

Я Павел Щеваев, CTO студии BIT.GAMES, части MY.GAMES. Вы можете знать нас по таким играм, как «Гильдия Героев» и «Домовята» в Одноклассниках (да, это тоже были мы), а также по нашему текущему флагману Storyngton Hall — это классическая три-в-ряд с сюжетом в викторианском стиле. О нем-то и пойдет речь далее.
Когда я писал про тестовую ферму из Android-устройств, я не раз упоминал наш самописный детерминированный движок Match-3, благодаря которому и возникла возможность повсеместного покрытия игры тестами без ущерба для жизни и здоровья QA-команды.
Но, конечно, это не единственная причина, почему мы пошли по пути создания именно детерминированного движка. О логике наших выборов и ошибках — про то, как мы отделили симуляцию от представления для более предсказуемого исполнения кода, максимального покрытия функционала тестами и освобождения ядра от частной логики, я и расскажу на этот раз.
Раньше, до Storyngton Hall, мы разрабатывали и другие игры с элементами Match-3. Но это было давно, и кодовая база ни одного из прежних тайтлов для новой игры нас не устраивала. А именно — не устраивало следующее:
отсутствие детерминированности и возможности реплея: нельзя отследить баг в сессии игрока и понять, что произошло;
логика модели «намертво» переплетена с представлением: нельзя отключить визуал и «перемотать» симуляцию;
ядро содержит супер-частную логику геймплея — классы типа Honey, Ferret или Rose, которые не переиспользуешь между проектами.
Поэтому первоначальный план был следующим:
создать маленькое функциональное ядро на C# с компактным API;
вести разработку через тестирование;
максимально изолировать симуляцию от представления;
ввести понятие детерминированности в симуляцию;
сделать так, чтобы вся частная геймплейная логика была реализована с помощью скриптов — в нашем случае на BHL.
И наверняка касательно последнего пункта у многих возник вопрос: BHL… это что?
BHL — это интерпретируемый строго типизированный язык программирования, который:
содержит удобные примитивы для псевдо-параллелизации кода;
поддерживает hot reload;
позволяет осуществлять загрузку байт-кода с сервера — это дает нам возможность внедрять разные патчи и фиксы без необходимости загружать приложение в стор.
BHL мы когда-то написали сами, и теперь этим языком в BIT.GAMES активно пользуются геймплейные программисты.
Но вернемся к нашему плану. Итак, концептуально мы хотели разделить симуляцию и представление. Здесь напрашивается аналогия с клиент-серверным программированием, где:
сервер — это детерминированная симуляция со своими «тиками», при этом симуляция предоставляет возможность подписываться на все значимые события;
клиент — представление, которое влияет на сервер при помощи ввода от игрока;
представление и сервер живут раздельно в своих собственных «тиках».
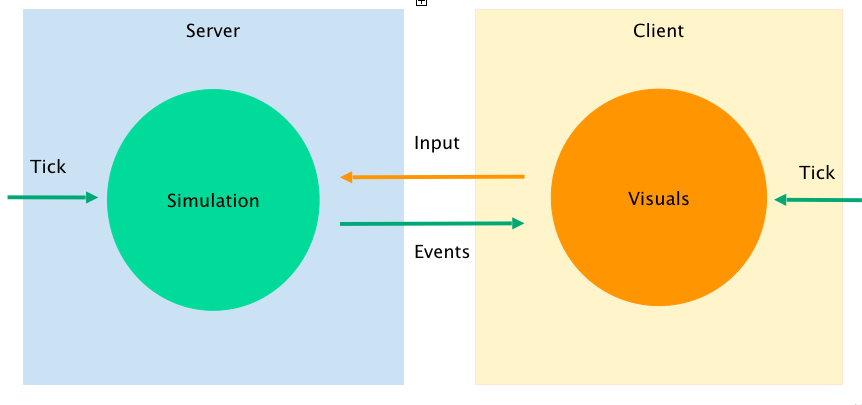
Архитектурно симуляцию мы реализовали как плагинную модель, в которой любой компонент можно заменить на иную имплементацию. Симуляция работает с этими компонентами при помощи строгих интерфейсов. Можно было бы попробовать использовать вместо этого ECS, однако на момент реализации мы все же решили поосторожничать и пойти более проторенным путем.

Работает это так. Из внешнего мира симуляция получает воздействие двумя способами: ввод от игрока и интервальный запрос на обновление («тик»).
Симуляция позволяет подписываться на все значимые события, которых довольно много.
Затем, уже в тике симуляции, мы в строгом порядке проходим по всем компонентам и плагинам — таким образом у нас складывается четкое понимание, что и когда вызывается. Ниже видно, как мы «тикаем» объекты ячеек, спаунеры, матчинг, гравитацию и прочее:
public void Tick() {
TickCellObjects();
TickMatches();
TickReplaces();
TickSpawner();
TickGravity();
TickGoals();
TickTurnsLeft();
TickShuffle();
TickCombo();
TickFieldZone();
...
}Событий, на которые симуляция позволяет подписаться, действительно много: это и спауны, и новые фишки, приземление, уничтожение разрушение фишкой стены и т.п.
public void AttachToModel() {
m3.OnSpawnNew += OnSpawnNewChip;
m3.OnSpawnNewMat += OnSpawnNewMat;
m3.OnSpawnNewBlocker += OnSpawnNewBlocker;
m3.OnChangeGoal += OnChangeGoal;
m3.OnLanded += OnLandedChip;
m3.OnMoveOnBelt += OnMoveOnBelt;
m3.OnDamage += OnDamageChip;
m3.OnMatch += OnMatchChips;
m3.OnReplace += OnReplaceChips;
m3.OnDestroy += OnDestroyChip;
m3.OnShuffle += OnShuffleChips;
m3.OnDestroyWall += OnDestroyWall;
m3.OnDamageBlocker += OnDamageBlocker;
m3.OnDestroyBlocker += OnDestroyBlocker;
m3.OnDestroyBlocked += OnDestroyBlocked;
m3.OnNextZoneSwitch += OnNextZoneSwitch;
m3.OnNextFieldSwitch += OnNextFieldSwitch;
m3.OnComboEnd += OnComboEnd;
...
}Детермированность — что это?
Если движок детерминирован, то вы:
Получаете возможность воспроизводимого реплея;
Можете контролировать сложность Match-3 — например, геймдизайнер сможет подобрать разные сиды с упрощенным и нормальным геймплеем, чтобы подыгрывать игроку в зависимости от тех или иных условий.
Одним из самых популярных способов реализации детерминированности является Random Seed — его-то мы и использовали изначально.
Random Seed — это некое число, которым параметризуется рандомизатор. Во время сессии игрока все обращения к рандомизатору будут возвращать некую псевдо-случайную последовательность чисел. В следующих игровых сессиях обращения к рандомизатору, использующему одинаковый Random Seed, будут возвращать идентичную последовательность чисел.

Разработка через тесты
Как я уже упоминал, изначально у нас было требование, что любой функционал, который реализуется в ядре, покрывается тестами. Используем мы для этого Unity Test Runner — это среда, которая позволяет выполнять тесты как группами, так и по отдельности.
Приведем пример простого тест-кейса, в котором мы тестируем влияние гравитации на фишки:
public void TestSimpleGravityFall() {
var sim = new M3Sim(4, 2);
sim.SpawnAt(new M3Pos(0,1), new M3Chip(2));
sim.SpawnAt(new M3Pos(1,1), new M3Chip(2));
sim.SpawnAt(new M3Pos(2,0), new M3Chip(2));
sim.SpawnAt(new M3Pos(3,1), new M3Chip(2));
Assert.AreEqual(
@"
--2-
22-2
",
sim.ToString());
sim.TickUntilIdle();
Assert.AreEqual(
@"
----
2222
",
sim.ToString());
}
Здесь мы:
создаем объект симуляции;
расставляем фишки;
проверяем, что они находятся в определенных позициях;
тикаем нашу симуляцию, пока она не перейдет в состояние покоя – TickUntilIdle;
проверяем, что фишка, которая находилась выше других, упала и находится с ними в одном ряду.
Подобных тестов у нас перевалило уже за несколько тысяч.

Кроме того, реплей позволил нам предсказуемо повторять ошибки с тестовой Android-фермы, подробнее о которой я уже рассказывал здесь. Если коротко, то каждую ночь мы стартуем все наши уровни на десяти устройствах. Эти тесты позволяют производить замеры по проходимости уровней, по памяти и FPS. Отчеты об ошибках приходят в Slack. Таким образом, у нас появляется возможность:
посмотреть реплеи с ошибками;
понять, что произошло;
оперативно все исправить.

Первый дебаговый UI
Первое время разработкой занимался один человек: не было ни художника, ни верстальщика — но был дебаговый UI в Unity. Через пару недель все это пусть примитивно, но уже работало.
Предварительные итоги были следующие:
Симуляция работала с дискретным перемещением фишек. Все вычисления были целочисленными: фишки перемещались за один тик между ячейками, у них отсутствовало промежуточное положение в пространстве. Из-за этого не было недетерминированных float-вычислений, над которыми нужно запариваться.
Дебаговый UI был играбелен, тесты работали отлично и подтверждали валидность модели. Казалось, что теперь надо было лишь прикрутить красивую визуализацию к этой модели. Однако...
...как только у нас в руках появился первый реальный UI, начались проблемы.
На видео видно, что каждая фишка притормаживает при прохождении над ячейками под воздействием гравитации. Причина оказалась проста: отсутствие промежуточного положения фишек в пространстве и дискретное перемещение. Из-за крупных «тиков» фишка могла находиться либо в одной ячейке, либо в соседней, но никак не между ними. Пробовать это исправить красиво только средствами визуализации довольно сложно, поэтому мы поступили иначе.
Что мы сделали:
Ввели промежуточное положение фишек в пространстве между ячейками;
Эмпирически подобрали значение в 20 Hz: симуляция стала чаще тикать в единицу времени;
Сделали так, чтобы представление интерполировало модель с максимальной частотой кадров.
Следующая проблема была в том, что промежуточное положение фишек в пространстве мы решили реализовывать при помощи float — но, как известно, float-математика плохо дружит с детерминированностью и на разном железе дает разные результаты. В итоге мы остановились на стандартном решении — Fixed Point Math, в основе которого — целочисленные вычисления.
Разумеется, Fixed Point Math тоже есть свои недостатки:
страдает точность;
она не столь быстрая на железе в сравнении с float;
ограниченный функционал: add, mul, sqrt, abs, cos, sin, atan.
Но учитывая то, что мы все же не шутер делаем, мы поняли, что с этим вполне можно мириться. Поэтому, недолго погуглив, мы нашли реализацию на Stack Overflow, внесли в нее косметические правки и остались вполне довольны.
public struct FInt
{
// Create a fixed-int number from parts.
// For example, to create 1.5 pass in 1 and 500.
// For 1.005 this would 1 and 5.
public static FInt FromParts( int PreDecimal, int PostDecimal = 0)
...
}
Эта реализация еще удобна тем, что она неявно переопределяет основные арифметические операторы, поэтому прежний код вычислений практически не переписывался. К примеру, ниже я привел код, который вычисляет работу гравитации, и выглядит он так же, как математика с использованием Unity-векторов:
var fall_dir = chip.fall_target - chip.fpos;
var fall_dirn = fall_dir.Normalized();
var new_fpos = chip.fpos + (fall_dirn * chip.fall_velocity * fixed_dt);
var new_fall_dir = chip.fall_target - new_fpos;
chip.fall_velocity += FALL_ACCEL * fixed_dt;
if(chip.fall_velocity > MAX_FALL_VELOCITY)
chip.fall_velocity = MAX_FALL_VELOCITY;
chip.fpos = new_fpos;
В связи с тем, что симуляция «тикает» с фиксированной частотой 20 кадров в секунду, образуя «подрагивания» кадра, нам необходимо было вводить интерполяцию на стороне представления. На видео наглядно видно, как это работает: до и после.
Без интерполяции:
С интерполяцией:
Кроме того, когда я это все прикручивал к визуалу, выяснилась еще одна вещь: хотя симуляция живет отдельно от визуала, она обязана резервировать некоторое время на различные взаимодействия на стороне представления. Например, фишка не может мгновенно визуально исчезнуть после получения урона, поэтому симуляция выделяет определенное количество фиксированных тиков на то, чтобы фишка «умерла». В течение этого времени представление вольно визуализировать процесс исчезновения фишки как ему угодно:
void DoDamage(M3Chip c, M3DamageType damage_type) {
Error.Assert(c.life > 0);
c.SetLife(c.life - 1);
c.damage_sequence_ticks = (int)(EXPLODE_TIME / FIXED_DT);
OnDamage(c, damage_type);
}
void TickChip(M3Chip c) {
...
if(c.damage_sequence_ticks > 0) {
--c.damage_sequence_ticks;
if(c.damage_sequence_ticks == 0) {
if(c.life == 0)
c.is_dead = true;
}
...
}Скриптинг частной логики
Для скриптинга мы используем BHL, и все основные события из симуляции пробрасываются в скрипты: различные эффекты, визуальные красоты, озвучка и прочее осуществляются уже там. Например, ниже в коде скрипта в ответ на событие приземления фишки стартует «пружина» красивого подергивания и проигрывается саунд-эффект:

Для реализации разного рода фишек — например, бомб, — можно было пойти по пути введения разных типов классов. Однако подобное решение довольно ригидно и не очень расширяемо.

Поэтому мы пошли другим путем — и ввели понятие активации. Это функционал, который можно проассоциировать с каким-либо типом фишки. Так, на примере ниже активация связывается с типом фишки 14, и при тапе на такую фишку вокруг нее происходит разрушение соседних фишек.

При наличии такой реализации уже можно было создавать разные виды «активаций» в скриптах на BHL. Ниже представлен тот же самый код, что и до этого, но уже на BHL: во время активации стартует функция, которая по заданному паттерну разрушает фишки вокруг себя.

Комплексный функционал – Жук
Рассмотрим теперь более сложную по сравнению с обычными фишками логику. Например, у нас есть фишка «жук» — особый тип бомбы, который выполняет нетривиальный протяженный по времени функционал после активации.
Чтобы это реализовать, понадобилось завести различные таск-менеджеры — как на уровне симуляции, которые тикают с ее частотой, так и на уровне представления — с частотой рендеринга.
Обычно, когда перед Unity-программистами возникает необходимость реализации подобных таск-менеджеров, они это реализуют при помощи Unity Coroutines. Они по-своему хороши:
работают из коробки;
у них понятная программная модель;
однако:
ими неудобно «дирижировать»;
нет четкого контроля за временем жизни.
Но в связи с тем, что у нас уже был прикручен BHL, где есть так называемые ноды, которые позволяют сделать все вышесказанное с более удобном виде, в своем проекте мы решили использовать именно их. Да, это in-house решение, все еще находящееся в альфе, но для нас выбор был очевиден.
Если разобрать на составляющие логику выполнения «жука», можно выделить следующие этапы.
На уровне симуляции:
Целевая фишка помечается как недоступная;
По истечение определенного времени помеченная фишка уничтожается.

Параллельно отрабатывается представление, где реализована вся «красота»:
Эффект взлета жука;
Пролет по траектории;
Взрыв.
Так «жук» выглядит в скрипте на BHL:

Зеленая секция кода отвечает за симуляцию, красная — за представление. Здесь мы стартуем два таска: на симуляцию и представление, соответственно. Эти таски тикают с разной частотой и синхронизируются при помощи специального канала. Подобный паттерн был заимствован нами из Go.
В редакторе можно посмотреть, как отрабатывается логика симуляции и представления:
В отладочной зоне симуляции в нижней части экрана видно, что фишка просто помечается и потом уничтожается, а сверху в зоне представления виден визуал и все эффекты.
Комплексный функционал — Большая бомба
По этому же принципу у нас устроены и другие фишки. Еще один пример — «Большая бомба», которая не только взрывает фишки вокруг себя, но и задевает те, что стоят после них.
В целом, она схожа с «жуком»:

В секции симуляции происходит следующее: стартует волна взрыва по определенной траектории. В красной секции срабатывает необходимая логика представления. Все это согласуется между собой уже знакомым нам паттерном синхронизационного канала.
Приятные бонусы
Воспроизводимый реплей
Теперь мы наконец-то добрались до воспроизводимого реплея. Как его реализовать?
Записываем Random Seed;
При каждом вводе от игрока фиксируем:
номер тика симуляции,
тип ввода и аргументы,
чек-сумму состояния поля, чтобы удостовериться, что нет расхождения.
Этого достаточно для воспроизведения.
Ниже я покажу пример геймплейной сессии и ее визуализации:
Что мы здесь видим? Стартует сессия игры. Игрок активно взаимодействует с игрой некоторое время. Останавливаем игру и включаем сессию реплея, которая была записана автоматически. Стартует специальный дебаговый UI, где можно пройтись по шагам и увидеть, что происходило на каждом этапе, — это очень удобно.
Реплей может сохраняться как в текстовом, так и в визуальном виде. Обычно мы используем текстовый: это бинарные данные в base64 формате, что особенно удобно для пересылки по почте и мессенджерам. В визуальном виде сохраняется последний скриншот поля в PNG с вшитым кодом реплея.

Отключение визуала от симуляции
Как только получилось все правильно разделить, мы, помимо всего прочего, смогли сделать «честную» перемотку симуляции для получения наград в конце уровня и внедрить быструю проверку уровней ботом. Это такая знакомая всем игрокам в Match-3 штука, когда после прохождения уровня возникает определенная секвенция действий, которую хочется пропустить: взрываются бомбы, получаются награды, начисляются очки и тому подобное.
public void SkipM3Rewarding(UIM3 ui) {
DetachUIFromModel(ui);
while(!m3.IsIdle())
m3.Tick();
AttachUIToModel(ui);
}Здесь мы отключаемся от UI, тикаем, пока симуляция не придет в состояние покоя, и после этого снова к ней присоединяемся.
Обратите внимание: после появления Джейн, нашей главной героини, пропускается весь «фейерверк», но при этом в симуляции все честно отрабатывается и происходит честный подсчет всех коинов с последующим награждением. И все это выполняется моментально.
Кроме того, отключение симуляции от визуала и детерминированность позволили нам сделать быстрого бота для базовых проверок работы геймдизайнеров. Вот так это выглядит в редакторе:
Допустим, геймдизайнер создает новый уровень и хочет протестировать его на проходимость. Он стартует специального бота, который, используя несколько десятков разных сидов, подсчитывает на основе своих эвристик проходимость уровня. По окончании выполнения бота можно посмотреть статистику прохождения с разными графиками.
Выводы
Детерминированная симуляция, скриптинг частной логики и разделение симуляции и визуала — это хорошо. Нехорошо было то, что ко всему этому нужно привыкать, это требует определенной «ломки шаблонов» и дисциплины, однако все это окупается. И, конечно, мы планируем задействовать эту схему в новых тайтлах, где требуется довольно сложное взаимодействие — а вот для небольших проектов типа гиперказуалок такие трудозатраты были бы излишни.
Комментарии (19)

pecheny
01.12.2021 18:17Причина оказалась проста: отсутствие промежуточного положения фишек в пространстве и дискретное перемещение. Из-за крупных «тиков» фишка могла находиться либо в одной ячейке, либо в соседней, но никак не между ними. Пробовать это исправить красиво только средствами визуализации довольно сложно, поэтому мы поступили иначе.
А в чем, собственно, проблема? Есть логика, она выдает «результат хода» в виде «фишка #32 перемещается из [1,1] в [1,2]», есть визуализатор, который знает как нужно анимировать перемещение – он его и анимирует.хотя симуляция живет отдельно от визуала, она обязана резервировать некоторое время на различные взаимодействия на стороне представления
Есть еще как минимум два варианта: 1) логика выполняется вся сразу и записывает результаты каждого хода в стопочку, а визуализатор их последовательно анимирует; 2) клиентская реализация логики управляется по шагам: тикает шаг, результат и управление передается визуализатору, и только после завершения анимации логика тикает снова.Обычно, когда перед Unity-программистами возникает необходимость реализации подобных таск-менеджеров, они это реализуют при помощи Unity Coroutines.
Да по-разному делают, когда что-то свое, когда готовое. Я когда-то пользовался вот такими промисами: github.com/Real-Serious-Games/C-Sharp-Promise
А можете рассказать, как вы реализуете гравитацию? Она работает для поля в общем виде, или считается/задается для каждой клетки индивидуально? Обрабатывать начинаете снизу-вверх, или сверху-вниз? Интересно, как разруливаются ситуации, когда, например, верхушка столбика, заблокирована и заполнение идет из соседних.
pachanga Автор
02.12.2021 11:22А в чем, собственно, проблема? Есть логика, она выдает «результат хода» в виде «фишка #32 перемещается из [1,1] в [1,2]», есть визуализатор, который знает как нужно анимировать перемещение – он его и анимирует.
Проблема была в том и, наверное, в статье следовало бы на этом сделать акцент, что симуляция у нас не блокируется после ввода от игрока. Игрок потенциально может влиять на перемещающиеся фишки, поэтому мы не знаем на 100%, что фишка гарантированно переместиться из [1,1] в [1,2]: где-то в промежутке с фишкой может случиться все, что угодно. Именно поэтому симуляция "тикает" мелкими шагами и на каждом шаге обновляет свое состояние.
Да по-разному делают, когда что-то свое, когда готовое. Я когда-то пользовался вот такими промисами: github.com/Real-Serious-Games/C-Sharp-Promise
Да, вот и мы, по сути, решили использовать привычное и понятное нам решение :)
А можете рассказать, как вы реализуете гравитацию? Она работает для поля в общем виде, или считается/задается для каждой клетки индивидуально? Обрабатывать начинаете снизу-вверх, или сверху-вниз?
Гравитация может задаваться индивидуально для каждой фишки. У нас гравитация высчитывается в несколько этапов: 1) проверка на потенциальные "падения" фишек 2) собственно "падение". Несколько этапов нивелируют проблему порядка обхода фишек.
Интересно, как разруливаются ситуации, когда, например, верхушка столбика, заблокирована и заполнение идет из соседних.
Для этого у нас есть специальная довольно замороченная эвристика "скатывания со склона". Когда мы ее реализовывали, то смотрели на уже существующие игры на Youtube с замедлением времени :)
pecheny
02.12.2021 17:35Игрок потенциально может влиять на перемещающиеся фишки, поэтому мы не знаем на 100%, что фишка гарантированно переместиться из [1,1] в [1,2]: где-то в промежутке с фишкой может случиться все, что угодно.
У вас есть какие-то особенные механики, связанные с воздействием на фишки во время полета? Просто, известные мне по топовым играм механики, не требуют ничего подобного.
Поясню свою мысль примером. Я ради забавы делал прототип match3, и у меня была совершенно независимая сущность – «заполнятор» поля, который оперировал только координатами ячеек и состояниями [блокировано|свободно|фишка] и тесты с маленькими фрагментами поля, похожими на ваши. Его тик равен перемещению на одну клетку, на выходе он выдавал набор траекторий падения в виде [{[0,0]→[0,1]→ [0,2]}, {null, [1,0]→ [1,1]}], его больше ничего не волновало.
Другая независимая штука – обработка матчей, которая может сказать допустим ли ход [2,2]→ [2,3].
А дальше еще одна совсем отдельная штука «клиент», которая почти ничего не знает про логику, но умеет рисовать анимации и обрабатывать пользователя. Когда палец шевелит фишку, то в зависимости от всяких условий клиент рисует перемещения фишки и анимации (с учетом того, какие ходы доступны) – и только после того, когда однозначно определено движение хода, которое нельзя отменить, уходит команда в логику. Логика сразу обрабатывает матч, затем обрабатывает заполнение поля и возвращает клиенту набор траекторий, которые клиент затем анимирует с любой скоростью, какая ему понравится.Гравитация может задаваться индивидуально для каждой фишки. У нас гравитация высчитывается в несколько этапов: 1) проверка на потенциальные «падения» фишек 2) собственно «падение». Несколько этапов нивелируют проблему порядка обхода фишек.
А как часта сменяются этапы: после движения на одну клетку, или после более крупных логических шагов?
Порядок обхода в любом случае играет роль, так как с ним связаны логика проверок и формат хранения промежуточных состояний. Можно «толкать» фишки с самого «верха», можно тянуть «снизу» (кавычки из-за условности верха и низа в произвольном графе гравитаций клеток), а можно обходить в произвольном порядке, но тогда, вероятно, для каждого этапа потребуется несколько проходов. У вас вот как, например?
Вообще, мне кажется, что эта тема очень интересная, на ее примере можно многое обсудить и по алгоритмам, и по структурам данных.
К сожалению, когда искал, не нашел вообще никаких публикаций на эту тему. Вы тоже все сами изобретали?Когда мы ее реализовывали, то смотрели на уже существующие игры на Youtube с замедлением времени :)
Я тоже пытался анализировать, и временами у меня создавалось впечатление, что оно везде работает черте-как, на разных уровнях может срабатывать по-разному.pachanga Автор
03.12.2021 09:12У вас есть какие-то особенные механики, связанные с воздействием на фишки во время полета?
Да. Например, где-то взрывается бомба и ее взрывная волна, которая у нас распространяется не мгновенно, повреждает фишки в полете. И это лишь один из примеров.
А как часта сменяются этапы: после движения на одну клетку, или после более крупных логических шагов?
Симуляция просчитывает потенциальное воздействие гравитации каждый тик, т.е. постоянно.
Порядок обхода в любом случае играет роль, так как с ним связаны логика проверок и формат хранения промежуточных состояний.
Как я выше написал, предварительный этап потенциального просчета вариантов падения фишки делают порядок обхода произвольным. Учитывая, что гравитация может быть расставлена на поле как угодно, для нас это было крайне важным условием.
К сожалению, когда искал, не нашел вообще никаких публикаций на эту тему. Вы тоже все сами изобретали?
К сожалению или к счастью, да :)
pecheny
03.12.2021 17:58Спасибо за объяснения, кажется, в общих чертах я понял. Поскольку у вас логика действительно просчитывает все промежуточные состояния, то наверно это тоже можно считать многопроходностью. А насколько глубоко «вниз» проверяется возможность движения на предварительном этапе каждого тика?
pachanga Автор
03.12.2021 18:08Т.к. в симуляции потенциально все может измениться в следующий тик, мы не пытаемся просчитать "глубоко". Учитываются текущие, актуальные для этого тика препятствия/фишки.
pecheny
03.12.2021 18:18То есть, на предварительном этапе первого тика потенциальное движение будет определено только для фишки, которая находится непосредственно над пустой ячейкой? Тогда пятая в столбике начнет движение условно на пятом тике?
pachanga Автор
05.12.2021 14:26Да, примерно так и произойдет
pecheny
05.12.2021 16:52А у вас есть какое-нибудь управление «удачей» пользователя? Слыхал, что некоторые помогают тем, кто надолго застрял на одном уровне, подсовывая такие фишки, из которых легко собираются бустеры. Но для такого цвет фишки нужно определять задолго до того, как она достигнет своего финального положения.

medex81
02.12.2021 00:59-1При всём уважении Павел вы переизобрели уровневую архитектуру игрового приложения где на нижнем слое менеджеры общего назначения-> выше жанровое ядро-> логика представления -> арт. Ну и назвали это детернимированным движком. Забыли ещё про жанровый плагинный редактор упомянуть тогда повестрование было закончено.
Очень спорный момент с обработкой состояний на каждом "тике", разве событийная модель не лучше? Это же не приложение требующее реального времени выполнения.
"Детерминированность"(нормальная архитектура) не имеет никакого отношения к воспроизводимости реплея. Вам достаточно добавить в архитектуру паттерн "команда" для управляющих сообщений и перед вами откроются бездны сериализации и прокрутки вперёд и назад с логированием перед эксепшеном или крашем.
Господи Карл гравитация в М3? рукалицо. В М3 для перемещения плиток со времён угля и пара используют динамическую анимацию(кокос) или твины(юнити, годо).
"Активация" эффектов - логика инитится из конфигурационного файла. а не реализуется в коде.
Для анимации "жука" не нужны потоки(таски) или кастомные автоматы состояний, это делается с помощью динамической анимации/твинов по завершению которого генерится событие в котором проигрывается эффект или анимация "взрыва".
Ну и завершая, весь смысл того что вы называете "детерминированностью", а другие уровневой архитектурой - это разрыв связности между уровнями и выставление между ними только универсализированных интерфейсов. Судя по последнему абзацу вы так и не поняли зачем это нужно, даю подсказку - уровни представления и конфигурируемой логики легко меняются как и арт и это решение максимально полезно именно для гиперказуалок. Вы можете клепать их десятками не тестируя, комбинировать и переиспользовать.
pachanga Автор
02.12.2021 10:39вы переизобрели уровневую архитектуру игрового приложения где на нижнем слое менеджеры общего назначения-> выше жанровое ядро-> логика представления -> арт. Ну и назвали это детернимированным движком. Забыли ещё про жанровый плагинный редактор упомянуть тогда повестрование было закончено.
Переизобретать мы ничего не хотели, а просто следовали устоявшимся best practices в индустрии.
"Детерминированность"(нормальная архитектура) не имеет никакого отношения к воспроизводимости реплея.
У меня стойкое ощущение, что мы говорим о разных вещах. В статье "детерминированность" является переводом термина "deterministic". Предлагаю ознакомиться со следующим материалом - https://gafferongames.com/post/deterministic_lockstep/ , послужившим источником вдохновения для упомянутых выше решений.
Вам достаточно добавить в архитектуру паттерн "команда" для управляющих сообщений и перед вами откроются бездны сериализации и прокрутки вперёд и назад с логированием перед эксепшеном или крашем.
Да, с подобным паттерном я знаком и в какой-то степени мы его используем, записывая ввод игрока, однако сам паттерн "команда" не сделает магическим образом симуляцию детерминированной. Статья говорит о более низкоуровневых проблемах.
Господи Карл гравитация в М3? рукалицо. В М3 для перемещения плиток со времён угля и пара используют динамическую анимацию(кокос) или твины(юнити, годо).
Перечисленные выше решения могут использоваться, но не являются единственно возможными. И, да, мы тоже используем твины, только не для гравитации, где требуется более гранулированный контроль.
"Активация" эффектов - логика инитится из конфигурационного файла. а не реализуется в коде.
Я предлагаю еще раз внимательнее прочитать статью. Использование скриптового языка как раз и дает нам возможность реализовать геймплейную логику, если в ваших терминах, через "конфигурационные файлы".



IlyaSinyavtsev
05.12.2021 14:26Спасибо за статью!
Я правильно понял, что ускорение фишек "зашито" в симуляцию (а не является частью представления)?
Тогда возникает вопрос, в какой момент начинают падать выше-идущие фишки?
Задержка ровно в 1 тик?pachanga Автор
05.12.2021 14:29Да, все верно, ускорение зашито в симуляцию конфигурационным параметром. Фишки начинают падать, как только во время тика гравитации определяется, что им можно падать. Т.к. во время симуляции может происходить множество разных событий из-за действий игрока, сказать на каком тике это произойдет точно невозможно.
v1000
как иронично, экономить несколько секунд в игре, которая заставляет тратить на нее часы
Rub_paul
Причём это ещё нужно суметь сэкономить время на такого типа игры