

Многие, если не все, проекты в области науки о данных требуют некоторого внешнего интерфейса для визуализации данных, чтобы отображать результаты для анализа данных людьми. Python, кажется, может похвастаться самыми мощными библиотеками, но не теряйте надежды, если вы разработчик Java (или если вы также владеете другим языком).
В этом посте я опишу, как вы можете сделать что-то полезное с помощью интерфейса визуализации данных, не написав ни единой строчки кода, лишь следуя пошаговому процессу.
Сценарий использования: изменения в Википедии
Я предполагаю, что вы уже знакомы с Википедией. Если нет, Википедия - это онлайн энциклопедия, которую курирует сообщество. По их собственным словам:
Википедия - это бесплатная многоязычная онлайн энциклопедия, написанная и поддерживаемая сообществом добровольцев с помощью модели открытого сотрудничества с использованием системы редактирования на основе вики.
Вышеупомянутое на самом деле является выдержкой из статьи из Википедии. Очень символично.
Идея состоит в том, чтобы позволить кому угодно писать что-нибудь на любую тему и позволить сообществу решать, улучшает ли эта статья совокупность знаний - или нет. Вы можете рассматривать эту систему как всемирный Git обзоров.
Даже с таким подходом очень легко исчерпать возможности сообщества по рассмотрению материалов, посылая очень много изменений. Чтобы предотвратить такое злоупотребление, потенциальным участникам необходимо сначала создать учетную запись. Однако это вызывает разногласия членов сообщества. Если я хочу внести свой вклад, исправив опечатку, добавив изображение или любую другую крошечную задачу, создание учетной записи потребует больше времени, чем просто участие. Чтобы разрешить возможности одноразового вклада, Википедия разрешает анонимные изменения. Однако в отношении злоупотреблений мы возвращаемся к исходной точке. В этом случае Википедия регистрирует ваш IP-адрес. IP будет отображаться в истории изменений вместо имени учетной записи.
Далее я использую визуализацию анонимных вкладов по всему миру. Сначала я прочту данные из Википедии, отфильтрую изменения по аутентифицированным учетным записям, сделаю вывод о местонахождении изменения, выберу язык изменения, а затем покажу их на карте мира. Затем бы визуально изучу изменения и замечу, что язык и местоположение как-то соответствуют друг другу.
Мы собираемся выполничь это, следуя пошаговому процессу.
Нанесем визит в мир перемен
Первый шаг - это фактически получить данные, то есть перенести изменения из Википедии в наше хранилище данных.
Это довольно просто, поскольку сама Википедия предоставляет свои изменения на специальной странице последних изменений.
Если вы нажмете кнопку «Обновление в реальном времени», вы увидите, что список обновляется в режиме реального времени (или очень близко к нему). Вот скриншот изменений на момент написания этого поста:

Пришло время создать конвейер для получения этих данных в Hazelcast. Обратите внимание: если вы хотите продолжить, проект доступен на GitHub.
Википедия предоставляет изменения посредством событий, отправленных сервером. Короче говоря, с помощью SSE (Server-Sent Events) вы регистрируете клиента на конечной точке, и каждый раз, когда поступают новые данные, вы получаете уведомление и можете действовать соответствующим образом. На JVM доступно несколько SSE-совместимых клиентов, включая Spring WebClient. Вместо этого я решил использовать OkHttp EventSource, потому что он легкий - он зависит только от OkHttp и использовать его относительно просто.
Вот выдержка из POM:
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>${hazelcast.version}</version>
</dependency>
<dependency>
<groupId>com.launchdarkly</groupId>
<artifactId>okhttp-eventsource</artifactId>
<version>2.3.2</version>
</dependency>Получение данных
Конвейеры данных Hazelcast работают, регулярно опрашивая источник. С конечной точкой HTTP это просто, но с SSE не очень, поскольку SSE полагается на подписку. Следовательно, нам нужно разработать кастомный Source и реализовать его на базе внутренней очереди для хранения изменений по мере их поступления, в то время как опрос будет исключать из очереди и отправлять их дальше по конвейеру.
Мы разрабатываем код для следующих компонентов:
Contextуправляет подпиской. Он создает новый экземплярWikipediaChangeEventHandlerи регистрирует его как наблюдателя потока SSE.WikipediaChangeEventHandler- компонента подписки. Каждый раз, когда происходит изменение, она получает уведомление и помещает данные об изменениях в свою внутреннюю очередь.Движок Hazelcast вызывает
Callчерез определенные промежутки времени. Когда это происходит, он удаляет элементы из очередиWikipediaChangeEventHandler, преобразует простую строку в строкуJSONObjectи помещает ее в буфер конвейера данных.
С динамической точки зрения систему можно смоделировать так:
Запустив код получим вывод вроде этого:
{"server_script_path":"/w","server_name":"en.wikipedia.org","$schema":"/mediawiki/recentchange/1.0.0","bot":false,"wiki":"enwiki","type":"categorize","title":"Category:Biography articles without listas parameter","meta":{"dt":"2021-07-28T04:07:40Z","partition":0,"offset":363427323,"stream":"mediawiki.recentchange","domain":"en.wikipedia.org","topic":"codfw.mediawiki.recentchange","id":"01592c7a-03f1-46cd-9472-3bbe63aff0ec","uri":"https://en.wikipedia.org/wiki/Category:Biography_articles_without_listas_parameter","request_id":"b49c3b98-2064-44da-aab4-ab7b3bf65bdd"},"namespace":14,"comment":"[[:Talk:Jeff S. Klotz]] removed from category","id":1406951122,"server_url":"https://en.wikipedia.org","user":"Lepricavark","parsedcomment":"<a href=\"/wiki/Talk:Jeff_S._Klotz\" title=\"Talk:Jeff S. Klotz\">Talk:Jeff S. Klotz<\/a> removed from category","timestamp":1627445260}
{"server_script_path":"/w","server_name":"commons.wikimedia.org","$schema":"/mediawiki/recentchange/1.0.0","bot":true,"wiki":"commonswiki","type":"categorize","title":"Category:Flickr images reviewed by FlickreviewR 2","meta":{"dt":"2021-07-28T04:07:42Z","partition":0,"offset":363427324,"stream":"mediawiki.recentchange","domain":"commons.wikimedia.org","topic":"codfw.mediawiki.recentchange","id":"68f3a372-112d-4dae-af8f-25d88984f1d8","uri":"https://commons.wikimedia.org/wiki/Category:Flickr_images_reviewed_by_FlickreviewR_2","request_id":"1a132610-85e0-4954-9329-9e44691970aa"},"namespace":14,"comment":"[[:File:Red squirrel (51205279267).jpg]] added to category","id":1729953358,"server_url":"https://commons.wikimedia.org","user":"FlickreviewR 2","parsedcomment":"<a href=\"/wiki/File:Red_squirrel_(51205279267).jpg\" title=\"File:Red squirrel (51205279267).jpg\">File:Red squirrel (51205279267).jpg<\/a> added to category","timestamp":1627445262}
{"server_script_path":"/w","server_name":"commons.wikimedia.org","$schema":"/mediawiki/recentchange/1.0.0","bot":true,"wiki":"commonswiki","type":"categorize","title":"Category:Flickr review needed","meta":{"dt":"2021-07-28T04:07:42Z","partition":0,"offset":363427325,"stream":"mediawiki.recentchange","domain":"commons.wikimedia.org","topic":"codfw.mediawiki.recentchange","id":"b4563ed9-a6f2-40de-9e71-c053f5352846","uri":"https://commons.wikimedia.org/wiki/Category:Flickr_review_needed","request_id":"1a132610-85e0-4954-9329-9e44691970aa"},"namespace":14,"comment":"[[:File:Red squirrel (51205279267).jpg]] removed from category","id":1729953359,"server_url":"https://commons.wikimedia.org","user":"FlickreviewR 2","parsedcomment":"<a href=\"/wiki/File:Red_squirrel_(51205279267).jpg\" title=\"File:Red squirrel (51205279267).jpg\">File:Red squirrel (51205279267).jpg<\/a> removed from category","timestamp":1627445262}
{"server_script_path":"/w","server_name":"www.wikidata.org","$schema":"/mediawiki/recentchange/1.0.0","minor":false,"bot":true,"wiki":"wikidatawiki","length":{"new":31968,"old":31909},"type":"edit","title":"Q40652","revision":{"new":1468164253,"old":1446892882},"patrolled":true,"meta":{"dt":"2021-07-28T04:07:43Z","partition":0,"offset":363427326,"stream":"mediawiki.recentchange","domain":"www.wikidata.org","topic":"codfw.mediawiki.recentchange","id":"70784dde-0360-4292-9f62-81323ced9aa7","uri":"https://www.wikidata.org/wiki/Q40652","request_id":"f9686303-ffed-4c62-8532-bf870288ff55"},"namespace":0,"comment":"/* wbsetaliases-add:1|zh */ 蒂托, [[User:Cewbot#Import labels/aliases|import label/alias]] from [[zh:巴西國家足球隊]], [[zh:何塞·保罗·贝塞拉·马希尔·儒尼奥尔]], [[zh:2018年國際足協世界盃參賽球員名單]], [[zh:埃德爾·米利唐]], [[zh:加布里埃爾·馬丁內利]], [[zh:2019年南美超级德比杯]], [[zh:2019年美洲杯决赛]], [[zh:2019年美洲杯参赛名单]], [[zh:2021年美洲杯B组]], [[zh:2021年美洲國家盃決賽]]","id":1514670479,"server_url":"https://www.wikidata.org","user":"Cewbot","parsedcomment":"\u200e<span dir=\"auto\"><span class=\"autocomment\">Added Chinese alias: <\/span><\/span> 蒂托, <a href=\"/wiki/User:Cewbot#Import_labels/aliases\" title=\"User:Cewbot\">import label/alias<\/a> from <a href=\"https://zh.wikipedia.org/wiki/%E5%B7%B4%E8%A5%BF%E5%9C%8B%E5%AE%B6%E8%B6%B3%E7%90%83%E9%9A%8A\" class=\"extiw\" title=\"zh:巴西國家足球隊\">zh:巴西國家足球隊<\/a>, <a href=\"https://zh.wikipedia.org/wiki/%E4%BD%95%E5%A1%9E%C2%B7%E4%BF%9D%E7%BD%97%C2%B7%E8%B4%9D%E5%A1%9E%E6%8B%89%C2%B7%E9%A9%AC%E5%B8%8C%E5%B0%94%C2%B7%E5%84%92%E5%B0%BC%E5%A5%A5%E5%B0%94\" class=\"extiw\" title=\"zh:何塞·保罗·贝塞拉·马希尔·儒尼奥尔\">zh:何塞·保罗·贝塞拉·马希尔·儒尼奥尔<\/a>, <a href=\"https://zh.wikipedia.org/wiki/2018%E5%B9%B4%E5%9C%8B%E9%9A%9B%E8%B6%B3%E5%8D%94%E4%B8%96%E7%95%8C%E7%9B%83%E5%8F%83%E8%B3%BD%E7%90%83%E5%93%A1%E5%90%8D%E5%96%AE\" class=\"extiw\" title=\"zh:2018年國際足協世界盃參賽球員名單\">zh:2018年國際足協世界盃參賽球員名單<\/a>, <a href=\"https://zh.wikipedia.org/wiki/%E5%9F%83%E5%BE%B7%E7%88%BE%C2%B7%E7%B1%B3%E5%88%A9%E5%94%90\" class=\"extiw\" title=\"zh:埃德爾·米利唐\">zh:埃德爾·米利唐<\/a>, <a href=\"https://zh.wikipedia.org/wiki/%E5%8A%A0%E5%B8%83%E9%87%8C%E5%9F%83%E7%88%BE%C2%B7%E9%A6%AC%E4%B8%81%E5%85%A7%E5%88%A9\" class=\"extiw\" title=\"zh:加布里埃爾·馬丁內利\">zh:加布里埃爾·馬丁內利<\/a>, <a href=\"https://zh.wikipedia.org/wiki/2019%E5%B9%B4%E5%8D%97%E7%BE%8E%E8%B6%85%E7%BA%A7%E5%BE%B7%E6%AF%94%E6%9D%AF\" class=\"extiw\" title=\"zh:2019年南美超级德比杯\">zh:2019年南美超级德比杯<\/a>, <a href=\"https://zh.wikipedia.org/wiki/2019%E5%B9%B4%E7%BE%8E%E6%B4%B2%E6%9D%AF%E5%86%B3%E8%B5%9B\" class=\"extiw\" title=\"zh:2019年美洲杯决赛\">zh:2019年美洲杯决赛<\/a>, <a href=\"https://zh.wikipedia.org/wiki/2019%E5%B9%B4%E7%BE%8E%E6%B4%B2%E6%9D%AF%E5%8F%82%E8%B5%9B%E5%90%8D%E5%8D%95\" class=\"extiw\" title=\"zh:2019年美洲杯参赛名单\">zh:2019年美洲杯参赛名单<\/a>, <a href=\"https://zh.wikipedia.org/wiki/2021%E5%B9%B4%E7%BE%8E%E6%B4%B2%E6%9D%AFB%E7%BB%84\" class=\"extiw\" title=\"zh:2021年美洲杯B组\">zh:2021年美洲杯B组<\/a>, <a href=\"https://zh.wikipedia.org/wiki/2021%E5%B9%B4%E7%BE%8E%E6%B4%B2%E5%9C%8B%E5%AE%B6%E7%9B%83%E6%B1%BA%E8%B3%BD\" class=\"extiw\" title=\"zh:2021年美洲國家盃決賽\">zh:2021年美洲國家盃決賽<\/a>","timestamp":1627445263}
{"server_script_path":"/w","server_name":"www.wikidata.org","$schema":"/mediawiki/recentchange/1.0.0","minor":false,"bot":true,"wiki":"wikidatawiki","length":{"new":239,"old":161},"type":"edit","title":"Q107674623","revision":{"new":1468164250,"old":1468164243},"patrolled":true,"meta":{"dt":"2021-07-28T04:07:43Z","partition":0,"offset":363427327,"stream":"mediawiki.recentchange","domain":"www.wikidata.org","topic":"codfw.mediawiki.recentchange","id":"40260137-ee52-4a67-b024-22d3cf86907a","uri":"https://www.wikidata.org/wiki/Q107674623","request_id":"db6e073a-19f6-4658-9425-7992b34b4208"},"namespace":0,"comment":"/* wbsetlabel-add:1|de */ Favolaschia filopes","id":1514670480,"server_url":"https://www.wikidata.org","user":"SuccuBot","parsedcomment":"\u200e<span dir=\"auto\"><span class=\"autocomment\">Bezeichnung für [de] hinzugefügt: <\/span><\/span> Favolaschia filopes","timestamp":1627445263}
{"server_script_path":"/w","server_name":"ko.wikipedia.org","$schema":"/mediawiki/recentchange/1.0.0","minor":true,"bot":true,"wiki":"kowiki","length":{"new":1158,"old":1161},"type":"edit","title":"이시다테 야스키","revision":{"new":29895993,"old":26098259},"meta":{"dt":"2021-07-28T04:07:43Z","partition":0,"offset":363427328,"stream":"mediawiki.recentchange","domain":"ko.wikipedia.org","topic":"codfw.mediawiki.recentchange","id":"c23bdb77-e88c-48d3-9d24-3c4dd8ef1dbf","uri":"https://ko.wikipedia.org/wiki/%EC%9D%B4%EC%8B%9C%EB%8B%A4%ED%85%8C_%EC%95%BC%EC%8A%A4%ED%82%A4","request_id":"0010e77b-fbcd-4de8-a5ad-4616adbbd6d4"},"namespace":0,"comment":"봇: 분류 이름 변경 (분류:1984년 태어남 → [[분류:1984년 출생]])","id":56333828,"server_url":"https://ko.wikipedia.org","user":"TedBot","parsedcomment":"봇: 분류 이름 변경 (분류:1984년 태어남 → <a href=\"/wiki/%EB%B6%84%EB%A5%98:1984%EB%85%84_%EC%B6%9C%EC%83%9D\" title=\"분류:1984년 출생\">분류:1984년 출생<\/a>)","timestamp":1627445263}
{"server_script_path":"/w","server_name":"commons.wikimedia.org","$schema":"/mediawiki/recentchange/1.0.0","minor":false,"bot":true,"wiki":"commonswiki","length":{"new":3864,"old":527},"type":"edit","title":"File:Albizia kalkora 06.jpg","revision":{"new":577195372,"old":577193453},"patrolled":true,"meta":{"dt":"2021-07-28T04:07:44Z","partition":0,"offset":363427329,"stream":"mediawiki.recentchange","domain":"commons.wikimedia.org","topic":"codfw.mediawiki.recentchange","id":"1a7fcb55-dec7-4303-b757-19f6a6a4dcdd","uri":"https://commons.wikimedia.org/wiki/File:Albizia_kalkora_06.jpg","request_id":"7f841b4a-ac70-4c2b-a148-bc07696ccf7a"},"namespace":6,"comment":"/* wbeditentity-update:0| */ Adding structured data: date, camera, author, copyright & source","id":1729953360,"server_url":"https://commons.wikimedia.org","user":"BotMultichillT","parsedcomment":"\u200e<span dir=\"auto\"><span class=\"autocomment\">Changed an entity: <\/span><\/span> Adding structured data: date, camera, author, copyright & source","timestamp":1627445264}
{"server_script_path":"/w","server_name":"id.wikipedia.org","$schema":"/mediawiki/recentchange/1.0.0","minor":true,"bot":true,"wiki":"idwiki","length":{"new":977,"old":962},"type":"edit","title":"Euporus linearis","revision":{"new":18801346,"old":16068468},"patrolled":true,"meta":{"dt":"2021-07-28T04:07:43Z","partition":0,"offset":363427330,"stream":"mediawiki.recentchange","domain":"id.wikipedia.org","topic":"codfw.mediawiki.recentchange","id":"6c3882f9-9fd0-4f43-ab69-e538762c7981","uri":"https://id.wikipedia.org/wiki/Euporus_linearis","request_id":"dea59b42-7c97-4cbc-9384-5d8836a981ec"},"namespace":0,"comment":"[[Wikipedia:Bot|Bot]]: fixed → [[Kategori:Taxonbar tanpa parameter from|taxonbar tanpa parameter from]]","id":42309169,"server_url":"https://id.wikipedia.org","user":"HsfBot","parsedcomment":"<a href=\"/wiki/Wikipedia:Bot\" title=\"Wikipedia:Bot\">Bot<\/a>: fixed → <a href=\"/wiki/Kategori:Taxonbar_tanpa_parameter_from\" title=\"Kategori:Taxonbar tanpa parameter from\">taxonbar tanpa parameter from<\/a>","timestamp":1627445263}
{"server_script_path":"/w","server_name":"www.wikidata.org","$schema":"/mediawiki/recentchange/1.0.0","minor":false,"bot":false,"wiki":"wikidatawiki","length":{"new":25025,"old":24908},"type":"edit","title":"Q80075231","revision":{"new":1468164255,"old":1467697536},"patrolled":true,"meta":{"dt":"2021-07-28T04:07:44Z","partition":0,"offset":363427331,"stream":"mediawiki.recentchange","domain":"www.wikidata.org","topic":"codfw.mediawiki.recentchange","id":"720f6507-1ea1-4665-b1b9-1665c97450a9","uri":"https://www.wikidata.org/wiki/Q80075231","request_id":"43b7d511-007f-4005-a562-5002c7e0aff4"},"namespace":0,"comment":"/* wbsetdescription-add:1|dv */ އަކުއިލާ ނަކަތުގައިވާ ތަރިއެއް, [[:toollabs:quickstatements/#/batch/60416|batch #60416]]","id":1514670481,"server_url":"https://www.wikidata.org","user":"EN-Jungwon","parsedcomment":"\u200e<span dir=\"auto\"><span class=\"autocomment\">Added [dv] description: <\/span><\/span> އަކުއިލާ ނަކަތުގައިވާ ތަރިއެއް, <a href=\"https://iw.toolforge.org/quickstatements/#.2Fbatch.2F60416\" class=\"extiw\" title=\"toollabs:quickstatements/\">batch #60416<\/a>","timestamp":1627445264}
{"server_script_path":"/w","server_name":"www.wikidata.org","$schema":"/mediawiki/recentchange/1.0.0","minor":false,"bot":false,"wiki":"wikidatawiki","length":{"new":5312,"old":4884},"type":"edit","title":"Q85766437","revision":{"new":1468164246,"old":1342535335},"patrolled":true,"meta":{"dt":"2021-07-28T04:07:42Z","partition":0,"offset":363427332,"stream":"mediawiki.recentchange","domain":"www.wikidata.org","topic":"codfw.mediawiki.recentchange","id":"ad173600-09b7-4ccd-9490-4a60f6a432ea","uri":"https://www.wikidata.org/wiki/Q85766437","request_id":"1228a17e-2baa-46cc-a3bc-2049a62982c9"},"namespace":0,"comment":"/* wbcreateclaim-create:1| */ [[Property:P7937]]: [[Q7366]], [[:toollabs:quickstatements/#/batch/60404|batch #60404]]","id":1514670483,"server_url":"https://www.wikidata.org","user":"Moebeus","parsedcomment":"\u200e<span dir=\"auto\"><span class=\"autocomment\">Created claim: <\/span><\/span> <a href=\"/wiki/Property:P7937\" title=\"Property:P7937\">Property:P7937<\/a>: <a href=\"/wiki/Q7366\" title=\"Q7366\">Q7366<\/a>, <a href=\"https://iw.toolforge.org/quickstatements/#.2Fbatch.2F60404\" class=\"extiw\" title=\"toollabs:quickstatements/\">batch #60404<\/a>","timestamp":1627445262}
{"server_script_path":"/w","server_name":"www.wikidata.org","$schema":"/mediawiki/recentchange/1.0.0","minor":false,"bot":false,"wiki":"wikidatawiki","length":{"new":5134,"old":5126},"type":"edit","title":"Q12444793","revision":{"new":1468164254,"old":1413396080},"patrolled":false,"meta":{"dt":"2021-07-28T04:07:43Z","partition":0,"offset":363427333,"stream":"mediawiki.recentchange","domain":"www.wikidata.org","topic":"codfw.mediawiki.recentchange","id":"c01d52c5-c476-4554-814d-513342e04686","uri":"https://www.wikidata.org/wiki/Q12444793","request_id":"6d0a32b9-1234-4c8e-a02a-d92608f06d33"},"namespace":0,"comment":"/* wbsetdescription-set:1|hi */ भारत के उत्तराखण्ड राज्य का एक गाँव bikash","id":1514670482,"server_url":"https://www.wikidata.org","user":"2409:4061:219C:613E:DFD9:6BD4:F234:E7E0","parsedcomment":"\u200e<span dir=\"auto\"><span class=\"autocomment\">बदला [hi] विवरण: <\/span><\/span> भारत के उत्तराखण्ड राज्य का एक गाँव bikash","timestamp":1627445263}
{"server_script_path":"/w","server_name":"www.wikidata.org","$schema":"/mediawiki/recentchange/1.0.0","minor":false,"bot":false,"wiki":"wikidatawiki","length":{"new":22936,"old":22819},"type":"edit","title":"Q80075234","revision":{"new":1468164258,"old":1467697544},"patrolled":true,"meta":{"dt":"2021-07-28T04:07:44Z","partition":0,"offset":363427334,"stream":"mediawiki.recentchange","domain":"www.wikidata.org","topic":"codfw.mediawiki.recentchange","id":"7016afae-6691-4dca-bfaf-a5a3363edf31","uri":"https://www.wikidata.org/wiki/Q80075234","request_id":"aa4f6828-149d-4feb-a3cf-cd39902773fe"},"namespace":0,"comment":"/* wbsetdescription-add:1|dv */ އަކުއިލާ ނަކަތުގައިވާ ތަރިއެއް, [[:toollabs:quickstatements/#/batch/60416|batch #60416]]","id":1514670484,"server_url":"https://www.wikidata.org","user":"EN-Jungwon","parsedcomment":"\u200e<span dir=\"auto\"><span class=\"autocomment\">Added [dv] description: <\/span><\/span> އަކުއިލާ ނަކަތުގައިވާ ތަރިއެއް, <a href=\"https://iw.toolforge.org/quickstatements/#.2Fbatch.2F60416\" class=\"extiw\" title=\"toollabs:quickstatements/\">batch #60416<\/a>","timestamp":1627445264}
{"server_script_path":"/w","server_name":"de.wikipedia.org","$schema":"/mediawiki/recentchange/1.0.0","minor":false,"bot":true,"wiki":"dewiki","length":{"new":17069,"old":17075},"type":"edit","title":"Liste der Biografien/Caro","revision":{"new":214271460,"old":213857611},"meta":{"dt":"2021-07-28T04:07:43Z","partition":0,"offset":363427335,"stream":"mediawiki.recentchange","domain":"de.wikipedia.org","topic":"codfw.mediawiki.recentchange","id":"6618b0ab-eadf-405a-a474-ec2ad9fef8bb","uri":"https://de.wikipedia.org/wiki/Liste_der_Biografien/Caro","request_id":"23181b86-03de-4153-ad99-e7e20e611ed6"},"namespace":0,"comment":"Bot: Automatische Aktualisierung, siehe [[Benutzer:APPERbot/LdB]]","id":309672385,"server_url":"https://de.wikipedia.org","user":"APPERbot","parsedcomment":"Bot: Automatische Aktualisierung, siehe <a href=\"/wiki/Benutzer:APPERbot/LdB\" title=\"Benutzer:APPERbot/LdB\">Benutzer:APPERbot/LdB<\/a>","timestamp":1627445263}Вот последняя запись, отформатированная для лучшего понимания:
{
"$schema": "/mediawiki/recentchange/1.0.0",
"bot": true,
"comment": "Bot: Automatische Aktualisierung, siehe [[Benutzer:APPERbot/LdB]]",
"id": 309672385,
"length": {
"new": 17069,
"old": 17075
},
"meta": {
"domain": "de.wikipedia.org",
"dt": "2021-07-28T04:07:43Z",
"id": "6618b0ab-eadf-405a-a474-ec2ad9fef8bb",
"offset": 363427335,
"partition": 0,
"request_id": "23181b86-03de-4153-ad99-e7e20e611ed6",
"stream": "mediawiki.recentchange",
"topic": "codfw.mediawiki.recentchange",
"uri": "https://de.wikipedia.org/wiki/Liste_der_Biografien/Caro"
},
"minor": false,
"namespace": 0,
"parsedcomment": "Bot: Automatische Aktualisierung, siehe Benutzer:APPERbot/LdB",
"revision": {
"new": 214271460,
"old": 213857611
},
"server_name": "de.wikipedia.org",
"server_script_path": "/w",
"server_url": "https://de.wikipedia.org",
"timestamp": 1627445263,
"title": "Liste der Biografien/Caro",
"type": "edit",
"user": "APPERbot",
"wiki": "dewiki"
}Kibana для визуализации данных
Как я уже упоминал во введении, в нашем распоряжении есть фантастический инструмент для визуализации данных, не требующий написания кода, и этим инструментом является Kibana. Kibana является частью так называемого стека ELK:
Elasticsearch предоставляет часть для хранения и индексации
Наконец, Kibana предлагает панели мониторинга и виджеты для изучения и визуализации данных, хранящихся в Elasticsearch.

Вместо того, чтобы писать в стандартный вывод, мы собираемся писать в экземпляр Elasticsearch. Для этого нам нужно создать файл Sink. Хотя вы можете использовать Elasticsearch API напрямую, Hazelcast предоставляет расширение, облегчающее вашу работу. Просто добавьте JAR в classpath, и вы сможете написать следующее: com.hazelcast.jet:hazelcast-jet-elasticsearch-7
private val clientBuilder = {
val env = System.getenv()
val user = env.getOrDefault("ELASTICSEARCH_USERNAME", "elastic") // 1
val password = env.getOrDefault("ELASTICSEARCH_PASSWORD", "changeme") // 1
val host = env.getOrDefault("ELASTICSEARCH_HOST", "localhost") // 1
val port = env.getOrDefault("ELASTICSEARCH_PORT", "9200").toInt() // 1
ElasticClients.client(user, password, host, port) // 2
}
val elasticsearch = ElasticSinks.elastic(clientBuilder) {
IndexRequest("wikipedia").source(it.toString(), XContentType.JSON) // 3
}Обеспечивает параметризацию, чтобы позволить работать в разных средах
Подключается к настроенному экземпляру Elasticsearch
Hazelcast обрабатывает запросы и эффективно отправляет данные в ES.
Теперь конвейер можно улучшить:
val pipeline = Pipeline.create().apply {
readFrom(wikipedia)
.withTimestamps({ it.getLong("timestamp") }, 100)
.writeTo(elasticsearch)
}
Hazelcast.bootstrappedInstance().jet.newJob(pipeline)Вишенка на торте, с хорошим именованием, Hazelcast API позволяет людям, не являющимся разработчиками, следовать логике API.
Запустив вышеупомянутый конвейер, мы уже видим результаты в Kibana. Если у вас нет доступного экземпляра, в репозитории GitHub есть файл docker-compose.yml. Вам нужно только запустить инфраструктуру с помощью docker compose up.
Перейдите по адресу http://localhost:5601 в своем любимом браузере
Аутентифицируйтесь с логином
elasticи паролемchangemeНажмите кнопку “Create index pattern”
Введите
wikipediaв качестве имени индексаНажмите кнопку “Next step”
Выберите
meta.dtдля поля TimeЗавершите ввод, нажав кнопку “Create index pattern”
В меню слева выберите Analytics → Discover
Вы должны увидеть что-то вроде этого:
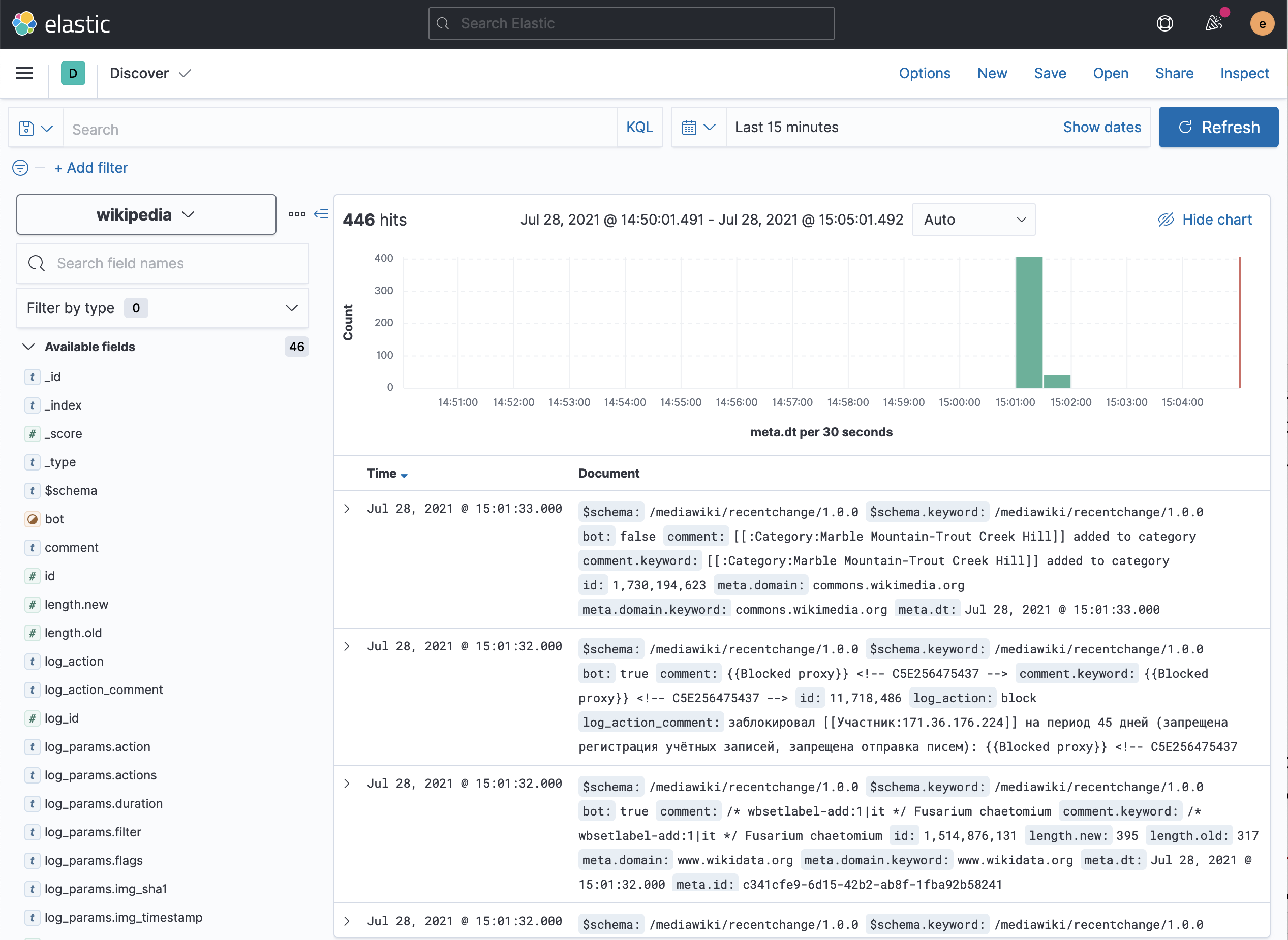
В этом представлении вы можете увидеть все загруженные документы. Для дальнейшего изучения вы можете выбрать поля, которые хотите видеть (справа), и отфильтровать документы на основе их структуры (в строке поиска выше).
Обработка «неправильных» данных
Если вы пытались выполнить задание с кодом, реализованным на этом этапе, вы могли заметить, что через некоторое время Elasticsearch перестает получать данные. Просматривая журналы Hazelcast, вы можете заметить примерно такую трассировку стека:
15:02:34.898 [ WARN] [c.h.j.i.e.TaskletExecutionService] [192.168.1.62]:5701 [dev] [5.0-BETA-1] Exception in ProcessorTasklet{068f-8bfa-4080-0001/elasticSink#0}
com.hazelcast.jet.JetException: failure in bulk execution:
[0]: index [wikipedia], type [_doc], id [PD017XoBfeUJ26i8qT-H], message [ElasticsearchException[Elasticsearch exception [type=mapper_parsing_exception, reason=object mapping for [log_params] tried to parse field [null] as object, but found a concrete value]]]
at com.hazelcast.jet.elastic.ElasticSinkBuilder$BulkContext.lambda$flush$0(ElasticSinkBuilder.java:248)
at com.hazelcast.jet.elastic.impl.RetryUtils.withRetry(RetryUtils.java:57)
at com.hazelcast.jet.elastic.ElasticSinkBuilder$BulkContext.flush(ElasticSinkBuilder.java:244)
at com.hazelcast.function.ConsumerEx.accept(ConsumerEx.java:47)
at com.hazelcast.jet.impl.connector.WriteBufferedP.process(WriteBufferedP.java:73)
at com.hazelcast.jet.impl.processor.ProcessorWrapper.process(ProcessorWrapper.java:97)
at com.hazelcast.jet.impl.pipeline.FunctionAdapter$AdaptingProcessor.process(FunctionAdapter.java:226)
at com.hazelcast.jet.impl.execution.ProcessorTasklet.lambda$processInbox$2f647568$2(ProcessorTasklet.java:439)
at com.hazelcast.jet.function.RunnableEx.run(RunnableEx.java:31)
at com.hazelcast.jet.impl.util.Util.doWithClassLoader(Util.java:498)
at com.hazelcast.jet.impl.execution.ProcessorTasklet.processInbox(ProcessorTasklet.java:439)
at com.hazelcast.jet.impl.execution.ProcessorTasklet.stateMachineStep(ProcessorTasklet.java:305)
at com.hazelcast.jet.impl.execution.ProcessorTasklet.stateMachineStep(ProcessorTasklet.java:300)
at com.hazelcast.jet.impl.execution.ProcessorTasklet.stateMachineStep(ProcessorTasklet.java:281)
at com.hazelcast.jet.impl.execution.ProcessorTasklet.call(ProcessorTasklet.java:255)
at com.hazelcast.jet.impl.execution.TaskletExecutionService$BlockingWorker.run(TaskletExecutionService.java:298)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:829)Это происходит из-за того, как работает Elasticsearch. Поскольку мы не предоставили какой-либо явной схемы индекса, Elasticsearch вывел ее для нас из первых полученных данных. В этом случае атрибут log_params в основном имеет следующую структуру:
"log_params": {
"userid": 108038
}Следовательно, Elasticsearch распознает его как объект JSON со свойством userid. Тем не менее, иногда поток содержит JSON массив. Elasticsearch не может согласовать эти два параметра и выдает указанное выше исключение."log_params":[]
Чтобы исправить это, мы можем либо отфильтровать такие данные, либо преобразовать свойство пустого массива в свойство пустого объекта. Поскольку мы хотим сохранить как можно больше данных, давайте выберем второй вариант. На данный момент мы не знаем, нужно ли нам делать это для другого поля, поэтому было бы неплохо сделать его универсальным:
class MakeFieldObjectIfArray(private val fieldName: String) : FunctionEx<JSONObject, JSONObject> { // 1
override fun applyEx(json: JSONObject) = json.apply { // 2
if (json.has(fieldName) && json.get(fieldName) is JSONArray) // 3
put(fieldName, JSONObject()) // 4
}
}
val pipeline = Pipeline.create().apply {
readFrom(wikipedia)
.withTimestamps({ it.getLong("timestamp") }, 100)
.map(MakeFieldObjectIfArray("log_params")) // 5
.writeTo(elasticsearch)
}Определяет
FunctionEx,которая принимаетJSONObjectв качестве параметра и возвращаетJSONObjectВозвращает тот же самый объект
JSONObjectсо следующими изменениямиЕсли у объекта есть определенное поле и если это поле
JSONArrayТогда заменим массив пустым объектом
JSONObjectПреобразует каждый элемент в конвейере, используя ранее определенные
FunctionEx
Перезапустим конвейер - теперь он работает без сбоев!
Сделать его более читабельным и «работоспособным»
Поскольку конвейер стабилен, пора провести рефакторинг, чтобы заложить прочный фундамент. Рефакторинг идет по двум направлениям:
Читаемость кода, ориентированая на разработчика
«Оперативность», ориентированная на эксплуатацию
С точки зрения разработчика мы можем улучшить опыт, используя API Hazelcast. GeneralStage предлагает обычные примитивы: map(), flatMap(), filter() и несколько более специализированные. Однако на этом уровне детализации мы предпочли бы сосредоточиться на том, что, а не на том, как. По этой причине StreamStage также предоставляет функцию apply(), которая преобразует один StreamStage в другой StreamStage. Воспользуемся этим:
class MakeFieldObjectIfArray(private val fieldName: String) : FunctionEx<StreamStage, StreamStage> {
override fun applyEx(stage: StreamStage) = stage.map { json ->
json.apply {
if (json.has(fieldName) && json.get(fieldName) is JSONArray)
put(fieldName, JSONObject())
}
}
}Используем этот класс:
val pipeline = Pipeline.create().apply {
readFrom(wikipedia)
.withTimestamps({ it.getLong("timestamp") }, 100)
.apply(MakeFieldObjectIfArray("log_params")) // 1
.writeTo(elasticsearch)
}Сосредоточимся на том, "что"
Следующим шагом будет улучшение «работоспособности». Единственный способ проверить, что происходит, - посмотреть Elasticsearch. Если проблема возникает между классами, приведенными выше, трудно точно определить в чем она. По этой причине мы должны добавить логирование:
val pipeline = Pipeline.create().apply {
readFrom(wikipedia)
.withTimestamps({ it.getLong("timestamp") }, 100)
.apply(MakeFieldObjectIfArray("log_params"))
.peek() // 1
.writeTo(elasticsearch)
}Мы выводим каждый элемент в стандартный вывод
При большом количестве данных может быть слишком много шума. Достаточно одного образца:
fun sampleEvery(frequency: Int) = PredicateEx {
Random.nextInt(frequency) == 0 // 1
}
val toStringFn = FunctionEx<Any?, String> {
it?.toString() // 2
}Вернуть,
trueесли случайное значение между0иfrequencyравно0Null-безопасный
toString()
Теперь мы можем найти хорошее применение этому коду:
val pipeline = Pipeline.create().apply {
readFrom(wikipedia)
.withTimestamps({ it.getLong("timestamp") }, 100)
.apply(MakeFieldObjectIfArray("log_params"))
.peek(sampleEvery(50), toStringFn) // 1
.writeTo(elasticsearch)
}В среднем выбираем один элемент из 50
Кроме того, Hazelcast предоставляет API для именования каждого шага конвейера.
class MakeFieldObjectIfArray(private val fieldName: String) : FunctionEx {
override fun applyEx(stage: StreamStage) = stage
.setName("remove-log-params-if-array") // 1
.map { json ->
json.apply {
if (json.has(fieldName) && json.get(fieldName) is JSONArray)
put(fieldName, JSONObject())
}
}
}При этом запуск конвейера выводит следующий журнал DAG :
digraph DAG {
"replace-log-params-if-array" [localParallelism=1];
"replace-log-params-if-array-add-timestamps" [localParallelism=1];
"map" [localParallelism=16];
"elasticSink" [localParallelism=2];
"replace-log-params-if-array" -> "replace-log-params-if-array-add-timestamps" [label="isolated", queueSize=1024];
"replace-log-params-if-array-add-timestamps" -> "map" [queueSize=1024];
"map" -> "elasticSink" [queueSize=1024];
}Геолокационные данные
Глядя на имеющиеся данные, мы можем заметить два типа публикаций:
Публикации аутентифицированных пользователей, например,
GeographBot-
Анонимные публикации, например:
84.243.214.62, для IP v4240D:2:A605:7600:A1DF:B7CA:5AF8:D971, для IP v6
Нет простого способа геолокации с использованием первого типа, но доступны библиотеки и онлайн-API, которые используют последнее. Для этого поста я решил использовать базу данных MaxMind GeoIP. Она предоставляет как локальный файл, так и библиотеку для его использования.
Добавим необходимые зависимости:
<dependency>
<groupId>commons-validator</groupId>
<artifactId>commons-validator</artifactId>
<version>1.7</version>
</dependency>
<dependency>
<groupId>com.maxmind.geoip2</groupId>
<artifactId>geoip2</artifactId>
<version>2.15.0</version>
</dependency>Далее мы можем добавить дополнительный шаг в конвейер обработки, чтобы проверить, является ли пользователь IP-адресом, и добавить информацию, если это так:
val enrichWithLocation = { stage: StreamStage ->
stage.setName("enrich-with-location") // 1
.mapUsingService(ServiceFactories.sharedService(databaseReaderSupplier)) { reader: DatabaseReader, json: JSONObject ->
json.apply {
if (!json.optBoolean("bot") && json.has("user")) { // 2
val user = json.getString("user")
if (InetAddressValidator.getInstance().isValid(user)) { // 3
reader.tryCity(InetAddress.getByName(user)) // 4
.ifPresent { json.withLocationFrom(it) } // 5
}
}
}
}
}
val pipeline = Pipeline.create().apply {
readFrom(wikipedia)
.withTimestamps({ it.getLong("timestamp") }, 100)
.apply(MakeFieldObjectIfArray("log_params"))
.apply(enrichWithLocation) // 6
.peek(sampleEvery(50), toStringFn)
.writeTo(elasticsearch)
}Установите описательное имя
Если свойство бота имеет значение false и если свойство пользователя существует
Убедитесь, что это IP-адрес, v4 или v6
Геолокация IP
Добавьте данные в JSON
Добавить шаг в конвейер
Наша первая визуализация данных
Имея геолокационные данные мы хотели бы отображать изменения на карте мира. Хорошая новость: Kibana предлагает такой виджет прямо из коробки.
Перейдите в Analytics > Maps.
Нажмите на кнопку "Add Layer".
Выберите Documents.
Для индекса выберите
wikipedia
К сожалению, Кибана жалуется, что индекс не содержит геопространственных полей!
Действительно, хотя мы отформатировали данные для создания поля данных с широтой и долготой, Elasticsearch не распознает их как тип Geo-Point. Нам нужно явно отобразить это. Хуже того, мы не можем изменить тип существующего поля. Следовательно, нам нужно остановить конвейер, удалить текущий индекс и потерять все данные.
Перейдите в Management > Stack Management.
Выберите Data > Index Management.
Выберите
wikipediaНажмите на кнопку "Manage Index".
Выберите Delete index.
Подтвердить удаление
Теперь мы готовы нанести поле на карту.
Перейдите в Management | Stack Management
Выберите Data | Index Management
Нажмите на вкладку Index Template (3-я)
Нажмите на кнопку "Create template"
Дайте ему подходящее имя, например,
geo-locateУстановите шаблон индекса, который соответствует
wikipedia, например,wikipediaНажмите на кнопку "Next", чтобы сохранить значения по умолчанию, пока не дойдете до 4-го шага – Mappings.
Добавьте новое поле с именем
location.coordinatesи типом Geo-point.-
Снова нажимайте на кнопку "Next" до последнего шага. На вкладке предварительного просмотра должен отобразиться следующий JSON:
{ "template": { "settings": {}, "mappings": { "properties": { "location": { "properties": { "coordinates": { "type": "geo_point" } } } } }, "aliases": {} } } Нажмите на кнопку «Создать шаблон».
В индексе wikipedia Elasticsearch сопоставляет каждое поле с именем coordinates внутри поля с именем location с географической точкой. По этой причине нам нужно немного изменить код функции сопоставления.
Давайте создадим такую специальную функцию сопоставления:
private fun JSONObject.withLocationFrom(response: CityResponse) {
val country = JSONObject()
.put("iso", response.country.isoCode)
.put("name", response.country.name)
val coordinates = JSONArray()
.put(response.location.longitude)
.put(response.location.latitude)
val location = JSONObject()
.put("country", country)
.put("coordinates", coordinates)
.put("city", response.city.name)
.put("timezone", response.location.timeZone)
.put("accuracy-radius", response.location.accuracyRadius)
put("location", location)
}Теперь мы можем использовать ее в конвейере:
reader.tryCity(InetAddress.getByName(user))
.ifPresent { json.withLocationFrom(it) }Давайте снова запустим конвейер. Теперь мы можем попробовать повторить шаги по созданию карты. На этот раз он распознает поле, которое мы нанесли на карту как географическую точку, что позволяет нам двигаться дальше.
Нажмите кнопку «Add layer» в правом нижнем углу. Вы уже можете наслаждаться некоторыми точками данных, отображаемыми на карте.
Изучение данных
Точки данных отличные, но этого недостаточно. Предположим, мы хотим понимать записи по их местонахождению. Для этого нам нужно добавить поля, такие как meta.uri и comment. Не забудьте назвать слой и сохранить его. Теперь можно щелкнуть точку данных, чтобы отобразить связанные данные:

Википедия - источник информации для миллионов пользователей по всему миру. Поскольку материалы могут быть анонимными (и помните, что они географически привязаны), злоумышленник может обновить статью не для пользы сообщества, а для продвижения геополитической повестки дня. Мы могли бы запросить данные, кажется ли триплет article-language-location нормальным и поднимает ли это какие-то красные флажки. У нас уже есть статья через meta.uri и местоположение, нам нужно добавить язык.
Добавление производных данных
Доступны два основных варианта получения языка:
Из URL-адреса сервера, например, it.wikipedia.org подразумевает итальянский, а fr.wikipedia.org означает французский.
Из комментария (если он не пустой)
В образовательных целях я решил выбрать второй. Каждое событие уже содержит поле comment. Вот пример:
"Anagrames [[esgota]], [[esgotà]], més canvis cosmètics"
"Added location template"
"[[:傑克·威爾許]]已添加至分类,[[Special:WhatLinksHere/傑克·威爾許|此页面包含在其他页面之内]]"
"/* wbsetdescription-add:1|ru */ провинция Алжира"
"/* Treindiensten */"
"יצירת דף עם התוכן \"אסף \"בובי\" מרוז, יליד חיפה, הינו מוזיקאי, מתופף, חבר בלהקות אבטיפוס, קילר ואיפה הילד == הרכבים == === קילר הלוהטת === בשנת 1980 - שימש מתופף של הלהקה קילר הלוהטת. === אבטיפוס === הלהקה הוקמה ב[[קריות]] באמצע [[שנות השמונים]] ועברה גלגולי הרכב שונים. בגלגולה הראשון בשנת...\"
"{{tham khảo|2}} → {{tham khảo|30em}}"
"Mooier wordt het er niet van."
"[[:Конуклар (Джиде)]] категори чу тоьхна"
И т.п.
Лингвист сразу может сделать вывод о языке поля. Также возможно использовать автоматизированный процесс в конвейере. Несколько библиотек NLP доступны в экосистеме JVM, но я обратил внимание на Lingua, одна из которых ориентирована на распознавание языков.
Нам нужно создать дополнительную функцию преобразования:
val languageDetectorSupplier = { _: ProcessorSupplier.Context ->
LanguageDetectorBuilder
.fromAllSpokenLanguages()
.build()
} // 1
val enrichWithLanguage = { stage: StreamStage<JSONObject> ->
stage.setName("enrich-with-language")
.mapUsingService(ServiceFactories.sharedService(languageDetectorSupplier)) { detector: LanguageDetector, json: JSONObject ->
json.apply {
val comment = json.optString("comment")
if (comment.isNotEmpty()) {
val language = detector.detectLanguageOf(comment) // 2
if (language != Language.UNKNOWN) {
json.put(
"language", JSONObject() // 3
.put("code2", language.isoCode639_1)
.put("code3", language.isoCode639_3)
.put("name", language.name)
)
}
}
}
}
}Создает функцию, которая предоставляет детектор языка
Здесь происходит магия
Добавляем данные, связанные с языком, в JSON
Теперь мы можем использовать недавно определенную функцию в конвейере:
val pipeline = Pipeline.create().apply {
readFrom(wikipedia)
.withTimestamps({ it.getLong("timestamp") }, 100)
.apply(MakeFieldObjectIfArray("log_params"))
.apply(enrichWithLocation)
.apply(enrichWithLanguage)
.peek(sampleEvery(50), toStringFn)
.writeTo(elasticsearch)
}На карте Kibana теперь можно добавлять поля, относящиеся к языку, например language.name, чтобы отображать их вместе с остальными точками данных. Тем не менее, у некоторых из них есть пустое поле comment, поэтому язык не отображается. Один из вариантов - соответствующим образом обновить конвейер данных, но также можно отфильтровать нежелательные точки данных в интерфейсе Kibana. В общем, это правильный путь: все равно отправьте данные и оставьте данные, которые они хотят отображать, конечному пользователю.
На карте, перейдите в раздел Фильтрация и добавить KQL фильтр, который отфильтровывает точек данных без значения: language.name : *. Результат будет примерно таким:
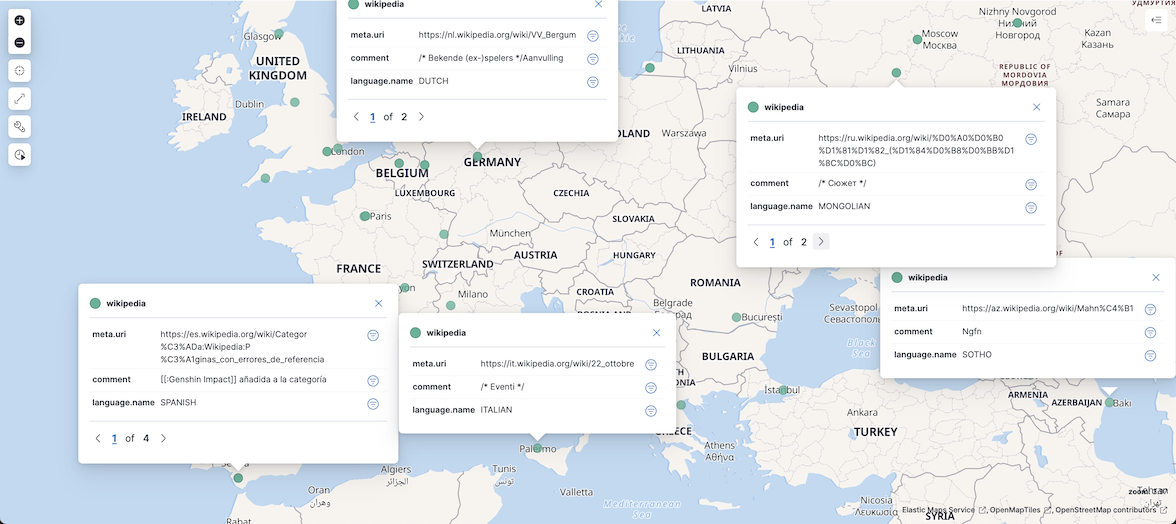
Уточнение данных
Уже лучше, хотя мы можем заметить некоторые неточности:
«Ngfn» - это не Sotho, а скорее похоже на то, что кто-то не нашел хорошего комментария
«Сюжет» может быть болгарским, казахским или русским, но не монгольским.
Хотя Lingua имеет хорошие результаты, она подвержена ошибкам. К счастью, Lingua может вернуть язык из фрагмента текста и карты языков с рейтингом достоверности. Первый язык имеет рейтинг достоверности 1,0; другие имеют рейтинг достоверности от 0,0 до 1,0.
Например, комментарий «Nufüs» возвращает следующую карту:
1.0: Турецкий
0.762256422055537: немецкий
0.6951232183399704: Azerbaïjani
0.6670947340824422: эстонский
0.5291088632328994: Венгерский
0.36574326772623783: каталонский
Следовательно, чем ближе рейтинг уверенности второго языка к 1, тем ниже доверие к первому языку. Чтобы отразить это, мы можем добавить к точке данных разницу между рейтингом уверенности второго языка и 1.0. Приведенный выше код обновим так:
val languagesWithConfidence = detector.computeLanguageConfidenceValues(comment) // 1
if (languagesWithConfidence.isNotEmpty()) {
val mostLikelyLanguage = languagesWithConfidence.firstKey()
val secondMostLikelyConfidence = languagesWithConfidence.filterNot { it.key == mostLikelyLanguage }.maxBy { it.value }?.value ?: 0.0 // 2
json.put(
"language", JSONObject()
.put("code2", mostLikelyLanguage.isoCode639_1)
.put("code3", mostLikelyLanguage.isoCode639_3)
.put("name", mostLikelyLanguage.name)
.put("confidence", 1.0 - secondMostLikelyConfidence) // 3
)
}Получаем отсортированную карту языков
Получаем рейтинг достоверности второго языка или 0, если на карте есть единственный элемент
Добавляем рейтинг достоверности к точке данных
Обратите внимание, что в зависимости от первой точки данных конвейера вы можете получить поле language.confidence типа int, т. е. 0 или 1. Если это произойдет, вам нужно удалить индекс и создать шаблон индекса с помощью типа Double, как мы уже делали выше с географической точкой.
На этом этапе вы можете отобразить достоверность языка и обновить фильтр, чтобы отфильтровать точки данных с низкой достоверностью, например, language.name : * и language.confidence > 0.2.
Вот результат:
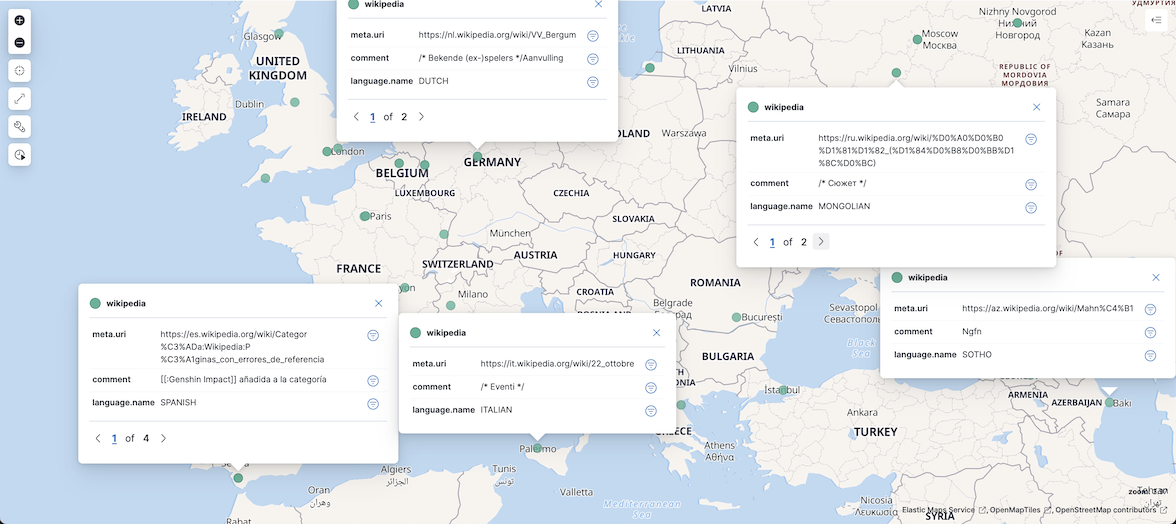
Заключение
В этом посте мы описали, как вы можете визуализировать и исследовать набор данных с помощью платформы Hazelcast для конвейерной части и Kibana для части визуализации. Для Kibana не нужны какие-либо навыки программирования интерфейса - или вообще какие-либо навыки кодирования. Вам не нужно быть специалистом по Python или графическим библиотекам, чтобы начать изучать свои наборы данных прямо сейчас: достаточно быть разработчиком JVM.
Начните исследовать данные прямо сейчас!
Исходный код для этого сообщения находится на GitHub.
AlexanderAlexandrovich
Интересное решение