

Шел 2021 год, русские хакеры продолжают переигрывать и уничтожать загнивающий Запад, вмешиваясь в выборы, ломая фейсбуки и пентагоны. Тем временем на Хабре выходят статьи о создании неубиваемых Kubernetes-кластеров, которые, по видимому, всех нас переживут. А кто-нибудь подумал о простых пацанах (пацанессах)??? Как быть обычному программисту, который хочет свой небольшой кластер и ламповый CI/CD с автодеплоем приложения, чтобы кенты с района не засмеяли?
Всем привет, меня зовут Алексей и я алкоголик разработчик на Python/Go в Домклик. Сегодня мы будем понижать порог входа в self-hosted Kubernetes и GitLab AutoDevops.
Это очередная статья из серии «ультимативных». Мы уже писали раньше, например, о том, как выглядит асинхронное приложение здорового человека. Или гайд по поиску утечек памяти в Python. Сегодня тоже будет весело.
Статья получилась довольно большая, поэтому после каждой главы будет стрелочка ↑, нажав на которую вы обратно перейдёте к оглавлению. Те, кто хочет всё и сразу — переходите к разделу TL;DR, там будет краткая выжимка из статьи.
Оглавление
Введение
Начнем с самого животрепещущего — с ценообразования. Откуда взялись эти 514$?
Если в вас живет маленький стартапер, то вам рано или поздно придется где-то развернуть свой кластер и настроить автоматическую поставку приложения в production-окружение (не руками же деплоить в 2к21?). Платить жадным гигантам по типу гугла или амазона огромные деньги — это зашквар. Денях-то нет, вот мы и держимся. Поэтому я решил попробовать собрать свой кластер и настроить CI/CD за минимально возможные средства, но при этом попытался не перегибать палку в чрезмерной экономии.
Кластер решил делать минимальный, состоящий из двух узлов — master и worker. Обе машины имеют конфигурацию 2x2,2 ГГц, 4 Гб RAM, 40 Гб SSD. Аренда одной в месяц ~ 12$. В год за две машины ~ 278$. Платил в рублях, перевел в доллары для удобства дальнейших расчетов (курс 72 р).
CI/CD решил реализовывать в GitLab (лежит к нему душа). И как оказалось, это довольно большая статья расходов. Еще в начале года был silver-аккаунт, с более менее приличными ценами ~ 9$ в месяц. Но сейчас его упразднили и на его место пришел premium за 19$ в месяц или 228$ в год. Естественно, там много плюшек типа овер-дофига CI-минут, канареечный деплой, защищенные переменные окружения, дашборд окружений Куба и т.д., но цена довольно кусачая.
Третья статья, самая маленькая — покупка доменного имени. Мне обошлось в 8$ за первый год (за последующие там вроде в два раза больше берут).
Итого: 278$ + 228$ + 8$ = 514$.
А что, если купить еще один VPS и установить туда GitLab? Официальная документация рекомендует использовать машину с двумя ядрами и 4 Гб оперативы. Если брать VPS у того же провайдера, то выйдет 12$ в месяц, а в год — 144$. Экономия в таком случае 84$ за год. Но тут прибавляется забота об установке, настройке, администрировании GitLab. И не уверен, насколько полная функциональность в таком случае будет доступна. Знатоки self-managed GitLab, напишите в коменты.
В итоге я решил не заморачиваться с установкой своего GitLab и весь материал статьи отрабатывал на конфигурации за 514$. Но вот только пару дней назад, неудовлетворенный качеством предоставляемых облачным провайдером услуг, решил погуглить в надежде на более дешевые альтернативы. Оказалось, что есть машины не просто дешевле, так ещё и мощнее. Например, предлагают в аренду VPS [3x2,8 ГГц, 5 Гб RAM, 60 Гб SSD] за 9$ и [2x2,8 ГГц, 2 Гб RAM, 40 Гб SSD] за 6$ в месяц. За год выйдет: (9$ + 6$) * 12 + 228$ + 8$ = 416$. В будущем планирую арендовать машины именно у этого провайдера.
Вывод: если задаться целью максимально сэкономить, то варианты найдутся. А на этом вступление окончено. Дальше будет долго, нудно и моментами даже чересчур подробно; думаю, полностью прочтут эту статью два человека: я и наш шеф-редактор блога (за что ему большое спасибо!). ↑
Установка Kubernetes на голое железо
Установка Kubernetes
Вам легко будет установить по этой замечательной инструкции. Но в ней есть ряд критических моментов, которые я разобрал под спойлером.
Подсказки по установке Kubernetes на Ubuntu 20.04 LTS
Установка делится на этапы и пункты. Здесь показаны те пункты, в которых возникает ошибка.
Этап 1. Пункт 4.
sudo systemctl enable dockerЕсли выполнить эту команду, будет ошибка:

Поэтому откройте файл /etc/hosts:
nano /etc/hostsВ моем случае не определен хост ruvds-2p1sn, мне надо добавить:
127.0.0.1 ruvds-2p1snА также в этом файле введите следующее имя (это для master-ноды; когда будете повторять для worker-ноды, то введите kubernetes-worker)
127.0.0.1 kubernetes-masterУ меня файл выглядит так:

Сохраняем и выходим. После чего можно выполнить команду:
sudo systemctl enable dockerЭтап 2. Пункт 1.
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key addЭта команда приведёт к ошибке:

Здесь нужно установить curl. Скопируйте предложенную в консоли команду и выполните:
apt install curlПотом выполните такую команду:
apt-get update && apt-get install -y gnupg2Готово. Теперь уже выполняем команду из пункта 1 второго этапа.
Этап 2. Пункт 2.
sudo apt-add-repository "deb http://apt.kubernetes.io/ kubernetes-xenial main"Эта команда приведёт к ошибке:

sudo apt-get install software-properties-commonИ возвращайтесь к команде пункта 2.
Этап 2. Пункт 3.
Предыдущие ошибки легко гуглятся и решаются одной командой. А вот с этой командой сложнее:
sudo apt install kubeadm kubelet kubectlЕще в начале этого года с ней не было проблем. Но на момент написания статьи эта команда приводит к проблеме инициализации master-ноды на этапе 3 пункт 4. Что изменилось? Вышла новая версия утилиты — 1.22.2. В начале же года я ставил версию 1.20.2 и всё было хорошо. Причину сбоя инициализации я на просторах интернета не нашел. Почти все руководства по установке не указывают конкретную версию утилит. А мы это исправим:
sudo apt install kubeadm=1.20.2-00 kubelet=1.20.2-00 kubectl=1.20.2-00Вам же я предлагаю сначала попробовать с последней версией (если это, конечно, не 1.22.2), и если в пункте 4 этапа 3 есть проблемы, то возвращайтесь сюда и откатывайтесь на версию 1.20.2.
И обязательно надо выполнить эту команду:
sudo apt-mark hold kubeadm kubelet kubectlЭтап 3. Пункт 1.
sudo swapoff –aЭта команда нерабочая. Будет ошибка:

Я заморочился и даже сравнил с перепечатанной командой вручную.

Оказалось, что тирешка вовсе не тирешка -_- . Используйте эту команду:
sudo swapoff -aЭтап 3. Пункт 4.
На этом этапе есть !критическое! замечание. Нужно выполнить такую команду:
sudo kubeadm init --pod-network-cidr=10.244.0.0/16Да, обязательно нужно добавить этот странный диапазон IP-адресов. Это нужно для сетевого плагина Flannel, который устанавливается далее по инструкции.
Этап 3. Пункт 7.
Тут команда верная, но адрес слетел на следующую строку. Используйте это:
sudo kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.ymlНа этом всё. Повторяйте инструкцию для worker-ноды (исключая некоторые пункты, которые нужны только для master-узла).
UPD 21.10.21 Попробовал установить кластер и на CentOS 8 по этой инструкции. Проблем практически не было (в отличии от Ubuntu), инструкция очень даже рабочая. Но есть пару моментов, на которые хочу обратить внимание под спойлером.
Подсказки по установке Kubernetes на CentOS 8.
Почти все команды с cat -нерабочие, я их тут поправил. Команда в пункте 6:
cat <<EOF> /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOFИ команда в пункте 1 следующего раздела:
cat <<EOF> /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-\$basearch
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
EOFОчень важный момент - в этой инструкции для фаервола добавляют некоторые исключения и доверительные хосты. Если следовать чисто по статье, то в последствии не получится достучаться до ingress-nginx (лично у меня не получилось). Поэтому я решил просто выключить фаервол (все-таки поднимаем dev кластер).
И в отличии от Ubuntu на CentOS 8 я смог поставить самую крайнюю (1.22.2) версию куба.
Поздравляю! Теперь у вас есть свой собственный Kubernetes кластер! ↑
Установка Helm
Инструкция взята с официального сайта для Ubuntu.
curl https://baltocdn.com/helm/signing.asc | sudo apt-key add -
sudo apt-get install apt-transport-https --yes
echo "deb https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helmПроверим успешность установки:
helm version
Инструкция для CentOS 8.
Тоже с официального сайта:
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.shHelm установлен! ↑
Установка Ingress-nginx
Инструкцию стянул из официальной документации.
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
helm install ingress-nginx ingress-nginx/ingress-nginxТакже запросим установленные сервисы:
kubectl get svc
Если бы вы пользовались облачным сервисом GKE или AWS, то в графе EXTERNAL-IP появился бы выделенный IP-адрес.
А Ingress-сервис стал бы доступен по адресу: http://*external-ip*:80

Но когда вы устанавливаете Куб на голое железо, внешний балансировщик отсутствует, поэтому службы не получают EXTERNAL-IP. Это описано в документации к Ingress-nginx (эти красивые картинки стянул оттуда же), а также тут.

Будем использовать первое предложенное в этом документе решение — поставим Metallb, который заменит нам внешний балансировщик. ↑
Установка Metallb
Внесем изменения в configmap:
kubectl edit configmap -n kube-system kube-proxyНужно в mode записать ipvs, a strictARP активировать. Кусок конфигурации должен выглядеть так:
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "ipvs"
ipvs:
strictARP: trueСохраняем и выходим, если сможете конечно, ибо запускается vim. Главное помните, в любой непонятной ситуации вводите:

Добавляем Helm-репозиторий:
helm repo add metallb https://metallb.github.io/metallbСоздаем файл с именем values.yaml и вставляем шаблон:
configInline:
address-pools:
- name: default
protocol: layer2
addresses:
- x.x.x.x/24В поле addresses указываем пул IP-адресов, которые заберёт в своё пользование Metallb. Адреса нужно указать в виде CIDR. В моём пользовании всего две виртуальные машины, поэтому речи о пуле адресов не идёт. Маска подсети для одного-единственного IP-адреса записывается как "/32".
В моем случае конфигурация выглядит так:
configInline:
address-pools:
- name: default
protocol: layer2
addresses:
- 194.87.253.108/32
- 87.247.157.40/32Сохраняем и выходим. Теперь установим helm chart metallb с указанием файла конфигурации:
helm install metallb metallb/metallb -f values.yamlПосле чего запросим сервисы:
kubectl get svc
Если вы всё сделали правильно, то в графе EXTERNAL-IP появится выделенный IP-адрес для этого сервиса. Проверим в браузере:

На этом настройка Куба на голом железе завершена. ↑
Альтернативное решение
К любому из сервисов (с типом LoadBalancer), можно обратиться по NodePort. Например, Ingress-сервис будет доступен по адресу: http://*ip-master-node*:*NodePort*.

Номер NodePort и тип сервиса можно увидеть тут:

Это один из вариантов решения проблемы отсутствия внешнего балансировщика. Описано в той же документации.
Если мы возьмём доменное имя, например, example.com, и свяжем его с IP-адресом master-ноды, то сервис будет доступен по адресу: http://example.com:32128. Выглядит стремновато. Но как вариант, можно поставить на master-ноду nginx и проксировать трафик с порта 80 на порт 32128. И тогда Ingress будет доступен по адресу http://example.com.
Нашел даже интересный проект на Github, который кроме запуска nginx в Docker-контейнере еще и настраивает SSL-сертификаты. Надо лишь указать, на какие доменные имена нужно выпустить сертификаты, и всё остальное он сделает сам. Действительно, ставится буквально одной командой, что очень порадовало.
Но лично у меня с этой схемой начались проблемы, когда я начал разворачивать Kubernetes dashboard и настраивать авторизацию через Keycloak. Поэтому, этот вариант пусть останется в истории.
Настройка CI/CD в GitLab
Выбираем доменное имя для сервиса
Сначала нужно придумать название для своего сервиса и купить доменное имя. Чур, мой сервис будет называться awesomeservice, а доменную зону я выбрал модную и красивую — .tech. Где покупать, в принципе, не имеет значения.
Cвяжем external-ip Ingress-nginx с новым купленным доменным именем. Для этого создайте A-запись (awesomeservice.tech -> 194.87.253.108). Полное обновление DNS-сервера занимает не более трёх часов. После этого Ingress-nginx будет доступен уже по доменному имени.

Естественно архитектура, будет микросервисная, а это значит, что для проекта могут быть развернуты разные приложения со своим API. У нас будет вспомогательный микросервис coolapp. И кряхтеть он будет по адресу http://coolapp.awesomeservice.tech. Причем это production-окружение, которое будет использовать конечный пользователь. Еще понадобятся test- и staging-окружения. В итоге у нас будет развёрнуто сразу несколько приложений с такими поддоменными именами:
http://coolapp.awesomeservice.tech
http://staging.coolapp.awesomeservice.tech
http://qa01.coolapp.awesomeservice.tech
http://qa02.coolapp.awesomeservice.tech
Это значит, надо сделать ещё четыре A-записи для поддоменых имен: coolapp., staging.coolapp., qa01.coolapp., qa02.coolapp.. И да, все эти имена разрешаются на Ingress EXTERNAL-IP. ↑
Создание проекта в GitLab

Создаём пустой проект. В 2к21 ребята из GitLab еще не завезли шаблон для Python-проекта ¯\_(ツ)_/¯.

Создадим вспомогательное приложение coolapp для сервиса awesomeservice. Использовать будем слегка модифицированный микросервис на FastApi из предыдущих статей. Иерархия:
coolapp
├── Dockerfile
├── README.md
├── main.py
└── requirements.txt
Dockerfile
FROM python:3.8
EXPOSE 8080
WORKDIR app
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
COPY . .
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080"]
main.py
from fastapi import FastAPI, Cookie
from typing import Optional
from uuid import uuid4
app = FastAPI()
uuid = uuid4()
@app.get("/api/v1/uuid")
async def root(key: Optional[str] = Cookie(None)):
print(key)
return {'uuid': uuid}
@app.get("/healthz")
async def health_check():
return {}
Ручку /healthz будет использовать Kubernetes для проверки работоспособности поды.
requirements.txt
fastapi==0.63.0
uvicorn==0.13.3
requests==2.26.0
Сборка и запуск приложения:
docker build . -t coolapp
docker run -p 8080:8080 -t coolappПроверяем работу:

Пушим проект в удаленный репозиторий. ↑
Интеграция Kubernetes-кластера
На главной проекта нажимаем кнопку <Add Kubernetes cluster>.

С невозмутимым лицом проходим мимо предложения воспользоваться облачными сервисами GKE, AWS. Переходим во вкладку «Подключить существующий кластер».

В принципе, официальная документация довольно подробно расписывает, как заполнить каждое поле. Но для удобства продублирую инструкцию тут:

Здесь надо заполнить шесть полей:
Kubernetes cluster name
Environment scope
API URL
CA Certificate
Service Token
Project namespace prefix (optional, unique)
Галочки RBAC-enabled cluster, GitLab-managed cluster и Namespace per environment должны быть активны.
Kubernetes cluster name
Просто записываем имя кластера. У меня этоdevkube.
Environment scope
Оставляем *.
API URL
В консоли выполните:
kubectl cluster-info | grep -E 'Kubernetes master|Kubernetes control plane' | awk '/http/ {print $NF}'
Копируем вывод из консоли и вставляем.
CA Certificate
Выполните команду:
kubectl get secretsНайдите название секрета, который начинается на default-token-xxxxx.

Вставьте это название секрета в следующую команду вместо secret name.
kubectl get secret "secret name" -o jsonpath="{['data']['ca\.crt']}" | base64 --decode
Скопируйте весь вывод консоли в поле CA Certificate.
Service Token
Создайте файл gitlab-admin-service-account.yaml и вставьте:
apiVersion: v1
kind: ServiceAccount
metadata:
name: gitlab
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: gitlab-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: gitlab
namespace: kube-system
Выполните в той же папке с файлом:
kubectl apply -f gitlab-admin-service-account.yamlПосле создания ресурсов выполните:
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep gitlab | awk '{print $1}')
Скопируйте токен и вставьте в поле Service Token.
Project namespace
Введите префикс вашего пространства имён проекта. Пространство имен проекта будет составлено из двух частей: префикса и имени окружения. Если не вписать, то GitLab сам сгенерирует некрасивое название с циферками. У меня это coolapp-devkube. Префикс должен быть уникальным для каждого проекта.
Заполняем все поля и сохраняем. В итоге должно выглядеть примерно так:

После добавления кластера сразу будут показаны его настройки. В окне <Base domain> введите базовый адрес кластера. В моем случае это awesomeservice.tech.

Теперь активируем Auto Devops. На главной проекта нажмите кнопку <Enable Auto Devops>.

Откроются настройки проекта, где нужно тыкнуть галочку <Default to Auto DevOps pipeline> и выбрать стратегию развертывания приложения. Я выбрал третий вариант, с предварительным деплоем в staging-среде, после которой будет доступна постепенная (ступенчатая) выкатка в production-среду. Подробнее о стратегиях выкатки можно почитать тут.

Начиная с этого момента для проекта активен Auto Devops. ↑
Настройка GitLab AutoDevops
Краткий обзор Auto Devops:
Auto DevOps покрывает весь цикл поставки: Просто сделайте коммит вашего кода в GitLab и позвольте Auto DevOps заняться остальным: эта система проведет сборку, тестирование, проверку качества кода, безопасности и лицензий, пакетирование, тестирование производительности, развертывание и мониторинг вашего приложения.
Звучит так классно, что даже утопично... Вам так не кажется?
Да. Вам не кажется.

После активации AutoDevops в master main-ветке сразу же запустится конвейер.

И конечно же, он зафейлится, разве могло быть иначе?

Сборка прошла успешно, что уже радует. В блоке тестирования прошли такие этапы, как проверка лицензии, качества кода и т.д. В общем, прошло всё то, что на этом этапе нас мало интересует. В итоге конвейер завершил работу на тестировании.

Быстрое гугление показало, что это проблема для всех питонистов: тестирование Python-проектов из коробки работать не будет. Но мы этап тестирования опустим, потому что наша цель — настроить автоматизированную поставку приложений. Выключать стадии можно несколькими способами.
1) Например, с помощью создания специальных переменных окружения в настройках проекта. Для этого перейдите в Settings -> CI/CD -> Variables и создайте переменную окружения TEST_DISABLED=true.
После этого нужно обязательно создать новый pipeline, текущий все равно будет запускать test.

Мы пропустили test, но ошибка возникла на этапе развертывания приложения в среду review (это аналог общепринятого окружения dev). Gitlab ожидает, что приложение отвечает по порту 5000, у нас же рабочий порт 8080. Можем, конечно, изменить на 5000, но так неинтересно. Хочется иметь возможность задавать порт самому. Решим эту проблему чуть позже.
2) Auto DevOps полностью изменяем, он работает по шаблону, который, по сути, является реализацией.gitlab-ci.yml.Мы можем в проекте определить свой .gitlab-ci.yml и добавить свои этапы, или переопределить стандартные из AutoDevops. Пойдём по второму пути.
Создадим ветку feature/autodevops(pipeline запустится автоматом).

Обратите внимание, что в ветке всё равно будет этап test, потому что я создал переменную среды TETEST_DISABLED как protect variable. Переменные такого типа доступны только в protected ветках, коей main и является.
Теперь переопределим стандартный шаблон AutoDevops. Мы оставим почти все стадии, уберём только test, deploy (это заглушка и так), dast и performance. Создайте файл .gitlab-ci.yml и вставьте следующие инструкции:
variables:
ROLLOUT_RESOURCE_TYPE: deployment # без этого деплой фейлится
stages:
- build
- review
- staging
- canary
- production
- incremental rollout 10%
- incremental rollout 25%
- incremental rollout 50%
- incremental rollout 100%
- cleanup
include:
- template: Jobs/Build.gitlab-ci.yml
- template: Jobs/Deploy.gitlab-ci.yml
В stages перечислены все стадии, которые будут выполняться, их реализация находится в подтягиваемых нами шаблонах (include). Например, шаблон деплоя, в котором описаны все стадии начиная с review до cleanup. Там же можно заметить, что review и cleanup выполняются только в ветках, а остальные — в main-ветке, это логично.
Если сейчас запушить, то будет ошибка во время деплоя, потому что GitLab ожидает приложение на порту 5000. Разумеется, и тут мы не ограничены и можем указать нестандартный порт. GitLab деплоит приложение с помощью Helm-чарта, настройки которого можно переопределить у себя в проекте. Для этого нужно создать папку .gitlab и файл auto-deploy-values.yaml. Чтобы приложение успешно развернулось, достаточно переопределить service.internalPort, service.externalPort и обязательно указать наш кастомный health check в разделе livenessProbe и readinessProbe. Также я явно указал, что TLS выключен, настройка сертификатов — это отдельная тема. Если этого не сделать, то, например, Postman будет ругаться на сертификат (через браузер же всё норм).
service:
internalPort: 8080
externalPort: 8080
livenessProbe:
path: /healthz
readinessProbe:
path: /healthz
ingress:
enabled: true
tls:
enabled: falseИерархия проекта такая (меняться больше не будет):
coolapp
├── .gitlab
│ └── auto-deploy-values.yaml
├── .gitlab-ci.yml
├── Dockerfile
├── README.md
├── main.py
└── requirements.txtЗапушим изменения и посмотрим результат выполнения конвейера.

Конвейер успешно завершил работу, но не спешите радоваться, это ещё не всё. Зайдём и проверим, что и куда задеплоилось.

Детализация стадии review показывает, что сервис успешно развёрнут по адресу с интересным поддоменом 29857899-review-feature-cu-jfvpge. Естественно, этот URL нерабочий, мы же не делали A-запись для такого поддомена.

Дело в том, что для каждой ветки GitLab (согласно шаблону AutoDevops) генерирует уникальный URL и разворачивает под ним сервис. Именно такая система была на моем прошлом месте работы, это довольно удобно, когда можно для своей ветки раскатить сервис и тестировать его изолированно. Но годится это для больших компаний и проектов. К тому же, чтобы это заработало нужно для домена awesomeservice.tech уметь настраивать автоподдомены. Для текущей статьи и в целом для небольшого проекта это излишняя фича, поэтому для веток мы сделаем два окружения: qa01 и qa02. Почему именно два?

Начнем с того, что выключим стадии review и cleanup. Так как создаётся отдельный сервис для каждой ветки, ресурсы начинаются быстро плодиться и их надо чистить; для этого существует cleanup — она удаляет все созданные ресурсы, связанные с этой веткой. Просто взять и удалить review и cleanup из stages не получится. Если мы используем шаблон, то все описанные там стадии должны быть указаны в блоке stages нашего gitlab-ci.yml. Но стадии можно выключить, как я уже упоминал ранее, с помощью специальных переменных окружения. Переменная REVIEW_DISABLED отключает сразу обе стадии, это видно в реализации оных в шаблоне Jobs/Deploy.gitlab-ci.yml. Заодно включим стадию canary (она по умолчанию выключена), это нам понадобится для конвейера в main-ветке.
variables:
ROLLOUT_RESOURCE_TYPE: deployment
REVIEW_DISABLED: "true"
CANARY_ENABLED: "true"
stages:
- build
- review # off stage
- staging
- canary
- production
- incremental rollout 10%
- incremental rollout 25%
- incremental rollout 50%
- incremental rollout 100%
- cleanup # off stage
include:
- template: Jobs/Build.gitlab-ci.yml
- template: Jobs/Deploy.gitlab-ci.yml
После выключения этапа review создадим свою стадию с именем qa. За основу возьмем стадию staging из того же стандартного шаблона. Вот так она выглядит:
staging:
extends: .auto-deploy
stage: staging
script:
- auto-deploy check_kube_domain
- auto-deploy download_chart
- auto-deploy ensure_namespace
- auto-deploy initialize_tiller
- auto-deploy create_secret
- auto-deploy deploy
environment:
name: staging
url: http://$CI_PROJECT_PATH_SLUG-staging.$KUBE_INGRESS_BASE_DOMAIN
rules:
- if: '$CI_KUBERNETES_ACTIVE == null || $CI_KUBERNETES_ACTIVE == ""'
when: never
- if: '$CI_COMMIT_BRANCH != $CI_DEFAULT_BRANCH'
when: never
- if: '$STAGING_ENABLED'
Нужно будет сделать небольшие правочки в блоках stage, environment и rules, а вот script останется нетронутым. Всё довольно просто: в stage записывается имя стадии, в environment.url указывается путь, под которым будет развёрнуто приложение (эта строчка просто пробрасывается в Ingress в spec.rules.host — кто знает, тот знает). В этом URL можно заметить странный префикс $CI_PROJECT_PATH_SLUG, если его оставить, то приложение развернётся с путем http://mopckou-coolapp-staging.awesomeservice.tech.
Выглядит стрёмно, поэтому для окружения qa01 и qa02 избавимся от этого префикса. И наконец, добавим ручной выбор, в какое окружение деплоить приложения в блоке rules. Вот так выглядят новенькие стадии qa01 и qa02:
qa01:
extends: .auto-deploy
stage: qa
script:
- auto-deploy check_kube_domain
- auto-deploy download_chart
- auto-deploy ensure_namespace
- auto-deploy initialize_tiller
- auto-deploy create_secret
- auto-deploy deploy
environment:
name: qa01
url: http://qa01.coolapp.$KUBE_INGRESS_BASE_DOMAIN # убрал префикс $CI_PROJECT_PATH_SLUG-
rules:
- if: '$CI_KUBERNETES_ACTIVE == null || $CI_KUBERNETES_ACTIVE == ""'
when: never # не трогаем
- if: '$CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH'
when: never # эта стадия не запускается если ветка называется main (default branch)
- if: '$CI_COMMIT_TAG || $CI_COMMIT_BRANCH'
when: manual # для ручного выбора куда деплоить
qa02: # копирка предыдущего блока, просто заменил qa01 на qa02
extends: .auto-deploy
stage: qa
script:
- auto-deploy check_kube_domain
- auto-deploy download_chart
- auto-deploy ensure_namespace
- auto-deploy initialize_tiller
- auto-deploy create_secret
- auto-deploy deploy
environment:
name: qa02
url: http://qa02.coolapp.$KUBE_INGRESS_BASE_DOMAIN
rules:
- if: '$CI_KUBERNETES_ACTIVE == null || $CI_KUBERNETES_ACTIVE == ""'
when: never
- if: '$CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH'
when: never
- if: '$CI_COMMIT_TAG || $CI_COMMIT_BRANCH'
when: manualЭти стадии можно сделать более читаемыми с помощью якорей. Следующая запись полностью эквивалентна предыдущей:
.qa_env_setup: &qa_setup
extends: .auto-deploy
stage: qa
script:
- auto-deploy check_kube_domain
- auto-deploy download_chart
- auto-deploy ensure_namespace
- auto-deploy initialize_tiller
- auto-deploy create_secret
- auto-deploy deploy
rules:
- if: '$CI_KUBERNETES_ACTIVE == null || $CI_KUBERNETES_ACTIVE == ""'
when: never
- if: '$CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH'
when: never
- if: '$CI_COMMIT_TAG || $CI_COMMIT_BRANCH'
when: manual
qa01:
<<: *qa_setup
environment:
name: qa01
url: http://qa01.coolapp.$KUBE_INGRESS_BASE_DOMAIN
qa02:
<<: *qa_setup
environment:
name: qa02
url: http://qa02.coolapp.$KUBE_INGRESS_BASE_DOMAINА для остальных этапов (staging, canary, production) придется так же переопредилить URL, чтобы избавиться от некрасивого префикса.
staging:
extends: .auto-deploy
environment:
name: staging
url: http://staging.coolapp.$KUBE_INGRESS_BASE_DOMAIN
.url: &production_url
environment:
name: production
url: http://coolapp.$KUBE_INGRESS_BASE_DOMAIN
production_manual:
extends: .auto-deploy
<<: *production_url
production:
extends: .auto-deploy
<<: *production_url
canary:
extends: .auto-deploy
<<: *production_url
timed rollout 10%:
extends: .auto-deploy
<<: *production_url
timed rollout 25%:
extends: .auto-deploy
<<: *production_url
timed rollout 50%:
extends: .auto-deploy
<<: *production_url
timed rollout 100%:
extends: .auto-deploy
<<: *production_url
rollout 10%:
extends: .auto-deploy
<<: *production_url
rollout 25%:
extends: .auto-deploy
<<: *production_url
rollout 50%:
extends: .auto-deploy
<<: *production_url
rollout 100%:
extends: .auto-deploy
<<: *production_url
Полный gitlab-ci.yml
variables:
ROLLOUT_RESOURCE_TYPE: deployment # без этого деплой фейлится
REVIEW_DISABLED: "true"
CANARY_ENABLED: "true"
stages:
- build
- review # off stage
- qa
- staging
- canary
- production
- incremental rollout 10%
- incremental rollout 25%
- incremental rollout 50%
- incremental rollout 100%
- cleanup # off stage
.qa_env_setup: &qa_setup
extends: .auto-deploy
stage: qa
script:
- auto-deploy check_kube_domain
- auto-deploy download_chart
- auto-deploy ensure_namespace
- auto-deploy initialize_tiller
- auto-deploy create_secret
- auto-deploy deploy
rules:
- if: '$CI_KUBERNETES_ACTIVE == null || $CI_KUBERNETES_ACTIVE == ""'
when: never
- if: '$CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH'
when: never
- if: '$CI_COMMIT_TAG || $CI_COMMIT_BRANCH'
when: manual
.production_env_setup: &production_url
environment:
name: production
url: http://coolapp.$KUBE_INGRESS_BASE_DOMAIN
qa01:
<<: *qa_setup
environment:
name: qa01
url: http://qa01.coolapp.$KUBE_INGRESS_BASE_DOMAIN
qa02:
<<: *qa_setup
environment:
name: qa02
url: http://qa02.coolapp.$KUBE_INGRESS_BASE_DOMAIN
staging:
extends: .auto-deploy
environment:
name: staging
url: http://staging.coolapp.$KUBE_INGRESS_BASE_DOMAIN
production_manual:
extends: .auto-deploy
<<: *production_url
production:
extends: .auto-deploy
<<: *production_url
canary:
extends: .auto-deploy
<<: *production_url
timed rollout 10%:
extends: .auto-deploy
<<: *production_url
timed rollout 25%:
extends: .auto-deploy
<<: *production_url
timed rollout 50%:
extends: .auto-deploy
<<: *production_url
timed rollout 100%:
extends: .auto-deploy
<<: *production_url
rollout 10%:
extends: .auto-deploy
<<: *production_url
rollout 25%:
extends: .auto-deploy
<<: *production_url
rollout 50%:
extends: .auto-deploy
<<: *production_url
rollout 100%:
extends: .auto-deploy
<<: *production_url
include:
- template: Jobs/Build.gitlab-ci.yml
- template: Jobs/Deploy.gitlab-ci.yml
Пушим изменения и наблюдаем за новеньким конвейером:
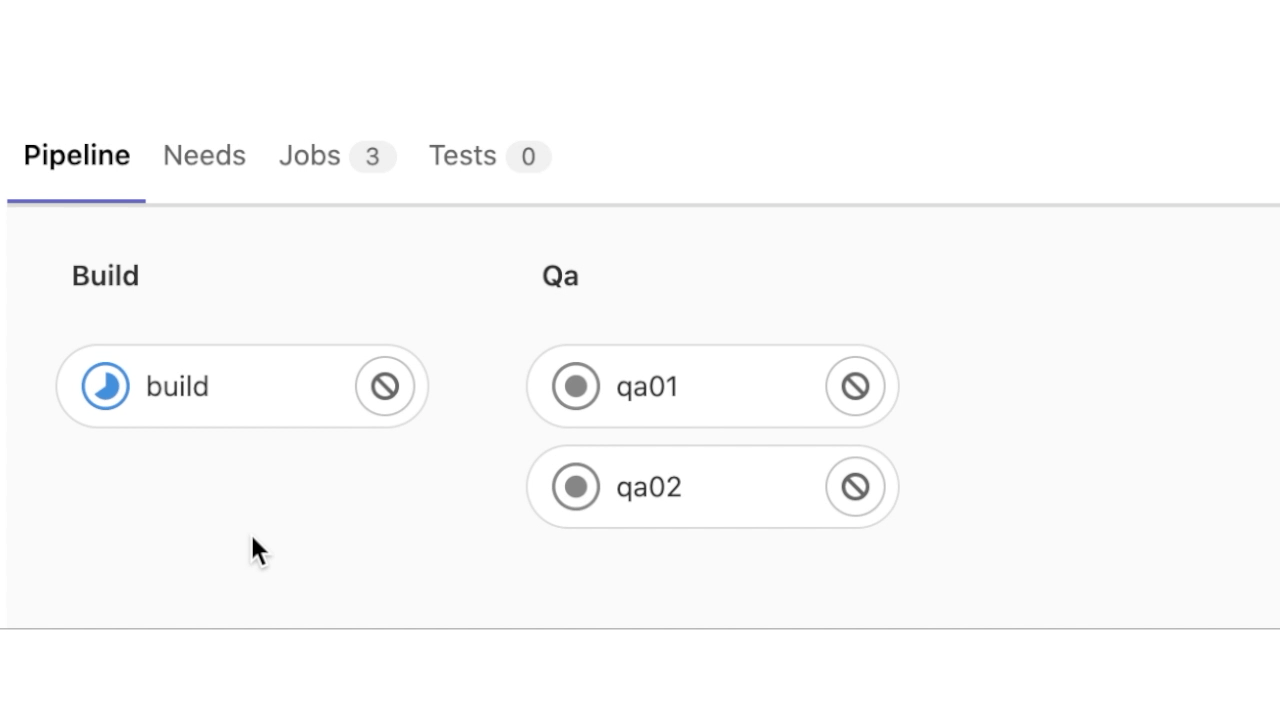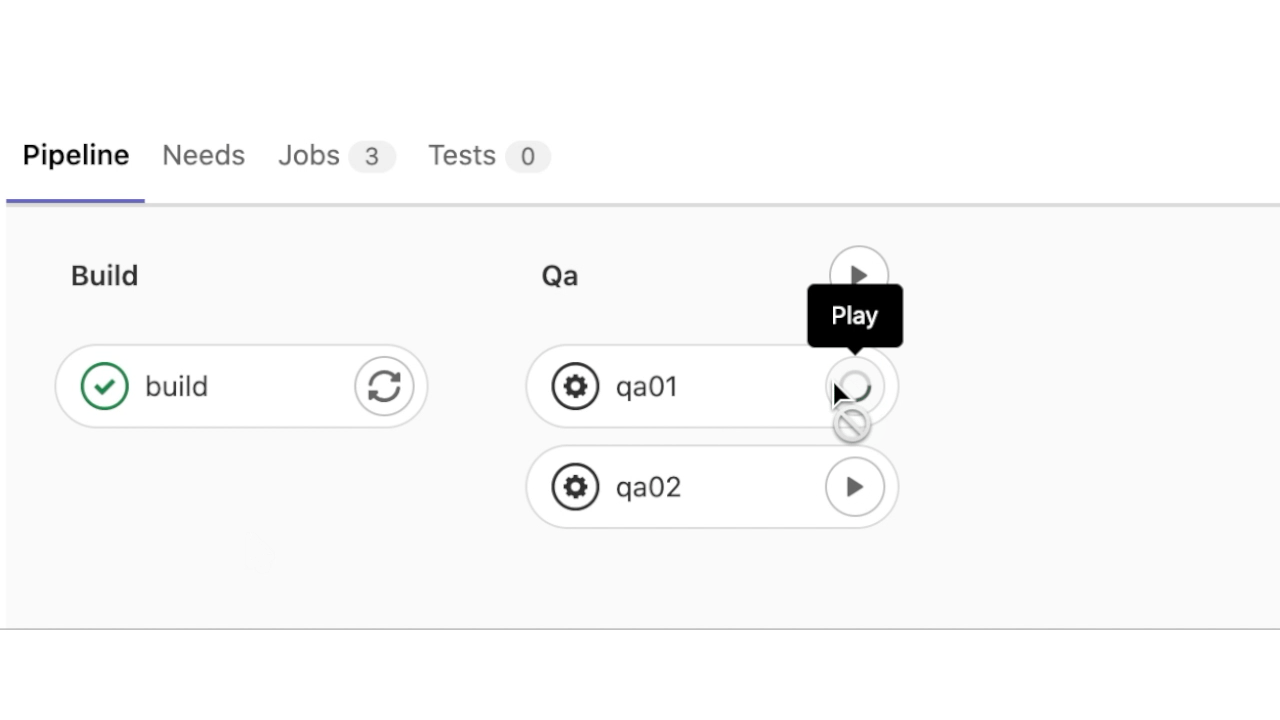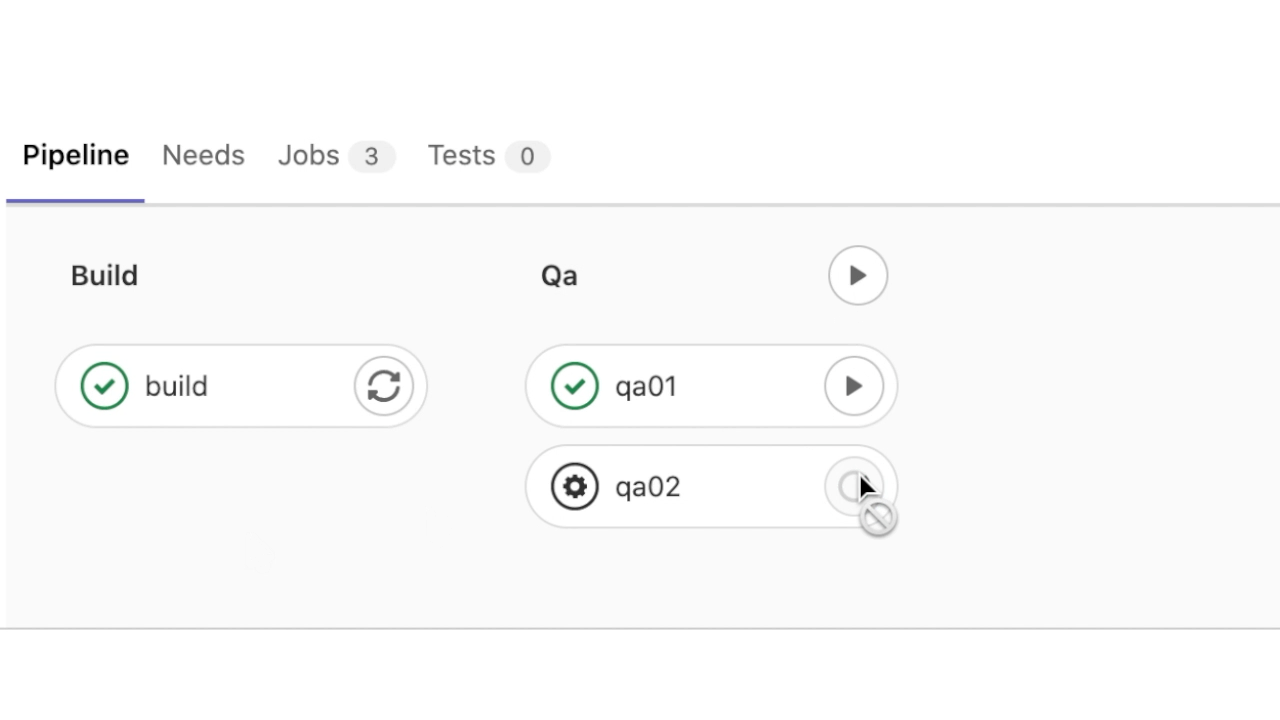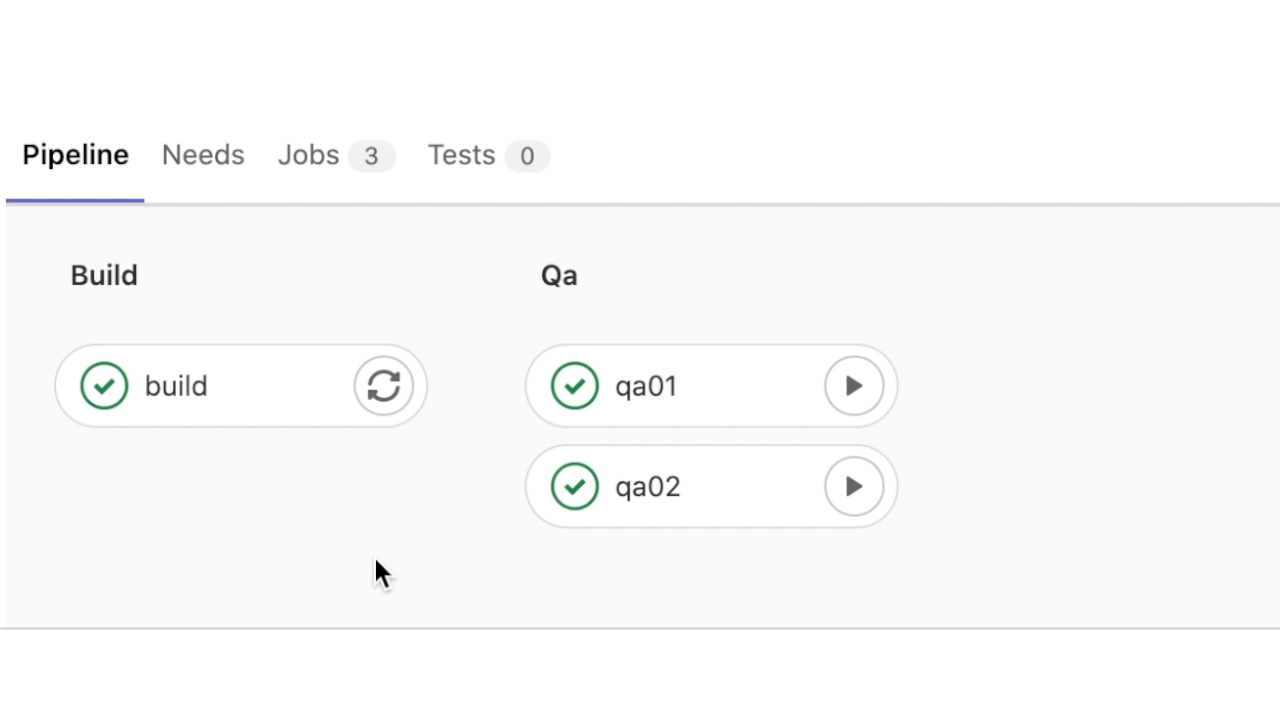
Приложение успешно развёрнуто в окружении qa01 и qa02. Посмотрим теперь детализацию этапа qa01:

Приложение развёрнуто с поддоменом qa01.coolapp. Проверим работу:

Приложение отвечает и отдает uuid по запросу. Chrome ругается на незащищенное HTTP-соединение, но настройка сертификатов выходит за рамки этой статьи.
В GitLab есть удобная борда для мониторинга под в каждом окружении. Перейдите в Deployments → Environments.

Но в данный момент она не работает. Панель включается только когда у каждой поды есть аннотация: app.gitlab.com/app=$CI_PROJECT_PATH_SLUG и app.gitlab.com/env=$CI_ENVIRONMENT_SLUG. Ребята из GitLab позаботились о нас и в Helm-чарте пробрасывают аннотацию подам, нам надо лишь переопределить эти параметры. Есть специальная переменная окруженияHELM_UPGRADE_EXTRA_ARGS, с помощью которой можно переопределить любой параметр из Helm-чарта.
Эту переменную я указал в gitlab-ci.yaml проекта в блоке variables, чтобы все переменные окружения были в одном месте. Но, конечно, все их можно указать на сайте в настройках вашего проекта в GitLab.
HELM_UPGRADE_EXTRA_ARGS: "--set gitlab.env=$CI_ENVIRONMENT_SLUG,gitlab.app=$CI_PROJECT_PATH_SLUG"
Теперь уже точно полный gitlab-ci.yaml. Честно-честно!
variables:
ROLLOUT_RESOURCE_TYPE: deployment
REVIEW_DISABLED: "true"
CANARY_ENABLED: "true"
HELM_UPGRADE_EXTRA_ARGS: "--set gitlab.env=$CI_ENVIRONMENT_SLUG,gitlab.app=$CI_PROJECT_PATH_SLUG"
stages:
- build
- review # off stage
- qa
- staging
- canary
- production
- incremental rollout 10%
- incremental rollout 25%
- incremental rollout 50%
- incremental rollout 100%
- cleanup # off stage
.qa_env_setup: &qa_setup
extends: .auto-deploy
stage: qa
script:
- auto-deploy check_kube_domain
- auto-deploy download_chart
- auto-deploy ensure_namespace
- auto-deploy initialize_tiller
- auto-deploy create_secret
- auto-deploy deploy
rules:
- if: '$CI_KUBERNETES_ACTIVE == null || $CI_KUBERNETES_ACTIVE == ""'
when: never
- if: '$CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH'
when: never
- if: '$CI_COMMIT_TAG || $CI_COMMIT_BRANCH'
when: manual
.production_env_setup: &production_url
environment:
name: production
url: http://coolapp.$KUBE_INGRESS_BASE_DOMAIN
qa01:
<<: *qa_setup
environment:
name: qa01
url: http://qa01.coolapp.$KUBE_INGRESS_BASE_DOMAIN
qa02:
<<: *qa_setup
environment:
name: qa02
url: http://qa02.coolapp.$KUBE_INGRESS_BASE_DOMAIN
staging:
extends: .auto-deploy
environment:
name: staging
url: http://staging.coolapp.$KUBE_INGRESS_BASE_DOMAIN
production_manual:
extends: .auto-deploy
<<: *production_url
production:
extends: .auto-deploy
<<: *production_url
canary:
extends: .auto-deploy
<<: *production_url
timed rollout 10%:
extends: .auto-deploy
<<: *production_url
timed rollout 25%:
extends: .auto-deploy
<<: *production_url
timed rollout 50%:
extends: .auto-deploy
<<: *production_url
timed rollout 100%:
extends: .auto-deploy
<<: *production_url
rollout 10%:
extends: .auto-deploy
<<: *production_url
rollout 25%:
extends: .auto-deploy
<<: *production_url
rollout 50%:
extends: .auto-deploy
<<: *production_url
rollout 100%:
extends: .auto-deploy
<<: *production_url
include:
- template: Jobs/Build.gitlab-ci.yml
- template: Jobs/Deploy.gitlab-ci.yml
Пушим изменения, деплоим в qa01 и qa02 и бежим в Deployments → Environments.

Появилась доска с информацией, сколько под развёрнуто и в каком окружении. Эти зеленые квадратики, кстати, кликабельные, так можно сразу провалиться к логам поды, они транслируются в режиме онлайн.
С тестовым окружением мы закончили, теперь сливаем ветку в master main. И наблюдаем за красивым пайпланчиком в главной ветке:
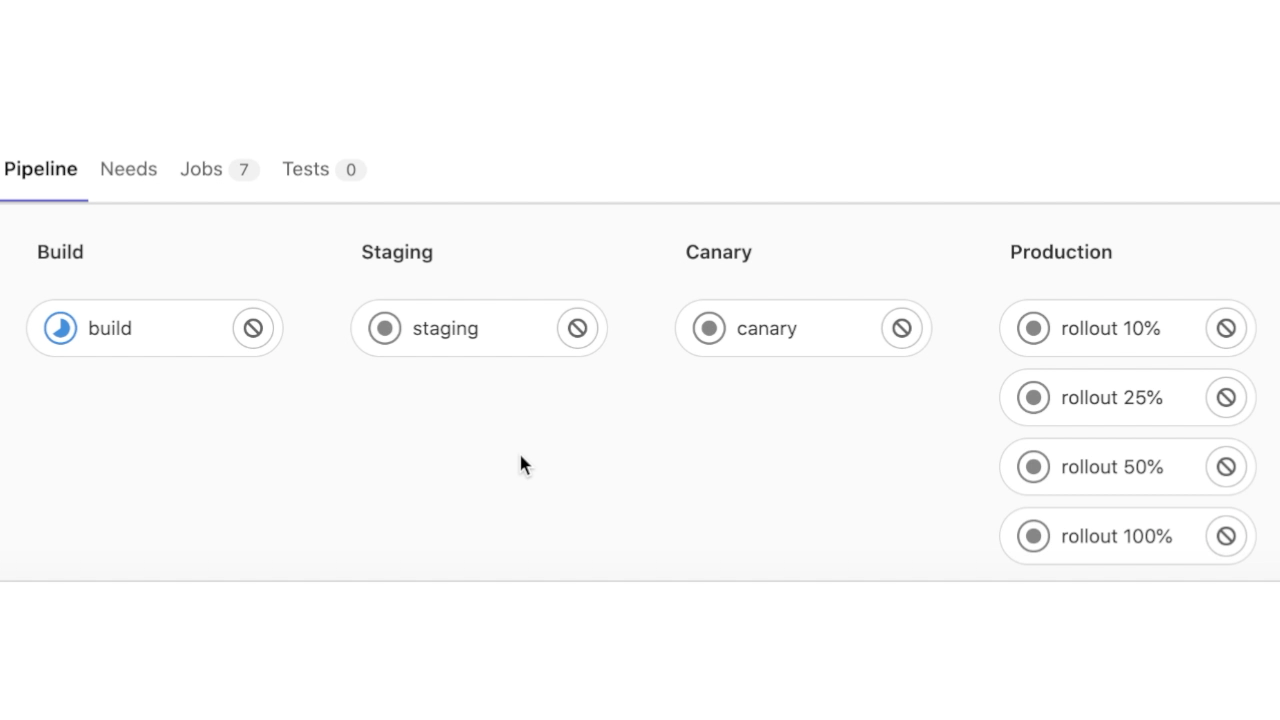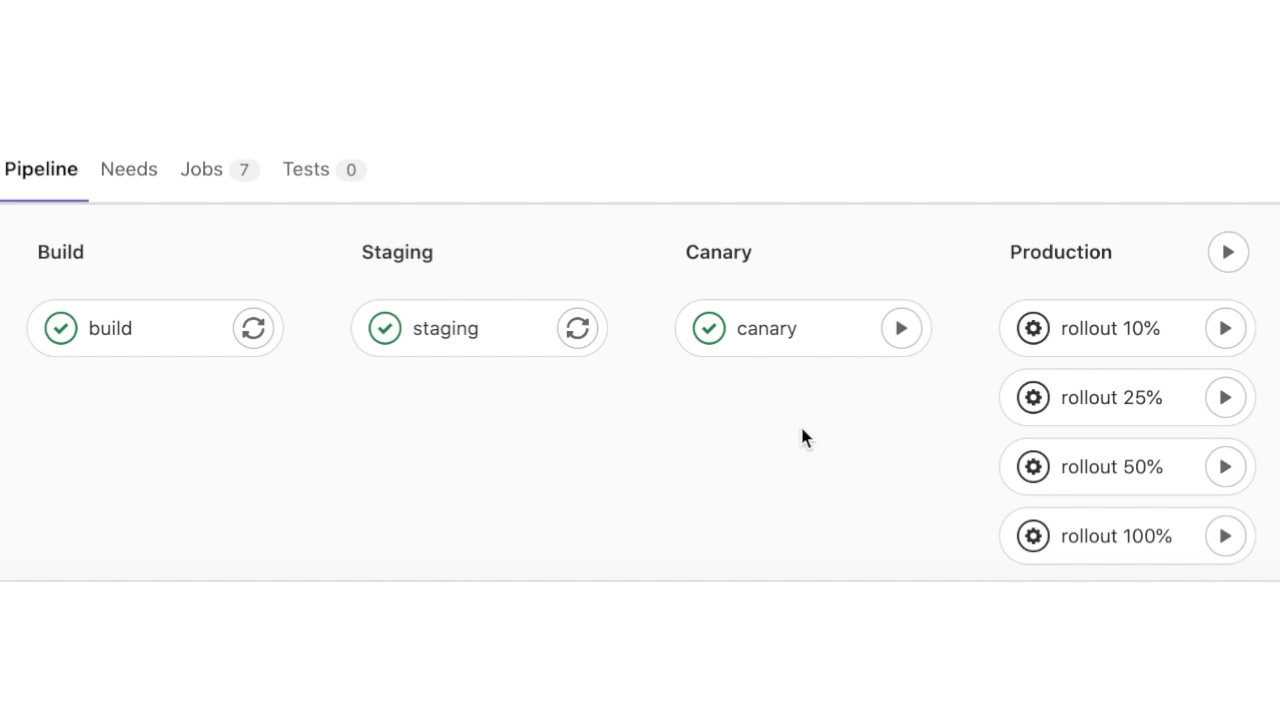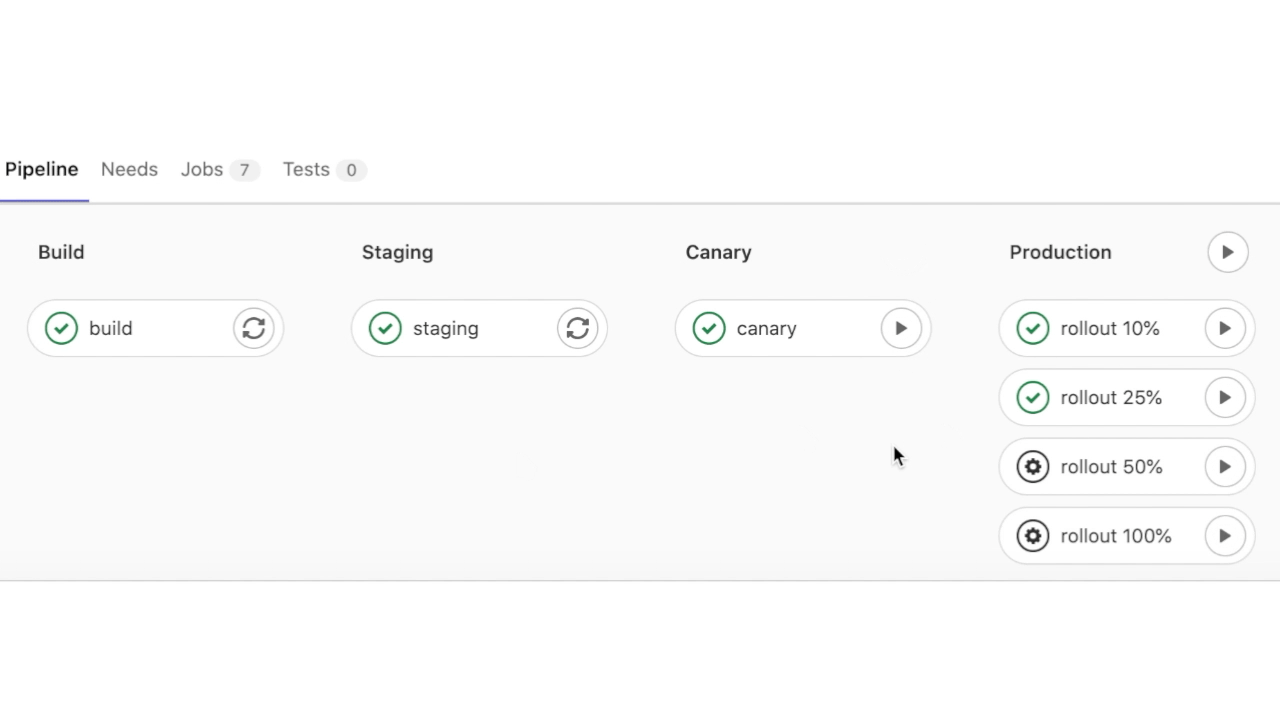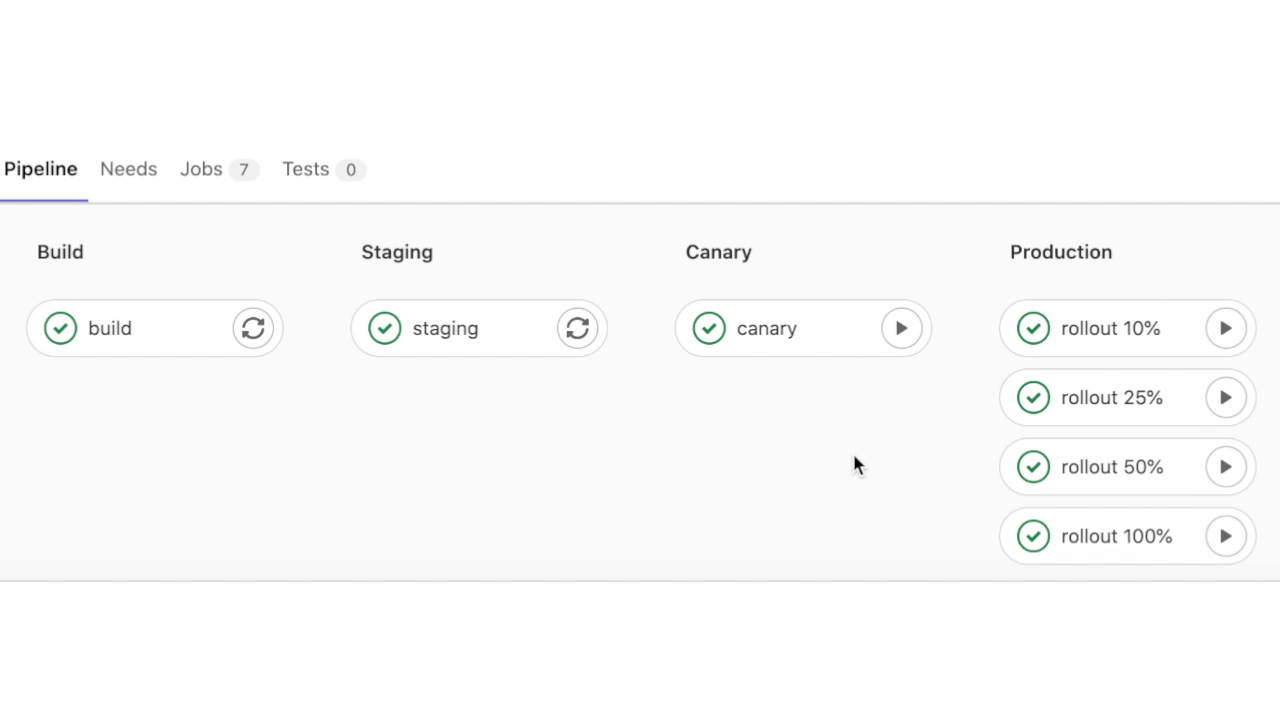

Приложение доступно по адресу:
http://staging.coolapp.awesomeservice.tech/api/v1/uuid — для staging-окружения

http://coolapp.awesomeservice.tech/api/v1/uuid — для prod-окружения

Масштабировать приложение очень просто. В переменных окружения проекта (Settings → CI/CD → Variables) создайте переменную PRODUCTION_REPLICAS с желаемым количеством под.

И запустите Re-deploy в панели:

Приложение успешно расплодилось до пяти под.

По идее, на этой замечательной ноте можно бы закругляться. Но на десерт давайте всё-таки разберёмся, как работает канареечный деплой. ↑
Разбираем канареечный деплой на практике
Суть канареечного деплоя в том, что мы направляем часть продуктового трафика на новую версию приложения (какую часть в процентах, мы выбираем сами). Наблюдаем, как ведёт себя новое приложение; если нет ошибок, то перебрасываем весь трафик на новую версию; если всё плохо, то просто откатываемся на предыдущую стабильную версию.
Достоинство: в случае ошибки страдает только небольшая часть пользователей, а не все, как при классическом деплое. Недостаток: надо понимать, что запрос от одного пользователя может попасть случайно как на стабильную версию, так и на новую канареечную. Это может привести к путанице и, возможно, к некоторым ошибкам. По идее, это можно решить настройкой sessionAffinity для Kubernetes services.
Продемонстрирую на практике. Изменим код приложения, чтобы по его ответу сразу было понятно, что это новая версия. Добавим в ответ ручки /api/v1/uuid ещё один ключ time:
from time import ctime
from fastapi import FastAPI, Cookie
from typing import Optional
from uuid import uuid4
app = FastAPI()
uuid = uuid4()
@app.get("/api/v1/uuid")
async def root(key: Optional[str] = Cookie(None)):
print(key)
return {
'uuid': uuid,
'time': ctime()
}
@app.get("/healthz")
async def health_check():
return {}
Пушим изменение и ждём, пока отработает deploy в staging-окружении:

Как только вы запустите canary stage, в том же пространстве имён запустится такое же количество под с новой версией приложения. В названии под есть специальный префикс -canary-:

Пока что весь трафик на старой версии приложения. Как только вы нажмете на конвейере на этап с процентом, то выбранная доля трафика станет поступать на канареечные поды.

Теперь взглянем на панель окружений.

Видно, что прибавилось ещё пять под с жёлтым кружочком, это обозначение канареечной поды. На панели можно менять соотношение трафика в любую сторону, и даже пустить весь поток на новую версию приложения.

В конвейере долю трафика можно менять как в большую сторону, так и в меньшую. Но как только вы нажмете на 100 %, весь трафик перейдёт на канареечные поды, в это время будут созданы поды с новой версией микросервиса и старое приложение начнёт удаляться.

Как только все новые будут запущены, а трафик на них переключится, канареечные поды начнут удаляться.

На этом процесc деплоя на новую версию закончен. ↑

TL;DR
1. Установите кластер на голое железо.
2. Купите доменное имя (подробнее тут), у меня это
awesomeservice.tech. И зарегистрируйте четыре поддомена:coolapp.,staging.coolapp.,qa01.coolapp,qa02.coolapp. В моем случае:- coolapp.awesomeservice.tech
- staging.coolapp.awesomeservice.tech
- qa01.coolapp.awesomeservice.tech
- qa02.coolapp.awesomeservice.tech
Поддоменные имена легко меняются в gitlab-ci.yaml (см. следующий пункт).
3. Форкните готовый шаблон проекта на Python. Там уже есть настроенный gitlab-ci.yaml.
4. Подключите свой кластер Куба к проекту в GitLab. После чего в настройках укажите
base domain. У меня этоawesomeservice.tech.5. Активируйте в проекте AutoDevops.
Создайте конвейер и наслаждайтесь:


В итоге мы создали свой небольшой Kubernetes кластер, состоящий из двух нод, и всё это на голом железе. И что важно — настроили в GitLab автодеплой приложения. На этой прекрасной ноте можно заканчивать.
Релизные практики. Best practice
Пссс... парень

Комментарии (27)

iliadmitriev
15.10.2021 16:04-2Прекрасная статья. Спасибо автору.
Но есть ошибка. 2к21 это 2210 год.
К - кило означает тысяча (10^3)
2.21 * 10^3 = 2210

Mopckou Автор
15.10.2021 16:15Как вы правильно заметили К - тысяча. А значит 2к21 и говорится как - две тысячи двадцать один С:
iliadmitriev
15.10.2021 16:29альтернативная форма записи:
22102.21 * 10^3
2k21
2.21k
2.21e3
https://zone.ni.com/reference/en-XX/help/375482B-01/multisim/acceptableunitletters/


AlexGluck
16.10.2021 03:12+1Можно на гитлабе сэкономить если разместить в кубере оператор ранеров и скалировать их, а тариф использовать бесплатный. Функционал сохранится, цена упадёт.
В качестве полу-спортивной экономии, при увеличении нагрузки, можно взять пару серваков в хетцнере, мощи там будет за глаза.

antonguzun
17.10.2021 01:55Спасибо за статью.
Как только нод становится больше одной - возникает проблема агрегации логов. Какие могут быть легковесные решения без использования elk стека?Mopckou Автор
17.10.2021 02:06Вообще это хороший вопрос, пока у меня нет ответа на него). Действительно я пытался запустить elk на этом кластере, но он очень ресурсоемкий. Возможно когда нибудь придется решать эту проблему)
tabtre
17.10.2021 01:55Кластер решил делать минимальный, состоящий из двух узлов — master и worker.
А можно пояснить что означает это раздение на master и worker? На один узел идет деплой на другом билд?Mopckou Автор
17.10.2021 02:04Мастер нода отводится чисто для обслуживания и поддержки кластера, тут не запускаются ресурсы пользователя. А вот воркер ноды обслуживают чисто клиента, в том числе и билды (если gitlab runner развернуть).
AlexGluck
17.10.2021 13:03-1Ещё вы могли использовать k3s, тогда хватило бы одного узла. А в случае расширения, можно было бы добавить новых узлов.

vesper-bot
18.10.2021 10:31Оно и k8s можно развернуть на одном узле (minikube в частности). Имхо в случае всего двух нод можно обойтись без выделенного мастера, разве что там памяти мало, тогда лучше развести во избежание конкуренции за память и вызова OOMKiller'a. Ну и k8s расширяться тоже неплохо умеет.
tabtre
18.10.2021 17:17То бишь worker только нужен что бы выкатываться на мастер ноду? Тогда не избыточно ли такая конфигурация для этой ноды? там же она часто работает
Mopckou Автор
18.10.2021 22:19Выкатывают приложение (или все пользовательские ресурсы) только на worker ноды.
Например тут хорошо расписано:Главный узел - это узел, который контролирует и управляет набором рабочих узлов. На мастер узле работают следующие процессы:
1. Kube-APIServer - Вся внешняя связь с кластером осуществляется через API-сервер.
2. Kube-Controller-Manager - контроллер-менеджер реализует управление в кластере.
3. Etcd - база данных состояний кластера.
4. Kube Scheduler - планирует действия для рабочих узлов на основе событий, происходящих в etcd.
Это все запускается только на мастер ноде и нужно для управления всем кластером.
Пример: есть кластер, он состоит из одной мастер ноды ив двух воркер нод. Если выйдет из строя мастер нода, то все до свидания кластеру и нашим сервисам. А вот если выйдет из строя воркер нода, то куб это заметит, и все пользовательские ресурсы перезапустит на второй рабочей ноде, таким образом будет небольшой простой в работе сервиса. Для надежности делают резервную мастер ноду - если вдруг выходит из строя главная, то резервная мастер нода перехватывает управление кластером на себя. Такие кластеры уже называют High-Availability cluster, HA cluster.
Или вот с офф сайта:
Мастер Kubernetes отвечает за поддержание желаемого состояния для вашего кластера. Когда вы взаимодействуете с Kubernetes, например, используя интерфейс командной строки
kubectl, вы работаете с мастером Kubernetes вашего кластера.Под "мастером" понимается совокупность процессов, которые управляют состоянием кластера. Обычно все эти процессы выполняются на одном узле кластера, и поэтому этот узел называется главным (master). Мастер также может быть реплицирован для доступности и резервирования.
vesper-bot
19.10.2021 09:25ЕМНИП воркер-ноды могут совпадать с мастер-нодами, но так делать не рекомендуется. Проблема просто в количестве процессов, но строгой необходимости разнести мастер и воркер не вижу.
tabtre
19.10.2021 21:08Спасибо за разъяснение. Стало понятно, кто чем занимается)
Осталось небольшое сомнение, что для мастер ноды нужен такой же по производительности VPS как для worker, но нигде данных по этому поводу не смог найти
F1RST
20.10.2021 05:40+1Да, Вы правы, для master не нужна такая производительность как для woker. Минимальные требования: 2 CPU, 2Gb RAM.
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
Mopckou Автор
21.10.2021 14:53Да, как правильно заметил @F1RST для мастера минимальные - 2 CPU, 2Gb RAM. А воркер нода может быть вообще любой. Хоть 1 CPU и 1GB RAM, но логично делать, конечно, рабочие машины производительными.
А можно сделать мощную мастер ноду, включить специальную настроечку в кубе, и тогда все рабочие нагрузки будут запускаться на мастер ноде, про это выше упомянул @vesper-bot.
vesper-bot
Зеленый деплой. Два раза ку.
PS: имхо многовато мемов, местами мешаются. Но расписано хорошо.
zelig81
Да - расписано очень хорошо.
Только у меня вопрос, а почему не GitHub Actions или Argo Workflows + Argo CD + Argo Rollouts? C точки зрения цены - это все бесплатно, но уже не так лампово, это да...
Mopckou Автор
Выбрал гитлаб я по нескольким причинам:
1. Все собрано в одном месте и не нужно бегать по разным сервисам.
2. Нравится, что в нем практически все работает из коробки (кроме тестирования =/ ).
3. Когда начинал с ним возиться (в начале года), то и цена использования была адекватна, сейчас это конечно уже минус.
4. И, наконец, примитивная вкусовщина.
Но, если задаться целью максимально сэкономить (не знаю насчет удобства использования и установки), то ваши варианты выглядят интересно, особенно Argo Workflows.
DCNick3
Ещё гитлаб можно бесплатно селф-хостить (правда, не уверен насчёт интеграции с кубером)
UPD: А, ну в статье про это есть.
rakhinskiy
В бесплатной версии подключается только один кластер кубера
Ghostello
Без проблем работает бесплатная селфхостед версия уже с тремя кластерами куба и кучей проектов с самописанным cicd.
Mopckou Автор
А там доступны все те же функции? Типа кубернетис дашборд или канареечный деплой? А какие системки на этой машине, которая хостит гитлаб?