
А давайте перенесем релиз на завтра? Мне тут один баг осталось пофиксить.
Если у вас только что случились вьетнамские флешбеки, значит эта статья точно для вас. Именно так начинается самый страшный кошмар тестировщика. И тогда происходит всё, что только может произойти: долгое review, баги в тестировании, а сами тесты падают. И пока ты фиксишь одно, тебе приходит уже новая фича, которую хочется выпустить в релиз. Потом — пятница, а мы ничего не зарелизили.
В этой статье я расскажу, как мы пришли к эффективному способу измерения качества релиз-трейна, какие совершали ошибки по пути и с какими сложностями столкнулись в процессе.

А для тех, кому больше нравится видеоформат, есть наш канал с Охэхэнными историями.
Как мы пришли к идее измерять качество релиза
Когда мы планировали второй квартал 2021 года, особое внимание решили уделить нашему релиз-трейну. С ним всё было вроде как нормально, но постоянно что-то да происходило: то мы забывали сделать какую-нибудь доработку, и нас заворачивали на review в App Store, то в релиз необходимо было добавить важную фичу. Релиз постоянно сдвигался, и это оставляло неприятное послевкусие. А что делать, когда существует недовольство, но вы не можете его сформулировать? Правильно! Нужно взять и померить, насколько всё плохо.
Зачем измерять релиз-трейн?
Ничего страшного, что мы отложили какую-нибудь штуку на денёк-другой. Никто не умер, всё хорошо, нет адской срочности. Так ведь?
Не совсем. Дело в том, что когда ваш релиз-трейн прибит гвоздями и релизы каждую неделю, мистер продакт точно знает, что в понедельник вечером отрежется релизная ветка, а в среду готовый релиз отправится в Google Play и App Store. В этом случае он не будет приходить с хотелками в формате: «А давайте бахнем релиз вот прямо сейчас, и чтоб моя фича в него обязательно попала. Сроки горят, голова чешется».
И вот вы сдвигаете дату релиза, чтобы попала эта фича, потом уже и другая туда целится, потом едет дата регресса и вот вы уже вынуждены сдвигать релиз на следующей неделе и никак не получается разорвать этот порочный круг.
Единственное, что вы можете сделать, чтобы этого не допустить — держать ваш релиз-трейн в тонусе и выпускать артефакты еженедельно в одно и то же время.
Что сложного в измерении?
Казалось бы, зачем все эти сложные измерения? Почему бы просто не взять каждый релиз и посмотреть, насколько позже он вышел? Всё не так просто. Мы же не хотим делать всё это руками, у нас лапки, мы хотим автоматизацию. И вот тут возникает множество корнер-кейсов.
Например, если мы затянули релиз настолько, что он вылетел уже на следующий понедельник, второй релиз на этой неделе делать мы уже не будем. А еще бывают всякие праздники, перевыпуски, нерабочие дни. Мы подумали и решили сделать самую простецкую метрику. Но для начала стоит погрузиться в нашу специфику.
О нашей специфике для контекста
Разработка у нас делится на большие задачи длиной в одну-две недели. Мы называем их «портфели». Портфели состоят из разработческих задач, в которых пишут цветные буковки и приносят продуктовую или техническую ценность. Портфель начинается с идеи, проходит через проработку продактами, разработку, релиз и имеет достаточно много статусов. Нам будут интересны следующие:
«Разработка» — именно в этом статусе идея обретает свой цифровой эквивалент в цветных буквах;
«Разработка: готово» — в этом статусе портфель пылится ожидая релиза;
«A/B эксперимент» — портфель вышел на пользователей, но так как в нем был эксперимент, его увидят в своем мобильном приложении только счастливчики;
«Обратная связь» — портфель ушел в прод и раскатан на всех.
Получается, чтобы понять, как долго портфель разлагался на плесень и липовый мед, нам необходимо измерить, сколько вообще он был в статусе «Разработка: готово».
Первая попытка измерений
Самая первая идея, что пришла нам в голову, была довольно банальной:
Смотрим дату, когда портфель перешел в статус «Разработка: готово»;
Если с этого момента прошло семь дней, а портфель все в том же статусе, помечаем портфель как “протухший”;
Для каждого дня считаем, сколько у нас протухших портфелей. Это будет показатель того, насколько у нас все плохо.
Данный показатель имеет смысл, потому что когда вас ждет один портфель – это плохо, но когда вас ждут десять портфелей — это уже залёт!
Вроде бы всё неплохо, но налицо неравенство и дискриминация по дате мерджа в develop. Portfolio Merge Days Matter! Те портфели, которые попали в develop раньше, и протухнут первыми, а те, что прямо перед релизом залетели в develop – значительно позже.
В жизни это выглядит следующим образом: в понедельник у нас портфель на флажке был смерджен в develop. Ребята старались, думали, как сделать, чтобы портфель попал куда надо, напряглись и подготовили. А срок “протухания” у него наступит только через неделю. И если вдруг даты регрессов поехали, этому портфелю уже задержали релиз. Не очень-то клево.
Мы подумали, что раз распределение портфелей у нас такое, то мы релизим их всегда в понедельник, и всё хорошо. Посмотрели, и оказалось, что наши портфели довольно равномерно размазаны по всем дням недели.
Разумеется, довольно много всего уходит в понедельник и вторник, но и в другие дни такие портфели тоже есть. Поэтому такой способ подсчета немножко сильно не подошел.
Вторая попытка измерений
Что нам важно? Нам важно смерджить портфель в develop, момент, когда он перешел в статус «Разработка: готово». Также нам важна дата следующего возможного релиза: подсчитать возможное окно. И уже оттуда мы будем отсчитывать дни, если он залежался. Получается, нужно взять дату, когда портфель попал в «Разработка: готово», и срок протухания отрезать. Промежуток, через который необходимо отрезать, будет свой для каждого портфеля.
Так и сделали. Получилась совсем другая метрика. Мы отталкивались от того, что следующая дата релиза будет в среду. В понедельник у нас ветка develop отрезается, но релиз при этом считается так, что чаще всего выходит примерно в среду. Получается уже более честная метрика.

На графике красным отображается первая итерация, а желтым — второй, более честный подход Метрика посчитана, и посчитана честно. С ней уже можно жить.
Мы так тоже подумали. Так начинался второй квартал. Когда пришло время на встрече по OKR check-in посмотреть, как обстоят дела, мы поняли, в чем ошибались. Ведь по этому графику абсолютно непонятно, хорошо наши дела или нет. Ведь метрика – это число от нуля до единицы. А у нас здесь пики! Ну вы поняли.
Как это вообще получилось, если все настолько очевидно? Дело в том, что метрики — это далеко не основная часть работы, и, получив какой-никакой индикатор для мониторинга, мы спешно побежали делать задачки.
Третья попытка измерений
Логика определения пиков протухания портфелей нам нравилась, поэтому проделанные вычисления хотелось переиспользовать. Во время брейншторма пришла следующая идея: «Не зря же мы учили матанализ. Давайте посчитаем интеграл от полученного графика».
Геометрическая интерпретация интеграла — площадь под графиком.
Выбираем день, для которого будем считать метрику
Выбираем длину окна, для котором будем считать интеграл. Пусть это будет 30 дней. Тогда мы будем учитывать кроме этого дня еще и 29 предыдущих
Считаем суммарный простой в портфеледнях: для каждого дня берем число протухших портфелей и добавляем его к общей сумме
Браво, мы получили общее число протухших портфелей дней за период
Теперь заставляем это окно скользить по нашему графику. Это можно сделать двумя способами: оставлять окно фиксированной длины и считать окно с начала квартала. Мы остановились на первом варианте, поскольку до второго на тот момент просто не додумались

И вот у нас получается уже новый график. На нем видно, что у нас были реальные проблемы с релизом, и нужно было над этим начать работать.
Остается вопрос: какое окно выбрать для расчета нашего интеграла? Сначала мы выбрали окно длиною 30 дней, так как на графике был огромный бугор из-за предыдущего квартала. Хотелось как можно быстрее про него забыть и смотреть на более свежие показатели. Кстати, если бы мы выбрали способ расчета с окном от начала квартала, то каждый квартал начинали бы с чистого листа.
Сначала мы смотрели только на 30-дневное окно. А сейчас наблюдаем окно в 90 дней. И как раз это дает нам представление, к какому результату мы придем к концу квартала.
Остался еще один шажок — нужно выбрать допустимое значение для этого графика, ведь задержка релиза раз в квартал на пару дней — это нормальное явление и не стоит чересчур закручивать гайки. Для 30-дневного интеграла мы выбрали порог в 20 протухших портфеледней, для 90-дневного — в 60.
Разбор инцидента с новым ростом значений на графике
Как видите, за квартал мы смогли прийти к тем показателям, которые взяли целевыми. Что мы делали, чтобы исправить ситуацию, достойно отдельной статьи. Однако в октябре метрика немного захворала, а к первому дню зимы уже снова стала выглядеть неприлично. Неужели все, что мы сделали, было напрасно?
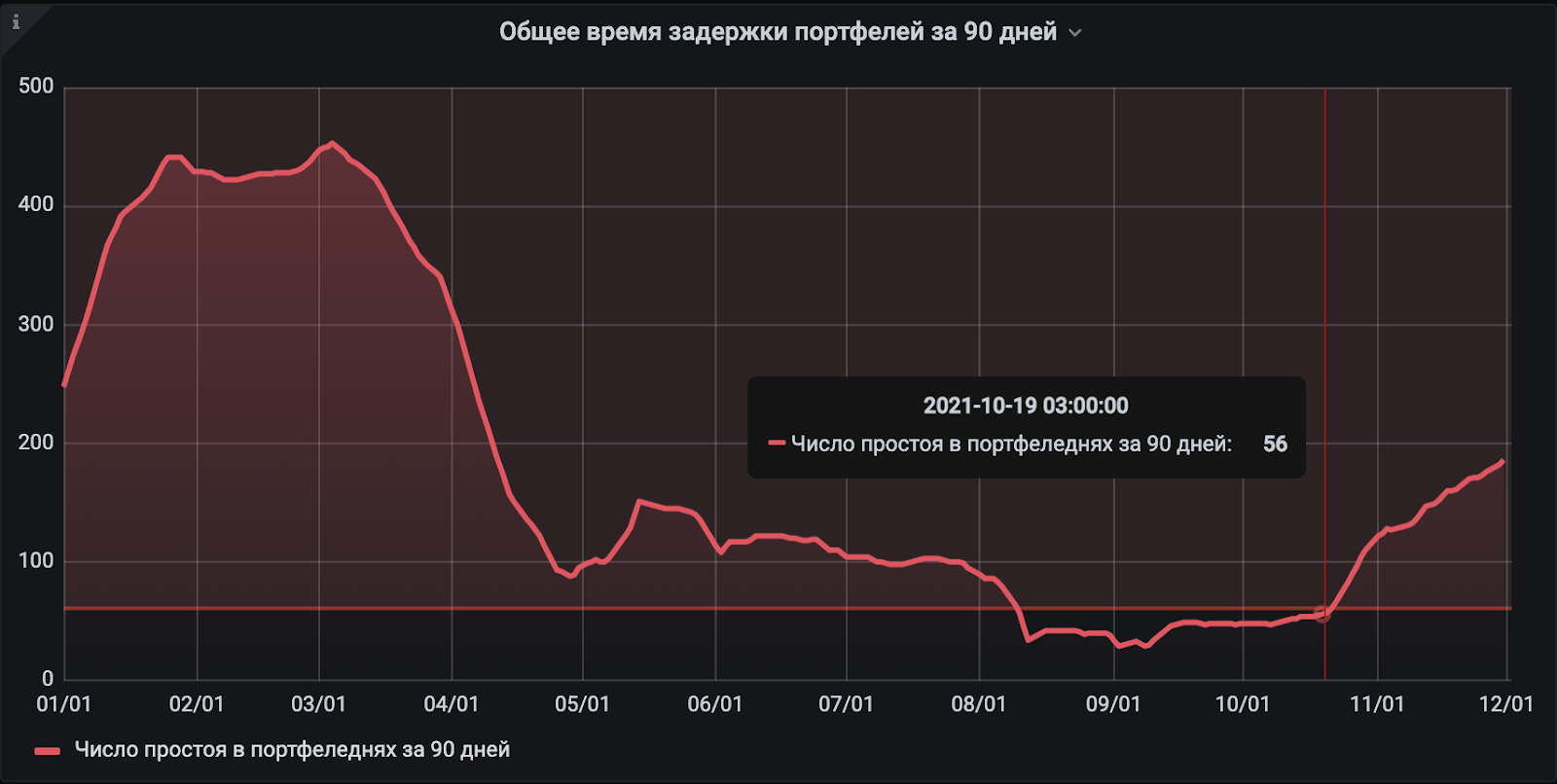
Дело в том, что еще летом у нас активно релизилось только одно приложение соискателей, но в то же время активно переписывалось с нуля приложение для работодателей, а в начале сентября и середине октября был релиз на Android и iOS.
Главная проблема обнаружена, но что с этими приложениями не так? Мы нашли две причины:
Над приложением для соискателей работает 3 команды, а над работодательским — одна. Поэтому артефактов накапливалось достаточно мало и ребята не хотели релизить по одному портфелю
Приложение не было покрыто UI-тестами. Мы рассказывали, что покрываем UI-тестами только стабильный функционал, а после редизайна мы поменяли практически всё! Подробнее про автотесты и тестирование в hh смотрите в плейлисте на Youtube.
Стали думать, что делать. Две дополнительные команды и хорошее покрытие UI-тестами быстро не отрастишь.
Для начала мы решили исключить из запроса все портфели команды, которая занималась переписыванием приложения.

Как видите, фиолетовый график стал более пологим. Смотрим, в какие дни у нас квасились портфели. Здесь будет полезен график, полученный во второй итерации, который мы заботливо сохранили для таких целей.
На детализированном графике уже видно, что причиной служит пара пиков на графике релизов iOS-приложений, а затем в историю подключился и Android. Вот до чего доводит синхронизация платформ.
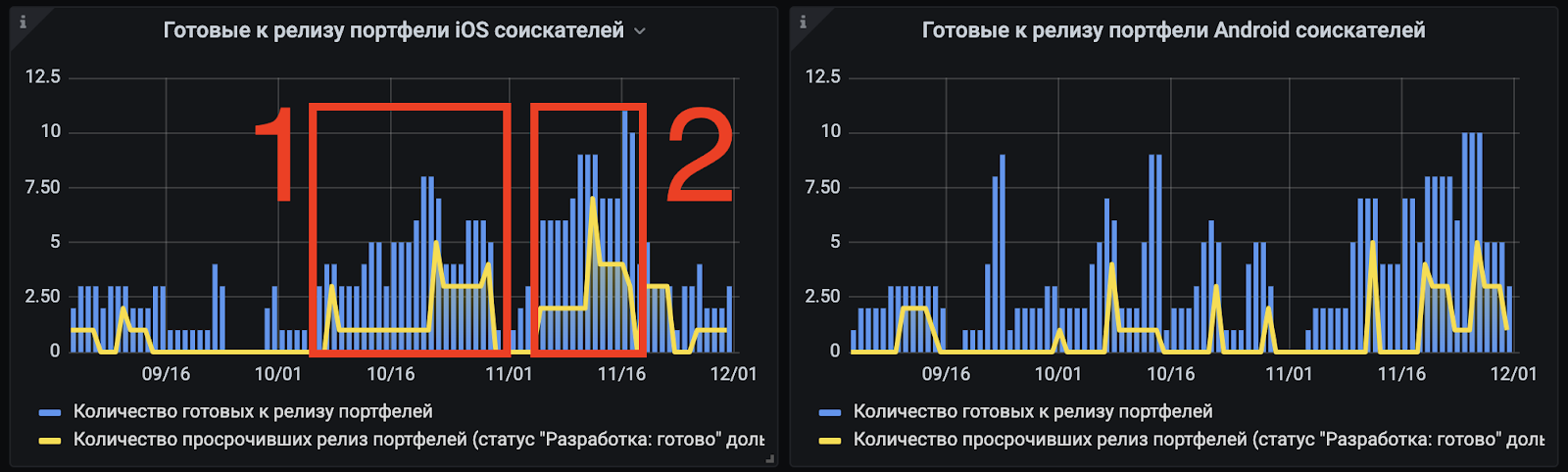
Нужно разобраться, что происходило с одной из платформ.
Ищем причину первого пика
Смотрим в App Store Connect: в этот период времени релизы были 11, 14 и 28 октября:
6.46 — Начало выпуска: 11.10.2021
6.47 — Начало выпуска: 14.10.2021
6.49 — Начало выпуска: 28.10.2021
Так, похоже релиз похитил злой Гринч задолго до Рождества, ищем в поиске в Slack строчку “6.48”. Понятно.

Смотрим баг, который аж отложил релиз, но это уже совсем другая история.
Ищем причину второго пика
Релизы iOS приложения были 28 октября, 16 и 22 ноября.

Смотрим на календарь, и получается, что релиза не было как раз в “нерабочую” неделю Шредингера. Если бы мы учли эти дни в предсказании даты предполагаемого релиза, то пика бы не было.
Вот мы и разобрали причины скачков метрик без мам, пап и поисков по Jira. Осталось понять, что делать со вторым приложением.
Несколько приложений в одной кодовой базе
В нашем случае всё решилось очень просто: мы договорились перейти на еженедельный релиз, так как в данной команде кроме сотрудников из hh мы подключили аутстафом ребят из SimbirSoft и эта команда поставляет достаточно много фичей, чтобы наполнить релиз. Кроме того, у нас в этой большой команде пропорция QA|Разработчики сдвинута в пользу QA и выглядит как 2:6 вместо обычных 1:4. Таким образом, команда успевает делать регресс и увеличивать покрытие UI-тестами.
Если вы не располагаете ресурсами и релизный цикл длиной больше недели можно рассмотреть следующий вариант:
Наш авторелиз записывает в базу данных дату релиза. Это позволит рассчитать прогноз для каждой следующей релизной даты. Кстати, если заинтересовал наш авторелиз, про него посмотреть «Охэхэнную историю».
Что можно улучшить и как жить дальше
Как следует из статьи, метрика считается довольно просто. При этом дни активной работы с релизом могут пересечься с какими-то из праздников, например, как у нас с “нерабочей” неделей при разборе полётов. Соответственно, релиз по плану должен быть не на этой неделе, а на следующей, а наша бездушная машина, увы, это не учитывает.
Ближе к новому году, мы дотюним расчет, чтобы не было ложно-положительных срабатываний.
Итоги
Во втором квартале, когда метрика была для нас целевой, мы достаточно хорошо над ней поработали и достигли поставленного порога в 60 протухших портфеледней. Каждое планирование мы смотрели на показатели и думали: «А что мы можем сделать?». Если ваш релиз-трейн оставляет у вас неоднозначные ощущения, советуем его померить. В настоящее время мы уже в фоновом режиме следим за данным показателем и стараемся не выбиваться из поставленных значений.
Как метрику стоит использовать площадь под графику, а для разбора инцидентов будет крайне полезен график с ежедневным числом протухших портфелей.
На этом всё. Пусть ваши метрики ползут в нужном направлении, а релиз-трейн летит вперед.
Пока!
YGeorge
Спасибо за статью, Александр! А почему объединяете фичи в портфели, почему не релизите по continuous delivery?
Xanderblinov Автор
Вот тут в охэхэнной истории про релиз Даня рассказал, почему мы переходили на GIthub Flow и почему нас не устроил подход trunk based.
Вкратце: хотели стабильный develop, при этом минимально вкладываться в инфраструктуру