

От переводчика: сейчас мы активно тестируем свой фреймворк Jmix на совместимость с JDK 17. Это последняя LTS версия, и рано или поздно на нее будет массовый переход (особенно после выхода Spring 6). Но есть ещё один аспект, который может сподвигнуть вас на переход на новый JDK - "бесплатное" увеличение производительности приложения. За счет чего? Узнаем в этой статье.
JDK 17 с нами уже несколько месяцев и он не только про новые возможности языка Java. Прирост производительности в сравнении с более старыми версиями JDK очень заметен. Это становится особенно очевидно, когда мы сравниваем его с предыдущими LTS версиями: JDK 8 и JDK 11. Большая доля в улучшении производительности происходит из новых функций и оптимизаций в JVM, и в этой статье фокус будет на улучшениях, которые были сделаны в области сборки мусора в JVM
Недавно у меня было выступление, посвященное новым возможностям в G1, начиная с JDK 8, и в этой статье мы расширим тему, чтобы также осветить прогресс, сделанный в Parallel GC и ZGC. Также у нас есть четвертый сборщик мусора, который мы поддерживаем, Serial GC, но он не будет включен в это сравнение. Serial – стабильный сборщик с небольшими накладными расходами, но тесты, которые мы будем использовать ниже, требуют высокопроизводительный сборщик мусора для нормальной работы.
Обрабатываем разные ситуации
Решить, какой сборщик мусора использовать – не всегда простая задача. Важно понимать, что для правильного выбора сначала нужно понять, каковы у вас основные цели. Часто цели – это оптимизация для большей пропускной способности, уменьшения латентности и/или потребления памяти. Оптимальным решением, конечно же, было бы оптимизировать все эти метрики и получить наилучшую производительность в любой ситуации. Все сборщики мусора стараются быть оптимальными во всех аспектах, но они спроектированы с некоторыми компромиссами, чтобы поддерживать разные случаи, в которых они могут использоваться.
Быстро пройдемся по тому, что мы имеем в виду, когда говорим о производительности в разных областях:
Пропускная способность – снижает воздействие GC на общее количество транзакций, которое может быть выполнено в заданный промежуток времени
Латентность – снижает воздействие GC на каждую единичную транзакцию
Объем памяти – уменьшает потребление дополнительных ресурсов, используемых GC
Когда мы говорим о компромиссах, это не значит, что сборщик не может быть улучшен во всех аспектах. В процессе улучшения сборщика мусора важной частью является то, чтобы все компромиссные части были сделаны настолько эффективно насколько можно. Ещё один хороший подход для глобального улучшения – пересмотреть решения, принятые при проектировании старой версии и найти лучшие решения для новой.
Прогресс со времен JDK 8
Если взглянуть на прогресс, сделанный со времен JDK 8, то можно увидеть, что сборщики улучшились практически во всех областях. Чтобы лучше это показать, сравнительные диаграммы ниже используют нормализованные значения индивидуального сравнения сборщиков мусора вместо "чистых" цифр. Для сравнения сборщиков мусора я использовал SPECjbb® 2015 с размером кучи 16 GB. Это хорошо известный и стабильный тест, который фокусируется не только на производительности GC, так что результаты ещё и покажут улучшения во всей платформе Java. В тесте производительности есть несколько режимов выполнения, и он производит замеры обоих метрик: пропускной способности и латентности. Латентность измеряется как пропускная способность с ограничением по времени ответа.
Для сравнения времени пауз я запускал тест с фиксированной нагрузкой в течение часа. В этом случае сборщики нагружены одинаково вне зависимости от их конечных значений метрик.
Последнее замечание перед тем, как взглянем на графики: ZGC появился в JDK 11 (годен для промышленного использования с JDK 15), так что у нас есть только два набора данных для ZGC, в то время как у G1 и Parallel их три.
Пропускная способность
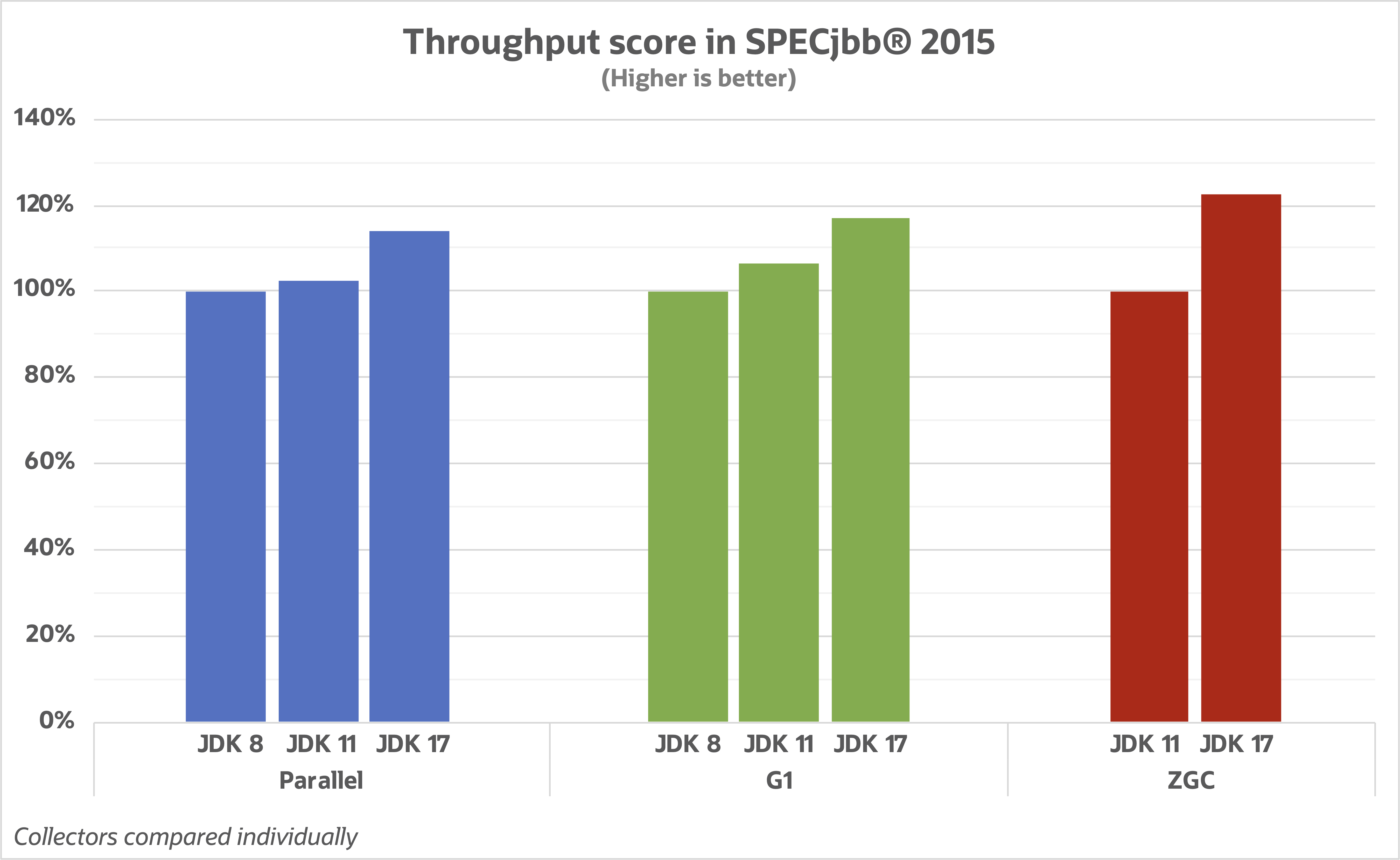
Взглянув на значения метрики пропускной способности, мы увидим, что все сборщики мусора значительно улучшились в сравнении со своими предыдущими версиями. ZGC показал наибольший прогресс в этой области. У G1 и Parallel все ещё неплохие показатели "чистых" значений пропускной способности, но при увеличении объема кучи ZGC наверстывает отставание.
Когда дело касается метрик, мы должны помнить, что мы замеряем не только производительность GC. Остальные части платформы Java, например, JIT компилятор, также вносят свою лепту в эти улучшения.
Латентность
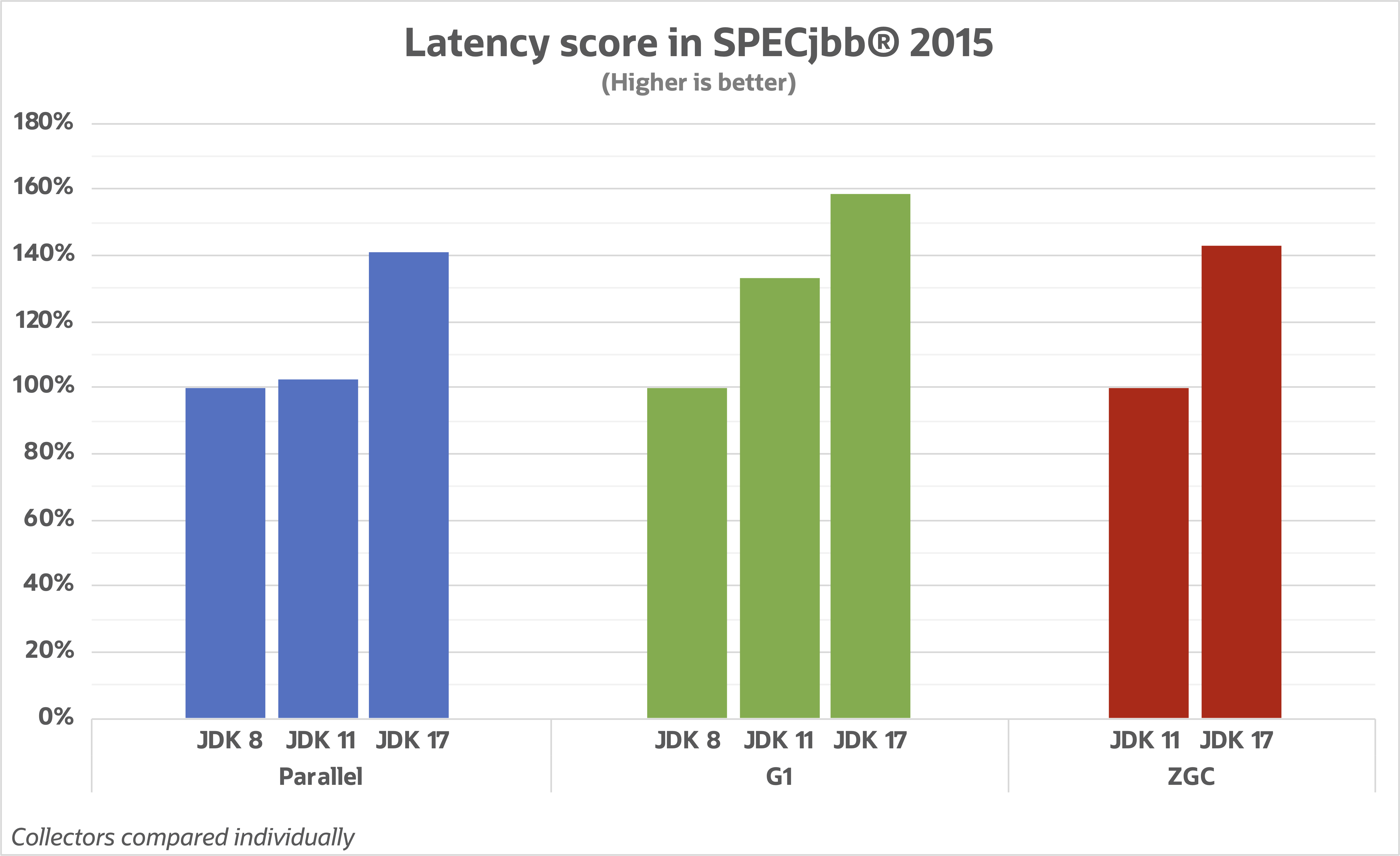
С точки зрения латентности результаты улучшились ещё сильнее. Здесь можно видеть все преимущества от усилий, вложенных в то, чтобы сделать паузы GC ещё короче. Когда дело доходит до этой метрики, большое количество улучшений можно списать на те вещи, которые были улучшены в GC.
G1 показывает наибольший прогресс в улучшении этой величины. ZGC также сильно улучшился в аспекте латентности. Наиболее впечатляющая часть незаметна на этой диаграмме, потому что тест замеряет латентности во всем приложении. ZGC делает свое дело настолько хорошо в области сокращения времени пауз JVM, что мы начали видеть другие вещи, влияющие на цифры латентности. Если мы вместо этого посмотрим, насколько уменьшилась длительность пауз, то можно увидеть просто экстраординарную работу, которую делает ZGC.

Здесь мы смотрим на "чистые" цифры (потому что нормализованная длительность пауз – это немного странно) и видим, что ZGC в JDK 17 сильно перевыполняет свои же планы по удержанию длительности пауз меньше миллисекунды. G1, который пытается держать баланс между латентностью и пропускной способностью, также показывает результаты лучше планируемой величины паузы в 200 миллисекунд. В эту диаграмму также включен ещё один дополнительный столбец, чтобы быстро показать, как разные сборщики мусора работают с увеличенным объемом кучи. ZGC был спроектирован так, чтобы размер кучи не влиял на длительность пауз, и мы ясно видим, что это работает, если увеличить кучу до 128 Гб. G1 работает с большой кучей лучше, чем Parallel с точки зрения длительности пауз, потому что в него заложена логика удержания целевого значения времени паузы.
Потребление памяти
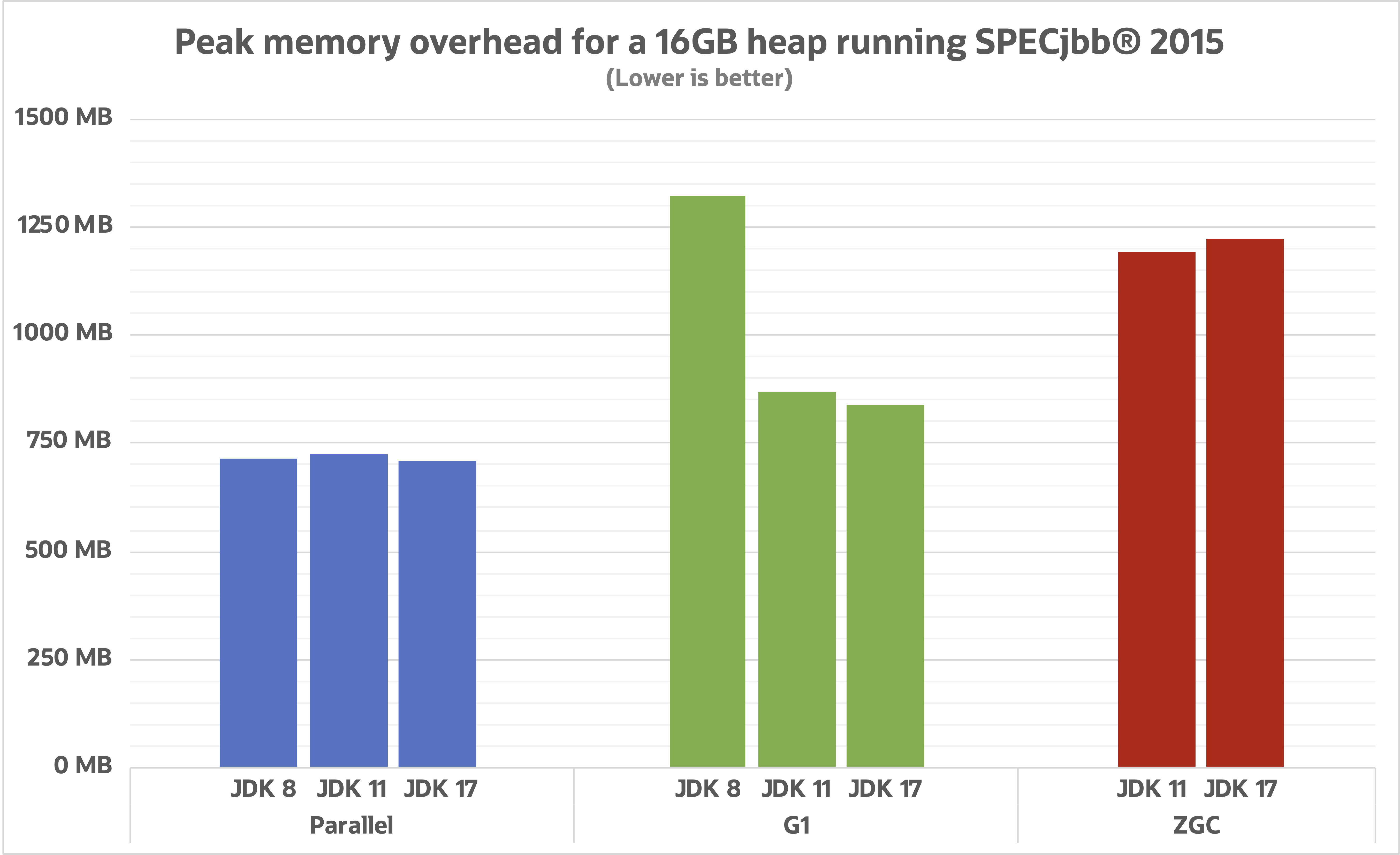
На этой диаграмме показано сравнение пикового значения потребления памяти для трех разных сборщиков мусора. Так как и ZGC, и Parallel довольно стабильны с этой точки зрения, есть смысл взглянуть на чистые цифры и в этом случае. Можно видеть, что G1 сильно улучшился в этой области и основная причина этого – все функции и улучшения, чтобы сделать управление ссылками между регионами памяти (remembered sets) более эффективным.
Даже если остальные сборщики мусора и не уменьшили объем накладных расходов, мы все ещё должны помнить, что они улучшили другие показатели без использования дополнительных объемов памяти.
Время обновляться
Общая производительность JDK 17 в сравнении с предыдущими версиями значительно выросла вне зависимости от того, какой сборщик мусора вы используете. Если вы все еще сидите на JDK 8 и планируете обновляться, то самое время пересмотреть планы на то, какой сборщик мусора использовать. В JDK 8 сборщик Parallel был установлен по умолчанию, но был заменен на G1, начиная с JDK 9. Хотя G1 был значительно улучшен по сравнению с Parallel, все ещё существуют ситуации, когда Parallel является наилучшим выбором. С появлением ZGC (готов к промышленному применению, начиная с JDK 15), у нас появляется третья, высокопроизводительная величина, которую также нужно включить в уравнение.
Больше подробностей
Если вам нужно больше подробностей по поводу того, что было сделано для достижения таких отличных результатов, я рекомендую к прочтению блог Per Linden’а, который посвящен ZGC и блог Thomas Schaltzl’а, посвященный G1 (и немного Parallel).
Если вам интересны новости и мысли команды Java в Oracle, посмотрите на inside.java.
Комментарии (11)

varanio
26.11.2021 08:00-1Поправьте меня, если я не прав, но по-моему, главная проблема Java в том, что она слишком много откладывает в кучу :). Даже самый простой объект из пары integer полей породит аллокацию. Очень мало делается на стеке.
Отсюда и вечная борьба за производительность gc. В отличие от того же Golang, где gc прост, но его вполне хватает, потому что убирать не так много надо

a_belyaev Автор
26.11.2021 10:44+4Да, наверное и это тоже. Поэтому делают Project Valhalla, например. И если вас не пугает английский с французским акцентом, есть доклад 2019 года, где рассказывается прям вообще про неочевидные сложности с перемещением объектов из кучи на стек. Мне прямо очень зашло.

Beholder
26.11.2021 19:29+1С включённым в JVM Escape analysis возможна оптимизация когда короткоживущий объект не попадает в кучу (даже в молодое поколение), а помещается на стеке.

YuryB
27.11.2021 17:02+3да, вас надо поправить, jvm умеет убирать аллокацию и делает это вполне хорошо, более того даже сильно лучше go. как убирает: у вас есть класс типа вектор, с конструктором, мат методами, где-то к вам попадают координаты и вам нужно узнать длину вектора, вы вызываете конструктор и потом метод у созданного объекта. так вот через 10к вызовов после работы jit у вас не будет создаваться объект. чтобы эта оптимизация не сработала у вас должен быть долгоживущий объект и очень сложный код. а так итераторы и т.д. - всё это идёт в лёт, никаких объектов не создаётся.
гонял для примера этот бенчмарк на 17-ой: https://github.com/Mark-Kovalyov/CardRaytracerBenchmark - всё прекрасно инлайнится, сборка мусора происходит в фоне без каких-либо задержек основного потока. там же люди измеряли реализацию на go и она оказалась кажется в 2 раза медленнее чем java! В принципе это чисто вычислительный код с классом вектор, т.е. по большей части бенчмарк gc и jit и gc go проигрывает с треском. Проблема эта вполне известная, разработчики jvm потратили много сил и лет, чтобы сделать то, что есть, и ничего этого в go нет, сборщик мусора у него сильно проще. Просто так взять go и надеяться, что всё заработает быстрее не стоит, с его сборщиком мусора нужно дважды подумать прежде чем создавать объект

Sap_ru
Оно, конечно, хорошо и впечатляюще, но он только под Linux-x64, а тот же Shenandoah уже практически везде есть.
Интересен выбор Shenandoah vs ZGC — кто где лучше.
a_belyaev Автор
Ещё бы сотрудник Oracle про Shenandoah написал :-) А если по теме - надо поискать обзоры. Тут правильно выбрать способ тестирования ещё надо. 1800$ за Specjbb не всем хочется выкладывать, а изобретать свой всеобъемлющий набор тестов долго. Вот, например, есть некоторые тесты всех GC. Давно делались, но, возможно будут полезны.
Sap_ru
Я эти тесты видел. Интересное. Но они 2019 года, а с тех пора оба GC очень сильно изменились.
eastig
Рекомендую попробовать https://github.com/corretto/heapothesys