
Привет!
Сегодня с вами Максим Козлов, руководитель Sber AR/VR Lab.
Устраивайтесь поудобнее, зовите кота, включайте лампу — это будет длинная история. О цифровых двойниках, volumetric-съёмке и о том, чем это всё обернётся для нас уже в скором будущем.

Всё началось с того, что Sber AR/VR Lab взялась за создание цифровых аватаров. В один момент стало понятно, что для них нам нужен датасет липсинка — то есть набор всех возможных положений лицевых мышц, которые используются при говорении и выражении эмоций. Такие датасеты позволили бы автоматизировать липсинк у цифровых аватаров.
Окей, решили мы — для этого нужно просто иметь возможность сканировать лица людей. И давайте чуть подробнее раскроем слово «сканировать».

Вот так это выглядит. Не слишком просто, но уж как есть.
Такая технология позволяет получить не просто качественную съёмку, а volumetric-данные, которые потом реконструируются в 3D-модель лица.
Какие камеры используются?
Для полноценной записи всех движений лица нужно минимум 18 камер машинного зрения. Разумеется, используется генлок — камеры синхронизированы между собой и со специальным стробосветом, который автоматически синхронизируется с каждым затвором камеры.
Мы используем камеры с технологией Global shutter, поэтому каждый пиксель в датчике начинает и заканчивает экспозицию одновременно. Это позволяет избежать смазанности и артефактов, которые возникают в стандартной схеме Rolling shutter при быстром движении, например при моргании.
Камеры далеко не простые: 4К, 60 кадров в секунду, 2 ТБ памяти на борту, специальная суперскоростная флешка. Такая камера снимает не видеоролик, а 60 кадров в секунду в DNG-формате — это максимально качественный на текущий момент исходник, где один кадр весит порядка 30 МБ.
Зачем нужен стробосвет?
Учитывая, что съёмка проводится на маленькой диафрагме, чтобы исключить смазанные кадры, нужно очень много света. Но если человека посадить перед всеми включёнными на полную мощность источниками света, он просто не сможет открыть глаза. Поэтому стробосвет позволяет минимизировать яркость для человека перед камерами и работать достаточно продолжительное время.
Также все источники света могут быть динамически управляемы, что даёт возможность воссоздать даже структуру пор — у каждого человека она своя, почти как отпечатки пальцев. Если уделить меньше внимания свету, смазанные и нечёткие кадры будут неизбежны, когда человек двигает головой или напрягает лицевые мышцы.
И вот что получается. Слева — лицо живого человека (моё, если быть точным). Посередине — многополигональная 3D-модель, промежуточный результат обработки. Справа — 3D-модель в цвете после финальной обработки.
Как выглядит этот процесс — от первого этапа к последнему
Вначале снимаются все положения мимических мышц (FACS) актёра, с которого мы создаём 3D-двойника. Использовать заранее заготовленные шаблоны не получится: мышцы у всех работают по-разному, а нам важна присущая конкретному человеку мимика. Когда все положения будут зафиксированы, получится полный датасет для создания цифрового аватара.
{kind=link}
Также у нас есть много часов съёмок актёра, наговаривающего различный текст. На этом большом датасете наша нейронка обучается липсинку. Конечно, есть моменты, по которым можно понять, что это всё же аватар, а не живой человек
Что примечательно: вся лицевая анимация и липсинк сделаны автоматически. На вход поступает только аудиодорожка с речью, фонемы распознаются нейронкой, и в соответствии с датасетом строится лицевая анимация.
Причём наша нейросеть уже умеет говорить на разных языках. Понятно, что актёру нужно создавать отдельные датасеты под каждый язык — наборы фонем различаются. Сейчас мы продолжаем снимать датасеты на разных языках, чтобы повысить качество липсинка.
Как итог — теперь с помощью нейросети можно автоматически создавать лицевую анимацию только на базе голоса. Больше никакой кропотливой работы 3D-аниматора, который вручную двигает губы под речь актёра.
Вот для этого мы и создавали volumetric-студию. Но используем её уже и для других целей — прогресс не стоит на месте.
Какие сейчас возможности у студии?
Анимация лица — не единственное, что мы сейчас можем сделать. Мы можем записывать и full-body-аватар — не только лицо, а всё тело. Получается полноценный цифровой двойник, которого можно переносить в метавселенные.
Например, вот volumetric-съёмки для проекта #СберТанцы, в рамках которого любой желающий мог станцевать вместе с цифровыми аватарами звёзд: Веры Брежневой, Клавы Коки, Вани Дмитриенко, Анет Сай и Филиппа Киркорова. Объёмное видео можно было посмотреть в браузере мобильного телефона в дополненной реальности на сайте проекта.
Мы работали в рамках ограничения 100 МБ, чтобы движущаяся модель сравнительно быстро скачивалась в 4G-сетях.
В чём сложности использования технологии?
Отдельная тема, как я уже писал выше, — подсветка. Несмотря на то, что volumetric снимается в движении, не должно быть теней — иначе возникнут сложности с реконструкцией.
Важно правильно расставить камеры — так, чтобы они снимали человека со всех сторон. Соответственно, самые низкие камеры должны захватывать нижнюю часть человека, а верхние камеры — с запасом снимать верхнюю часть. К примеру, когда записывали Филиппа Киркорова, камеры пришлось перенастраивать, потому что актёр выше среднего роста.
Пока есть ограничения по костюмам. Например, не получится снять модель в костюме с блёстками или светоотражающими элементами. Совсем мелкие детали, такие как шнурки, мы также не сможем реконструировать, если планируется в дальнейшем использовать низкополигональную модель.
Важно захватить для реконструкции все элементы тела и одежды — иначе придётся много работать в редакторе, вручную добавляя недостающие полигоны. Впрочем, какие-то мёртвые зоны всё равно могут быть. Например, та же подошва — если движения не предполагают поднятия ног на такую высоту, чтобы камера захватила обувь снизу. Или, например, могут быть не видны части широких штанин. Это уже можно доделать на этапе обработки.
Для обработки volumetric video мы используем Houdini. В нём мы делаем оптимизацию по количеству полигонов и клинап, а также можем частично изменить движения. В зависимости от задачи, мы можем уже записанное движение корректировать в Houdini после съёмок, а также можем запрограммировать, чтобы голова актёра постоянно смотрела на зрителя в зависимости от положения телефона.
Окей, настроили, изображение получается качественным. Что дальше?
Далее в бой вступает сервер по обработке записей с камер и множество cloud GPU-машин.
Основной сервер устанавливается вместе с остальным оборудованием на месте съёмок. Он не обрабатывает видео — только управляет камерами, экспортом данных, конвертацией и заливкой в облако. Для этого нужна соответствующая начинка: жёсткий диск на 300 ТБ и 20-гигабитная сетевая карта. Железу приходится пропускать через себя огромный поток данных, поэтому предусмотрен серьёзный сетевой стек.
Схематично процесс выглядит так:
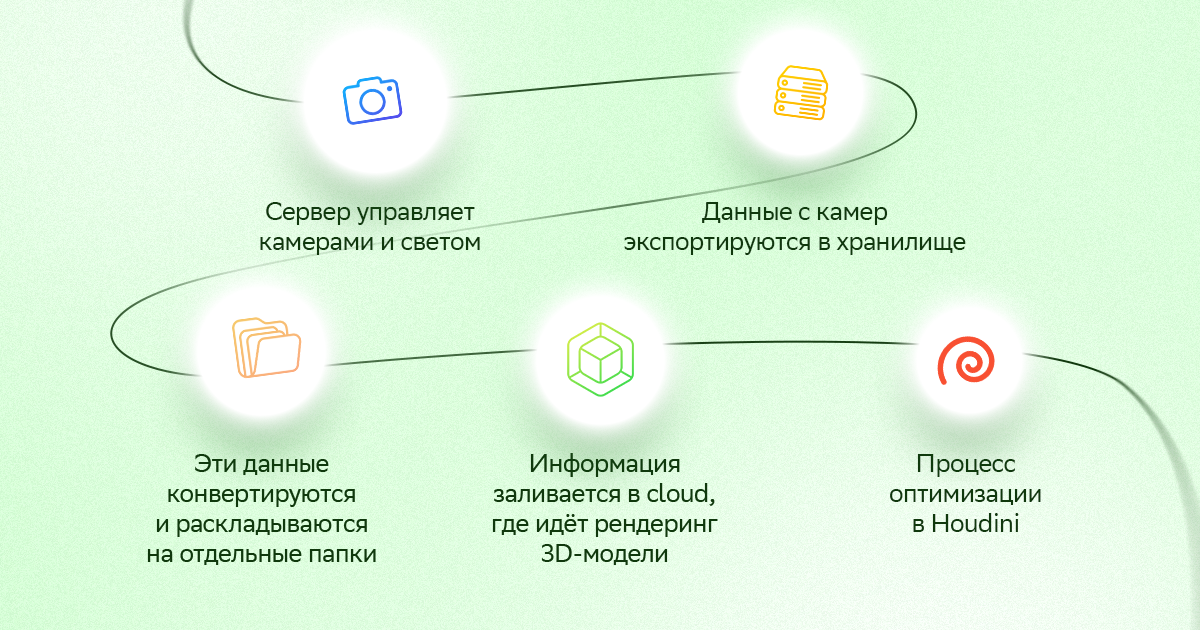
В каком качестве могут использоваться volumetric-модели?
В общем-то, в любом — вплоть до того, когда 3D-модель для нетренированного глаза неотличима от живого человека. Это определяется в первую очередь тем, где и как эти модели будут использоваться.
При первой сборке мы всегда получаем высокополигональную 3D-модель, которую крайне сложно отличить от оригинала. Уже сейчас мы можем обеспечить более 7 млн полигонов и максимально детальную сетку. Много текстур, много деталей:

Для видео (фильмов, рекламы) возможна максимальная детализация, как на изображении вверху. В этом случае мы минимально ограничены, так как при монтаже используется мощное оборудование, которое вытянет «тяжёлую» 3D-модель.
Если же 3D-аватар используется в интерактиве, где есть много пользователей с разным по мощности железом, здесь приходится идти на компромиссы — нужно учитывать пропускную способность канала и мощность устройства.
К примеру, для WebAR на мобильном телефоне лимит составляет 10 000 полигонов. Также важно учитывать и вес получаемого volumetric-видео, которое придётся скачивать на мобильный телефон. Мы работали в рамках ограничения 100 МБ на 15-20 секунд видео, чтобы пользователи могли сравнительно быстро открыть это видео в мобильном браузере телефона.

Куда дальше будет развиваться volumetric-технология?
Дальше — это онлайн-стриминг. Доработка нейросети, оптимизация изображения с меньшей потерей качества для воспроизведения на разных устройствах в реальном времени.
Представьте себе 50 камер вокруг боксёрского ринга или сотню камер вокруг футбольного поля. И вы смотрите матч с любой удобной точки и «летите» по полю.
Более того, это же не просто видео, это может быть виртуальный мир, в который мы интегрируем живое выступление артиста, и в это время мы можем одновременно путешествовать и взаимодействовать с другими участниками этого концерта.
И вновь — это сопряжение реального мира с метавселенной. Хотим мы того или нет, а они подбираются всё ближе к нам. Будем готовы?