
Общие вводные
Участники опроса — кто они?
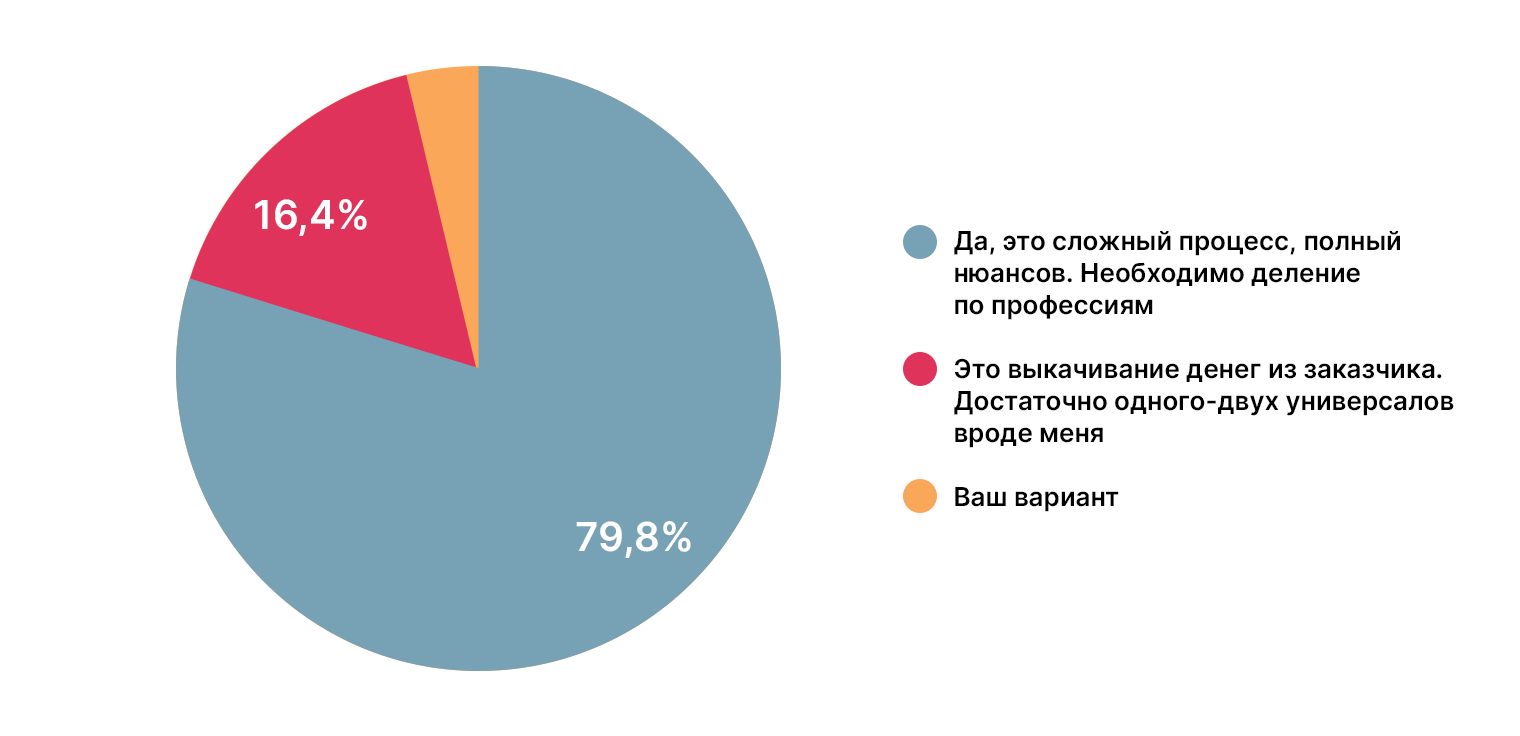
Представления о профессии
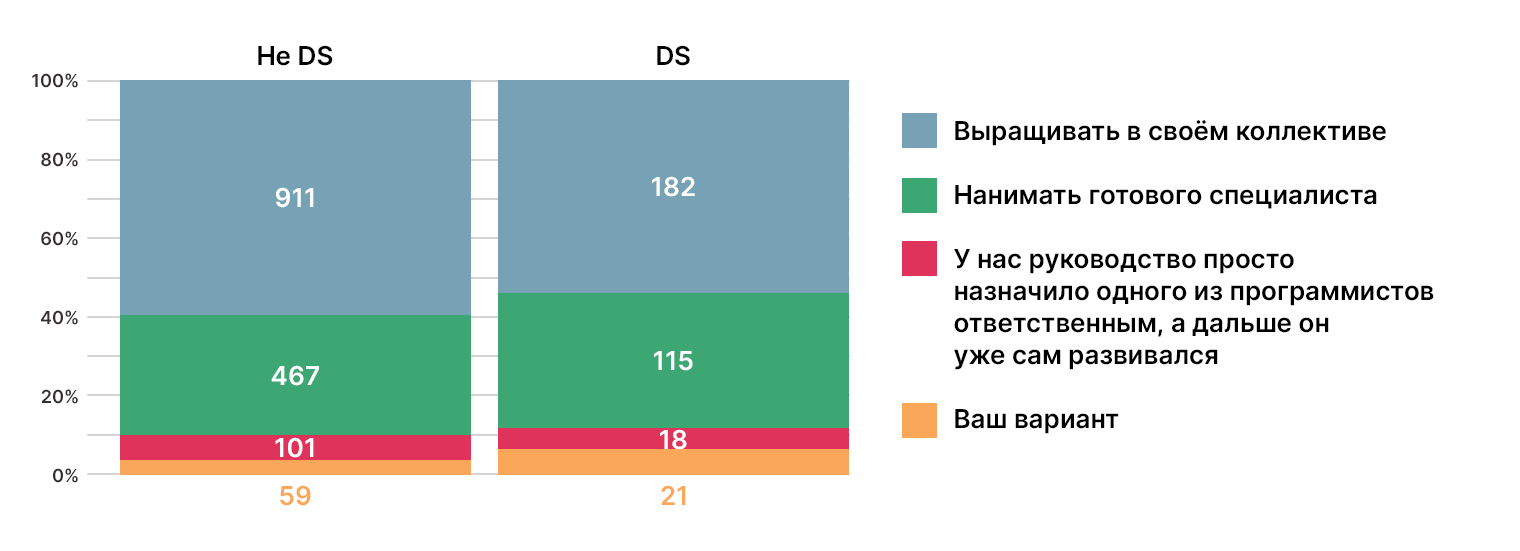
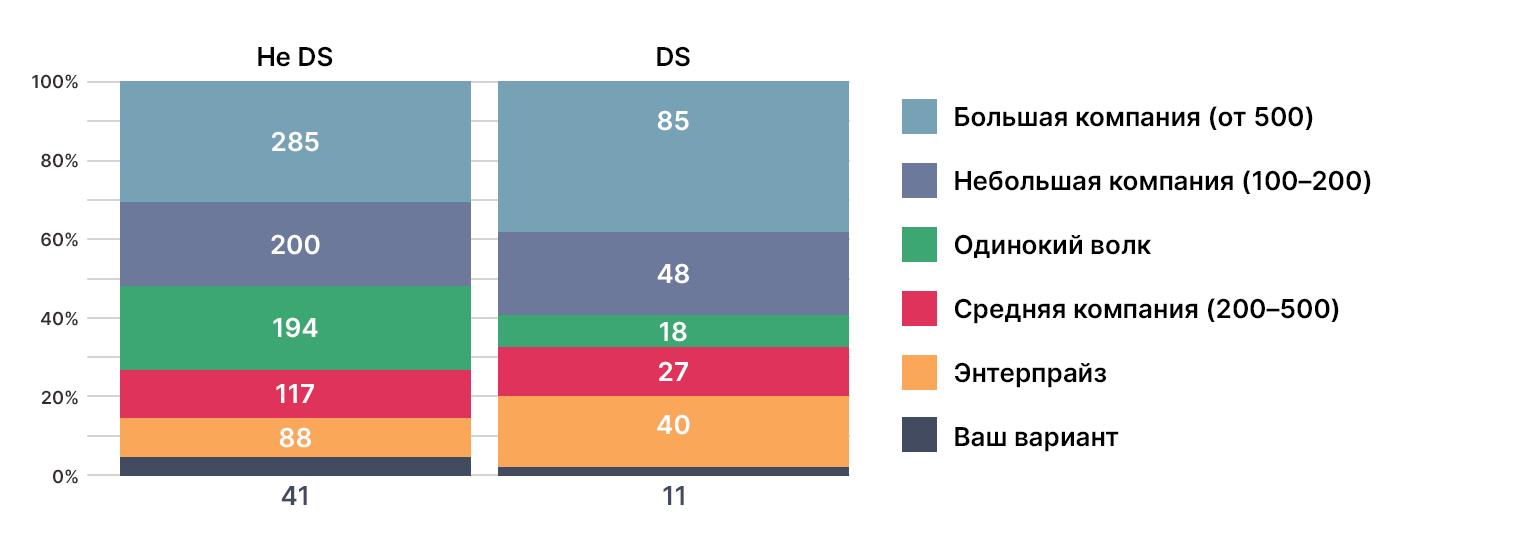
Откуда берутся дата-сайентисты?
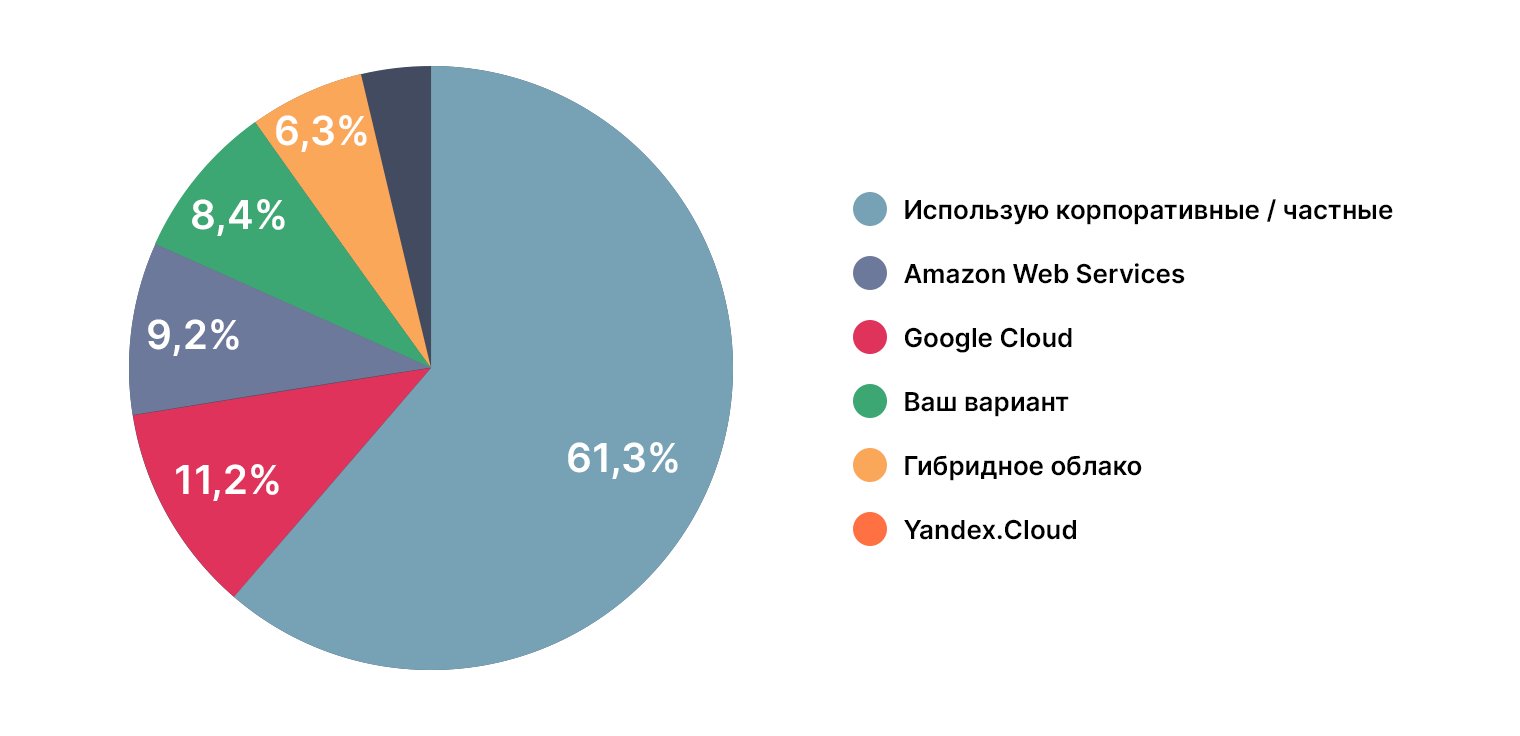
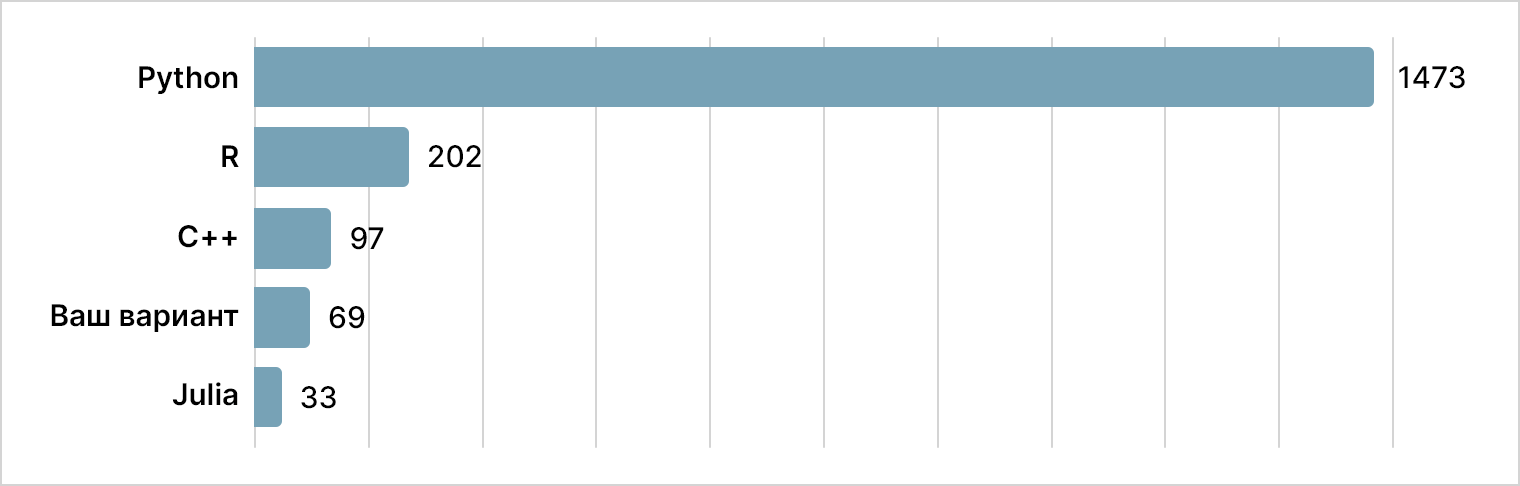
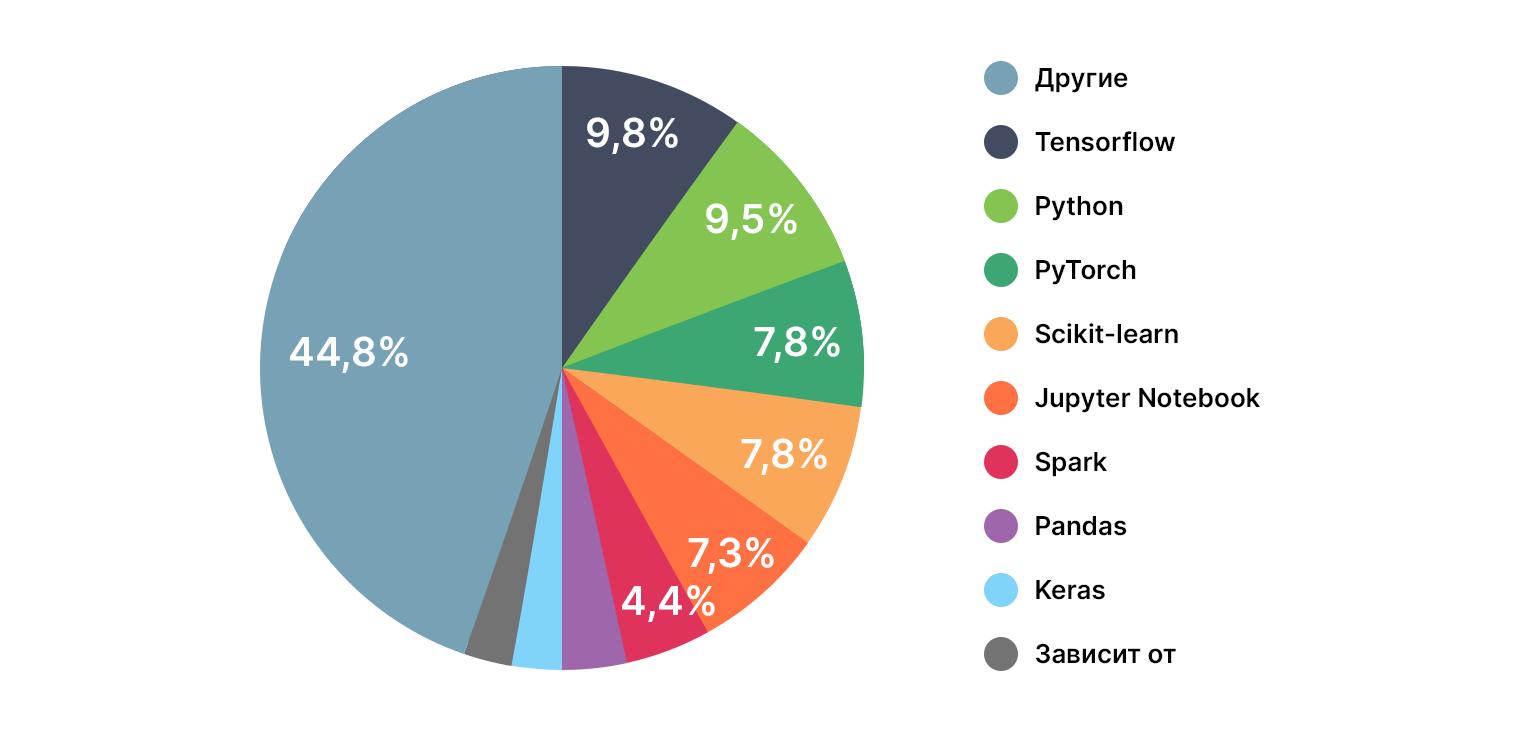
Инструментарий
- TensorFlow;
- Python;
- PyTorch;
- Scikit-learn;
- Jupyter Notebook
Выводы
Общие вводные


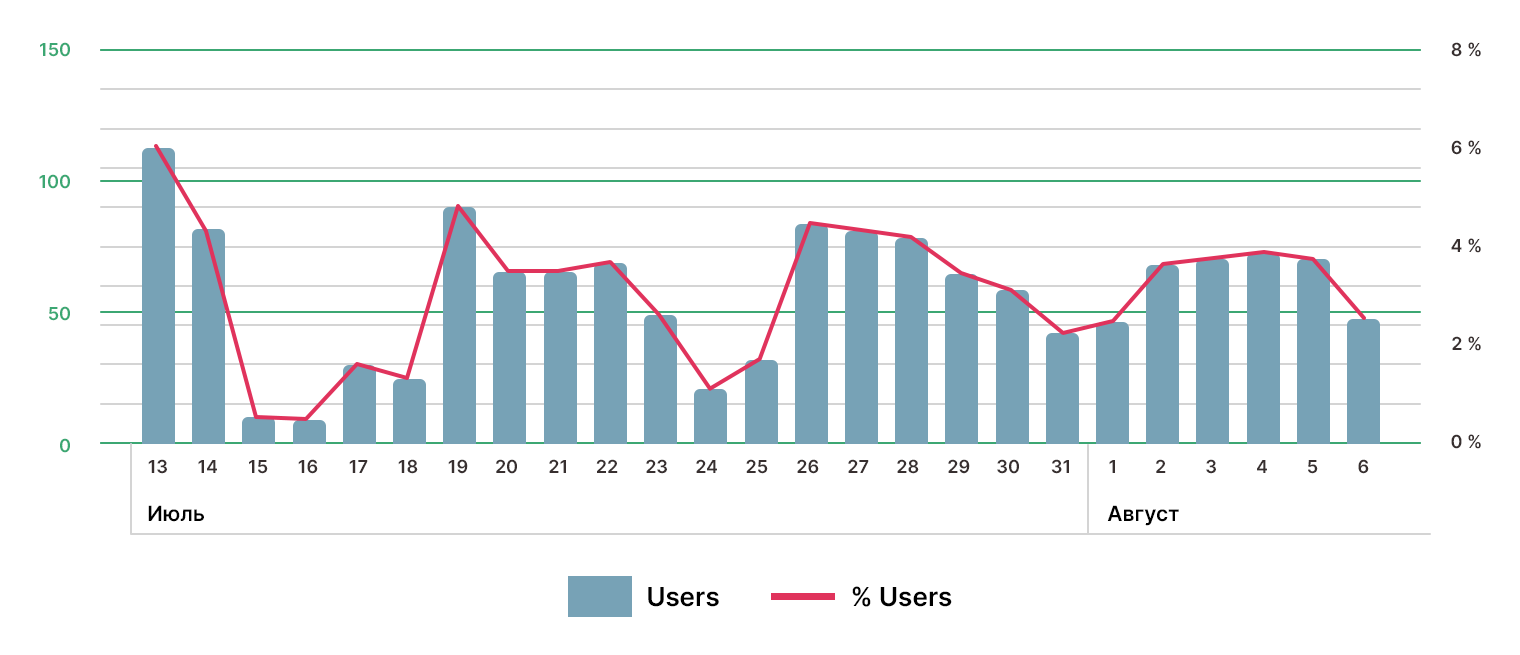
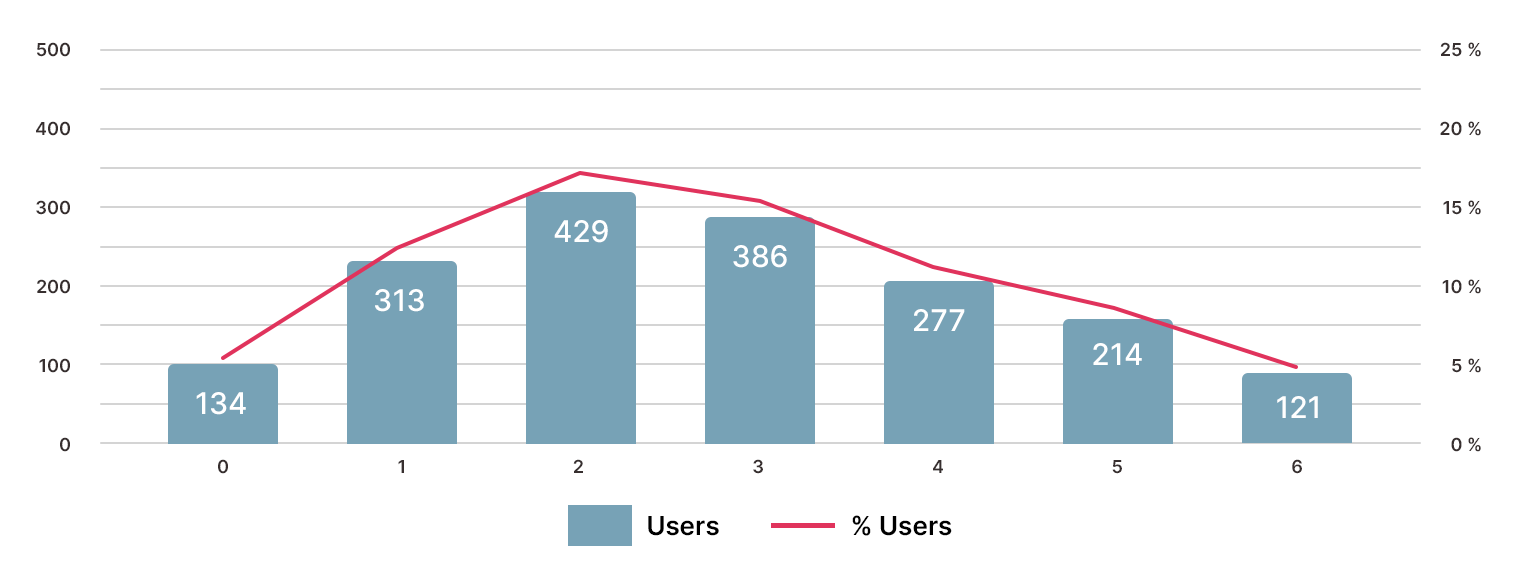
Участники опроса — кто они?
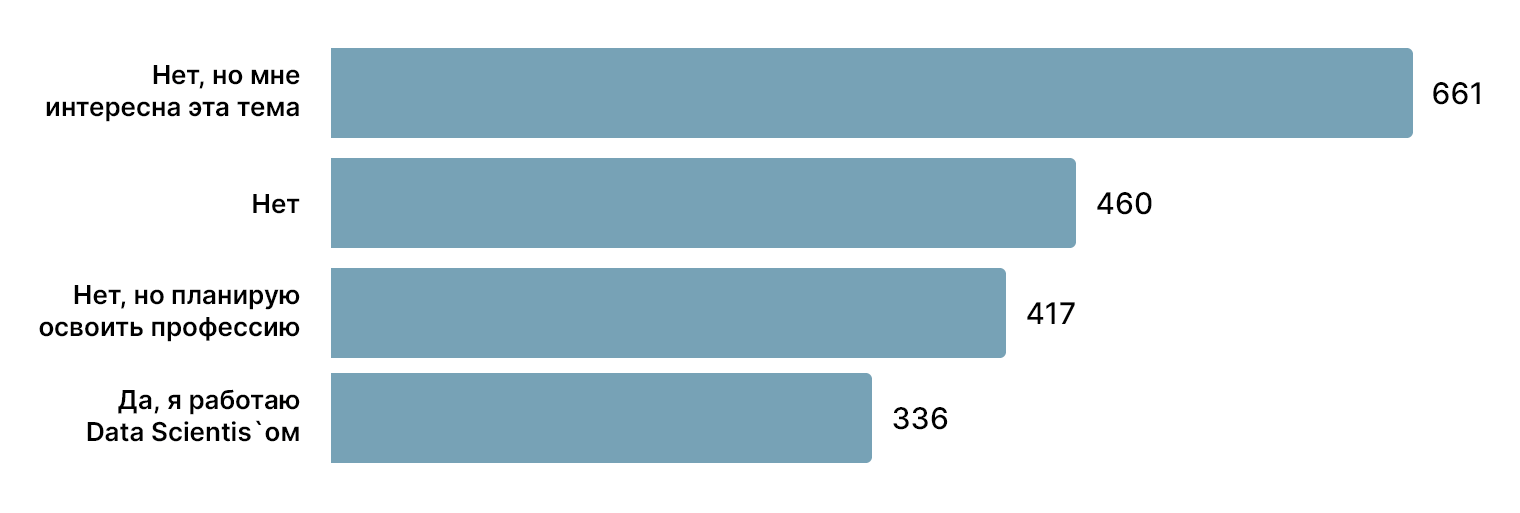
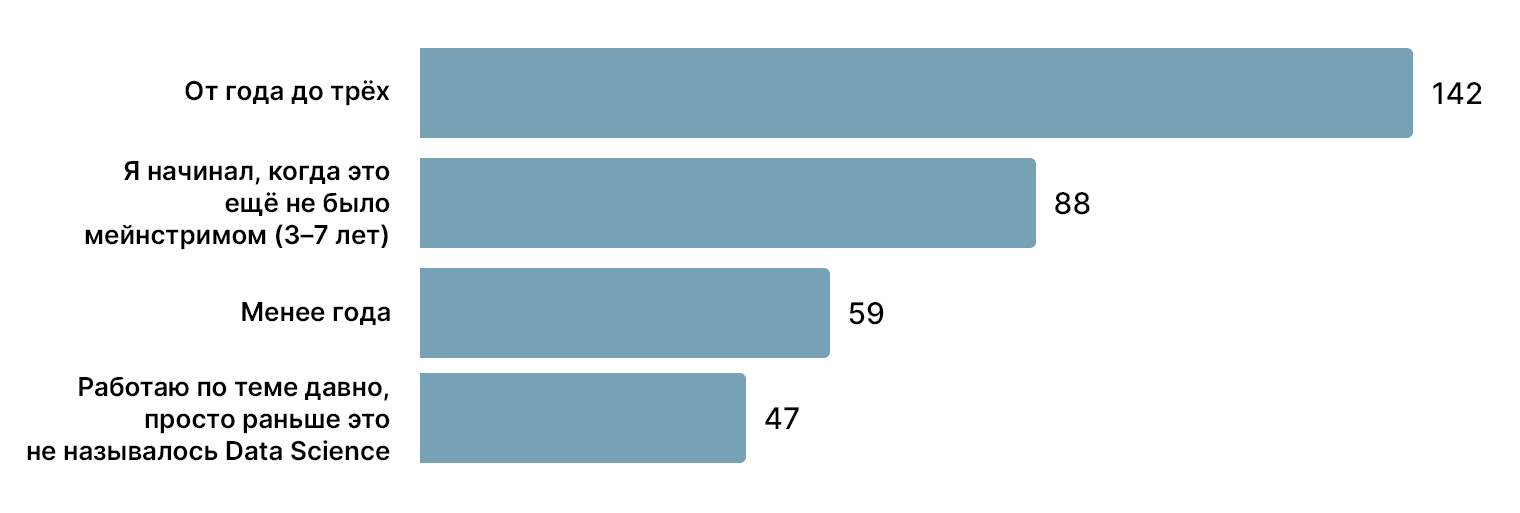
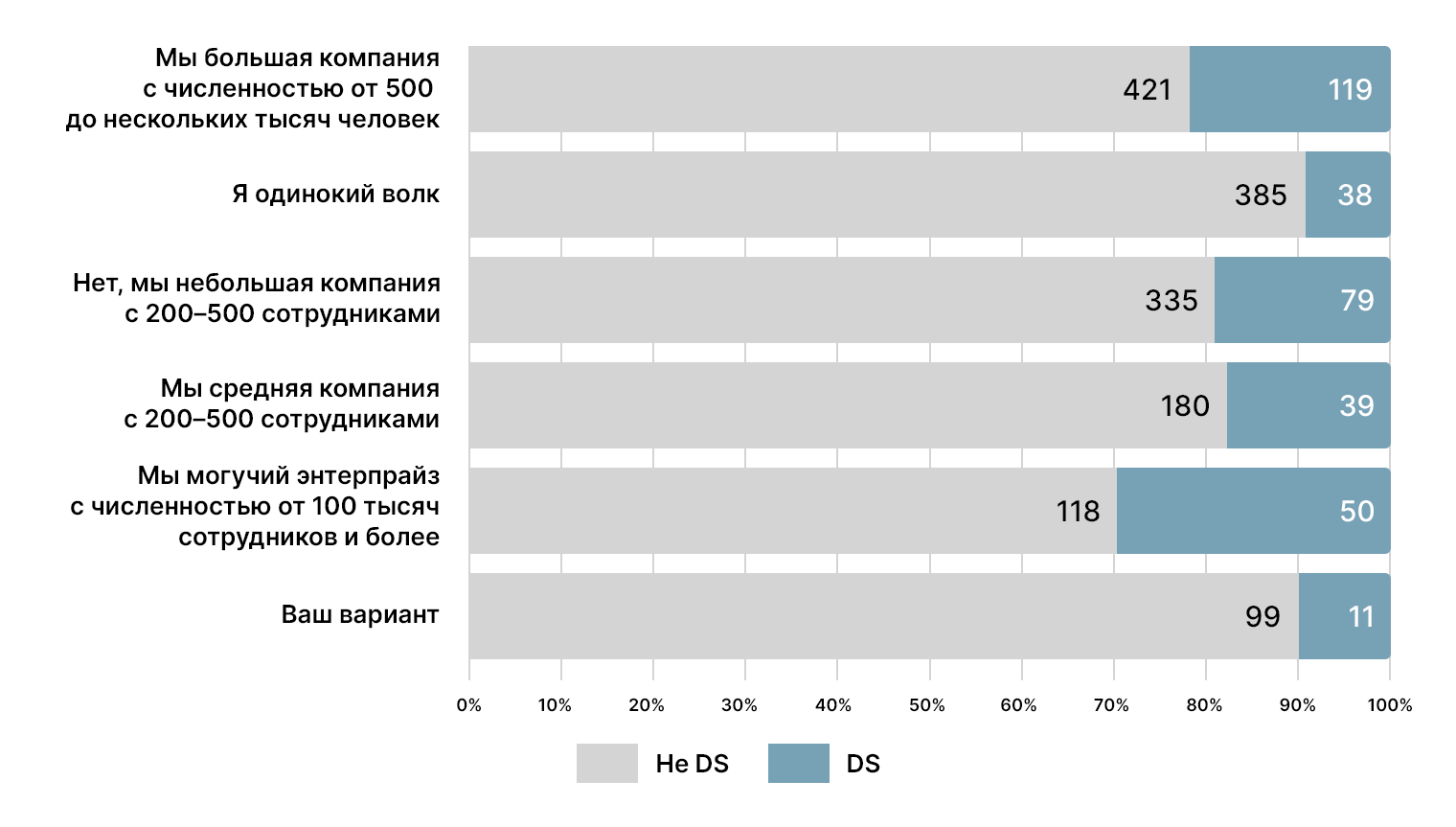
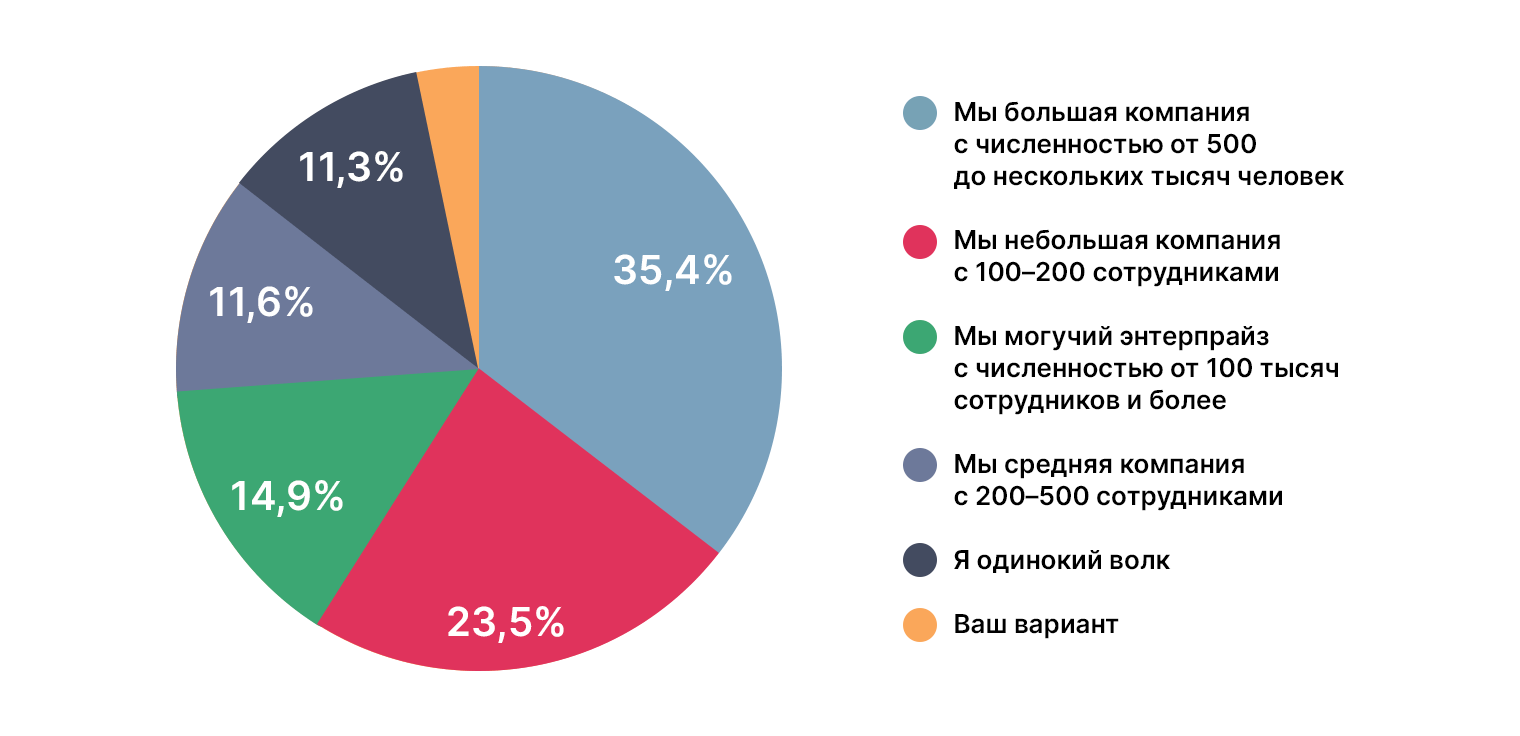
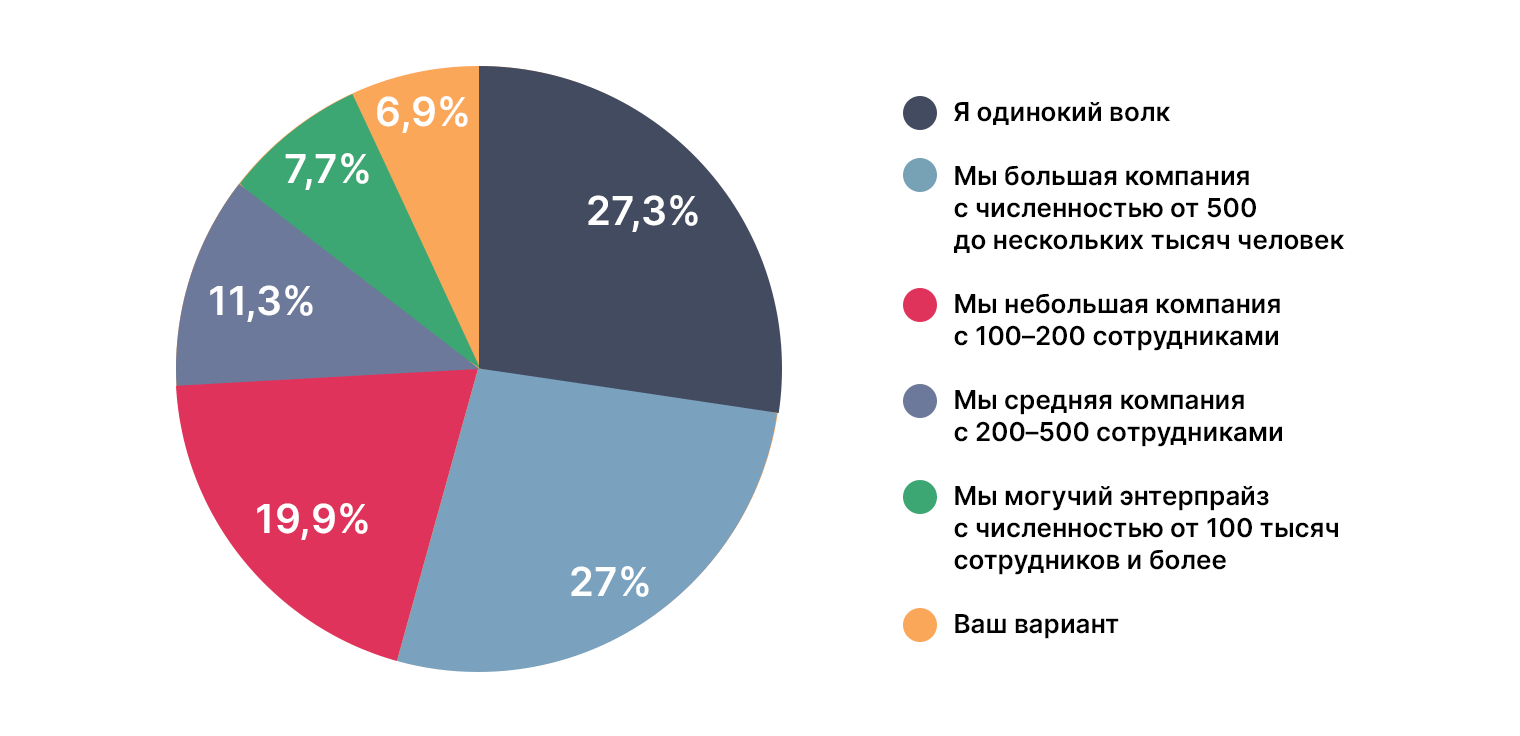
Представления о профессии
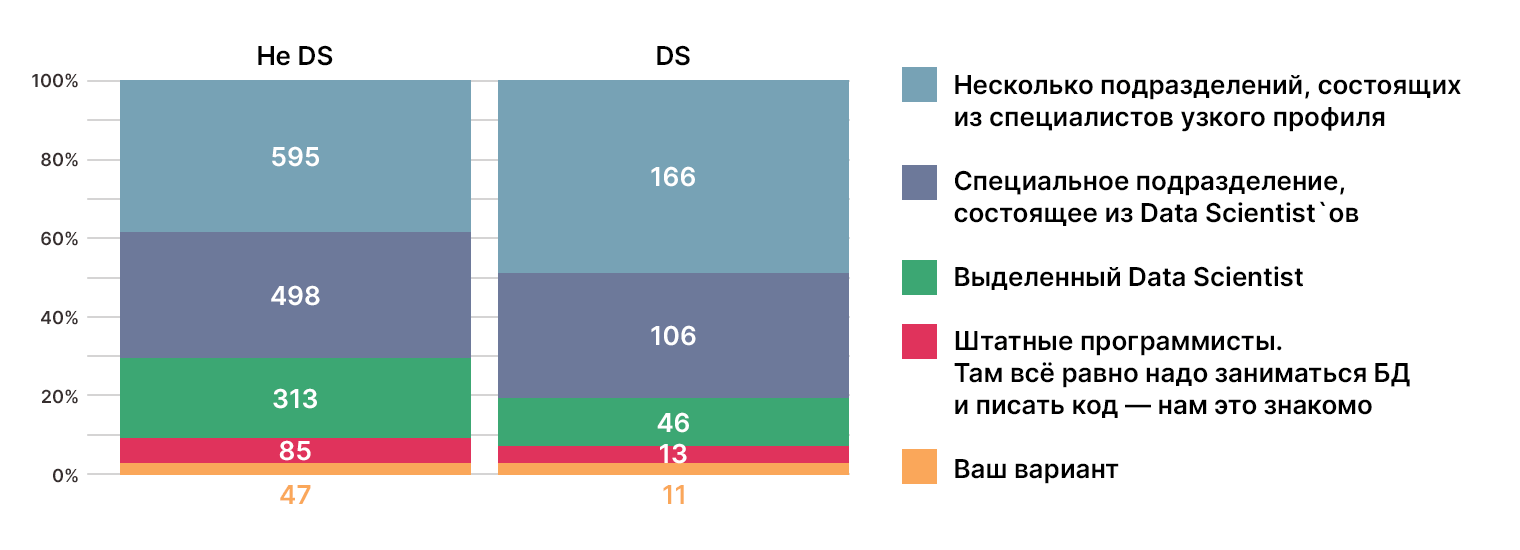
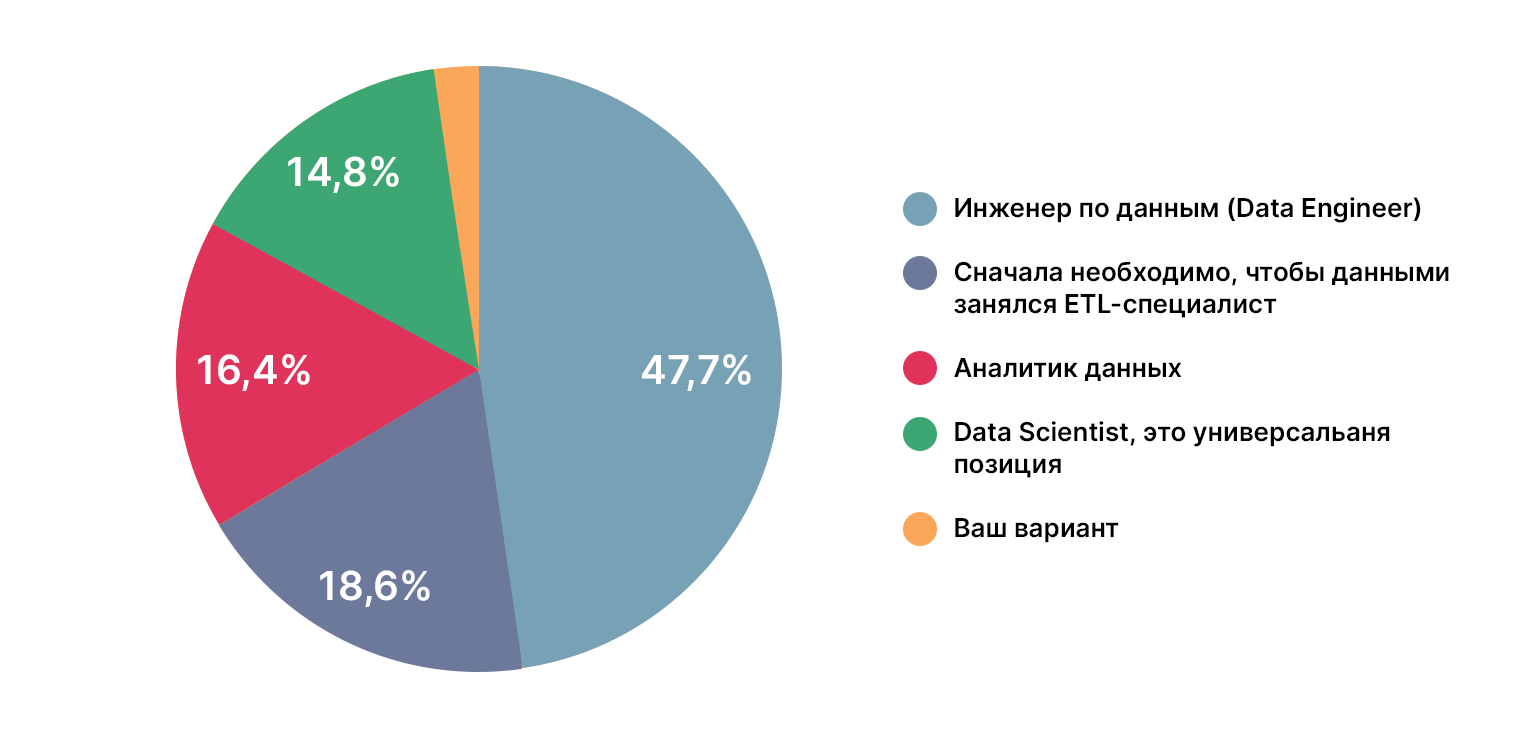
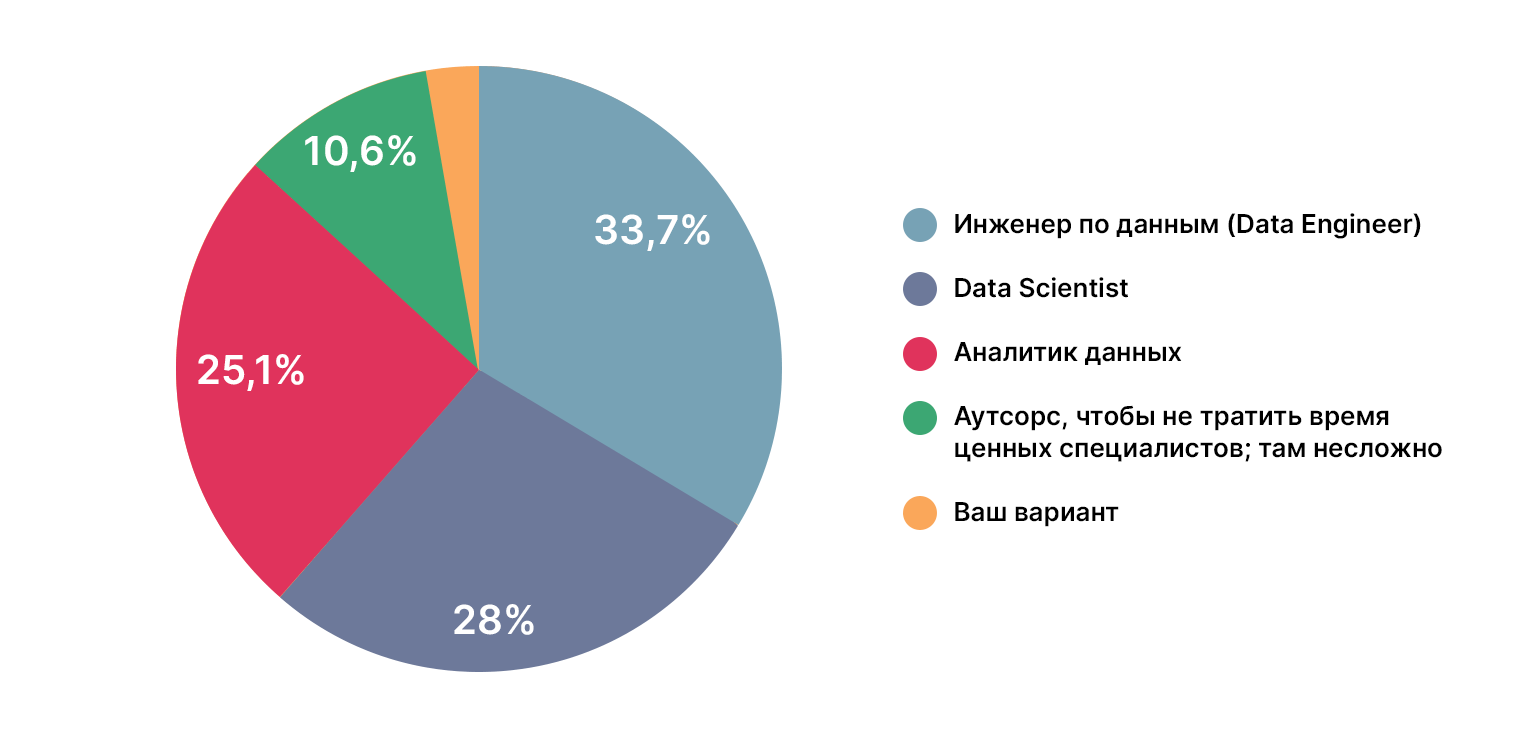
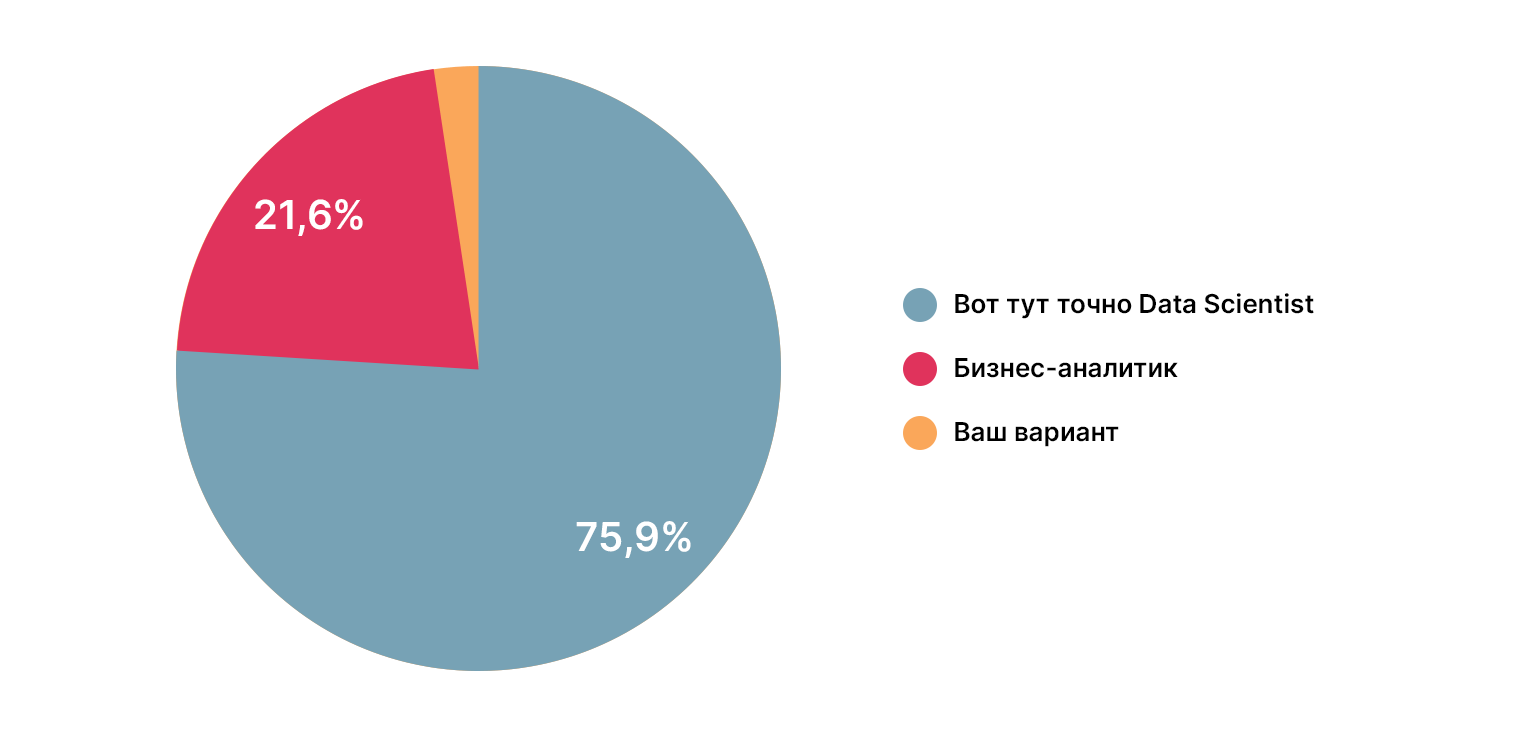
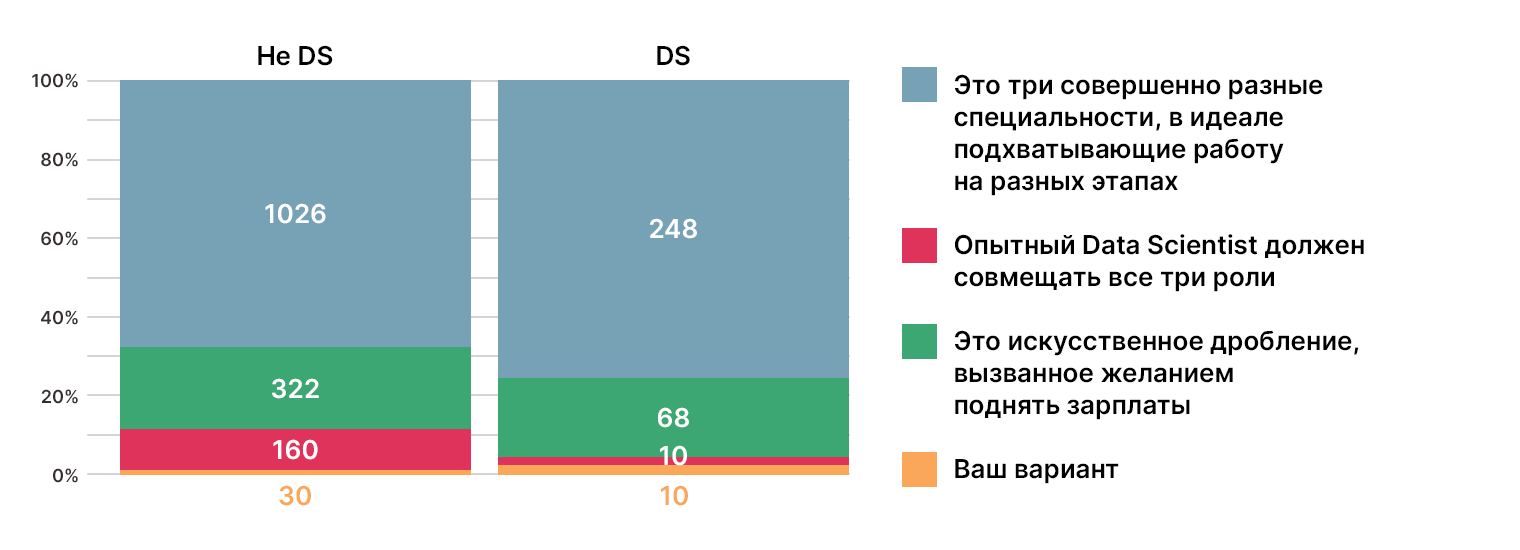
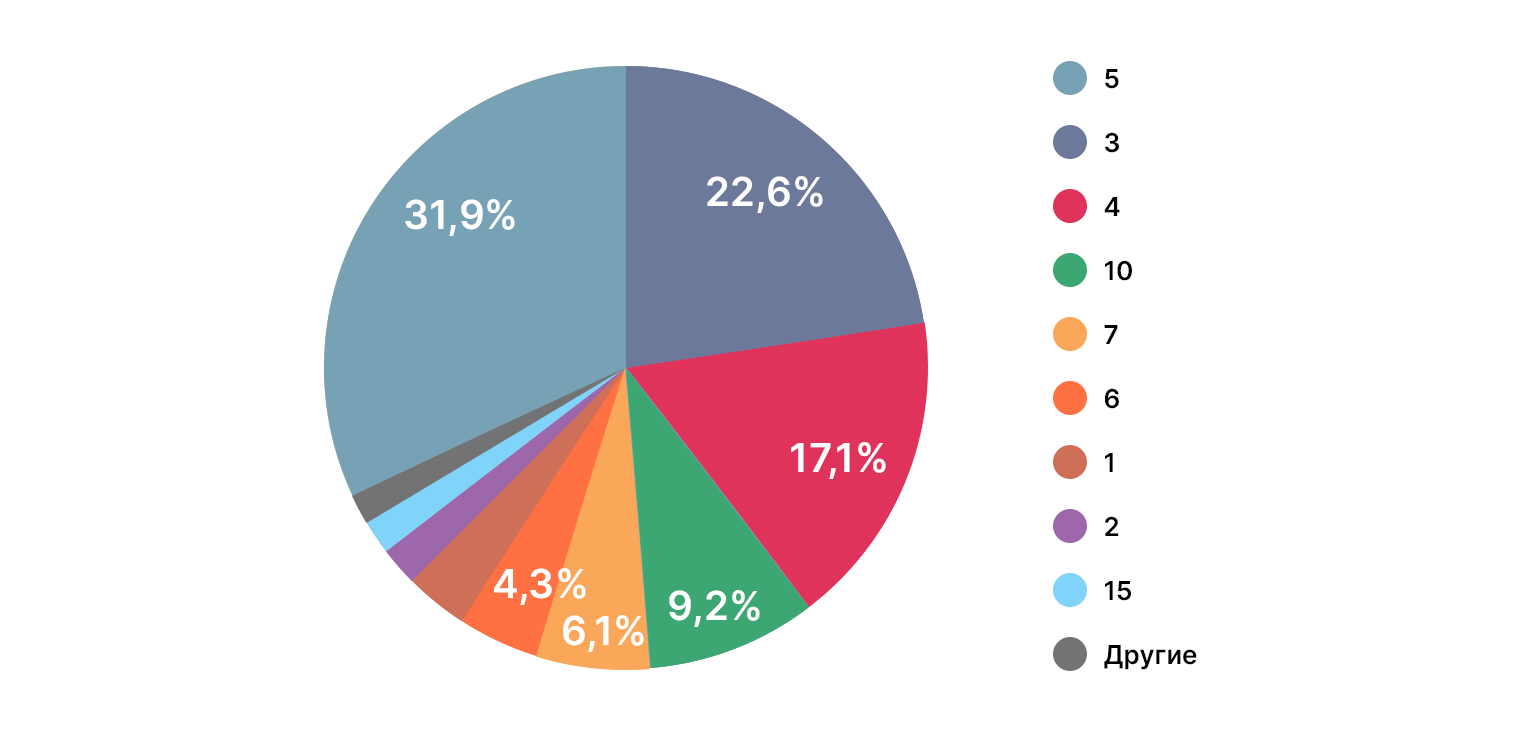
Откуда берутся дата-сайентисты?
Инструментарий
- TensorFlow;
- Python;
- PyTorch;
- Scikit-learn;
- Jupyter Notebook
Выводы
Комментарии (9)


Alexrook
23.10.2021 09:12Почему у Julia такой мизерный процент использования? Я не DS, но если бы им был, то скорее всего использовал бы именно Julia.
rshcherbakov
25.10.2021 11:48Скорее всего потому, что в плане DS не особо важно на чем писать.. а питон под рукой есть всегда и с ним хлопот объективно меньше
Alexrook
29.10.2021 23:26Чем отличается Julia? Что Python можно поставить за 3 минуты, что Julia. Абсолютно никакой разницы, и то и то доступное всегда и бесплатное. Интернет сегодня всегда под рукой. Про хлопоты вообще не понял.
rshcherbakov
30.10.2021 19:46@Alexrook,смотрите:
Для того, чтобы хоть как то предметно ответить на ваш вопрос, мне пришлось лезть в гугл и смотреть обертки и фреймворки под Юлю. К примеру, чтобы решить какую нибудь простенькую задачу, например MNIST пошатать или таблички, или временные ряды или еще чтото...
Ок, я нашел обертку под TF, которая вроде как работает, не проверял, но всеравно допустим она написана чисто хорошо с хорошим "запахом" и кодовым покрытием. И более того, я смогу засервить полученную модель в прод.Разумеется, для ассесмента запроса заказчика я не могу рекомендовать Юлю, поскольку, я не знаю, есть ли серьезная коммерческая поддержка требуемых фреймворков или поддержки комьюнити... Ну, оно (комьюнити) пока достаточно маленькое, то есть фиксить и контребьютить придется самим и за свой счет, либо заказчика радовать высокими счетами при малом количестве нового полезного функционала.
Допустим мы все нашли и решили вопросы с лицензиями, саппортом и прочими аспектами, и нам надо "застафить" наш проект. Нам нужен софтвер инженер, знающий Юлю, иначе просто нет смысла, мы не получим велью от использования Юли, нужны датасаентисты (поскольку из-за них весь сырбор), возможно датаинженеры, и прочее (там специалисты по автоматизации тестов, если компания богатая и большая, к примеру). Согласитесь, пока проблема?
Собсвенно вот. Я не спорю, что Julia это офигенная штука и возможно за ней будущее, но сейчас я бы не стал рекомендовать этот технологический стек заказчикам, просто из-за того, что пока глобольного перехода на Julia нет как и комьюнити подобного Python или JS комьюнити пока не сформировалось и денег скорее всего в Julia тоже нет, а вот риски связанные с саппортом, лицензированием и закрытием проектов, как мне кажется огромны.
В своей практике, пять лет назад я обжигался с TokuMX. Проект был крутой и хайповый, затем стартап, который развивал эту технологию купили, а проект закрыли и нам пришлось пол года выпиливать интеграцию с этой фигней из нашего продукта... В деньгах это было больно.
your_lucky_smile
25.10.2021 11:48"Начинающие сайентисты более одиноки" - за что так больно?
но да, так и есть
DS28
Привет, я DS28, и я использую DS… А опрос прошёл мимо меня…