

Фото Cenk Batuhan Ozaltun, Unsplash.com
Обзор
- Облачные платформы должны предоставлять современным распределённым приложениям возможности, связанные с управлением жизненным циклом, взаимодействием, привязками и состояниями.
- Kubernetes хорошо поддерживает управление жизненным циклом, но для остального использует другие платформы с помощью концепции sidecar-контейнеров и операторов.
- В будущем распределённые системы на базе Kubernetes будут состоять из нескольких сред выполнения, где бизнес-логика будет ядром приложения, и «меха»-компоненты (прим. переводчика: «меха» — сокращение от mechanics) в виде сайдкаров будут предлагать большие возможности в виде распределённых примитивов «из коробки».
- Такая разделённая меха-архитекура связывает элементы бизнес-логики и улучшает операции второго дня, вроде патчинга, апгрейдов и долгосрочной поддержки.
На конференции QCon в марте я рассказывал об эволюции распределённых систем в Kubernetes. Главный вопрос: что будет после микросервисов? У вас наверняка есть мнение на этот счет. У меня оно тоже есть. В конце вы узнаете, что я думаю. Но для начала давайте обсудим потребности распределённых систем. Как эти потребности развиваются с годами, начиная с монолитных приложений до Kubernetes и таких новых проектов, как Dapr, Istio, Knative, и как они меняют наши методы работы с распределёнными системами. Попробуем сделать несколько прогнозов на будущее.
Современные распределённые приложения
Что я называю распределёнными системами? Это системы, состоящие из сотен компонентов. Эти компоненты могут быть stateful, stateless или бессерверными. Более того, эти компоненты можно создавать на разных языках в гибридных средах, с помощью опенсорс-технологий, открытых стандартов и интероперабельности. Вы можете создавать такие системы с помощью коммерческого ПО, в AWS и в других местах. Здесь мы поговорим об экосистеме Kubernetes и о том, как создать такую систему на платформе Kubernetes.
Начнем с потребностей распределённых систем. Допустим, мы хотим создать приложение или сервис и написать бизнес-логику. Что еще нам нужно от платформы и от рантайма, чтобы создать распределённую систему? Для начала нам нужны способы управлять жизненным циклом. Вот мы написали приложение на каком-то языке, а теперь хотим упаковать и задеплоить его, делать откаты и проверки работоспособности. Еще мы хотим разместить приложение на разных нодах, изолировать ресурсы, масштабировать их, управлять конфигурацией и все в таком духе. Это первое, что нам нужно для создания распределённого приложения.
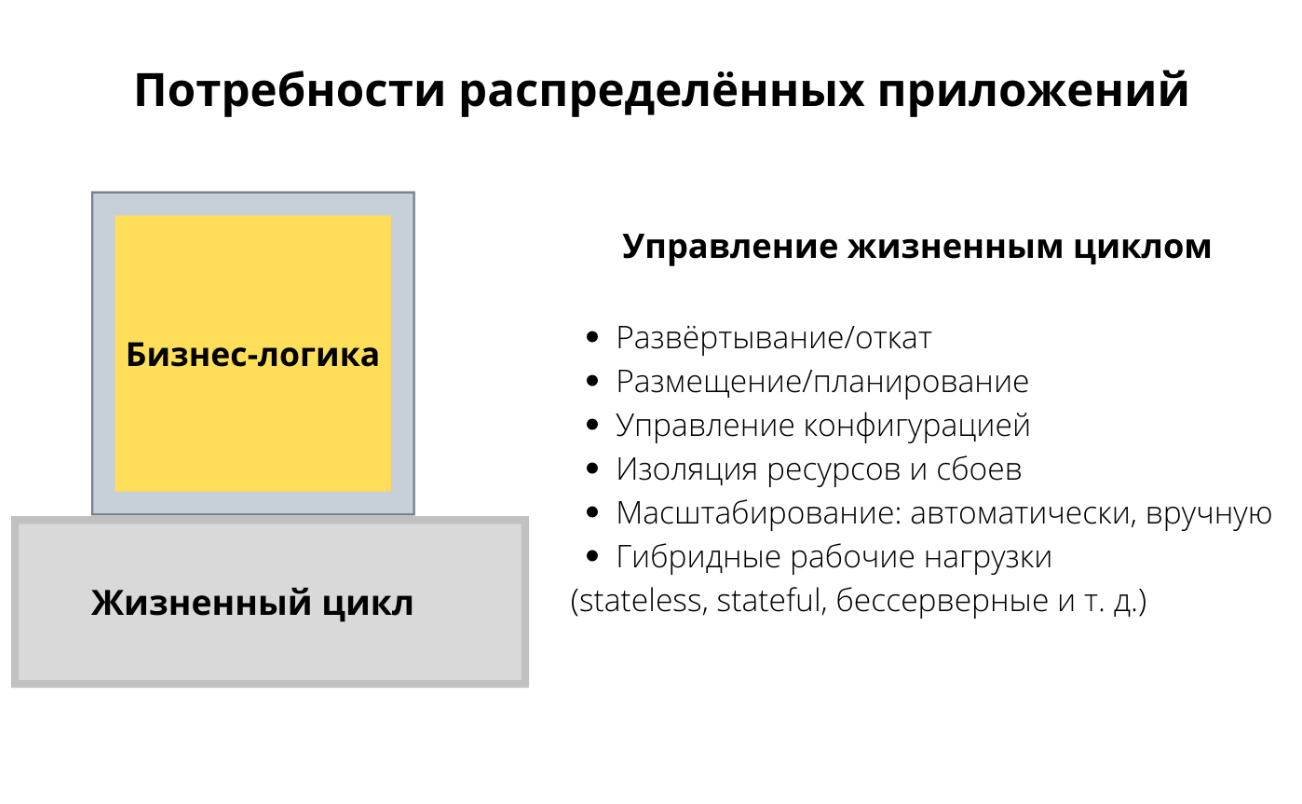
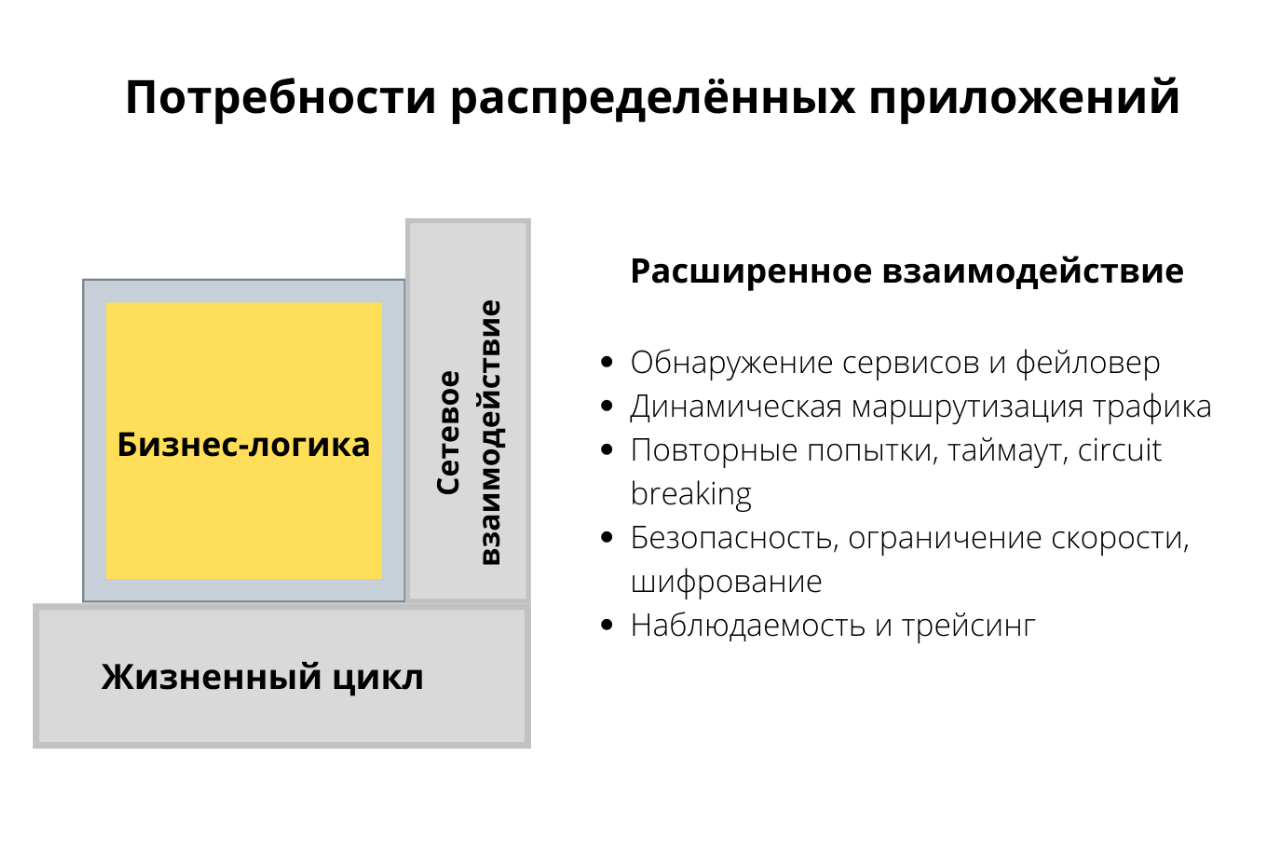
Второе — это взаимодействие. Наше приложение должно надежно подключаться к другим сервисам в кластере или во внешнем мире. Нам нужны такие возможности, как обнаружение сервисов (service discovery) или балансировка нагрузки. Мы хотим перераспределять трафик для разных стратегий релизов или по другим причинам. Еще нам нужно устойчивое взаимодействие с другими системами с помощью повторных попыток, таймаутов и circuit breaker. Не забудем и про безопасность, а еще адекватный мониторинг, трейсинг, наблюдаемость и тому подобное.
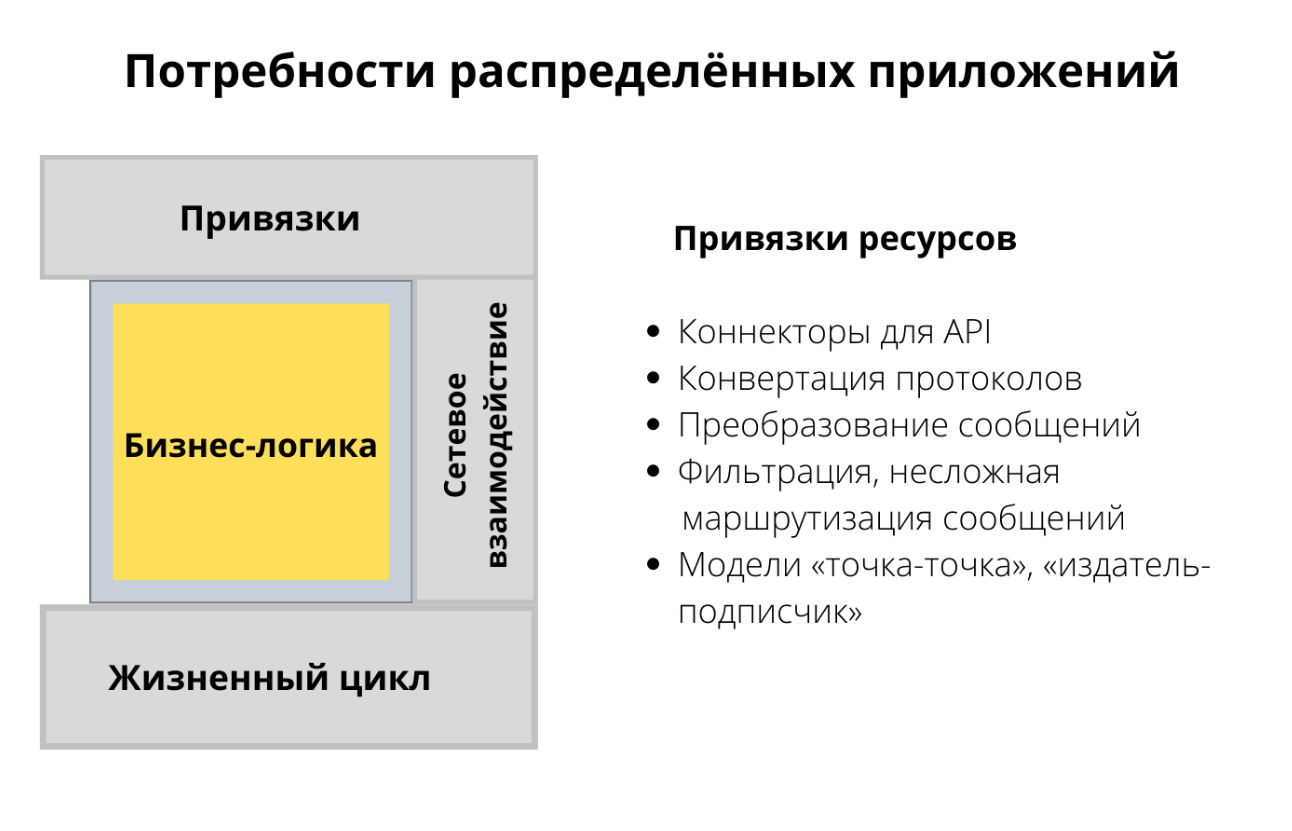
Наладив сетевые соединения, мы переходим к привязке ресурсов и связываемся с разными API и эндпоинтами, чтобы использовать другие протоколы и разные форматы данных. Может быть, мы даже хотим преобразовывать один формат данных в другой. Я бы еще включил сюда фильтрацию, чтобы можно было подписаться только на определённые события в теме.
Последняя категория — состояние. Здесь я не имею в виду управление состоянием, как в базе данных или файловой системе. Речь об абстракциях, которые используют состояние. Например, мы хотим управлять рабочим процессом, какими-то долговременными процессами, хотим что-то запланировать или выполнять задания по расписанию для периодического запуска сервисов. Еще нам может понадобиться распределённое кэширование, идемпотентность или возможность откатов. Все это примитивы уровня разработки, которые зависят от состояния. Для создания надёжных распределённых систем нам обязательно понадобятся эти абстракции.
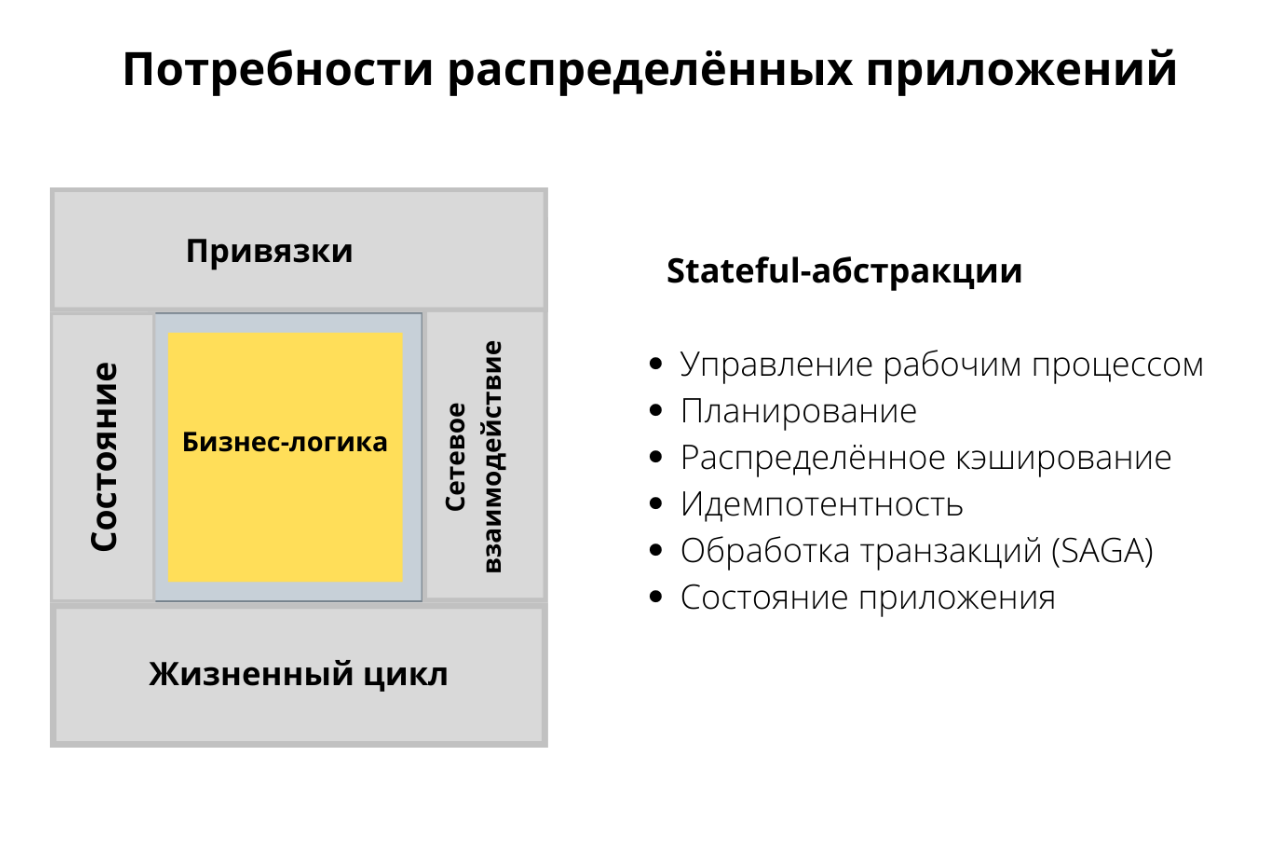
На примере этих примитивов посмотрим, что меняется в Kubernetes и других проектах.
Монолитная архитектура — традиционные возможности промежуточного ПО
Начнём с монолитной архитектуры. В контексте распредёленных приложений первое, что приходит на ум, — ESB (Enterprise Service Bus, сервисная шина данных). Это довольно эффективный инструмент, который прекрасно поддерживает все stateful-абстракции из нашего списка требований.
С ESB можно оркестрировать долгосрочные процессы, выполнять распределённые транзакции и откаты и гарантировать идемпотентность. Более того, ESB предлагает широкие возможности привязки ресурсов и сотни коннекторов, а еще поддерживает преобразование, оркестрацию и даже сетевые функции. И, наконец, ESB может взять на себя service discovery и балансировку нагрузки.
С устойчивостью соединения все нормально, повторные попытки есть. Распределённость тут изначально особо не предусмотрена, так что ESB не нужны очень продвинутые возможности взаимодействия и релизов. Чего в ESB нет, так это управления жизненным циклом. Рантайм всего один, так что и язык может быть один. Обычно это тот язык, на котором создан рантайм — Java, .NET и тому подобные. В одном рантайме нельзя просто взять и сделать декларативное развёртывание или автоматическое размещение — все такое большое и тяжёлое, что требует вмешательства человека. Еще одна сложность в монолитной архитектуре — масштабирование. Мы не можем масштабировать отдельные компоненты.
Что касается изоляции, то в монолитной архитектуре невозможно изолировать ни ресурс, ни сбой. Выходит, нашему списку требований монолитная архитектура ESB не отвечает.

Облачная архитектура — микросервисы и Kubernetes
Давайте теперь обратимся к облачной архитектуре и связанным с ней изменениями. Если смотреть в общих чертах, изменения в нативной облачной архитектуре, пожалуй, начались с микросервисов. Микросервисы позволяют разделить монолитное приложение на бизнес-домены. Оказалось, что контейнеры и Kubernetes отлично подходят для управления микросервисами. Какие фичи и возможности делают Kubernetes привлекательной платформой для микросервисов?
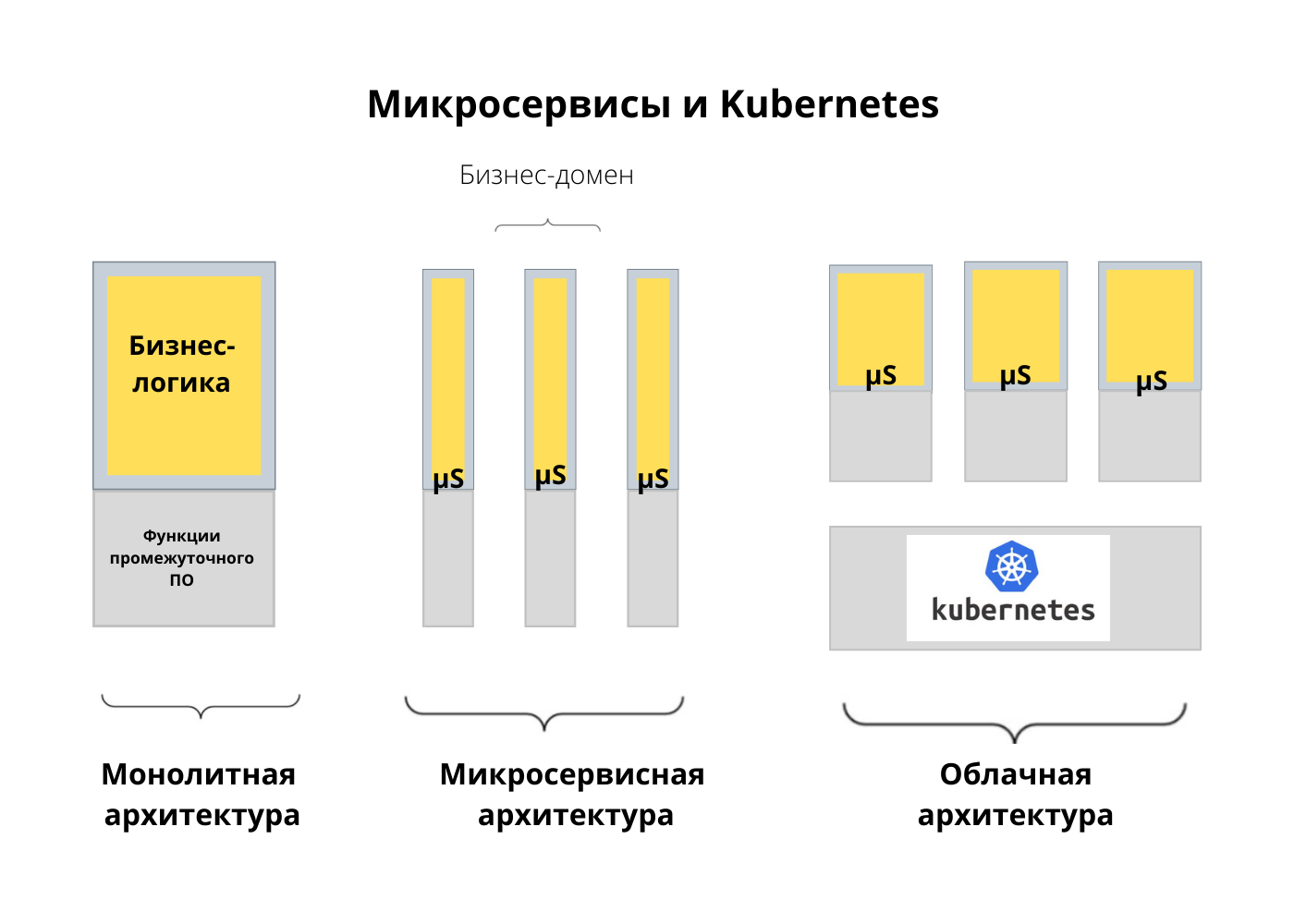
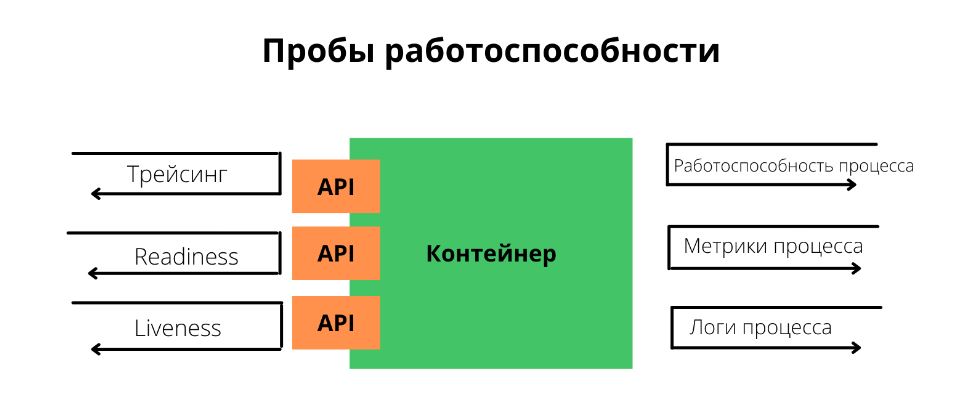
Изначально Kubernetes стал популярен благодаря пробам работоспособности (health probe). На практике это означает, что вы деплоите контейнер в под, а Kubernetes следит за работоспособностью процесса. Обычно такая модель недостаточно хороша. Процесс может выполняться, но при этом не быть работоспособным. Здесь пригодятся проверки readiness и liveness. Kubernetes выполняет readiness-проверку, чтобы решить, когда приложение будет готово принимать трафик во время запуска. Liveness-проба непрерывно проверяет работоспособность сервиса. До Kubernetes это было не очень популярно, зато сегодня почти все языки, фреймворки и рантаймы проводят проверки работоспособности для быстрого запуска конечного устройства.
Также Kubernetes предложил управление жизненным циклом приложения, то есть нам больше не нужно самим контролировать запуск и остановку сервиса. Kubernetes запускает приложение, останавливает его, переносит по разным нодам. Чтобы вся эта система работала, нужно правильно настроить события при запуске и остановке.
Еще одна причина популярности Kubernetes — декларативные развёртывания. Нам больше не нужно запускать сервисы и проверять логи, чтобы узнать, запущены ли они. Нам не нужно апгрейдить инстансы вручную. За все отвечает декларативное развёртывание в Kubernetes. В зависимости от выбранной стратегии оно останавливает старые инстансы и запускает новые. А если что-то пошло не так, само делает откат.
Еще одно преимущество — объявление требований для ресурсов. При создании сервиса мы упаковываем его в контейнер и говорим платформе, сколько ЦП и памяти ему понадобится. На основе этой информации Kubernetes подбирает самую подходящую ноду для ваших рабочих нагрузок. Раньше приходилось вручную размещать инстанс на ноде, опираясь на наши критерии. Теперь мы сообщаем Kubernetes наши предпочтения, и он все решает за нас.
В Kubernetes можно управлять конфигурациями на разных языках. Нам не нужно проверять конфигурацию в рантайме приложения — Kubernetes проследит, чтобы настройки оказались на той же ноде, что и рабочая нагрузка. Настройки для приложения подключаются как файлы в томе или переменные окружения.
Оказывается, что эти возможности, о которых я говорил, тоже связаны. Например, нам нужно выполнить автоматическое размещение, и мы сообщаем Kubernetes требования к ресурсам для сервиса и желаемую стратегию развёртывания. Чтобы стратегия работала правильно, приложение должно уметь обрабатывать события, поступающие из окружения, и проверки работоспособности. Если следовать всем рекомендациям и использовать все доступные возможности, мы получим приложение, которое идеально вписывается в облако и готово для автоматизации в Kubernetes. Это — базовые паттерны выполнения рабочих нагрузок в Kubernetes. Кроме того, существуют паттерны, связанные со структурированием контейнеров в поде, управлением конфигурацией и поведением.
Перейдем к рабочим нагрузкам. В рамках жизненного цикла мы хотим выполнять разные рабочие нагрузки. В Kubernetes это возможно. Запускать 12-факторные приложения (Twelve-Factor App) и stateless-микросервисы довольно просто, Kubernetes справится с этим без проблем. Но у нас будут и другие рабочие нагрузки, в том числе stateful, — для них в Kubernetes используется stateful set.
Или это может быть singleton. Допустим, мы хотим, чтобы инстанс приложения был единственным на всем кластере, и это должен быть надежный singleton. При сбое он должен перезапускаться. В этом случае мы выбираем между stateful set и replica set в зависимости от потребностей и семантики — at least one (не менее одного раза) или at most one (не более одного раза). Kubernetes также поддерживает job и cron job.
В целом, Kubernetes покрывает все наши потребности в отношении жизненного цикла. Обычно мой список требований основан на том, что сейчас предоставляет Kubernetes. Это возможности, которые можно ожидать от любой платформы, — управление конфигурацией, изоляция ресурсов и изоляция сбоев. Кроме того, Kubernetes поддерживает разные рабочие нагрузки, кроме бессерверных (без дополнительных инструментов).
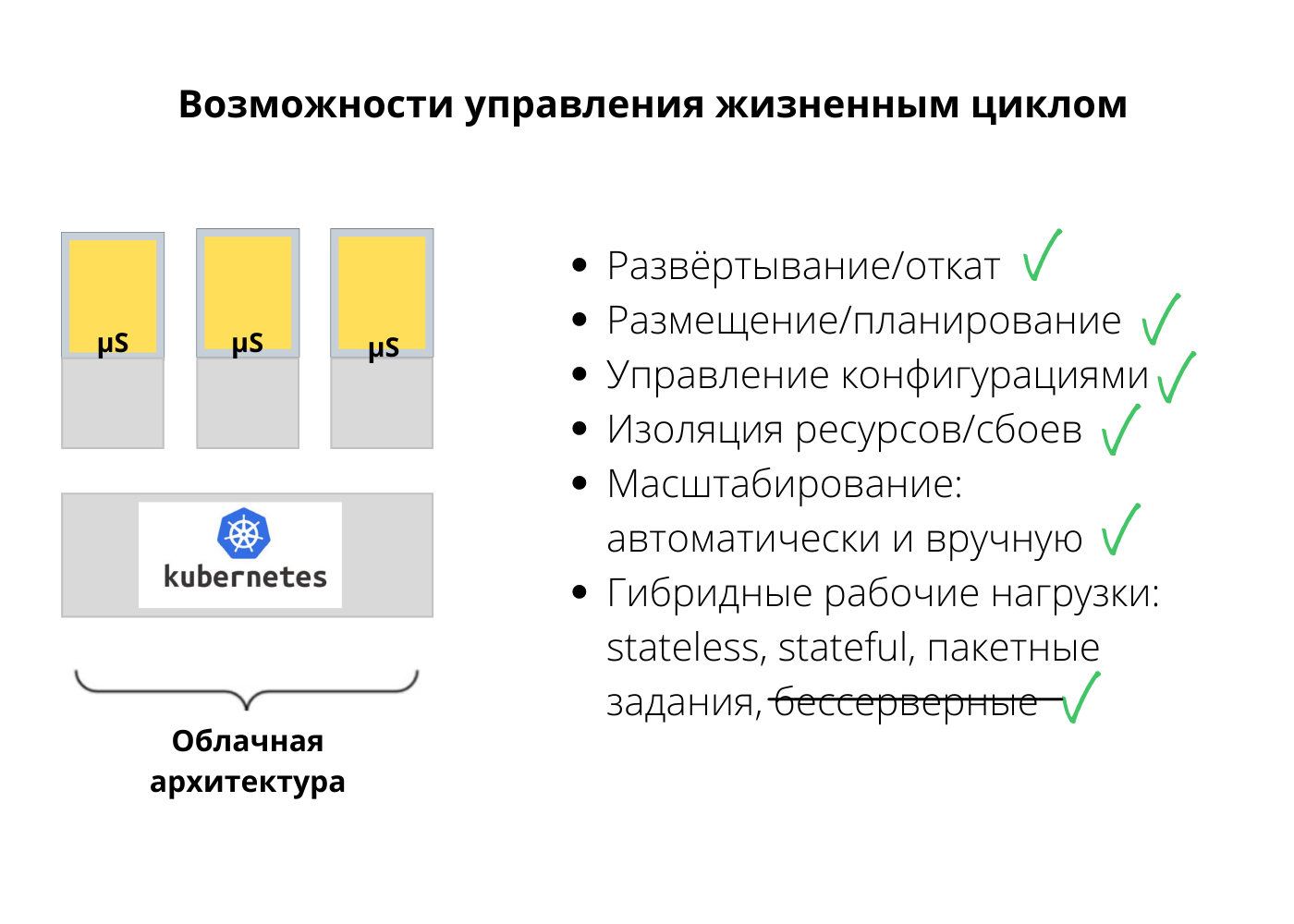
Если это все, что дает Kubernetes, как его расширить? Как получить больше функций? Есть два распространенных способа.
Механизм расширения out-of-process
Под — это абстракция, которую мы используем, чтобы деплоить контейнеры на нодах. Под дает две гарантии:
- Гарантия развертывания. Все контейнеры в поде деплоятся на одной ноде и могут общаться через localhost или асинхронно через файловую систему или другой механизм IPC.
- Гарантия жизненного цикла. Не все контейнеры в поде равны.
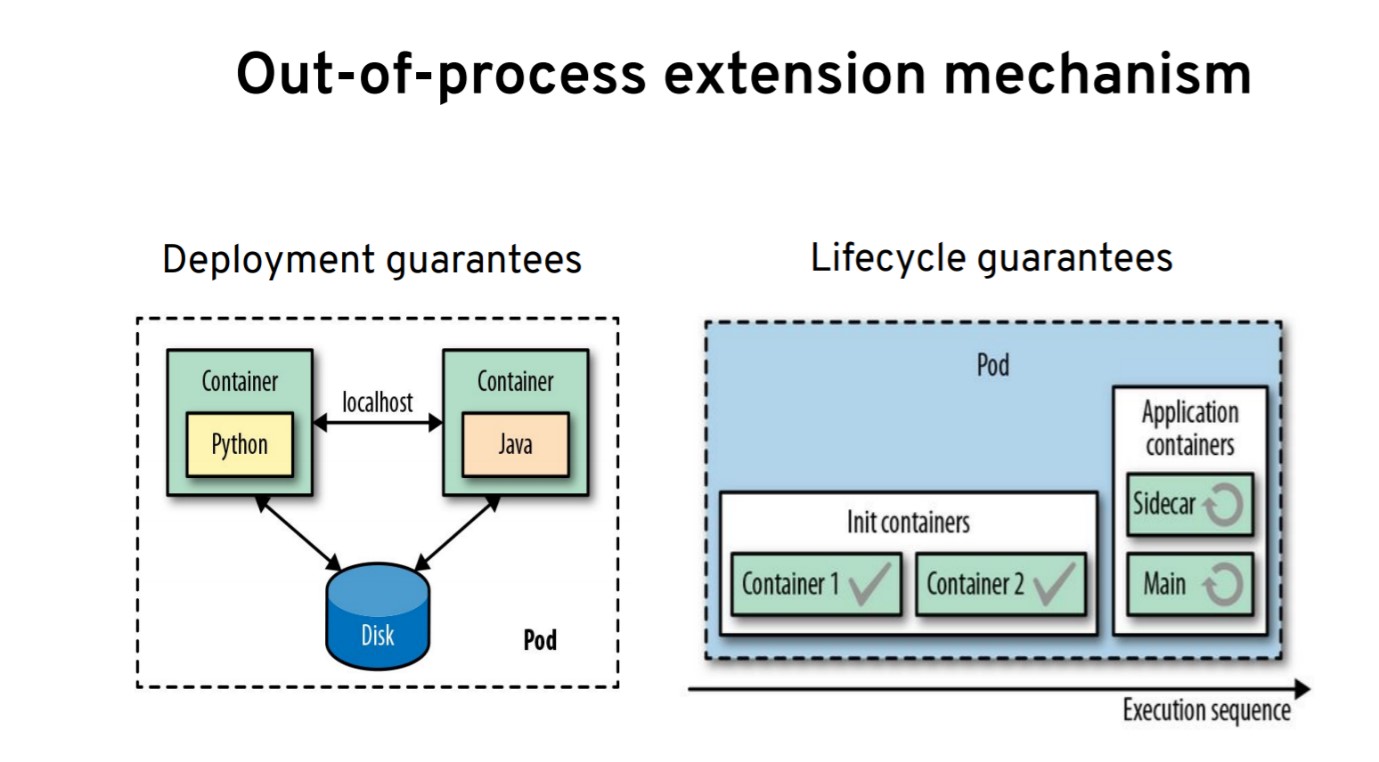
Для init-контейнеров и контейнеров приложения предоставляются разные гарантии. Например, init-контейнеры выполняются в начале, один за другим, строго после выполнения предыдущего контейнера. Они помогают реализовать логику рабочего процесса.
Контейнеры приложений выполняются параллельно на протяжении жизненного цикла пода. На этом основаны sidecar-контейнеры, которые могут запускать несколько контейнеров, совместно выполняющих ту или иную задачу для пользователя. Это один из основных механизмов добавления функционала в Kubernetes.
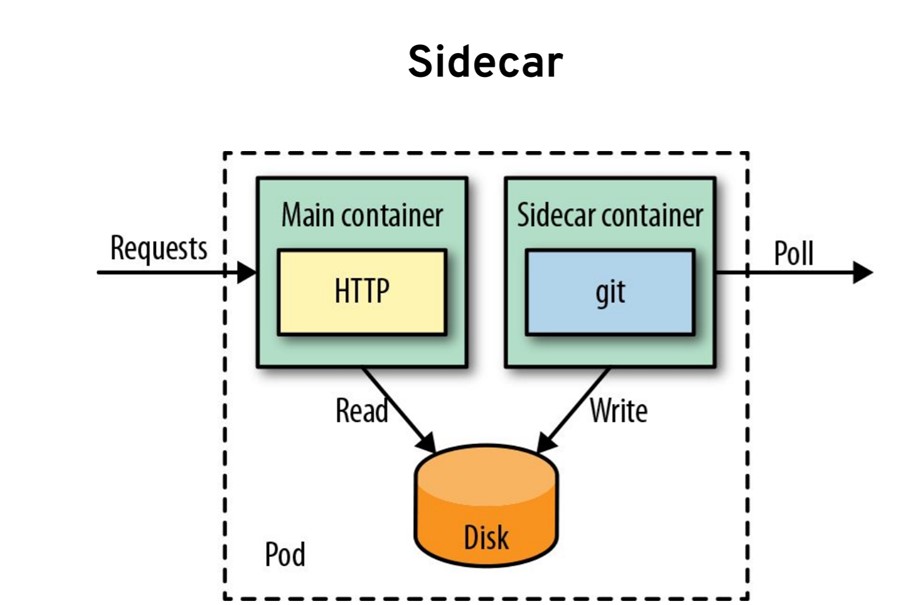
Чтобы понять, как работает следующая возможность, нужно вспомнить о внутренних механизмах Kubernetes. Все основано на цикле согласования (reconciliation loop), который воплощает желаемое состояние в фактическое. В Kubernetes от этого многое зависит. Допустим, мы объявляем, что нам нужно два инстанса пода. Это желаемое состояние системы. Цикл контроля (control loop) постоянно проверяет, есть ли у пода два инстанса. Если их не два, а больше или меньше, он вычисляет разницу. Его задача — гарантировать, что их будет ровно два.
Таких примеров много. Допустим, replica set или stateful set. Определение ресурса сопоставляется с контроллером, а контроллеры есть почти на все случаи жизни. Контроллер следит за тем, чтобы реальность соответствовала нашим желанием, причем контроллер можно даже написать самому.
Например, при выполнении приложения в поде нельзя загрузить файл конфигурации с изменениями в реальном времени. Зато можно написать кастомный контроллер, который будет обнаруживать эти изменения и в соответствии с ними перезапускать под и приложение.
Хотя в Kubernetes достаточно ресурсов, они удовлетворяют не все наши потребности. Поэтому в Kubernetes появилось такое понятие, как кастомные определения ресурсов (custom resource definitions, CRD). То есть мы можем изложить свои требования и определить API, который будет сосуществовать с нативными ресурсами Kubernetes. Контроллер можно написать на любом языке, который сможет описать нашу модель. Можно, например, создать ConfigWatcher, реализованный на Java, который всё это описывает. Это и будет оператор — контроллер, который работает с кастомными определениями ресурсов. Сегодня появляется много операторов, и это второй способ расширения возможностей Kubernetes.
Теперь давайте поговорим о платформах поверх Kubernetes, которые активно используют sidecar-контейнеры и операторы, чтобы предоставлять дополнительные возможности.
Что такое service mesh?
Начнем с service mesh.
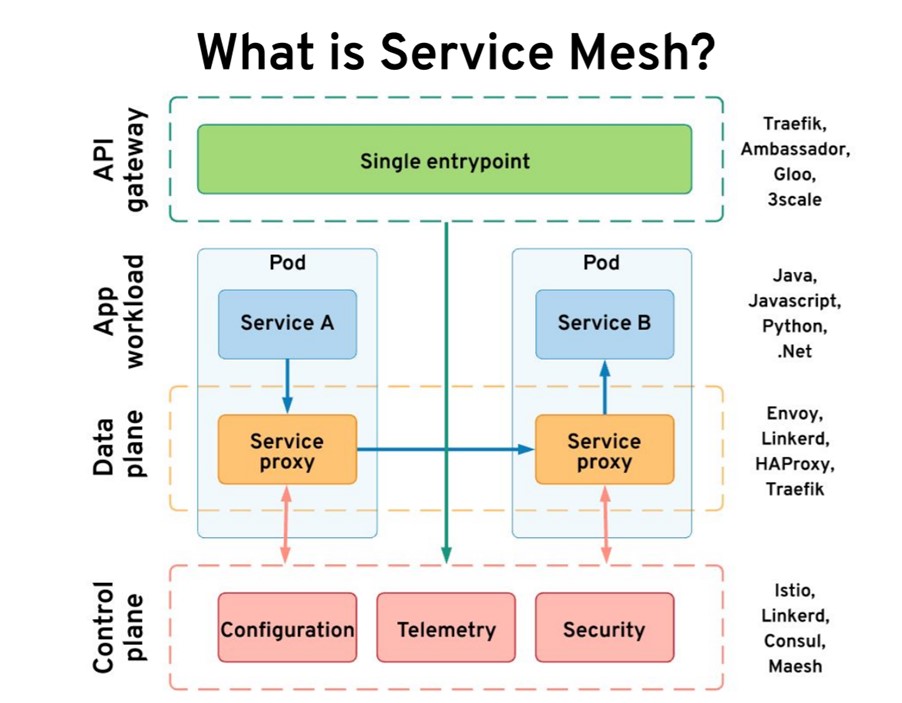
Допустим, у нас есть два сервиса. Сервис A (на любом языке) вызывает сервис B. Допустим, это рабочая нагрузка нашего приложения. Service mesh использует sidecar-контроллеры и внедряет прокси рядом с сервисом. В итоге мы получаем в поде два контейнера. Прокси прозрачный, и приложение не догадывается о его существовании, при этом он перехватывает весь входящий и исходящий трафик. Прокси также работает как файрвол.
Эти маленькие stateless-прокси составляют плоскость данных (data plane). Состояние и конфигурацию они получают от плоскости управления (control plane). Плоскость управления отслеживает состояния. Она хранит все конфигурации, собирает метрики, принимает решения и взаимодействует с плоскостью данных. Нам нужен еще один компонент — шлюз API (API gateway), через который данные попадают в кластер. У некоторых service mesh есть свой шлюз API, другие используют сторонний. Все эти компоненты предоставляют нам нужные возможности.
Шлюз API абстрагирует реализацию наших сервисов, скрывая детали и устанавливая границы. У service mesh противоположная задача. В каком-то смысле она повышает видимость и надежность сервисов. Вместе шлюз API и service mesh удовлетворяют все наши сетевые потребности. Одних сервисов будет недостаточно, нужна service mesh.
Что такое Knative?
Давайте теперь поговорим о проекте Knative, запущенном Google несколько лет назад. Это слой поверх Kubernetes, который предоставляет бессерверные вычисления и состоит из двух модулей:
- Knative Serving — взаимодействия для запросов и ответов.
- Knative Eventing — взаимодействия на основе событий.
Как работает Knative Serving? С Knative Serving мы определяем сервис, но не как в Kubernetes. Тут свои особенности. Когда мы определяем рабочую нагрузку с сервисом Knative, мы используем бессерверные вычисления. Нам не нужно запускать инстанс. Его можно запустить с нуля при поступлении запроса. Масштаб бессерверных вычислений можно быстро увеличивать или уменьшать до нуля.
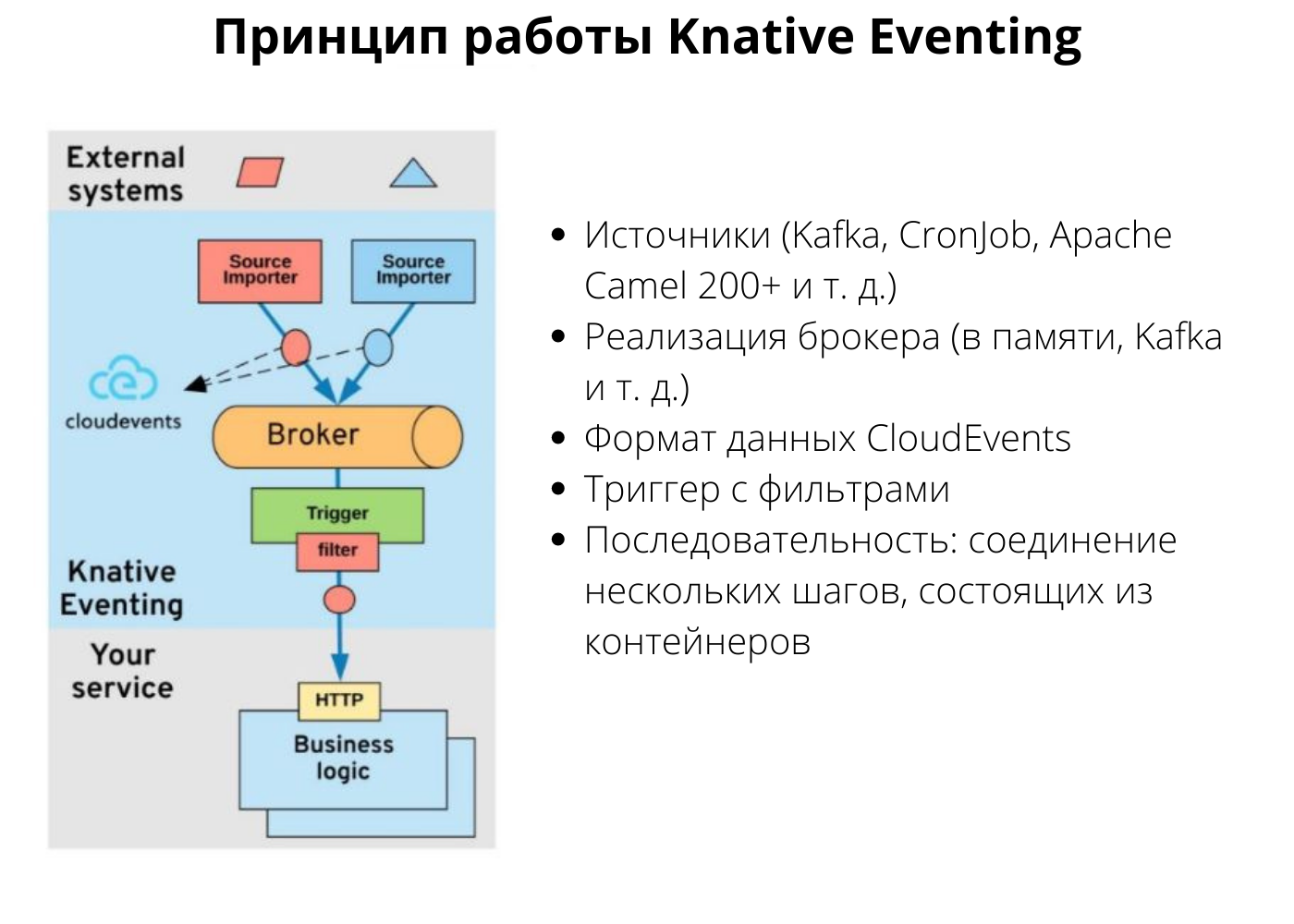
Knative Eventing предоставляет полностью декларативную систему управления событиями. Допустим, мы хотим интегрировать внешние системы, которые создают события. Внизу на схеме находится наше приложение в контейнере с HTTP endpoint. С Knative Eventing мы можем запустить брокер. Это может быть Kafka, процесс в памяти или облачный сервис. Еще можно запустить импортеры, которые подключатся к внешней системе и будут импортировать события в наш брокер. Эти импортеры могут быть основаны, например, на Apache Camel с сотнями коннекторов.
Когда события будут поступать в брокер, мы можем подписать на них контейнер декларативно при помощи yaml-файла. В самом контейнере нам не нужны клиенты обмена сообщениями, вроде Kafka. Он будет получать события через HTTP POST с помощью облачных событий. Эта инфраструктура обмена сообщениями полностью управляется платформой. Разработчик просто пишет в контейнере бизнес-код и не занимается логикой сообщений.
Knative удовлетворяет несколько потребностей из нашего списка. С точки зрения жизненного цикла он предоставляет бессерверные вычисления нашим рабочим нагрузкам, чтобы они масштабировались до нуля или на увеличение. С точки зрения сетей, если будет какое-то перекрытие с service mesh, Knative может перераспределять трафик. Что касается привязок, они поддерживаются импортерами Knative. Мы можем использовать шаблон Pub/Sub («издатель-подписчик»), взаимодействие «точка-точка» или даже последовательности. Это удовлетворяет наши требования в нескольких категориях.
Что такое Dapr?
Еще один проект, который использует sidecar и операторы, — Dapr. Microsoft запустила его всего несколько месяцев назад, но он быстро набирает популярность. Более того, версия 1.0 считается готовой для продакшена (прим. переводчика: в конце мая 2021 вышла версия 1.2.0). В Dapr все фичи предоставляются как sidecar. Он предлагает так называемые «стандартные блоки», или наборы возможностей.
Что это за возможности? Первый набор связан с сетями. Dapr может обнаруживать сервисы и устанавливать прямую интеграцию между ними. Он выполняет трейсинг, устанавливает надежное взаимодействие, обеспечивает повторные попытки и восстановление, как service mesh. Второй набор связан с привязкой ресурсов:
- У Dapr много коннекторов для облачных API и разных систем.
- Он обеспечивает обмен сообщениями по шаблону «издатель–подписчик» и другую логику.
Что интересно, в Dapr есть управление состояниями, которое дополняет Knative и service mesh. С Dapr можно взаимодействовать с помощью пар «ключ-значение» на основе механизма хранения.
В общих чертах архитектура выглядит так. Сверху у нас приложение на любом языке. Можно использовать клиентские библиотеки от Dapr, но это не обязательно. Можно использовать языковые функции, чтобы делать HTTP- и gRPC-вызовы к sidecar. Отличие от service mesh в том, что Dapr sidecar — это не прозрачный прокси. Его нужно вызывать из приложения и с ним нужно взаимодействовать по HTTP или gRPC. В зависимости от наших потребностей Dapr может общаться с другими системами, например, облачными сервисами.
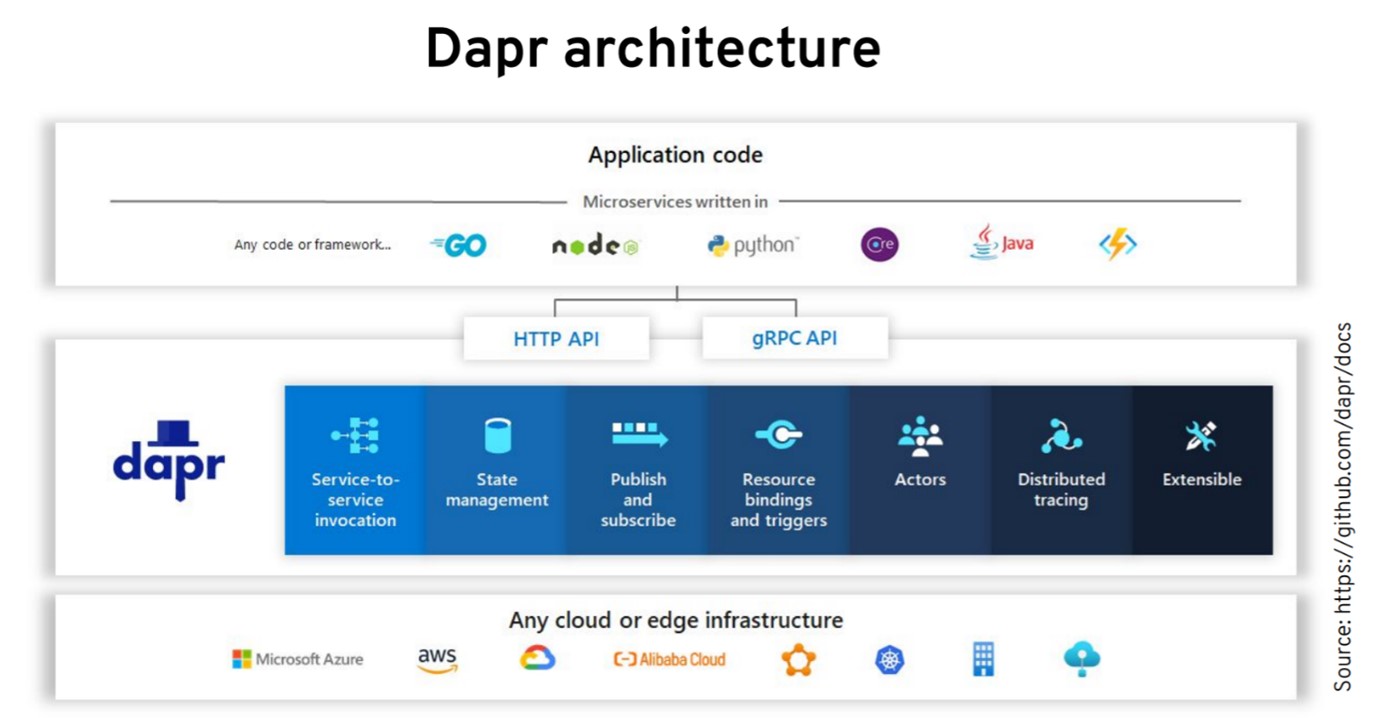
В Kubernetes Dapr деплоится как sidecar и может работать не только с Kubernetes. Более того, у него есть оператор (один из двух основных механизмов расширения). Другие компоненты управляют сертификатами, работают с моделированием на основе акторов и внедряют sidecar. Наша рабочая нагрузка взаимодействует с sidecar, который обеспечивает взаимодействие с другими сервисами, а мы получаем интероперабельность с разными облачными провайдерами.
Кроме того, в нашем распоряжении дополнительные возможности распределенной системы.
Если подытожить преимущества этих проектов, можно назвать ESB ранним воплощением распределенных систем, где у нас есть централизованная плоскость управления и плоскость данных, но нет удобного масштабирования. В облачных проектах централизованная плоскость управления еще присутствует, а вот плоскость данных децентрализована, легко масштабируется и предлагает приемлемую изоляцию.
Нам все равно нужен Kubernetes для управления жизненным циклом, но поверх него можно реализовать что-то еще. Например, Istio для расширенного взаимодействия. Knative может отвечать за бессерверные рабочие нагрузки, а Dapr — за интеграцию. Они прекрасно сочетаются с Istio и Envoy. Из Dapr и Knative можно выбрать что-то одно, но вместе они дают то, что было у нас в ESB, но в облаке.
Будущие облачные тренды — жизненный цикл
Я составил субъективный список из нескольких проектов, от которых я многого жду.

Начнем с жизненного цикла. В Kubernetes мы можем контролировать жизненный цикл приложения, но этого не хватит для более сложных сценариев, например, где примитивов развертывания Kubernetes недостаточно для сложного stateful-приложения.
В этих случаях можно использовать операторы, например, оператор, который отвечает за развертывание и апгрейд и, допустим, хранение сервиса в S3. Механизм проверки работоспособности в Kubernetes может оказаться для нас недостаточно эффективным. Допустим, нам мало проверок liveness и readiness. В этом случае можно использовать оператор для усовершенствованных проверок приложения, и на их основе выполнять восстановление.
Третий пример — автоскейлинг и тюнинг. Мы можем использовать оператор, который будет лучше понимать наше приложение и выполнять автотюнинг на платформе. На сегодня есть два основных фреймворка для написания операторов — Kubebuilder, от группы SIG Kubernetes, и Operator SDK, который входит в Operator Framework от Red Hat.
С помощью Operator SDK можно написать оператор, Operator Lifecycle Manager позволяет управлять его жизненным циклом, а в OperatorHub его можно опубликовать. Сейчас там больше 100 операторов для управления базами данных, очередями сообщений, инструментами мониторинга и т. д. В плане жизненного цикла именно в области операторов сейчас происходит самое активное развитие в экосистеме Kubernetes.
Тренды в сфере взаимодействия — Envoy
Еще один проект в моем списке — Envoy. С помощью спецификации интерфейсов service mesh нам будет проще переключаться между разными реализациями service mesh. Благодаря консолидации деплоев в Istio нам не придется деплоить семь подов на плоскости управления, достаточно одного развертывания. Гораздо интереснее, что происходит в проекте Envoy на плоскости данных. Как видим, туда добавляется все больше и больше протоколов L7.

Service mesh теперь поддерживает MongoDB, ZooKeeper, MySQL, Redis, а с недавнего времени еще и Kafka. Сообщество Kafka совершенствует свой протокол, чтобы он лучше работал с service mesh. Можно ожидать еще более тесную интеграцию и еще больше возможностей. Скорее всего, появится какая-то возможность бриджинга. Допустим, в сервисе мы делаем HTTP-вызов локально, из приложения, а прокси будет использовать Kafka. Мы можем выполнять преобразование и шифрование за пределами приложения, в sidecar для протокола Kafka.
Еще одно интересное нововведение — HTTP-кэширование, на которое теперь способен Envoy. Нам не нужно использовать клиенты кэширования в приложении, все это делается прозрачно в sidecar. Там есть фильтры перехвата, так что мы можем перехватывать и копировать трафик. Благодаря недавно появившемуся WebAssembly мы можем написать кастомный фильтр для Envoy, и при этом нам не придется использовать C++, а потом компилировать весь рантайм Envoy. Мы можем написать фильтр в WebAssembly, а потом задеплоить его в рантайме. Большинство из этих возможностей пока в разработке, но уже понятно, что плоскость данных и service mesh не остановятся на поддержке только HTTP и gRPC. Они будут поддерживать и другие протоколы на уровне приложения, чтобы у нас было больше возможностей и доступных сценариев использования. Например, с появлением WebAssembly мы можем писать кастомную логику в sidecar. Только бизнес-логику туда вставлять не надо.
Тренды в сфере привязок — Apache Camel
Apache Camel — это проект для интеграций, который предлагает множество коннекторов к разным системам с помощью шаблонов интеграции корпоративных приложений. Camel версии 3, например, глубоко интегрирован в Kubernetes и использует примитивы, о которых мы уже говорили, например операторы.
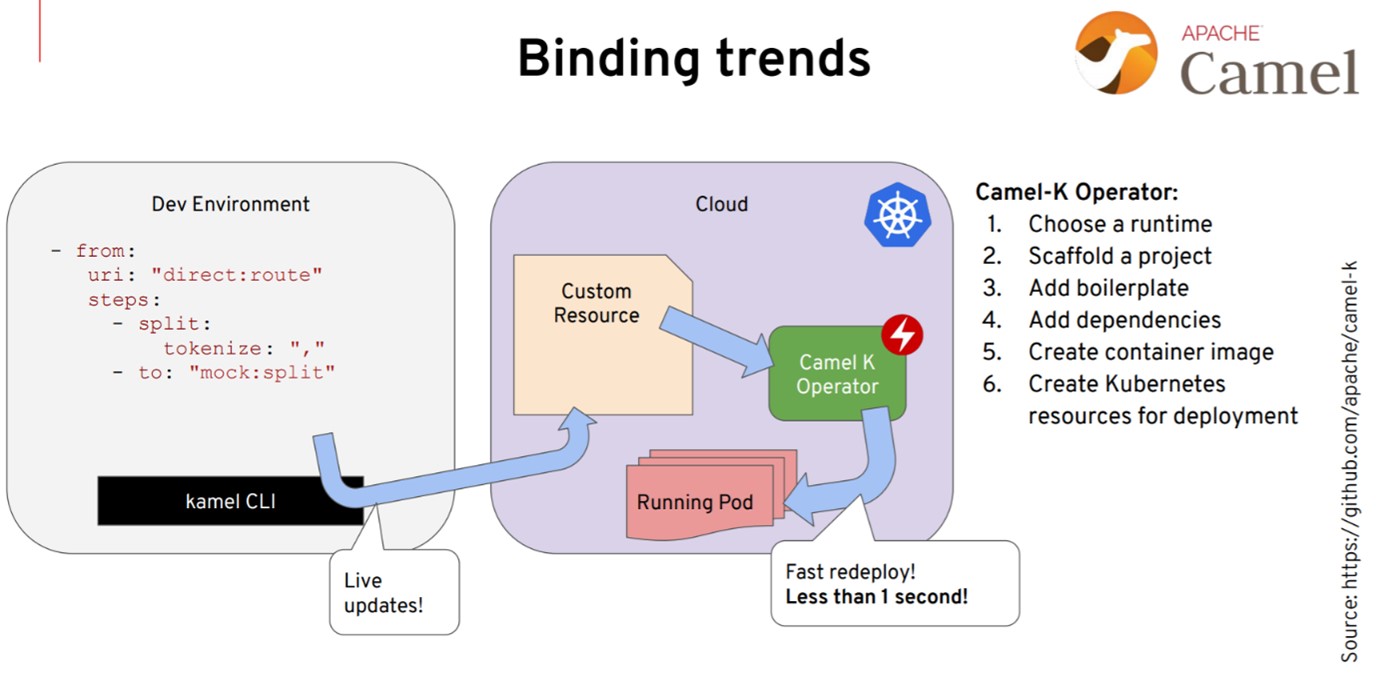
Мы можем написать логику интеграции в Camel на Java, JavaScript или YAML. В последней версии представлен оператор Camel, который выполняется в Kubernetes и понимает нашу интеграцию. Допустим, мы пишем приложение Camel и деплоим его в кастомном ресурсе, а оператор сам знает, как собрать контейнер или найти зависимости. В зависимости от возможностей нашей платформы (просто Kubernetes или Kubernetes с Knative) он решает, какие сервисы использовать и как реализовать нужную интеграцию. За пределами рантайма, в операторе, происходит много всего интересного, причем очень быстро. Почему я называю это трендом в сфере привязок? В основном, благодаря возможностям Apache Camel со всеми его коннекторами, причем все это тесно интегрировано в Kubernetes.
Тренды в сфере состояний — Cloudstate
Рассмотрим еще один проект — Cloudstate, который отвечает за состояния. Cloudstate от Lightbend ориентирован на бессерверную разработку на основе функций. Последние релизы тесно интегрированы с Kubernetes с помощью sidecar и операторов.
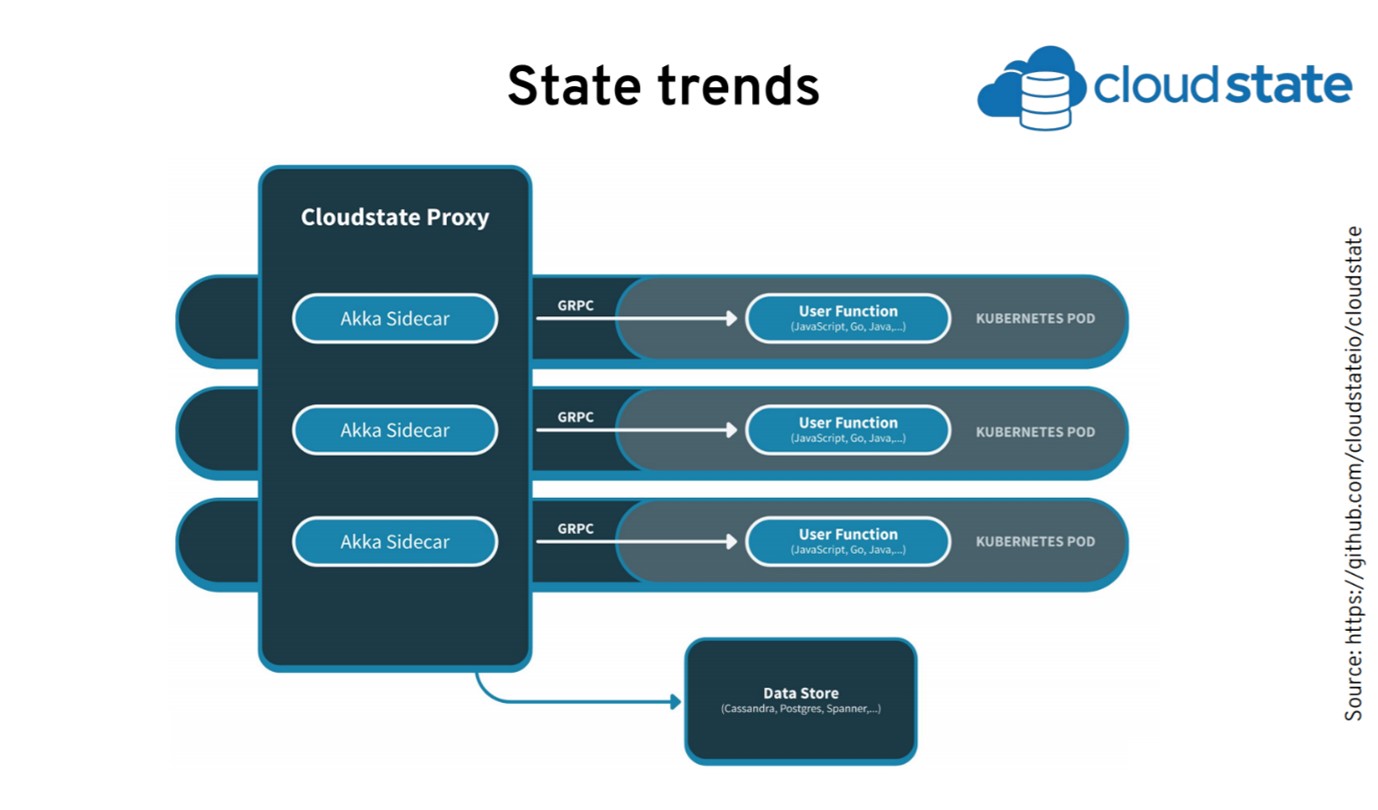
Идея в том, что когда мы пишем функцию, нам достаточно использовать gRPC, чтобы получить состояние и взаимодействовать с ним. Всё управление состояниями происходит в sidecar, который объединен с другими sidecar. Это позволяет нам создавать события, использовать CQRS, искать пары «ключ-значение» и передавать сообщения.
Приложение не вникает во все эти сложности — оно просто делает вызов к локальному sidecar, который обо всём позаботится. Sidecar может использовать два источника данных. У него есть все stateful-абстракции, которые понадобятся разработчику.
Итак, мы рассмотрели текущее состояние облачной экосистемы и последние тренды. Что всё это значит?
Микросервисы в нескольких рантаймах уже близко
Если мы используем микросервисы в Kubernetes, нам нужен разный функционал. Например, Kubernetes должен управлять жизненным циклом. Скорее всего, нам понадобится прозрачная service mesh, что-то вроде Envoy, для взаимодействия, допустим, для маршрутизации трафика, обеспечения устойчивости, дополнительной безопасности или хотя бы для мониторинга. Поверх, в зависимости от сценария и рабочих нагрузок, можно использовать Dapr или Knative. Всё это доступные нам дополнительные возможности, которые предоставляются вне процесса. Нам остаётся только написать бизнес-логику в отдельном рантайме. Скорее всего, в будущем микросервисы будут представлять собой несколько рантаймов, состоящих из нескольких контейнеров. Некоторые из них будут прозрачными, другие мы будем использовать явно.
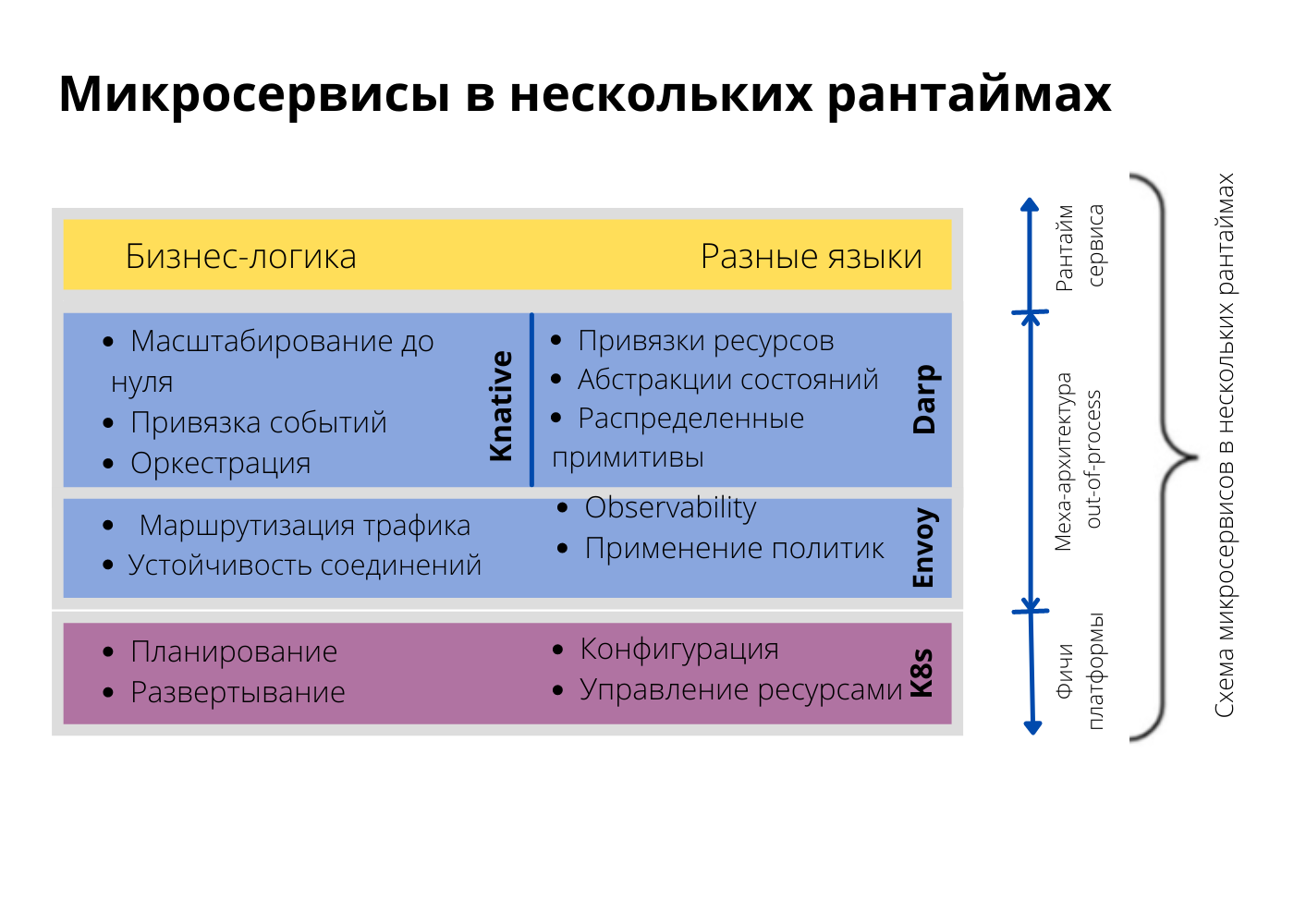
Умные sidecar, глупые каналы
Я представляю это так. Мы пишем бизнес-логику на любом высокоуровневом языке — это уже не обязательно должен быть Java, берите любой.
Любые взаимодействия между бизнес-логикой и внешним миром происходят через sidecar, который интегрирован в платформы, управляет жизненным циклом, абстрагирует подключения для внешней системы и предоставляет расширенные возможности привязки и абстракций состояния. Мы не пишем sidecar сами — просто берем готовый, немного корректируем YAML или JSON и используем. Это значит, что sidecar можно легко обновлять и исправлять, ведь он больше не входит в наш рантайм. Получаем рантайм для бизнес-логики на любом языке.
Что будет после микросервисов?
Возвращаемся к вопросу, который я задал в начале, — что будет после микросервисов?

Если вспомнить, как развивалась архитектура приложений, все началось с монолитов. Микросервисы показали принципы разделения монолитных приложений на бизнес-домены. Затем появились бессерверные архитектуры и функция как услуга (FaaS), когда мы поняли, что приложения можно делить на операции. Так мы получили широкие возможности масштабирования, ведь масштабировать можно каждую операцию по отдельности.
FaaS, пожалуй, не лучшая модель. С помощью функций непросто реализовать сложные сервисы, в которых несколько операций должны вместе взаимодействовать с одним набором данных. Скорее всего, это будет несколько рантаймов, я называю это меха-архитектурой, где бизнес-логика находится в одном контейнере, а все, что связано с инфраструктурой, — в другом. Вместе они представляют микросервис в нескольких рантаймах. Пожалуй, это более подходящая модель, потому что мы получаем все преимущества микросервисов, при этом вся бизнес-логика хранится в одном месте, а все требования к инфраструктуре и распределённой системе находятся в отдельном контейнере, и их можно объединять в рантайме. Наверное, ближе всего к такой архитектуре сейчас Dapr. Если вас больше интересует, как реализовать взаимодействие, Envoy тоже приближается к этой модели.

redskif
спасибо за перевод, еще не читал но видно что глобальная статья и думаю она будет популярна в закладках.
И хочу предложить поменять в тексте «меха»-компоненты и меха-архитекура на мех-компоненты и мех-архитектуру, мне кажется это более правильное сокращение, но возможно мой словарный запас банально испорчен чтением книг BattleTech в юные годы.
Polina_Averina Автор
Добрый день! Спасибо за комментарий! Возможно, вы правы, мы просто не нашли устоявшегося термина и оставили вариант, максимально близкий к оригиналу.