
Сервисы для онлайн-общения и всевозможная доставка — наверное, самые востребованные и активно развивающиеся отрасли 2020–21-го. Мы ВКонтакте тоже не остались в стороне: работая удалённо с первых месяцев пандемии, запустили групповые видеозвонки. Сперва они вмещали одновременно 128 человек, а теперь мы полностью сняли лимиты на число участников.
В этой статье рассказываем, с какими трудностями сталкивается большинство сервисов звонков. И показываем, что нам понадобилось сделать и изобрести, чтобы преодолеть ограничения по числу участников. Попутно отвечаем на вопросы, которые прилетали со всех сторон на волне интереса к технологиям real-time коммуникации: как устроены Zoom и Clubhouse, что взять для своего сервиса звонков из open source, как встроить звонки в приложение. Про эффективную доставку тоже будет — но не еды, а данных, аудио и видео.

Disclaimer: Выводы и заключения по конкурентам сделаны исключительно из общедоступной информации, общих наблюдений и измерений и могут быть ошибочными.
Что происходило с сервисами видеоконференций во время пандемии?
Спрос на сервисы видеоконференций возник по всему миру и у самых разных людей, кому раньше это было не нужно. Мессенджерам пришлось срочно развивать технологии и встраивать звонки: с видео или хотя бы аудио. А специализированным продуктам — учиться работать с новой аудиторией и подстраиваться под нужды пользователей с непривычными задачами.
С марта прошлого года буквально каждый месяц что-то запускалось и менялось.
Март-2020. Discord увеличил число участников видеочата до 50.
Апрель-2020. WhatsApp тоже покрутил константу и увеличил количество участников групповых звонков с 4 до 8. Facebook Messenger запустил десктопное приложение для MacOS и Windows. Вышел Clubhouse для iOS. Zoom, наоборот, после скандала с Zoombombing и уязвимостями объявил, что замораживает работу над фичами и фокусируется на безопасности. Slack интегрировал в своё приложение аудиозвонки из Microsoft Teams, Zoom, Cisco и других сервисов.
Май-2020. Zoom снял ограничение в 40 минут на длительность группового звонка в бесплатной версии. Позже ограничение вернулось, но Zoom иногда убирает его на праздники вроде Рождества или Дня благодарения. Google выпустил бесплатную версию Google Meet для всех пользователей.
Июль-2020. Discord запустил видеочаты на мобильных.
Август-2020. Facebook добавил Zoom, Cisco Webex, BlueJeans, GoToMeeting в Facebook Portal — серию устройств для видеоконференций со следящей камерой.
Сентябрь-2020. Google включил технологию шумоподавления в Google Meet.
Октябрь-2020. В Zoom появилось сквозное шифрование.
Январь-2021. Илон Маск принял участие в эфире в Clubhouse. Сервис стремительно набрал популярность — даже притом что приложения для Android всё ещё не было.
Март-2021. WhatsApp запустил свои первые видеозвонки на десктопе, но только один на один.
Апрель-2021. Facebook выпустил Hotline — ответ Clubhouse, но с возможностью включить и видео.
Июнь-2021. Telegram пригласил в свои групповые видеозвонки: с видео могут подключиться 30 человек, ещё 1 000 получают просто трансляцию, а остальные в чате могут только слушать.
История звонков ВКонтакте началась гораздо раньше:
в 2012 году появились видеозвонки на вебе;
в 2018-м видеозвонки один на один стали доступны на мобильных;
в мае 2020-го мы запустили видеозвонки на 8 человек;
в сентябре 2020-го — видеозвонки на 128 участников и с дополнительными функциями: демонстрацией экрана, подключением по ссылке и без ограничения по длительности;
в августе 2021-го выпустили десктопный клиент и сделали возможным собирать в звонках ВКонтакте до 2 048 человек;
в ноябре 2021-го сняли все ограничения на число участников.
Кроме пользовательского спроса, нас подталкивало ещё и то, что нам самим был нужен удобный инструмент для онлайн-общения на удалёнке: с записью, 4К-демонстрацией экрана и качественным шумоподавлением. Пришлось поторопиться с запуском своих групповых видеозвонков и сделать их такими, чтобы удовлетворяли всем современным требованиям и превосходили конкурентов в технологическом плане.
Требования к звонкам
Прежде чем приступать к любой задаче, нужно определить, каким должен быть результат и что будет критерием успеха. В случае продуктовой разработки важно понять, чего хотят пользователи. Для этого в крупных компаниях проводят маркетинговые исследования (мы так и сделали), а стартапам на выручку приходят коридорные опросы.
Наше исследование показало, как ни удивительно, что пользователям нужен хороший сервис. Они хотят, чтобы звонки были:
качественными;
с видео;
без ограничений по времени;
безопасными;
доступными на всех устройствах;
и, конечно, бесплатными.
То есть удобство интерфейса и дополнительные фишки беспокоят пользователей гораздо меньше, чем качество.
Тем не менее посмотрим, какие функции предоставляют другие сервисы и без каких из них не обойтись, если мы хотим быть конкурентоспособными.
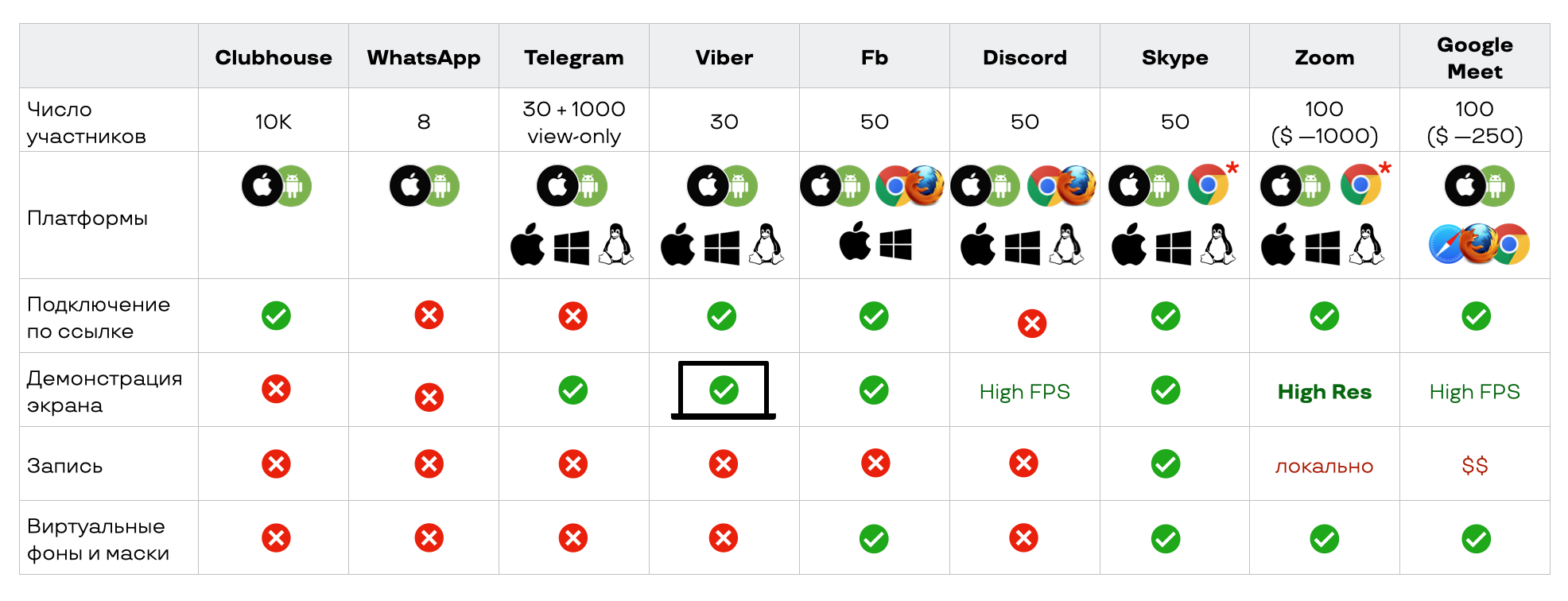
Zoom и Google Meet, которые больше всего выросли с начала пандемии, выделяются числом участников. Скорее всего, онлайн-встречи на 1 000 человек проводятся редко, но потенциально такая возможность есть, и при необходимости за доп. плату её можно использовать.
Почти все сервисы поддерживают мобильные платформы и десктоп-клиенты, но мессенджеры не дружат с вебом — ниже разберёмся, почему. Звонками по ссылке никого не удивишь, демонстрация экрана тоже есть почти у всех. А вот запись есть только в сервисах, ориентированных на корпоративное использование.
Посмотрев на всё это, мы поставили такие амбициозные требования к звонкам ВКонтакте:
неограниченное число участников — почему бы не потягаться с лидерами в этом показателе;
работа на всех платформах;
низкое потребление серверных ресурсов — мы комплементарный сервис и не можем себе позволить то, что доступно в on-premise сегменте;
высокое качество с точки зрения пользователей, которое складывается из стабильности, низких задержек, высокого разрешения видео, демонстрации экрана без артефактов и т. д.;
низкое потребление ресурсов на пользовательских устройствах — чтобы обеспечить качество и консистентность опыта для всех наших пользователей, у которых далеко не всегда флагманские смартфоны.
Всё это можно кратко сформулировать так: «Сделать крутые звонки».
Минимум теории
Чтобы не только понять, как всё устроено ВКонтакте, но и лучше разобраться, как это применить у себя, начнём с базовой теории.
Любые звонки состоят из трёх уровней:
signaling — уровень бизнес-логики, на котором вы подключаете пользователей, координируете и устанавливаете сетевое соединение;
сетевой слой — транспорт и сеть;
уровень передачи аудио- и видеоданных.

Задачи на уровне signaling:
координация участников;
аутентификация или авторизация;
распространение сообщений между участниками с гарантией порядка и подтверждением;
установка сетевого соединения с сервером или между участниками;
список участников;
блокировки и т. д.
То есть примерно всё то же самое, что нужно в мессенджере на WebSocket. Его наверняка все писали, поэтому подробно здесь останавливаться не будем.
В этой статье сосредоточимся на сетевом слое и серверной архитектуре. А о том, из чего состоит пайплайн передачи данных, смотрите в статье об аудио и о видео.
Сетевой уровень
Сразу договоримся: поскольку мы говорим о звонках и нам нужны минимальные задержки, то мы всегда, когда это возможно, выбираем сетевой протокол UDP. Сейчас пытаться запустить VoIP поверх TCP кажется очень странной затеей, так как осталось около 1% сетей, которые не поддерживают UDP. А других аргументов, кроме разве что недостаточной поддержки, у TCP для потоковых данных и раньше не было.
Освежим в памяти основные моменты о том, как пакеты данных ходят между клиентом и сервером и какие основные характеристики их передачи определяют сеть.
Представим, что вы отправляете данные по сети, они разбиваются на пакеты и приходят клиенту-получателю с какими-то интервалами. Суммарный объём пакетов, который можно передать за единицу времени, определяет пропускную способность, или bandwidth (BW). Единица измерения пропускной способности — Кбит/с или более привычные сейчас Мбит/с.
Время между отправкой пакета и получением подтверждения (acknowledgement) о том, что он дошёл, показывает round trip time, или RTT. RTT измеряется в мс — понятно, что чем меньше, тем лучше.
Третья важная характеристика — packet loss. Показывает, сколько из отправленных пакетов потерялись по дороге, измеряется в процентах. Для наглядности все три характеристики изображены на картинке ниже.

Теперь для разминки рассмотрим задачку. Пусть есть два клиента: Алиса и Борис. Алиса звонит Борису по аудио. Сеть у обоих хорошая, пропускная способность, например, 10 Мбит/с, packet loss 0%. Мы знаем, что при прямом p2p-соединении RTT между Алисой и Борисом обычно около 150 мс, а если звонить через сервер, то RTT от обоих клиентов до сервера равно 100 мс.

Вопрос: где задержка будет меньше — p2p или через сервер?
Правильный ответ
Неизвестно.
Чтобы ответить на этот вопрос, попингуем какой-нибудь сайт — например, сайт конференции HighLoad++.

Если сделать достаточно много проб, то получится какая-то такая картина:

То есть на практике RTT — случайная величина, и разброс может быть большим. А значит, заранее точно ответить на вопрос из задачки мы не можем.
Чтобы оценить вариации задержки пакетов, используется jitter. Мы принимаем jitter за разницу между максимальной и минимальной задержкой (в спецификации RFC 3550 для RTСP описан чуть более сложный способ измерения jitter).

Jitter-эффект негативно сказывается на работе кодеков и на качестве аудио и видео. Например, обычно в VOIP-пакетах содержится по 20 мс аудио, клиент проигрывает их один за другим. Если между пачками пакетов возникла задержка в 40 мс, то клиент 40 мс будет играть тишину. Чтобы с этим бороться и равномерно работать с пакетами данных, есть jitter buffer.

Задача jitter buffer — компенсировать задержку, вызванную jitter.
Для борьбы с packet loss есть forward error correction (FEC), или избыточное кодирование: к каждым n пакетам добавляем, например, XOR; если один из этих пакетов пропал, то через XOR его возможно восстановить.

Естественно, это добавляет лишние накладные расходы даже в отсутствие потери пакетов, но зато позволяет справляться с фиксированным небольшим процентом packet loss.
FEC хорошо комбинировать с NACK — negative acknowledgment: если потеряно больше пакетов, чем можно восстановить с помощью FEC, то часть из них можно перезапросить.
Но на самом деле единственное, что поможет уменьшить RTT, — это CDN. Причём, как ни странно, CDN нужны и для p2p-звонков, и для звонков через сервер. Дело в том, что из-за особенностей работы операторов может получиться так, что p2p-звонок по VoIP между абонентами во Владивостоке может пойти через Москву. Чтобы починить это для наших пользователей, мы устанавливаем CDN, которые напрямую соединяем с разными операторами. За счёт этого мы можем запустить звонок во Владивостоке через Хабаровск или хотя бы Новосибирск — задержка наверняка будет меньше, чем через Москву.

Всего у ВКонтакте больше 50 CDN-площадок, но для размещения конференц-серверов мы выбрали часть из них по следующим критериям:
Число звонков, которые совершаются с IP-подсетей, обслуживаемых площадкой провайдера. Если их слишком мало, разворачивать и поддерживать точки может быть невыгодно.
Направления этих звонков. Совершаются ли они в рамках одной площадки или трафик идёт через другие точки.
Показатели RTC-соединения. При звонке через близкий CDN эти показатели должны быть лучше, чем через базовый. Например, до запуска сервера в Новосибирске 75-й перцентиль RTT между абонентами из ближайших регионов (Новосибирской области, Омской области, Алтайского края) был в районе 500 мс, потому что соединение происходило через Москву. После запуска локального сервера 75-й перцентиль RTT между этими регионами станет 250 мс (значения условные, но показывают общий смысл).
Метрики сети
Степень важности метрик сети зависит от специфики каждого конкретного сервиса, геораспределённости пользователей и сценария взаимодействия. Если приложение предназначено для жителей одного региона и им обычно пользуются с десктопа, то CDN и адаптация к неустойчивой мобильной сети скорее всего не понадобятся. Но это не наш случай.
Чтобы составить представление о нашей многомиллионной аудитории, мы обычно используем перцентили по метрикам. Ниже распределение RTT, медиана в 140 мс и 99-й перцентиль в 550 мс. То есть у 99% наших пользователей RTT меньше 550 мс.
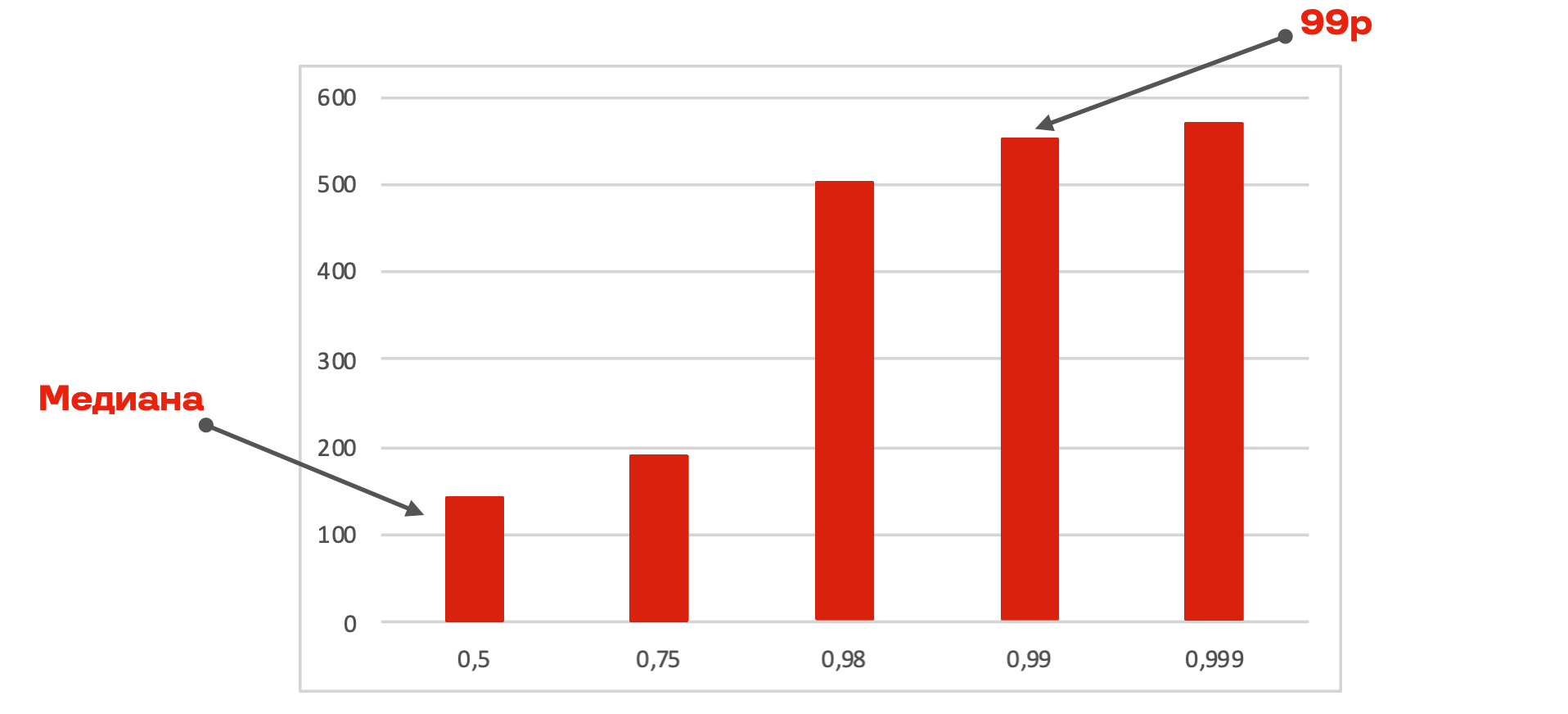
Характеристики сети пользователей ВКонтакте:
медиана: RTT — 140 мс, пропускная способность 3,3 Мбит/с, packet loss — 0,9%, packet jitter/10с — 60 мс;
99-й перцентиль: RTT — 550 мс, пропускная способность 0,3 Мбит/с, packet loss — 2,2%, packet jitter/10 с — 1 400 мс.
Такую сеть — с небольшой потерей пакетов, но большим RTT — выгоднее компенсировать с помощью FEC.
Итого: что нужно знать для стабильной работы на сетевом уровне
Выбирая технические решения, не смотрите на среднее — опирайтесь на медиану и перцентили (лучше 99-й).
Jitter компенсируется через jitter buffer и вызывает задержку.
С высоким RTT и недостаточной пропускной способностью можно бороться за счёт CDN.
Packet loss чинится через FEC/NACK.
Одно и то же решение для звонков, развёрнутое в разных условиях, будет показывать разные результаты.
Пайплайн звонка
Теперь соберём все этапы и посмотрим на пайплайн звонка целиком.
Пользователи подключаются по Signaling (WebSocket).
Устанавливают транспортную сессию (UDP).
Обмениваются доступными каждому из них кодеками для аудио и видео.
Кодируют с помощью этих кодеков: для аудио — Opus, видео — H.264 или VP8/VP9 в зависимости от условий.
При необходимости адаптируют кодирование под пропускную способность и отправляют в сеть.
Чинят пропажу пакетов в динамически меняющейся сети с помощью FEC и NACK. Для аудио ещё есть Packet loss concealment в Opus.
Компенсируют задержки с помощью ускорения (time stretching).
Получается видеоконференция.
Стоит заметить, что WebRTC в каком-то виде реализует сетевой уровень и аудио- и видеопайплайн из коробки. И что мы поддерживаем WebRTC как стандарт передачи real-time данных между браузерами, поскольку хотим работать на всех платформах, включая веб.

Но в групповых звонках его стандартных механизмов становится недостаточно, чтобы выполнить наши требования по качеству и количеству участников. Поэтому мы в некоторых случаях отходим от них — где и как, читайте в статье об аудио и о видео или смотрите в докладе). Да и в принципе WebRTC никак не реализует групповую топологию. О том, какие варианты таких топологий применяются в звонках, поговорим дальше.
Групповые звонки и топологии
Мы разобрались с сигналингом и транспортом. Осталось перейти от звонков один на один к групповым. Для этого базово есть три варианта топологии:
бессерверная Mesh-топология — в которой каждый участник группового звонка устанавливает прямое соединение с каждым из собеседников (так делает, например, WhatsApp);
через микширующий сервер MCU (Multipoint Conferencing Unit) — когда видео- и аудиопотоки от разных пользователей собираются на сервере в один и только этот объединённый поток передаётся клиенту. Вся нагрузка в MCU-топологии ложится на сервер;
через сервер как ретранслятор пакетов — SFU (Selective Forwarding Unit). Все потоки кодируются на клиенте, отправляются на сервер, а сервер перенаправляет их остальным участникам звонка, которые их обратно декодируют тоже на клиенте. Большая часть нагрузки таким образом ложится на клиентские устройства.

Минусы Mesh. В Mesh-топологии с ростом числа участников очень быстро растёт входящий и исходящий трафик. Создаётся большая нагрузка на CPU клиентского устройства, потому что большинство устройств поддерживают аппаратно ускоренное кодирование только одного потока в один момент, а тут надо кодировать и декодировать сразу много потоков.
Собрать в групповом видеозвонке больше 8 участников в Mesh-топологии практически невозможно.
Зато Mesh-топология выгоднее с точки зрения задержек — за счёт прямого соединения между пользователями без участия сервера.
Минусы MCU. В MCU основная проблема в том, что необходимо много серверных ресурсов — и комплементарный бесплатный сервис не всегда может выделить столько. А также в задержке, которая теоретически в этой топологии самая большая.
Плюсы MCU. MCU экономит ресурсы на клиенте и позволяет:
добавить процессинг — мы так и сделали, а также реализовали кастомное шумоподавление и voice activity detection (об этом тоже есть статья). За счёт этого повысили качество звонка;
реализовать трансляцию звонка и запись на сервере;
подключить участников на SIP и телефонных сетях.
Главное преимущество MCU — число участников ограничено только тем, сколько потоков вы сможете смикшировать на сервере.
SFU — компромиссный вариант. Часть нагрузки переносится с сервера на клиент (или с клиента на сервер, смотря с чем сравнивать). Исходящий трафик постоянный, но входящий растёт пропорционально числу участников в звонке.
Максимальное число участников в SFU-топологии, конечно, намного больше, чем в Mesh. Но дорогое микширование входящих потоков ложится на клиентов — и, например, браузер с WebRTC на 50 участниках, скорее всего, развалится.
Mesh |
MCU |
SFU |
|
in/out streams |
3/3 |
1/1 |
3/1 |
input traffic |
3 Мбит/сек |
1 Мбит/сек |
3 Мбит/сек |
output traffic |
3 Мбит/сек |
1 Мбит/сек |
1 Мбит/сек |
client CPU |
3*encoder + 3*decoder = 60% |
1*encoder + 1*decoder = 20% |
1*encoder + 3*decoder = 40% |
server CPU |
0 |
100% |
10% |
latency |
min |
max |
avg |
SIP/live |
— |
+ |
— |
max participants |
~ 8 |
∞ |
~ 50 |
Ошибка выбора топологии — 1: Mesh на 8 и более участников. Если где-то прочитаете, что это возможно, не верьте. Не зря WhatsApp даже под давлением конкуренции увеличил количество участников с 4 до 8 — и не больше.
Ошибка выбора топологии — 2: serverless forwarding broadcast вместо сервера (для ретрансмита других пользователей). Очень трудная в реализации история для real-time данных. Пусть это лучше работает там, где хорошо применимо, — в торрентах.

Формальная постановка задачи
Теперь, когда мы освежили в памяти основные понятия и характеристики, давайте определим, что значит задача «сделать классные звонки» с точки зрения разработки.
«Качественные» на нашем языке — это:
с минимальной задержкой, чтобы пользователи друг друга не перебивали;
с минимальными искажениями аудио и особенно видео;
с минимальным потреблением ресурсов на клиенте.
Факторы, которые влияют на качество звонка и осложняют нам жизнь:
характеристики сети пользователя — пропускная способность, RTT, packet loss, jitter;
устройство и (или) браузер;
количество и качество доступных клиентских ресурсов;
количество участников в звонке и их параметры.
Какие у нас есть ручки, чтобы с этим бороться? Мы можем повлиять на:
алгоритмы сетевого уровня;
аудио- и видеопайплайн;
методы и алгоритмы компенсации задержки, jitter buffer;
топологию групповых звонков.
Формально постановка задачи сводится к многокритериальной оптимизации:
где:
Для всего пространства X, ограниченного 99-м перцентилем и количеством участников [1, 10 000+].
Готовые решения
Посмотрим, какие существуют готовые решения. Может быть, можно не разрабатывать свои звонки, а просто поднять уже реализованные компоненты.
Если вы хоть немного интересовались проектами для видеоконференций (особенно, конечно, такой интерес вызвала повсеместная удалёнка), то наверняка слышали название Jitsi.
Jitsi — мощный open-source проект, у него много плюсов:
работает из коробки;
бесплатный, с открытым исходным кодом;
есть все необходимые для запуска компоненты: jitsi-meet, jicofo, jitsi-videobridge, jibri и т. п.
Jitsi написан на Java — для нас это скорее плюс, но если вашему стеку ближе C++, то есть, например, Mediasoup. Его просто развернуть, и он реализует возможности, которые есть в WebRTC из коробки: SFU, Scalable Video Coding, transport Bandwidth Estimation, simulcast. Но это чистый SFU, без аудиомикширования и серверного транскодирования (за ответом, зачем они нужны, опять отсылаем к предыдущим статьям). То есть нагрузка на клиент будет линейно зависеть от числа участников и расти пропорционально ему.
В таблице ниже — ещё несколько вариантов и их характеристики. Если вам нужны внутренние звонки максимум на 50 участников, без особых изысков по качеству и перспектив на рост, — выбирайте готовый проект, который лучше подходит по стеку. И довольно скоро у вас будет свой конференц-сервер.

Agora в этом сравнении участвует не совсем честно, так как это платный SDK. Но на нём работает, например, Clubhouse. И в некоторых случаях это тоже может быть лучшим вариантом, чем писать всё самим.
Для нас же, понятно, такой путь не подходил даже в начале. У нас уже была инфраструктура, на которой работали онлайн-трансляции и p2p-звонки, не хватало только SFU-сервера. Параллельно запускать и поддерживать приложение, например, на Jitsi было бы невыгодно. Многие другие компоненты тоже пришлось бы значительно перелопатить. Но некоторую часть действительно использовали: например, ice4j для анализа ICE-пакетов при установлении соединения.
Архитектура решения для звонков на неограниченное количество участников
Теперь самое интересное: какую же архитектуру выбрать и какие подходы применить, чтобы построить сервис видеоконференций, способный поддерживать звонки на неограниченное число участников?
У нас три основные группы серверов:
Signaling-серверы обрабатывают подключение участников по WebSocket и осуществляют обмен сервисными данными между участниками. В качестве WebSocket-сервера используем Apache Tomcat, все изменения в состоянии звонка сохраняются в Cassandra.
На conferencing-серверах реализован WebRTC, приём медиа.
Transform-серверы крутятся в облаках и подключаются к работе, когда нужно транскодировать видео (соединение с conferencing по кастомному протоколу поверх TCP).
ZooKeeper координирует, где какой звонок сейчас идёт и обрабатывается, GSLB балансирует нагрузку на conferencing.

Масштабирование одного звонка на N серверов
Предположим, Алиса звонит Борису. Если видео можно передавать как есть и ничего не нужно транскодировать, то Алиса может быть подключена к одному серверу, а Борис к другому — серверы напрямую перекинут видео, и всё (сработает только нижняя половина следующей схемы).
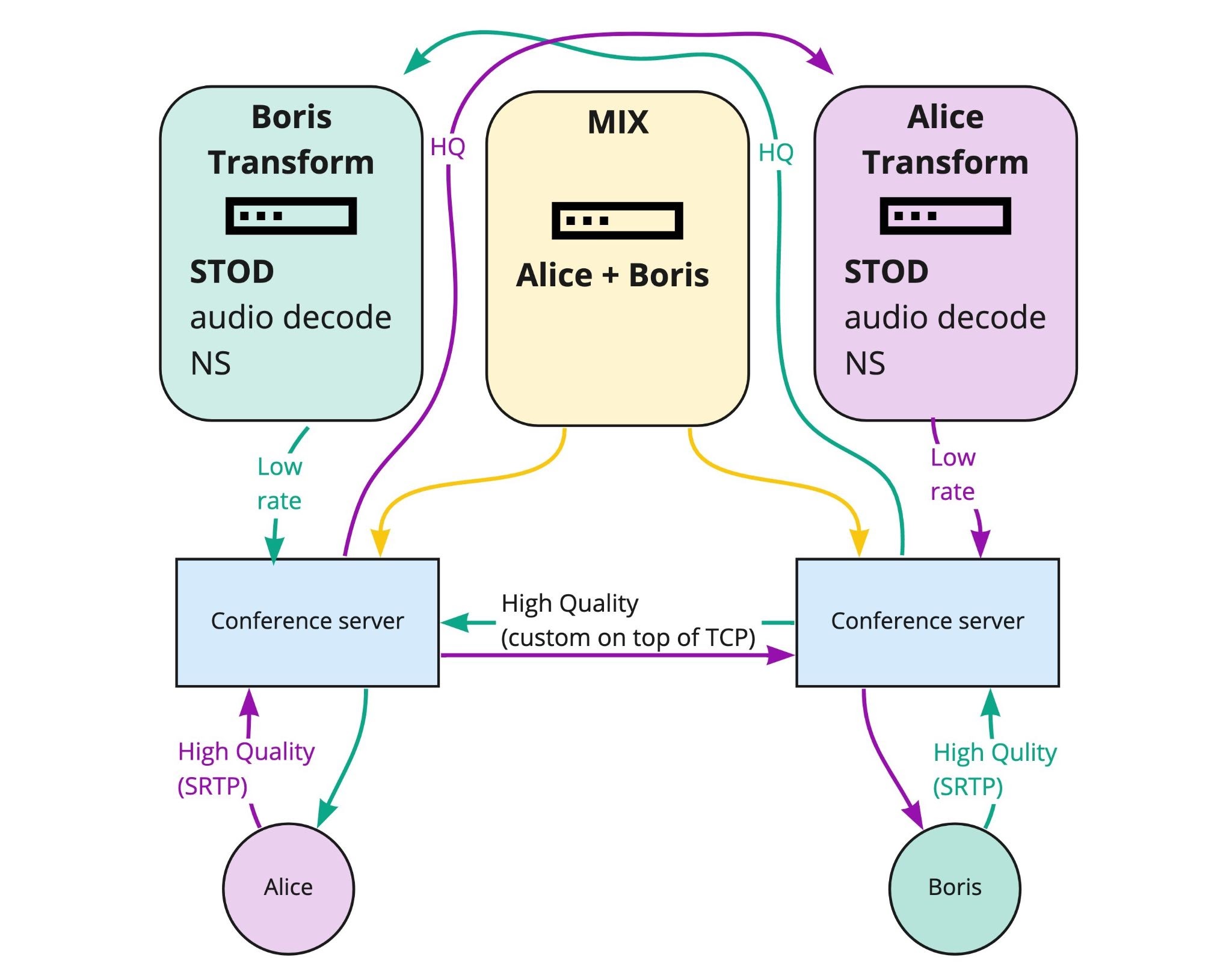
Если участников много, нужно смиксовать аудио, транскодировать видео в разные разрешения, включить серверное шумоподавление и т. д., то мы в облаке запустим соответствующие процессы. Причём это можно «размазать» по любому количеству процессов. В этой схеме нет бутылочного горлышка — можно масштабироваться на сколько угодно серверов для одного звонка.
Для отказоустойчивости закрываем наши signaling-серверы балансировщиком NFWare от NFV. Даже если что-то выпадет, то звонок не оборвётся безвозвратно. ZooKeeper оркестрирует перераспределение нагрузки и досылает всё необходимое из Cassandra.

Так как участники подключены к разным серверам, транскодирование и другая обработка выполняется на отдельных серверах. Так что при потере отдельных узлов может мигнуть видео; возможно, некоторые участники автоматически переподключатся. Но звонок останется жив и в нём будет можно быстро продолжить общение.
Уменьшаем latency серверной архитектуры
Во-первых, если вы работаете с медиа внутри дата-центров, то включите везде TCP_NODELAY.
Во-вторых, нужно будет бороться с latency, которую генерирует сам сервер. Наш WebRTC-сервер написан на Java, что поставляет ещё один источник для jitter и увеличения latency — Java safepoints. JVM делает паузы в выполнении кода, во время которых совершает различные вспомогательные операции: GC, замену классов и методов JIT-компилятором, сбор стектрейсов и другое. Это случайные паузы, мы не можем полностью от них избавиться, но можем попытаться минимизировать их влияние на jitter.
Чтобы обеспечить низкую задержку в обработке медиаданных на Java-сервере, воспользуемся следующей установкой: чем реже и (или) короче паузы, тем лучше; несколько коротких пауз лучше, чем одна большая.
Исходя из этого, два типа операций в safepoints не сильно портят latency:
операции, которые выполняются не регулярно, а по запросу, например thread dump;
операции, которые выполняются быстрее, чем длительность фрейма (обновление inline-кешей, деоптимизация кода и т. д.).
Гораздо более существенное влияние оказывают паузы для сборки мусора — они могут доходить до 50 мс. Поэтому мы заменили GC с дефолтного G1GC на Shenandoah, ориентированный на низкие паузы. В результате длительность максимальной safepoint-паузы на conference-сервере стала около 10 мс, а на transcoding-сервере — 3 мс.
Кстати, для Jitsi этот трюк с GC тоже сработает, потому что Jitsi тоже написан на Java.
Data-channel
Кроме всех прочих действий по уменьшению задержки, мы изменили подход в передаче метаданных и используем data-channel — протокол доставки произвольных данных внутри транспортного UDP-потока вместе с SRTP аудио/видео, использующий SCTP.
Зачем это понадобилось, проиллюстрируем на примере метаданных по аудиоактивности — или, по-простому, на рамочке говорящего.

Выше на рисунке схема без data-channel. Между signaling-сервером и streaming-сервером есть обмен данными, из-за которого возникают накладные расходы:
дополнительная задержка метаданных, особенно в случае CDN (signaling и streaming могут быть в разных регионах);
лишняя нагрузка на серверную инфраструктуру;
рассинхрон соединений и плохой user experience — если, например, WebSocket ушёл в реконнект, а SRTP-транспорт работает — данные доходят, метаданные нет;
из-за большого трафика WebSocket конкурирует за канал с SRTP, сложно координировать адаптацию под сеть.
Так выглядит схема с data-channel:

Она даёт следующие преимущества:
переиспользование UDP-порта, нет head-of-line blocking и NAT unbinding;
мультиплексирование нескольких каналов с данными;
возможность создавать reliable-/unreliable-каналы.
Кроме того, что data-channel помог нам достичь изначальную цель и уменьшить задержку при доставке метаданных, получили дополнительные плюсы:
выше устойчивость в нестабильной сети, так как у протокола есть низкоуровневый доступ к сообщениям и буферу клиента, мы можем «схлопнуть» в одно несколько сообщений одинакового типа, когда они накапливаются в исходящем буфере (например, подсветки активных говорящих);
нулевая вероятность того, что при доставке данных потеряются метаданные, — потому что и те и другие доставляются по одному транспортному каналу.
Видеотреки
Наверное, главное узкое место в реализации звонков на неограниченное число участников возникает из-за WebRTC. Вместе с кучей коробочных решений и возможностью звонить прямо из браузера WebRTC приносит ограничение на число входящих видеотреков, которые можно поддержать.
В обычном сценарии от каждого участника звонка видео приходит на клиент со стриминг-сервера в отдельном треке:
с точки зрения RTP, трек — это пара SSRC: основной и retransmit;
с точки зрения WebRTC, под каждый трек необходимо создать MediaStreamTrack и RTCRtpReceiver.

Когда в звонок добавляется новый участник, для всех остальных клиентов создаётся дополнительная пара SSRC и происходит переобмен SDP между клиентом и стриминг-сервером. Когда участник выходит из звонка — соответствующая ему пара SSRC удаляется.
То есть чем больше участников, тем больше треков нужно держать клиентам, тем выше нагрузка и тем сильнее не хватает производительности на клиенте. В Chrome, например, звонок развалится на 50 треках, в iOS Safari — при количестве треков больше 1.
Чтобы ограничение на количество треков в одном peer connection нам не мешало, используем альтернативный подход:
перед открытием peer connection клиент сообщает серверу о том, какое количество видеотреков он в состоянии поддержать;
сервер добавляет в SDP соответствующее количество пар SSRC;
ни один SSRC не привязан к конкретному участнику звонка — вместо этого каждая пара SSRC играет роль «свободного слота», в который можно «поместить» видео от любого участника.
То есть аллоцируем столько треков, сколько видео может быть в лейауте, и подставляем туда нужные видео.

Таким образом, ограничено не общее количество собеседников, а лишь количество одновременно отображаемых. Клиент сообщает серверу, каких участников звонка он хочет отображать, и посылает информацию о любом изменении лейаута: уменьшении или увеличении размеров окна звонка, прокрутке и т. п.
Сервер, в свою очередь, принимает решение, в каком из треков отобразить каждого участника, и сообщает клиенту, в каком треке, с какого момента и какой участник будет показываться.
В результате можем делать звонки на практически неограниченное число участников — столько, сколько может потребоваться собрать в реальном звонке. И всё пройдёт без проблем у клиента. Как бонус — немного экономим сетевой трафик на посылке SDP:
при добавлении и удалении участников переобмен SDP не требуется;
даже если в звонке 10 000 участников, клиенту отсылаем в SDP гораздо меньше треков.
Must have для звонков на неограниченное число участников:
горизонтальное масштабирование звонка;
обход ограничения на число треков peer connection — мы сделали то, что называем «слоты»;
серверная топология SFU и микширование аудио в MCU;
продвинутая (нейросетевая) работа с аудио — VAD и шумоподавление.
Улучшаем алгоритмы
Вспомним, что в формальной постановке мы решаем задачу многокритериальной оптимизации:
Оказывается, можно завести модель, которая с помощью, например, градиентного бустинга будет предсказывать решение — то есть оценивать качество звонка до того, как вы его начали.
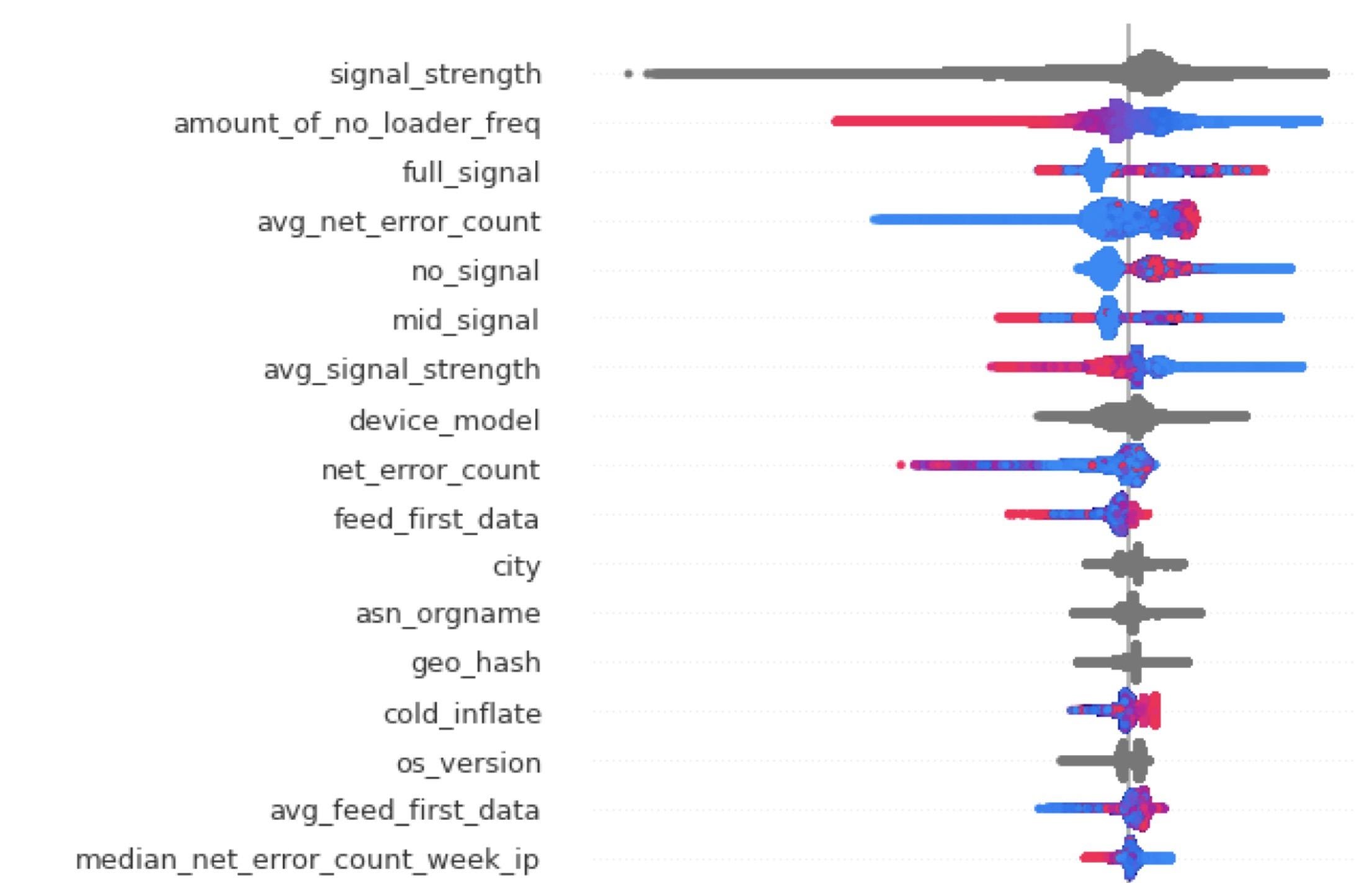
По таким пользовательским данным, как, например, уровень сигнала или то, как до этого работала сеть в приложении, можно предсказать качество звонка. Даже то, сколько ошибок было на вашем IP-адресе за последнюю неделю, может помочь нам предугадать, будет ли у вас в звонке всё хорошо или нужно перенастроить тот или иной алгоритм.
Что получилось в результате
Месячная аудитория звонков ВКонтакте — 20 млн пользователей, ежедневно на платформе совершается 6 млн звонков. У нас есть все важные функции, а главное, наша архитектура позволяет делать звонки на тысячи участников.

Вторая таблица показывает задержки в сравнении с сервисами, с которыми мы играем в одной лиге по числу участников. Казалось бы, эти данные должны больше говорить о качестве и интересовать нас сильнее.
Мы видим, что у Zoom большие задержки. Но также знаем, насколько он популярен, в том числе у требовательных бизнес-пользователей. В чём же дело?

Ответ в последней строчке: Zoom разменял задержку на работу в сетях с высоким packet loss. В ужасных условиях с packet loss 50% (это потеря каждого второго пакета!) у Zoom почти не возрастает задержка, а мы и Google Meet страдаем — и, скорее всего, звонок развалится ещё раньше.
Google Meet, в свою очередь, разменял задержку на работу в вебе и разгрузку WebRTC-клиентов.
Наше решение и по архитектуре, и по метрикам ближе к Google Meet: мы поддерживаем WebRTC, разгружаем клиентов, но боремся за каждую миллисекунду latency.
Будущее интернет-звонков
В заключение ещё пару слов о том, как с точки зрения технологий, а не продуктов, менялся мир VoIP за последний год. Главное, что нужно иметь в виду: во всех областях появились алгоритмы машинного обучения:
ML Voice activity detection на градиентном бустинге;
ML noise suppression на нейросетях;
ML-аудиокодек — Google Lyra (3 kbps);
ML-видеокодеки;
ML-улучшение изображения, лица;
ML-оптимизация параметров алгоритмов адаптации — решающие деревья;
ML-оценка качества звонков — NISQA;
ML-починка пропажи пакетов — WaveNetEQ чинит 120 мс (а классический PLC только 20 мс).
Жирным в списке выделено то, что мы ВКонтакте уже используем и где нейросети у нас уже вытеснили эвристические алгоритмы.
Общий подход к решению сложных инженерных задач
На примере сервиса видеоконференций мы рассмотрели этапы работы, которые применимы и для многих других задач.
Работая над любыми сложными инженерными решениями:
определите требования, сделайте опрос или коридорное исследование;
изучите теорию и формализуйте задачу — если у вас есть хорошая постановка задачи, то шансы на достижение результата сильно повышаются;
запустите решение (можно MVP на open source);
cоберите метрики;
определите, где вы находитесь относительно конкурентов, — это очень важно (и об этом иллюстрация ниже);
развивайте решение, опираясь на эти знания и метрики;
заменяйте классические (эвристические) алгоритмы на ML.
Всегда очень важно понимать, где вы находитесь с точки зрения результатов и стоимости решения. В рамках нашей сегодняшней темы: чем большее количество участников мы хотим обеспечить, чем ниже хотим задержки и выше качество, тем сильнее растёт сложность. И, как следствие, стоимость: разработки, владения, поддержки, развития.

То, что высокие требования делают решение более сложным, — это нормально. Но если вы оказались на красной траектории, что-то пошло не так.
Всегда, что бы вы ни разрабатывали, сравнивайте своё решение с продуктами конкурентов и корректируйте своё развитие, чтобы не оказаться по качеству на уровне open source, а по сложности на уровне самых продвинутых продуктов рынка.
И последнее, ответ на вопрос «Что мне с этим делать?». Варианта три:
встройте звонки в свой сервис;
пройдите собеседование в VoIP-команду и помогайте развивать один из существующих сервисов звонков;
начните свой стартап.
Или примените общую тенденцию, которую мы рассмотрели на примере звонков, — внедряйте ML. Почти все эвристические алгоритмы заменил ML, и в вашем проекте точно есть что улучшить с его помощью.
Комментарии (13)

wataru
25.11.2021 17:56История звонков ВКонтакте началась гораздо раньше:
Весьма громкое заявление, если учесть, что webrtc гугл пилит с 2011 года и сразу сделал на нем свой hangouts или как оно тогда называлось.
Или у вас какая-то своя собственная реализация?Да и в принципе WebRTC никак не реализует групповую топологию
Для груповых звонков webrtc умеет симулькаст. Вы ниже как раз об этом и пишете. Как раз потому что все-со-всеми звонок не скейлится вообще никак.

Aidar87
26.11.2021 19:53Вдобавок, Гугл опирался на исходник продукта от Global IP Solution, купленный компанией Google в мае 2010

alatobol Автор
27.11.2021 13:03Про «история звонков ВКонтакте началась гораздо раньше» там по тексту имеется в виду не раньше других сервисов, но сильно раньше пандемии. И когда видеосвязь стала так необходима, у нас уже была неплохая, чтобы соответствовать рынку.


iluha_vlg
26.11.2021 19:53+1Отличная статья, спасибо!
Решил попробовать звонок в ВК, но к сожалению даже на двоих пока не работает. Висит "Ожидание" и нет картинки от другого пользователя. Надеюсь скоро поправите.


23derevo
30.11.2021 11:22Мне всегда казалось, что Mesh — это скорее слово про репитеры (точки-коммутаторы). По идее, этим словом стоило бы назвать топологию, в которой Петя может гнать видео Кате, как через выделенный SFU-сервер, так и через другого участника звонка (Васю).
О том, чего стоит реализовать такую схему, и нужно ли оно — отдельный большой вопрос. Кажется, что для звонков скорее нет :)
@alatobolно в какой момент P2P топологию WebRTC-звонка (каждый с каждым) начали называть словом Mesh? Чо-то у всех вижу этот термин.
alatobol Автор
02.12.2021 14:20кажется это терминология webRTC https://webrtcglossary.com/mesh/
mesh можно делать, если групповой звонок на небольшое количество участников и не хочется вкладываться в серверное решение и CDN

enamchuk
07.12.2021 08:56Было бы здорово, если бы была возможность подключить ВК к телефонной станции по SIP, чтобы принимать вызовы.
Пользователи ВК могли бы звонить в техподдержку своего провайдера или справочную службу банка.
Teapot
Чем-то сильно напоминает сотовую связь, так скоро M2M соцсеть вещей увидим.
Jitsi небось активно JNI использует, как это сказывается на задержках?
ZGC ещё не молодец?
Выбирали ли системный аллокатор?
Bloof
> Jitsi небось активно JNI использует, как это сказывается на задержках?
Если имеется в виду Быстро ли делать JNI вызовы в натив, то да, быстро, оверхед приемлем. Если речь о том, что у нас какие-то операции в джаве, а у Jitsi в нативе, и может быстрее сходить в натив, то тут мы сравнений не проводили. А абстрактно это зависит от конкретных операций. Мы тоже не всё делаем в джаве. Например, сетевые вызовы идут через one-nio и linux сокеты, просто потому что в джаве не все есть. Например, нет sendmmsg. Для dtls шифрования мы используем Jitsi либу, которая использует openssl опять-таки через JNI.
> ZGC ещё не молодец?
Тоже молодец. На Java 17 и нашем размере хипа (10G) мы не увидели разницы против Shenandoah.
> Выбирали ли системный аллокатор?
При дефолтном аллокаторе в linux видели утечки памяти. Перешли на jemalloc. Когда-то пробовали tcmalloc, с ним не задалось. Также проверяли mimalloc, с ним футпринт вышел больше, чем с jemalloc.