
Когда говорят о выборе архитектуры IT-системы, почти всегда упускают один ма-а-аленький нюанс: мы делаем продукты для пользователей, не для себя. А пользователям совершенно неважно, какая у сервиса архитектура. Никто в отзывах не ставит звёздочки за event-driven подход или классную реализацию service mesh — разве что в редких случаях, когда речь о продуктах для разработчиков.
Техническое совершенство — современные инструменты, предельная оптимизация, чистота кода и лаконичная, но гибкая и масштабируемая архитектура — всё это нужно нам, технарям. А как это всё связано со счастьем пользователей, как его измерять и учитывать при проектировании сервиса, разберёмся под катом.

В прошлой статье мы выяснили, как построить отказоустойчивую систему и обеспечить первое пользовательское требование — чтобы сервис всегда был доступен. Здесь поговорим о том, какие архитектурные решения помогут сделать любую контентную платформу лучше для пользователей.
Искать связь между архитектурой и пользовательским опытом будем на примере VK Видео. Эта платформа объединяет все видеосервисы компании VK, содержит 5 000 серверов, хранилище на 1 эксабайт данных, обеспечивает до 2,5 млрд просмотров видео в сутки и 4 Тбит/с трафика. Чтобы проследить формирование платформы, оглянемся назад и посмотрим, с чего всё начиналось. А затем обобщим главные пользовательские метрики и разберём основные составляющие архитектуры:
История одного видеосервиса
Архитектура нашей платформы начала складываться почти десять лет назад. Картинка ниже — это артефакт из 2013 года: тогда в Одноклассниках мы создали такую схему архитектуры. И теперь это почти единственная документация, которая сохранилась с тех пор.

Тогда у нас было 10 млн ежемесячной аудитории, которые генерировали 50 млн просмотров в сутки и 100 Гбит/с трафика. Все видео умещались в хранилище на 5 Пбайт, а для обслуживания платформы хватало 200 серверов. Это несколько процентов от сегодняшних объёмов, но в то время это были неплохие нагрузки, которые уже требовали серьёзного подхода к разработке.
За почти десять лет развития платформы мы сделали многое. Например, всего на год позже YouTube поддержали 4К, сделали сервис трансляций и показали рекордный стрим на 3 Тбит/сек (подробности см. в этом докладе). На этой же базе создали сервис коротких вертикальных видео VK Клипы — раньше YouTube Shorts и подобных форматов у других социальных сетей.
В 2021-м объединили видеоконтент из соцсетей и сервисов VK и официально запустили VK Видео. С момента запуска уже вышло много продуктовых релизов: ML-автосубтитры, нейросетевая технология NeuroHD для повышения разрешения и FPS, офлайн-просмотр, приложение для SmartTV и другие технологии, о которых ещё поговорим в этой статье.
Изначальная архитектура позволила нам реализовать все эти новшества без существенной перестройки и глобального изменения подхода. Она состоит из блоков, из которых выстраивается архитектура любого контентного сервиса:
пользователи загружают контент на наши серверы;
мы его как-то преобразуем, чтобы потом эффективнее показывать другим пользователям;
сохраняем и раздаём.

У любого видеохостинга, сервиса для постинга фотографий или обмена музыкой примерно такая же структура. Но некоторые из них нравятся пользователям больше. Бывает, что мы бьёмся над качеством технических решений, а люди всё равно предпочитают конкурентов, у которых под капотом всё «на проволоке и изоленте». В этой статье попробуем разобраться, почему так и как связать счастье пользователей с техническими метриками.
Метрики пользовательского опыта
Есть разные метрики, которые помогают отслеживать, насколько аудитория довольна сервисом. Например, CSat (Customer Satisfaction Score) — это когда пользователь ставит приложению звёздочки в сторе; NPS (Net Promoter Score) — когда советует (или наоборот, не советует) сервис друзьям и коллегам; CSI (Customer Satisfaction Index) — баланс ожиданий, полученной пользы и качества; индекс TRI*M учитывает опыт использования, готовность рекомендовать продукт и продолжать работать с ним, а также мнение о преимуществах сервиса перед альтернативами. Все эти показатели можно и нужно измерять, проводя опросы.
Ещё есть множество технических метрик, на которые завязаны мониторинги. У всех нас прописаны SLI/SLO, мы следим за availability своих сервисов, измеряем и стараемся уменьшать latency, потерю пакетов, метрики приложения вроде PLT, TTI и LCP.
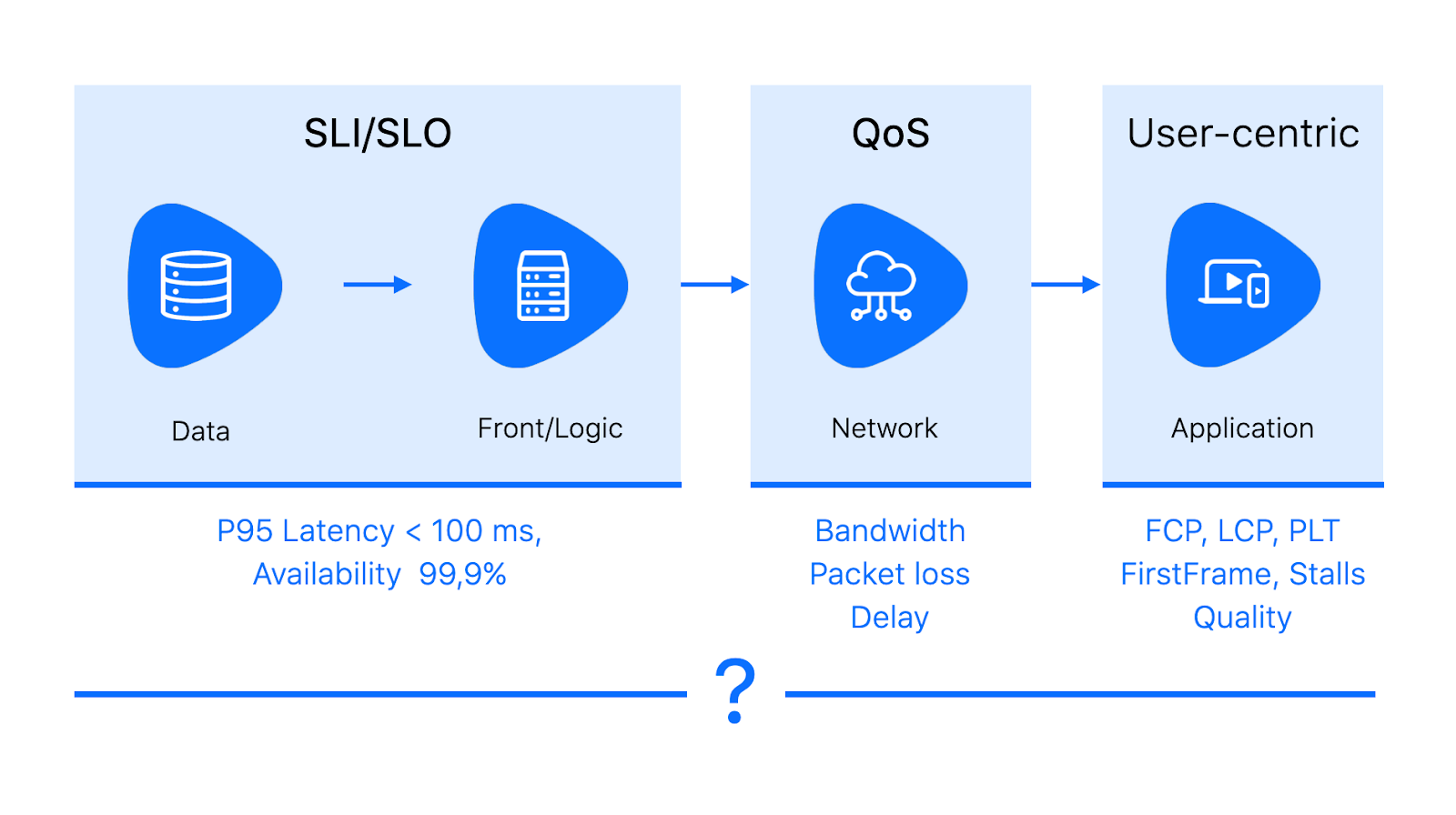
Свести всё это вместе можно через QoE — Quality of experience. Это обобщающая метрика родом из телекома. Она учитывает разные факторы, влияющие на восприятие системы целиком: от технических (задержек и качества сети) до характеристик устройства и самого пользователя (страна, образование). QoE обычно отображается в engagement (вовлечённости) и коррелирующем с ней счастье пользователя. Очевидно, что никто не станет много и часто пользоваться сервисом, который не устраивает. Но при этом счастье и удовлетворённость зависят ещё и от цены, бренда и других факторов.
QoE сильно коррелирует с продуктовыми метриками. Отслеживая её, можно увидеть, какие изменения в архитектуре сервиса и технологические решения влияют на мнение пользователей о продукте. Самый простой способ измерять QoE — это собирать MOS (mean opinion score): периодически просить пользователей оценить сервис по пятибалльной шкале, от «отлично» до «плохо».
Если собрать достаточно много оценок в разных ситуациях, то можно попытаться найти корреляцию удовлетворённости пользователя и некоторых технических параметров. Например, в исследовании о QoE-driven видеостриминге в LTE-сетях приводится зависимость MOS от битрейта видео.

В другой статье MOS измеряют относительно FPS. Результаты холиварные: разница между 15 и 30 FPS очень существенная, повышение с 30 до 60 FPS даёт небольшой прирост MOS, а FPS больше 60 практически не улучшает пользовательский опыт. Но эти данные за 2011 год. Возможно, с тех пор мы стали придирчивее и лучше замечаем разницу в кадровой частоте.

Пользовательские ожидания год от года растут: то, что недавно было стандартом качества, скоро может стать неудовлетворительным. А ещё в определённых обстоятельствах метрики могут конфликтовать между собой. Например, при недостаточной пропускной способности сети нужно искать компромисс между битрейтом и FPS — и находить баланс тоже лучше через метрики и эксперименты.
QoE также применима к веб-сервисам (см. статью Waiting times in quality of experience for web based services). В частности, можно увидеть, что к разным видам действий немного разные требования по Page Load Time (PLT): картинки должны загружаться мгновенно, а результатов поиска пользователи готовы секундочку подождать. Но в любом случае после ожидания больше 200 мс оценки начинают проседать.

Хорошие показатели QoE не гарантируют успех у пользователей, но без них завоевать аудиторию вряд ли получится. Дальше на примерах рассмотрим основные составляющие видеоплатформы и ключевые характеристики, влияющие на QoE.
Загрузка: скорость
Требования пользователей к загрузке и скачиванию файлов полностью описывает мультик двадцатилетней (!) давности.
Но с тех пор сильно изменились и размеры файлов, и ожидания от качества и скорости загрузки. Загрузка обязана быть отказоустойчивой и возобновляемой — как этого добиться, рассказываем в другой статье. Остаётся вопрос скорости: быстро — это как?
Метрики говорят, что если небольшой файл не загружается за 5–7 секунд, то пользователь начинает нервничать. На графике ниже пример с файлом в 25 Мбайт: сейчас это короткое видео, несколько фотографий или небольшая презентация. А ещё видно, что и для больших объёмов ждать 2 минуты никто не хочет.

Причём рядовой пользователь не хочет и не должен разбираться, на чьей стороне проблема: дело в неустойчивой сети, слабом телефоне или сервис действительно плохо работает. Человек, скорее всего, просто останется недоволен приложением.
Чтобы ускорить upload, нужно эффективнее использовать пропускную способность. Вариантов для этого не так много: HTTP/1.1, HTTP/2 и HTTP/3.
HTTP/1.1 и загрузка чанками
Работает так: разбиваем файл на чанки; отправляем целиком первый блок данных POST-запросом, ждём ответа 200 OK (здесь появляется задержка в RTT — Round Trip Time), затем отправляем следующий блок новым POST-запросом.
Допустим, чанки размером по 4 Мбайта. Тогда, чтобы загрузить файл в 1 Гбайт, понадобится 256 лишних RTT, то есть 38 секунд при RTT = 150 мс (это, в принципе, немного: RTT может быть и 400 мс).
HTTP/2 и мультиплексирование
Конечно, если использовать мультиплексирование и в одно соединение запихнуть несколько потоков, будет быстрее.

Проблема HTTP/2 в том, что, чем больше потеря пакетов, тем сильнее снижается эффективность утилизации сетевого канала (подробнее в статье о сетевом стеке).
HTTP 1.1 и параллельная загрузка
Проведя замеры, мы пришли к выводу, что лучшим вариантом для ускорения будет параллельная загрузка. То есть открывать столько соединений до сервера, сколько позволяет браузер или приложение, и в 4–6 потоков по частям загружать файл.

Причём такой способ как минимум не проигрывает относительно HTTP/3. Скорость загрузки будет либо такой же, либо даже выше — за счёт большего количества подключений и «не fair» распределения канала связи. К тому же TCP всё равно всегда нужен для фолбэка.
Если нет времени и ресурсов делать свой загрузчик, то можно использовать открытую библиотеку tus в связке с S3-хранилищем. Возможно, это будет не так эффективно и потребуется много доработок для обеспечения качества сервиса, но настройки для параллельной загрузки там тоже есть.

Что может пойти не так на этапе загрузки?
На объёмах до 14 млн новых роликов в сутки всё, что может пойти не так, рано или поздно стрельнёт. Для примера допустим, что мы в параллельной загрузке раздаём чанки потокам по одному, как игральные карты. То есть первый поток грузит первый, пятый, девятый чанки и так далее, второй — второй, шестой... Тогда, если один из потоков устанет и перестанет работать, получится слишком много дыр, список которых для ретрая просто переполнит HTTP header.

Максимальный размер HTTP header зависит от того, что вы используете — nginx или Apache. Но он в любом случае ограничен и может переполниться. Поэтому мы раздаём чанки потокам, по сути, последовательно — то есть ближайшие неотправленные.
Другая проблема возникает с DNS-запросами — она редкая, но коварная. Оказывается, что два DNS-запроса, отправленные подряд, могут зарезолвиться на разные IP и в разные дата-центры из-за TTL. Тогда, даже с учётом распределённого хранения состояния, загрузка становится медленнее — и в принципе возможно, что одни и те же чанки будут грузиться в разные дата-центры. При построении отказоустойчивой высоконагруженной системы нужно предусматривать и такие ситуации и уметь их разрешать.
В комплексе все меры, повышающие надёжность и ускоряющие загрузку, увеличили QoE нашего сервиса. Мы получили +7% успешных загрузок, то есть существенно повысили вовлечённость аудитории.
Специфика видеофайлов
Видео состоит из кадров. Если передавать его просто как набор полных кадров, то для 4К-видео в 60 FPS потребуется сеть с пропускной способностью на 18 Гбит/с. Это может обеспечить HDMI-кабель длиной несколько метров, но не обычная пользовательская интернет-сеть. Поэтому видео кодируется так, чтобы только часть кадров передавать в полном разрешении, а остальные кодировать через изменения относительно предыдущих. Так для 4К-видео становится достаточно 50 Мбит/с.
Каждые несколько лет появляется новый кодек, который примерно в два раза эффективнее предыдущего по степени сжатия, но и вычислительно затратнее. VP8, VP9 — открытые стандарты, которые разрабатываются в основном в Google. H.264, H.265, H.266 — лицензируемые форматы. AV1 разрабатывается «Альянсом за открытые медиа», в который входят AMD, Nvidia, Apple, Google, Microsoft и многие другие компании.
Кодек |
Год |
Эффективность относительно предыдущего |
Аппаратная поддержка на сервере |
Android |
iOS |
||
decoder |
encoder |
decoder |
encoder |
||||
H.264 |
2003 |
baseline |
GPU, CPU |
HW |
HW 3.0+ |
HW |
|
VP8 |
2008 |
0% |
CPU |
HW/SW |
SW 4.3+ |
SW |
|
H.265/HEVC |
2013 |
50% |
GPU, CPU |
5.0+ |
— |
SoC, iOS11 (faceTime) |
|
VP9 |
2012 |
CPU, GPU |
Snapdragon, Exynos |
— |
|||
AV1 |
2018 |
35% |
CPU, GPU |
Exynos |
coming soon |
||
H.266/JVET |
2021 |
50% |
|||||
Источник и детальные сравнения видеокодеков: compression.ru/video/codec_comparison/index.html
Чем старше кодек, тем обычно шире у него поддержка. В большом сервисе с разнообразной аудиторией, конечно, требуется поддерживать все популярные форматы и уметь между ними переключаться.
Знакомые расширения файлов: MP4, Matroska, 3GP — это контейнеры. Спецификации контейнеров описывают формат по размещению медиаданных в одном файле. Контейнеры, по сути, содержат видео и аудио, упакованные разными способами, чтобы их было можно было перематывать или запускать с середины.

Транскодирование: качество
Пользователи ежедневно загружают на нашу платформу миллионы новых видео в самых разных кодеках, контейнерах и разрешениях. Мы, в свою очередь, должны их показать на всех устройствах и с любой сетью. Для этого видео надо преобразовать во всевозможные форматы — это и есть задача этапа транскодирования.

Главное требование — сжимая видео, сохранить адекватное разрешению качество.
Для оценки качества видео есть такие метрики, как PSNR, SSIM, VMAF.
PSNR — пиковое отношение сигнала к шуму. Проще всего его определять через среднеквадратичную ошибку. SSIM, или индекс структурного сходства, в отличие от PSNR, отражает «восприятие ошибки» благодаря учёту структурного изменения информации. VMAF (Video Multimethod Assessment Fusion) разработана в Netflix в 2016 году, чтобы предсказывать субъективное восприятие качества видео.
По большому счёту, все они пытаются смоделировать то, как сжатую картинку или видео оценил бы человек. Ниже на графиках видим: по горизонтальной оси MOS-оценка для нескольких образцов из разных доменов, по вертикальной — смоделированная. Чем меньше расстояние от точек до диагонали, тем ближе предсказанная и фактические субъективные оценки. И значит, точнее метрика.

Судя по этим диаграммам, VMAF — лучшая метрика для оценки качества видео. Правда, это диаграммы из whitepaper от Netflix, в которой VMAF как раз и презентуется. По другим независимым тестам (например, здесь) корреляция VMAF с MOS не такая уж хорошая. Оттуда же следует, что лучше всего методика Netflix применяется к видео в высоком разрешении — что логично и соответствует их доменной области онлайн-кинотеатра.

Для пользовательского видео с бюджетных смартфонов или регистраторов может быть эффективнее и удобнее измерять метрики попроще. Главное, как всегда, хоть как-то замерять и мониторить динамику. Потому что проблема с транскодированием в том, что нужен баланс между временем и ресурсами, которые затрачиваются на преобразование, и потерей качества.
За неограниченное время с неисчерпаемыми вычислительными ресурсами можно, наверное, добиться того, что транскодированное видео будет неотличимо от исходного. Но мы помним, что пользователи не любят ждать. Поэтому в своём пайплайне зафиксировали допустимое окно PSNR в 43–44 дБ и в этих рамках стараемся ускориться.
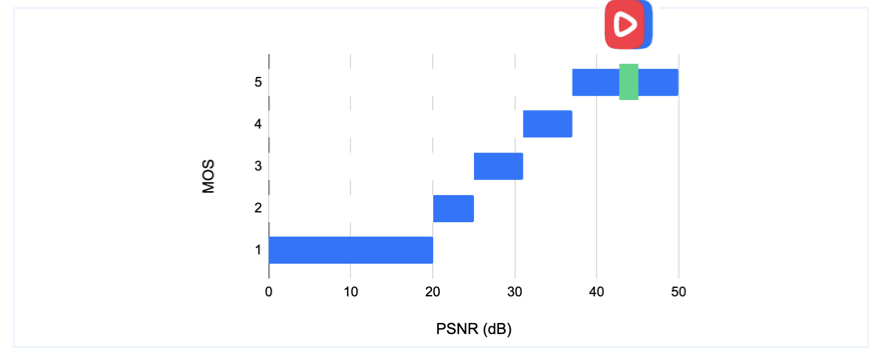
Мы отказались от стандартного и вполне рабочего варианта реализации транскодирования с помощью FFmpeg. Вместо него написали поверх libav свой транскодер и используем аппаратный энкодер Nvidia NVENC для GPU — подробнее о наших изменениях относительно FFmpeg рассказываем в этом видео.
В результате всех этих ухищрений получили прирост по скорости обработки в FPS на 30 %. Также улучшили время процессинга: обработка 15-минутного видео размером 1 Гбайт занимает 6 минут на GPU и 8 минут на CPU — а у конкурентов примерно 10 минут.
Мгновенная доступность
Мы ускорили загрузку и транскодирование — и увидели, что наши пользователи могут начинать смотреть видео быстрее, чем на других сервисах. И, было дело, обрадовались этому результату. Но фидбэк авторов был неутешительным: «Почему моё видео не доступно сразу же после того, как я его загрузил? Почему его могут посмотреть только через несколько минут?» И действительно: например, для новостей это может быть критично.
Поэтому мы переосмыслили весь процесс и перешли к транскодированию on-demand. Видео в исходном формате можем прокинуть прозрачно, а если требуется другое разрешение или кодек, то нарезать по запросу на лету. По сути с точки зрения транскодирования это похоже на прямые трансляции, но только для многогигабайтного видеофайла и с произвольной позиции в медиафайле.
В целом процесс довольно простой: читаем заголовок файла; находим и вычитываем нужные семплы; скармливаем их транскодеру на базе ffmpeg; передаём результат на сервер, раздающий сегменты видео. Сейчас мы работаем только с MP4, так как больше 80 % видео к нам загружают именно в нём. Если от пользователя приходит другой формат, например mkv, то ремуксим его в MP4 — это чуть дольше, но всё равно быстрее полного транскодирования.
Несмотря на то что идея простая, мы пришли к ней далеко не сразу — думали, что на лету резать терабайты видео будет невозможно. Но за счёт кеширования нагрузка почти не возрастает: тратим примерно 4 000 vCore. А бонусом к качеству клиентского сервиса ещё и экономим до 40–50 % места в хранилище — во всех разрешениях храним только популярные видео, для остальных роликов достаточно исходного. С точки зрения баланса ресурсов и улучшения сервиса мгновенная доступность оказалась очень выгодным решением.
Раздача: надёжность, скорость, качество
Большая часть трафика из общих 4 Тбит/с приходится на небольшой процент популярного контента. Поэтому сервер раздачи по сути является большим кеширующим сервером. Есть кеширование на разных уровнях: в оперативной памяти (LRU — least recently used) и на диски (LRU и FIFO — first in, first out), на центральном сервере и на CDN и т. д. Кеширование защищает хранилище от перегрузок.

Кешируем не целиком файлы, а блоками по 256 Кбайт. Обязательно первый кадр, так как начало видео смотрят больше, чем остальную его часть. А также превентивно качаем вперёд по K блоков, не дожидаясь обращения.
Чтобы использовать сервер эффективно и раздавать на скорости 100 Гбит/с, мы перенастроили сетевой стек, работу с прерываниями и NUMA. Подробнее рассказываем в статье об отказоустойчивости нашей архитектуры.

Балансировка
Для раздачи мы используем порядка 200 серверов — это немного на фоне их общего количества в 5 000. Трафик на отдачу в вечернее время сейчас составляет около 4 Тбит/с, но, естественно, мы должны быть готовы к его кратному росту. Поэтому балансировка для нас очень важна и требует тщательного выбора архитектурных решений.
Чтобы обеспечить эффективную раздачу с точки зрения ресурсов и скорости доставки данных до пользователей, используем согласованное хеширование (consistent hashing) по всему контенту. Оно устроено так, что по сути каждый сервер отвечает за определённый контент. Если он выйдет из строя, не потребуется переназначать все ключи.
При этом самый популярный контент раздаётся с большего числа серверов, при необходимости — со всех сразу.

У серверов раздачи обязательно есть лимиты на нагрузку. Если на сервере слишком высокая нагрузка на CPU, память и диски — из-за DDoS или по другим причинам, — то сервер нужно разгрузить, перенаправляя трафик на другие.
Рассмотрим на примере, почему нельзя перегружать серверы. Плеер кеширует видео и заранее скачивает сегменты суммарной длительностью, например, в минуту. Допустим, на сервере раздачи случилась какая-то локальная проблема — например, мигнула сеть у провайдера. Весь буфер израсходовался на то, чтобы нивелировать перебои в скачивании. В ответ плеер начинает активнее скачивать сегменты, чтобы заполнить буфер. Если видео популярное и проблема задевает сразу многих клиентов, то сервер раздачи получает удар трафиком: сразу много запросов на быстрое скачивание.

Успеть обработать такой напор и предотвратить лавину на уровне балансировки физически не получится. А это именно лавина: сервер не справляется с нагрузкой, выходит из ротации, включается хеширование, данные перераспределяются, ключи перестраиваются… и так сразу с кучей серверов.

Защищаться нужно на уровне сервиса. Если сервер не справляется с нагрузкой, можно не выводить его сразу из оборота, а деградировать. Сервер должен сам защищаться от пользователей. Мы используем throttler и не отдаём видео быстрее, чем ×3 от скорости просмотра. Дальше задача плеера — разобраться, что делать, и при необходимости понизить качество воспроизведения. Для этого есть алгоритмы адаптивного стриминга.

Этот же подход помогает защищаться от DDoS — очень трудно «задидосить» систему, рассчитанную на десятки Тбит/с. Если какой-то сервер подвергается DDoS-атаке, мы выводим его из ротации и продолжаем спокойно обслуживать пользователей. Злоумышленники атакуют следующий сервер — у нас в запасе есть ещё и так далее.
CDN
Кроме скорости раздачи, время доставки контента зависит от физического расстояния между пользователем и серверами с данными. Быстрее скорости света они, как ни крути, не долетят. Поэтому для быстрой раздачи глобальному сервису необходим CDN.

В нашей сети больше 50 узлов, расположенных в разных регионах России и мира. Но само по себе количество узлов CDN не гарантирует быстрой доставки. Нужно ещё отправить запрос пользователя на тот сервер, с которого действительно будет быстрее загрузить контент.
Базово есть два типа реализации CDN: GeoDNS и AnyCast CDN.

При GeoDNS общий хост превращается в IP-адрес сервера раздачи на нашем DNS-сервере. Когда пользователь запрашивает видео или любые другие данные по ссылке вида https://video.mycdn.me/?id=12345&q=1080, мы независимо от расположения отдаём один адрес — https://video.mycdn.me/. Резолвим его на конкретный сервер на уровне нашего DNS, в идеале на ближайший к пользователю.
Есть несколько проблем с этим подходом:
Если какой-то из DNS Recursor на пути запроса не поддерживает EDNS, до нашего DNS-сервера не долетит IP-адрес клиента. Тогда мы не сможем вычислить ближайший сервер и вернём центральный. EDNS осознанно выключен, например, на крупном DNS-резолвере 1.1.1.1. Утверждается, что как раз для того, чтобы не раскрывать адрес пользователя и обеспечить приватность.
DNS-сервер видит только доменное имя, но не весь запрос. Это делает неэффективным кеширование. Вот почему: мы делим контент на партиции, а партиции фиксируем за конкретными серверами на площадках. И все запросы за видео id=12345 из примера внутри площадки стоит отправить на один и тот же сервер — но на уровне DNS-запросов это не решить.
Есть проблемы с оперативным выводом серверов из ротации, так как DNS-ответы кешируются серверами.
Такая схема хорошо работает для статики: CSS, JS, небольших картинок. То есть когда все серверы хранят одно и то же и нет проблем с партиционированием. Но подход плох для тяжёлого и часто обновляющегося контента типа видео.
При AnyCast CDN общий хост превращается в один адрес сервера раздачи. Ближайший сервер определяется уже на сетевом уровне в момент установки соединения — этим занимаются маршрутизаторы провайдеров. То есть, как и GeoDNS, мы всё ещё выдаём общее доменное имя и https://video.mycdn.me/ превращается в условные 12.3456.78. Но на сетевом уровне трафик до этого IP-адреса, когда он приходит в нашу AS (автономную систему), направляется на ближайший сервер.
Так за одним IP может скрываться несколько разных серверов. Это решает некоторые проблемы GeoDNS, но и привносит новые:
нужны хитрые манипуляции на сетевом уровне — например, поддерживать TCP-соединения;
требуется, чтобы все серверы были в нашей AS — а с провайдерскими площадками такое невозможно. В нашем CDN есть как собственные дата-центры, так и провайдерские.
Поэтому у нас своё решение и мы всегда выдаём ссылки на конкретный хост конкретной площадки, который закреплён за запрашиваемой партицией видео. Определяем его исходя из IP-адреса пользователя и данных, которые нам сообщают провайдеры (список подсетей по BGP). Благодаря нашему BGP-коллектору маршрутов мы точно знаем, какой длины AS path между клиентом и каждой нашей площадкой, доступной для него. Вычисляем ближайшую не по расстоянию, а по длине сетевого маршрута.

Если основной сервер перегружен или проблемы на площадке, мы найдём чуть менее подходящую и отдадим ссылку на неё. Также выдадим резервную ссылку на какой-то из серверов центрального дата-центра — плеер будет дублировать запросы. Если во время просмотра длинного видео что-то пойдёт не так на ближайшей к пользователю площадке, проигрывание не прервётся.
Эта схема позволяет реализовать два режима кеширования:
Когда все видео, которые смотрят с какой-то площадки, раздаём с неё — это удобно некоторым провайдерам, которые хотят, чтобы весь трафик шёл через серверы на их площадке.
Когда по IP-адресам пользователей собираем на площадке топ популярных видео именно для неё, с учётом мощности серверов и объёма канала.
Так мы экономим канал от площадок до центрального дата-центра в Москве и повышаем эффективность кеширования. Например, есть площадки, для которых соотношение трафика к клиентам (downlink) и трафика от площадки до дата-центра (uplink) равно 40:1.
Несмотря на то что большинство проблем с качеством видео возникает на «последней миле», CDN позволяет до 1,5 раз сократить time-to-first-byte и в результате примерно на 20 % повысить качество видео.
Говоря о раздаче, нужно упомянуть QUIC. В прошлом году мы ускорили ВКонтакте в два раза, переведя на QUIC доставку статики и картинок. Как мы это запускали, подробнее про результаты и как вам это применить у себя, читайте в отдельной статье. А недавно мы внедрили этот протокол и для видео.
Результаты от внедрения QUIC для доставки видео пока не такие впечатляющие. Но для пользователей с самыми сложными сетевыми условиями улучшение действительно есть: 90-й перцентиль по time to first byte и tyme to first frame снизился на 20–25 % в зависимости от платформы и типа контента. В предельных случаях ускорение может достигать и нескольких раз. Для обычных ситуаций видим уменьшение количества фризов на 3 % и ускорение по ttff и ttfb на проценты. Здесь нам ещё есть куда расти — когда получим удовлетворяющие нас результаты, обязательно расскажем подробности.
Воспроизведение и просмотр: CAP-теорема для видео
Последний этап, на котором замыкается путь видео, снова связан с клиентом. От плеера зависит, насколько комфортным будет просмотр. Если точнее, 2,5 млрд ежедневных просмотров роликов на нашей платформе.
Помним, что метрика пользовательского опыта зависит от битрейта, времени старта, количества буферизаций (событий stall) и других факторов.

В CAP-теореме для видео три компонента, между которыми приходится балансировать: это качество, скорость старта и количество буферизаций.
Например, если всё показывать в минимальном разрешении, то это будет быстро и без сбоев-крутилок. Или можно начать показывать видео только после того, как закешируется его значительная часть (а лучше — всё целиком). Это хорошо для качества, но пользователь может не дождаться старта.
При этом пропускная способность сети практически всегда переменная, особенно в беспроводных сетях. Поэтому балансировать приходится не один раз на видео, а непрерывно. За это отвечают алгоритмы адаптивного стриминга.
Адаптивный стриминг
Базово есть две стратегии: одна основана на предсказании пропускной способности, вторая — на размере буфера.
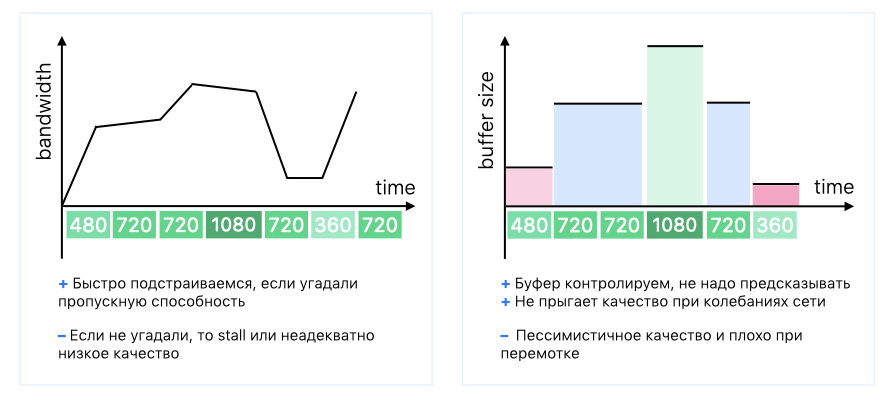
Для обоих вариантов есть математические модели и строгие алгоритмы. Но эффективность первого упирается в то, что в реальных условиях прогнозировать пропускную способность очень трудно. А второй подходит только для линей⁸ного просмотра.
Поэтому на практике используется гибридная схема.

Оценивается и размер буфера, чтобы не возник stall, и пропускная способность, чтобы определить максимальный битрейт, который можно передать.
HLS vs DASH
Плеер на клиенте получает манифест с информацией о доступных качествах, их битрейте и расположении соответствующих сегментов видео. Формат манифеста зависит от выбранного протокола адаптивного стриминга. Тут, конечно, есть конкурирующие варианты: HLS от Apple и DASH от Google.
Манифест HLS состоит из двух уровней вложенности. Сначала указаны битрейты каждого из качеств. На схеме, например, для самого нижнего качества прописан битрейт 200 Кбит/с. Также указано, где брать сегменты в соответствующем качестве. На втором уровне для каждого разрешения прописаны сегменты и их длительность. Из-за этой вложенности на первом кадре возникает лишний RTT (запрос на сервер) и проигрывание стартует медленнее.

MPEG-DASH организован чуть проще: в нём есть манифест с качествами, а индекс просто прописан в начале файла.

То есть на запрос с выбором качества плеер сразу получает нужный сегмент. И значит, до first frame проходит на целый RTT меньше времени (это примерно 100–500 мс). Причём root-манифест можно отдавать заранее, чтобы ещё ускорить старт.

В остальном сейчас технологии HLS и DASH сравнимы по возможностям. Но когда в 2014 году мы запускали 4К, то безальтернативно использовали DASH, так как в HLS поддержка 4К появилась только в 2017-м. DASH поддерживает больше кодеков, включая свободные VP8 и VP9, а HLS поддерживается большим количеством устройств.
HLS |
MPEG-DASH |
|
Кодек |
H.264, H.265* |
любой, например VP9 |
Транспорт или контейнер |
mpeg2-ts, mp4 c 2016 |
mpeg2-ts, mp4, webm |
4K |
c 2017 |
+ |
Манифест |
m3u8 |
mpd |
RTT до данных |
2 |
1 |
Adoption |
iOS, Android 4+ |
Android |
Ключевое преимущество |
Выше adoption |
Больше возможностей |
С HLS удобнее начинать разрабатывать свой видеосервис, так как он более распространён. DASH при тонкой доводке позволит добиться лучшего качества
Плееры
Под все клиенты есть популярные плееры, которые реализуют адаптивный стриминг.
Для веба это Shaka Player, dash.js, hls.js. Если вы делаете стриминг и можете проигрывать DASH, то берёте dash.js — и у вас есть нормальный плеер. Мы запилили свой, чтобы работал стабильнее и быстрее, плюс поддерживал всё, что нам нужно.
% Video with stalls count |
Avg stalls duration |
First frame p50 |
First frame p95 |
% HD |
|
Shaka Player |
16 % |
2 050 мс |
705 мс |
3 800 мс |
32 % |
dash.js |
5 % |
375 мс |
600 мс |
4 200 мс |
30 % |
hls.js |
13 % |
580 мс |
860 мс |
5 800 мс |
26 % |
VK Video |
4 % |
385 мс |
535 мс |
2 900 мс |
42 % |
В табличке выше некоторые из метрик, на которые мы ориентируемся:
процент воспроизведений с хотя бы одним stall’ом;
среднее время stall’ов за всё воспроизведение ролика;
время до первого кадра по перцентилям (от открытия видео, например, кликом по кнопке play до начала проигрывания);
процент проигрываний видео в HD — позволяет понять, как часто можем проиграть хорошее качество. Это показательнее, чем битрейт, потому что битрейт не обязательно означает рост качества.
Для Android есть open-source ExoPlayer, который умеет играть и DASH, и HLS. Ещё его при необходимости можно дотюнить. Для iOS — AVPlayer: закрытый, поддерживает только HLS.
При сравнимом битрейте среднее время до первого кадра составляет:
~660 мс на Android в ExoPlayer — после оптимизаций и с учётом распределённости нашей большой аудитории;
~790 мс на iOS в AVPlayer — и это после всех танцев с бубном. Например, AVPlayer всегда стартует с того разрешения, которое прописано в манифесте на первом месте. Напишете 4К — будет пытаться загрузить 4К, а только потом адаптироваться.
Поэтому мы отказались от AVPlayer и под iOS запилили свой плеер. Получили:
На 28 % быстрее first frame — 50-й перцентиль ~510 мс. Отличается от Android в том числе потому, что пользователи iOS чаще живут в крупных городах с лучшей сетью.
На 5 % реже возникают буферизации (stall).
На 100 Кбит/с выше средний битрейт. Наш плеер позволяет в тех же условиях смотреть видео в лучшем качестве.
На 6 % выросла продуктовая метрика просмотров.
Более подробно о том, что потюнить в ExoPlayer и как написать свой плеер, читайте в этой статье. Или можно просто использовать наш плеер и получить весь профит из коробки — через SDK VK Видео для веба, iOS и Android. В SDK также входят загрузчик и инфраструктурные решения для видео и прямых трансляций. Для управления контентом используется gRPC-шина.
Основные профиты от архитектурных решений в QoE- и бизнес-метриках:
С повышением надёжности и ускорением загрузки количество успешных добавлений видео на платформу выросло на 7 % — а вместе с ним и вовлечённость аудитории.
Транскодирование в обход FFmpeg позволило обрабатывать видео на 30 % быстрее. Но мгновенная доступность и транскодирование на лету ещё лучше. Пользователи довольны, нагрузка выросла незначительно, а в хранилище экономим до 40–50 % места.
CDN позволяет до 1,5 раз сократить time-to-first-byte, QUIC — для видео пока только на 25 %, и то по 90-му перцентилю.
С кастомными плеерами снижаем количество stall’ов и сокращаем время старта, получаем прирост в просмотрах.
ML на службе у метрик пользовательского опыта
Мы улучшили пайплайн там и тут. Сделали, чтобы видео быстрее грузилось, транскодировалось на лету, бодро стартовало, лучше адаптировалось под сетевые условия и показывалось в максимально возможном качестве. Но есть большое «но»: на платформе много UGC-контента разного уровня и с разным разрешением исходника. А пользователи оценивают сервис в том числе и по качеству того, что они видят: в ленте, в разделе с видео, в рекомендациях.
Так что берёмся и за это. На помощь приходит ML — как ещё улучшить видео с регистратора или сделать, чтобы пользователь видел ролики, которые ему точно понравятся.
Чтобы повысить качество видео на платформе, мы разработали технологию NeuroHD. Она с помощью нейросетей повышает разрешение и интерполирует кадры, увеличивая FPS. Эта технология вписана в основной пайплайн транскодирования. То есть, по сути, улучшенное видео является одним из вариантов разрешения и нарезается как одно из разрешений.

Ключевое требование здесь — производительность. Точнее, баланс качества и производительности: это должна быть массовая технология, которую мы сможем предоставить всей аудитории, а не рендер одного видео в сутки. Поэтому мы улучшаем видео по запросу через очередь, задействуя свободное от транскодирования оборудование, и ускоряем нейросетевую обработку с помощью TensorRT. Как только добьёмся желаемых результатов, поделимся всеми подробностями и архитектурой, учитывающей временную консистентность. Это тема для отдельной статьи.
Ещё о вызовах для ML: иногда оказывается, что надо работать не с видео, а с аудио. Вернее, сделать так, чтобы видео можно было смотреть совсем без звука — с субтитрами. Эту задачу решаем с помощью собственной технологии распознавания речи и генерации автоматических субтитров. На видео с ними приходится больше 10 % просмотров видео в ленте. Ещё субтитры становятся источником данных для качественных рекомендаций. Какие модели лежат в основе нашего распознавания речи и как устроен пайплайн с точки зрения инфраструктуры, подробно расскажут коллеги на Saint HighLoad++.
И это ничто по сравнению с качественными рекомендациями. С помощью модифицированного YouTube-8M, собственного распознавания лиц и распознавания речи мы знаем о видео всё: какого оно жанра, что там происходит, какие люди и предметы в кадре.
Для примера — воронка для VK Клипов.

Из миллионов доступных интересных видео мы отбираем 5 тысяч — это персональные рекомендации, полученные с помощью матричной факторизации, топы по любимым категориям, видео из рекомендованных сообществ и подобное. Ранжируем и, соблюдая требование к разнообразию контента, формируем ленту. Делаем это в real-time и перестраиваем рекомендации в ответ на каждый новый сигнал от пользователя: кроме явных «Нравится», «Это не интересно» и комментариев учитываем менее явные пролистывание, глубину просмотра и многое другое.
Продуктовый результат от рекомендаций — +111 % просмотров по сравнению с прошлым годом. Напомню: улучшения в пайплайне, которые растят продуктовые метрики на 5 %, мы считаем очень эффективными.
Для длинных «классических» видео к рекомендательной системе добавляется способ представления. С помощью ML можно подбирать обложки или превью по предпочтениям разных аудиторий. Для обложек мы используем многоруких бандитов и учитываем соцдем: в этой статье подробнее рассказываем об этом.
Ниже пример для обычного пользовательского ролика, автор которого не выбрал, что показывать на обложке. Поэтому мы можем поэкспериментировать и узнать, что:
кадр с юношей не вызывает у зрителя интереса — в том числе потому, что этот ролик в рекомендациях, скорее всего, покажется преимущественно парням;
девушка с ведром мороженого явно больше нравится зрителям;
девушка без мороженого снова проигрывает;
парням больше нравится обложка с двумя девушками и мороженым — её конверсия целых 17 %.

Для сравнения, конверсия в просмотр у случайной обложки была бы в районе 1 %. У общей обложки, выбранной с помощью многоруких бандитов, — 14 %. А у выбранной с учётом дополнительных соцдем-факторов — 15 % (показывали в основном мужчинам, поэтому в суммарной конверсии они учитываются с бо́льшим весом).
Тем временем ML проникает и в задачи, которые традиционно считаются алгоритмическими. Например, есть попытки сделать кодек, основанный на ML, и использовать машинное обучение в структурах данных.
Приближайте будущее — внедряйте машинное обучение! Но не забывайте об отказоустойчивости и эффективной утилизации ресурсов. ML — это зачастую дорого.
Итого. Как технические решения повлияли на метрики
Быстрая возобновляемая загрузка повышает вовлечённость — +7 % успешных добавлений видео на платформу.
Переход на GPU и замена FFmpeg на собственное транскодирование позволяет ускорить процесс на 50 %. Но моментальная доступность ещё круче.
CDN даёт +20 % качества, QUIC ускоряет старт и уменьшает количество фризов.
Собственный iOS-плеер даёт +6 % смотрения, тюнинг ExoPlayer на Android — +3 % смотрения. А люди больше смотрят, только если видео лучше проигрывается.
ML-рекомендации с анализом контента — +111 % смотрения.
Мы разобрались, как можно измерить счастье пользователей и связать его с техническими метриками. Но найти прямую связь между счастьем пользователя и архитектурой сложной системы нам не удалось ¯\_(ツ)_/¯
Архитектура нашей системы базово не изменилась с 2013 года: как была простой, так и осталась. Главное, чему мы научились: измерять пользовательские метрики и растить счастье пользователей. И вам советуем.
Нашим опытом можно воспользоваться: причём не только вооружиться идеями для реализации собственного отказоустойчивого сервиса, но и взять себе готовое решение. Для быстрого старта можно воспользоваться нашей инфраструктурой для видео и трансляций и SDK видеоплеера, которые мы предоставляем сторонним разработчикам.
А если хотите больше узнать об архитектурных подходах, скоро на Saint HighLoad++ буду разбирать их эволюцию и показывать, как это отражается в архитектуре ВКонтакте. Приходите лично задавать вопросы или следите за блогом — статья тоже обязательно будет.
Комментарии (13)

md_backend_binance
13.09.2022 19:59+4@atrolovможете не пытаться , тут просто было задание сделать статью всё. В прошлой и позапрошлой статье , там столько вопросов , никому не ответили ....
Отношение vk к IT комьюнити - ужасное...

novoselov
13.09.2022 21:07А есть статистика сколько процентов пользователей смотрят видео в 240p, 360p, 480p?

e_finkel
14.09.2022 13:44А что хотели бы узнать из такой статистики? В статье есть табличка по веб-плееру, в ней наоборот все разрешения от 720p выше составляют 42%. С одной стороны, у нас есть NeuroHD для апскейла, с другой — в комментах к одной из прошлых статей выяснили, что бывают сценарии, когда люди хотят ограничить качество сверху и сделали такой режим. Поэтому и вопрос, что покажет процент, который вы спрашиваете?

MyWave
14.09.2022 12:07+1Эротику искать невозможно. Вводишь название сайта, видео с которых ищешь, в поиске, и если сортировать по дате добавления, то выдаётся тысячи только что залитых скам видосов с другими названиями, которые в тэги вводят все самые популярные слова. Никакого булевого поиска, никакого праздника.

klounader
14.09.2022 12:20+3Все эти эти чудачества делятся на ноль, когда интерфейс превращается в говно.
мы делаем продукты для пользователей, не для себя.
А складывается совершенно обратное впечатление.
ELForcer
14.09.2022 13:31Как раз в этом и проблема. Надо делать для себя, что б самому было удобно пользоваться, а раз не делают для себя, то и испытать пользовательский опыт не могут.
klounader
14.09.2022 13:42+2Прошло уже достаточно много времени с момента ввода нового богомерзкого видеоинтерфейса в вк. Можно создать банальный опрос и посмотреть, насколько пользователи рады этому нововведению. При этом, более чем уверен, что сами разработчики (заказчики этого убожества) были таки рады этому нововведению наверняка.

Miharus
15.09.2022 08:29+1Никто никогда не рад обновлению. Если бы все делали опросы, мы бы до сих пор сидели на windows xp
klounader
15.09.2022 12:34А у разработчиков самих критического мышления нету?
Складывается ощущение, что они там все думают одинаково, типа:
— Вот, смотрите, всё просто, лаконично и быстро работает. Бесит до усрачки! Как нам поднять бабла?
— Говно вопрос! Щас перехреначим интерфейс, заставим пользователя бегать по страницам в поисках нужной вкладки, перенесём функцию в отдельную категорию, у меня пятилетний братишка шизофреник интерфейс нарисует и будет ваще всё огонь. А потом будем тут ещё долго жопы согревать, пытаясь удержать всю эту махину, чтобы не уволили. А т.к. тут куева гора всякой дичи, то и платить будут огого. Здорово, правда?
— Ага, пошли трясти бабло на инновации!Miharus
16.09.2022 12:06Такое чувство что лично у вас просто подгорает от того что разработчики "незаслуженно" трясут бабло, по крайней мере 80% того что я прочитал - об этом.
Но если по существу, то на конкурентном коммерческом рынке перемены нужны, даже если они вызывают в начале дискомфорт у юзеров. Иначе сервис останется позади. По тому что рынок никогда не находится в статичном состоянии: появляются конкуренты, старые конкуренты внедряют фичи, беднеют юзеры, регуляторы печатают законы со скоростью бешенного принтера.

Didimus
15.09.2022 06:35В статье о каких-то космических кораблях, а по факту как будто через модем смотришь. Походу, хд-версии пережали вусмерть в 320, чтобы диски сэкономить. Ну и поиск отдельно доставляет, он не работает. Даже если в названии есть нужное слово, искомое зачастую отсутствует в результатах поиска
atrolov
Давно за вами наблюдаю, у вас реально крутые технологии не уступающие конкурентам, а может и превосходящие.
Когда уже вы замените Ютуб, Инстграм, Тикток, Зум и др сервисы?
Экосистема и суперапп это хорошо, но кажется, что продукты надо продвигать отдельно, тогда шансов больше, потому что у ВК уже сложилось позиционирование и переломить его будет очень сложно/невозможно. Тот же фб, тот еще комбайн, но инстаграмм, ватсап, ютуб и др успешно работают самостоятельно.
fidonet-network
никогда не заменят