

Декабрь – пора подводить итоги года. В этом посте постараемся рассказать читателям Хабра о новых интересных идеях, которые появились в области анализа и распознавания изображений документов.
В сентябре прошла очередная, 16-я конференция ICDAR-2021 – главное событие в области анализа и распознавания документов. Конференция проводится раз в два года, в этом году ABBYY также принимала участие с докладом, но сейчас речь пойдет не о нашей работе, а о других интересных, на наш взгляд, публикациях с этой конференции. К сожалению, не все работы легко найти в свободном доступе, поэтому под катом будет множество полезных ссылок для ознакомления. Поехали!
Трансформеры, трансформеры повсюду
Начнем с того, что за прошедшие два года архитектуры трансформеров стали применяться повсеместно (хотя и не всегда уместно), не только в NLP, но и в CV-задачах. И область OCR документов, разумеется, не исключение:
“TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models”
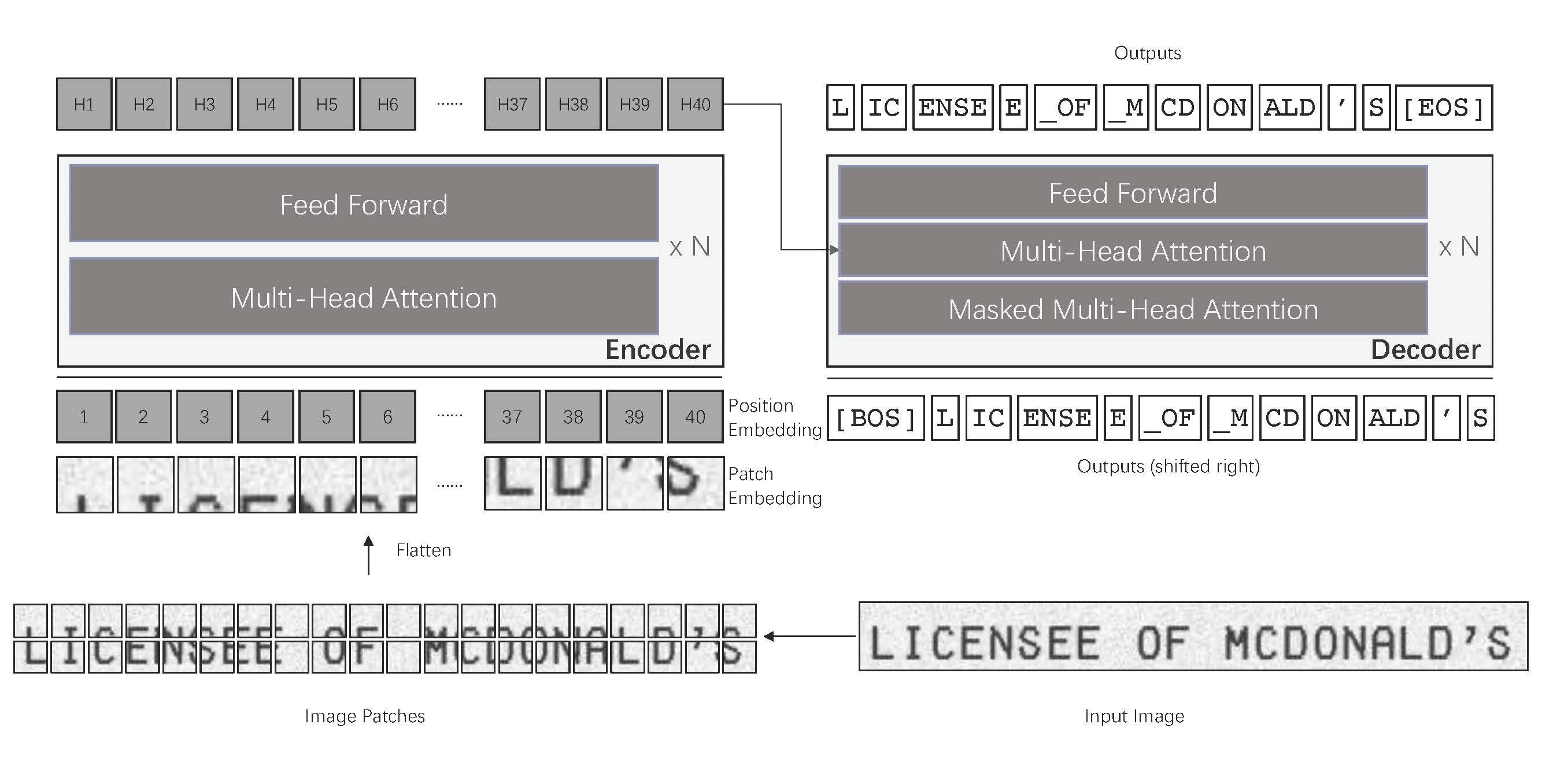
Что мы видим на этой диаграмме? Классическую архитектуру трансформера с энкодером и декодером, примененную к задаче распознавания строк. А что здесь принципиально нового, спросит читатель, ведь эта идея и так лежит на поверхности с момента публикации статьи о Vision Transformer (ViT)?
Авторы из Microsoft предложили использовать для распознавания строк претренированные CV и NLP-модели (BEiT и RoBERTa соответственно). Причем бóльшая часть обучения происходила в режиме unsupervised либо на синтетически сгенерированных изображениях строк. В конце производилось дообучение модели на одну из двух подзадач: распознавание печатного или рукописного текста.
К достоинствам работы стоит отнести то, что исходный код и полученные модели опубликованы, есть скрипты для запуска и все результаты теоретически можно проверить. С проверкой, правда, есть загвоздка: датасет для претренировки модели состоял из 684 миллионов изображений строк с ground truth, нарезанных из digital-born pdf с просторов интернета. Далее использовались «какие-то» 18 миллионов рукописных строк, сгенерированных с помощью 5427 шрифтов.
В абстракте статьи заявлено, что модель TrOCR превосходит по точности известные SOTA-решения в задачах распознавания печатного и рукописного текста. Однако, если заглянуть в таблицу с их результатами на датасете IAM, то оказывается, что в более ранней публикации от Google результат достигается как минимум не хуже, причем без использования трансформеров:
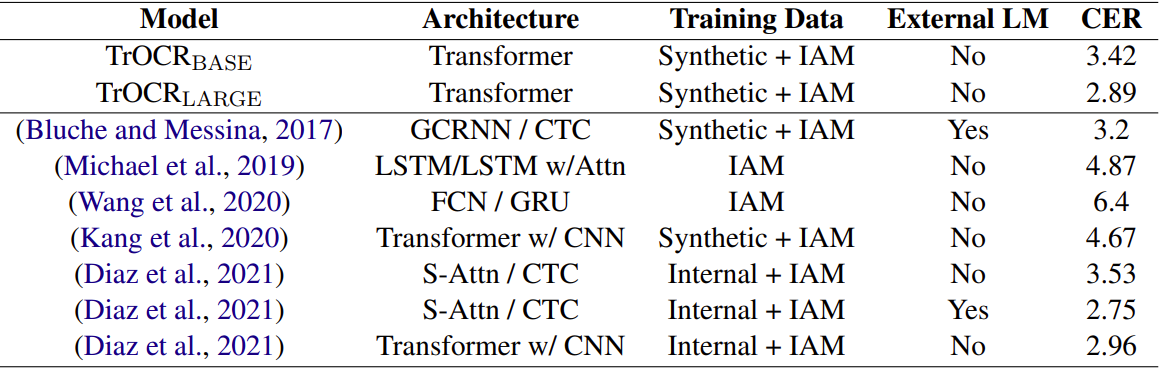
Метрика – character error rate (CER).
Следующая публикация, достойная упоминания – “Vision Transformer for Fast and Efficient Scene Text Recognition”
Сразу же оговоримся, что в статье рассматривается задача распознавания текста на произвольных сценах, она более сложная, и препятствий на пути к успеху тут предостаточно:

Чтобы распознавать текст на произвольных сценах быстро и эффективно, предлагается следующий вариант трансформера – ViTSTR:

Предложенная архитектура похожа на ViT тем, что в ней не используется декодер, но отличается от него устройством «головы» сети. Обучается это добро, разумеется, на синтетике (MJSynth + SynthText).
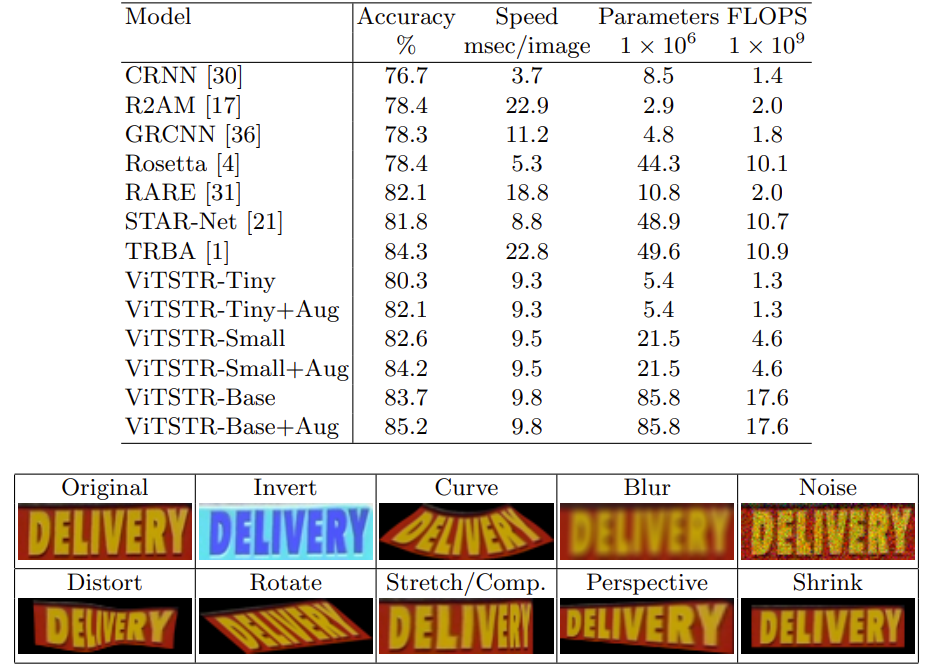
Метрики выросли, автору удалось превзойти сильный baseline в виде TRBA. Интересно, что сравнительно несложный набор аугментаций обеспечивает весьма существенный рост метрик (в таблице это заметно в строках с +Aug). Пожалуй, их можно было бы применить и к baseline решению.
Еще одна интересная работа – про значимую роль мультимодального обучения в задаче классификации документов: “EAPML: Ensemble Self-Attention-based Positive Mutual Learning Network for Document Image Classification”. Оригинальная статья из журнала имеет чуть более короткое название, а жаль, ведь именно positive mutual learning – одна из двух основных идей этой работы.
Мультимодальную классификацию документов давно и успешно применяют, ее суть в том, чтобы обучать классификатор на объединенных эмбеддингах от изображения и распознанного текста. Да-да, именно так: сначала все распознаем, затем классифицируем, если необходимо – перераспознаем еще раз другими моделями… и все это работает лучше, чем классификатор по одной модальности, будь то картинка или текст.
На воркшопе CVPR 2020 те же авторы в другой своей публикации (“Visual and Textual Deep Feature Fusion for Document Image Classification”) предложили сразу учить объединенную модель на двух модальностях:
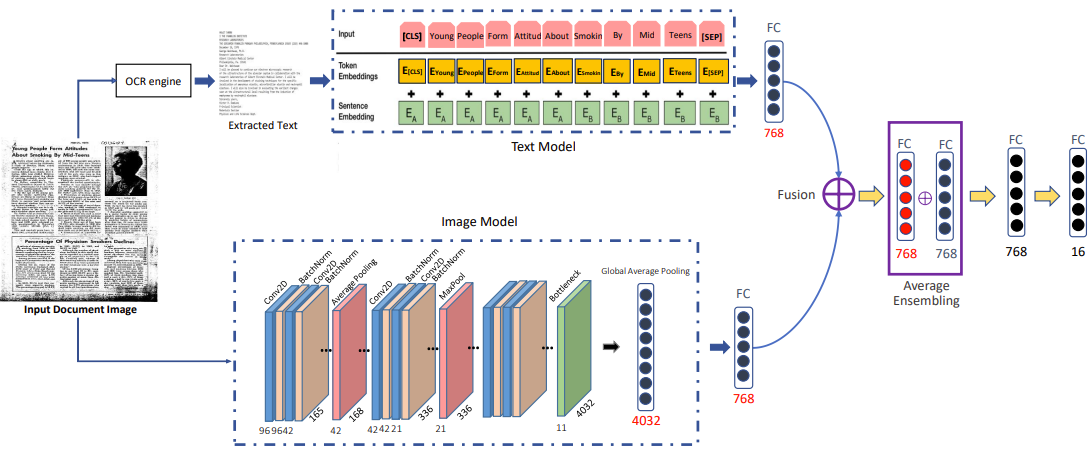
Это само по себе подняло метрики на датасете RVL-CDIP, но на достигнутом решили не останавливаться, и вот перед нами новая схема обучения с Attention Fusion:
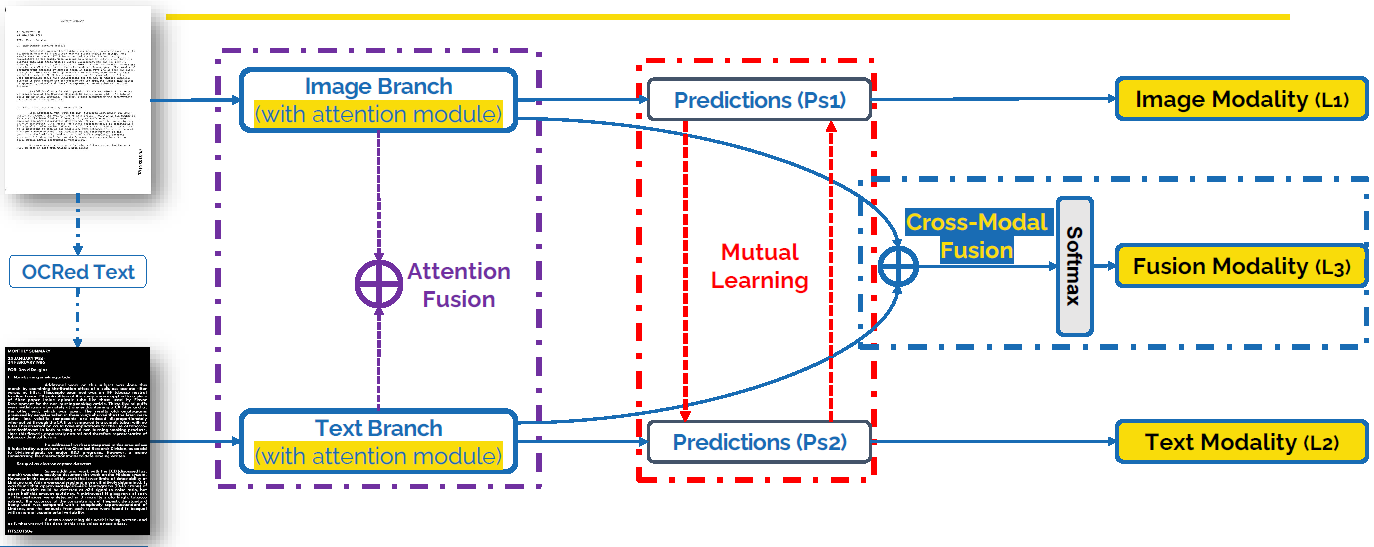
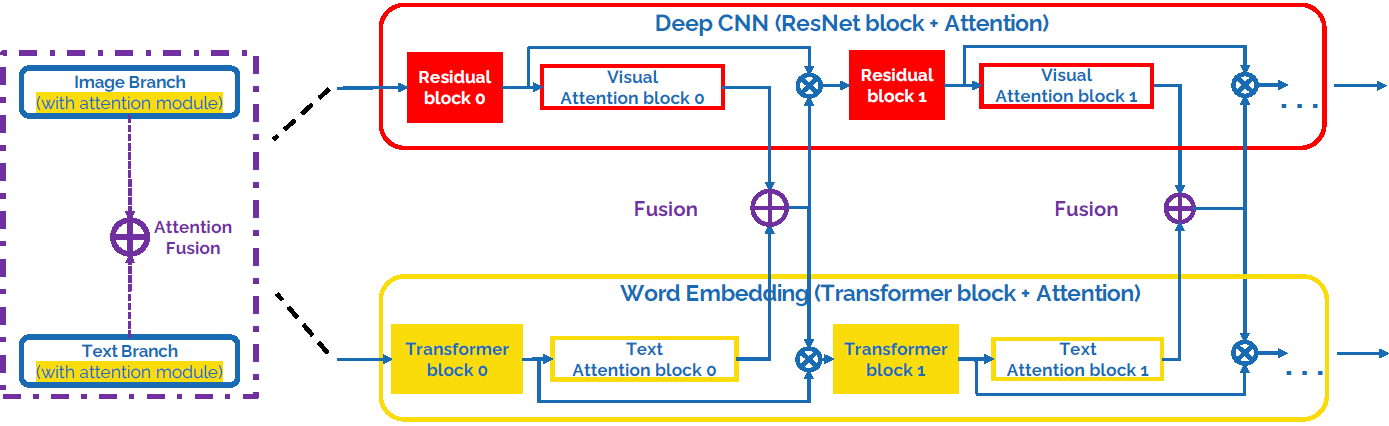
Идея Attention Fusion основана на том, что обе ветви сети пытаются кодировать информацию в эмбеддингах одного размера, вектора внимания складываются в каждом блоке сети. Изображение обрабатывает ветвь из residual блоков с поканальным вниманием, а текст обрабатывается блоками из BERT.
Помимо соединения механизмов внимания в обеих ветках сети, используется стратегия обучения с передачей только «положительных» знаний в каждую модальность (то самое positive). Зачем это нужно? Конечно, при взаимном обучении двух ветвей сети обучаемая модальность может и должна учиться на лучшем примере из другой модальности, но в то же самое время другая ветвь, «хороший ученик» учится уже на худшем примере из первой модальности, а этого нам очень хотелось бы избежать!
Вот как этого можно добиться: используем неотрицательное (truncated) расстояние Кульбака-Лейблера между распределениями в качестве слагаемого функции потерь:
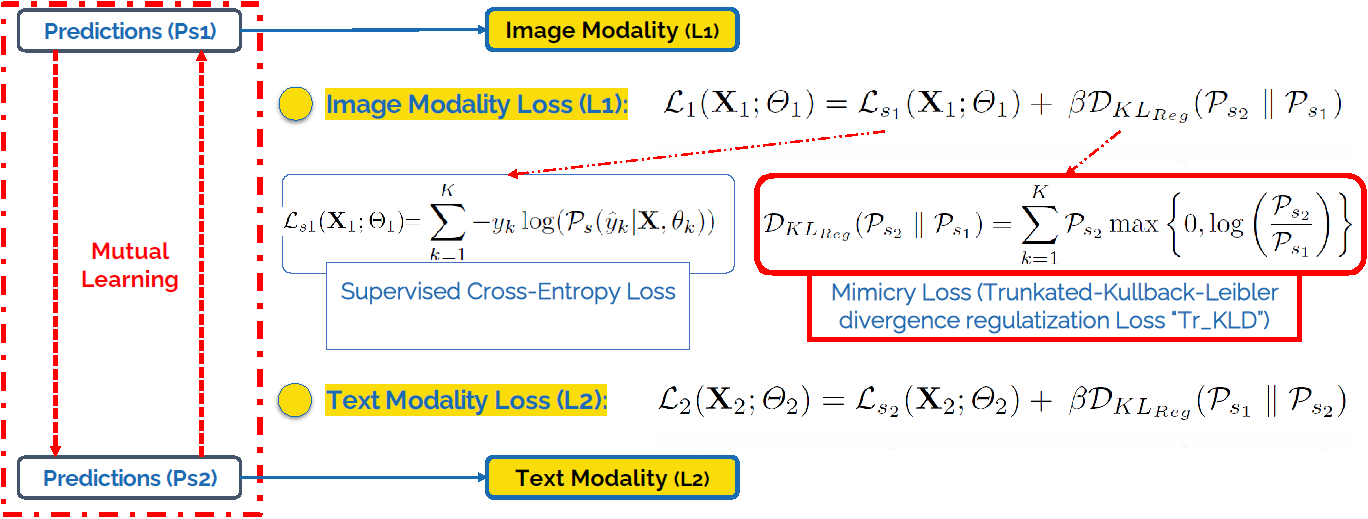
Общая функция потерь – сумма функций потерь по двум модальностям + функция потерь Softmax классификатора с перекрестной энтропией на суммарном векторе признаков (поэлементная сумма, Cross-Modal Fusion).
Если верить авторам, то в конечном итоге это повышает качество как мультимодальных предсказаний, так и одномодальных, только по изображению или по тексту:
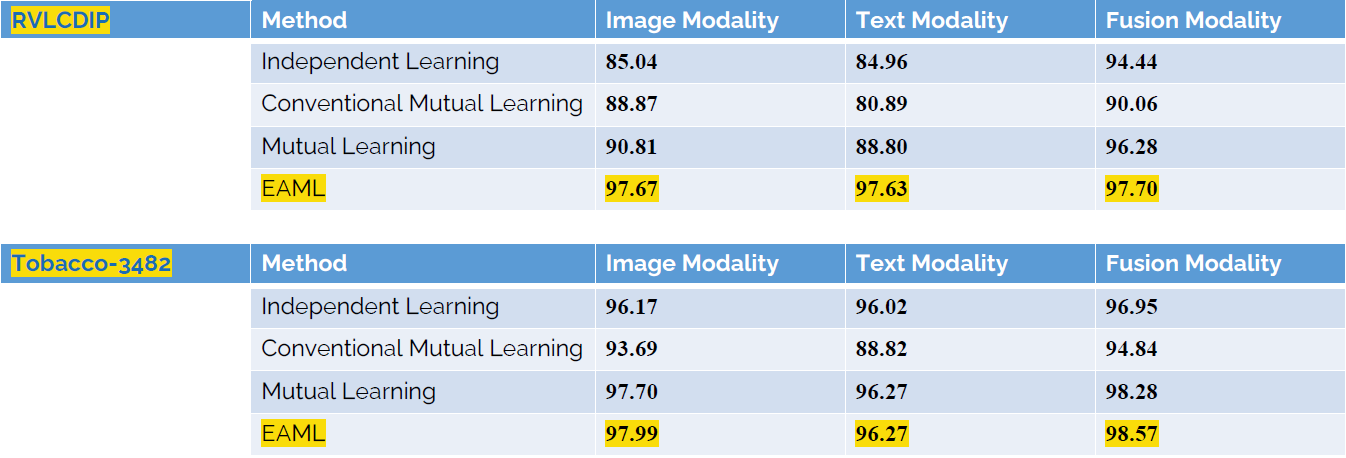
Предложенный подход показал новый SOTA результат и оставил далеко позади более сложные модели вроде LayoutLMv2.
Жаль только, что приходится верить этому на слово, код и модель для воспроизведения результатов так и не были опубликованы.
Детектирование объектов на изображениях документов
Что было нового по задачам детектирования объектов на изображениях документов? Принципиально – ничего. Можно лишь упомянуть несколько уже ставших популярными трендов, пришедших к нам из области «general CV» решений для детектирования объектов в произвольных сценах:
Использование нейросетевой пирамиды признаков (feature pyramid network, FPN) , или даже стека из них
Детектирование центра объекта (в нашем случае это центральная линия строки или слова)
Использование деформируемых сверток (deformable convolutions)
Использование семантической сегментации и нескольких целей в обучении в противовес регрессионным моделям, которые понемногу сдают свои позиции в задачах детектирования текста
На последней идее остановимся немного подробнее, остальные уже давно известны и с ними можно ознакомиться по приведенным выше ссылкам.
Дифференцируемая бинаризация была представлена на конференции AAAI 2020, идея прижилась благодаря своей простоте и эффективности.
Суть метода в том, чтобы предсказывать в каждой точке heatmap не только вероятность принадлежности к классу «текст», но и значение порога бинаризации, который имеет смысл применять локально к этому heatmap. Обычный оператор бинаризации по жесткому порогу заменяется на дифференцируемую функцию, что позволяет обучать такую модель end-to-end:


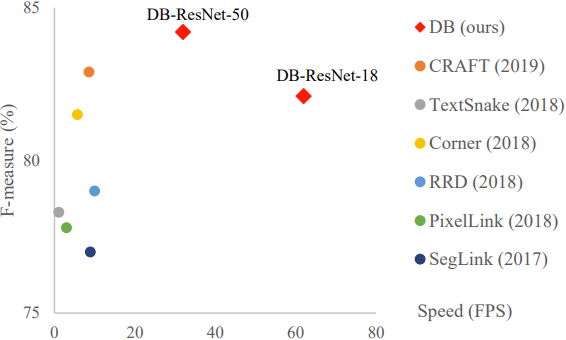
В сочетании с FPN, deformable convolutions, детектированием центральной части строки при обучении, это обеспечивает весьма высокие показатели по F-мере на датасете MSRA-TD500:
Анализ структуры документов
Перейдем к работам, посвященным анализу семантической структуры документов и извлечению из них структурированной информации в виде полей, таких как адрес, телефон, название компании, итоговая сумма и т.п.
Сложность задачи в том, что рассматриваются документы, не имеющие жесткой структуры, такие как чеки, инвойсы, или даже договора. Интересующие нас поля не имеют строгой привязки к координатам, а находить их при этом необходимо, в том числе и на новых разновидностях документов, не встречавшихся ранее в обучающей выборке.
Google и Microsoft в своих keynote talks представили весьма схожие между собой подходы примерно годичной давности. Если не вдаваться сильно в детали, оба подхода подразумевают в качестве первого этапа «давайте сначала распознаем весь текст на документе», а затем уже решают задачи поиска значимых полей и зависимостей «ключ-значение», используя текстовые и позиционные эмбеддинги, применяя для этого трансформеры с многоголовым вниманием. Модели предобучаются на огромных датасетах, аналогично языковым моделям (и даже используя схожие цели в обучении).
Довольно сильный противовес таким подходам представлен в работе “Visual FUDGE: Form Understanding via Dynamic Graph Editing” , в которой задача решается обучением лишь визуальных признаков на сравнительно небольшом датасете. При этом достигается практически та же точность детектирования зависимостей на документах, а в ситуации с плохим качеством распознанного текста, на датасете исторических документов NAF метод и вовсе превосходит известные ранее подходы. Что особенно приятно, авторы опубликовали код на GitHub.
Задача, поставленная в работе – находить текстовые строки на документе и определять наличие взаимосвязей между ними. Общая схема подхода представлена на диаграмме:
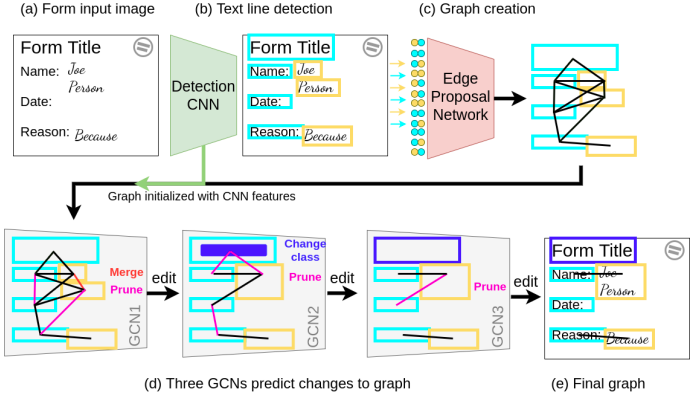
В качестве детектора объектов используется сверточная сеть с «головой» от YOLO
Гипотезы ребер предсказывает двухслойная полносвязная сеть, она получает признаки от всех пар найденных объектов и классифицирует их на принадлежность одной сущности, не связанным сущностям или наличию связи между ними
Первоначальный граф состоит из половины обнаруженных связей с наибольшими оценками
Наряду с геометрическими признаками, в узлах и ребрах графа используются признаки с двух слоев сверточной сети (низкоуровневые и высокоуровневые), которые извлекаются с помощью ROIAlign с паддингом вокруг найденных объектов и обрабатываются дополнительно маленькой сверточной сетью, она и формирует итоговый одномерный вектор признаков
Далее граф обрабатывается в три этапа (ровно столько, по мнению авторов, необходимо и достаточно) с помощью графовой сверточной сети (GCN)
GCN предсказывает, как именно граф стоит отредактировать: любое ребро может быть удалено (prune), может соединить два узла в один (merge), либо ребро будет классифицировано как group или relationship
Для вершин сеть предсказывает тип сущности: заголовок/вопрос/ответ…
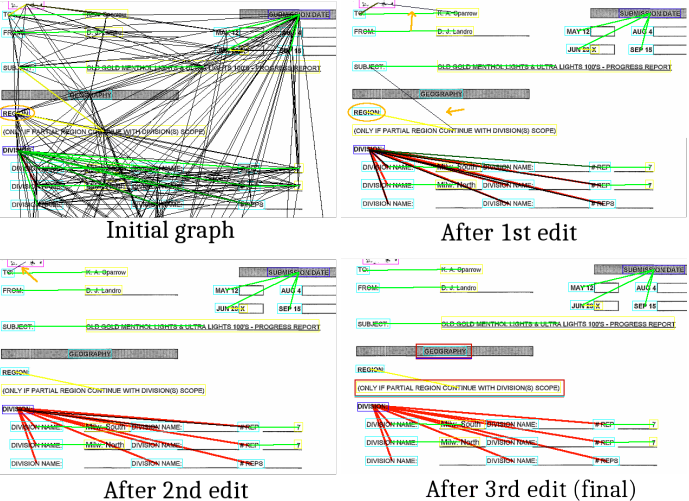
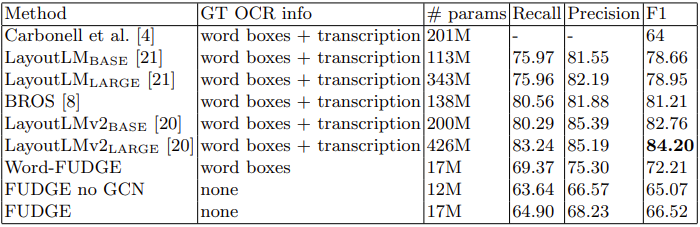
Результаты на датасете FUNSD далеки от SOTA, однако следует учитывать размер модели и тот факт, что она совсем не использует текстовые признаки. А еще, по общему мнению нашей команды, это была одна из лучших презентаций на ICDAR-2021!
Исправление дефектов на изображениях документов
Еще одно направление исследований, за которым просто интересно понаблюдать – исправление сложных геометрических дефектов на изображениях документов:
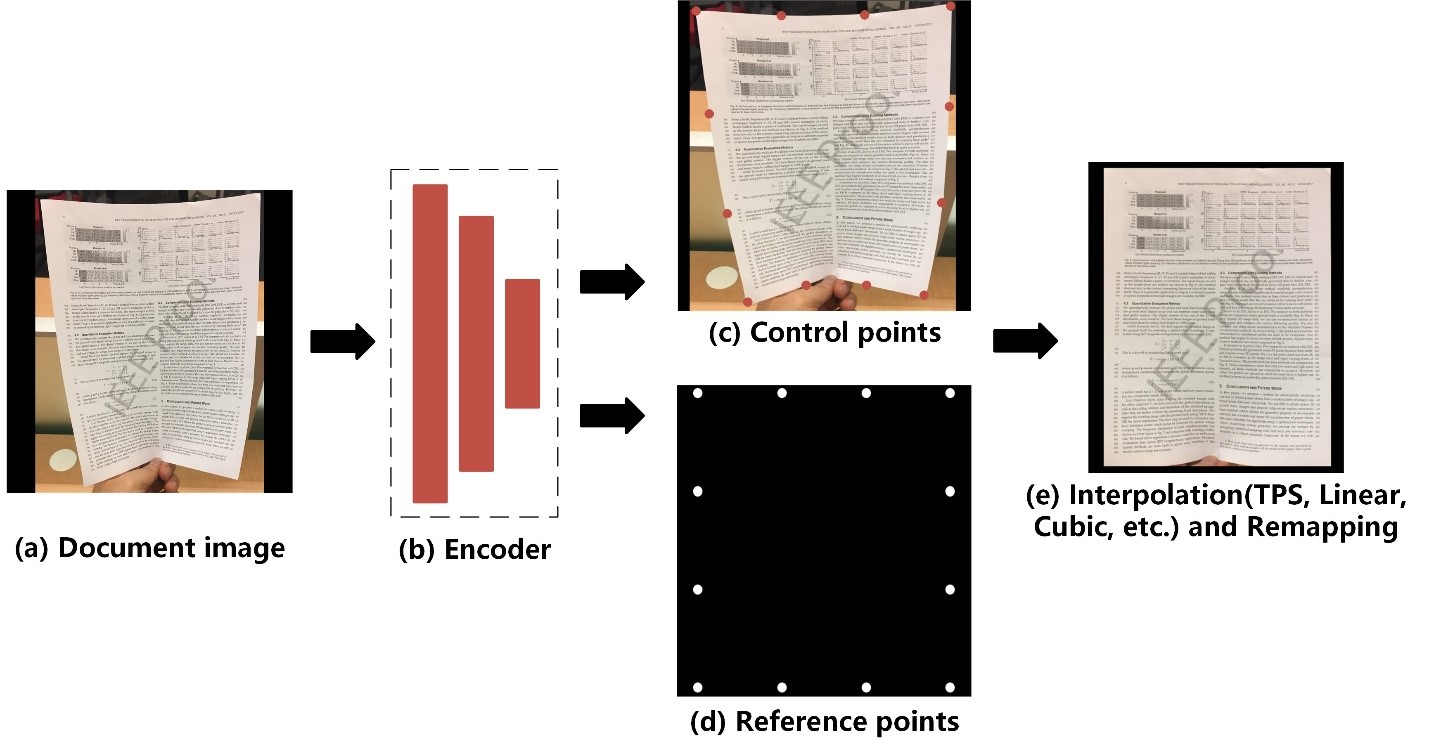
Метод, предлагаемый авторами работы “Document Dewarping with Control Points” предельно прост: обычная сверточная сеть-энкодер обучается предсказывать положение «контрольных точек» на изображении документа, а также референсные координаты этих же точек. По сути, сеть определяет поле векторов перемещения в низком разрешении, а исправление (dewarping) осуществляется через интерполяцию этих векторов для каждой точки.

«Неужели это работает?» - пожалуй, этот вопрос задавали себе практически все слушатели. Выглядит подозрительно, учитывая, насколько сложен альтернативный подход (“End-to-end Piece-wise Unwarping of Document Images”), демонстрирующий схожее качество. Быть может, среди читателей найдутся желающие это проверить? Авторы публикации пообещали выложить исходный код и, что не менее важно, свой синтетический датасет для обучения модели на GitHub, однако «воз и ныне там».
Заключение
В минувшем году наметился явный тренд на то, чтобы сделать архитектуры трансформеров для задач CV более эффективными, сочетающими в себе преимущества от обычных сверток (которые обладают прекрасной обобщаемостью) и механизма глобального внимания (позволяющего лучше учитывать удаленный контекст), в связи с этим нельзя не упомянуть работы “Convolutional Vision Transformer (CvT)” и “CoAtNet: Marrying Convolution and Attention for All Data Sizes”.
Хотим также предложить вниманию читателей Хабра несколько статей, поданных на конференцию ICLR-2022. Эти работы не связаны напрямую с задачами анализа и распознавания документов. Пока что неизвестно, какие из них будут приняты, но почему бы прямо сейчас не заглянуть немного в будущее? Ведь до нового 2022 года осталось уже совсем немного!
“Patches Are All You Need?” – нужны ли нам публикации на 10 страниц, если вся идея (и код!) умещается в один твит? Статья расскажет о том, как сделать эффективное подобие трансформера из сверточной сети.
Ting Chen, Saurabh Saxena, Lala Li, David J. Fleet, Geoffrey Hinton, “Pix2seq: A Language Modeling Framework for Object Detection”. Статья на Openreview и Arxiv.
Chun-Fu Chen, Rameswar Panda, Quanfu Fan, “RegionViT: Regional-to-Local Attention for Vision Transformers”. Статья на Openreview и на Arxiv.
“Pixelated Butterfly: Simple and Efficient Sparse training for Neural Network Models”
Ankit Goyal, Alexey Bochkovskiy, Jia Deng, Vladlen Koltun, “Non-deep Networks” - нужны ли нам глубокие сети, если критичным является время inference? Статья на Openreview и на Arxiv.
А какие статьи/публикации заинтересовали вас в этом году? Мы будем очень благодарны, если вы поделитесь ими в комментариях.