
Любой компании важно понимать своих клиентов, знать их нужды и желания. Наиболее простой и очевидный способ получить обратную связь от потенциальной аудитории – провести опрос. Сегодня существует довольно много опросных сервисов и инструментов, нацеленных на исследование поведения человека. Ожидается, что с их помощью можно получить точную и полезную информацию для понимания образа мыслей и действий потенциальных клиентов. Но так ли это на самом деле?
Результаты исследований будут достоверными, если они хорошо отражают зависимости, присущие генеральной совокупности. Но поскольку охватить и измерить данные всей генеральной совокупности невозможно, на практике обычно применяется выборочный метод, когда вся совокупность объектов исследования обобщается до некоторого ограниченного подмножества.

Существуют два важных требования, предъявляемых к выборке: она должна быть достаточного размера и достоверно отражать важные для исследования параметры генеральной совокупности (быть несмещенной). Соблюсти оба этих требования на практике довольно сложно. Набрать большую и качественную, а значит несмещенную выборку дорого и проблематично в реализации, поскольку рекрутирование респондентов происходит оффлайн.
Есть альтернативный вариант – это онлайн-рекрутмент, который давно зарекомендовал себя как максимально быстрый, простой и дешевый способ привлечь респондентов для различных исследований. Однако выборки, набранные в интернете, являются неслучайными и, как правило, искажены по ряду параметров, даже если процедура рекрутирования была хорошо спланирована. Так, круг онлайн-панели, как минимум, ограничен пользователями интернет площадок, на которых размещалась реклама участия в исследовании. Онлайн-панелям также присущ перекос в сторону «профессиональных» респондентов, которые регулярно зарабатывают на исследованиях в интернете. Есть еще и другие, неизвестные причины смещения выборки, которые могут исказить оценку медиа активности онлайн-респондентов.
В этой статье мы расскажем о методе Propensity Score Adjustment, который применим для коррекции смещений и улучшения данных, полученных на онлайн-панелях. Этот алгоритм помогает калибровать (уточнять) вклад респондентов, набранных в панель онлайн.

Неслучайность рекрутмента онлайн-панели приводит к ее социально-демографическому перекосу, что влияет на смещение оценок активности на такой выборке – они значимо отличаются от оценок на основе эталонной вероятностной выборки. Когда в нашем распоряжении есть две выборки, одна из которых набрана не случайно (онлайн), а вторая – вероятностная и эталонная (набрана оффлайн), мы можем сравнить данные респондентов из онлайн-панели с данными «образцовых» оффлайн-панелистов и определить степень смещения оценок активности для каждого респондента. Одновременно можно проанализировать перекос онлайн-панели по социально-демографическим атрибутам, которые значимы для исследования и влияют на оценку активности.
Если в данных появляется перекос по важной для исследования демографической группе, который нельзя исправить, или же эта группа вовсе отсутствует, подумайте о применимости таких данных и коррекции процедуры рекрутирования. Если социально-демографические атрибуты хорошо сбалансированы или перекосы по ним поддаются простой первичной коррекции, можно переходить к исправлению смещения оценок активности. При этом нас интересует только факт и степень смещения.
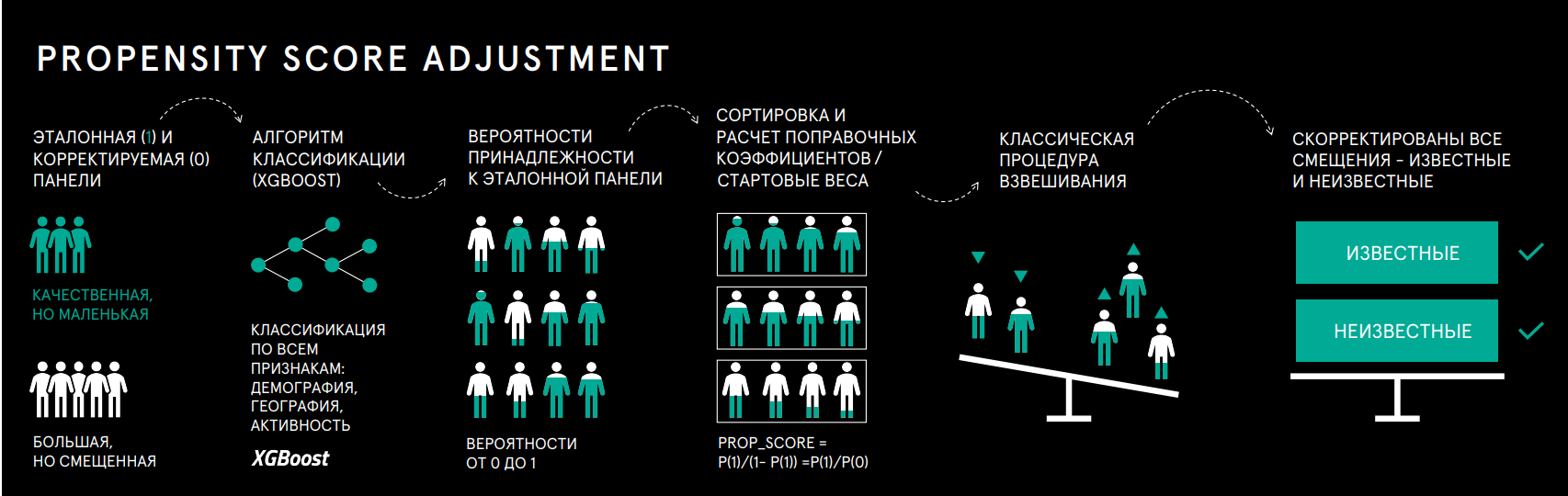
Нам не обязательно знать причину смещения оценок активности онлайн-панелистов, важно лишь понимать, насколько сильно они отличаются от эталона. Меру этого отличия можно узнать, построив модель классификации, которая попытается предсказать, к какой выборке принадлежит каждый конкретный респондент – к корректируемой смещенной или к эталонной. Обозначив эталонную выборку за единицу, а корректируемую – за ноль, на «выходе» классификатора для каждого респондента мы получим вероятность принадлежать эталонной выборке. Зная данную вероятность, можно рассчитать для респондентов оценки склонности prop_score = p(1)/(1- p(1)) =p(1)/p(0), которые по сути являются сравнимой с единицей мерой отличия корректируемой выборки от эталонной.
Действительно, сумма вероятностей эталона и корректируемой выборки p(0)+p(1)=1. Если респондент похож на респондентов эталонной панели и вероятность p(1)>0.5, то отношение p(1)/p(0) будет больше единицы. Так мы получим оценку склонности prop_score, которая увеличивает ранг этого панелиста. Если человек, наоборот, не похож на эталон, то получим отношение p(1)/p(0)<1 и оценку, понижающую ранг такого респондента. Итоговые коэффициенты, корректирующие смещение онлайн-выборки, можно рассчитать по методу Хорвица-Томпсона.
Этот расчёт обоснован тем, что описанная модель классификации строится на основе некоторых ковариат, которые включают географические/демографические параметры и активность. Респонденты, чьи ковариаты, а значит и оценки склонности похожи, будут сопоставимы в эталонной и корректируемой выборках. Для удобства сопоставления и минимизации систематической модельной ошибки, массив оценок склонностей обобщается до пяти классов, на каждый из которых приходится по 20% объединенной выборки. Поправочный коэффициент для каждого класса вычисляется как отношение доли по этому классу для эталона к доле по классу для корректируемой выборки.
Существует несколько методов коррекции смещения выборок с использованием полученных коэффициентов:
-
Взвешивание (Weighting)
Этот метод предназначен для коррекции известных перекосов выборок по социально-демографическим атрибутам. Например, для выравнивания вынужденных перекосов по географии под эталонные доли населения. Однако взвешивание может учитывать и корректировочные коэффициенты, рассчитанные в рамках Propensity Score Adjustment. Для реализации этого подхода корректировочные коэффициенты респондентов подаются на «вход» взвешивания в качестве стартовых весов. Так мы одновременно устраняем два вида смещения: известное смещение соцдема, которое обусловлено вероятностной процедурой рекрутирования и неизвестное смещение онлайн-выборки. Методика взвешивания более подробно описана здесь.
-
Сопоставление (Matching)
В этом методе каждая оценка склонности в целевой выборке сопоставляется с наиболее похожей оценкой из онлайн-выборки. Так для каждого респондента в целевой выборке будет найден наиболее близкий соответствующий респондент в корректируемой выборке. Онлайн респонденты, для которых не были найдены соответстветствия, отбрасываются. В результате набор оставшихся онлайн-респондентов должен стать похожим на целевую совокупность.
В своей практике мы чаще всего обращаемся к одному из перечисленных методов – RIM-взвешиванию, поскольку при взвешивании нам не нужно отбрасывать панелистов из онлайн-выборки. Кроме того, этот метод хорошо соответствует специфике нашего производства данных.
На этапе моделирования оценок склонностей важно выбрать классификатор, который даст наилучшую точность и снижение систематической ошибки. Авторы оригинального исследования Pew Research рекомендуют использовать для корректировки онлайн-опросов модели случайных лесов (random forest). Взяв за основу данные и результаты исследования Pew Research, мы попробовали улучшить точность подгонки классификатора и коррекцию смещения с помощью градиентного бустинга XGBoost. Использование этого алгоритма машинного обучения показало хорошие результаты коррекции итогового смещения. Взвешивание данных оценками склонности XGBoost позволило устранить около 40% первоначальной систематической ошибки, чего авторам Pew Research не удалось добиться с помощью модели случайных лесов в комбинации с другими методами.
Ниже представлены результаты, полученные на случайной выборке размером 8000 человек для каждого из трёх поставщиков данных. Снижение систематической ошибки было рассчитано с учетом корректировочных весов Pew Research. Расчет ошибки производился по 24 целевым переменным. Для XGBoost моделирования использовались предоставленные авторами данные онлайн-выборок и эталонной синтетической популяции.

Из полученных результатов можно сделать вывод, что использование XGBoost, в том числе в комбинации с другими способами коррекции, существенно улучшает качество онлайн-данных.
Онлайн- и кросс-исследования являются одной из наиболее актуальных тенденций в сфере медиа. Поэтому интерес к проблеме качества данных онлайн-панелей закономерно растет и требует от медиаисследователей вдумчивого анализа и применения эффективных методов, которые отвечают запросам рынка. Сейчас стандарт коррекции онлайн-выборок находится на стадии обсуждения и разработки и метод Propensity Score Adjustment, который мы рассмотрели, может стать общепринятым способом коррекции онлайн-панелей. Практическая реализации этого алгоритма – большая тема, достойная отдельного текста. Ей мы посвятили вторую часть статьи. Надеемся, что наш опыт привлечет внимание к проблеме качества данных и окажется полезен всем, кто анализирует данные онлайн-панелей и принимает решения по результатам таких исследований.
Авторы: команда департамента Data Science, обработки данных и аналитики, Mediascope