

Zip появился 32 года назад. Можно подумать, что настолько зрелый формат должен быть отлично задокументирован. К сожалению, нет. Что же конкретно в нем не так, и каким образом его можно было бы оптимизировать? Подробно рассмотрим эти вопросы, опираясь на исходную документацию.
Вообще, есть у меня ощущение, что это касается многих форматов файлов. Они не прорабатываются, а скорее создаются разработчиками на ходу. Если в итоге такой формат становится популярен, то у пользователей возникает желание считывать и/или записывать соответствующие файлы. При этом им приходится либо делать реверс-инжиниринг, либо запрашивать спецификации. Даже если разработчик и пишет спецификацию, он зачастую не может вспомнить все допущения, которые делает его программа. В итоге они не записываются, и спецификация получается неполной. К таким форматам и относится Zip.
Соответствующая документация находится в
APPNOTE.TXT, который доступен здесь.Если коротко, то zip-файл состоит из записей, каждая запись начинается с некоторого 4-байтового маркера, который обычно имеет следующую структуру:
0x50, 0x4B, ??, ??Здесь
0x50 и 0x4B представляют буквы PK, означающие “Phil Katz”, собственно, имя создателя этого формата. Два байта ?? определяют тип записи. Вот примеры:0x50 0x4b 0x03 0x04 // local file record
0x50 0x4b 0x01 0x02 // central directory file record
0x50 0x4b 0x05 0x06 // end of central directory recordЗаписи не следуют какому бы то ни было стандартному шаблону. Чтобы считать или даже пропустить запись, необходимо знать ее формат. Я имею ввиду, что есть несколько других форматов файлов, которые следуют определенному соглашению, например, когда каждый
id записи сопровождается ее длиной. Поэтому, если вы видите id и не понимаете его, то просто считываете длину, пропускаете такое же количество байтов* и оказываетесь у следующего id. К примерам подобной схемы относится большинство форматов видео-контейнеров, jpg, tiff, файлы Photoshop, wav, да и многие другие.* некоторые форматы требуют округления длины до ближайшего числа, кратного 4 или 16. Zip же этого не делает. Если вы видите id и не знаете, как этот тип содержимого записи структурирован, то понять, сколько байтов нужно пропустить, вам не удастся.
APPNOTE.TXT сообщает нам следующее:4.1.9 ZIP-архивы МОГУТ быть потоковыми, разделенными на сегменты (на стационарных или съемных носителях) либо «самораспаковывающимися» (SFX). SFX-архивы ДОЛЖНЫ нести в себе код извлечения для целевой платформы.
4.3.1 ZIP-архив ДОЛЖЕН содержатьend of central directory record. ZIP-архив, содержащий толькоend of central directory record, рассматривается как пустой. Файлы внутри ZIP-архива можно заменять, добавлять и удалять. ZIP-архив ДОЛЖЕН содержать только однуend of central directory record. Другие записи, определенные в этой спецификации, МОЖНО использовать при необходимости для поддержания требований хранилища к отдельным ZIP-архивам.
4.3.2 Каждому помещенному в ZIP-архив файлу ДОЛЖНА предшествовать записьlocal file header. Каждая записьlocal file headerДОЛЖНА сопровождаться соответствующейcentral directory record, расположенной внутри раздела центрального каталога ZIP-архива.
4.3.3 Файлы внутри ZIP-архива можно сохранять в произвольном порядке. ZIP-архив МОЖЕТ включать несколько томов или быть разделен на сегменты определенного пользователем размера. Все значения ДОЛЖНЫ храниться в порядке байтов от младшего к старшему, если для конкретного элемента данных этой документацией не установлено иное.
4.3.6 Общая структура формата .ZIP:[local file header 1] [encryption header 1] [file data 1] [data descriptor 1] . . . [local file header n] [encryption header n] [file data n] [data descriptor n] [archive decryption header] [archive extra data record] [central directory header 1] . . . [central directory header n] [zip64 end of central directory record] [zip64 end of central directory locator] [end of central directory record]
4.3.7 Local file header:local file header signature 4 bytes (0x04034b50) version needed to extract 2 bytes general purpose bit flag 2 bytes compression method 2 bytes last mod file time 2 bytes last mod file date 2 bytes crc-32 4 bytes compressed size 4 bytes uncompressed size 4 bytes file name length 2 bytes extra field length 2 bytes file name (variable size) extra field (variable size)
4.3.8 File data
Сразу после local header файла ДОЛЖНЫ идти сжатые или сохраненные данные этого файла. Если файл зашифрован, заголовок шифрования ДОЛЖЕН идти междуlocal file headerиfile data. Последовательность[local file header][encryption header] [file data][data descriptor]повторяется для каждого файла в ZIP-архиве.
Файлы нулевой длины и другие типы файлов без содержимого НЕ ДОЛЖНЫ включатьfile data.
4.3.12 Структура центрального каталога:[central directory header 1] . . . [central directory header n] [digital signature]
File header:central file header signature 4 bytes (0x02014b50) version made by 2 bytes version needed to extract 2 bytes general purpose bit flag 2 bytes compression method 2 bytes last mod file time 2 bytes last mod file date 2 bytes crc-32 4 bytes compressed size 4 bytes uncompressed size 4 bytes file name length 2 bytes extra field length 2 bytes file comment length 2 bytes disk number start 2 bytes internal file attributes 2 bytes external file attributes 4 bytes relative offset of local header 4 bytes file name (variable size) extra field (variable size) file comment (variable size)
4.3.16 End of central directory record:end of central dir signature 4 bytes (0x06054b50) number of this disk 2 bytes number of the disk with the start of the central directory 2 bytes total number of entries in the central directory on this disk 2 bytes total number of entries in the central directory 2 bytes size of the central directory 4 bytes offset of start of central directory with respect to the starting disk number 4 bytes .ZIP file comment length 2 bytes .ZIP file comment (variable size)
Есть и другие детали, относящиеся к шифрованию, более крупным файлам, дополнительным данным, но для целей текущей статьи этого нам будет достаточно. Потребуется лишь уточнить процесс создания SFX-архивов.
Для этого можно вернуться к
ZIP2EXE.exe, который сопровождал PKZIP в 1989 году, и посмотреть, что он делает. Однако проще будет заглянуть в Info-ZIP:Как создать DOS (или другой не-нативный) SFX-архив под Unix?Ну а теперь с учетом всего этого мы пройдемся по ряду проблем.
Суть этой процедуры объяснена на странице мануала UnZipSFX. Сперва понадобится подходящий бинарный дистрибутив UnZip для целевой платформы (DOS, Windows, OS/2 и т.д.). В следующем примере мы предположим, что работаем с DOS. Затем нужно извлечь из дистрибутива модуль UnZipSFX и добавить его, как если бы он был нативным модулем Unix:> unzip unz552x3.exe unzipsfx.exe // извлечение SFX-модуля для DOS > cat unzipsfx.exe yourzip.zip > yourDOSzip.exe // создание SFX-архива > zip -A yourDOSzip.exe // корректировка внутренних смещений >
Вот и все. При этом вы по-прежнему можете тестировать, обновлять и удалять записи архива. Получился полностью функциональный файл zip.
Как считывать zip-файл?
В спецификации по этому поводу ничего не сказано.
Есть два очевидных пути:
- Просканировать его с начала и при встрече
idзаписи выполнять нужные действия. - Просканировать его с конца. Найти
end of central directory recordи использовать ее для считывания всего центрального каталога, рассматривая только те элементы, на которые он ссылается.
По принципу обратного сканирования работает оригинальный PKUNZIP. В его случае это означает, что при запросе некоего подмножества файлов он может перескочить сразу к ним, не прибегая к сканированию всего архива. Это оказывалось особенно актуально, если архив был разбит на несколько флоппи-дискет.
Однако пункт 4.1.9 утверждает, что zip-архивы можно считывать потоком. Как такое возможно? Что, если есть некая
local file record, на которую центральный каталог не ссылается? Валидна ли она? Неизвестно.В 4.3.1 сказано:
Файлы внутри ZIP-архива МОЖНО заменять, добавлять и удалять.Как вам? Это предполагает, что центральный каталог может ссылаться не на все файлы архива, иначе это утверждение о возможности добавления, замены и удаления файлов не имело бы смысла.
Если у меня есть
file1.zip, содержащий файлы A, B, C, и я генерирую file2.zip, который содержит только A и B, то получается два независимых zip-файла. Нет никакого смысла писать в спецификации о возможности добавления, замены и удаления файлов, если только эта информация каким-то образом не влияет на структуру zip-файла. Другими словами, если перед нами такая структура:
[local file A]
[local file B]
[local file C]
[central directory file A]
[central directory file C]
[end of central directory]Тогда очевидно, что
B удален, поскольку центральный каталог на него не ссылается. С другой стороны, если [local file B] отсутствует, тогда мы имеем просто независимый zip-архив, т.е. независимый от другого zip-архива, в котором B содержится. Нет необходимости даже упоминать об этой ситуации в спецификации.Аналогичным образом, если перед нами:
[local file A (old)]
[local file B]
[local file C]
[local file A (new)]
[central directory file A(new)]
[central directory file B]
[central directory file C]
[end of central directory]Тогда, согласно центральному каталогу,
A (old) был заменен на A (new). С другой стороны, если [local file A (old)] отсутствует, то мы имеем просто еще один независимый zip-архив.Это может показаться бессмыслицей, но нужно помнить, что PKZIP происходит из эпохи дискет. Операции считывания содержимого всего zip-архива и записи нового zip-архива могут оказаться чрезвычайно медленными. В обоих случаях возможность удаления файла простым обновлением центрального каталога или добавления файла считыванием существующего центрального каталога с присоединением новых данных и последующей записью обновленного центрального каталога окажется весьма желаемой.
Это было особенно актуально в случаях, когда zip-архив занимал несколько дискет. В 1989 году подобная ситуация была не редкостью. Оказывалось гораздо удобнее обновлять
README.TXT в zip-архиве без необходимости перезаписывать несколько дискет. Представители PKWARE в обсуждении сказали следующее:
Изначально этот формат подразумевал прямую запись от начала к концу, поэтомуКонечно же, «добавление» отличается от «удаления» и «замены». Наличие или отсутствие локальных файлов, на которые не ссылается центральный каталог, спецификацией не определяется. Это лишь подразумевается следующим упоминанием:central directoryиend of central directory recordмогли записываться после того, как будут узнаны и записаны все включаемые в ZIP-архив файлы. При добавлении файлов изменения можно применять без перезаписывания всего файла. Именно так была реализована запись файлов.ZIPв оригинальной программе PKZIP. При считывании она сначала читаетend of central directory recordдля обнаруженияcentral directory, а затем ищет все файлы, к которым нужно обратиться.
Файлы внутри ZIP-архива МОЖНО заменять, добавлять и удалять.Если для центрального каталога допустимо не ссылаться на все локальные файлы, тогда считывание архива путем его прямого сканирования может провалиться. Если дополнительно не постараться, то вы либо получите файлы, которые не должны существовать, либо ошибки из-за попытки перезаписать существующие файлы.
Но это противоречит пункту 4.1.9, в котором говорится, что zip-архивы могут считываться в потоковом режиме. Если архивы допускают потоковое считывание, тогда оба вышеприведенных примера провалятся, потому что сначала в первом случае мы увидим файл
B, а во втором файл A (old), и лишь потом то, что центральный каталог на них не ссылается. Если же нам придется дожидаться чтения центрального каталога прежде, чем верно использовать любые из его записей, тогда функционально мы просто не сможем считывать zip-файл потоком.Может ли SFX-компонент содержать какие-либо ID?
Следуя вышеприведенной инструкции по созданию SFX-компонента, мы просто подставляем исполняемый код в начало этого файла, а затем корректируем смещения в центральном каталоге.
Предположим, что у SFX-компонента следующий код:
switch (id) {
case 0x06054b50:
read_end_of_central_directory();
break;
case 0x04034b50:
read_local_file_record();
break;
case 0x02014b50:
read_center_file_record();
break;
...
}Судя по этому коду, в SFX-компоненте, представляющем начало zip-файла, в двоичном виде появятся значения
0x06054b50, 0x04034b50, 0x02014b50. Если считывать zip-архив прямым сканированием, то сканер может увидеть эти id и ошибочно принять их за записи zip.Вот как можно представить SFX-компонент с находящимся в нем zip-файлом:
// данные для zip-файла, содержащие:
// LICENSE.txt
// README.txt
// player.exe
const unsigned char[] runtimeAndLicenseData = {
0x50, 0x4b, 0x03, 0x04, ??, ??, ...
};
int main() {
extractZipFromFile(getPathToSelf());
extractZipFromMemory(runtimeAndLicenseData, sizeof(runtimeAndLicenseData));
}Теперь внутри SFX-компонента находится zip-файл. Любой ридер, который считывает с начала, увидит этот внутренний zip-файл и даст сбой. Валиден ли данный zip-файл? Спецификация об этом молчит.
Я проверил. Оригинальный
PKUNZIP.exe в DOS, Windows Explorer, MacOS Finder, Info-ZIP (UNZIP, включенный в MacOS и Linux), все четко считывают с конца и видят эти файлы уже после SFX-компонента. А вот Keka и 7z видят zip, вложенный в него. Считать ли это сбоем или плохим zip-файлом?
APPNOTE.TXT ответа не дает. Я считаю, что здесь должна быть ясность, и что это является одним из незаявленных допущений. PKUNZIP сканирует с конца, поэтому такая схема работает, но как именно она работает, в документации не сказано. Проблема того, что данные в SFX-компоненте могут оказаться похожи на zip-файл, не освещается. Аналогичным образом, потоковое считывание скорее всего провалится, если еще не провалилась из-за недочетов, описанных ранее.Вы можете решить, что это не такая уж проблема, но в сетевом архиве находятся сотни тысяч SFX zip-ов из 1990-х. Попытка считать такие файлы прямым сканером вполне может провалиться.
Может ли zip-комментарий содержать идентификаторы zip?
Если еще раз взглянуть на пункт 4.3.16, то мы увидим, что в конце zip-архива идет комментарий переменной длины. Поэтому при обратном сканировании мы, по сути, выполняем чтение с конца файла в поиске
0x50 0x4B 0x05 0x06. Но что, если эта последовательность байтов находится в комментарии?Уверен, что Фил Кац никогда об этом не задумывался. Он просто предположил, что люди будут помещать туда эквивалент
README.txt. В таком случае там будут находиться только значения от 0x20 до 0x7F, возможно, с 0x0D (возврат каретки), 0x0A (перевод строки), 0x09 (табуляция) и 0x06 (звонок).К сожалению, все эти значения в
ID являются действительными кодами ASCII, даже utf-8. В начале статьи мы уже прошлись по 0x50 = P и 0x4B = K. Что же касается 0x06 и 0x05, то первый в ASCII означает «звонок» (издает звук или вызывает мигание экрана), а второй «Запрос».APPNOTE.TXT наверняка должен явно сообщать, если это невалидно. Пункт 4.3.1 косвенно указывает:ZIP-архив ДОЛЖЕН содержать только одну end of central directory record.Но что именно это значит? Значит ли это, что байты 0x50 0x4B 0x05 0x06 не могут появиться в комментарии или коде SFX? Значит ли это, что когда вы в первый раз видите их при обратном сканировании, то второе совпадение уже не ищете?Если вы сканируете с начала и не сталкиваетесь ни с одной из перечисленных ранее проблем, то прямой сканер успешно это считает. С другой стороны, сам PKUNZIP бы не справился.
Что, если смещение до центрального каталога равно 1,347,093,766?
Это смещение
0x504b0506, значит оно окажется заголовком end of central directory. Я думаю, что во времена создания формата zip файлы размером 1.3 Гб даже не предполагались, и, действительно, расширения требовались для обработки файлов больше 4 Гб. Но это лишь еще раз указывает на недостаточную продуманность структуры формата.А что значит продуманная структура?
Этот вопрос определенно требует обсуждения, но, если рассмотреть возможность повторить разработку, то кое-что можно определить без сомнений.
1. Лучше, если записи будут иметь фиксированный формат, например
id, сопровождаемый размером, чтобы можно было пропускать запись в случае непонимания.2. Лучше, если последняя запись в конце файла будет просто записью
offset-to-end-of-central-directory, как здесь:0x504b0609 (id: some id is not in use)
0x04000000 (size of data of record)
0x???????? (relative offset to end-of-central-directory)Это исключит двусмысленность при обратном считывании.
2.a. Считать последние 12 байтов.
2.b. Проверить, являются ли первые 8 байтов следующими:
0x50 0x4b 0x06 0x09 0x04 0x00 0x00 0x00. Если нет, сбой.2.c. Считать смещение и перейти к
end-of-central-directory.Или, напротив, поместить комментарий в собственную запись и расположить перед
central directory, указав смещение до него в end-of-central-directory-record. Тогда, по крайней мере, исчезнет проблема сканирования комментария.
3. Внести ясность в том, какие данные могут появиться в компоненте SFX.
Если вам нужна поддержка прямого считывания, то будет логичным утвердить, что SFX-компонент не может содержать какие-либо записи.
Но обеспечить это сложно, разве что специально написать валидатор. Если вы будете просто проверять, исходя из того, может ли ваше приложение считывать zip-файл, то на сегодня для PKZIP, PKUNZIP, info-ZIP, Windows Explorer и MacOS содержимое SFX-компонента безразлично, поэтому для валидации они не годятся. Нужно явно указать в спецификации на необходимость применения именно обратного сканирования, либо же написать валидатор, который отвергает zip-файлы, не допускающие прямого сканирования, и также в спецификации указать причину.
4. Внести ясность в том, может ли
central directory расходиться с записями локальных файлов.5. Внести ясность в том, могут ли между записями появиться случайные данные.
Обратный сканер не волнует, что находится между записями. Его волнует лишь возможность найти центральный каталог, и считывает он только то, на что центральный каталог указывает. Это означает, что между записями могут быть любые случайные данные (по крайней мере между некоторыми).
Необходима ясность в том, нормально это или нет. Не нужно полагаться на скрытые схемы.
Что же делать? Как все исправить?
На мой взгляд все эти проблемы относятся к деталям реализации, которые не попали в
APPNOTE.TXT. При этом на самом деле APPNOTE.TXT хочет сказать, что «валидный zip-файл – это тот, с которым может работать PKZIP, и который может правильно распаковать UNZIP”. Но вместо этого он определяет все таким образом, что в результате некоторые реализации могут создавать файлы, которые не могут прочесть другие реализации.Конечно же, спустя всю 32-летнюю историю zip-файлов, мы уже этот формат не исправим. Но все же в PKWARE могли бы внести ясность по поводу рассмотренных пограничных случаев. Лично я бы добавил соответствующие разделы в
APPNOTE.TXT.4.3.1 ZIP-файл ДОЛЖЕН содержатьЭто один способ. Я верю, что в таком случае удалось бы считать сотни миллионов существующих zip-файлов.end of central directory record. ZIP-файл, содержащий толькоend of central directory recordсчитается пустым. Файлы в ZIP-архиве МОЖНО обновлять, добавлять и удалять. ZIP-файл ДОЛЖЕН содержать толькоодну end of central directory record. Другие записи, определенные в этой спецификации, МОЖНО использовать по необходимости для поддержания требований хранилища к отдельным ZIP-файлам.End of central directory recordдолжна находиться в конце файла, и последовательность байтов0x50 0x4B 0x05 0x06не должна встречаться в комментарии.Сentral directoryруководит содержимым zip-файла, и считать из него можно только те данные, на которые он указывает. Во-первых, причина в том, что содержимое SFX-компонента файла не определено и может содержать zip-записи, которые фактически к zip-файлу не относятся. Во-вторых, возможность добавлять, обновлять или удалять содержимое zip-файла опирается на доступную лишьcentral directoryинформацию о том, какие локальные файлы валидны.
С другой стороны, если в PKWARE заявляют, что файлов, имеющих подобные проблемы, не существует, тогда также сработает следующий вариант:
4.3.1 ZIP-архив ДОЛЖЕН содержатьНадеюсь, что файлend of central directory record. ZIP-архив, содержащий толькоend of central directory record, считается пустым. Файлы в ZIP-архиве МОЖНО заменять, добавлять и удалять. Другие записи, определенные в этой спецификации, МОЖНО использовать по необходимости для поддержания требований хранилища к отдельным ZIP-архивам.End of central directory recordдолжна находиться в конце файла, и последовательность байтов0x50 0x4B 0x05 0x06не должна встречаться в комментарии.
Не может быть таких[local file records], которые бы не содержались вcentral directory. Эта гарантия необходима, чтобы считывание файла в прямом и обратном направлении давало одинаковые результаты. Любой файл, не следующий этому правилу, является недействительным zip-архивом.
SFX-архив не должен содержать любую из последовательностейidзаписей, перечисленных в этом документе, так как они могут быть неверно поняты zip-сканерами прямого чтения. Любой файл, не следующий этому правилу, является недействительным zip-архивом.
APPNOTE.TXT все же обновят, чтобы различные zip-ридеры и zip-генераторы трактовали валидность файлов одинаково.К сожалению, все говорит в пользу того, что PKWARE не хотят вносить в этом вопросе ясность. Их позиция состоит в том, что zip является неоднозначным форматом. Если вы хотите пользоваться прямым сканированием, то просто не делайте этого для файлов, которые его не поддерживают. Они по-прежнему остаются валидными zip-файлами, и то, что их нельзя таким образом считать, значения не имеет. Вы сами выбираете отказ от их поддержки.
Думаю, эту точку зрения можно понять. Ведь лишь несколько библиотек поддерживают все возможности zip, а может и ни одна. Тем не менее, было бы здорово знать, намеренно ли вы не обрабатываете какой-то файл, или же просто неверно его считываете, и по воле случая иногда получается.
Желание все это осветить возникло у меня в процессе написания JS-библиотеки для распаковки. Их уже существует очень много, но меня интересовали особые возможности, которых в найденных мной вариантах не было. В частности, мне нужно было, чтобы библиотека позволяла считывать из большого архива один файл максимально быстро. Это означало использование обратного сканирования, поиск смещения до нужного файла и его разархивирование. Надеюсь, что и другим моя библиотека пригодится.
P.S.
Вам может быть весьма интересна эта история ZIP (англ.):

Комментарии (80)


balamutang
29.07.2021 10:30+2CD стоял у приятеля на 386SX в начале 90х, а DVD формат массово появился лет через десять, "из-за чего CD и пользовался популярностью" :)

Bellerogrim
29.07.2021 10:58-1Либо «начало 90х» — это 1996 год, и у вашего приятеля была некрота страшная, либо что-то не сходится. В памяти остались первые CDROM чуть ли не за тысячу, сейчас правда только нашёл PC Magazine от мая 1993, там CDROM предлагают за $225 в комплект к DX2-66. Вообще cd на трёшке — странная такая история.
balamutang
29.07.2021 11:30Почему странная, я помню что этот CD еще в саундбластер подключался шлейфом, в не в материнку, собственно он его потом вместе с саундбластером и продал. В 94 у него уже пень был, а в 98 пень уже был и у меня, за целых 200$ купленный

hw_store
31.07.2021 18:21Я купил ранней весной 1995 года в "Мультимедиа Клубе" CD-ROM Matsushita (с интерфейсом Panasonic) за 285 долл. В соседнем санрайзе такой же стоил 300. Привод был двухскоростной. Подключал его к Sound Galaxy NX2, купленной там же (не помню, тогда же или двумя неделями раньше). Это было время, когда все эти штуки продавались в огромных красивых коробках
balamutang
29.07.2021 11:40Ща почитал эту статью на википедии и вспомнил что у него был как раз этот упомянутый "Multimedia Upgrade Kit"

K0styan
29.07.2021 12:00+2CD-ROM были сравнительно доступны ещё в условном 1994, даже в России. И в тот же Myst или Command&Conquer можно было ну хотя бы на 486 сносно играть.
Вот пишущие CD-приводы - те да, были дорогими до начала 2000-х.
Bellerogrim
29.07.2021 12:221994 это не ещё, а уже. И это не начало, а скорее середина 90х, как по мне.

quwy
29.07.2021 15:25Так написали же специально, что "даже в России ", когда зарплата 50 долларов/мес. считалась очень высокой.
Западный мир, где создавались компьютерные технологии, жил в немного других финансовых измерениях. И поэтому CD-привод и звуковая карта на 386 машине были частью базового комплекта, а дискеты не HD-плотности давно валялись по кладовкам.

mSnus
28.07.2021 21:30Мало какие форматы сравнимы по удобству. Такое ощущение, что разработчики предусмотрели вообще всё!

APh
29.07.2021 04:54+8{Не лично Вам. Комментарий подходящий... ))}
Формат TIFF (контейнер для растровых, сеточных/табличных данных) довольно неплохо документирован. Также есть стандартный путь расширения. Так появился GeoTIFF. Причём, в ячейке растра (сетки, таблицы) можно хранить, как целые, так и вещественные данные (для полей значений, например, превышения над уровнем референц-эллипсоида, температуры, концентрации какого-то минерала в почве и пр.).
При этом, из-за его заложенной расширяемости существует правило: не знаем что за данные под конкретным тегом скрыты — не читаем.
Поэтому, даже файл с кучей метаданных не все программы могут полностью прочитать. Зато, хотя бы показать должен почти любой визуализатор.
И тут... больше вопросов не к создателям формата, а к программистам. Так, в TIFF можно записать изображение, сжатое алгоритмом JPEG, но не все программисты делают так, что это изображение можно прочитать, т. к. ограничиваются интерпретацией только базовых примитивных схем кодирования растров/сеток.
А потому у многих недалёких программистов есть предубеждение ,что формат TIFF плохой, ограниченный и устаревший. Это, как сказать, что авоська или холщовая сумка устарела и твердотельные диски из магазина можно носить домой только в пластиковом нанопакете. )) Хотя их можно перенести и в авоське. ))
А если вспомнить тайлы и пирамидальные слои в TIFF, то можно сказать, что это ОТЛИЧНЫЙ формат, который позволяет очень быстро оперировать с растрами/сетками в графических программах при визуализации.
Отсюда, все программисты делятся на тех, кто предусматривает дальнейшее использование изделия, и на тех, у кого нет времени, нет желания что-то доделывать, нет квалификации, чтобы предусмотреть дальнейшие пути развития.
А так... Делить программистов на создателей формата и неких загадочных пользователей — контрпродуктивно. Все они программисты. ))mSnus
29.07.2021 10:39+3Со всем согласен, кроме последнего абзаца) пользователи -- это вполне реальные пользователи, в случае с TIFF -- дизайнеры, полиграфисты.
Почему они? Формат получился тяжеловесный, с кучей параметров и сложной реализацией и интерпретацией, которую далеко не все осилили, поэтому пользователям пришлось годами договариваться между собой "формат используем, но в такой-то версии, без сжатия, без слоёв".
При этом не было общепринятой договоренности про какой-то fallback, поэтому в броузерах его поддерживать особо и не пытались -- слишком сложно.
Зато для обмена между дизайнерскими системами, в CMYK, без сжатия -- самое то.
ALF_Zetas
29.07.2021 19:56+1авторские права на формат tiff давно принадлежат Adobe, у которой нет ни малейшего желания продвигать его в ущерб PSD

NikRag
29.07.2021 14:29+2Возможно, это неплохой пример нарушения причинно-следственной связи.
Удобство развилось исходя из доступности именно такого формата, а не какого-то другого.Примерно как "у кошки дырочки на шкурке там же где глаза!"
https://bash.im/quote/397561

borovinskiy
28.07.2021 21:36+20А как же проблемы с кодировкой (с её отсутствием)?
Пожатые на Linux файлы с кириллицей в UTF-8 превратятся после распаковки на Windows с CP1251 в кракозябры. Ну и наоборот.
"В какой локали запаковывали - в такой и распаковывайте" - очень удобно!
DistortNeo
28.07.2021 22:18+1Сейчас уже и Windows c UTF-8 по умолчанию может оказаться.
borovinskiy
28.07.2021 22:38+4В историческом контексте оно может и хорошо, что когда-нибудь все файлы будут в UTF-8 и проблема уйдет для новых архивов, но в конкретный момент времени Windows-админы, не знавшие проблем пока ZIP-архивы только между Windows с CP1251 пересылались, хлебанут проблем с архивами -)
Казалось бы, такой известный формат, так все его повсюду используют, что может пойти не так?)))
justhabrauser
28.07.2021 23:18+14А как же проблемы с кодировкой (с её отсутствием)?
Нет кодировки — нет проблем.
А то придумают тоже — кодировки какие-то, локали еще…
PS. напомнило "если в телефоне фирмы не указан код страны, то фирма — американская; если и код города — то московская". Кодировка — обычная ™

symbix
29.07.2021 18:31+1В том самом appnote (в относительно новых ревизиях) четко специфицирован юникод-флаг в 11м бите. Если выставлен - значит, utf8, если нет - то cp437. Известные мне линуксовые архиваторы юникод-флаг корректно выставляют. В общем, это уже давно проблема не формата, а конкретных реализаций.

usrsse2
28.07.2021 22:35+2Перезаписывать весь архив долго не только на дискетах. Когда у меня в цикле добавлялись файлы в 5-гигабайтный архив и он каждый раз переписывался полностью, это было очень долго.


grishkaa
29.07.2021 02:16+12Продолжая тему безумно популярных, но плохих форматов файлов: mp3. Никакого заголовка самого файла не предусмотрено вообще. Сжатые данные разбиты на фреймы, каждый фрейм начинается с сигнатуры FFFx. Чтобы узнать длительность файла, надо прочитать несколько первых байт первого фрейма и по нескольким таблицам рассчитать его длительность во времени и длину в байтах. Затем взять размер файла, поделить его на длину фрейма и умножить на его длительность. Перемотка работает примерно так же, надо рассчитать смещение, округлить до длины фрейма и начать читать оттуда. Это если битрейт постоянный. А если переменный, там наркомании ещё больше: два вида заголовков с лукап-таблицами для перемотки вместо первого фрейма, при перемотке надо искать заголовок фрейма, при этом FFFx может быть и в середине фрейма, и тогда это будет уже не заголовок, тут уж как повезёт…
И да, ещё есть ID3-тэги для метаданных. 1й версии в конце файла, с фиксированным набором полей фиксированной длины, 2й версии в начале, хитрого формата и с кучей возможностей. Между фреймами может быть мусор. В конце и в начале файла может быть мусор. Я почти уверен, что можно сделать rarjpegmp3, причём засунув одну половину mp3 в exif в jpeg, а другую в архив без сжатия.
В общем, да, mp3 — не лучший формат файла.
vorphalack
29.07.2021 04:37+1а еще там почти у каждого тега свой формат и декодер, и поддержку не-latin1 тегов добавили чуть ли не в 2.4…

HardWrMan
29.07.2021 09:15+6Я почти уверен, что можно сделать rarjpegmp3, причём засунув одну половину mp3 в exif в jpeg, а другую в архив без сжатия.
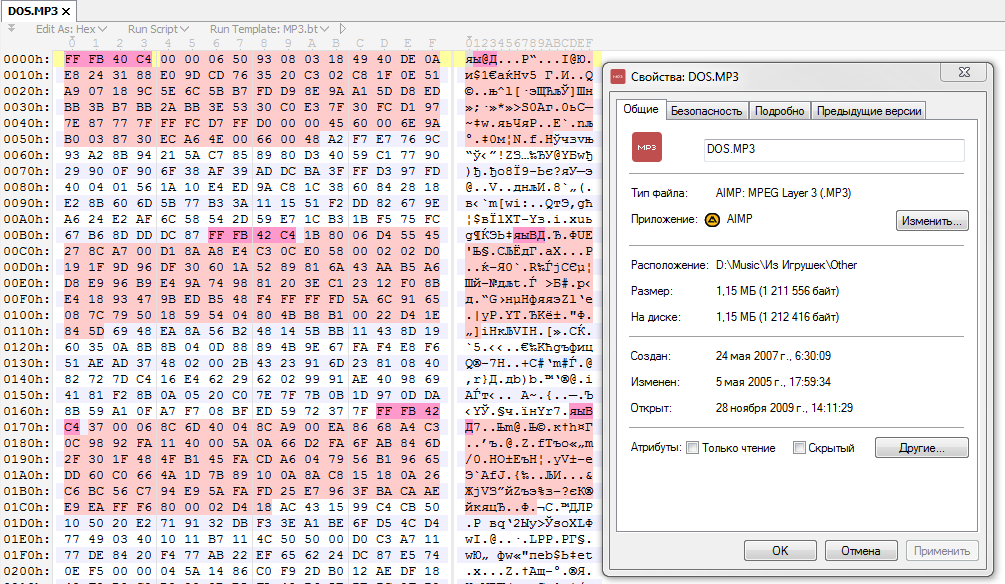
В бытность FIDO ходил один DOS.MP3 (та самая известная песенка). Но на самом деле это был архив с МР3 без сжатия. Как итог - плееры его играли без проблем, т.к. о формате судили по расширению файла, а оболочки "проваливались" в него, так как анализировали содержимое файла, и показывали DOS.MP3 файл внутри DOS.MP3 файла, снося крышу новичкам и неискушённым.

vesper-bot
29.07.2021 12:42Хм, у меня где-то сохранился файл с таким именем… надо будет проверить, а ну как в нем есть-таки zip-заголовок.

aamonster
29.07.2021 13:54По сравнению с файлом, который было невозможно прочитать с CD, это всё цветочки.

naishin
29.07.2021 18:38А ягодки - это файл с именем con
aamonster
29.07.2021 19:21По сравнению с примером, который я привёл выше (когда читаемость файла зависит от его содержимого, и это не ошибка одного человека, а часть стандартов ISO/IEC/ECMA, разработанных гигантскими корпорациями) – всё ещё цветочки :-)
Но так-то да, тоже забавное наследие древних времён.naishin
29.07.2021 19:42Так до сих пор нельзя! Вин10, какой-то там летний апдейт 20H1.
А диски же изначально для музыки создавались. Может там не критично..
aamonster
29.07.2021 23:54Сравните ситуацию: нельзя (зарезервированное имя файла из-за совместимости с DOS) и можно (нигде в документации запрета нет), но файл с определённой сигнатурой внутри не прочитается.
На самом деле такие файлы крайне маловероятны (по ссылке описано, как файл получился и почему эта сигнатура ломает чтение с диска). Но вообще это просто баг в стандарте. В DVD такого уже, кажется, нет.
naishin
30.07.2021 00:26+3Было бы сравнимо если бы эту беду заботливо перенесли сначала на DVD, потом на блюрей, и далее в Нетфликс :)

czz
29.07.2021 12:19+6Не то то чтобы плохой, но не совсем подходящий для тех целей, для которых его начали применять.
MP3-файл - это MPEG с одним только звуковым потоком. MPEG - стриминговый формат, и он рассчитан на то, чтобы поток можно было начать читать с произвольного места, не имея доступа к началу или к концу файла. При этом в нем могут перемежаться потоки видео, аудио и метаданных. Предполагается, что при перемотке декодер тыкается приблизительно в нужное место, а дальше ищет синхропоследовательности знакомых ему типов фреймов.
Но вот ID3 второй версии - это реально больной формат, нет ему оправданий.
ALF_Zetas
29.07.2021 20:02ну да - официально формата MP3 не существует - на самом деле это MPEG-1 Layer 3


Finesse
29.07.2021 02:39Что, если есть некая
local file record, на которую центральный каталог не ссылается?Стеганография

DarthPadla
29.07.2021 04:53+1Жаль что статья кончилась так быстро, мне так хотелось почитать раздел про пароли на архив
TakashiNord
29.07.2021 05:55+1а почему, товарищи из Windows, решили встроить в ос формат zip ? какая выгода?
раз так все плохо?

VioletGiraffe
01.08.2021 14:27Про появление встроенной поддержки ZIP в Windows можно узнать от самого автора этой фичи :)

usa_habro_user
29.07.2021 07:19+5By the way, а на Хабре вообще есть не переводы?! Ведь тут просто бессмысленно возражать против неверных постулатов или утверждений - с переводчика какой спрос? :(
JordanoBruno
29.07.2021 15:31-1Раньше были. Потом авторов подразогнали и осталось самое простое - переводить чужие тексты.
hw_store
31.07.2021 18:31+1У тех, кто для себя постановил публиковать 2-3 поста ежедневно, оригинальных текстов почти не встречается.
Да и вообще, какой-то дайджест перепечаток.
С другой стороны, если тема интересна и видишь, что перевод корявый, всегда можно пойти прочесть оригинал, а так может никогда бы и не наткнулся на него
rrust
29.07.2021 08:48+1Тут в комментариях почему-то не упомянули что можно разобрать заголовок EXE SFX и сразу пропустить весь распаковщик, перейдя на собственно ZIP данные.
Ведь обычно работают с SFX на той же системе, которой он был создан, DOS/WIN или Linux. Хотя можно было бы и поддержать исполняемый формат большинства популярных SFX, их полагаю не так много. И для этого необязательно вносить поправки в описание формата.
Насчет обязательности к каждому типу записи придавать размер. В случае с архивом тут немаловажно учитывать влияние на итоговый размер. В общем случае достаточно указывать размер в файловых записях чтобы можно было перейти на следующий файл, если у текущего файла не знаем как обработать полностью его подзаписи.

vesper-bot
29.07.2021 09:56+1смещение до центрального каталога равно 1,347,093,766?
Это смещение 0x504b0506Эм, если архив пишется в формате LSB, то искомое смещение должно быть равно 0x06054b50=101010256 (любопытное число, красивое такое). Все равно слишком много для тех времен, но уже более вменяемое.


Daddy_Cool
29.07.2021 12:23+1Zip плох, но Microsoft так не считает. Как-то узнал, что формат docx — это XML (или что-то близкое) запакованное банальным zipом. Пользуюсь когда из файла надо выдрать картинки — переименовать *.docx в *.zip и разархивировать. (Написал, вдруг кому полезно будет).

opxocc
29.07.2021 13:27+2Ооо, это формат OOXML, вот там действительно наркомания и упомянутый в статье формат zip даже рядом не стоял, одна часть описания формата в виде zip архива занимает 42Мб, сама спека на 5029 страниц и чёрт там ногу сломит, особенно когда пытаешься разобраться почему тот или иной офисный пакет не хочет этому стандарту следовать.

speshuric
10.08.2021 23:09+1Справедливости ради - старый XLS по упоротости (даже без OLE Compound) вполне гармонично вписывается в эту компанию.
ADD: если подумать, то все сложные форматы при чтении вызывают определённый WTF/мин. И только старый однобитный TXT и такой же старый COM просты и понятны. Но TXT обзавёлся BOM, а COM (тот, старый, который глузился и выполнялся as is и был ограничен по размеру) нафиг уже никому не нужен.
balamutang
30.07.2021 11:24+2Скажу больше - явовский jar это тоже zip, в который упакованы все файлы программы вместе с манифестом




JordanoBruno
29.07.2021 15:36+1Даже не знаю, каким занудой надо быть, чтобы быть недовольным форматом файла из 89-го года, который еще и стал открыт для бесплатного использования.
hw_store
31.07.2021 18:34Kстати, не раскрыта тема, почему вымер .arj
DistortNeo
01.08.2021 00:35Мне тоже интересно. Пытался погуглить — информации ноль. Возможно, ARJ просто стал abandonware, т.к. он разрабатывался одним человеком, и этот человек в итоге на него забил.

netch80
01.08.2021 15:42Проблема не в том, что он был такой в 89-м — а что он остаётся таким в 2021.
Вот тут надо или лечить, или заменять.JordanoBruno
01.08.2021 18:46Что или кого надо лечить, я не очень понял? Да и зачем? Для zip написано огромное количество библиотек, он поддерживается на всех системах по дефолту. Кому нужно, используют более современные форматы, тот же 7z.

radchand
29.07.2021 18:0512 лет назад наступал на те же грабли ;-) Помню, тогда написал о проблеме разработчикам, но ответа не получил. Так чего уж кулаками махать спустя 30 лет... )))
По ссылке выше есть зипчик с другим зипчиком в качестве комментариев. Разные архиваторы видели либо оригинальный архив, либо комментарий. Любопытно, что 7zip, который 12 лет назад открывал файл из комментария (т.е. сканировал файл с конца), сегодня открывает файл из основного архива (т.е. уже сканирует сначала). Win10 (она нативно умеет в зип) считает что файл битый.
aamonster
29.07.2021 22:21+1Извините, а как вы 12 лет назад рассчитывали получить ответ от разработчиков? Фил Кац умер в 2000-м году.
radchand
30.07.2021 09:17Я тогда об этом не знал (если честно, то узнал только сейчас). Спасибо, теперь понятно. А писал, уже точно не помню, но вроде где-то нашел мэйл pkware.com.

Oxyd
31.07.2021 12:41Я правильно понимаю, что в архиве могут быть файлы отсутствующие в Central Directory? И при листинге списка файлов, стандартными распаковщиками типа InfoZip?, они будут не видны, а при распаковке не будут извлечены?
Bellerogrim
> Если же нам придется дожидаться чтения центрального каталога прежде, чем верно использовать любые из его записей, тогда функционально мы просто не сможем передавать zip-файл потоком.
Передавать мы как раз можем. Мы не можем читать, но это уже проблемы клиента. А передавать мы можем — файлы не зависят друг от друга, и мы можем добавлять их на лету.
> во времена создания формата zip файлы размером 1.3 Гб даже не предполагались [...] еще раз указывает на недостаточную продуманность структуры формата.
Ну да, ну да. В 1990 году кто-то не подумал про файлы размером в миллион дискет. Кошмар! А в 2020 кто-то думает о том, что int64 может закончиться? Что ядро линукса принципиально не способно адресовать вигинтиллион йоттабайтов памяти? На костёр, на костёр немедленно! Сначала надо продумать, чтобы потомки через 3000 лет не писали про нас статьи!
quwy
В 1990 году гигабайтное хранилище уже давно не было чем-то запредельным. Один IBM 0681 вмещал 857 МБ. Через год модель 0663 уже перешагнула за гигабайт. И это по сути тогдашний аналог одного современного HDD, и на серьезных машинах их стояло по несколько штук.
cat_crash
При этом создатель ZIP был школьником\студентом которому были доступны 640 Кб которых как известно должно было хватить всем (с)
Тогда IBM 0681 как и сейчас квантовые компьютеры - доступны очень узкому кругу. Если бы PK так широко мыслил то думаю первым что бы он сделал - оформил патент а потом бы уже думал как адресовать гигабайты правильно
quwy
Не оправдание. Все равно что сегодня студент-нищеброд придумает новый, очень крутой по сравнению с существующими, архиватор, и заложит в него предел 20 ТБ. Это тоже еще не домашний уровень, но совершенно очевидно, что ограничивать архиватор уже достигнутым уровнем вместимости дисков -- глупо.
И да, 1 ГБ -- это совсем не миллион дискет, а в районе тысячи. Годовой расход средненькой бухгалтерской конторы тех времен.
vonabarak
Кажется, мы тут рассуждаем о причинах, а не оправданиях.
Bellerogrim
Да, ошибся. Всё равно не тысяча, а несколько тысяч. Сама ходовая дискета всё ещё 360Кб. И потом — да, на больших компьютерах были гигабайтные хранилища. Но кому придёт в голову делать файловый архив такого размера? Зачем?!
quwy
Трехдюймовый FDD на 1.44 МБ был представлен в 1987, а 5.25″ на 1.2 МБ существовал аж с 1982 года. Вся эта информация открыта.
Так что дискеты на 360 КБ в 1990 году были распространенны разве что в отстающих странах, типа Варшавского блока.