

Подавляющее большинство инструментов глубокого обучения позволяет нам быстро создавать новые приложения с потрясающей производительностью, от программ компьютерного зрения, классифицирующих сложные объекты по фотографиям, до анализаторов естественного языка при помощи извлечения семантики из текстов. Однако самым серьёзным узким местом всех этих методик является огромное количество данных, необходимое для обучения моделей — обычно сотни тысяч примеров для обучения.
Если вы приступаете к созданию с нуля классификатора изображений, допустим, для распознавания несвежих продуктов на конвейерной ленте, для сбора и ручной разметки всех этих фотографий вам понадобятся недели или месяцы. К счастью, существует множество глубоких нейронных сетей, уже обученных на больших массивах данных фотографий с большим количеством классов. Они позволяют устранить проблему «холодного запуска». Идея, лежащая в основе трансферного обучения заключается в использовании результатов работы этих моделей, фиксирующих высокоуровневую семантику изображений, в качестве входящих данных для новых классификаторов, решающих требуемую задачу. Это значительно уменьшает объём данных, которые нужно аннотировать вручную — с сотен тысяч до тысяч.
Однако аннотирование даже тысяч примеров может быть затратной задачей, особенно если для выполнения задачи по аннотированию требуется навыки специалиста в соответствующей области. В идеале достаточно было бы разметить только несколько сотен задач и позволить конвейеру машинного обучения самообучаться без контроля. Эта задача также называется бюджетированное обучение (budgeted learning): мы выделяем сумму денег на приобретение набора данных обучения для создания модели с нужной производительностью. Ещё одна проблема связана с дрейфом концепции, при котором целевая задача со временем меняется (на линию распознавателя поступают новые продукты) и показатели прогнозирования без вмешательства человека деградируют.
Оптимизируем обучение
Итак, как ещё мы можем снизить объём работы по разметке, кроме использования возможностей трансферного обучения? Для этого можно использовать пару методик. Одна из наиболее изученных — это активное обучение (active learning). Его принцип прост — размечать только то, что полезно для текущей модели. Формально алгоритм активного обучения можно разбить на следующие этапы:
- Обучение исходной модели
- Выбор наиболее полезного сэмпла (того, насчёт которого модель не имеет уверенности на основании спрогнозированных вероятностей классов)
- Разметка этого сэмпла и добавление в набор для обучения
- Повторное обучение модели на новом наборе для обучения
- Повторение, начиная с этапа 2
Эта эвристика достаточно неплохо работает с олдскульными моделями машинного обучения (например, с линейными классификаторами наподобие логистической регрессии, SVM и т. п.), но эмпирические исследования дают понять, что в условиях глубокого обучения она становится неэффективной. Ещё один редко упоминаемый недостаток заключается в том, что в классическом активном обучении повторное обучение модели требуется после каждого нового размеченного сэмпла, а это длительный процесс.
То есть, подводя итог, можно сказать, что для обеспечения быстрого обучения нового классификатора без размеченных данных и с минимальными трудозатратами нам нужно выполнить следующий процесс:
- Воспользоваться пространством признаков, созданным какими-нибудь высококачественными заранее обученными моделями
- Выбрать самые информативные сэмплы и выполнить их разметку силами живых аннотаторов
- Быстро обновлять текущее состояние машинного обучения
Первый этап хорошо изучен во многих исследовательских статьях и обзорах, и даже крупные компании предоставляют сегодня доступ к своим заранее обученным нейросетям, которые можно легко подключить к конвейеру извлечения признаков командой вида vectorized_examples = pretrained_model(raw_examples). Идеальной опорной точкой можно считать TensorflowHub.
Следующие этапы — это сложное искусство машинного обучения. Понятно, что такое информативность сэмпла, но не всегда известно, как её точно рассчитать. Поэтому существует множество разных метрик на основании вероятности классов p₁(x), p₂(x), …, pᵢ(x),…, отсортированной в убывающем порядке:
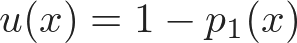
Неопределённость
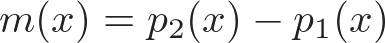
Граница
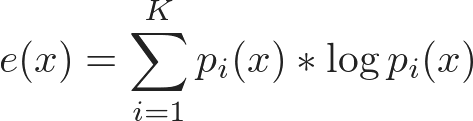
Энтропия
Все они подвержены максимизации над множеством примеров x ∈ X. Когда мы находим такой неопределённый пример x, мы надеемся увидеть, что после повторного обучения модель будет гораздо более точной по соседству с x. Но если по соседству с x нет элементов? Этот пример, несмотря на неуверенность модели, не даст нам достаточно информации для ускорения схождения модели, поэтому нам нужно исключить эти выбросы из пространств поиска. Это можно выполнить при помощи максимизации:

Информационная плотность
также называемой информационной плотностью примера. Максимизировав i(x), мы отбираем только те точки, которые уже плотно окружены другими точками в нашем пространстве признаков.
Метрики неуверенности в сочетании с информационной плотностью позволяют нам выбирать точки, которые являются прекрасными представителями и дают новые знания для модели. Но если есть две репрезентативные точки, в которых модель не уверена, как выбрать одну из них? Один из способов — выбрать пример, наименее непохожий на уже выбранный. Последняя информативная метрика — это разнообразие:
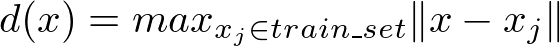
стимулирующее выбирать как можно больше разнообразных точек.
Чтобы скомбинировать эти три метрики в одну функцию оценки, можно использовать произведение соответствующих им накопительных функций распределения (cumulative distribution functions, CDF) (в противном случае вам придётся иметь дело с числами разных порядков или даже с отрицательными числами):

Функция оценки
где каждая функция с заглавной буквой обозначает CDF, например, U(x) = P(u < u(x)).
Получаем результаты быстрее
Наконец, мы выбрали пример и можем его разметить (существует множество доступных инструментов разметки). Последний этап — это обучение модели. Это может быть многочасовое ожидание завершения процесса повторного обучения, после которого можно перейти к следующему сэмплу.
Но что если её вообще НЕ обучать? Звучит безумно, но если ваше пространство признаков существует без дополнительных параметров, которые нужно изучать, то можно положиться на создаваемые ею эмбеддинги и использовать простые метрики наподобие евклидового расстояния и косинусного сходства. Эта техника хорошо известна и называется классификатором k-ближайших соседей.
Несмотря на свою простоту, это очень мощный способ благодаря следующим особенностям:
- Он позволяет «обучать» новую модель мгновенно — на самом деле обучение не выполняется, размеченный пример просто сохраняется в какой-нибудь эффективной структуре данных (если только вы не используете поиск перебором)
- Он создаёт нелинейную модель
- Его легко масштабировать и разворачивать без повторного обучения модели — достаточно добавить новые векторы в уже работающую модель
- Если простого расстояния, например, евклидова, недостаточно, можно обучиться офлайн новым пространствам метрик (см. обзор некоторых методик обучения метрикам, а также few-shot learning)
- Кроме того, он обеспечивает частичную объясняемость: при классификации неизвестного примера всегда возможно изучить, что повлияло на этот прогноз (так как у нас есть доступ ко всему набору данных обучения, что возможно только при изученных параметрах)
Вот визуализация того, как это выглядит на практике:
Есть два класса, фиолетовые (p) и оранжевые (o). На каждом шаге наш способ выбора пытается найти наиболее информативный пример и разметить его. Как видите, модель всегда пытается выбрать следующий сэмпл между точками первого и второго класса, в основном потому, что максимизация метрики неуверенности u(x) приводит к минимизации

Это приводит к исследованию границы (рядом с X=0) на протяжении примерно 30 первых шагов. Затем наши методы активного выбора пытаются благодаря информационной плотности исследовать плотный кластер точек. Более того, они всегда нацелены на исследование разных точек из-за метрики разнообразия, что намного лучше: традиционное активное обучение застревает только на одной граничной линии и может игнорировать другие кластеры точек.
Валидация и результаты
Давайте проведём эксперимент на реальном наборе данных фотографий свежих/гнилых фруктов, чтобы валидировать этот метод активного сэмплирования.
Есть три типа фруктов (яблоки, бананы и апельсины), каждый класс представлен фотографиями свежих и гнилых фруктов, то есть в сумме получается шесть классов. 90% набора данных берётся для обучения, оставшаяся часть — для тестирования. Для устранения статистических погрешностей применяется перекрёстная валидация K-fold с K=16, а затем тестовые погрешности усредняются.
В качестве вставок в наше пространство признаков мы возьмём 1280-мерные результаты работы нейросети MobileNet-v2, а для пространства метрик воспользуемся косинусной схожестью. Вот примеры того, как выглядят эмбеддинги набора данных:
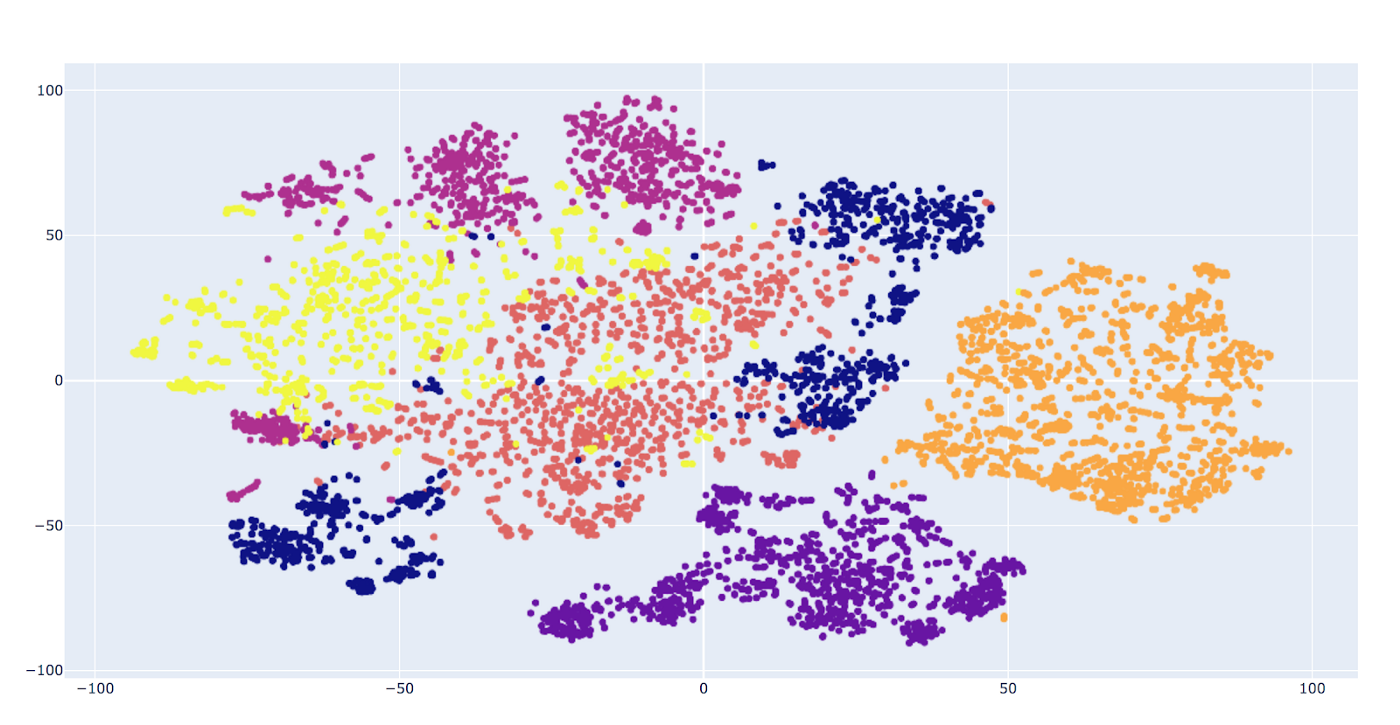
Как мы видим, здесь присутствуют облачные кластеры, так что мы можем воспользоваться этим, применив наряду с неуверенностью дополнительные метрики информативности.

Выше показана усреднённая производительность модели на множестве размеченных примеров. Как мы видим, для достижения точности в 90% при стратегии активного сэмплирования требуется почти в два раза меньше размечанных данных по сравнению со стратегией, при которой точки для разметки выбираются случайным образом.
Ещё один эксперимент был проведён с текстовыми данными, взятыми из набора данных Sentiment140. Задача заключается в классификации твитов на основе определения их положительного/отрицательного эмоционального тона. В целях эксперимента мы случайным образом сэмплируем 20 тысяч точек и выполняем тот же эксперимент, что и с фотографиями свежих/гнилых фруктов. Для извлечения признаков использован Universal Sentence Encoder, выводящий для каждого твита 512-мерные эмбеддинги.

Вот график производительности модели со сравнением стратегий активного и случайного выбора. Модель с активным выбором снова сходится гораздо быстрее, однако абсолютная производительность ниже (точность всего 62%, при максимальной точности в случае использования полного набора данных в 70%).
Подведём итог
- Когда узким местом при создании проекта машинного обучения является процесс разметки, используйте активное обучение для минимизации объёмов задач разметки
- Используйте результаты предварительно обученных глубоких нейросетей для превращения сырых данных (изображений, текстов) в векторы (эмбеддинги)
- Применяйте сочетание метрик информативности для выбора новых сэмплов для обучения, снижения неуверенности модели, стимулирования репрезентативности и разнообразия
- Когда вам необходимо выполнить мгновенное обучение, быстрое и прозрачное прогнозирование, выбирайте в качестве классификатора k-NN
- На каждом этапе сравнивайте результаты активного обучения со стратегией однородного сэмплирования опорного набора данных, чтобы отслеживать поэтапное изменение производительности и видеть, как можно сэкономить выделенный на разметку бюджет.