
В данной статье речь пойдёт о том, что такое инструмент MLflow и из каких компонентов он состоит. Как работает данный фреймворк, в каких случаях рекомендуется его использовать и какие проблемы он позволяет решить. Затронем основные плюсы и минусы данного инструмента.
Итак, когда настраиваешь параметры модели машинного обучения, возникает потребность в её переобучении с различными параметрами и настройками. Нужно не только помнить, какая версия с какими настройками обучалась, но и где-то хранить саму модель и её альтернативные версии. Конечно, можно использовать Excel или блокнот для записей, но это не продакшн-решение и быстро превращается в хаос.
А когда таких моделей становятся десятки, потребность в системе, что позволяла бы управлять и мониторить состояние моделей, становится острой. Нужно контролировать весь жизненный цикл модели от первых экспериментов при её разработке и до поддержки в продакшне.
У нас в X5 выбор пал на набирающий популярность в последнее время фреймворк MLflow. Изучив его более подробно, мы пришли к выводу, что он нам подходит: система позволяет организовывать эксперименты, мониторить результаты и метрики, хранить и упаковывать модели, а также поддерживает основные ML-библиотеки.
Что такое MLflow?
MLflow — это Open Source-Фреймворк, предназначенный для управления жизненным циклом моделей машинного обучения, включая эксперименты, развертывание и реестр моделей.
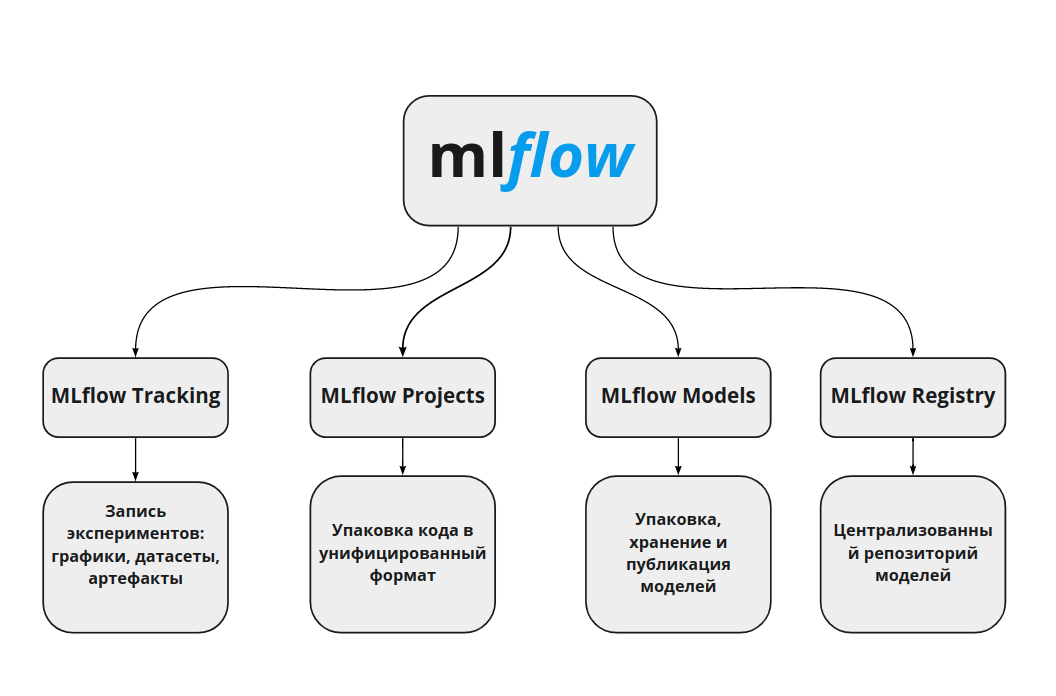
MLflow состоит из нескольких компонентов:
Mlflow Tracking
Это API и пользовательский интерфейс для регистрации экспериментов и показателей. Также можно смотреть метрики и параметры моделей. С помощью API можно логировать метрики, параметры и артефакты. Поддерживаются Python, Java, R и REST.

В MLflow Tracking есть две важных концепции: runs и experiments.
Run — это единичный запуск эксперимента. При каждом запуске эксперимента создается новая запись с текущими параметрами модели.
Experiment объединяет несколько Run в одну группу.
Если провалиться в один из экспериментов, то можно увидеть основную мета-информацию запуска:
Параметры, с которыми было запущено обучение модели.
Метрики качества модели.
Артефакты, что мы залогировали (это могут быть картинки, конфигурационные файлы, переменные окружения и т. п.).
Есть возможность добавлять описание и тэгировать эксперимент, чтобы кастомизировать внутреннюю организацию.

MLflow Projects
Это формат упаковки кода для многократного использования и воспроизведения эксперимента. Каждый проект описывается файлом MLProject в формате yaml. Основными параметрами проекта являются: имя, окружение и библиотеки.

MLflow Models
Это формат для упаковки моделей машинного обучения, что позволяет использовать модель как сервис. Например, для стриминговых запросов через REST API или при батч обработка через Apache Spark.
С помощью MLflow Models можно упаковывать модель в Docker-образ для последующего использования в Kubernetes.
MLflow Registry
Этот централизованное хранилище моделей. Оно включает в себя UI, который позволяет управлять полным жизненным циклом модели. Также он позволяет сравнивать разные модели между собой, например, чтобы увидеть отличия в параметрах.
Всё это позволяет удобно управлять выкаткой моделей.

Данный компонент управляет жизненным циклом модели. В контексте MLflow есть три стадии жизненного цикла: Staging, Production и Архив. Также есть поддержка версионности.
Архитектура MLflow
MLflow работает в различных вариантах: его можно развернуть у себя локально на компьютере и использовать местное хранение файлов или задеплоить в K8s кластере и использовать более продакшн-хранилище (hdfs или s3), что выступает нашим вариантом.

Основные причины выбора именно HDFS:
Неограниченное количества места, есть возможность загружать сколь угодно моделей и любого размера.
Все наши данные, витрины также хранятся на HDFS.
Меньше времени на чтение данных.
Наш основной фреймворк для вычислений Spark который также читает данные с HDFS.
Ну и удобство пользования, всем знакомая файловая система, с которой мы умеем работать).
В качестве хранения метаданных об экспериментах и моделях используется PostgreSQL, либо любая реляционная СУБД.
Связка с MlFlow + Airflow
Конечно, сервис не живёт сам по себе в вакууме. Данный инструмент интегрирован в наш процесс продуктивизации, где за мониторинг и состояние моделей отвечает MLflow, а переобучение и предикт происходит по расписанию (Airflow).
Где и когда используется MLflow?
Основное предназначение данного инструмента — упростить жизнь ML-разработчика, ведь с ростом кол-ва моделей и экспериментов возникает хаос в их хранении, упорядочивании и версионировании: нужно помнить, с какими параметрами обучалась модель, а если было несколько переобучений, то добавляются различные версии моделей. Их как-то нужно сравнивать, чтоб отобрать лучший вариант. Также нужно хранить саму модель и отслеживать основные показатели и метрики. И иметь возможность простым способом воспроизвести эксперименты, в случае если хотите поделиться своими наработками.
Все эти проблемы решает MLflow. Имея удобный UI-интерфейс, можно просматривать эксперименты, с какими параметрами обучалась модель и какие получились метрики и сравнивать различные версии между собой.

Таким образом весь жизненный цикл модели — от первой её версии до поддержки в проде, а также сопутствующие этапы, например, мониторинг метрик качества — может организовываться в MLflow.
Какую пользу принёс инструмент нашему продукту
Инструмент используется для продуктивизации моделей:
Например, у нас в продукте применяется при разработке таких моделей как Look-Alike, Uplift. И используется для хранения самих моделей, управлении и версионировании в проде.
Активно используется Data Scientist для разработки моделей.
Безопасное, централизованное хранилище всех экспериментов с моделями в продукте.
Одно из преимуществ, что все данные по экспериментам (параметры моделей, метрики хранятся в едином и доступном для всех разработчиков месте). Получается есть возможность совместной разработки моделей.
Так, например, скриншот использования MLflow из ноутбука JupyterHub:

Плюсы и минусы MLflow
Коротко о преимуществах
Унификация метрик моделей.
Масштабируемость — неважно сколько моделей, вся информация задокументирована (записана).
Централизованное, безопасное и масштабируемое хранилище.
Вся полезная информация по экспериментам структурирована и упорядочена.
Возможность сохранения (логирования) любых типов файлов (картинки, csv, html, графики).
Простая и понятная документация и API (низкий порог вхождения).
Простое подключение к «безграничному» хранилищу артефактов для сохранения огромных датасетов.
Недостатки MLflow
Одно пространство экспериментов для всех (используется шаблон имени эксперимента user/model/task).
Отсутствие разделения по ролям (Viewer, User) и авторизации.
В связи с отсутствием авторизации, система является публичной и все эксперименты лежат в открытом доступе. И в связи с этим другие разработчики могут случайно сохранять свои запуски в чужие эксперименты.
Данную проблему мы решили, разделив разработчиков на небольшие команды и развернув для каждой отдельный сервис MLFlow.
serebryakovsergey
Было бы интересно почитать про детали интеграции MLFlow и Apache Airflow. В частности, используете ли вы MLFlow для трекинга метаданных конвееров (пайплайнов) машинного обучения? Например, если мой конвеер состоит из нескольких этапов (загрузка данных, предобработка, тренировка и тестирование), и каждый этап представляет собой отдельный MLFlow run, то связываете ли вы эти этапы друг с другом через метаданные входов/выходов каким-нибудь образом? Мы ради экспермента написали слой поверх MLFlow для решения этой задачи, посути получив достаточно простую реализацию того, что доступно при использовании TFX Pipelines / KubeFlow с MLMD (ML Metadata от Google). Интересно узнать, если кто-либо еще думает в этом направлении.