

Сентиментный анализ (анализ тональности) – это область компьютерной лингвистики, занимающаяся изучением эмоций в текстовых документах, в основе которой лежит машинное обучение.
В этой статье я покажу, как мы использовали для этих целей внутреннюю разработку компании – фреймворк LightAutoML, в котором имеется всё для решения поставленной задачи – предобученные готовые векторные представления слов FastText и готовые текстовые пресеты, в которых необходимо только указать гиперпараметры.
Задача
При возникновении трудностей в работе с автоматизированными системами внутренние клиенты оставляют обращения нейтрального или же негативного характера (положительный не учитывается по причине того, что таких обращений очень мало).
Анализ тональности текста позволит понять, что в обращении пытается донести пользователь – что-то нейтральное или негативное. Нас интересуют случаи, где напрямую описываются проблемы в автоматизированной системе и на что требуется внимание и проведение дальнейшего анализа.

Первым этапом мы загружаем и обезличиваем данные. Теперь можно приступать к ручной разметке обращений и формированию датасета, на основе которого модель будет обучаться и тестироваться. В состав этого датасета вошли 1500 вручную размеченных экземпляров. В дальнейшем мы добавили в выборку еще 2300 сэмплов из числа правильно размеченных моделью обращений.
Предобработка данных
Предобработаем данные с помощью регулярных выражений, убрав лишние символы и стоп-слова. Кроме того, приведем слова к нормальной форме с помощью библиотеки pymorphy2.
data['text'] = data['text'].replace("[0-9!#()$\,\'\-\.*+/:;<=>?@[\]^_`{|}\"]+", ' ', regex=True)
data['text'] = data['text'].replace(r'\s+', ' ', regex=True)
data['text'] = data['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop_words)]))
data['text'] = data['text'].apply(lambda x: ' '.join([morph.parse(word)[0]. normal_form for word in x.split()]))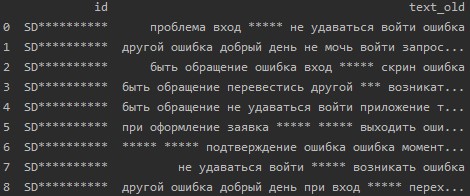
Описание модели
Далее мы формируем на основе размеченного датасета обучающую (65% от его размера) и тестовую (35% соответственно) выборки и задаем гиперпараметры для модели. Мы будем использовать текстовый пресет, который был реализован специально для выполнения NLP задач.
automl = TabularNLPAutoML(task=Task('binary', metric = f1_binary),
timeout=2000,
memory_limit=16,
cpu_limit=4,
text_params={'lang': 'ru'},
general_params={'nested_cv': False,
'use_algos': [['linear_l2', 'lgb']]},
reader_params={'cv': 3, 'random_state': 42}task=Task(‘binary’, metric = f1_binary) – в качестве задачи мы выбираем бинарную классификацию и метрики функцию, которая вычисляет F1-score
timeout=2000 – ставим ограничение работы модели по времени на 2000 секунд
memory_limit=16 – обозначаем объем выделяемой RAM
cpu_limit=4 – обозначаем число выделяемых ядер
text_params={‘lang’: ‘ru’} – в качестве текстовых параметров выбираем русский язык
general_params={‘nested_cv’: False – обозначаем, что нам нет необходимости в выполнении оптимизации гиперпараметров
‘use_algos’: [[‘linear_l2’, ‘lgb’]]} – в качестве используемых алгоритмов мы обозначаем ридж-регрессию и ансамбль LightGBM
Обучение модели:
Код обучения модели выглядит следующим образом:
roles = {'target': 'sentiment', 'text': ['review']}
pred = automl.fit_predict(train_data, roles=roles, verbose=3)
print('oof_pred:\n{}\nShape = {}'.format(pred, pred.shape))
class_result = classification_report(y_true=train_data['sentiment'].values, y_pred=np.where(pred.data[:, 0] >= 0.5, 1, 0), target_names=['Neutral', 'Negative'])
print(class_result)roles = {‘target’: ‘sentiment’, ‘text’: [‘review’]} – описываем ключевое и текстовое поля
pred = automl.fit_predict(train_data, roles=roles, verbose=3) – обучаем модель на основе обучающей выборки, передаем затрагиваемые поля
На выходе мы имеем одномерный массив, который показывает вероятность отнесения обращения к негативному классу
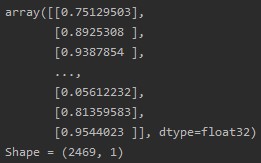
При обучении модели значение метрики F1-score достигло 0.894, соответственно можно сделать вывод о том, что модель хорошо справляется с задачей определения нейтральных и негативных обращений.

Также одним из способов оценить работу модели в целом можно по кривой ROC-AUC, которая описывает площадь под кривой (Area Under Curve – Receiver Operating Characteristic).

Объяснение работы модели
В качестве подтверждения вышесказанного можно привести работу встроенного в LAMA модуля – LIME, который раскрывает работу модели окрашивая слова в тот или иной цвет, в зависимости от их эмоционального окраса.Реализация данной возможно представлена на коде ниже:
lime = LimeTextExplainer(automl, feature_selection='lasso', force_order=False)
exp = lime.explain_instance(data.iloc[1013], labels=(0, 1), perturb_column='review')lime = LimeTextExplainer(automl, feature_selection=’lasso’, force_order = False) – вызываем функцию LIME и в качестве параметров передаем нашу обученную модель, в качестве алгоритма отбора фич – LASSO (least absolute shrinkage and selection operator – наименьшее абсолютное сжатие и оператор выбора)
exp = lime.explain_instance (data.iloc[1013], labels=(0, 1), perturb_ column= ‘review’) – далее в качестве параметров передаем случайную строку нашего датасета, обозначаем подписи классов и затрагиваемый столбец
Применяем его к обращению, которое не содержится в размеченных данных и получим следующий результат:


Рассматривая данный пример, мы видим, что модель наиболее явно выделяет относящиеся к негативу слова – вход и ошибка, которые сигнализируют о том, что в данной автоматизированной системе имеются какие-то проблемы со входом.Теперь рассмотрим пример, где встречаются слова обоих классов:


Мы видим, что слова спасибо и пожалуйста, правильно распознаны в нейтральный класс, слова маршрут сигнализируют о проблемах с подключением, которое занимает длительное время, что правильно относится к негативному классу.
На что ещё способен фреймворк
Прежде всего стоит выделить мультиклассовую классификацию, синтаксис реализации которой идентичен с бинарной, но в качестве задачи мы выбираем multiclass:
automl = TabularNLPAutoML(task=Task('multiclass', metric = f1_score)
. . .Доразметив нашу выборку третьим (положительным) классом и обучив на ней модель, мы получим следующий результат:

Где первый столбец означает вероятность негативного окраса обращения, второй – нейтрального, третий – позитивного.
Также фреймворк может решать задачи регрессионного анализа, целью которого является определение зависимости между переменными и оценкой функции регрессии.
automl = TabularAutoML(task = Task ('reg', loss = 'rmsle', metric = rmsle_metric, greater_is_better = False)
. . .Работа с текстом
В LightAutoML имеется большое количество вариантов разработки той или иной модели, работающей с текстом. Библиотека предоставляет не только получение стандартных признаков на основе TF-IDF, но и на основе эмбеддингов:1) На основе встроенного FastText, который можно тренировать на том или ином корпусе2) Предобученных моделей Gensim3) Любой другой объект, который имеет вид словаря, где на вход подается слово, а на выходе его эмбеддинги
Среди используемых стратегий извлечения представлений текстов из эмбеддингов слов, можно выделить:
1) Weighted Average Transformer (WAT) – взвешивается каждое слово с некоторым весом
TabularNLPAutoML(task = task,
autonlp_params = {'model_name': 'wat',
'transformer_params': {'weight_type': 'idf',
'use_svd': True}}
)2) Bag of Random Embedding Projections (BOREP) – строится линейная модель со случайными весами
TabularNLPAutoML(task = task,
autonlp_params = {'model_name': 'wat',
'transformer_params': {'model_params':
{'proj_size': 300, 'pooling': 'mean',
'max_length': 200, 'init': 'orthogonal',
'pos_encoding': False},
'dataset_params':
{'max_length': 200}}}
)3) Random LSTM – LSTM со случайными весами
TabularNLPAutoML(task = task,
autonlp_params = {'model_name': 'random_lstm',
'transformer_params': {'model_params':
{'embed_size': 300, 'hidden_size': 256,
'pooling': 'mean', 'num_layers': 1},
'dataset_params':
{'max_length': 200, 'embed_size': 300}}}
)4) Bert Pooling – получение эмбеддинга с последнего выхода модели Transformer
TabularNLPAutoML(task = task,
autonlp_params = {'model_name': 'pooled_bert',
'transformer_params': {'model_params':
{'pooling': 'mean'},
'dataset_params':
{'max_length': 256}}}
)За препроцессинг текста отвечает класс токенайзера, по умолчанию применяется только для TF-IDF.
Что выполняется для русского языка:
Производится замена ё на е
Удаляются знаки препинания, отдельно стоящие цифры
Токенизация происходит по пробелу
Текст приводится к нижнему регистру
Удаляются слова, состоящие из одного символа
Опционально удаляются стоп-слова
Подводя итоги стоит сказать, что LightAutoML благодаря встроенному инструментарию способен показывать достаточно хорошие результаты в задачах бинарной или мультиклассовой классификации и регрессии.
Конкретно в нашем случае нам удалось создать модель сентиментного анализа, которая с 89% точностью определяет эмоциональный окрас обращения и слова, которые оказывают на это наибольшее влияние.