
В процессорах компании Intel на смену AVX2 приходит новый набор инструкций AVX512, в котором появилась концепция масочных регистров. Автор этой статьи уже несколько лет занимается разработкой версии библиотеки Intel Integrated Performance Primitives, оптимизированной для AVX512, и накопил довольно большой опыт использования AVX512 инструкций с масками, который было решено объединить в одну отдельную статью, поскольку само использование таких инструкций с масками позволяет упростить и ускорить код в дополнение к ускорению от двукратного увеличения ширины регистров.
Рассмотрим функцию сложения двух изображений.
Код функции очень прост и в принципе компилятор icl вполне способен векторизовать данный код. Однако наша цель – продемонстрировать использование масочных avx512 регистров, поэтому напишем первую и очевидную версию avx512 кода.
В данном коде добавлен цикл, складывающий сразу по 16 элементов за итерацию. Поскольку ширина изображения может быть произвольной и не кратной 16, то в следующем цикле складываются элементы, оставшиеся до конца строки. Число таких элементов может достигать 15-ти, и влияние этого цикла на общую производительность может быть достаточно велико. Использование же масочных регистров позволяет существенно ускорить обработку «хвоста».
Массив len2mask используется для преобразования числа в соответствующее число битов подряд. И вместо скалярного цикла, мы получаем всего один if, который в-принципе тоже не обязателен, поскольку в случае маски состоящей из одних нулей, чтение и запись не будут осуществляться.
Для достижения максимальной производительности рекомендуется выравнивать данные на ширину кэш линии, а загрузки осуществлять по выровненному на ширину регистра адресу. В Skylake ширина кэш линии по прежнему 64 байта, поэтому, в нашем коде мы можем добавить такое выравнивание по pDst опять же с помощью масочных операций, но только до основного цикла.
Код стал выглядеть короче, и при достаточно длинной последовательности вычислений, затраты на вычисление маски в каждой итерации на таком фоне могут оказаться незначительными.
В различных алгоритмах обработки изображений одним из входных параметров может быть бинарная маска. К примеру, такая маска используется в операциях морфологии изображений.
Функция ищет минимальный по величине пиксель внутри квадрата 3x3. Входная маска pMask представляет собой массив из 3x3=9 байтов. Если значение байта не равно нулю, то входной пиксель из квадрата 3x3 участвует в поиске, если равно, то не участвует.
Пишем avx512 код.
Вначале формируется массив масок __mmask msk[9]. Каждая маска получается заменой байта из pMask на бит (0 на 0, все другие значения на 1) и этот бит размножается на 16 элементов. Основной цикл загружает по этой маске 16 элементов. Причем, если элемент не участвует в поиске, то он и не будет загружен. В данном коде также с помощью масок обрабатывается и хвост, мы просто выполняем операцию & над маской операции морфологии и маской хвоста.
Конечно, продемонстрированый код не совсем оптимален, однако он демонструет саму идею, а усложнение кода привело бы к потере наглядности.
Еще в первом 256 битном наборе инструкций AVX регистры были разделены барьером на 2 части, называемые lane. Большинство векторных инструкции независимо обрабатывают эти части. Выглядит это как 2 параллельные SSE инструкции. В avx512 регистр разделяется уже на четыре 128-битные части по четыре float/int элемента. А во многих алгоритмах обработки изображений используются три канала и объединение их по 4 довольно проблематично. В этом случае можно рассмотреть возможность использования инструкций вида expand/compress
__m512 _mm512_mask_expandloadu_ps (__m512 src, __mmask16 k, void const* mem_addr)
void _mm512_mask_compressstoreu_ps (void* base_addr, __mmask16 k, __m512 a)
Инструкция _mm512_mask_expandloadu_ps загружает из памяти непрерывный блок float данных длиной равной количеству единичных бит в маске. Таким образом может быть загружен блок длиной от 0 до 16 элементов. В регистр-приемник данные помещаются следующим образом. Начиная с самого младшего бита маски проверяется, если бит равен 1, то элемент из памяти записывается в регистр, если 0, то переходим к рассмотрению следующего бита и того же самого элемента, рис. 3.1
Рис. 3.1 Демонстрация работы _mm512_mask_expandloadu_ps
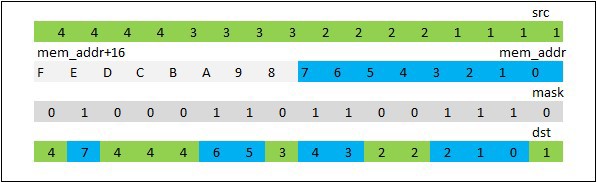
Видно, что область памяти как бы “растягивается” (expand) по всему 512 битному регистру. Инструкция _mm512_mask_compressstoreu_ps работает в противоположную сторону — “сжимает”(compress) регистр по маске и записывает в непрерывную область памяти.
Итак, допустим нам необходимо перейти из цветового пространства RGB в XYZ.
Используя expand/compress avx512 код может выглядеть следующим образом.
С помощью _mm512_mask_expandloadu_ps мы помещаем 4 пикселя в разные lane, после чего последовательно формируем r3r3r3r3 … r0r0r0, …g0g0g0, b0b0b0 и умножаем на коэффициенты преобразования. Для проверки переполнения также используются операции с масками _mm512_mask_max/min_ps. Запись преобразованных данных обратно в память выполняется командой _mm512_mask_compressstoreu_ps. В этой функции для обработки хвоста также можно использовать маски, в зависимости от длины хвоста.
Если Вы дочитали до этого места, то уже подготовлены к самой, на мой взгляд, интересной области применения масочных регистров. Это векторизация циклов с условиями. Речь идет о некоем подобии предикатных регистров, имеющихся в процессорах семейства Itanium. Рассмотрим простую функцию, у которой есть if внутри цикла for.
Функция осуществляет интерполяцию по соседним горизонтальным или вертикальнам элементам, между которыми разность минимальна. Главное здесь то, что внутри цикла идет разделения на две ветки, когда if-условие истенно, и когда нет. Но, мы можем вычислить на avx512 регистрах значения в том и другом случае, а потом их объединить по маске.
Таких if в реализуемом алгоритме может быть несколько, для них можно завести новые маски до тех пор пока код будет быстрее скалярного.
В действительности, компилятор icc вполне способен векторизовать код 4.1 Для этого достаточно всего лишь добавить ключевое слово restrict к указателям pSrc1 и pDst и ключ –Qrestrict.
Напомню, что модификатор restrict указывает компилятору, что доступ к объекту осуществляется только через этот указатель и таким образом вектора pSrc1 и pDst не пересекаются, что и делает возможной векторизацию.
Измерения на внутреннем симуляторе CPU с поддержкоий avx512 показывают, что производительность практически равна производительности нашего avx512 кода. Т.е компилятор тоже умеет эффективно использовать маски
Казалось бы на этом все. Но посмотрим, что будет если мы слегка модицифируем нашу функцию и внесем в нее зависимость между итерациями.
Функция также осуществляет интерполяцию по соседним пикселям, и если разница по вертикали и горизонтали одинакова, то используется то направление интерполяции, которое было в предыдущей итерации. На алгоритмах такого рода снижается эффект от механизма out of order, реализованных в современных cpu из-за того, что образуется длинная последовательность зависимых операций. Компилятор также теперь не может векторизовать цикл и производительность стала в 17 раз медленее. Т.е. как раз примерно на ширину в 16 float элементов в AVX512 регистре. Теперь попробуем как-то модифицировать и наш avx512 код, чтобы получить хоть какое то ускорение.
Введем в рассмотрение следующие бинарные маски-переменные
mskV(n) – для n-го элемента V разница минимальна
mskE(n) – для n-го элемента V и H разницы одинаковы
mskD(n) – для n-го элемента использована V интерполяция.
Теперь построим таблицу истинности, как формируется mskD(n) в зависимости от mskV(n),mskE(n) и предыдущей использованой маски – mskD(n-1)
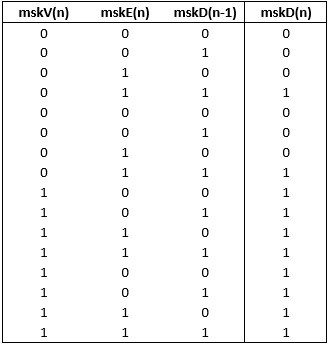
Из таблицы следует, что
mskD(n) = mskV(n) | (mskE(n)&mskD(n-1)),
что в общем-то и так было очевидно. Итак наш avx512 код будет выглядеть следующим образом.
В нем последовательно перебираются все 16 бит маски. На размере 64x64 он работает в ~1.7X раз быстрее чем С-шный. Ну хотя бы что-то удалось получить. Следующая возможная оптимизация заключается в том, что можно предварительно просчитать все комбинации масок. На каждой итерации по 16 элементов у нас есть 16 бит mskV, 16 бит mskE, и 1 бит от предыдущей итерации. Итого 2^33 степени вариантов для mskD. Это много. А что если обрабатывать не по 16, а по 8 элементов за итерацию? Получаем 2^(8+8+1)=128кбайт таблицу. А это вполне вменяемый размер. Создаем функцию инициализации.
Переписываем код.
Код стал работать в ~4.1X раз быстрее. Можно добававить обработку по 16 элементов, но к таблице придется обратиться дважды за итерацию.
Теперь ускорение составляет ~5.6X по сравнению с изначальным С кодом, что очень даже неплохо для алгоритма с обратной связью. Таким образом комбинация масочного регистра и предварительно вычисленной таблицы позволяет получить существенный прирост производительности. Код такого рода вовсе не является специально подобранным для статьи и встречается к примеру в алгоритмах обработки фотографий, при конвертации изображения из RAW формата. Правда там используются целочисленные значения, но такой табличный метод вполне можно применить и для них.
В этой статье показаны лишь некоторые способы применения масочных инструкций AVX 512. Вы можете применять их в своих приложениях или придумывать свои приемы. А можете воспользоваться библиотекой IPP, в которой уже присутствует код, оптимизированный специально для процессоров Intel с поддержкой avx512, важной частью которого являются инструкции с масочными регистрами.
Пример 1. Применяем инструкции с масками «до и после» основного цикла
Рассмотрим функцию сложения двух изображений.
Лист 1.1
void add_ref( const float* pSrc1, int src1Step, const float* pSrc2, int src2Step,
float* pDst, int dstStep, int width, int height)
{
int h, i;
for( h = 0; h < height; h++ ) {
for( i = 0; i < width; i++ ) {
pDst[i] = pSrc1[i] + pSrc2[i];
}
pSrc1 = pSrc1 + src1Step;
pSrc2 = pSrc2 + src2Step;
pDst = pDst + dstStep;
}
}
Код функции очень прост и в принципе компилятор icl вполне способен векторизовать данный код. Однако наша цель – продемонстрировать использование масочных avx512 регистров, поэтому напишем первую и очевидную версию avx512 кода.
Лист 1.2
void add_avx512( const float* pSrc1, int src1Step, const float* pSrc2, int src2Step,
float* pDst, int dstStep, int width, int height)
{
int h, i;
for( h = 0; h<height; h++ ) {
i = 0;
__m512 zmm0, zmm1;
for(i=i; i < (width&(~15)); i+=16 ) {
zmm0 = _mm512_loadu_ps(pSrc1+i );
zmm1 = _mm512_loadu_ps(pSrc2+i );
zmm0 = _mm512_add_ps(zmm0, zmm1);
_mm512_storeu_ps (pDst+i, zmm0 );
}
for(i=i; i < width; i++ ) {
pDst[i] = pSrc1[i] + pSrc2[i];
}
pSrc1 = pSrc1 + src1Step;
pSrc2 = pSrc2 + src2Step;
pDst = pDst + dstStep;
}
}
В данном коде добавлен цикл, складывающий сразу по 16 элементов за итерацию. Поскольку ширина изображения может быть произвольной и не кратной 16, то в следующем цикле складываются элементы, оставшиеся до конца строки. Число таких элементов может достигать 15-ти, и влияние этого цикла на общую производительность может быть достаточно велико. Использование же масочных регистров позволяет существенно ускорить обработку «хвоста».
Лист 1.3
__mmask16 len2mask[] = { 0x0000, 0x0001, 0x0003, 0x0007,
0x000F, 0x001F, 0x003F, 0x007F,
0x00FF, 0x01FF, 0x03FF, 0x07FF,
0x0FFF, 0x1FFF, 0x3FFF, 0x7FFF,
0xFFFF };
void add_avx512_2( float* pSrc1, int src1Step, const float* pSrc2, int src2Step,
float* pDst, int dstStep, int width, int height)
{
int h, i;
for( h = 0; h < height; h++ ) {
i = 0;
__m512 zmm0, zmm1;
__mmask16 msk;
for(i=i; i < (width&(~15)); i+=16 ) {
zmm0 = _mm512_loadu_ps(pSrc1+i );
zmm1 = _mm512_loadu_ps(pSrc2+i );
zmm0 = _mm512_add_ps (zmm0, zmm1);
_mm512_storeu_ps (pDst+i, zmm0 );
}
msk = len2mask[width - i];
if(msk){
zmm0 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc1+i );
zmm1 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc2+i );
zmm0 = _mm512_add_ps (zmm0, zmm1);
_mm512_mask_storeu_ps (pDst+i, msk, zmm0 );
}
pSrc1 = pSrc1 + src1Step;
pSrc2 = pSrc2 + src2Step;
pDst = pDst + dstStep;
}
}
Массив len2mask используется для преобразования числа в соответствующее число битов подряд. И вместо скалярного цикла, мы получаем всего один if, который в-принципе тоже не обязателен, поскольку в случае маски состоящей из одних нулей, чтение и запись не будут осуществляться.
Для достижения максимальной производительности рекомендуется выравнивать данные на ширину кэш линии, а загрузки осуществлять по выровненному на ширину регистра адресу. В Skylake ширина кэш линии по прежнему 64 байта, поэтому, в нашем коде мы можем добавить такое выравнивание по pDst опять же с помощью масочных операций, но только до основного цикла.
Лист 1.4
void add_avx512_3(float* pSrc1, int src1Step, const float* pSrc2, int src2Step,
float* pDst, int dstStep, int width, int height)
{
int h, i, t;
for( h = 0; h < height; h++ ) {
i = 0;
__m512 zmm0, zmm1;
__mmask16 msk;
t = ((((int)pDst) & (63)) >> 2);
msk = len2mask[t];
if(msk){
zmm0 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc1+i );
zmm1 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc2+i );
zmm0 = _mm512_add_ps (zmm0, zmm1);
_mm512_mask_storeu_ps (pDst+i, msk, zmm0 );
}
i += t;
for(i=i; i < (width&(~15)); i+=16 ) {
zmm0 = _mm512_loadu_ps(pSrc1+i );
zmm1 = _mm512_loadu_ps(pSrc2+i );
zmm0 = _mm512_add_ps (zmm0, zmm1);
_mm512_storeu_ps (pDst+i, zmm0 );
}
msk = len2mask[width - i];
if(msk){
zmm0 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc1+i );
zmm1 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc2+i );
zmm0 = _mm512_add_ps (zmm0, zmm1);
_mm512_mask_storeu_ps (pDst+i, msk, zmm0 );
}
pSrc1 = pSrc1 + src1Step;
pSrc2 = pSrc2 + src2Step;
pDst = pDst + dstStep;
}
}
<source>
</spoiler>
Рассмотренная функция add довольно простая и тут вполне допустимо сделать загрузки по маске до и после основного цикла. Но в более сложных, к примеру целочисленных с округлением к ближайшему четному, алгоритмах количество таких операций может достигать десятков и такая методика маски для выравнивания и обработки хвоста может привести к существенному увеличению размера кода. А править ошибки придется в трех разных местах этого довольно длинного кода. Использование же масочных регистров позволяет и снизить размер кода и упростить его дальнейшую поддержку. Лист. 1.5 демонстрирует эту идею
<spoiler title=" Лист 1.5">
<source lang="C++">
#define min(a,b) ((a)<(b)?(a):(b))
void add_avx512_4( const float* pSrc1, int src1Step, const float* pSrc2, int src2Step,
float* pDst, int dstStep,
int width, int height)
{
int h, i;
for( h = 0; h < height; h++ ) {
i = 0;
__m512 zmm0, zmm1;
__mmask16 msk;
for(i=i; i < width; i+=16 ) {
msk = len2mask[min(16, width - i)];
zmm0 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc1+i );
zmm1 = _mm512_mask_loadu_ps(_mm512_setzero_ps(),msk,pSrc2+i );
zmm0 = _mm512_add_ps (zmm0, zmm1);
/*THE LONG PIPELINE HERE*/
_mm512_mask_storeu_ps (pDst+i, msk, zmm0 );
}
pSrc1 = pSrc1 + src1Step;
pSrc2 = pSrc2 + src2Step;
pDst = pDst + dstStep;
}
}
Код стал выглядеть короче, и при достаточно длинной последовательности вычислений, затраты на вычисление маски в каждой итерации на таком фоне могут оказаться незначительными.
Пример 2. Маска как непосредственная часть реализуемого алгоритма.
В различных алгоритмах обработки изображений одним из входных параметров может быть бинарная маска. К примеру, такая маска используется в операциях морфологии изображений.
Лист 2.1
void morph_3x3_ref( const float* pSrc1, int src1Step, char* pMask,
float* pDst, int dstStep, int width, int height)
{
int h, i;
for( h = 0; h < height; h++ ) {
for(i=0; i < width; i++ ) {
int x, y;
char* pm = pMask;
/*we assume that pMask is not zero total*/
float m = 3.402823466e+38f;
float val = 0.0;
for (y = 0; y < 3;y++){
for (x = 0; x < 3; x++){
if (*pm){
val = pSrc1[i + src1Step*y + x];
if (val < m) {
m = val;
}
}
pm++;
}
}
pDst[i] = m;
}
pSrc1 = pSrc1 + src1Step;
pDst = pDst + dstStep;
}
}
Функция ищет минимальный по величине пиксель внутри квадрата 3x3. Входная маска pMask представляет собой массив из 3x3=9 байтов. Если значение байта не равно нулю, то входной пиксель из квадрата 3x3 участвует в поиске, если равно, то не участвует.
Пишем avx512 код.
Лист 2.2
void morph_3x3_avx512( const float* pSrc1, int src1Step, char* pMask, float* pDst, int dstStep, int width, int height)
{
int h, i;
__mmask msk[9], tail_msk;
for ( i = 0; i < 9; i++){
msk[i] = (!pMask[i]) ? 0 : 0xFFFF;//create load mask
}
tail_msk = len2mask[width & 15]; //tail mask
for( h = 0; h < height; h++ ) {
__m512 zmm0, zmmM;
int x, y;
i = 0;
for(i=i; i < (width&(~15)); i+=16 ) {
zmmM = _mm512_set1_ps(3.402823466e+38f);
for (y = 0; y < 3;y++){
for (x = 0; x < 3; x++){
zmm0 = _mm512_mask_loadu_ps(zmmM, msk[3*y+x], &pSrc1[i + src1Step*y + x]);
zmmM = _mm512_min_ps(zmm0, zmmM);
}
}
_mm512_storeu_ps (pDst+i, zmmM );
}
if(tail_msk) {
zmmM = _mm512_set1_ps(3.402823466e+38f);
for (y = 0; y < 3;y++){
for (x = 0; x < 3; x++){
zmm0=_mm512_mask_loadu_ps(zmmM,msk[3*y+x]&tail_msk,&pSrc1[i+src1Step*y+x]);
zmmM=_mm512_min_ps(zmm0, zmmM);
}
}
_mm512_mask_storeu_ps (pDst+i, tail_msk, zmmM );
}
pSrc1 = pSrc1 + src1Step;
pDst = pDst + dstStep;
}
}
Вначале формируется массив масок __mmask msk[9]. Каждая маска получается заменой байта из pMask на бит (0 на 0, все другие значения на 1) и этот бит размножается на 16 элементов. Основной цикл загружает по этой маске 16 элементов. Причем, если элемент не участвует в поиске, то он и не будет загружен. В данном коде также с помощью масок обрабатывается и хвост, мы просто выполняем операцию & над маской операции морфологии и маской хвоста.
Конечно, продемонстрированый код не совсем оптимален, однако он демонструет саму идею, а усложнение кода привело бы к потере наглядности.
Пример 3. Инструкции семейства expand/compress
Еще в первом 256 битном наборе инструкций AVX регистры были разделены барьером на 2 части, называемые lane. Большинство векторных инструкции независимо обрабатывают эти части. Выглядит это как 2 параллельные SSE инструкции. В avx512 регистр разделяется уже на четыре 128-битные части по четыре float/int элемента. А во многих алгоритмах обработки изображений используются три канала и объединение их по 4 довольно проблематично. В этом случае можно рассмотреть возможность использования инструкций вида expand/compress
__m512 _mm512_mask_expandloadu_ps (__m512 src, __mmask16 k, void const* mem_addr)
void _mm512_mask_compressstoreu_ps (void* base_addr, __mmask16 k, __m512 a)
Инструкция _mm512_mask_expandloadu_ps загружает из памяти непрерывный блок float данных длиной равной количеству единичных бит в маске. Таким образом может быть загружен блок длиной от 0 до 16 элементов. В регистр-приемник данные помещаются следующим образом. Начиная с самого младшего бита маски проверяется, если бит равен 1, то элемент из памяти записывается в регистр, если 0, то переходим к рассмотрению следующего бита и того же самого элемента, рис. 3.1
Рис. 3.1 Демонстрация работы _mm512_mask_expandloadu_ps
Видно, что область памяти как бы “растягивается” (expand) по всему 512 битному регистру. Инструкция _mm512_mask_compressstoreu_ps работает в противоположную сторону — “сжимает”(compress) регистр по маске и записывает в непрерывную область памяти.
Итак, допустим нам необходимо перейти из цветового пространства RGB в XYZ.
Лист 3.1
void rgb_ref( const float* pSrc1, int src1Step,
float* pDst, int dstStep, int width, int height)
{
int h, i;
for( h = 0; h < height; h++ ) {
for(i=0; i < width; i++ ) {
pDst[3*i+0]=(0.412f*pSrc1[3*i]+0.357f*pSrc1[3*i+1]+0.180f*pSrc1[3*i+2]);
pDst[3*i+1]=(0.212f*pSrc1[3*i]+0.715f*pSrc1[3*i+1]+0.072f*pSrc1[3*i+2]);
pDst[3*i+2]=(0.019f*pSrc1[3*i]+0.119f*pSrc1[3*i+1]+0.950f*pSrc1[3*i+2]);
if (pDst[3 * i + 2] < 0.0){
pDst[3 * i + 2] = 0.0;
}
if (pDst[3 * i + 2] > 1.0){
pDst[3 * i + 2] = 1.0;
}
}
pSrc1 = pSrc1 + src1Step;
pDst = pDst + dstStep;
}
}
Используя expand/compress avx512 код может выглядеть следующим образом.
Лист 3.2
void rgb_avx512( const float* pSrc1, int src1Step, float* pDst, int dstStep, int width, int height)
{
int h, i;
for( h = 0; h < height; h++ ) {
__m512 zmm0, zmm1, zmm2, zmm3;
i = 0;
for(i=i; i < (width&(~3)); i+=4 ) {
zmm0 = _mm512_mask_expandloadu_ps(_mm512_setzero_ps(), 0x7777, &pSrc1[3*i ]);
zmm1 = _mm512_mul_ps(_mm512_set4_ps(0.0f, 0.019f, 0.212f, 0.412f), _mm512_shuffle_ps(zmm0, zmm0, 0x00));
zmm2 = _mm512_mul_ps(_mm512_set4_ps(0.0f, 0.119f, 0.715f, 0.357f), _mm512_shuffle_ps(zmm0, zmm0, 0x55));
zmm3 = _mm512_mul_ps(_mm512_set4_ps(0.0f, 0.950f, 0.072f, 0.180f), _mm512_shuffle_ps(zmm0, zmm0, 0xAA));
zmm0 = _mm512_add_ps(zmm1, zmm2);
zmm0 = _mm512_add_ps(zmm0, zmm3);
zmm0 = _mm512_mask_max_ps(zmm0, 0x4444,_mm512_set1_ps(0.0f), zmm0);
zmm0 = _mm512_mask_min_ps(zmm0, 0x4444,_mm512_set1_ps(1.0f), zmm0);
_mm512_mask_compressstoreu_ps (pDst+3*i, 0x7777, zmm0 );
}
pSrc1 = pSrc1 + src1Step;
pDst = pDst + dstStep;
}
}
С помощью _mm512_mask_expandloadu_ps мы помещаем 4 пикселя в разные lane, после чего последовательно формируем r3r3r3r3 … r0r0r0, …g0g0g0, b0b0b0 и умножаем на коэффициенты преобразования. Для проверки переполнения также используются операции с масками _mm512_mask_max/min_ps. Запись преобразованных данных обратно в память выполняется командой _mm512_mask_compressstoreu_ps. В этой функции для обработки хвоста также можно использовать маски, в зависимости от длины хвоста.
Пример 4. Векторизация ветвления
Если Вы дочитали до этого места, то уже подготовлены к самой, на мой взгляд, интересной области применения масочных регистров. Это векторизация циклов с условиями. Речь идет о некоем подобии предикатных регистров, имеющихся в процессорах семейства Itanium. Рассмотрим простую функцию, у которой есть if внутри цикла for.
Лист 4.1
#define ABS(A) (A)>=0.0f?(A):(-(A))
void avg_ref( float* pSrc1, int src1Step,
float* pDst, int dstStep, int width, int height)
{
int h, i;
for( h = 0; h < height; h++ ) {
for(i=0; i < width; i++ ) {
float dv, dh;
float valU = pSrc1[src1Step*(h - 1) + i ];
float valD = pSrc1[src1Step*(h + 1) + i ];
float valL = pSrc1[src1Step*( h ) + (i-1)];
float valR = pSrc1[src1Step*( h ) + (i+1)];
dv = ABS(valU - valD);
dh = ABS(valL - valR);
if(dv<=dh){
pDst[i] = (valU + valD) * 0.5f; //A branch
} else {
pDst[i] = (valL + valR) * 0.5f; //B branch
}
}
pDst = pDst + dstStep;
}
}
Функция осуществляет интерполяцию по соседним горизонтальным или вертикальнам элементам, между которыми разность минимальна. Главное здесь то, что внутри цикла идет разделения на две ветки, когда if-условие истенно, и когда нет. Но, мы можем вычислить на avx512 регистрах значения в том и другом случае, а потом их объединить по маске.
Лист 4.2
void avg_avx512( const float* pSrc1, int src1Step,
float* pDst, int dstStep, int width, int height)
{
int h, i;
for( h = 0; h < height; h++ ) {
i = 0;
for(i=i; i < (width&(~15)); i+=16 ) {
__m512 zvU, zvD, zvL, zvR;
__m512 zdV, zdH;
__m512 zavgV, zavgH, zavg;
__mmask16 mskV;
zvU = _mm512_loadu_ps(pSrc1+src1Step*(h - 1) + i );
zvD = _mm512_loadu_ps(pSrc1+src1Step*(h + 1) + i );
zvL = _mm512_loadu_ps(pSrc1+src1Step*( h ) + (i-1));
zvR = _mm512_loadu_ps(pSrc1+src1Step*( h ) + (i+1));
zdV = _mm512_sub_ps(zvU, zvD);
zdH = _mm512_sub_ps(zvL, zvR);
zdV = _mm512_abs_ps(zdV);
zdH = _mm512_abs_ps(zdH);
mskV = _mm512_cmp_ps_mask(zdV, zdH, _CMP_LE_OS);
zavgV = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvU, zvD));
zavgH = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvL, zvR));
zavg = _mm512_mask_or_ps(zavgH, mskV, zavgV, zavgV);
_mm512_storeu_ps(pDst + i, zavg);
}
//remainder skipped
pDst = pDst + dstStep;
}
}
Таких if в реализуемом алгоритме может быть несколько, для них можно завести новые маски до тех пор пока код будет быстрее скалярного.
В действительности, компилятор icc вполне способен векторизовать код 4.1 Для этого достаточно всего лишь добавить ключевое слово restrict к указателям pSrc1 и pDst и ключ –Qrestrict.
void avg_ref( float* restrict pSrc1, int src1Step, float* restrict pDst, int dstStep, int width, int height)
Напомню, что модификатор restrict указывает компилятору, что доступ к объекту осуществляется только через этот указатель и таким образом вектора pSrc1 и pDst не пересекаются, что и делает возможной векторизацию.
Измерения на внутреннем симуляторе CPU с поддержкоий avx512 показывают, что производительность практически равна производительности нашего avx512 кода. Т.е компилятор тоже умеет эффективно использовать маски
Казалось бы на этом все. Но посмотрим, что будет если мы слегка модицифируем нашу функцию и внесем в нее зависимость между итерациями.
Лист 4.3
void avg_ref( float* restrict pSrc1, int src1Step,
float* restrict pDst, int dstStep, int width, int height)
{
int h, i;
for( h = 0; h < height; h++ ) {
int t = 1;
for(i=0; i < width; i++ ) {
float dv, dh;
float valU = pSrc1[src1Step*(h - 1) + i ];
float valD = pSrc1[src1Step*(h + 1) + i ];
float valL = pSrc1[src1Step*( h ) + (i-1)];
float valR = pSrc1[src1Step*( h ) + (i+1)];
dv = ABS(valU - valD);
dh = ABS(valL - valR);
if(dv<dh){
pDst[i] = (valU + valD) * 0.5f;
t = 1;
} else if (dv>dh){
pDst[i] = (valL + valR) * 0.5f;
t = 0;
} else if (t == 1) {
pDst[i] = (valU + valD) * 0.5f;
} else {
pDst[i] = (valL + valR) * 0.5f;
}
}
pDst = pDst + dstStep;
}
}
Функция также осуществляет интерполяцию по соседним пикселям, и если разница по вертикали и горизонтали одинакова, то используется то направление интерполяции, которое было в предыдущей итерации. На алгоритмах такого рода снижается эффект от механизма out of order, реализованных в современных cpu из-за того, что образуется длинная последовательность зависимых операций. Компилятор также теперь не может векторизовать цикл и производительность стала в 17 раз медленее. Т.е. как раз примерно на ширину в 16 float элементов в AVX512 регистре. Теперь попробуем как-то модифицировать и наш avx512 код, чтобы получить хоть какое то ускорение.
Введем в рассмотрение следующие бинарные маски-переменные
mskV(n) – для n-го элемента V разница минимальна
mskE(n) – для n-го элемента V и H разницы одинаковы
mskD(n) – для n-го элемента использована V интерполяция.
Теперь построим таблицу истинности, как формируется mskD(n) в зависимости от mskV(n),mskE(n) и предыдущей использованой маски – mskD(n-1)
Из таблицы следует, что
mskD(n) = mskV(n) | (mskE(n)&mskD(n-1)),
что в общем-то и так было очевидно. Итак наш avx512 код будет выглядеть следующим образом.
Лист 4.4
void avg_avx512( const float* pSrc1, int src1Step,
float* pDst, int dstStep, int width, int height)
{
int h, i;
for( h = 0; h < height; h++ ) {
__mmask16 mskD = 0xFFFF;
i = 0;
for(i=i; i < (width&(~15)); i+=16 ) {
__m512 zvU, zvD, zvL, zvR;
__m512 zdV, zdH;
__m512 zavgV, zavgH, zavg;
__mmask16 mskV, mskE;
zvU = _mm512_loadu_ps(pSrc1+src1Step*(h - 1) + i );
zvD = _mm512_loadu_ps(pSrc1+src1Step*(h + 1) + i );
zvL = _mm512_loadu_ps(pSrc1+src1Step*( h ) + (i-1));
zvR = _mm512_loadu_ps(pSrc1+src1Step*( h ) + (i+1));
zdV = _mm512_sub_ps(zvU, zvD);
zdH = _mm512_sub_ps(zvL, zvR);
zdV = _mm512_abs_ps(zdV);
zdH = _mm512_abs_ps(zdH);
mskV = _mm512_cmp_ps_mask(zdV, zdH, _CMP_LT_OS);
mskE = _mm512_cmp_ps_mask(zdV, zdH, _CMP_EQ_OS);
mskD = mskV | (mskE & (mskD >>15) & (1<<0)); // 0 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<1)); // 1 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<2)); // 2 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<3)); // 3 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<4)); // 4 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<5)); // 5 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<6)); // 6 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<7)); // 7 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<8)); // 8 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<9)); // 9 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<10)); // 10 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<11)); // 11 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<12)); // 12 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<13)); // 13 bit
mskD = mskD | (mskE & (mskD << 1) & (1<<14)); // 14 bit
mskD = mskD | (mskE & (mskD << 1) & (1 << 15)); // 15 bit
zavgV = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvU, zvD));
zavgH = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvL, zvR));
zavg = _mm512_mask_or_ps(zavgH, mskD, zavgV, zavgV);
_mm512_storeu_ps(pDst + i, zavg);
}
pDst = pDst + dstStep;
}
}
В нем последовательно перебираются все 16 бит маски. На размере 64x64 он работает в ~1.7X раз быстрее чем С-шный. Ну хотя бы что-то удалось получить. Следующая возможная оптимизация заключается в том, что можно предварительно просчитать все комбинации масок. На каждой итерации по 16 элементов у нас есть 16 бит mskV, 16 бит mskE, и 1 бит от предыдущей итерации. Итого 2^33 степени вариантов для mskD. Это много. А что если обрабатывать не по 16, а по 8 элементов за итерацию? Получаем 2^(8+8+1)=128кбайт таблицу. А это вполне вменяемый размер. Создаем функцию инициализации.
Лист 4.5
unsigned char table[2*256 * 256];
extern init_table_mask()
{
int mskV, mskE, mskD=0;
for (mskD = 0; mskD < 2; mskD++){
for (mskV = 0; mskV < 256; mskV++){
for (mskE = 0; mskE < 256; mskE++){
int msk;
msk = mskV | (mskE & (mskD ) & (1 << 0)); // 0 bit
msk = msk | (mskE & (msk << 1) & (1 << 1)); // 1 bit
msk = msk | (mskE & (msk << 1) & (1 << 2)); // 2 bit
msk = msk | (mskE & (msk << 1) & (1 << 3)); // 3 bit
msk = msk | (mskE & (msk << 1) & (1 << 4)); // 4 bit
msk = msk | (mskE & (msk << 1) & (1 << 5)); // 5 bit
msk = msk | (mskE & (msk << 1) & (1 << 6)); // 6 bit
msk = msk | (mskE & (msk << 1) & (1 << 7)); // 7 bit
table[256*256*mskD+256 * mskE + mskV] = (unsigned char)msk;
}
}
}
}
Переписываем код.
Лист 4.6
void avg_avx512( const float* pSrc1, int src1Step,
float* pDst, int dstStep, int width, int height)
{
int h, i;
for( h = 0; h < height; h++ ) {
__mmask16 mskD = 0xFFFF;
i = 0;
mskD = 0x00FF;
for(i=i; i < (width&(~7)); i+=8 ) {
__m512 Z = _mm512_setzero_ps();
__m512 zvU, zvD, zvL, zvR;
__m512 zdV, zdH;
__m512 zavgV, zavgH, zavg;
__mmask16 mskV, mskE;
zvU = _mm512_mask_loadu_ps(Z,0xFF, pSrc1+src1Step*(h - 1) + i );
zvD = _mm512_mask_loadu_ps(Z,0xFF, pSrc1+src1Step*(h + 1) + i );
zvL = _mm512_mask_loadu_ps(Z,0xFF, pSrc1+src1Step*( h ) + (i-1));
zvR = _mm512_mask_loadu_ps(Z,0xFF, pSrc1+src1Step*( h ) + (i+1));
zdV = _mm512_sub_ps(zvU, zvD);
zdH = _mm512_sub_ps(zvL, zvR);
zdV = _mm512_abs_ps(zdV);
zdH = _mm512_abs_ps(zdH);
mskV = _mm512_cmp_ps_mask(zdV, zdH, _CMP_LT_OS)&0xFF;
mskE = _mm512_cmp_ps_mask(zdV, zdH, _CMP_EQ_OS)&0xFF;
mskD = table[256 * 256 * (mskD >> 7) + 256 * mskE + mskV];
zavgV = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvU, zvD));
zavgH = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvL, zvR));
zavg = _mm512_mask_or_ps(zavgH, mskD, zavgV, zavgV);
_mm512_mask_storeu_ps(pDst + i, 0xFF, zavg);
}
pDst = pDst + dstStep;
}
}
Код стал работать в ~4.1X раз быстрее. Можно добававить обработку по 16 элементов, но к таблице придется обратиться дважды за итерацию.
Лист 4.7
void avg_avx512( const float* pSrc1, int src1Step,
float* pDst, int dstStep, int width, int height)
{
int h, i;
for( h = 0; h < height; h++ ) {
__mmask16 mskD = 0xFFFF;
i = 0;
for(i=i; i < (width&(~15)); i+=16 ) {
__m512 zvU, zvD, zvL, zvR;
__m512 zdV, zdH;
__m512 zavgV, zavgH, zavg;
__mmask16 mskV, mskE;
ushort mskD_0_7=0, mskD_8_15=0;
zvU = _mm512_loadu_ps(pSrc1+src1Step*(h - 1) + i );
zvD = _mm512_loadu_ps(pSrc1+src1Step*(h + 1) + i );
zvL = _mm512_loadu_ps(pSrc1+src1Step*( h ) + (i-1));
zvR = _mm512_loadu_ps(pSrc1+src1Step*( h ) + (i+1));
zdV = _mm512_sub_ps(zvU, zvD);
zdH = _mm512_sub_ps(zvL, zvR);
zdV = _mm512_abs_ps(zdV);
zdH = _mm512_abs_ps(zdH);
mskV = _mm512_cmp_ps_mask(zdV, zdH, _CMP_LT_OS);
mskE = _mm512_cmp_ps_mask(zdV, zdH, _CMP_EQ_OS);
mskD_0_7 = table[256 * 256 * (((ushort)mskD) >> 15) +
256 * (((ushort)mskE) & 0xFF) + (((ushort)mskV) & 0xFF)];
mskD_8_15 = table[256 * 256 * (((ushort)mskD_0_7) >> 7) +
256 * (((ushort)mskE)>> 8 ) + (((ushort)mskV) >>8 )];
mskD = (mskD_8_15 << 8) | mskD_0_7;
zavgV = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvU, zvD));
zavgH = _mm512_mul_ps(_mm512_set1_ps(0.5f), _mm512_add_ps(zvL, zvR));
zavg = _mm512_mask_or_ps(zavgH, mskD, zavgV, zavgV);
_mm512_storeu_ps(pDst + i, zavg);
}
pDst = pDst + dstStep;
}
}
Теперь ускорение составляет ~5.6X по сравнению с изначальным С кодом, что очень даже неплохо для алгоритма с обратной связью. Таким образом комбинация масочного регистра и предварительно вычисленной таблицы позволяет получить существенный прирост производительности. Код такого рода вовсе не является специально подобранным для статьи и встречается к примеру в алгоритмах обработки фотографий, при конвертации изображения из RAW формата. Правда там используются целочисленные значения, но такой табличный метод вполне можно применить и для них.
Итог
В этой статье показаны лишь некоторые способы применения масочных инструкций AVX 512. Вы можете применять их в своих приложениях или придумывать свои приемы. А можете воспользоваться библиотекой IPP, в которой уже присутствует код, оптимизированный специально для процессоров Intel с поддержкой avx512, важной частью которого являются инструкции с масочными регистрами.
Комментарии (14)

Salabar
29.09.2015 17:28Если этого всё-равно не умеет компилятор, почему бы просто не взять видеокарту того же самого Скайлейка и не прикрутить OpenCL? Получится просто по дефолту энергоэффективнее и, скорее всего, быстрее. И код не будет напоминать сатанинские письмена. Если этим всем приходится заниматься вручную, то сакральный смысл AVX2 от меня ускользает.

Ivan_83
Нихрена мы не можем!
Интел зажало AVX512 для десктопных процов скайлейк и даёт только в серверных.
https://en.wikipedia.org/wiki/AVX-512
http://www.3dnews.ru/910311
Видимо только так есть шанс показать в следующих процах хоть какие то улучшения.
a_bakshaev
Ну что тут сказать. Да, в десктопных вариантах планируются лишь микроархитектурные изменения. Но вот когда выйдет серверный вариант с поддержкой AVX-512, то надо чтобы и ПО использовало эти инструкции. Я надеюсь эта статья и поможет разработать такой avx-512 код, причем с масками, это действительно очень эффективный инструмент.
ion2
Чтобы ПО использовало эти инструкции, нужны разработчики с опытом их применения и отладки кода на реальном железе, а не в эмуляторе.
a_bakshaev
Это верно. Но хотелось бы добавить, что количество инструкций на сегодняшний день и в AVX2 уже довольно велико, а когда будет AVX512 оно будет еще больше. И уже вообще сложно понять, где можно эффективно применить ту или иную инструкцию. Вот к примеру, понятно что раз в avx512 регистры в два раза шире то и данных за одну итерацию можно обработать в два раза больше. А вот маски можно применять в другом аспекте, как и рассказано в статье.
grossws
А разработчики должны отлаживать и тестировать всё исключительно на сервере?
a_bakshaev
Нет не обязательно. Для отладки AVX512 кода существует инструмент sde. Он позволяет выполнять код, содержащий AVX 512 инструкции.
grossws
Правильно ли я понимаю, что sde бесплатно для использования в коммерческих целях?
Даёт ли он равномерное замедление для поддерживаемых и не поддерживаемых на хосте операций, чтобы можно было оценить изменение производительности при использовании, например, avx512 против avx2?
a_bakshaev
я боюсь насчет использования в коммерческих целях вопрос вне моей компетенции, но
sde использует другой инструмент — pintool
…
Intel SDE is built upon the Pin dynamic binary instrumentation system and the XED encoder decoder.
…
Distribution
Pin is proprietary software developed and supported by Intel and is supplied free of charge for non-commercial use.
Мысль кстати интересная измерять замедление вместо ускорения. Но тем не менее хотя с помощью sde можно исполнить avx512 код, но вот измерить производительность нельзя, поскольку в sde не заложено описание микроархитектуры.
grossws
Т. е. можно только гадать, будет ли ускорение на avx512 относительно avx2, а реальные оценки строить только по новым xeon'ам на skylake. А значит, значительной доле разработчиков фактически невозможно оценить прирост производительности от avx512, и оно пока нафиг не нужно.
tsafin
Ну почему же гадать? Процессоростроение — очень строгая дисциплина, с кучей полезных инструментов, даже когда кристалл появится лет через 7, и у Интела всегда есть пара тузов в загашничке, чтобы померить изменения в производителности для измененного или планируемого new instructions set.
(И sde здесь очень важный инструмент, т.к. им занимается ровно тот же человек, участвующий во всех совещаниях по расширению instruction set, и пишуший декодер XED, используемый во всех ну или в большинстве интеловских симуляторах разного уровня подробности)
В данном случае flow предполагается таким: вы переделываете код с применением расширений (расширяя свой компилятор или через assembler), убеждаетесь на sde что все работает, запускаете там же его с PIN-LIT, записываете измененные трассы (LIT) исполнения, и уже эти трассы изучаете (не вы, скорее всего, а специально обученный performance engineer или microarchitecture engineer) в потактовом симуляторе типа keiko.
Если вы большой и важный клиент, типа Microsoft, то такое низкоуровневое взаимодействие давно налажено, и все инструменты у нужных людей уже есть, но если же пока нет настолько близкого контакта и у вас какой high-profile проект, то можно через SSG DRD запросить помощь и выйти на нижегородскую команду performance инженеров. Они помогут.
P.S.
Я уже пару лет не в Intel, т.ч. детали могли слегка измениться
grossws
К сожалению, такой путь выглядит слишком сложным для физика или маленькой компании. Так что, видимо, я по старинке: появились соответствующие железки в массовом доступе — сравниваем производительность, не появились — ждём дальше =)