имеет никакого физического воплощения.
А вот первичный ключ — это индекс. Вполне себе зримая штука в таблице, с конкретным физическим воплощением. К тому же это индекс, обременённый кучей ограничений, вроде запрета на NULL для любого поля, упомянутого в выражении первичного ключа, даже если этот NULL не приводит к NULL-значению выражения индекса. А в случае упомянутого MySQL, он ещё и кластерный.
sshikov
>внешний ключ в БД вообще не имеет никакого физического воплощения.
На самом деле я бы разделял логическую модель (где нам все равно, какое там воплощение у некой сущности), и физическую, которая содержит определения, названия, типы и параметры скажем индексов, которые нашу логическую модель реализуют. Логически и первичный ключ может не иметь никакого воплощения — хотя обычно он да, индекс.
Но скажем в Hive за PK вполне может не быть ничего — потому что первичные ключи там игнорируются самой системой, а вот приложения уже могут читать метаданные, и проверять на уникальность, или делать что-то еще. Да, Hive вообще странная СУБД (или вообще не СУБД, хотя и имеет многие ее признаки) — но и такие существуют в природе.
Akina
Ну… вариант parsed but ignored — это случай, когда первичного ключа просто нет. И к фрагменту DDL, в котором описывается ПК, в данном случае отношение такое же, как к комментарию.
sshikov
Не, почему? Если DDL приложению доступен — то приложение скажем может сделать distinct, прежде чем сохранить новые данные в таблицу. Ну то есть вариантов на самом деле два — игнорировать, и переложить на приложение.
mSnus
Только не целостности, а связности. Это просто выносит логику связи между таблицами на уровень базы данных.
tmpnick
Что это делает на хабре? Уже вторая статья уровня детский сад. Такие статьи делают хабр хуже. Я за бан автора.
Immortal_pony
Чем вам не угодили статьи для начального уровня? Если вы знаете предмет хорошо, то статья не для вас, просто не читайте.
smind
Но это как статьи про мурзилку и его приключения публиковать, это же бред.
Immortal_pony
Статья-то по-прежнему техническая, а не про мурзилку. Просто для новичков. Тысячи их на Хабре, почему именно эта так не угодила?
werevolff
Тем, что у автора много домыслов. Например,
В то же самое время, в документациях мы читаем, что внешний ключ можно поставить только на primary key связываемой таблицы. Далее, автор предполагает, что foreign key можно поставить на группу колонок связываемой таблицы, но это не так. В документации по тому же PostgreSQL ясно читаем, что первичным ключом может быть группа колонок, которая ссылается на pk связываемой таблицы. То есть, всё наоборот. В то же время, есть понятие Потенциального Ключа таблицы, но Потенциальный Ключ - это для определения уникальности строки, а не для связывания. Опять же, выше писали абсолютно правильно, что foreign key обеспечивает не связь таблиц, а ограничение целостности. Далее, тот же постгрес автоматически создаёт индексы для уникальных значений и первичных ключей. Foreign Key, как мы помним, ссылается на pk. Отсюда следует, что выборка связанных объектов через foreign key, по дефолту производится через индекс (за исключением некоторых ситуаций).
Отсюда следует, что при подготовке материала автор не изучает документацию и не сверяет свои слова с тем, что описано в официальной теории. И вот, представь: джун читает на хабре: "foreign key может ссылаться на несколько столбцов". Он запоминает это, и уже вкачавшись до миддла носит в голове эту ересь. И ещё может ссылаться на неё: типа, нифига вы гоните - вот на хабре есть статья об этом.
Даже простая подача материала не должна создавать ситуаций, когда контент противоречит официальной документации. Автор должна сверять то, что она пишет, с документацией и материалом от людей, которые разрабатывают СУБД или участвуют в официальных изысканиях в области математических обоснований работы с данными.
Учитывая, что это не первая статья автора с её собственными домыслами, которые она выдаёт за факты, я поддерживаю мнение о необходимости бана автора. Нуили пусть она переписывает статьи, сверяя свои слова с авторитетными источниками.
varanio
вообще-то в postgres можно поставить foreign key на группу колонок и без primary key
так что перечитайте сами документацию
werevolff
Ну, по содержанию замечание верное. А по сути — не совсем. Да, безусловно, fk может ставиться и на уникальные значения, но не на любой столбец, как указано у ТС. по группе тоже есть замечание:
www.postgresql.org/docs/11/ddl-constraints.html#DDL-CONSTRAINTS-FK
Это мало меняет суть претензий к фразе
А так, да, вы совершенно правы: связь с primary key идёт по-дефолту, что является синтаксическим сахаром и позволяет писать
вместо
Molechka Автор
Я проконсультируюсь с разработчиками и потом вернусь с ответом или изменением в статье. (Пока исходно писала, тоже консультировалась с гуглом и людьми)
Molechka Автор
Вернулась) Можно ставить не только на «primary key», но и на уникальную колонку. Колонку можно обозвать уникальной любую, можно сделать связку колонок уникальными, а потом повесить на них FK.
То есть чисто технически при создании БД можно сказать «ФИО + ДР будут уникальными, вешаем на них ключ» (хотя это называется «выстрелить себе в ногу», но в жизни всякое бывает)
Про «какую бы выбрать» — ну так разработчик принимает решение, где хранятся уникальные данные. Или аналитик это делает за него. Не суть. Но это именно человек определяет, в какой колонке (или каких колонках) данные будут уникальными.
И что уж далеко ходить, пример с ФИО и ДР очень даже жизненный, можно погуглить статьи о том, как у людей деньги со счета списывали, потому что их тезка — должник. И потом начинаются суды с доказательством «да это не я был».
При этом судебные приставы приходят в банк с запросом «дай мне людей с такими то ФИО + ДР», а те не имеют права отказать, потому что это закон. Кстати, любопытно, изменилась ли ситуация за последние пару лет… Надеюсь, что да =)
В статью добавила слова об уникальности колонки для FK
werevolff
Таблица users, колонка patronymic - можно "обозвать" уникальной?
Таблица goods, колонка hex_color - можно "обозвать" уникальной?
Таблица orders, колонка price может быть уникальной?
И вы своими статьями решили сделать эту ошибку повсеместной практикой?
Molechka Автор
А почему нельзя то? Что помешает при создании базы это сделать? Другой вопрос, насколько быстро мы огребем ошибку «данные неуникальны», но ведь это вообще никак не связано с возможностью выбрать колонку.
Если человек прочитает мой пример до конца, он увидит, что вариант «ФИО + ДР уникальные» — плохой сценарий. И даже увидит хорошую альтернативу ему. Если он при этом решит, что всё же «это отличный сценарий для повсеместной практики», то это уже проблема не статьи
Akina
Тогда добавьте ещё и указание СУБД — вообще, или конкретно к этому факту. Ибо в общем случае оно неверно. См. напр. fiddle — внешний ключ в MySQL прекрасно работает и без всякой уникальности. Как я говорил в комментарии выше — внешний ключ есть правило. Правило, которое контролирует, что вставляемое/изменяемое в зависимой таблице значение присутствует в базовой. И ему глубоко плевать на уникальность.
Да, каскадные операции на нём дадут результат, далёкий от желаемого — но они и не обсуждаются.
Molechka Автор
Ну давайте теперь распишем один пример для всех СУБД… Сам пример про ключи вообще НИКАК не меняется от того, надо на колонку уникальность предварительно повесить или нет. Но ок, снова перефразировала слово «уникальной». Нет, конкретную СУБД я указывать не хочу, потому что повесить ключ можно в самых разных
Exchan-ge
Нормальная статья. Далеко не все читатели хабра — универсалы и знают все обо всем.
И у каждого специалиста есть смежные с основной специальностью области, для которых нужны определенные знания. А получить их обычно некогда.
И тут помогает научно-популярный подход к теме.
fndl
Никогда не понимал зачем в подобных статьях «для начинающих» закидывать абсолютно всё и сразу. Сначала «что такое БД», «как извлечь данные (select)» и в конце «хинты и план запроса»! Зачем? Тема хинтов и плана запроса очень сложные, по хорошему это отдельная добротная статья. Пример джоина таблиц clients и phone в демонстрации «плана запроса» тоже вызывает много вопросов, но повторюсь это можно обсуждать очень долго и наверное о таких вещах (хинты и план запроса) лучше вообще не писать в статьях «для начинающих».
Shannon
Ну так если зайдет начало, то лучше сразу знать и про план, чтобы хотя бы знать что гуглить.
VitalKoshalew
Видел «программистов», уложивших на лопатки сервер БД. Делать SELECT по какому-нибудь букварю вроде этого они выучились, а про план и оптимизацию/индексацию никогда не догадывались, в букваре этого не было.
Molechka Автор
Да, спасибо. В целом я тут согласна, что можно оставить на уровне «до этого момента, а не всё и сразу». Просто делать несколько коротких статей — ну точно не для Хабра. А у новичков (по крайней мере тестировщиков) иногда спрашивают именно общее понимание «что такое план / статистика», поэтому решила оставить
unsignedchar
Если бы в заголовке было написано "Что такое база данных с точки зрения новичка - тестировщика" - многих вопросов не возникло бы. Новичок-тестировщик узнал, что существуют базы данных и написал статью, прошу понять и простить. Но можно же хотя бы статью из Википедии пересказать, там информация хотя бы систематизирована.
anonymous
Но зачем пересказывать статью из Википедии, если статья в Википедии уже есть?
unsignedchar
Википедия это тоже пересказ.
Molechka Автор
Хотела сказать, что это не в заголовке, а в первых абзацах написано, но не написано. Спасибо, исправила :)
MaxDM1993
Тема индексов в таблице не раскрыта. Общая концепция ясна, но без конкретных примеров не очень понятно как применять её на практике. Понимаю, что эта статья должна стать лишь отправной точкой (чем для меня и стала), но с отсутствующим примером, статья ощущается не полной.
За проделанную работу и оставленные ссылки спасибо. Изложено предельно просто и доходчиво.
Molechka Автор
Спасибо) Если подкинете хороший ссылки для раскрытия тем, обязательно добавлю в статью ^_^
sshikov
Главное — не валите все в одну кучу. Вы тут пытались упомянуть оптимизацию, так я как-то недавно писал пост на тему, какие они вообще бывают, виды оптимизаций. И там далеко не все описано, что бывает — куча видов индексов вообще не затронута, например. Т.е. условно — только это тема для поста минимум. А полноценно — для книги. А чтобы впихнуть это в пару абзацев…
Да и планы скажем — чтобы понимать, что такое вообще план, нужно понимать, как вообще выполняется та или иная операция в СУБД. Скажем, сортировка… вы очевидно можете отсортировать таблицу при выполнении запроса — а можете выбрать нужные данные из индекса, если у вас уже есть подходящий индекс, уже отсортированный в нужном порядке (и в нем есть все нужные вам колонки).
Или JOIN — его можно выполнять несколькими принципиально разными способами. И если человек не знает этих способов, их преимущества и недостатки (разные в зависимости от свойств наших данных) — ему ничем не поможет тот факт, что он сумел набрать команду EXPLAIN. Ну узнал он, что вот там HASH JOIN, ему сильно полегчало?
Molechka Автор
Спасибо, ссылку на вашу статью добавила.
Да, тестировщику полегчало, ведь даже если он не умеет сам разбираться в планах (а обычно так оно и есть), он может его собрать и передать разработчику / DBA.
sshikov
Я не знаю как у вас там, а у меня обычно просто нет права смотреть планы. Во всяком случае в пром окружении. Так что я сразу прошу DBA, тем более они как правило лучше знают, как оптимизировать, потому что видят всю картину целиком, а не только одну таблицу или запрос.
oxff
Реально достал уже этот детсад. Поставил минус посту. Открываешь почитать тематическую ленту после тяжёлого трудового дня, и видишь этот бред с картинками. Люди с цветными линзами от телескопа вместо глаз.
KislyFan
Я так и не понял для кого эта статья? Для школьников? Для гламурных девочек? Перебарщиваете с картинками, и со стилем текста "для самых маленьких".. не надо так.
После текста для самых маленьких сразу идет упоминание хинтов, индексов, и прочего что не нужно в рамках этой статьи. Еще и с кучей ошибок.
Matisumi
Отличная статья, огромное спасибо автору! С нетерпением ждем статью "что такое компьютер"!
unsignedchar
Только в статье должны обязательно быть:
Комиксы
Занимательные факты из биографии Билла Гейтса
Простыня какого-то кода
Чтобы стиль сохранялся ;)
DinSmol
Тут нужен цикл статей: "Как включить компьютер?", "Что такое компьютерная мышь?" и т.д.
MikkaRUS
Вот и пришло время, когда на Хабре котируются статьи уровня "БД для чайников"?
Cepblu_yo
Снимаю шляпу! Спасибо! Очень просто, можно советовать любому начинающему вникать в "что есть бд и с чем её едят".
Если поэтапно разбить:
1) серверная часть на ПК (к примеру, express выпуски, freeware,...)
2) серверная часть на сервере (standart, условно-бесплатные, enterprise,...)
3) клиентская часть на ПК(express,lite, ...)
4) клиентская часть на мобильных устройствах (...)
Можно прямо книгу выпускать для детей. Просто взрослым понятно, где клиентская часть, для чего она нужна, где "основная" база и зачем она нужна. Попробовать расписать почему одна база "в поле не воин"(пока без кластеров, тяжело слишком будет), прочее)
Ну и постараться не использовать слова типа "винде", грубовато не кажется? Хотя молодежь поймёт лучше (мягче чем Windows).
Да, понимаю,что цель статьи не писать книгу, а просто сделать заметку, которую легко скинуть ребёнку. Но всё же, с детства, считаю более правильным приучать к бумажной литературе, и только потом, позже... А что я пишу, всё равно обойдут "ограничения")))
Спасибо!
PereslavlFoto
Вам интересно раскрывать для новичков простые вопросы, связанные с организацией БД. Предложу вам ещё один простой вопрос.
Веб-сайт работает на основе базы данных. В базе хранятся нормализованные данные, словари, индексы. База поддерживает требования ACID. База находится в одном файле MS Access и подключается через ODBC.
Какие недостатки у этого решения? Когда и зачем надо переходить на другую СУБД?
Спасибо.
Molechka Автор
Ничего себе у вас «простые» вопросы! :) Я не знаю ответ
unsignedchar
На эти вопросы тестировщик не должен знать ответ.
DWM
А по таблице в первой комнате живет кот с идентификатором 11.
Molechka Автор
Хм. Пересмотрела пример, не нашла там кота с id=11
Akina
«Я ничего не понимаю в БД. Но я всё-таки расскажу то, как я понимаю.»
Это ужасно. Уважаемый автор, ради всего святого, не пишите больше подобных вещей — или хотя бы найдите тех, кто реально эксперт в данной области, отдайте им на рецензирование свой труд, и публикуйте только тогда, когда хотя бы одна рецензия будет положительной.
Сейчас это труд из разряда «запомните, дети — на ноль делить нельзя». Потому что как только столкнёшься с практикой, так «а теперь, дети, забудьте всё то, что вам говорили раньше». И выясняется, что и на ноль делить можно, и корень квадратный из минус единицы извлекать, и вообще…
Molechka Автор
Я всегда консультируюсь в вопросах, в которых не уверена. В том числе отдаю труд на рецензирование.
С «забудьте всё» не согласна, эта статья даёт общее понятие о том, что такое база, зачем в ней индексы, как может помочь статистика, итд. Что отсюда надо забыть для реальной практики? У меня этой практики около 6 лет, да, не на уровне DBA или разработчика, но про «кому в первую очередь предназначена статья», я уже внесла в самое начало
GospodinKolhoznik
Вас обманули. На самом деле на ноль делить нельзя.
mSnus
Почему?
koreychenko
Т.е. рассказывать про "Базы данных для малышей" надо обязательно на примере одной из самых люто-коммерческих энтерпрайзных БД Oracle?
Molechka Автор
А почему бы и нет? Что такого изменится сильно в другой реляционной базе? Внешний вид интерфейса разве что, но тут из интерфейса пара картинок всего
unsignedchar
В заголовке нет упоминания, что речь будет идти именно про реляционные базы данных. Но для примера можно взять бесплатный кроссплатформенный sqlite размером в 300 кб, или люто энтерпрайзный oracle.
Molechka Автор
Раздел «что такое БД» от этого не меняется, а дальше написано, что примеры именно про реляционные и почему.
Ну а так как статья не про SQL, и запросов «бери и повторяй» в ней нет, не вижу принципиальной разницы. И лучше рассказать о том, с чем работаешь, чтобы не наделать ещё больше ляпов)
sav13
Автор явно не различает БД и СУБД
minamoto
За рассказ про хинты в статье для «начинающих» отдельный огромный дизреспект. Вот начитаются таких статей, и потом начинают гуглить самые популярные хинты и куда их вставлять.
Тем более что далее идет рассказ по большей части не про хинты а про план выполнения — и это действительно может быть полезно для тестировщиков в плане «как посмотреть план, сохранить его и отправить разработчикам», но, в основном, для тестировщиков, работающих с одной конкретной СУБД с помощью одного конкретного приложения.
В общем и целом, статья требует огромной редакторской работы от нормального разработчика БД, очень много что требует правок, в текущем виде я даже не знаю, чего больше — пользы или вреда. Наверное, все таки пользы для совсем уж новичков, но жалко, что не сделан тот небольшой, но важный вклад от профессионала, который позволил бы избежать таких явных ошибок.
Molechka Автор
Возможно, вы правы, и именно хинты можно убрать вообще от слова совсем. На собеседованиях обычно спрашивают про индексы или статистику, на уровне понимания, что это такое. Но именно из-за этого блок про ускорение убирать совсем не хочется
Molechka Автор
Впрочем, можно назвать этот пункт «Что делать, если запросы тормозят» и оставить там только инфу для тестировщиков о том, что вот есть статистика и можно собрать план и отдать разработчикам. Так будет лучше? :)
Про хинты и индексы я тогда в блог просто вынесу отдельно, на индексы отсылку где-то дам, потому что это полезно для понимания именно новичку.
minamoto
Про статистику и планы в целом ок, индексы создавать в целом не задача тестировщика, но понимание будет полезным и если он сможет увидеть на плане отсутствие нужного индекса — это тоже полезные умения, так что да, в таком виде будет лучше, наверное.
Molechka Автор
Переписала разделы:
Посмотрите, пожалуйста, так лучше? :)
minamoto
Да, вроде получше, хотя можно было и совсем упоминания хинтов выкинуть, но это уже не критично — можно и оставить для увеличения глоссария читающего.
Ну и небольшое пожелание по индексам (раз уж перечитал их):
Вот тут у вас пример про многоколоночный индекс, а вывод — про одноколоночный. Можно расширить вывод, что индекс можно повесить на несколько нужных колонок (только есть ограничения в размерах, но это уже тонкости), главное — не забывать порядок поиска в индексе. Если у нас индекс сначала по автору а потом по названию, то если нам нужно найти книгу по названию — такой индекс нам будет бесполезен и придется все равно пересматривать все книги, поэтому, если нам часто нужно искать по названию и почти никогда — только по автору, имеет смысл поменять порядок в индексе — сначала название, потом автор.
Molechka Автор
Спасибо, добавила ваш пример :)
unsignedchar
Жаловаться специалисту, очевидно же. Желательно тому, кто прослушал курсы DBA от этого самого oracle ;)
Molechka Автор
Это верно! Но задача тестировщика — жаловаться грамотно, то есть с предоставлением всей нужной информации =)
unsignedchar
Не троллинга окаянного ради, но подвести черту для ;)
Картинки хороши. Это плюс.
Картинки совершенно не связаны с текстом. Это минус. Не надо так. Ведь этот ваш склад с коробками - готовая абстракция и для таблиц, и ключей, и даже для индексов; почему вы не оформили это графически - непонятно.
Текст никакой.
Рифма вроде есть, смысла вроде нет. Куча разрозненных представлений, как-то связанных с базами данных. Кому это может быть интересно и полезно? Кто ваш читатель? Это точно для хабра?Molechka Автор
Не совсем поняла, как стыкуется «картинки не связаны с текстом» и «можно было идею с коробками пронести через всю статью». Пронести можно было, но это же не делает другие картинки несвязанными с текстом.
Кто мой читатель, написано в первых абзацах. Хабр прекрасно гуглится, а запросов от новичков поступает много, ведь их больше, чем опытных коллег. Почему бы не дать им понятное объяснение на уровне «что это такое»
unsignedchar
Сорри, я просто сломался на 4 картинке ;) Посыпаю голову пепелом, дальше картинки лучше ;) Но, согласитесь, без них информация из статьи не станет менее понятной ;)
Я этого не предлагал ;) Но коробка как визуальное представление блока данных — это весьма наглядно.
Могу порекомендовать книгу «Access для чайников» (гуглится, пиратится), глава про основы баз данных. Всё разложено по полочкам, коротко и понятно.
Molechka Автор
Спасибо, хорошим книгам всегда рада, это такая? www.ozon.ru/product/bazy-dannyh-access-dlya-chaynikov-183864357
unsignedchar
Я имел в виду эту книгу. Только нужно творчески отбросить специфику Access.
Molechka Автор
Спасибо)
mrpinax
Солидарна с автором! С помощью данного тренажера отточила практически навыки sql-запросов.