
Test-driven development — по-прежнему спорная тема. Часто встречается обоснованное, в общем-то, мнение, что такая разработка нужна только большим компаниям, потому что только у них достаточно ресурсов для создания и поддержки большого количества тест-кейсов. Но сегодня на примере iOS-приложения Маркета я покажу, что стремление как раз обратное: хочется, чтобы тесты поглощали как можно меньше времени разработчиков.
Меня зовут Даша, работаю в команде iOS-разработки Яндекс.Маркета. Два года назад мы поняли, что без автотестов нам тяжело: с их помощью мы снизили вероятность крешей после релиза и ускорили регрессионное тестирование. Релизы приложения происходят еженедельно, и это большая нагрузка на тестировщиков и разработчиков — протестировать всё руками и быстро внести правки за несколько дней не получилось бы. Я постараюсь порефлексировать и рассказать, как эволюционировал наш подход к UI-тестам за это время, и, более конкретно, какие работы мы провели для их «улучшения»: почему решили избавиться от JSON-моков и как справились с этой задачей.
Процессы, цифры, даты
2019 vs 2021
Наши мобильные команды затащили инфраструктуру для автотестов в проекты Яндекс.Маркета ещё в 2019 году. Тогда же, летом 2019, был сделан первый рывок к автоматизации.
Как это происходило? Тестировщики создали пул регрессионных тест-кейсов, разбили их по экранам приложения (например «Вишлист», «Главная», «Карточка товара» и так далее). Стажёры покрывали большую часть составленных тест-кейсов. Разработчики подхватывали и доделывали тесты для уже «готовых» (покрытых
accessibilityIdentifier) экранов. При разработке новых фич тестировщики сразу же заводили задачи на покрытие свежих функциональностей автотестами.Таким образом тестировщики и разработчики автоматизировали порядка ~180 тест-кейсов за несколько месяцев. В то время релизы происходили еженедельно, в команде разработки было 8 человек, в команде тестирования — 5, и с помощью автотестов удалось добиться того, что регресс занимал один-полтора дня. То есть с увеличением числа фич в последние годы регресс не замедлился, а даже немного ускорился. Без автоматического тестирования только регресс на сегодняшний день занимал бы около недели.
Как всё устроено сейчас:
- Над проектом работают 37 разработчиков и 30 тестировщиков.
- К ноябрю 2021 года силами разработчиков и тестировщиков автоматизировано ~400 тест-кейсов.
- Наши тестировщики тратят полдня на короткий тест-ран и до полутора дней на полный, прогоняя руками от 110 до 150 тест-кейсов.
- Прогон автотестов на CI занимает ~1 час 15 минут и позволяет выявить кто, когда и чем сломал тесты.
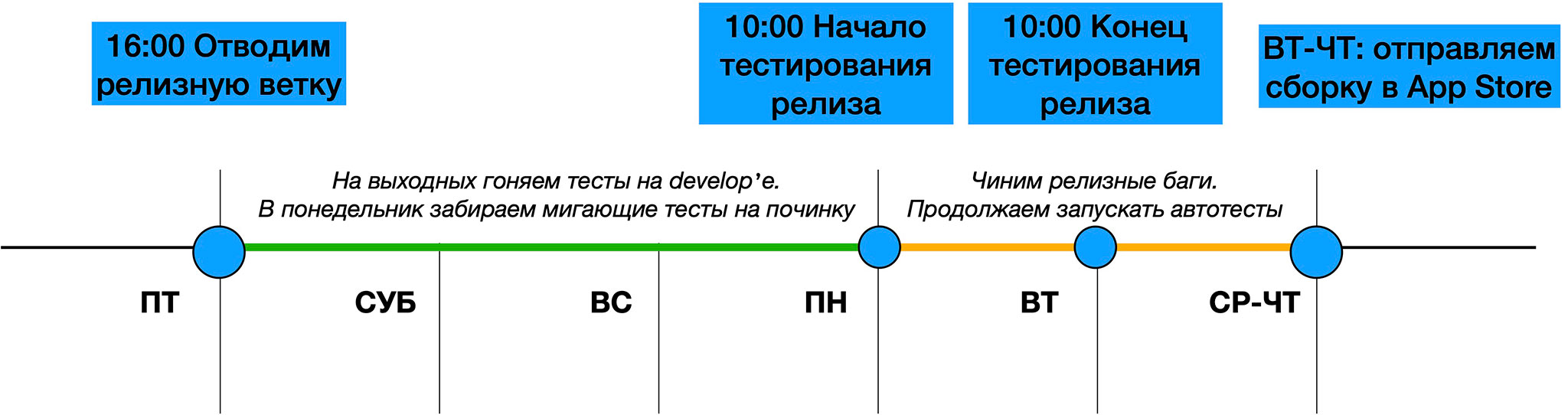
Наш релиз начинается в пятницу: и в iOS-, и в Android-команде релизная ветка отводится автоматически в 16:00. На выходных запускаются автотесты в develop: так выявляем кандидатов на первоочерёдную починку в понедельник.
В понедельник в 10 утра стартует тестирование, которое продолжается примерно до утра вторника. За это время дежурный разработчик фиксит найденные в релизе баги (на каждом пул-реквесте с фиксами также прогоняются автотесты, всё в штатном порядке). Фиксы могут затянутся до среды. После последней проверки дежурный тестировщик отправляет сборку в App Store (это может произойти как во вторник, так и, в крайнем случае, в четверг). И уже в пятницу всё начинается заново.
Наша инфраструктура
Поговорим о нашем стеке:
- Для тестирования интерфейса используем XCUITest от Apple, как самое популярное решение.
- При выборе HTTP-сервера для тестирования нам была важна базовая функциональность, поэтому остановились на GCDWebServer, чтобы мокировать ответы.
- С помощью AutoMate написали вспомогательные методы для работы с тестами. Мы также искали готовое решение, которое можно было бы легко использовать для конфигурации локали, клавиатуры и других настроек при запуске теста.
Что касается CI, то перед влитием задачи в develop мы прогоняем тесты (в том числе UI-) в TeamCity. По итогу прогона получаем Allure-отчёты, которые помогают увидеть детальную информацию об упавших тестах. Также в TeamCity пользуемся статистикой: она позволяет выявлять «флакающие» тест-кейсы. На такие тесты заводим задачи и фиксим их на дежурствах.
Недавно прогонов на пул-реквестах нам показалось мало: нужна была более точная статистика по флакающим тестам в develop. Тогда мы ввели практику ночных прогонов на CI. Каждую ночь, по расписанию, мы собираем статистику по состоянию тестов в develop — это позволяет с утра видеть состояние всех UI-тестов и отлавливать нестабильные.
При написании UI-тестов используем шаблон Page Object: с помощью него можно представить в коде иерархию элементов страницы приложения. Этот шаблон часто используется при написании UI-тестов и про него написано много статей, но главное его преимущество — с его помощью мы получаем красивую структуру теста, переиспользуем уже написанный код.
Как продолжаем поддерживать и развивать UI-тесты
Одно дело — затащить инфраструктуру и написать кучу тестов, совсем другое — продолжать их написание, когда команда растёт, и поддерживать адекватное время прогона на CI при появлении новых функциональностей. У нас уже есть двухлетний опыт поддержки и улучшения наших тестов, теперь хотим поделиться им с вами.
Есть два способа улучшить UI-тесты:
-
Ускорять время прогона на CI
Чем больше тест-кейсов было покрыто, тем больше времени занимал прогон на CI. В конце 2019 года 180 тест-кейсов при прогоне на 1 девайсе на CI занимали 2,5 часа. Тогда мы узнали про возможность распараллеливания UI-тестов и одновременного прогона сразу на нескольких девайсах — после включения этой настройки на CI время прогона уменьшилось до 40 минут. -
Ускорять время написания или поддержки тестов командой
Про этот пункт мы в подробностях поговорим далее.
Убираем повторы
Если запустить все ваши тесты и посмотреть, какие действия повторяются, что вы увидите?
Скорее всего, то же, что и мы:
- В большой части тестов, чтобы проверить нужный функционал, надо сначала авторизоваться в приложении. Мы используем в приложении стандартную авторизацию Яндекса, и раньше в тестах по-честному проходили все её шаги: заходим в профиль > нажимаем на кнопку > вводим логин > пароль. В сумме это отнимает 7–10 секунд. А теперь представьте, что у нас 100 юзкейсов имеют предусловие «пользователь авторизован в приложении». Решили замокать авторизацию и при прогоне тестов подменять менеджер авторизации на
StubAccountManagerс нужными нам параметрами. В setUp-методе базового класса тестов добавили конфигурацию, хотим ли мы быть авторизованными в приложении (и под каким аккаунтом.) Таким образом сэкономили на CI 16 (!) минут. - Многие тесты повторяют друг друга: открывается один и тот же экран, но при этом в одном тесте проверяется видимость хедера, а в другом — кнопки. Почему бы это не проверять в одном тесте? Время от времени мы проводим такой рефакторинг тестов, объединяем сценарии, в которых не важен порядок действий, если сомневаемся — уточняем у тестировщиков.
- Повторяются переходы в нужную часть приложения. Например, мы очень много тестируем экран выдачи (т.е результатов поиска), но для того чтобы на него попасть, приходится совершать одни и те же действия: встать на строку поиска -> вбить запрос -> нажать поиск -> получить выдачу. Чтобы сократить это время, мы воспользовались механизмом диплинков — теперь на выдачу мы попадаем сразу же, при запуске приложения, минуя поисковую строку. Оставили только один тест c упомянутыми переходами для тестирования поиска.
В технические детали первого и третьего пункта я углубляться не буду, а поговорим мы с вами дальше про наш опыт с мокированием запросов.
Мокирование запросов
В начале нашего пути мы использовали стандартный способ мокирования запросов: записывали нужные нам ответы от сервера в формате JSON и складывали их в
.bundle. При прогоне тестов отправленные запросы мэтчились с JSON из указанного бандла и подставлялись в качестве ответа. Это достаточно распространённый метод мокирования, но у него есть несколько недостатков:- Переиспользование моков: в самом начале втаскивания UI-тестов был создан
DefaultSet.bundle— бандл с общими моками. Эти моки по умолчанию загружались в каждый тест, их можно было переопределить по желанию другими моками, указав их непосредственно в тесте. Дефолтный набор JSON-файлов было очень сложно переиспользовать в тестах, так как часто нужно было минимально, но изменить ответ от сервера. По этой причине набор бандлов очень быстро стал разрастаться, что приводило к недостатку из следующего пункта. - При изменении контракта API тяжело чинить тесты. Чем больше мы писали тестов, тем больше становилось в нашем проекте JSON-моков. Например, на карточку товара у нас порядка 100 тестов, и на ~80 из них нужно было записать свои моки. А теперь представьте: API меняется, переезжаем на новую ручку. Что делать? Как поддерживать тесты? Пришлось перезаписывать все 80 ответов. На это уходили недели времени и куча сил.
Поиск подходящего решения
Нам нужно было прийти к таким мокам, которые можно было бы легко поддерживать, максимально переиспользовать и легко вносить минимальные изменения при написании новых тестов. Решение подсмотрели у нашей Android-команды — DTO-моки.
Что это такое? Базовая идея: в тестах используем Codable-модели вместо громоздких JSON, создаём константы для переиспользуемых сущностей, пишем необходимые обёртки для их лёгкого изменения. Для формирования ответа от сервера сериализуем модели в виде JSON и отдаём тестовому приложению.
| Критерий сравнения | JSON-моки | DTO-моки |
| Изменение моков | Тяжело, так как надо перебирать все JSON-файлы. | Легко, так как нужно изменить саму структуру модели (остальные необходимые изменения подскажет компилятор). |
| Ревью | Тяжело ревьюить боле 10 тысяч строк JSON-файлов (и практически никто этого не делает). | Есть константы, у которых меняем отдельные поля, легко ревьюить. |
| Прозрачность | Большие JSON-файлы, непонятно что используется внутри теста. | Состояние видно прямо в коде теста. |
| Парсинг | Тестируется. | Тестируется, так как DTO сериализуются и десериализуются как реальные ответы, полученные от сервера. |
| Лёгкость написания | Достаточно легко записать, вставив JSON ответов от сервера. | Можно переиспользовать константы (легко), иногда придётся дополнять модели данными (терпимо) или делать новые (плюс-минус терпимо). |
Реализация в проекте
Так как все наши тесты уже жили на JSON-моках, то при переезде на новые моки одной из задач было поддержать уже существующие. Что касается архитектуры, то был выработан следующий подход:
- Мы, как и раньше, используем GCDWebServer. Только теперь необходимые ответы загружаем не из указанных бандлов в формате JSON, а из «состояния» тестового приложения, сериализуя нужные DTO-модели в виде ответа от сервера в формате JSON.
- Тестовое приложение — это набор состояний (
[State]), которые можно задать непосредственно из теста. Чтобы управлять этими состояниями, мы создали структуру. Назовём её DTOStateManager. Это менеджер по управлению логикой подмены состояний из теста. Весь интерфейс этого менеджера содержит два метода:/// Новый стейт менеджер моков, без бандлов protocol DTOStateManager { /// Устанавливаем стейт в хранилище состояний func setState(newState state: LocalState) /// Загружаем стейт, ищем нужный DTO-мок и формируем JSON для ответа /// - Parameters /// - request: запрос, по URL которого находим нужный мок /// - Returns: JSON c ответом func loadState(_ request: GCDWebServerRequest) -> GCDWebServerResponse? } - Для каждой User story мы создавали так называемые State — структуры состояния сценария, который можно бы было устанавливать напрямую из теста. Например,
CartState— состояние корзины в приложении. Внутри этого состояния содержатся методы установки содержимого корзины, трешхолда бесплатной доставки, количеству монеток в корзине и так далее. Все запросы, которые имеют отношения к корзине, можно настроить в этом стейте.
Посмотрим на реализацию стейта корзины на примере нашего проекта: он состоит из списка DTO-моков запросов, тело которых сериализуется и возвращается в GCDWebServer как ответы на запросы, отправленные приложением. Поиск этих самых DTO-моков конкретно в нашем случае мы производим по совпадению URL (аналогичной стратегией пользовались и в случае с JSON из бандлов.)
Стейт корзины пользователя
public struct CartState: LocalState {
// MARK: - Private
private var thresholdInfoHandler: GetThresholdInfo?
private var userCartHandler: GetUserCart?
...
// MARK: - Public
/// Инициализируем DTO ответа на запрос для трешхолда в корзине
/// - Parameter info: значения для трешхолда
public mutating func setThresholdInfoState(with info: ThresholdInfo) {
thresholdInfoHandler = GetThresholdInfo(info: info)
}
/// Инициализируем DTO ответа на запрос о содержимом корзины
/// - Parameter offers: базовая настройка содержимого корзины с помощью офферов
public mutating func setUserCart(with offers: [Offer]) {
userCartHandler = GetUserCart(offers: offers)
}
...
}Вот так происходит мэтчинг запросов и нужных структур для подмены ответа от сервера. Совпадение по URL для нас работает отлично, но может не запуститься в вашем случае.

В самом коде теста вся настройка состояния выглядит так:
var cartState = CartState()
"Настраиваем стейт корзины".ybm_run { _ in
cartState.setThresholdInfoState(with: .regionWithoutThreshold))
cartState.setUserCart(with: [.protein])
stateManager?.setState(newState: cartState)
}Что тут происходит? Мы инициализируем дефолтный стейт корзины и начинаем его менять: устанавливаем плашку доставки, кладём содержимое корзины (протеин) и отправляем в менеджер состояний её новый статус. При вызове замоканного запроса из приложения, из stateManager загружается (через ‘loadState’) DTO-мок запроса, сериализуется в JSON и отдаётся как респонс.
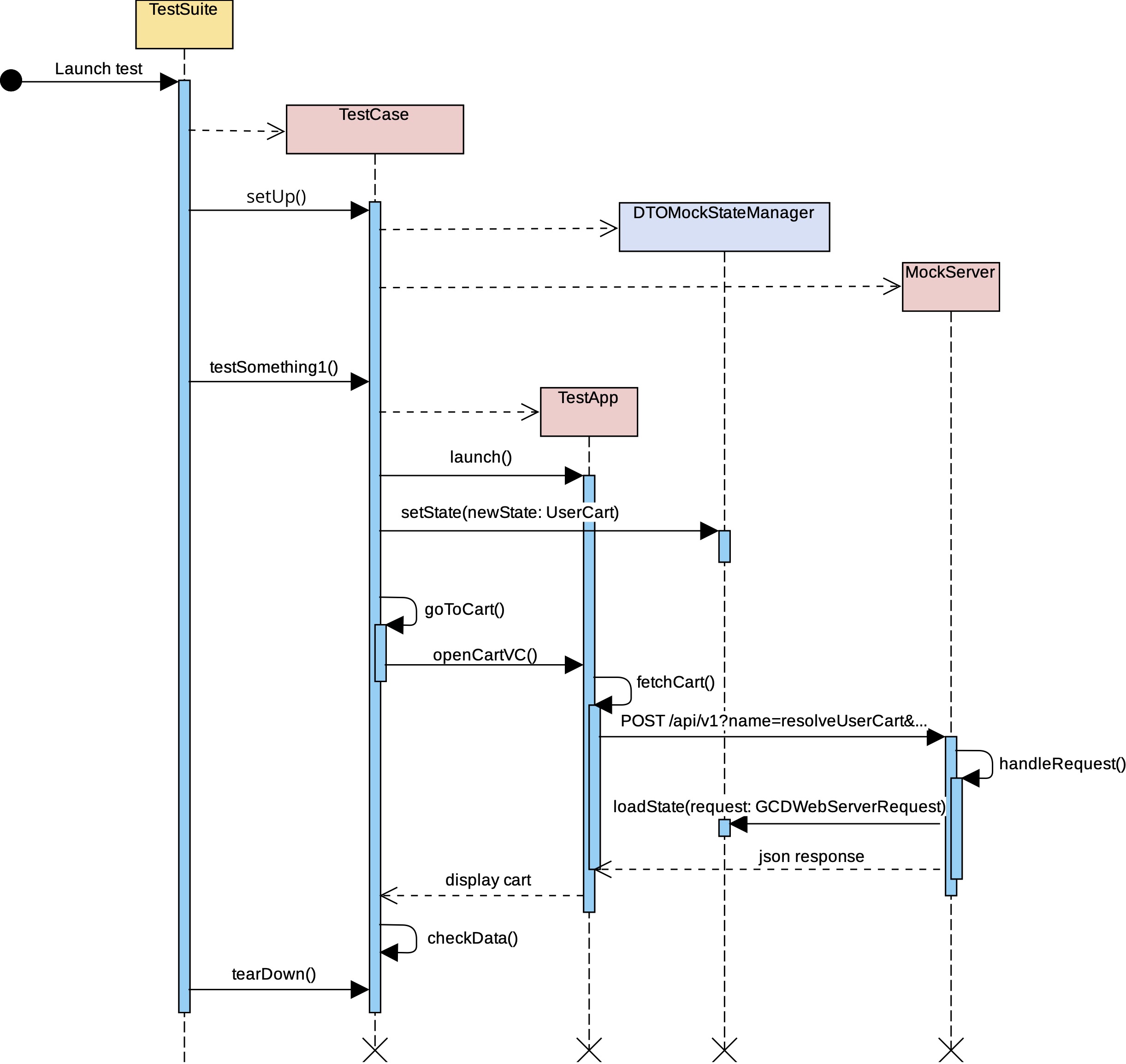
Вот так мы и внедрили в наши UI-тесты мокирование с помощью DTO-моделей.
Заключение
Надеюсь, эта статья была полезной как для разработчиков, которые только думаю внедрять UI-тесты в свой проект, так и для команд, которые находятся в поиске улучшений. Для себя мы сделали вывод, что поддерживать и улучшать тесты после внедрения — очень важная задача.
На своём опыте мы убедились, что UI-тесты не только упрощают жизнь тестировщикам и значительно ускоряют регресс перед релизом, но также очень помогают отслеживать состояния приложения. Но важно не только покрыть основные кейсы тестами, но и продолжать их поддержку.
Спустя два года после написания UI-тестов на JSON-моках мы пришли к выводу, что с ростом приложения (и, соответственно, количества тест-кейсов) нам нужно изменить существующий подход и перейти к DTO-мокам. Это позволило нам не только ускорить время разработки теста и начать более осознанно писать его, но также активно переиспользовать моки вместо ненужного дублирования. DTO-подход также позволил легко править тесты при изменении контрактов бэкенда. Для активно растущего приложения это очень важно.
ivankudryavtsev
Видимо, ускорили "темпы регрессионного тестирования". Обычно, прогресс ускоряют, а вы регресс? Лучше поправить.
dasharedd Автор
Спасибо! Поправили :)