
Уже около года команда поддержки одного из наших высоконагруженных продуктов использует ML-систему нашей собственной разработки – Problem Detection Platform (PDP). Этот сервис умеет анализировать логи и автоматически классифицировать возникающие ошибки. В результате саппорт получает из логов не тонны сырой информации, а данные, с которыми можно быстро и удобно работать.
Платформа использует машинное обучение, чтобы определять ранние признаки сбоев в логах. В отличие от человека, роботу несложно просмотреть десятки тысяч цепочек логов и найти в них характерные признаки технических сбоев. Обученная модель может использовать накопленный опыт, чтобы таким же образом фиксировать будущие проблемы. По этим данным инженеры смогут принимать решение: завести баг в разработку или пропустить, потому что это типичная ошибка. В результате поддержка избавляется от рутины, её эффективность качественно вырастает.
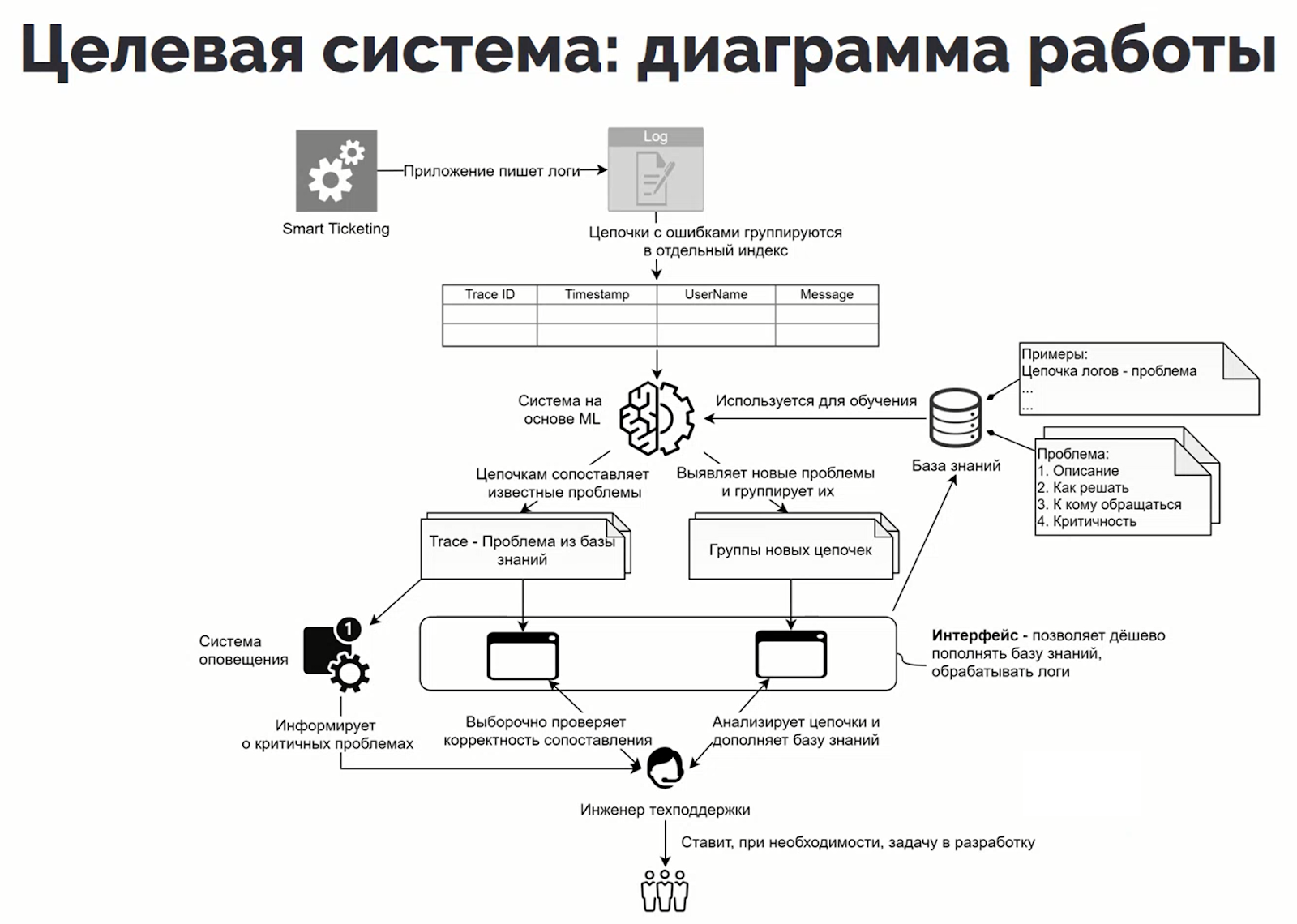
Как это работает
Решение состоит из трёх приложений: одно анализирует логи и сохраняет результат анализа в базу, второе раз в сутки обновляет модель, т.е. обеспечивает возможность обучения, третье (консольная утилита) позволяет корректировать результаты для дообучения модели. У инженеров также есть дашборд в Kibana, где можно погрузиться в нужные события.
Результаты анализа сервис собирает в Excel-таблицу, где можно увидеть общую статистику по возникшим проблемам, разбивку по классам и потенциальной угрозе, динамику в течение дня. Тут же можно увидеть, какие события имеют регулярный характер, а какие случились впервые.
Датасет для обучения модели собрали так:
Взяли 130 000 логов из системы (это цифра за 5 дней)
Выделили скриптом из них порядка 3500 уникальных логов со схожими сообщениями
Сгруппировали их в 37 файлов по уровню похожести
Заполнили описания, по которым модель относит ошибку к определенному кластеру и определенной группе.
PDP в нашей практике
В прошлом году с прототипом продукта начала работать команда поддержки нашей высоконагруженной системы продаж. Уже в первые недели благодаря PDP поддержка действительно нашла несколько багов и технических проблем. В том числе, ошибку, которая влияла на критически важный бизнес-процесс.
В первые месяцы работа была рутинной – нужно было обучить модель. Для этого инженеры в ручном режиме размечали ошибки в поступающих логах. Проработали десятки тысяч логов, чтобы PDP научилась сама определять в них ошибки.
И со временем результаты стали всё очевиднее. Главное – стало возможно эффективно работать с большим объемом записей в логах. В день сейчас возникает около 58 тыс событий, и в отличие от человека, система читает каждую строчку. Поддержка видит динамику по известным кейсам, быстро замечает неизвестные, новые ошибки.
Всё это очень ценная информация для поддержки. Например, можно увидеть, что несколько десятков ошибок могут быть серьёзнее тысячи инцидентов. Если последние размазаны по суткам, то проблемы может и не быть, а ошибки носят технический характер. А вот пик из небольшого количества ошибок за короткое время может говорить об угрозе.
На практике это означает, что команда не узнаёт о проблемах от заказчика или пользователей, а выпускает хотфикс буквально в течение получаса после релиза (реальная цифра).
Что планируем дальше
На данный момент сервис на стадии прототипа. Конечная цель - сделать настоящий MLOps с автоматическими и непрерывными процессы сбора данных для обучения, дообучения модели, её публикации. Плюс, технологии для обеспечения отказоустойчивости и масштабирования под нагрузками и непрерывного сопровождения во время работы.
Чтобы сократить ручную работу саппорта и участие специалистов в работе PDP, нужно точнее определять критичность событий и правильно относить его к какому-то из классов. В теории машинного обучения работа по выделению новых признаков называется Feature Engineering. В итоге PDP будет бить тревогу только в тех случаях, когда поддержке действительно стоит обратить внимание на ошибки.
Ещё одно важное направление – обработка ошибок средней критичности, если их количество начинает резко расти. Иногда плотный поток не самых значимых сбоев говорит о серьёзных проблемах – такие случаи могут не встревожить PDP, но отлавливать их надо. Чтобы реализовать эту качественно новую функцию, в систему добавят дополнительную модель.
Не забываем и про UX. Сейчас команда поддержки смотрит логи в Kibana, а анализ событий и дообучение модели происходит через Excel. В финальной версии PDP будет единое окно, чтобы посмотреть сводную информацию по ошибкам в том или ином классе, доразметить события, отправить данные для дообучения. Также в планах реализация предикативного ввода, чтобы система подсказывала уже известные проблемы по введённым символам или сообщала, что аналогичная цепочка уже размечалась в прошлом.
Однако по отзывам поддержки, уже на стадии прототипа PDP свою полезность доказала:
«Картинка по критичности и частоте возникающих проблем выглядит объективно. Уже в нынешнем виде инструмент стал маст-хэвом на запуск после релизов, благодаря тому, что можно моментально замечать ошибки».
Комментарии (2)

Groramar
21.07.2021 17:36ML это отлично! Однако продуманная система журналирования, которая сама бы выделяла критические проблемы среди тысяч рядовых записей мне кажется была бы лучше и надежнее.
Говорю по опыту журналирования достаточно нагруженных систем в том числе.
S_A
Молодцы что внедряете ML! вы кстати смотрели что предлагает в этом плане elasticsearch из коробки? насколько помню там только unsupervised + timeseries, но обогатить вход фичами можно предполагаю неплохо.
а так... хорошо когда есть разметка :)