
Как и всегда, сохраняя обратную совместимость мы увеличили скорость восстановления в 20 раз! Благодаря этому мы сделали внешнее восстановление очень надежным и быстрым процессом, на который вы можете рассчитывать. О том, как этого удалось добиться, рассказывает Product Owner & Solution Advisor Zextras Luca Arcara.

Процесс восстановления был разработан так, чтобы использовать как можно меньше ресурсов, чтобы сделать данный процесс фоновой операцией, которая не влияет на производительность службы. Однако со временем объем электронной почты изменился (размер почтовых ящиков пользователей растет, и пользователи хотят хранить в них всю электронную почту) в соответствии с общими спецификациями сервера (более мощный процессор и более быстрый диск).
Согласно отзывам наших клиентов, системным администраторам хотелось бы ускорить процесс, чтобы он мог использовать все доступные ресурсы.
Резервное копирование состоит из 3 этапов - подготовка, восстановление данных, восстановление общих ресурсов - и для достижения этой цели мы переписали вторую фазу, что позволило завершить процесс восстановления в 20 раз быстрее. Чтобы глубже понять 3 фазы резервного копирования, вы можете прочитать статью про Zextras Backup.
Позвольте мне более подробно объяснить, как работает процесс восстановления и как мы достигли этой цели.
Как известно, резервная копия состоит из двух типов объектов:
Метаданные, которые описывают, как изменяются элементы (их статус, папки, в которых они находятся, их атрибуты)
БЛОБы, которые физически содержат двоичные данные объекта, другими словами, base64 EML.
Для больших двоичных объектов требуется большая часть хранилища, но зачастую именно метаданные больше всего влияют на производительность резервного копирования. Это связано с тем, что резервным копиям необходимо считывать состояния каждого элемента, декодировать метаданные, строить зависимости метаданных (например, ограничение папок), читать большой двоичный объект, добавлять элемент в хранилище почты пользователя и обновлять файл с маппингом.
Лучший способ понять это - взглянуть на результаты серии проведенных нами тестов. Учтите, что резервное копирование работает на «серверном» уровне: каждый сервер должен оцениваться и анализироваться отдельно.
Такой была настройка нашей тестовой среды:
Версия ESX |
6.7.0 Update 3 (Build 14320388) |
Сервер |
Dell PowerEdge R440 |
Центральный процессор |
Intel(R) Xeon(R) Silver 4208 CPU @ 2.10GHz |
Параметры виртуальной машины:
ЦПУ |
4 vCPU |
|
Оперативная память |
16 gb |
|
Том 1 |
140 gb – /dev/sda – EXT |
/ |
Том 2 |
100 gb – /dev/sdb – XFS |
/backup |
Том 3 |
100 gb – /dev/sdc – XFS |
/opt/zimbra-index |
Том 4 |
100 gb – /dev/sdd – XFS |
/backup-to-restore |
ОС |
Linux Ubuntu 18.04.5 LTS |
|
Версия Zimbra |
8.8.15.GA FOSS edition Patch 8.8.15_P19 |
Также для тестирования использовалось 2 бакета S3.
Один бакет S3 для централизованного хранения
Один бакет S3 для резервного копирования на внешнем хранилище
На виртуальной машине установлен агент Prometheus, отправляющий собранные данные на портал Grafana.
Сначала мы сделали упор на управление метаданными, заполнив сервер 15 000 000 небольших писем размером в несколько килобайт: в основном только текстовые сообщения. Этот сценарий был предназначен для создания огромного количества строк базы данных и файлов в резервной копии без превышения общей квоты.
После того, как сервер был заполнен, было выполнено глубокое сканирование, и все учетные записи и домен были удалены с исходного хоста. Состав резервной копии для тестового примера был следующим:
Группа |
Число учетных записей |
Число элементов |
A |
1 |
1.450.000 |
B |
32 |
270.000 |
C |
32 |
105.000 |
D |
5 |
21.000 |
E |
10 |
9.000 |
F |
30 |
4.500 |
Затем созданная резервная копия была смонтирована под точкой монтирования /backup-to-restore.
Для ускорения восстановления были остановлены следующие службы: AntiVirus, AntiSpam, OpenDKIM.
Тест 1 - Внешнее восстановление отдельной учетной записи
Чтобы реализовать тестовую среду, аналогичную реальному варианту использования, все тома были ограничены 200 операциями ввода-вывода.
Для этого теста мы решили импортировать одну учетную запись с 270 000 писем: это в среднем соответствует пользователю с пятилетним стажем, который отправлял и получал более 100 писем каждый день.
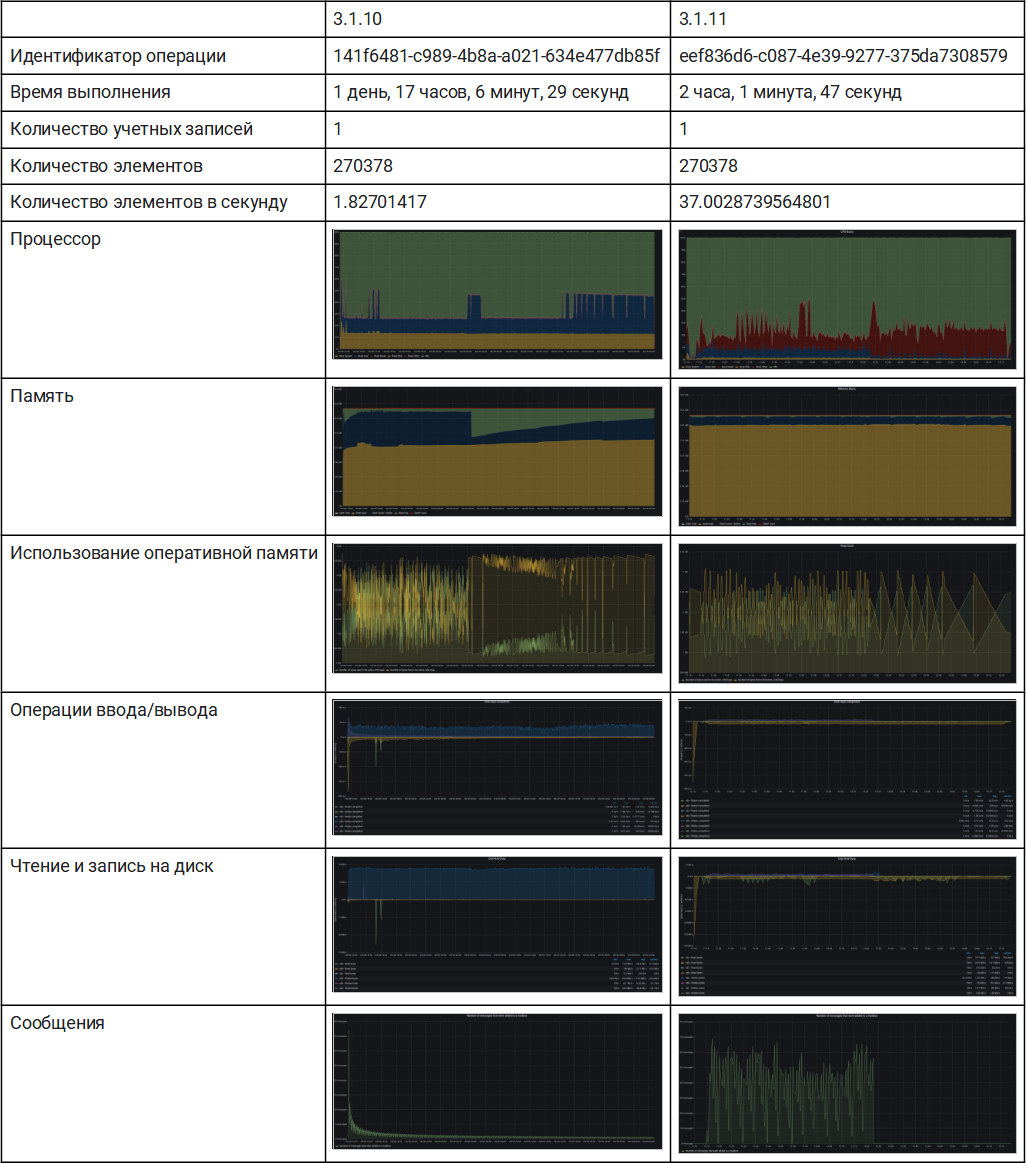
Этот тест дает чёткое представление о том, как мы поменяли процесс.
Версия 3.1.10 меньше использовала ЦП, а также меньше операций ввода-вывода и пыталась добавить небольшое количество элементов для каждой одновременно восстанавливаемой учетной записи.
Версия 3.1.11 максимально быстро считывает данные резервных копий, добавляя кластеры сообщений так быстро, как это позволяет сервер, используя всю доступную память.
Как мы видим, узким местом является количество операций ввода-вывода в секунду для точки монтирования восстанавливаемой резервной копии.
Набор тестов был завершен за 2 часа 1 минуту 47 секунд по сравнению с 41 часом 6 минут 26 секунд в предыдущей версии.
Это примерно в 20 раз быстрее, даже если 3.1.10 немного замедлился из-за параллельного выполнения ночного смарт-сканирования и других запланированных задач.
Тест 2 - Внешнее восстановление целого домена
В этом тесте мы снимаем все ограничения, чтобы обеспечить максимальную производительность хранилища.

Версия 3.1.10 не смогла пройти тест в течение 48 часов, что является ограничением по времени тестового примера. Все учетные записи были настроены, но через 48 часов после начала восстановления учетные записи из групп A и B все еще действуют.
Версия 3.1.11 завершила полное восстановление менее чем за 12 часов, в среднем 1200 операций ввода-вывода в секунду при чтении из исходной резервной копии и 600 операций ввода-вывода в секунду при записи в активный путь резервной копии.
Если убрать ограничения для дисков, статистика подскочила с 37 до 356 единиц в секунду (x10), в зависимости от увеличения IOPS (с 200 до 1800).
Также, глядя на статистику, вы можете увидеть, что последние 15 минут были интенсивными для ЦП, потому что на этом этапе резервное копирование заново выстраивает все общие ресурсы для восстановленных учетных записей.
Тест 3 - Внешнее восстановление отдельной учетной записи из группы A и B

Чтобы лучше понять связь между производительностью диска и скоростью резервного копирования, мы попытались восстановить по отдельности одну учетную запись из группы B и одну из группы A.
В отличие от предыдущего теста, скорость элементов упала до 213 элементов в секунду и 92 элементов в секунду. Частая сборка мусора и большая нагрузка на одну и ту же таблицу mysql вызвали интенсивную загрузку ЦП и замедлили весь процесс.
Мы можем заметить, что восстановление 1,5 млн элементов заняло менее 5 часов, в то время как для всего домена (около 15 млрд) потребовалось всего 12 часов.
Тест 4 - Внешнее восстановление 85 учетных записей - 50 из них одновременно

Чтобы проверить нашу гипотезу, мы запускаем еще один импорт 85 учетных записей из групп B, C и D (7 миллиардов элементов), используя 50 одновременных операций, чтобы ограничить восстановление.
Очевидно, средняя нагрузка была выше, чем раньше, и SSD обеспечил в среднем 1800 операций ввода-вывода в секунду, но восстановление было завершено менее чем за 4 часа, в среднем 595 элементов в секунду. Это максимальная скорость, которую мы смогли достичь!
Дополнительные кейсы
В предыдущих тестах мы полностью сфокусировались на метаданных, потому что знаем, что они являются критическим фактором. Но на общую производительность также влияет скорость передачи или пропускная способность, доступная для БЛОБов
Чтобы завершить тесты, мы также дополнительно провели небольшой тестовый кейс, организованный следующим образом:
20 учетных записей
Более 1170 000 писем
Общий объем хранилища 60 ГБ
Мы настроили резервное копирование с использованием внешнего хранилища S3. Он использовал около 45 ГБ на S3 и 628 МБ на локальном диске метаданных (10% логического пространства).
Мы продолжили процесс восстановления по разным сценариям.
Полностью удаленный: после загрузки метаданных сервер считывает БЛОБы из удаленной резервной копии и использует удаленное централизованное хранилище в качестве основного тома.
Наполовину удаленный: после загрузки метаданных и БЛОБов сервер считывает данные локально и использует удаленное централизованное хранилище в качестве основного тома.
Локальный: после загрузки метаданных и БЛОБов сервер считывает данные локально и использует локальное хранилище в качестве основного тома.
1. Полностью удаленный:

Восстановление было выполнено с чтением метаданных с локального диска, а БЛОБ-объекты считывались непосредственно с S3. Также mariaDB находилась на локальном SSD, в то время как БЛОБы были записаны в централизованном хранилище S3.
В этой конфигурации все операции с метаданными выполнялись локально, а БЛОБ-объекты записывались и извлекались с использованием подключения к Интернету.
3.1.11 был в 1,2 раза быстрее предыдущей версии в управлении метаданными, но скорость передачи данных оказала огромное влияние на общую продолжительность.
2. Наполовину удаленный:
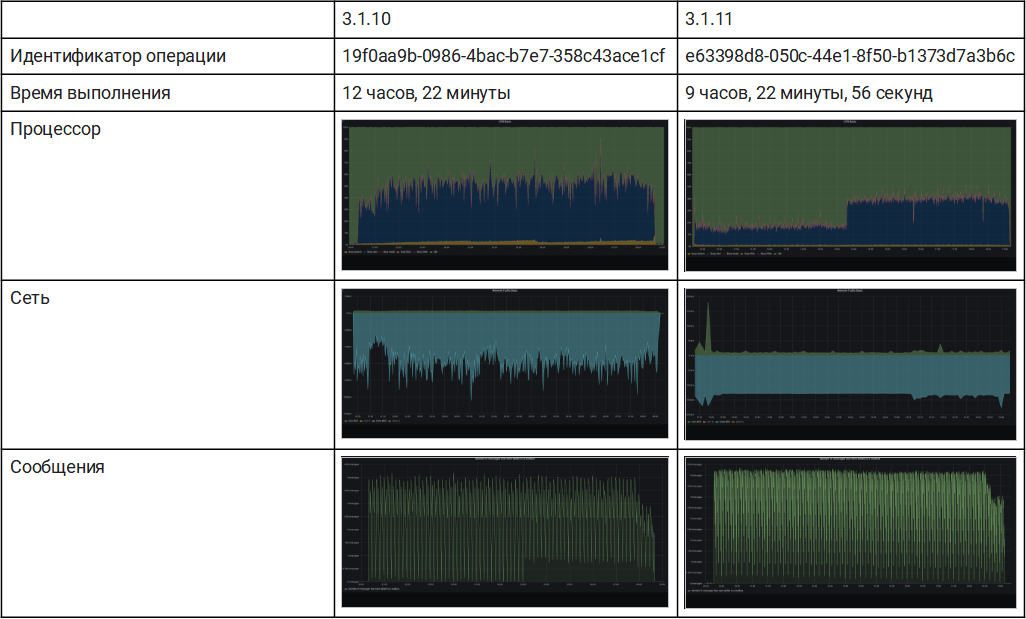
Восстановление было выполнено с чтением БЛОБ-объектов и метаданных с локального диска. В частности, резервная копия была подключена локально. По-прежнему mariaDB была расположена локально на SSD, а БЛОБ-объекты были записаны в централизованное хранилище S3.
В этой конфигурации все операции с метаданными выполнялись локально, а записанные БЛОБ-объекты извлекались с использованием подключения к Интернету.
3.1.11 был в 1,3 раза быстрее по сравнению с предыдущей версией в управлении метаданными, но скорость передачи по-прежнему влияла на общую продолжительность.
3. Локальный
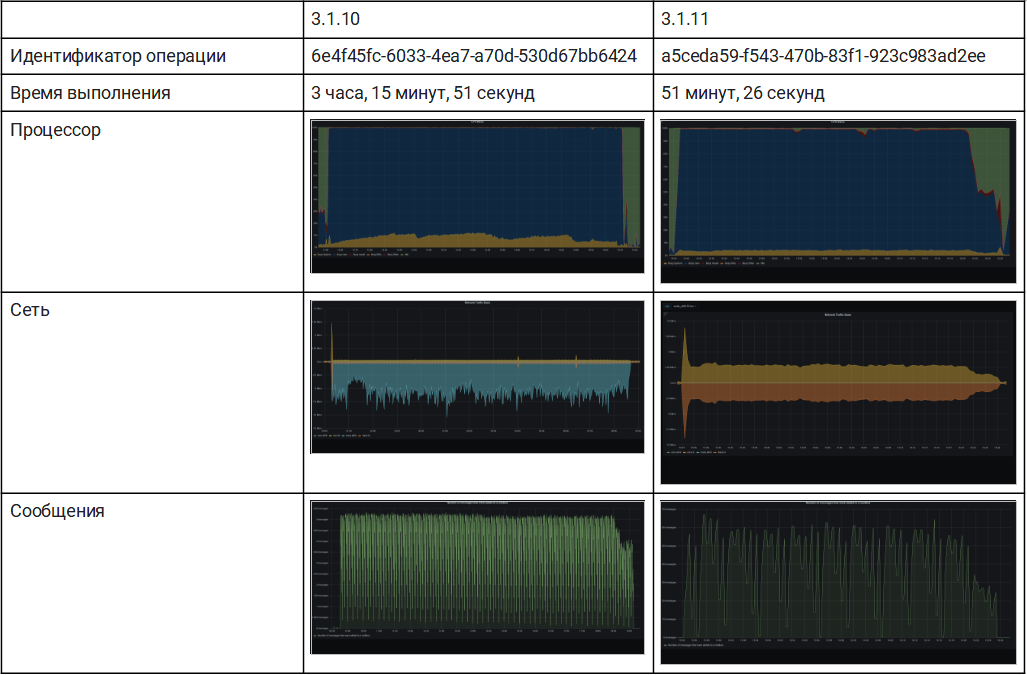
Восстановление было выполнено с использованием локального диска как для метаданных, так и для БЛОБ-объектов. Оба были на SSD, однако всегда должна быть возможность перемещать данные с основного тома на HSM.
3.1.11 по итогам проведения всего процесса оказалась в 4 раза быстрее, чем предыдущая версия.
Мы постоянно работаем над улучшением нашего решения для резервного копирования и улучшением его производительности. Однако из-за того, что оно работает в реальном времени, производительность всегда строго связана с производительностью ввода-вывода.
По этой причине при масштабировании инфраструктуры вам следует подумать о:
Оперативной памяти и количестве операций ввода-вывода для метаданных MariaDB и Zextras
Скорости передачи и пропускной способности при резервировании BLOB-объектов для последовательного доступа
Количестве элементов для каждой учетной записи
Чтобы уменьшить объем хранилища, необходимый для метаданных, рассмотрите вариант «внешнего хранилища», который может уменьшить объем локального хранилища на 80%. Это сделает процесс восстановления более быстрым и надежным для сценариев миграции и восстановления.
По всем вопросам, связанными c Zextras Suite и Team Pro вы можете обратиться к Представителю компании «Zextras» Екатерине Триандафилиди по электронной почте ekaterina.triandafilidi@zextras.com
amarao
Zextras today at 15:00
ОС: Linux Ubuntu 18.04.5 LTS
свежо...