

Привет, Хабр! Мы продолжаем делиться технологической кухней Retail Rocket. В сегодняшней статье мы разберем вопрос выбора БД для хранения больших и часто обновляемых данных.
На самом начальном этапе разработки платформы перед нами возникли следующие задачи:
- Хранить у себя товарные базы магазинов (т.е. сведения о каждом товаре всех подключенных в нашу платформу магазинов с полным обновлением 25 млн. товарных позиций каждые 3 часа).
- Хранить рекомендации для каждого товара (около 100 млн. товаров содержит от 20 и более рекомендуемых товаров для каждого ключа).
- Обеспечение стабильно быстрой выдачи таких данных по запросу.
Схематично можно представить так:
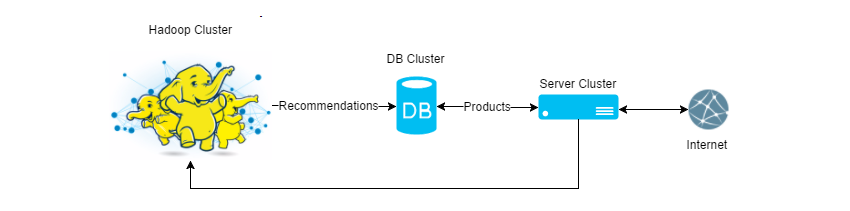
Среди популярных реляционных и документальных БД для старта мы выбрали MongoDb и сразу столкнулись со следующими трудностями:
- Оптимизация скорости обновления 100K—1M товаров за раз.
- MongoDb при записи данных упирался в диск, а призрак проблемы с вакуумом (когда запись удалена из БД, а место под нее все еще занято) заставил нас задуматься об In-memory DataBase.
Столкнувшись с первыми трудностями, мы решили продолжить поиск решения среди In-Memory Db и достаточно быстро наш выбор пал на Redis, который должен был обеспечить нас следующими преимуществами:
- Персистентность (сохраняет свое состояние на диск).
- Широкий набор типов данных(строки, массивы и т.д.) и команд работы с ними.
- Современная In-Memory Db, что оказалось немаловажным в противовес Memcached.
Но реальный мир изменил наше отношение к этим плюсам.
Чудеса персистентности

Почти сразу после запуска Redis`a в «продакшене» мы стали замечать, что временами скорость выдачи рекомендаций к товарам значительно проседает и причина была не в коде. После анализа нескольких показателей мы заметили, что в момент, когда на серверах Redis`а появляется дисковая активность, время ответа от нашего сервиса растет — очевидно, дело в Redis, а точнее в том, как он себя ведет, когда работает с диском. На некоторое время мы снизили частоту сохранения данных на диск и тем самым «подзабыли» об этой проблеме.
Следующим открытием для нас стало, что Redis недоступен все время, пока он поднимает данные с диска (это логично, конечно), т.е. если вдруг у вас упал Redis-процесс, то до тех пор, пока вновь поднятый сервис не поднимет все свое состояние с диска, сервис отвечать не будет, даже если для вас отсутствие данных гораздо меньшая проблема чем недоступная БД.
Из-за двух вышеописанных особенностей Redis`а перед нами встал вопрос: «А не отключить ли нам его персистентность?». Тем более что все данные, которые мы в нем храним, мы можем перезалить с нуля за время, сопоставимое с тем, как он сам поднимает их с диска и, при этом, Redis будет отвечать. Решено! Мы взяли за правило не хранить в Redis`е данные, без которых работа системы не возможна и, которые мы не можем быстро восстановить, а затем отключили персистентность. С тех пор прошло 1.5 года, и мы считаем, что приняли верное решение.
Выбор драйвера для Redis
Для нас с самого начала стало неприятным фактом то, что у Redis`а нет своего драйвера для .Net. Проведя тесты среди неофициальных драйверов на скорость работы, удобство использования, оказалось, что подходящий драйвер всего один. И еще хуже, что через некоторое время он стал платным и все новые функции стали выходить только в платной версии.
Нужно отметить, что с того момента прошло много времени, и, скорее всего, что-то изменилось в этой ситуации. Но быстрым анализом мы так и не увидели среди бесплатных драйверов поддержки redis-cluster, так что ситуация точно неидеальна.
Горизонтальное масштабирование
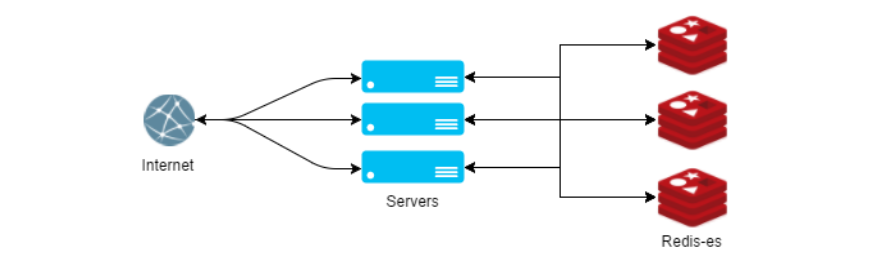
Спустя всего полгода использования Redis`а мы арендовали под него сервер с максимально допустимым количеством оперативной памяти в ДЦ, и стало понятно — шардинг не за горами. Redis-cluster, на тот момент, только собирался выходить, а ставшими платными драйвера, подсказывали, что нам придется решать эту задачу самим.
Нам до сих пор кажется, что есть только один вариант сделать шардинг в Redis`е правильно. Если описывать этот способ просто, то мы запроксировали все методы, получающие ключ записи в параметре. Внутри каждого такого метода хешируется ключ, и простым остатком от деления выбирается сервер, на который записывается/считывается ключ. Казалось бы, достаточно примитивное решение, не лишенное своих явных недостатков, позволяет нам до сих пор с успехом не думать о проблемах с горизонтальным масштабированием.
Код нашей реализации обертки для RedisClient с поддержкой sharding`а вы можете посмотреть в нашем репозитории на GitHub.
Главной задачей после внедрения шардинга стало слежение за доступностью оперативной памяти на Redis-серверах. Свободной памяти на серверах должно быть столько, чтобы при падении 1-2 Redis-машин нам хватило бы памяти для передачи всех данных на оставшиеся в бою сервера и продолжения работы до тех пор, пока вылетевшие сервера не вернутся в строй.
Первые проблемы производительности
Так как Redis может хранить только текстовые данные, то объекты перед сохранением приходиться сериализовать, а перед выдачей десериализовывать в какой-то текстовый формат. Наш драйвер по умолчанию сериализует данные в JSON-формат и мы заметили, что процесс десериализации отъедает значимое время выдачи рекомендаций. Проведя беглый анализ сериализаторов, мы приняли решение заменить стандартный серилизатор драйвера на JIL, что полностью сняло вопрос производительности сериализиторов.
В заключение
Прочитав все пункты выше, может сложиться впечатление, что Redis — это проблемная БД с кучей скрытых рисков, но на самом деле именно с Redis`ом у нас все прошло предсказуемо. Мы всегда понимали, где ждать проблем, поэтому решали их заранее. Мы используем Redis в бою уже 2 года и, хотя нас и посещают иногда мысли «А не заменить ли его «на обычную БД»?», мы все еще считаем, что сделали правильный выбор в самом начале нашего пути.
Наш чеклист «как правильно приготовить редис»:
- Хранить только те данные, которые можно быстро восстановить в случае потерь.
- Не использовать персистентность редиса.
- Свой шардинг.
- Использовать эффективный сериализатор.
Комментарии (73)

evnuh
20.10.2015 13:47+2Почему ничего не рассказали про данные? Что у вас в хадупе, что в редисе, как они туда-сюда перетекают? Как происходит решардинг, когда падает один из редисов? Плавно автоматом или принудительно вся база рехешится?
Я так понял, у вас рекомендации одни для всех, или для каждого юзера свои? То есть вы просто парсите товарные выгрузки, пихаете их в память и отдаёте на каждом запросе пользователю? Или есть какая-то сверсекретная магия?
chizh_andrey
20.10.2015 15:34Почему ничего не рассказали про данные?
Что Вам могло быть интересно про данные? Постараюсь в коментариях ответить.
Что у вас в хадупе, что в редисе, как они туда-сюда перетекают?
С хадупом работают мои коллеги, но я постараюсь ответить на ваш вопрос.
Для хадупа связь редис-хадуп односторонняя. Хадуп только заливает данные в редис, но не читает их от туда.
На сколько я знаю, никаких специальных средств для работы с редисом из хадупа не применяется, к примеру для заливки данных из спарка применяется просто драйвер jedis + модификация для поддержки нашего шардинга.
Плавно автоматом или принудительно вся база рехешится?
Постучим по дереву, нам пока такое пригодилось однажды, и мы в ручном режими изменили конфиги и перезалили данные.
Я так понял, у вас рекомендации одни для всех, или для каждого юзера свои?
В общем случае мы стараемся все типы рекомендаций персонализировать для пользователя, но не везде это дает плюс к деньгам магазина поэтому делаем это очень осторожно. В общем «Типы рекомендаций» — это уже отдельная большая тема для другой статьи, если это интересно мы с радостью опишем их.
То есть вы просто парсите товарные выгрузки, пихаете их в память и отдаёте на каждом запросе пользователю? Или есть какая-то сверсекретная магия?
Мы отдаем не товарную выгрузку, а рекомендации к товару, т.е. к этой футболке подойдут вот эти кроссовки, поэтому некоторая магия все-таки есть.
Не буду рисковать вдаваться в детали не относящихся к теме статьи.

drakmail
20.10.2015 15:03Не смотрели в сторону couchbase?
chizh_andrey
20.10.2015 15:35Нет, почему-то прошли мимо. Может подойти для наших задач?
drakmail
20.10.2015 15:39В своё время использовали для массового складирования данных от клиентов и последующего извлечения после простого map-reduce. Очень понравилось кеширование map-reduce – время получения ответа практически мгновенное. Еще всё прекрасно с горизонтальным масштабированием – просто устанавливается еще один сервер и при настройке указывается, что надо подключаться к имеющемуся (как в одном ДЦ, так и в разных). На чтение/запись скорость отличная для нас была (точные цифры сказать уже не могу — не помню). Из нюансов – для совсем мелочи не подходит, так как по дефолту берёт себе под кеши от 4Гб памяти :)
Вообще, достаточно интересный продукт, обязательно посмотрите.

stargrave2
20.10.2015 15:56+2Почему вы пишите что Redis хранит только текстовые данные? Его строки — binary safe. Можно спокойно сохранять любые бинари. Например JSON можно легко заменить на MessagePack например у которого огромное количество binding-ов под самые разные платформы и хорошая скорость сериализации.

BasilioCat
20.10.2015 16:01+3Остаток от деления на число серверов в шарде страдает в случае добавления новых узлов. В вашем случае с перезаливкой это может и не так критично (хотя перезаливка всех узлов наверняка занимает значительное время), но остальным, особенно у кого БД содержит данные (а не просто кэш) это врядли подойдет. Для решения этой проблемы существуют алгоритмы консистентного хэширования, например ketama
evnuh
20.10.2015 16:30Для их задачи с read-only in-memory данными их вариант — лучшее решение. Залить всё в оперативку — это не решардить по медленным дискам, поэтому ничего страшного абсолоютно, даже с полным решардом при добавлении нового сервера.
chizh_andrey
20.10.2015 16:43комент предназначен для поста выше
Как мне кажется, если вы работаете с БД ключ-значение то при обнавлении БД всегда существует состояние в ктором часть ключей обновилось, а часть еще нет.
Т.е. при добавлении сервера в систему есть только одна новая проблема: на новых серверах нет ключей которые там ожидаются для чтения.
Мы у себя эту проблему решаем следующим образом: мы сначало подключаем новый сервер к сервисам которые заливают данные и они обновляют ключи в старых редисах и заливают данные на новые сервера. Затем мы сообщаем фронтам(сервисам которые читают данные) о том, что появился новый сервер и они начинают читать только обнавленные ключи со всех(старый и новых) серверов.


chizh_andrey
20.10.2015 16:36Да на него мы смотрели, но смутило, что он платный и не так распространен как redis.

ZOXEXIVO
20.10.2015 17:13+2Погодите, а причем тут клиенты Redis и шардинг?
Есть StackExchange, который все базовые вещи делать умеет, а шардингом сейчас занимается сам Redis.
В 3 версии Redis (под Windows уже идет портирование) есть рекомендация указывать в имени ключа данные в фигурных скобках posts_{userId}.
В этом случае, если экземпляр запущен как кластер, он парсит имя, находит эти скобки, берет хэш от данных внутри них и на основе этой информации выбирает нужную ноду и решардинг при добавлении новых узлов происходит автоматом.chizh_andrey
20.10.2015 17:251) А почему нет? В статье пример: «как задачу шардинга решить только через клиент».
2) StackExchange: мы обязательно изучим этот драйвер и его возможности, но на момент, когда мы делали выбор БД, еще не было стабильной 3-й версии редиса и не было StackExchange-драйверов.ZOXEXIVO
20.10.2015 17:55+1Только как всегда, есть свои проблемы.
Например, есть команда MGET, которая возвращает множество значений по множеству ключей.
В обычном Redis, который запущен как кластерный, она будет работать некорректно, если значения лежат на разных шардах, но о, чудо, она работает отлично, если у вас Enterprise версия Redis (redislabs). Ну вы поняли…chizh_andrey
20.10.2015 18:00Отличное предостережение :)
В нашем случае драйвер правильно группирует запросы и отправляет на нужный редис.

Railsmax
20.10.2015 18:00А вместо самописного шардинга вы рассматривали twemproxy github.com/twitter/twemproxy? У самого проблемка с шардингом возникла — сначал тоже хотел сам написать, но потом осознал что чего-это я тут напрягаюсьсам и нашел готовое внешнее решение. Пока только 5 дней работает в продакшене но я доволен :)
chizh_andrey
20.10.2015 18:22У нас было несколько итераций поиска решения этой задачи, но именно этот прокси, по-моему, мы не исследовали. Если будут проблемы — обязательно отпишите в этот тред.
Railsmax
20.10.2015 18:45тьфу тьфу тьфу надеюсь не будут ) но если будут проблемы отпишу обяззательно

mynameisdaniil
21.10.2015 00:12Зашел сюда, чтобы написать про твемпрокси. Кушаем — ненарадуемся.
chizh_andrey
21.10.2015 11:58Как-то резервировали twemproxy на случай падения сервера?
mynameisdaniil
21.10.2015 12:05Твемпрокси ставится рядом с клиентом. И внутри себя умеет выкидывать сбойные сервера редиски или на время или навсегда.

alekciy
21.10.2015 12:30«Рядом с клиентом» в смысле клиент — бэкэнд (т.е. какой-то конкретный сервер), либо клиент — приложение. И во втором случае «случай падения сервера с twemproxy» нет, потому что в этом случае его клиент, приложение, тоже лежит?
chizh_andrey
21.10.2015 12:37Ничего не мешает упасть процессу на сервере(на том где клиент), так что это все еще SPOF. Придется городить самим high availability этой прокси.
mynameisdaniil
21.10.2015 13:05Ничего не мешает упасть и процессу вашего приложения или серверу с приложением целиком, так что пока у вас один сервер приложения это все-равно единственная точка отказа. Если серверов приложения у вас больше — все хорошо в любом случае. Упал сервер или прицесс приложения или процесс твемпрокси — не важно. Процессы поднимутся апстартом(или что там у вас), сервер поднимется админом и все будут счастливо жить дальше.
chizh_andrey
21.10.2015 13:09Вы правы. Фронтов больше чем один поэтому не страшно падение одного из них.
mynameisdaniil
21.10.2015 13:00Клиент — клиент редиски т.е. бэкэнд приложения (или кто там у вас клиент редиски). И падения сервера с твемпрокси нет, потому, что в этом случае, скорее всего, упал весь сервер.
Railsmax
21.10.2015 17:34И еще 5 копеек: маленький баш скрипт да или монит можно думаю — проверяем каждую минуту — процесс запущен — круто, если нет — убили процесс и стартанули заново (тут еще на всяк случай убить пид файл для надежности )
chizh_andrey
22.10.2015 11:51У нас есть что-то подобное и где-то даже применяется, но из-за того, что все сервисы задублированы, мы предпочитаем после падения посмотреть последние записи в логе, а уже потом перезапускать.
Railsmax
21.10.2015 17:36Есть вопрос если давно пользуете twemproxy сколько он зажирает ресурсов при длительном процессе использования месяц-пол года? А то я на вский случай взял large instance ec2 под него и смотрю как-то у меня пока нет необходимости в 8гб озу но кто его знает может разростется
mynameisdaniil
21.10.2015 18:13Не могу вам точно ответить, потому что все твемпрокси стоят рядом с клиентами редиски, а по отдельным процессам я память не мониторю, только по серверам. Могу лишь сказать, что проблемм каких то он ни разу не создавал за последние пару лет.
Railsmax
21.10.2015 20:53О спасибо большое — как раз задумвался а не добавить ли мне редис сервер к твемпрокси )
mynameisdaniil
21.10.2015 20:58:) Говорю же, твемпрокси нужно ставить туда где вы редиской пользуетесь. На сервер с вашим приложением. Рядом с клиентом редиски. А ферму редиски держать отдельно.
alekciy
22.10.2015 09:28Т.е. к примеру у нас 2 севера приложений, 2 сервера с редиской. Получается, что twemproxy тоже два, на каждом из серверов приложений. А они между собой как-то общаются для отслеживания состояния фермы с редиской или каждый из них автономен и сам решает вопрос куда роутить запросы и сам отслеживает доступность серверов фермы?
mynameisdaniil
22.10.2015 10:27+1Да, все верно. Нет, между собой они не общаются, каждый сам по себе. Поэтому, теоретически, возможны ситуации когда один инстанс твемпрокси считает, например, что отвалилась первая редиска, а второй считает что отвалилась вторая редиска. Или еще интереснее, только один из инстансов считает что отвалилась редиска а второй пишет в обе редиски. Разумеется, на практике такое бывает редко и не долго, но лучше всего если ваше приложение будет к этому готово. Вообще, как только у вас больше одного сервера чего угодно (и чтобы вам там не обещали) забудьте о простой жизни, потому что CAP теорема не дремлет а вместе с Мерфи они сделают вашу жизнь насыщенной и увлекательной :)
alekciy
22.10.2015 14:06А по какому алгоритму они ключи распределяют по серверам?
mynameisdaniil
22.10.2015 14:26По хэшу, а хеш на выбор (там куча алгоритмов). Ну и можно задать при помощи hash_tag чтобы данные попадали на один сервер т.е. хэш будет считаться не по всему ключу, а только по этому тегу.
т.е. my_key и my_other_key скорее всего попадут на разные сервера, зато my_key{group1} и my_{group1}_other_key попадут на один сервер.Railsmax
22.10.2015 18:14Там есть 3 типа на выбор судя по докам ketama, modula, random. (https://github.com/twitter/twemproxy) distribution:…
Railsmax
22.10.2015 18:17Хммм — у меня 5 web серваков и 2 редис сервера — зачем мне ставить 2 twemproxy? Я сделал отдельный сервак для twemproxy и все запросы шлю к нему а он уже решает куда рассылать дальше(собственно как обычный лоад балансер такой получается только с постоянным распределением по ключу ) — или я что-то не верно осознал?
chizh_andrey
22.10.2015 18:21Предлагается ставить не 2, а 5 в вашем случае для того чтобы избавиться от SPOF ( единой точки отказа ).



MuLLtiQ
22.10.2015 00:04А elasticsearch для этих целей не рассматривали?
chizh_andrey
22.10.2015 11:50Очень проницательно. Мы иногда думаем о таком подходе, но смущает то, что это не общая практика. Скажите, у вас есть опыт такого использования ES? Он масштабируется горизонтально?
alekciy
22.10.2015 14:11Только сейчас обсуждали с коллегой переход в одном крупном проекте с sphinx на elasticsearch. Все круто (ожидаемо). Из особенностей которые я, к примеру, учитываю — Java -> много ОЗУ, много ресурсов. Поэтому в таком контексте это не мой случай. Но у вас-то проблем с ОЗУ нет. С другой стороны, как я понял, у вас и с редиской проблем тоже нет.

ekho
22.10.2015 18:25Есть ещё довольно мощный и быстрый tarantool (http://tarantool.org/). Его активно используют такие проекты как avito и badoo.
jrip
>проблема больших данных
Больших это сколько терабайт?
>Не использовать персистентность редиса
Т.е. вы надеетесь что все целиком никогда не рухнет, а если рухнет у вас будет даунтайм на время заполнения редисов?
chizh_andrey
1) В нашем случае это несколько сотен Гб, для In-Memory это не мало.
2) Если ВСЕ целиком рухнет, да, у нас будет даунтайм, с этим не поспоришь, но наш способ позволяет избавиться от единой точки отказа ( в статье эту тему не затронули ).
GHostly_FOX
А если попробовать увеличить производительность за счет более производительных дисков?
Активировать вновь персистентность на SSD дисках при этом заставим Redis работать в режиме Master/Slave все данные добавляете/обновляете в мастере, а получение данные выполняете с Slave?
И еще вопрос — у вас обновление информации в Redis идет напрямую из приложения или через сервер очередей?
chizh_andrey
1) В общем случае персистентность в редисе работает, я бы только не рекомендовал режим, в котором Redis форкается перед сбросом данных. В нашем случае, за ненадобностью, проще отказаться от этой функции.
2) И так и так. Если не секрет, то почему это важно?
GHostly_FOX
интересуюсь потому что мы сейчас сами стоим перед выбором технологии
chizh_andrey
У нас архитектура позволяет многие сообщения положить в очередь и уже на бэкэнде в сервисах их обработать и там же идет большая часть обращений к редису. Но я считаю, что редис крайне быстр и к нему можно ходить и с фронта на прямую.
GHostly_FOX
ну вот мы тоже хотели на монго стоить архитектуру, но теперь думаю
chizh_andrey
Монга и редис не взаимо исключаемы, а скорее дополняемы.
В редисе доступны только запросы по ключу т.е. вы не можете сделать выборку всех товаров к примеру с категорией 5 или ценой больше 1000.
pansa
Можно поддерживать set, в котором будут перечислены все id товаров категории 5 или ценой больше 1000. =)
Если необходимые выборки заранее известны и их не очень много, то это вполне решение.
alekciy
А тип set разве не подходит? На сколько я помню на нем в редисе даже фасетчатый поиск строят.
chizh_andrey
Можно, но получается дублирование данных. Просто редис для других задач.
alekciy
Правильно ли я понимаю, что в вашем случае чисто в set хранить данные не получиться и нужно будет продублировать данные из других типов? Как результат возникает проблема с необходимость увеличить объем ОЗУ кластера + вопрос неконсистентности данных ввиду дублирования?
chizh_andrey
Да, правильно. Но я хотел донести основную идею: «Если у вас саморез, то не надо тянуться за молотком, нужно взять отвертку». Редис — это узкоспециализированная БД, ей не стоит заменять базы данных с «богатым инструментарием».
miolini
А чем второй режим лучше? Он append only.
chizh_andrey
Кстати, и это немаловажно, у редиса шикарная документация. И вот тут в деталях описаны плюсы и минусы различных подходов обеспечения персистентности.
Лично меня крайне сильно смущает в первом подходе необходимость форка. Пока форкается процесс, он не работает + копирует всю память, это приводит к тому, что реально можно использовать только половину оперативной памяти сервера, т.к. если занять больше, то редис при форке упадет.
stargrave2
В современных GNU/Linux системах fork-нутый процесс не копирует полностью память, а делает copy-on-write. В итоге объём потребляемой памяти при fork будет зависеть только от скорости обновления данных.
chizh_andrey
Могу лишь поделиться нашим опытом: в итоге либо сильно падает время ответа на время форка, либо процесс полностью лочится.
alekciy
Почему? В смысле, в чем там подводный камень.
chizh_andrey
Чуть выше писал, что у редиса отличная документация.
Отвечая на ваш вопрос, я писал о режиме RDB, который на момент форка перестает обслуживать запросы. В документации сказано, что это происходит от миллисекунд до секунд. В нашем случае даже это критично, хотя мы наблюдали и более долгие остановки.